 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Attention-Guided Generative Adversarial Networks for Unsupervised Image-to-Image Translation
Apr 14, 2019

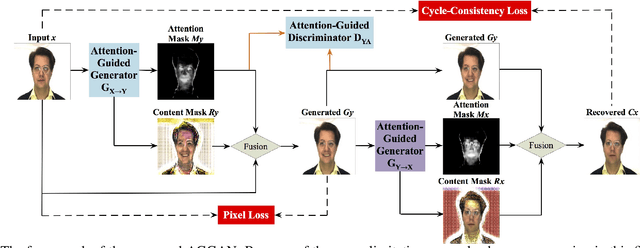

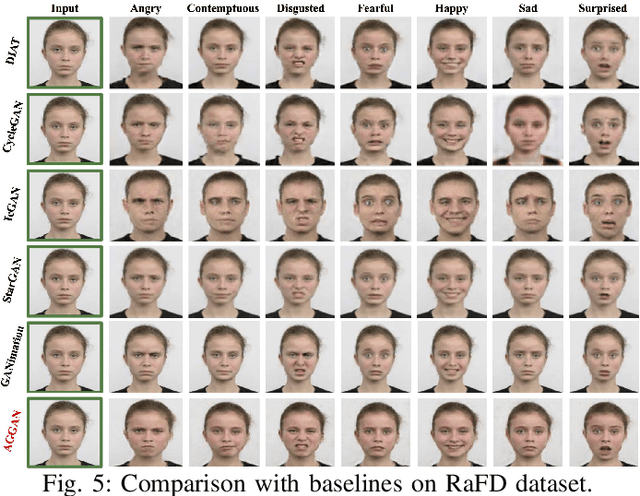
The state-of-the-art approaches in Generative Adversarial Networks (GANs) are able to learn a mapping function from one image domain to another with unpaired image data. However, these methods often produce artifacts and can only be able to convert low-level information, but fail to transfer high-level semantic part of images. The reason is mainly that generators do not have the ability to detect the most discriminative semantic part of images, which thus makes the generated images with low-quality. To handle the limitation, in this paper we propose a novel Attention-Guided Generative Adversarial Network (AGGAN), which can detect the most discriminative semantic object and minimize changes of unwanted part for semantic manipulation problems without using extra data and models. The attention-guided generators in AGGAN are able to produce attention masks via a built-in attention mechanism, and then fuse the input image with the attention mask to obtain a target image with high-quality. Moreover, we propose a novel attention-guided discriminator which only considers attended regions. The proposed AGGAN is trained by an end-to-end fashion with an adversarial loss, cycle-consistency loss, pixel loss and attention loss. Both qualitative and quantitative results demonstrate that our approach is effective to generate sharper and more accurate images than existing models.
