 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
MT-ORL: Multi-Task Occlusion Relationship Learning
Aug 12, 2021
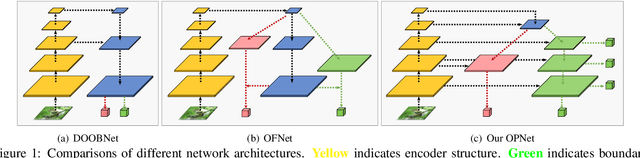
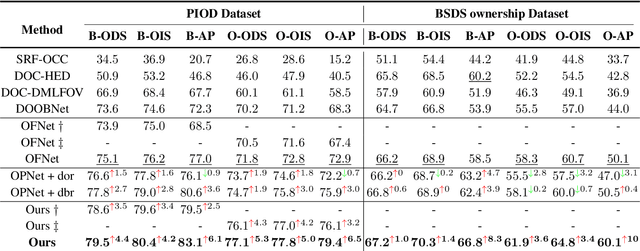
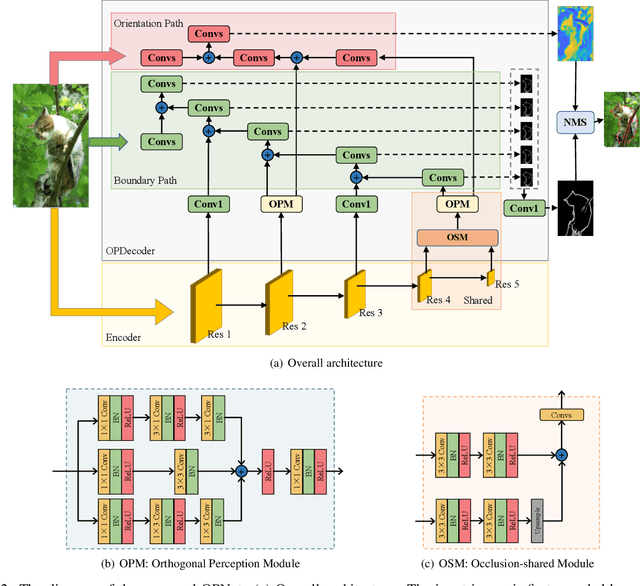
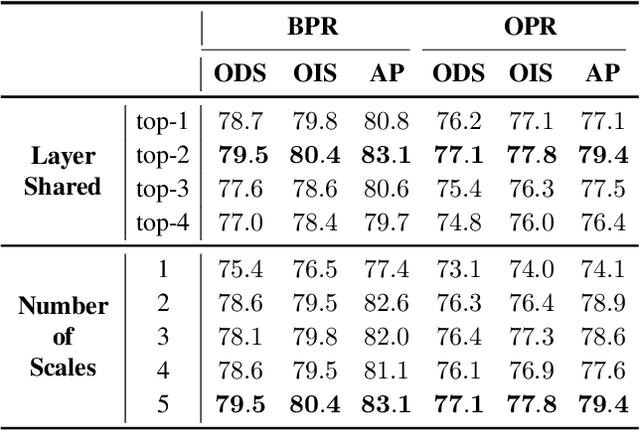
Retrieving occlusion relation among objects in a single image is challenging due to sparsity of boundaries in image. We observe two key issues in existing works: firstly, lack of an architecture which can exploit the limited amount of coupling in the decoder stage between the two subtasks, namely occlusion boundary extraction and occlusion orientation prediction, and secondly, improper representation of occlusion orientation. In this paper, we propose a novel architecture called Occlusion-shared and Path-separated Network (OPNet), which solves the first issue by exploiting rich occlusion cues in shared high-level features and structured spatial information in task-specific low-level features. We then design a simple but effective orthogonal occlusion representation (OOR) to tackle the second issue. Our method surpasses the state-of-the-art methods by 6.1%/8.3% Boundary-AP and 6.5%/10% Orientation-AP on standard PIOD/BSDS ownership datasets. Code is available at https://github.com/fengpanhe/MT-ORL.
