 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
OOWL500: Overcoming Dataset Collection Bias in the Wild
Aug 24, 2021

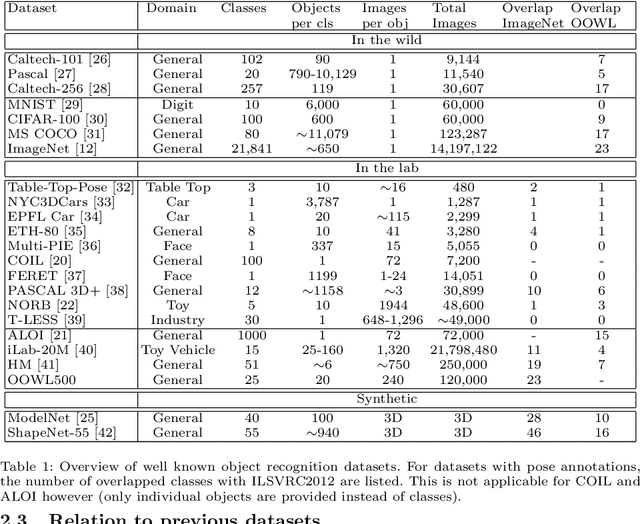

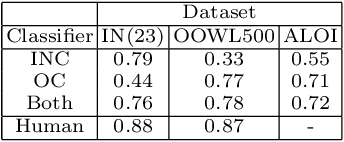
The hypothesis that image datasets gathered online "in the wild" can produce biased object recognizers, e.g. preferring professional photography or certain viewing angles, is studied. A new "in the lab" data collection infrastructure is proposed consisting of a drone which captures images as it circles around objects. Crucially, the control provided by this setup and the natural camera shake inherent to flight mitigate many biases. It's inexpensive and easily replicable nature may also potentially lead to a scalable data collection effort by the vision community. The procedure's usefulness is demonstrated by creating a dataset of Objects Obtained With fLight (OOWL). Denoted as OOWL500, it contains 120,000 images of 500 objects and is the largest "in the lab" image dataset available when both number of classes and objects per class are considered. Furthermore, it has enabled several of new insights on object recognition. First, a novel adversarial attack strategy is proposed, where image perturbations are defined in terms of semantic properties such as camera shake and pose. Indeed, experiments have shown that ImageNet has considerable amounts of pose and professional photography bias. Second, it is used to show that the augmentation of in the wild datasets, such as ImageNet, with in the lab data, such as OOWL500, can significantly decrease these biases, leading to object recognizers of improved generalization. Third, the dataset is used to study questions on "best procedures" for dataset collection. It is revealed that data augmentation with synthetic images does not suffice to eliminate in the wild datasets biases, and that camera shake and pose diversity play a more important role in object recognition robustness than previously thought.