A Matched-filter based method in the Synthetic Aperture Radar Images Using FMCW radar
Oct 31, 2021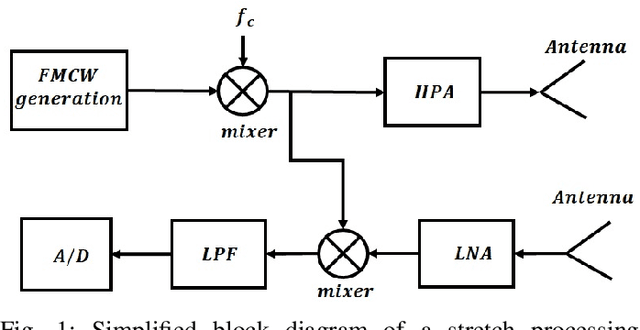
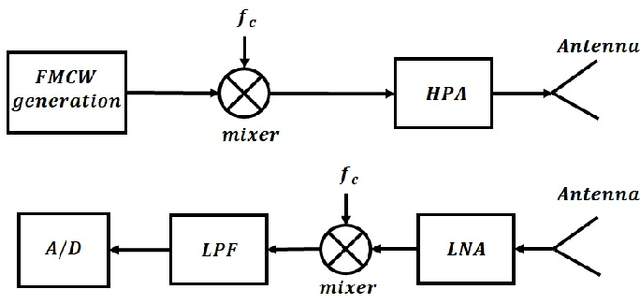
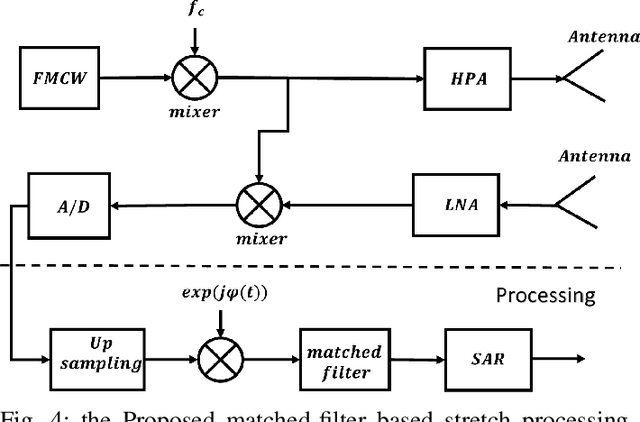
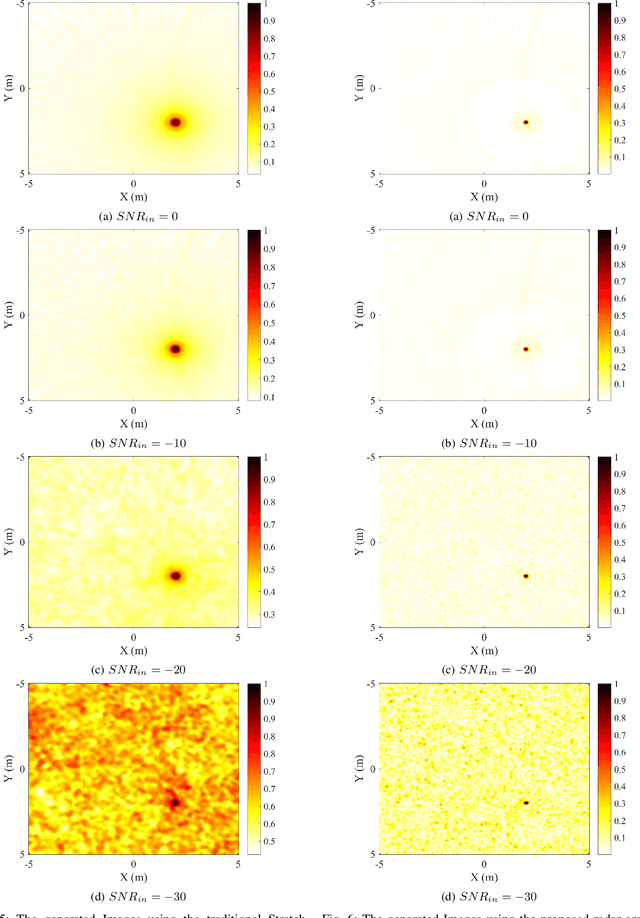
The stretch processing architecture is commonly used for frequency modulated continuous wave (FMCW) radar due to its inexpensive hardware, low sampling rate, and simple architecture. However, the stretch processing architecture is not able to achieve optimal Signal to Noise ratio (SNR) in comparison to the matched-filter architecture. In this paper, we aim to propose a method whereby stretch processing can achieve optimal SNR. Hence, we develop a novel processing method to enable applying a matched filter to the output of the stretch processing. The proposed architecture achieves optimal SNR while it can operate on a low sampling rate. In addition, the combination of the proposed radar architecture and SAR technique can generate high-quality images. To evaluate the performance of the proposed architecture, four scenarios are considered. Simulation is carried out based on these scenarios. The simulation results show that the proposed radar demonstrates the ability to generate an image with higher quality over stretch processing. This proposed radar can also bring a bigger gain compression.
