 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Image Aesthetics Assessment using Multi Channel Convolutional Neural Networks
Nov 21, 2019



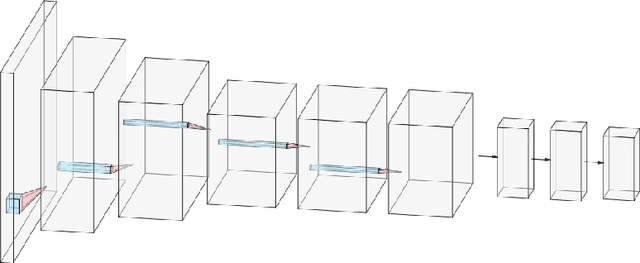
Image Aesthetics Assessment is one of the emerging domains in research. The domain deals with classification of images into categories depending on the basis of how pleasant they are for the users to watch. In this article, the focus is on categorizing the images in high quality and low quality image. Deep convolutional neural networks are used to classify the images. Instead of using just the raw image as input, different crops and saliency maps of the images are also used, as input to the proposed multi channel CNN architecture. The experiments reported on widely used AVA database show improvement in the aesthetic assessment performance over existing approaches.
Deep learning-based attenuation correction in the image domain for myocardial perfusion SPECT imaging
Feb 10, 2021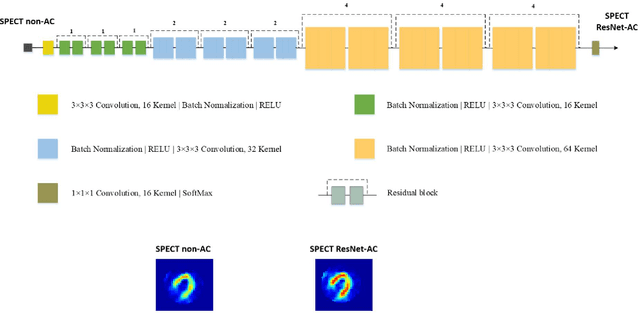
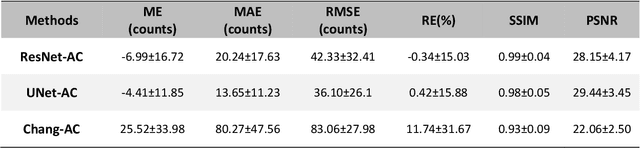
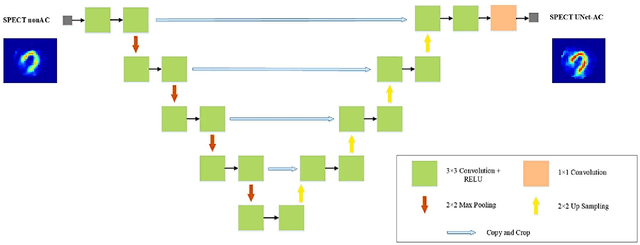
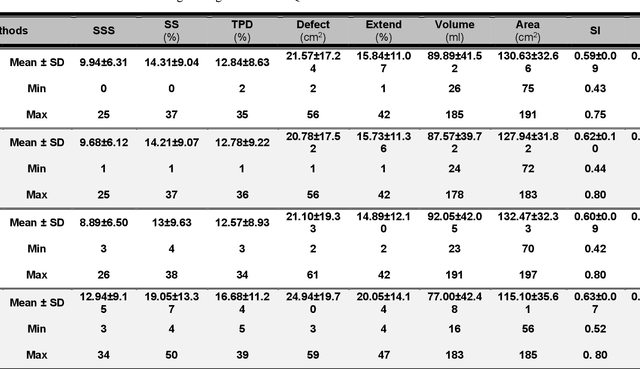
Objective: In this work, we set out to investigate the accuracy of direct attenuation correction (AC) in the image domain for the myocardial perfusion SPECT imaging (MPI-SPECT) using two residual (ResNet) and UNet deep convolutional neural networks. Methods: The MPI-SPECT 99mTc-sestamibi images of 99 participants were retrospectively examined. UNet and ResNet networks were trained using SPECT non-attenuation corrected images as input and CT-based attenuation corrected SPECT images (CT-AC) as reference. The Chang AC approach, considering a uniform attenuation coefficient within the body contour, was also implemented. Quantitative and clinical evaluation of the proposed methods were performed considering SPECT CT-AC images of 19 subjects as reference using the mean absolute error (MAE), structural similarity index (SSIM) metrics, as well as relevant clinical indices such as perfusion deficit (TPD). Results: Overall, the deep learning solution exhibited good agreement with the CT-based AC, noticeably outperforming the Chang method. The ResNet and UNet models resulted in the ME (count) of ${-6.99\pm16.72}$ and ${-4.41\pm11.8}$ and SSIM of ${0.99\pm0.04}$ and ${0.98\pm0.05}$, respectively. While the Change approach led to ME and SSIM of ${25.52\pm33.98}$ and ${0.93\pm0.09}$, respectively. Similarly, the clinical evaluation revealed a mean TPD of ${12.78\pm9.22}$ and ${12.57\pm8.93}$ for the ResNet and UNet models, respectively, compared to ${12.84\pm8.63}$ obtained from the reference SPECT CT-AC images. On the other hand, the Chang approach led to a mean TPD of ${16.68\pm11.24}$. Conclusion: We evaluated two deep convolutional neural networks to estimate SPECT-AC images directly from the non-attenuation corrected images. The deep learning solutions exhibited the promising potential to generate reliable attenuation corrected SPECT images without the use of transmission scanning.