Image Super-Resolution via Attention based Back Projection Networks
Oct 10, 2019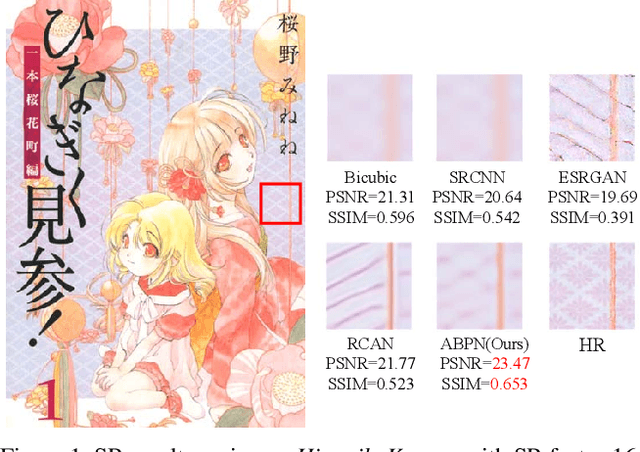
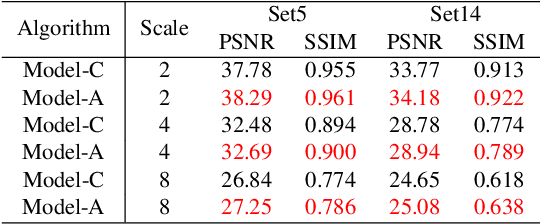
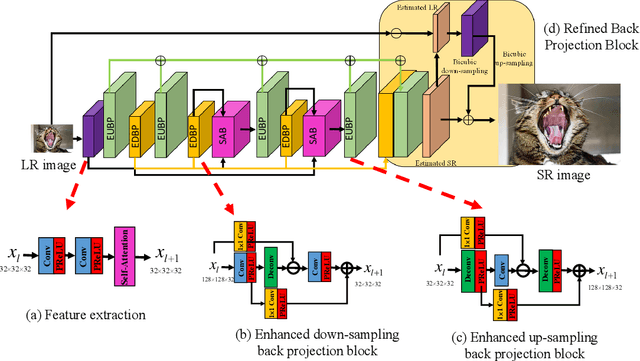
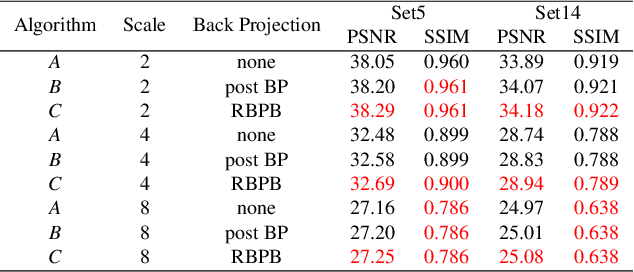
Deep learning based image Super-Resolution (SR) has shown rapid development due to its ability of big data digestion. Generally, deeper and wider networks can extract richer feature maps and generate SR images with remarkable quality. However, the more complex network we have, the more time consumption is required for practical applications. It is important to have a simplified network for efficient image SR. In this paper, we propose an Attention based Back Projection Network (ABPN) for image super-resolution. Similar to some recent works, we believe that the back projection mechanism can be further developed for SR. Enhanced back projection blocks are suggested to iteratively update low- and high-resolution feature residues. Inspired by recent studies on attention models, we propose a Spatial Attention Block (SAB) to learn the cross-correlation across features at different layers. Based on the assumption that a good SR image should be close to the original LR image after down-sampling. We propose a Refined Back Projection Block (RBPB) for final reconstruction. Extensive experiments on some public and AIM2019 Image Super-Resolution Challenge datasets show that the proposed ABPN can provide state-of-the-art or even better performance in both quantitative and qualitative measurements.
* 9 pages, 7 figures, ABPN
A Picture May Be Worth a Hundred Words for Visual Question Answering
Jun 25, 2021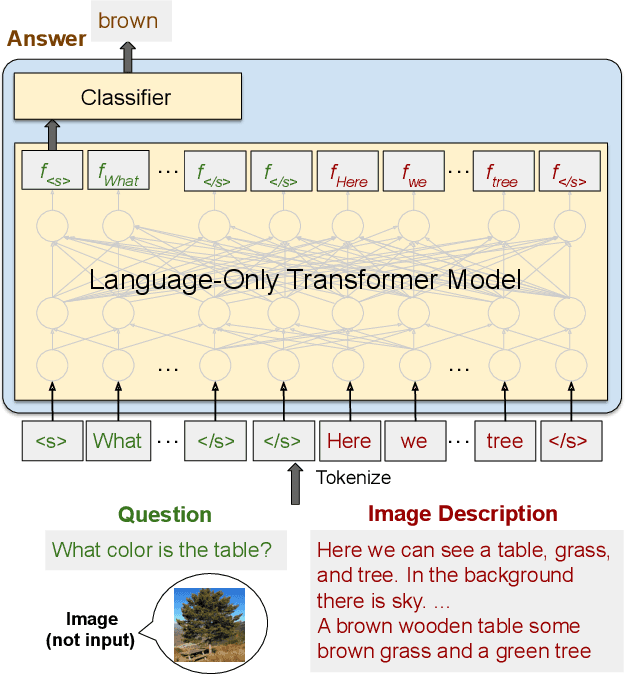

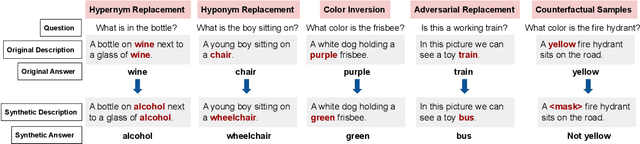
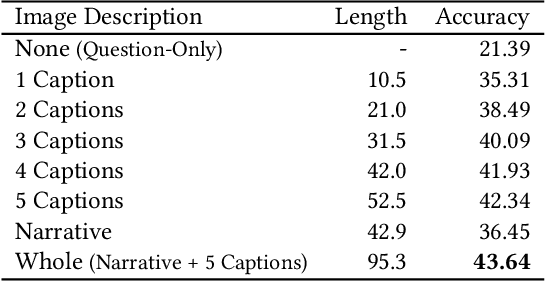