Low-Rank Subspaces in GANs
Jun 08, 2021
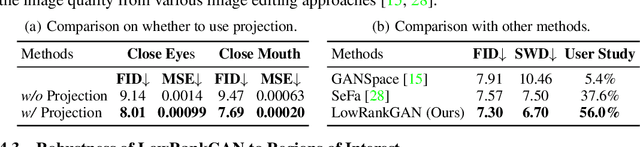


The latent space of a Generative Adversarial Network (GAN) has been shown to encode rich semantics within some subspaces. To identify these subspaces, researchers typically analyze the statistical information from a collection of synthesized data, and the identified subspaces tend to control image attributes globally (i.e., manipulating an attribute causes the change of an entire image). By contrast, this work introduces low-rank subspaces that enable more precise control of GAN generation. Concretely, given an arbitrary image and a region of interest (e.g., eyes of face images), we manage to relate the latent space to the image region with the Jacobian matrix and then use low-rank factorization to discover steerable latent subspaces. There are three distinguishable strengths of our approach that can be aptly called LowRankGAN. First, compared to analytic algorithms in prior work, our low-rank factorization of Jacobians is able to find the low-dimensional representation of attribute manifold, making image editing more precise and controllable. Second, low-rank factorization naturally yields a null space of attributes such that moving the latent code within it only affects the outer region of interest. Therefore, local image editing can be simply achieved by projecting an attribute vector into the null space without relying on a spatial mask as existing methods do. Third, our method can robustly work with a local region from one image for analysis yet well generalize to other images, making it much easy to use in practice. Extensive experiments on state-of-the-art GAN models (including StyleGAN2 and BigGAN) trained on various datasets demonstrate the effectiveness of our LowRankGAN.
Feature Detection for Hand Hygiene Stages
Aug 06, 2021
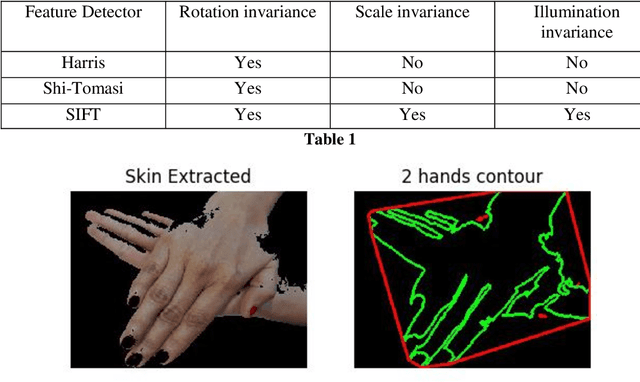
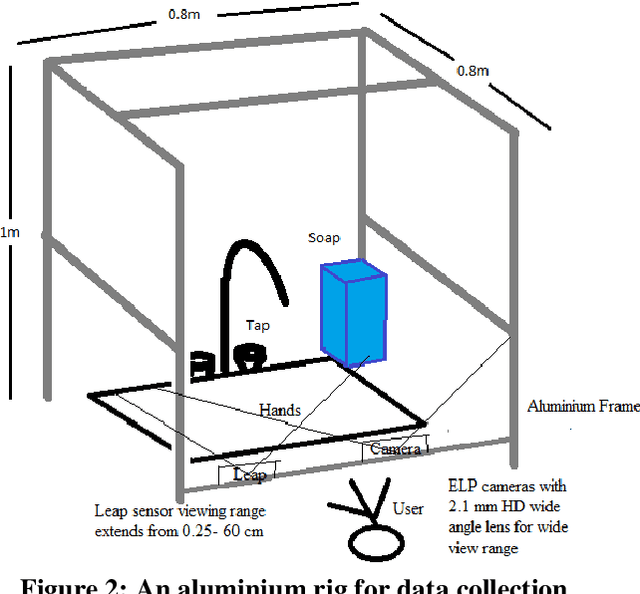
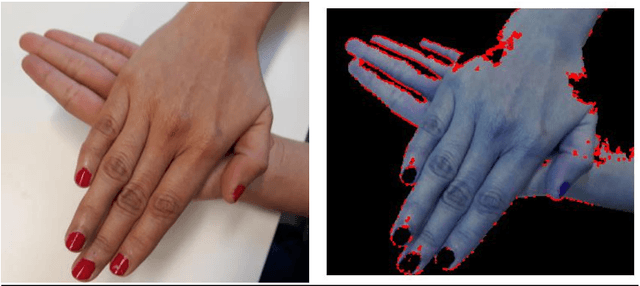
The process of hand washing involves complex hand movements. There are six principal sequential steps for washing hands as per the World Health Organisation (WHO) guidelines. In this work, a detailed description of an aluminium rig construction for creating a robust hand-washing dataset is discussed. The preliminary results with the help of image processing and computer vision algorithms for hand pose extraction and feature detection such as Harris detector, Shi-Tomasi and SIFT are demonstrated. The hand hygiene pose- Rub hands palm to palm was captured as an input image for running all the experiments. The future work will focus upon processing the video recordings of hand movements captured and applying deep-learning solutions for the classification of hand-hygiene stages.