Robustness in Deep Learning for Computer Vision: Mind the gap?
Dec 01, 2021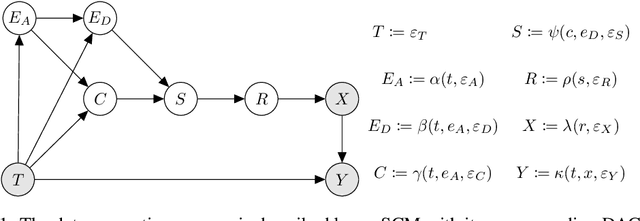
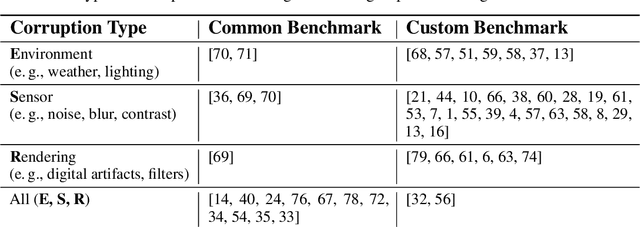

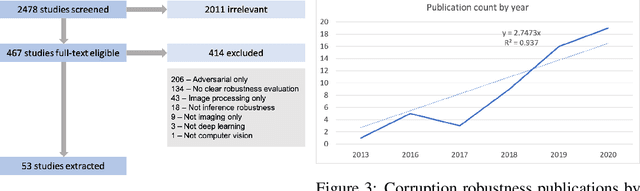
Deep neural networks for computer vision tasks are deployed in increasingly safety-critical and socially-impactful applications, motivating the need to close the gap in model performance under varied, naturally occurring imaging conditions. Robustness, ambiguously used in multiple contexts including adversarial machine learning, here then refers to preserving model performance under naturally-induced image corruptions or alterations. We perform a systematic review to identify, analyze, and summarize current definitions and progress towards non-adversarial robustness in deep learning for computer vision. We find that this area of research has received disproportionately little attention relative to adversarial machine learning, yet a significant robustness gap exists that often manifests in performance degradation similar in magnitude to adversarial conditions. To provide a more transparent definition of robustness across contexts, we introduce a structural causal model of the data generating process and interpret non-adversarial robustness as pertaining to a model's behavior on corrupted images which correspond to low-probability samples from the unaltered data distribution. We then identify key architecture-, data augmentation-, and optimization tactics for improving neural network robustness. This causal view of robustness reveals that common practices in the current literature, both in regards to robustness tactics and evaluations, correspond to causal concepts, such as soft interventions resulting in a counterfactually-altered distribution of imaging conditions. Through our findings and analysis, we offer perspectives on how future research may mind this evident and significant non-adversarial robustness gap.