LVIS Challenge Track Technical Report 1st Place Solution: Distribution Balanced and Boundary Refinement for Large Vocabulary Instance Segmentation
Nov 04, 2021
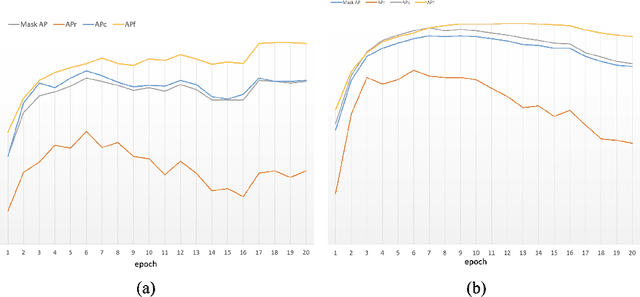
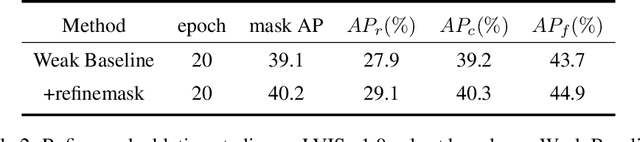

This report introduces the technical details of the team FuXi-Fresher for LVIS Challenge 2021. Our method focuses on the problem in following two aspects: the long-tail distribution and the segmentation quality of mask and boundary. Based on the advanced HTC instance segmentation algorithm, we connect transformer backbone(Swin-L) through composite connections inspired by CBNetv2 to enhance the baseline results. To alleviate the problem of long-tail distribution, we design a Distribution Balanced method which includes dataset balanced and loss function balaced modules. Further, we use a Mask and Boundary Refinement method composed with mask scoring and refine-mask algorithms to improve the segmentation quality. In addition, we are pleasantly surprised to find that early stopping combined with EMA method can achieve a great improvement. Finally, by using multi-scale testing and increasing the upper limit of the number of objects detected per image, we achieved more than 45.4% boundary AP on the val set of LVIS Challenge 2021. On the test data of LVIS Challenge 2021, we rank 1st and achieve 48.1% AP. Notably, our APr 47.5% is very closed to the APf 48.0%.
CN-LBP: Complex Networks-based Local Binary Patterns for Texture Classification
May 14, 2021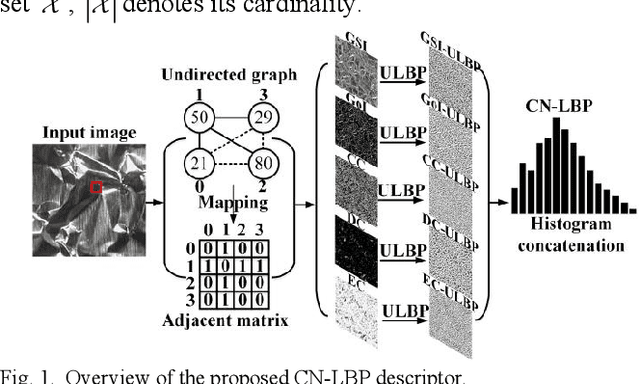
To effectively overcome the limitations of local binary patterns (LBP), this letter proposes a new texture descriptor aided by complex networks (CN) and uniform LBP (ULBP), namely, CN-LBP. Specifically, we first abstract a gray-scale image (GSI) as an undirected graph with the help of pixel distance and intensity, and gradient of image (GoI). Second, three variants of CN-based feature measurements (clustering coefficient, degree centrality, and eigenvector centrality) are proposed to decipher the image spatial-relationship, energy, and entropy, respectively, thus generating three feature maps, which can retain the image information as much as possible. Third, given the generated feature maps, we apply ULBP on feature maps, GSI, and GoI, and obtain the discriminative representation of the texture image. Finally, CN-LBP is obtained by jointly calculating and concatenating the spatial histograms. In contrast to original LBP, the proposed texture descriptor contains more detailed image information and shows certain resistance to noise. Experiment results show that the proposed approach significantly improves the texture classification accuracy compared with state-of-the-art LBP-based variants and deep learning-based approaches.