Dynamic Token Normalization Improves Vision Transformer
Dec 05, 2021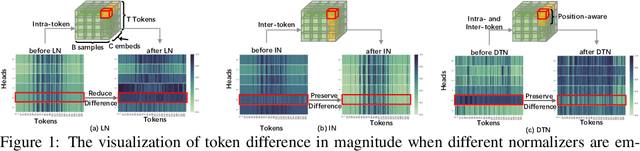
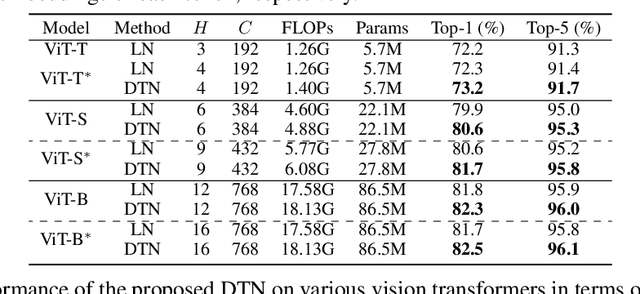
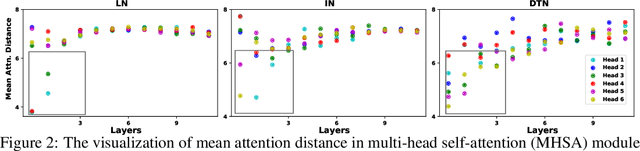

Vision Transformer (ViT) and its variants (e.g., Swin, PVT) have achieved great success in various computer vision tasks, owing to their capability to learn long-range contextual information. Layer Normalization (LN) is an essential ingredient in these models. However, we found that the ordinary LN makes tokens at different positions similar in magnitude because it normalizes embeddings within each token. It is difficult for Transformers to capture inductive bias such as the positional context in an image with LN. We tackle this problem by proposing a new normalizer, termed Dynamic Token Normalization (DTN), where normalization is performed both within each token (intra-token) and across different tokens (inter-token). DTN has several merits. Firstly, it is built on a unified formulation and thus can represent various existing normalization methods. Secondly, DTN learns to normalize tokens in both intra-token and inter-token manners, enabling Transformers to capture both the global contextual information and the local positional context. {Thirdly, by simply replacing LN layers, DTN can be readily plugged into various vision transformers, such as ViT, Swin, PVT, LeViT, T2T-ViT, BigBird and Reformer. Extensive experiments show that the transformer equipped with DTN consistently outperforms baseline model with minimal extra parameters and computational overhead. For example, DTN outperforms LN by $0.5\%$ - $1.2\%$ top-1 accuracy on ImageNet, by $1.2$ - $1.4$ box AP in object detection on COCO benchmark, by $2.3\%$ - $3.9\%$ mCE in robustness experiments on ImageNet-C, and by $0.5\%$ - $0.8\%$ accuracy in Long ListOps on Long-Range Arena.} Codes will be made public at \url{https://github.com/wqshao126/DTN}
A Point Cloud Generative Model via Tree-Structured Graph Convolutions for 3D Brain Shape Reconstruction
Jul 21, 2021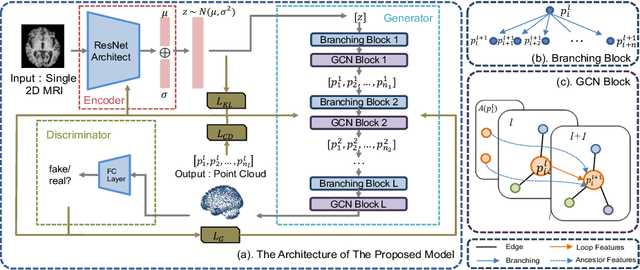

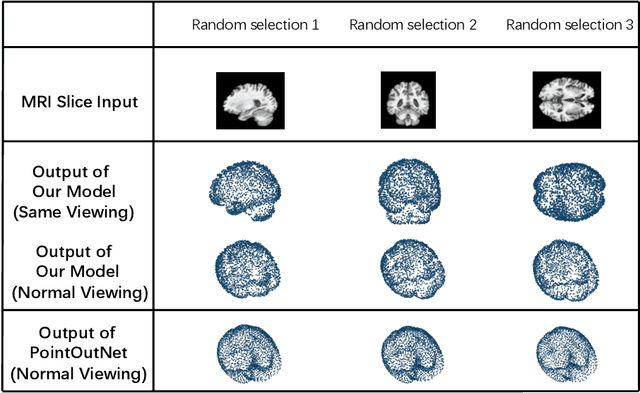