How far can we go with textual representations for understanding pictures? In image understanding, it is essential to use concise but detailed image representations. Deep visual features extracted by vision models, such as Faster R-CNN, are prevailing used in multiple tasks, and especially in visual question answering (VQA). However, conventional deep visual features may struggle to convey all the details in an image as we humans do. Meanwhile, with recent language models' progress, descriptive text may be an alternative to this problem. This paper delves into the effectiveness of textual representations for image understanding in the specific context of VQA. We propose to take description-question pairs as input, instead of deep visual features, and fed them into a language-only Transformer model, simplifying the process and the computational cost. We also experiment with data augmentation techniques to increase the diversity in the training set and avoid learning statistical bias. Extensive evaluations have shown that textual representations require only about a hundred words to compete with deep visual features on both VQA 2.0 and VQA-CP v2.
Boosting EfficientNets Ensemble Performance via Pseudo-Labels and Synthetic Images by pix2pixHD for Infection and Ischaemia Classification in Diabetic Foot Ulcers
Nov 30, 2021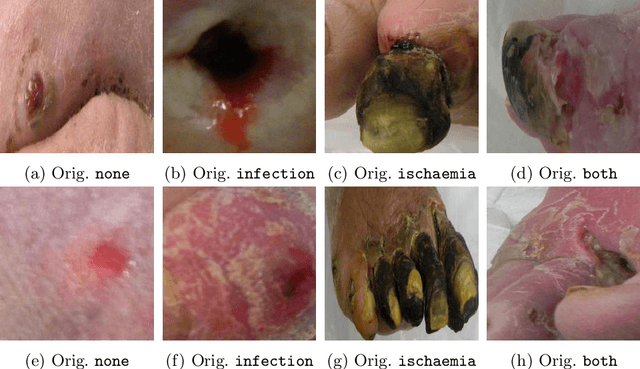
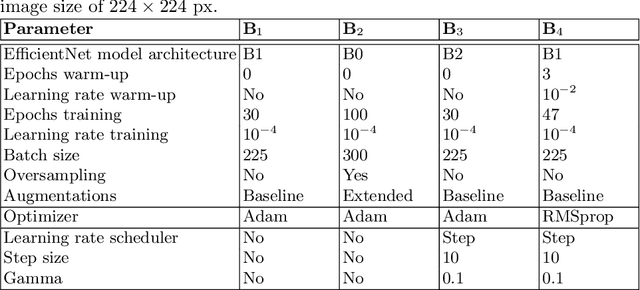
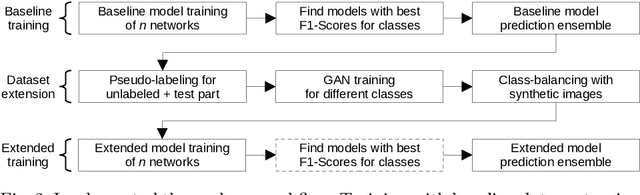
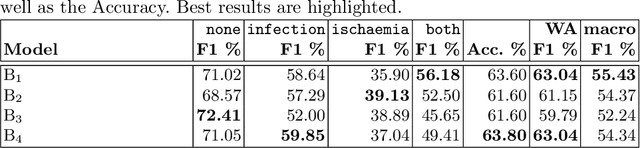
Diabetic foot ulcers are a common manifestation of lesions on the diabetic foot, a syndrome acquired as a long-term complication of diabetes mellitus. Accompanying neuropathy and vascular damage promote acquisition of pressure injuries and tissue death due to ischaemia. Affected areas are prone to infections, hindering the healing progress. The research at hand investigates an approach on classification of infection and ischaemia, conducted as part of the Diabetic Foot Ulcer Challenge (DFUC) 2021. Different models of the EfficientNet family