GANtruth - an unpaired image-to-image translation method for driving scenarios
Nov 26, 2018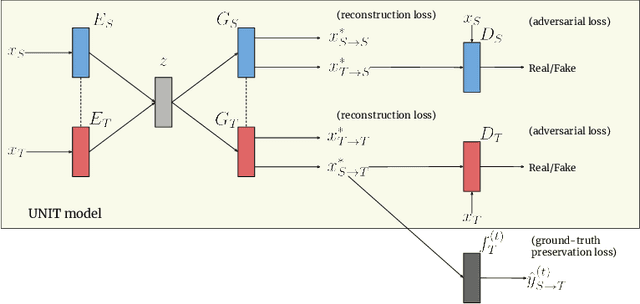
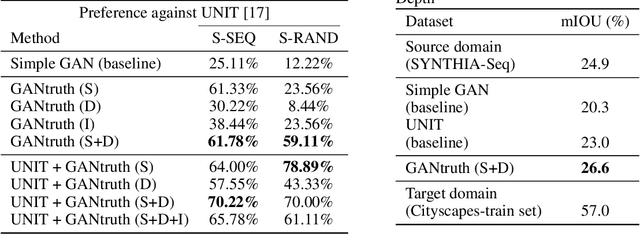


Synthetic image translation has significant potentials in autonomous transportation systems. That is due to the expense of data collection and annotation as well as the unmanageable diversity of real-words situations. The main issue with unpaired image-to-image translation is the ill-posed nature of the problem. In this work, we propose a novel method for constraining the output space of unpaired image-to-image translation. We make the assumption that the environment of the source domain is known (e.g. synthetically generated), and we propose to explicitly enforce preservation of the ground-truth labels on the translated images. We experiment on preserving ground-truth information such as semantic segmentation, disparity, and instance segmentation. We show significant evidence that our method achieves improved performance over the state-of-the-art model of UNIT for translating images from SYNTHIA to Cityscapes. The generated images are perceived as more realistic in human surveys and outperforms UNIT when used in a domain adaptation scenario for semantic segmentation.
Blind Image Deconvolution using Pretrained Generative Priors
Aug 20, 2019
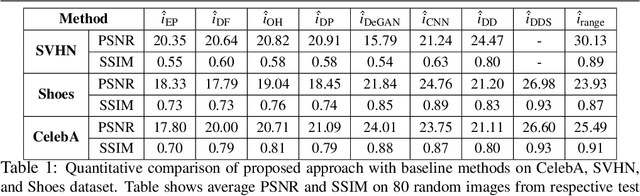
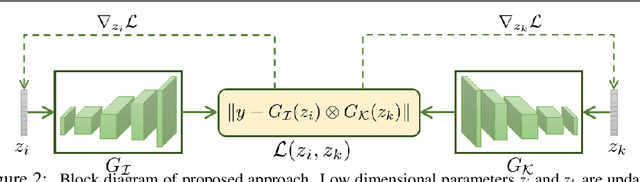