Fusing medical images and the corresponding 3D shape representation can provide complementary information and microstructure details to improve the operational performance and accuracy in brain surgery. However, compared to the substantial image data, it is almost impossible to obtain the intraoperative 3D shape information by using physical methods such as sensor scanning, especially in minimally invasive surgery and robot-guided surgery. In this paper, a general generative adversarial network (GAN) architecture based on graph convolutional networks is proposed to reconstruct the 3D point clouds (PCs) of brains by using one single 2D image, thus relieving the limitation of acquiring 3D shape data during surgery. Specifically, a tree-structured generative mechanism is constructed to use the latent vector effectively and transfer features between hidden layers accurately. With the proposed generative model, a spontaneous image-to-PC conversion is finished in real-time. Competitive qualitative and quantitative experimental results have been achieved on our model. In multiple evaluation methods, the proposed model outperforms another common point cloud generative model PointOutNet.
TALISMAN: Targeted Active Learning for Object Detection with Rare Classes and Slices using Submodular Mutual Information
Nov 30, 2021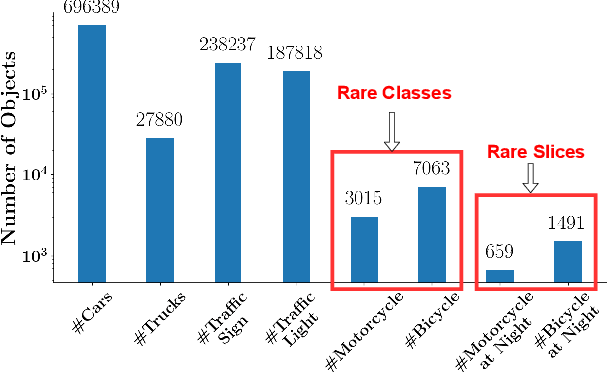
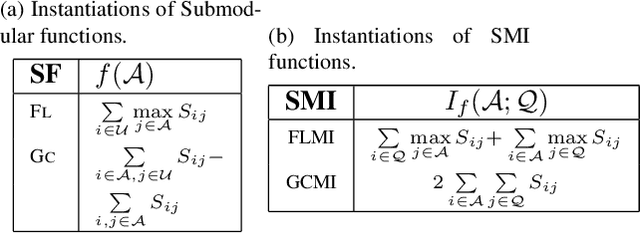
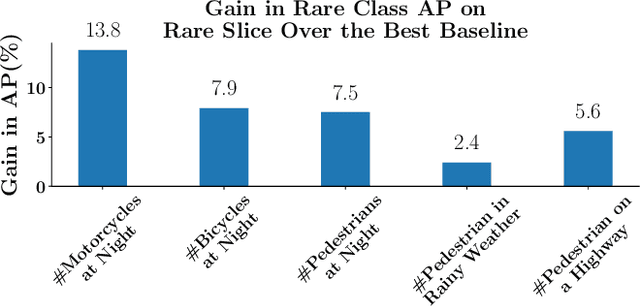
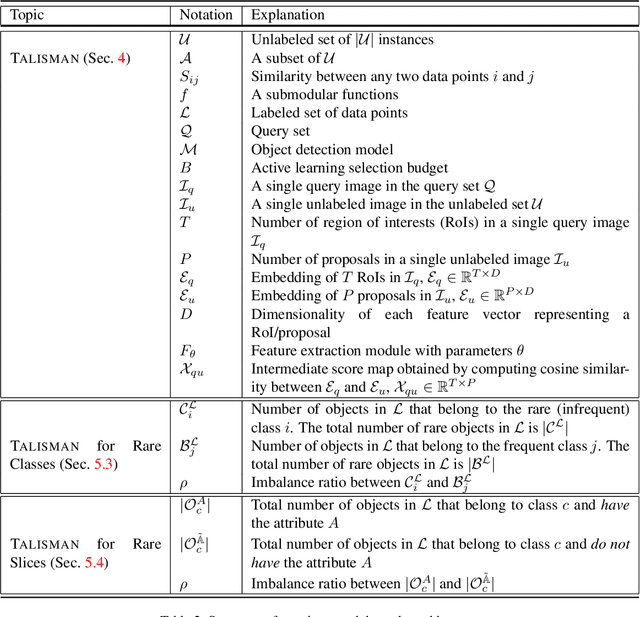
Deep neural networks based object detectors have shown great success in a variety of domains like autonomous vehicles, biomedical imaging, etc. It is known that their success depends on a large amount of data from the domain of interest. While deep models often perform well in terms of overall accuracy, they often struggle in performance on rare yet critical data slices. For example, data slices like "motorcycle at night" or "bicycle at night" are often rare but very critical slices for self-driving applications and false negatives on such rare slices could result in ill-fated failures and accidents. Active learning (AL) is a well-known paradigm to incrementally and adaptively build training datasets with