are utilized in ensembles. An extension strategy for the training data is applied, involving pseudo-labeling for unlabeled images, and extensive generation of synthetic images via pix2pixHD to cope with severe class imbalances. The resulting extended training dataset features $8.68$ times the size of the baseline and shows a real to synthetic image ratio of $1:3$. Performances of models and ensembles trained on the baseline and extended training dataset are compared. Synthetic images featured a broad qualitative variety. Results show that models trained on the extended training dataset as well as their ensemble benefit from the large extension. F1-Scores for rare classes receive outstanding boosts, while those for common classes are either not harmed or boosted moderately. A critical discussion concretizes benefits and identifies limitations, suggesting improvements. The work concludes that classification performance of individual models as well as that of ensembles can be boosted utilizing synthetic images. Especially performance for rare classes benefits notably.
Reversible GANs for Memory-efficient Image-to-Image Translation
Feb 07, 2019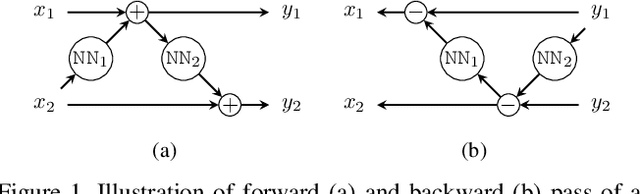
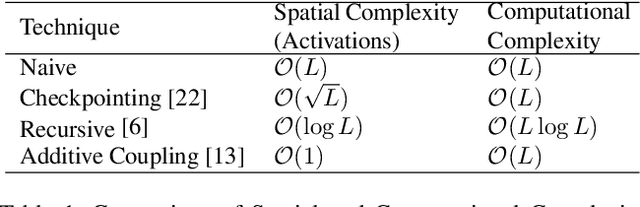
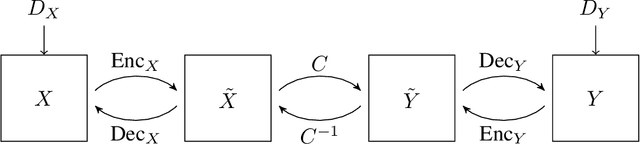

The Pix2pix and CycleGAN losses have vastly improved the qualitative and quantitative visual quality of results in image-to-image translation tasks. We extend this framework by exploring approximately invertible architectures which are well suited to these losses. These architectures are approximately invertible by design and thus partially satisfy cycle-consistency before training even begins. Furthermore, since invertible architectures have constant memory complexity in depth, these models can be built arbitrarily deep. We are able to demonstrate superior quantitative output on the Cityscapes and Maps datasets at near constant memory budget.