Range Image-based LiDAR Localization for Autonomous Vehicles
May 25, 2021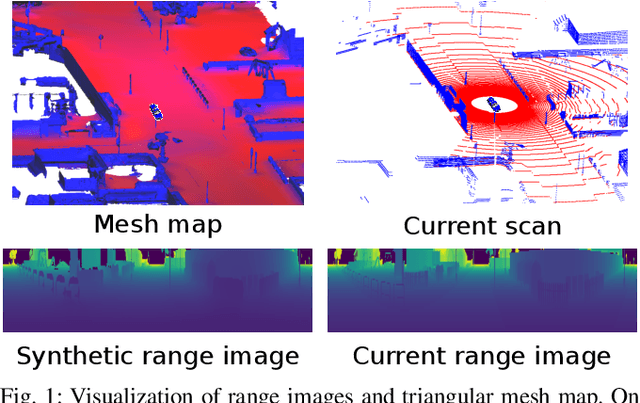
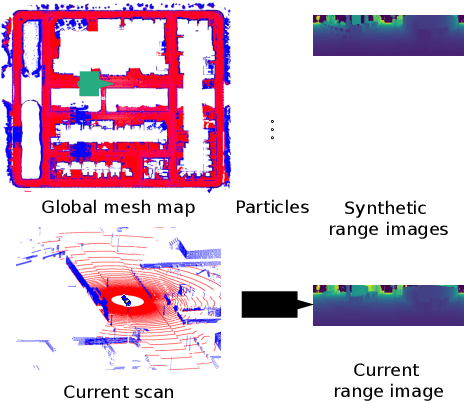
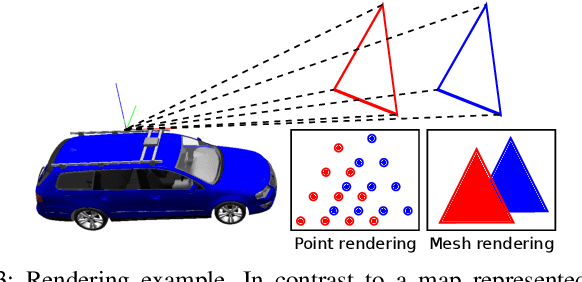
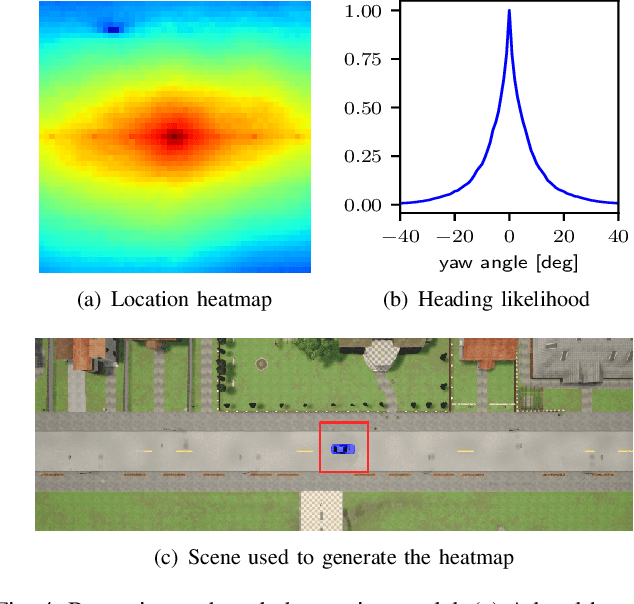
Robust and accurate, map-based localization is crucial for autonomous mobile systems. In this paper, we exploit range images generated from 3D LiDAR scans to address the problem of localizing mobile robots or autonomous cars in a map of a large-scale outdoor environment represented by a triangular mesh. We use the Poisson surface reconstruction to generate the mesh-based map representation. Based on the range images generated from the current LiDAR scan and the synthetic rendered views from the mesh-based map, we propose a new observation model and integrate it into a Monte Carlo localization framework, which achieves better localization performance and generalizes well to different environments. We test the proposed localization approach on multiple datasets collected in different environments with different LiDAR scanners. The experimental results show that our method can reliably and accurately localize a mobile system in different environments and operate online at the LiDAR sensor frame rate to track the vehicle pose.
PoseGAN: A Pose-to-Image Translation Framework for Camera Localization
Jun 23, 2020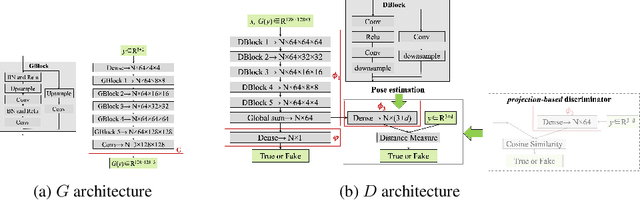
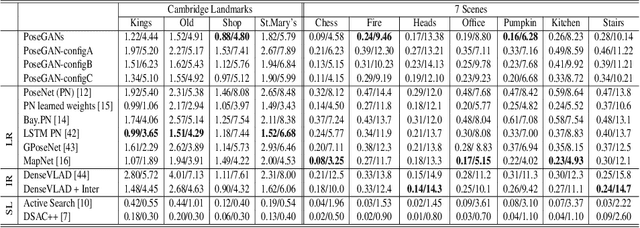


Camera localization is a fundamental requirement in robotics and computer vision. This paper introduces a pose-to-image translation framework to tackle the camera localization problem. We present PoseGANs, a conditional generative adversarial networks (cGANs) based framework for the implementation of pose-to-image translation. PoseGANs feature a number of innovations including a distance metric based conditional discriminator to conduct camera localization and a pose estimation technique for generated camera images as a stronger constraint to improve camera localization performance. Compared with learning-based regression methods such as PoseNet, PoseGANs can achieve better performance with model sizes that are 70% smaller. In addition, PoseGANs introduce the view synthesis technique to establish the correspondence between the 2D images and the scene, \textit{i.e.}, given a pose, PoseGANs are able to synthesize its corresponding camera images. Furthermore, we demonstrate that PoseGANs differ in principle from structure-based localization and learning-based regressions for camera localization, and show that PoseGANs exploit the geometric structures to accomplish the camera localization task, and is therefore more stable than and superior to learning-based regressions which rely on local texture features instead. In addition to camera localization and view synthesis, we also demonstrate that PoseGANs can be successfully used for other interesting applications such as moving object elimination and frame interpolation in video sequences.