a human in the loop. However, current AL based acquisition functions are not well-equipped to tackle real-world datasets with rare slices, since they are based on uncertainty scores or global descriptors of the image. We propose TALISMAN, a novel framework for Targeted Active Learning or object detectIon with rare slices using Submodular MutuAl iNformation. Our method uses the submodular mutual information functions instantiated using features of the region of interest (RoI) to efficiently target and acquire data points with rare slices. We evaluate our framework on the standard PASCAL VOC07+12 and BDD100K, a real-world self-driving dataset. We observe that TALISMAN outperforms other methods by in terms of average precision on rare slices, and in terms of mAP.
Adversarial Examples Improve Image Recognition
Nov 21, 2019
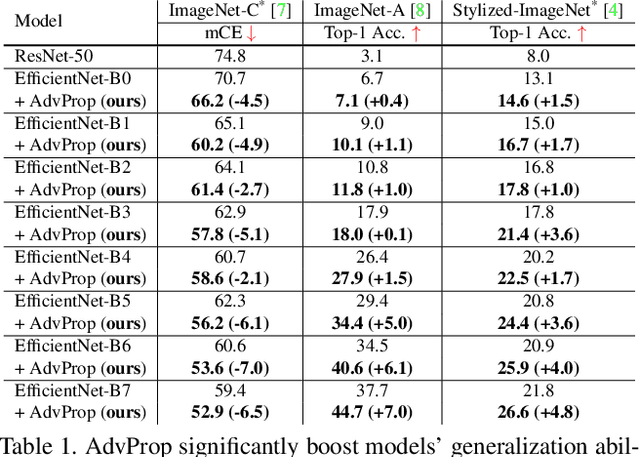
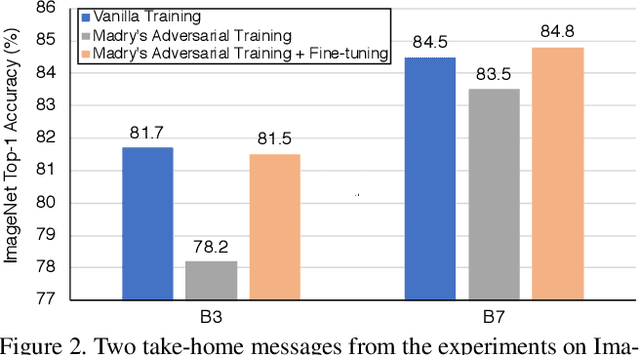
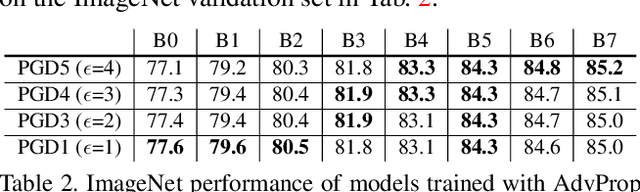
Adversarial examples are commonly viewed as a threat to ConvNets. Here we present an opposite perspective: adversarial examples can be used to improve image recognition models if harnessed in the right manner. We propose AdvProp, an enhanced adversarial training scheme which treats adversarial examples as additional examples, to prevent overfitting. Key to our method is the usage of a separate auxiliary batch norm for adversarial examples, as they have different underlying distributions to normal examples. We show that AdvProp improves a wide range of models on various image recognition tasks and performs better when the models are bigger. For instance, by applying AdvProp to the latest EfficientNet-B7 [28] on ImageNet, we achieve significant improvements on ImageNet (+0.7%), ImageNet-C (+6.5%), ImageNet-A (+7.0%), Stylized-ImageNet (+4.8%). With an enhanced EfficientNet-B8, our method achieves the state-of-the-art 85.5% ImageNet top-1 accuracy without extra data. This result even surpasses the best model in [20] which is trained with 3.5B Instagram images (~3000X more than ImageNet) and ~9.4X more parameters. Models are available at https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet.