Gradient Inversion Attack: Leaking Private Labels in Two-Party Split Learning
Nov 25, 2021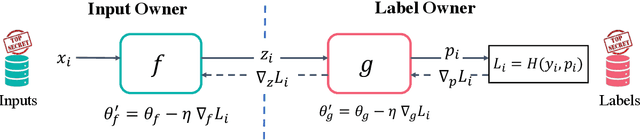
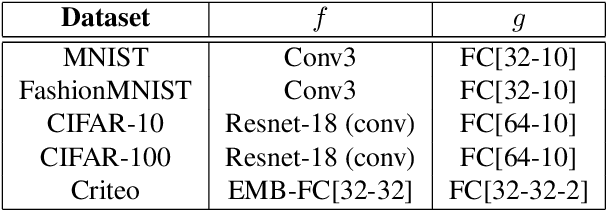
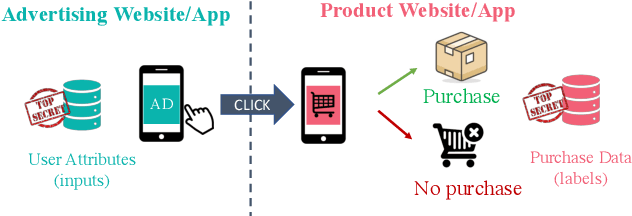
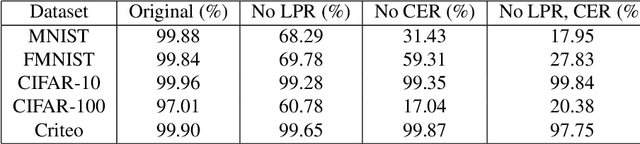
Split learning is a popular technique used to perform vertical federated learning, where the goal is to jointly train a model on the private input and label data held by two parties. To preserve privacy of the input and label data, this technique uses a split model and only requires the exchange of intermediate representations (IR) of the inputs and gradients of the IR between the two parties during the learning process. In this paper, we propose Gradient Inversion Attack (GIA), a label leakage attack that allows an adversarial input owner to learn the label owner's private labels by exploiting the gradient information obtained during split learning. GIA frames the label leakage attack as a supervised learning problem by developing a novel loss function using certain key properties of the dataset and models. Our attack can uncover the private label data on several multi-class image classification problems and a binary conversion prediction task with near-perfect accuracy (97.01% - 99.96%), demonstrating that split learning provides negligible privacy benefits to the label owner. Furthermore, we evaluate the use of gradient noise to defend against GIA. While this technique is effective for simpler datasets, it significantly degrades utility for datasets with higher input dimensionality. Our findings underscore the need for better privacy-preserving training techniques for vertically split data.
BUSU-Net: An Ensemble U-Net Framework for Medical Image Segmentation
Mar 08, 2020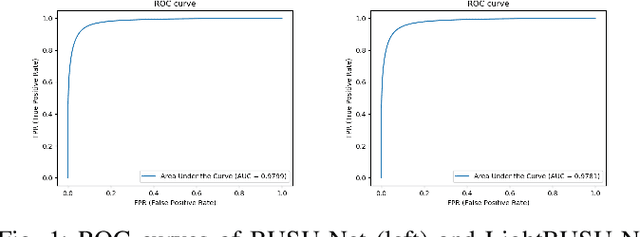
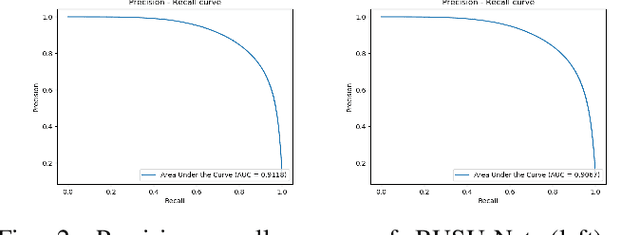
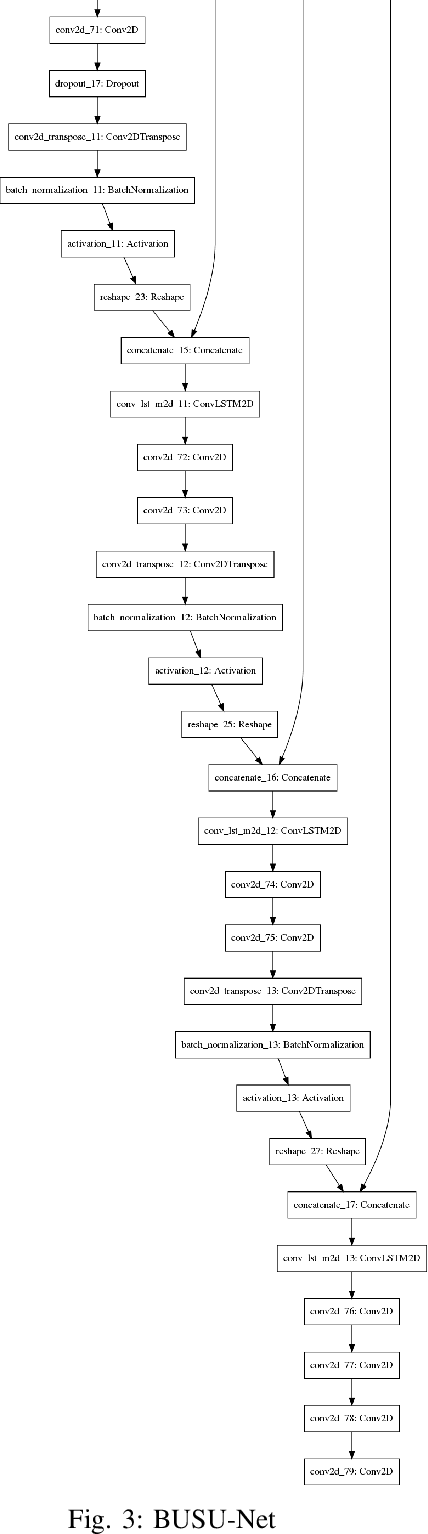
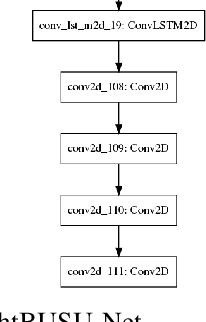