This paper proposes a novel approach to regularize the ill-posed blind image deconvolution (blind image deblurring) problem using deep generative networks. We employ two separate deep generative models - one trained to produce sharp images while the other trained to generate blur kernels from lower dimensional parameters. To deblur, we propose an alternating gradient descent scheme operating in the latent lower-dimensional space of each of the pretrained generative models. Our experiments show excellent deblurring results even under large blurs and heavy noise. To improve the performance on rich image datasets not well learned by the generative networks, we present a modification of the proposed scheme that governs the deblurring process under both generative and classical priors.
T$_k$ML-AP: Adversarial Attacks to Top-$k$ Multi-Label Learning
Jul 31, 2021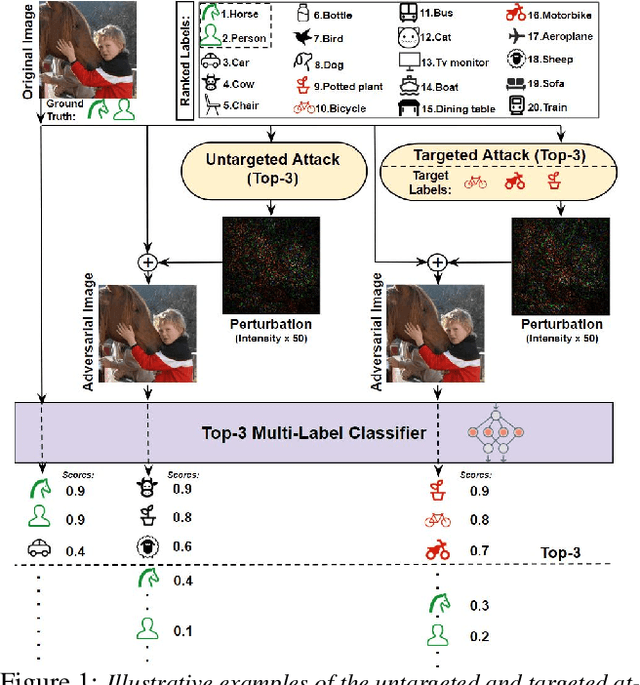
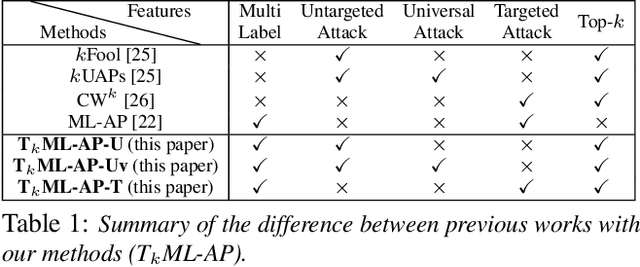
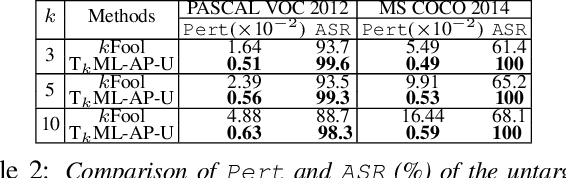
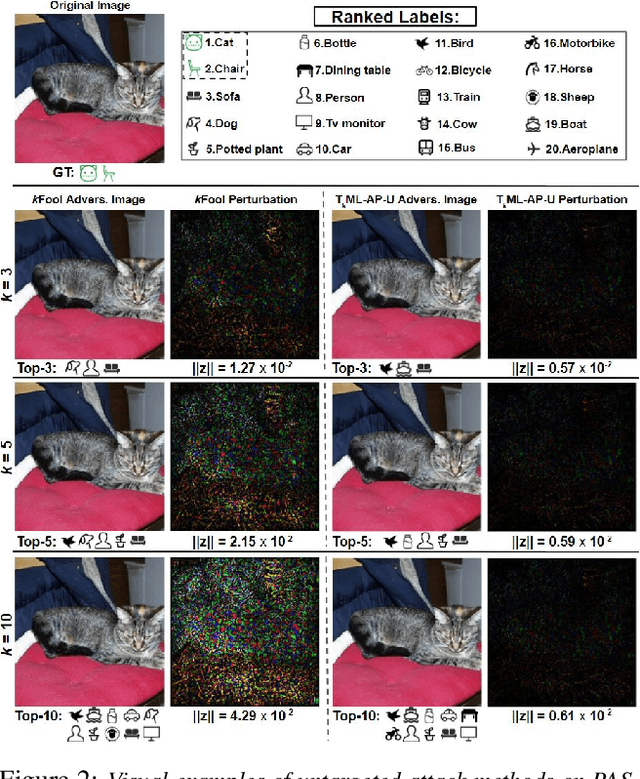
Top-$k$ multi-label learning, which returns the top-$k$ predicted labels from an input, has many practical applications such as image annotation, document analysis, and web search engine. However, the vulnerabilities of such algorithms with regards to dedicated adversarial perturbation attacks have not been extensively studied previously. In this work, we develop methods to create adversarial perturbations that can be used to attack top-$k$ multi-label learning-based image annotation systems (TkML-AP). Our methods explicitly consider the top-$k$ ranking relation and are based on novel loss functions. Experimental evaluations on large-scale benchmark datasets including PASCAL VOC and MS COCO demonstrate the effectiveness of our methods in reducing the performance of state-of-the-art top-$k$ multi-label learning methods, under both untargeted and targeted attacks.