Image Super-Resolution via Attention based Back Projection Networks
Oct 10, 2019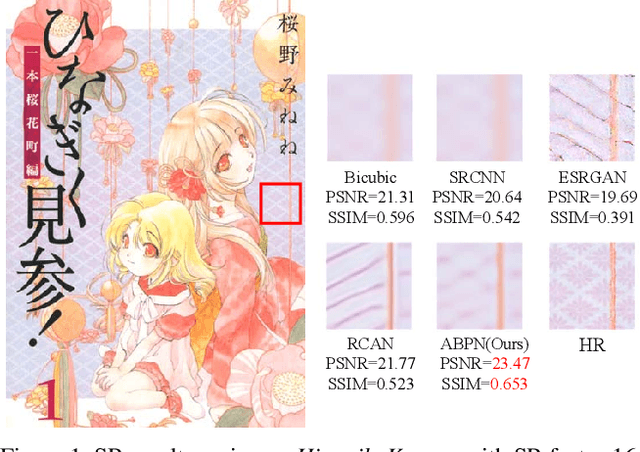
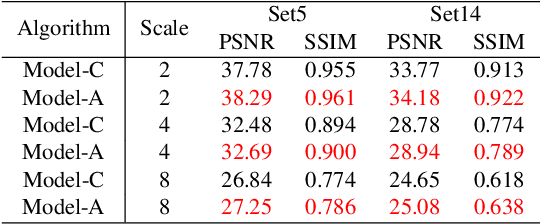
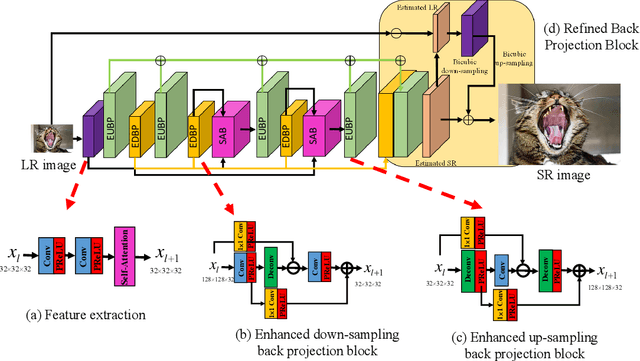
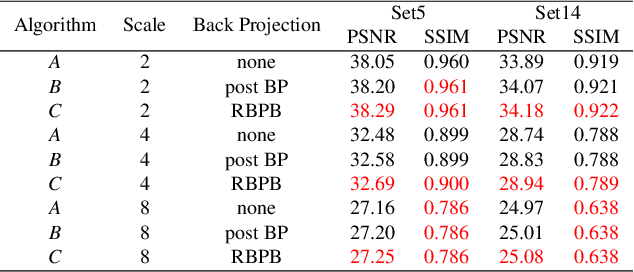
Deep learning based image Super-Resolution (SR) has shown rapid development due to its ability of big data digestion. Generally, deeper and wider networks can extract richer feature maps and generate SR images with remarkable quality. However, the more complex network we have, the more time consumption is required for practical applications. It is important to have a simplified network for efficient image SR. In this paper, we propose an Attention based Back Projection Network (ABPN) for image super-resolution. Similar to some recent works, we believe that the back projection mechanism can be further developed for SR. Enhanced back projection blocks are suggested to iteratively update low- and high-resolution feature residues. Inspired by recent studies on attention models, we propose a Spatial Attention Block (SAB) to learn the cross-correlation across features at different layers. Based on the assumption that a good SR image should be close to the original LR image after down-sampling. We propose a Refined Back Projection Block (RBPB) for final reconstruction. Extensive experiments on some public and AIM2019 Image Super-Resolution Challenge datasets show that the proposed ABPN can provide state-of-the-art or even better performance in both quantitative and qualitative measurements.