In recent years, convolutional neural networks (CNNs) have revolutionized medical image analysis. One of the most well-known CNN architectures in semantic segmentation is the U-net, which has achieved much success in several medical image segmentation applications. Also more recently, with the rise of autoML ad advancements in neural architecture search (NAS), methods like NAS-Unet have been proposed for NAS in medical image segmentation. In this paper, with inspiration from LadderNet, U-Net, autoML and NAS, we propose an ensemble deep neural network with an underlying U-Net framework consisting of bi-directional convolutional LSTMs and dense connections, where the first (from left) U-Net-like network is deeper than the second (from left). We show that this ensemble network outperforms recent state-of-the-art networks in several evaluation metrics, and also evaluate a lightweight version of this ensemble network, which also outperforms recent state-of-the-art networks in some evaluation metrics.
Unsupervised Deformable Image Registration Using Cycle-Consistent CNN
Jul 02, 2019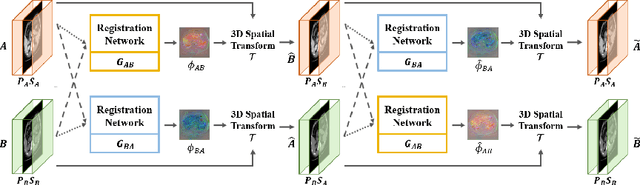
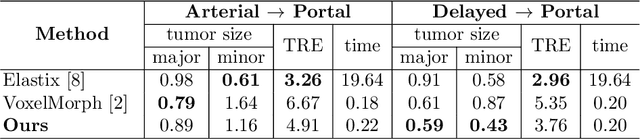
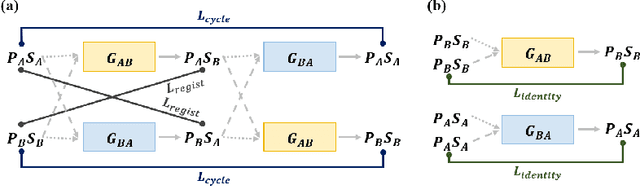
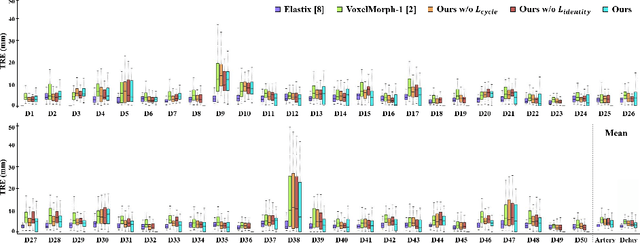
Medical image registration is one of the key processing steps for biomedical image analysis such as cancer diagnosis. Recently, deep learning based supervised and unsupervised image registration methods have been extensively studied due to its excellent performance in spite of ultra-fast computational time compared to the classical approaches. In this paper, we present a novel unsupervised medical image registration method that trains deep neural network for deformable registration of 3D volumes using a cycle-consistency. Thanks to the cycle consistency, the proposed deep neural networks can take diverse pair of image data with severe deformation for accurate registration. Experimental results using multiphase liver CT images demonstrate that our method provides very precise 3D image registration within a few seconds, resulting in more accurate cancer size estimation.