Chest X-ray Image Phase Features for Improved Diagnosis of COVID-19 Using Convolutional Neural Network
Nov 06, 2020
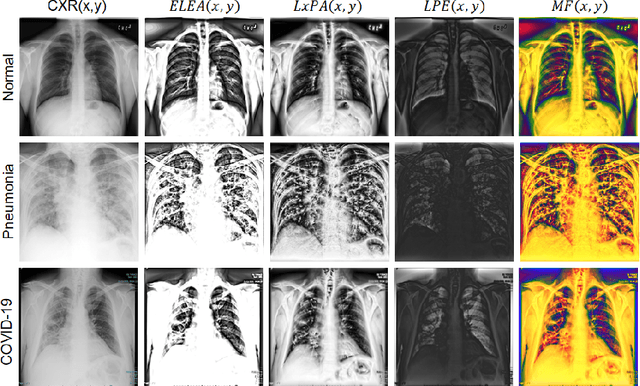

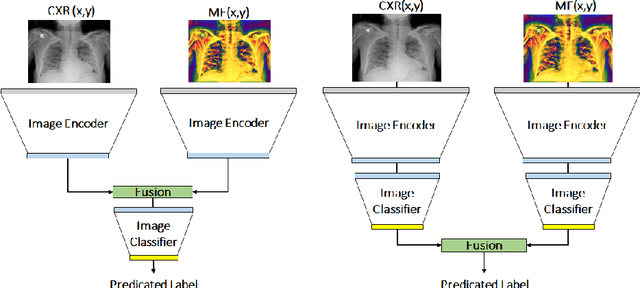
Recently, the outbreak of the novel Coronavirus disease 2019 (COVID-19) pandemic has seriously endangered human health and life. Due to limited availability of test kits, the need for auxiliary diagnostic approach has increased. Recent research has shown radiography of COVID-19 patient, such as CT and X-ray, contains salient information about the COVID-19 virus and could be used as an alternative diagnosis method. Chest X-ray (CXR) due to its faster imaging time, wide availability, low cost and portability gains much attention and becomes very promising. Computational methods with high accuracy and robustness are required for rapid triaging of patients and aiding radiologist in the interpretation of the collected data. In this study, we design a novel multi-feature convolutional neural network (CNN) architecture for multi-class improved classification of COVID-19 from CXR images. CXR images are enhanced using a local phase-based image enhancement method. The enhanced images, together with the original CXR data, are used as an input to our proposed CNN architecture. Using ablation studies, we show the effectiveness of the enhanced images in improving the diagnostic accuracy. We provide quantitative evaluation on two datasets and qualitative results for visual inspection. Quantitative evaluation is performed on data consisting of 8,851 normal (healthy), 6,045 pneumonia, and 3,323 Covid-19 CXR scans. In Dataset-1, our model achieves 95.57\% average accuracy for a three classes classification, 99\% precision, recall, and F1-scores for COVID-19 cases. For Dataset-2, we have obtained 94.44\% average accuracy, and 95\% precision, recall, and F1-scores for detection of COVID-19. Conclusions: Our proposed multi-feature guided CNN achieves improved results compared to single-feature CNN proving the importance of the local phase-based CXR image enhancement.
Compact Heterogeneous Integration for Next Generation High Frequency Scalable Array with Miniaturized and Efficient Power Delivery Network
Nov 15, 2021


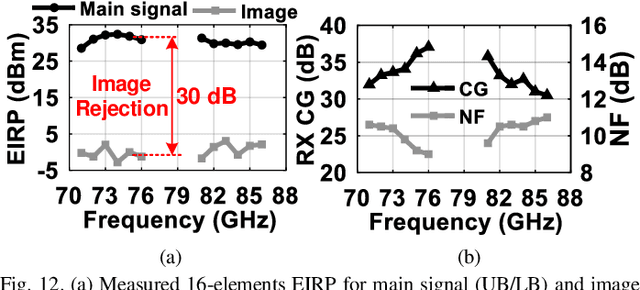
Next generation communication and sensing require enabling technologies for miniaturized and efficient heterogeneous systems while integrating technologies ranging from silicon to compound semiconductors and from photonic chips to micro-sensors. To this end, high frequency and mm-wave (MMW) lossy parasitics and delay between modules need to be significantly reduced to minimize area, loss and thermal heating of inter-chip wiring and power delivery networks. In this work, we propose novel approaches to achieve an efficient wideband MMW array integrations. The proposed techniques are built upon the following: 1) fixed antenna package buildup for every element with differential excitation on two half sides of array to reduce the fabrication cost and the IC-to-antenna routing loss; 2) miniaturized aperture coupled local oscillator (LO) and intermediate frequency (IF) power delivery feed distribution to minimize the packaging stacked layers and their loss. The proposed 16-element antenna array is integrated which 4 dies in 2x2 configurations implemented in a 90-nm SiGe BiCMOS process using compact Weaver image-selection architecture (WISA). The proposed miniaturized and efficient architecture from circuit and chip level to package level results in 1.5 GHz modulation bandwidth for 64 QAM (9 Gb/s) and 2 GHz for 16 QAM with only +-2 dB EVM variation over the 20% FBW (71-86 GHz). The system produces 30-dBm EIRP with enhanced efficiency of 25% EIRP/PDC over the bandwidth
Do Vision Transformers See Like Convolutional Neural Networks?