* 9 pages, 7 figures, ABPN
Focusing on Persons: Colorizing Old Images Learning from Modern Historical Movies
Aug 14, 2021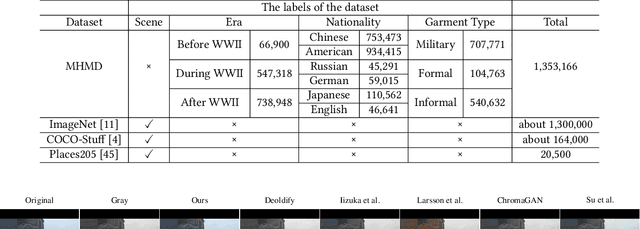
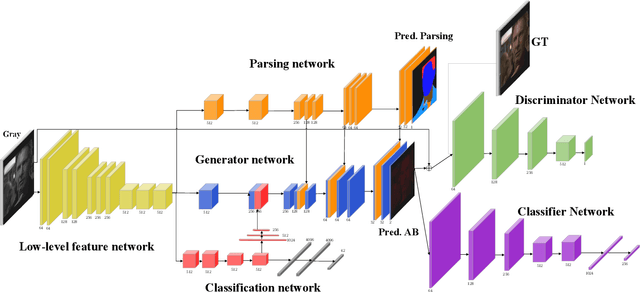
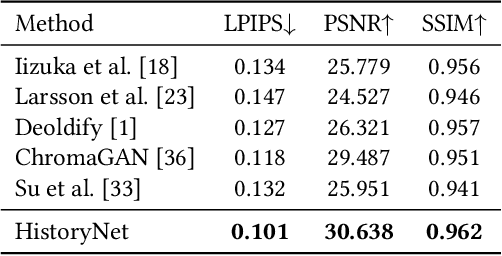
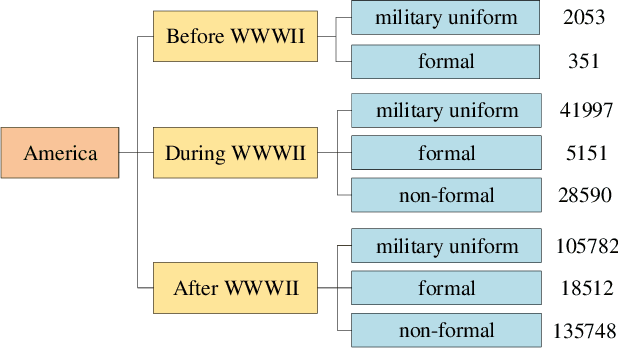
In industry, there exist plenty of scenarios where old gray photos need to be automatically colored, such as video sites and archives. In this paper, we present the HistoryNet focusing on historical person's diverse high fidelity clothing colorization based on fine grained semantic understanding and prior. Colorization of historical persons is realistic and practical, however, existing methods do not perform well in the regards. In this paper, a HistoryNet including three parts, namely, classification, fine grained semantic parsing and colorization, is proposed. Classification sub-module supplies classifying of images according to the eras, nationalities and garment types; Parsing sub-network supplies the semantic for person contours, clothing and background in the image to achieve more accurate colorization of clothes and persons and prevent color overflow. In the training process, we integrate classification and semantic parsing features into the coloring generation network to improve colorization. Through the design of classification and parsing subnetwork, the accuracy of image colorization can be improved and the boundary of each part of image can be more clearly. Moreover, we also propose a novel Modern Historical Movies Dataset (MHMD) containing 1,353,166 images and 42 labels of eras, nationalities, and garment types for automatic colorization from 147 historical movies or TV series made in modern time. Various quantitative and qualitative comparisons demonstrate that our method outperforms the state-of-the-art colorization methods, especially on military uniforms, which has correct colors according to the historical literatures.