DRBANET: A Lightweight Dual-Resolution Network for Semantic Segmentation with Boundary Auxiliary
Oct 31, 2021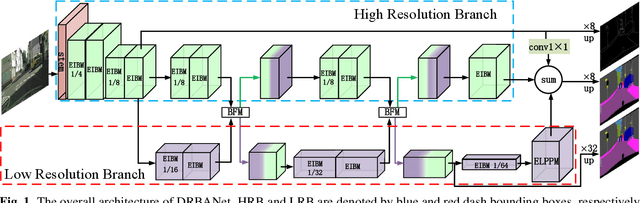
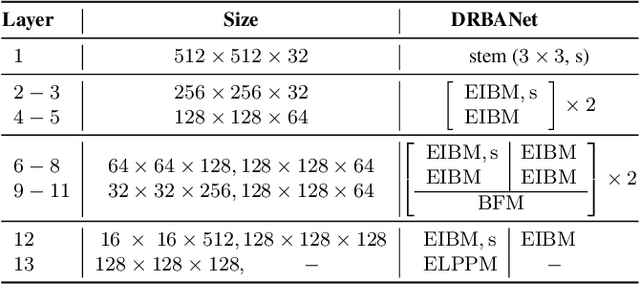
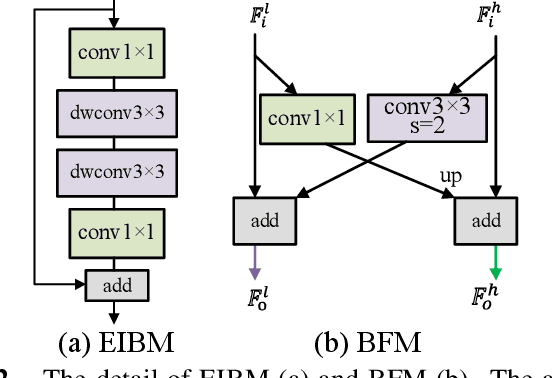
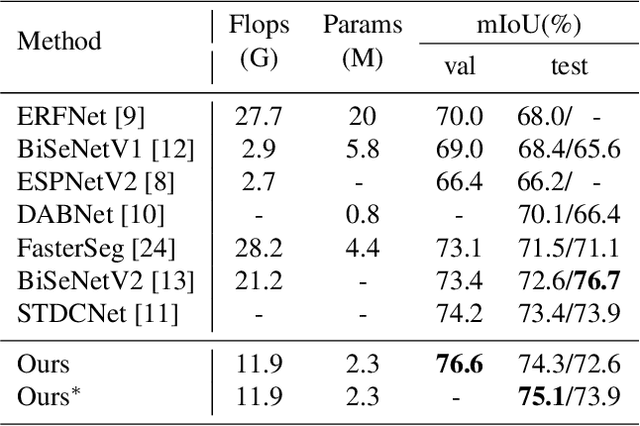
Due to the powerful ability to encode image details and semantics, many lightweight dual-resolution networks have been proposed in recent years. However, most of them ignore the benefit of boundary information. This paper introduces a lightweight dual-resolution network, called DRBANet, aiming to refine semantic segmentation results with the aid of boundary information. DRBANet adopts dual parallel architecture, including: high resolution branch (HRB) and low resolution branch (LRB). Specifically, HRB mainly consists of a set of Efficient Inverted Bottleneck Modules (EIBMs), which learn feature representations with larger receptive fields. LRB is composed of a series of EIBMs and an Extremely Lightweight Pyramid Pooling Module (ELPPM), where ELPPM is utilized to capture multi-scale context through hierarchical residual connections. Finally, a boundary supervision head is designed to capture object boundaries in HRB. Extensive experiments on Cityscapes and CamVid datasets demonstrate that our method achieves promising trade-off between segmentation accuracy and running efficiency.