Aug 19, 2021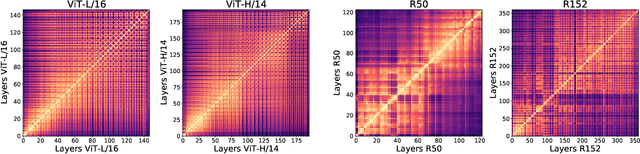
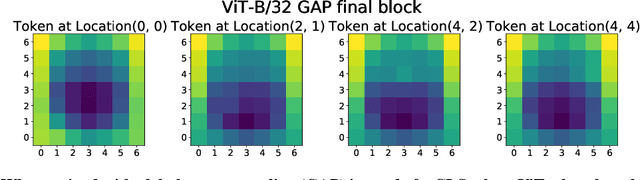
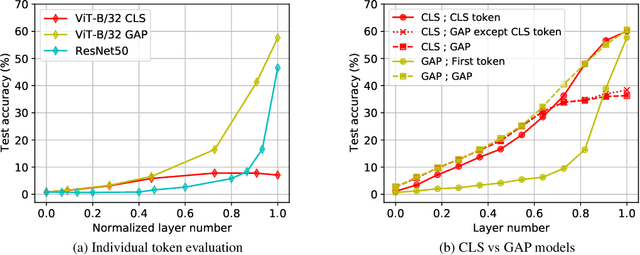
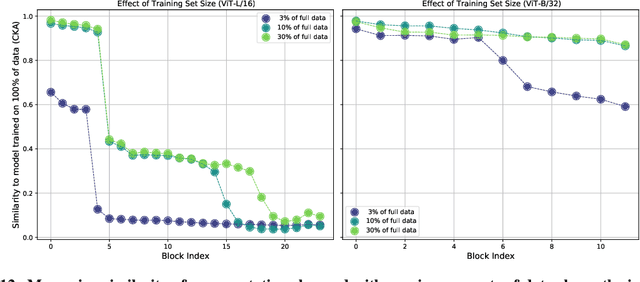
Convolutional neural networks (CNNs) have so far been the de-facto model for visual data. Recent work has shown that (Vision) Transformer models (ViT) can achieve comparable or even superior performance on image classification tasks. This raises a central question: how are Vision Transformers solving these tasks? Are they acting like convolutional networks, or learning entirely different visual representations? Analyzing the internal representation structure of ViTs and CNNs on image classification benchmarks, we find striking differences between the two architectures, such as ViT having more uniform representations across all layers. We explore how these differences arise, finding crucial roles played by self-attention, which enables early aggregation of global information, and ViT residual connections, which strongly propagate features from lower to higher layers. We study the ramifications for spatial localization, demonstrating ViTs successfully preserve input spatial information, with noticeable effects from different classification methods. Finally, we study the effect of (pretraining) dataset scale on intermediate features and transfer learning, and conclude with a discussion on connections to new architectures such as the MLP-Mixer.
THOMAS: Trajectory Heatmap Output with learned Multi-Agent Sampling
Oct 17, 2021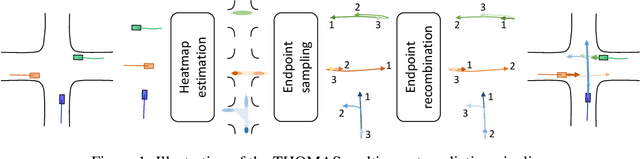

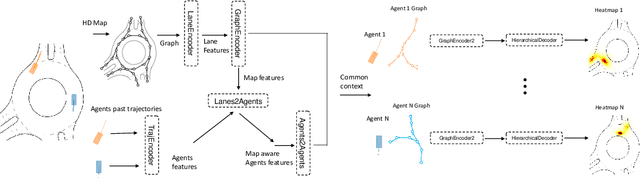

In this paper, we propose THOMAS, a joint multi-agent trajectory prediction framework allowing for efficient and consistent prediction of multi-agent multi-modal trajectories. We present a unified model architecture for fast and simultaneous agent future heatmap estimation leveraging hierarchical and sparse image generation. We demonstrate that heatmap output enables a higher level of control on the predicted trajectories compared to vanilla multi-modal trajectory regression, allowing to incorporate additional constraints for tighter sampling or collision-free predictions in a deterministic way. However, we also highlight that generating scene-consistent predictions goes beyond the mere generation of collision-free trajectories. We therefore propose a learnable trajectory recombination model that takes as input a set of predicted trajectories for each agent and outputs its consistent reordered recombination. We report our results on the Interaction multi-agent prediction challenge and rank $1^{st}$ on the online test leaderboard.