Hierarchical Attention Networks for Medical Image Segmentation
Nov 20, 2019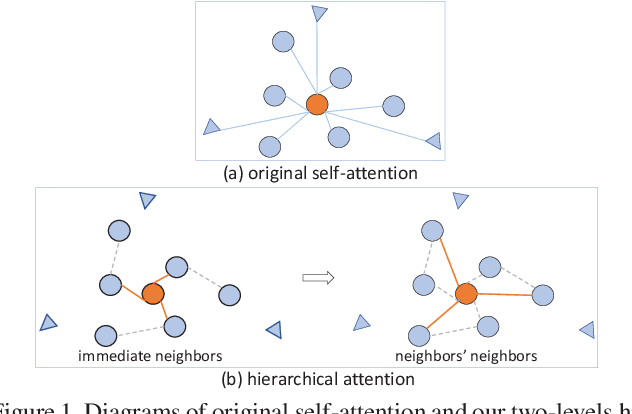
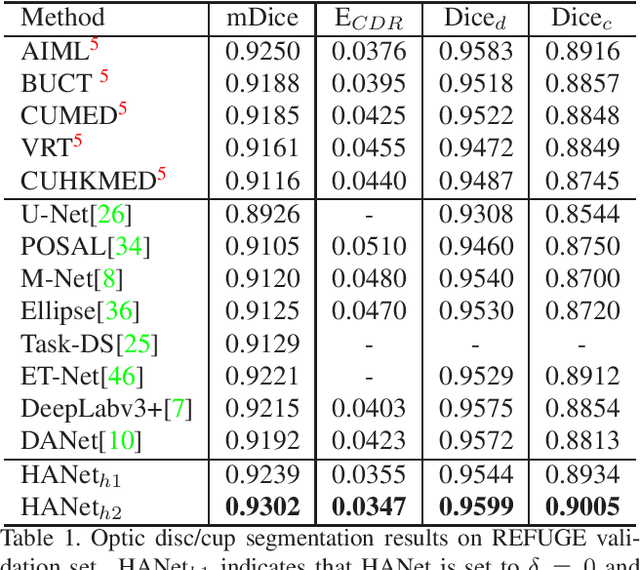
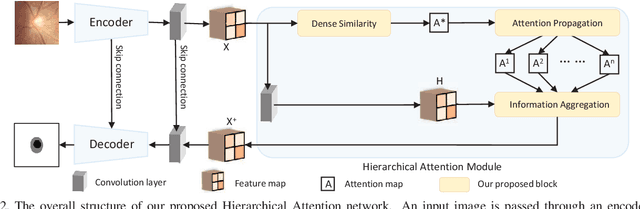
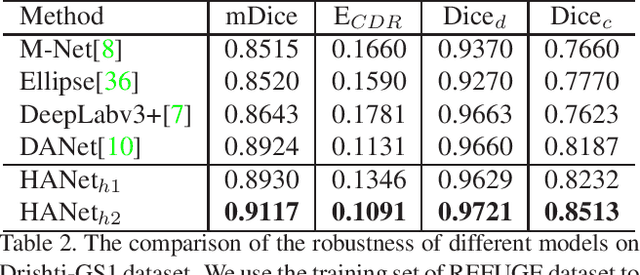
The medical image is characterized by the inter-class indistinction, high variability, and noise, where the recognition of pixels is challenging. Unlike previous self-attention based methods that capture context information from one level, we reformulate the self-attention mechanism from the view of the high-order graph and propose a novel method, namely Hierarchical Attention Network (HANet), to address the problem of medical image segmentation. Concretely, an HA module embedded in the HANet captures context information from neighbors of multiple levels, where these neighbors are extracted from the high-order graph. In the high-order graph, there will be an edge between two nodes only if the correlation between them is high enough, which naturally reduces the noisy attention information caused by the inter-class indistinction. The proposed HA module is robust to the variance of input and can be flexibly inserted into the existing convolution neural networks. We conduct experiments on three medical image segmentation tasks including optic disc/cup segmentation, blood vessel segmentation, and lung segmentation. Extensive results show our method is more effective and robust than the existing state-of-the-art methods.