Exploring Explicit Domain Supervision for Latent Space Disentanglement in Unpaired Image-to-Image Translation
Mar 26, 2019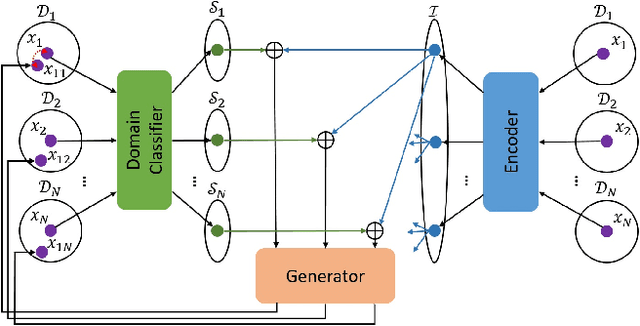
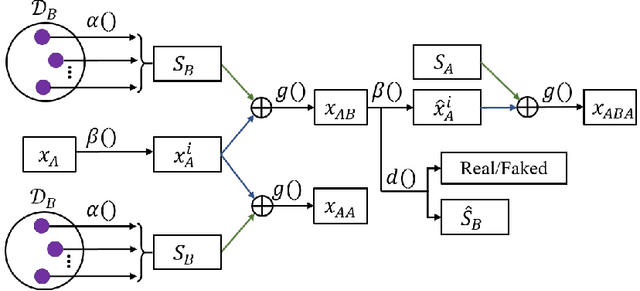

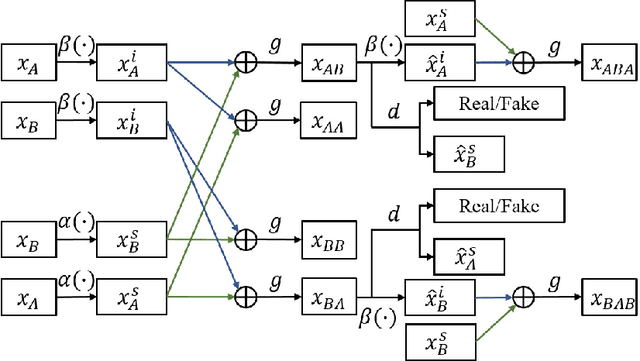
Image-to-image translation tasks have been widely investigated with Generative Adversarial Networks (GANs). However, existing approaches are mostly designed in an unsupervised manner while little attention has been paid to domain information within unpaired data. In this paper, we treat domain information as explicit supervision and design an unpaired image-to-image translation framework, Domain-supervised GAN (DosGAN), which takes the first step towards the exploration of explicit domain supervision. In contrast to representing domain characteristics using different generators in CycleGAN or multiple domain codes in StarGAN, we pre-train a classification network to explicitly classify the domain of an image. After pre-training, this network is used to extract the domain-specific features of each image by using the output of its second-to-last layer. Such features, together with the domain-independent features extracted by another encoder (shared across different domains), are used to generate an image in the target domain. Extensive experiments on multiple hair color translation, multiple identity translation, multiple season translation and conditional edges-to-shoes/handbags demonstrate the effectiveness of our method. In addition, we can transfer the domain-specific feature extractor obtained on the Facescrub dataset with domain supervision information to unseen domains, such as faces in the CelebA dataset. We also succeed in achieving conditional translation with any two images in CelebA, while previous models like StarGAN cannot handle this task.
Unified Style Transfer
Oct 20, 2021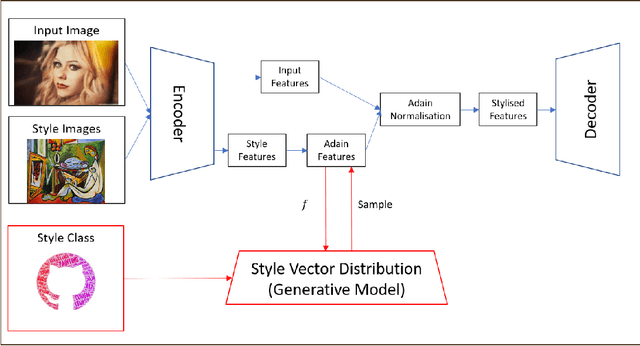
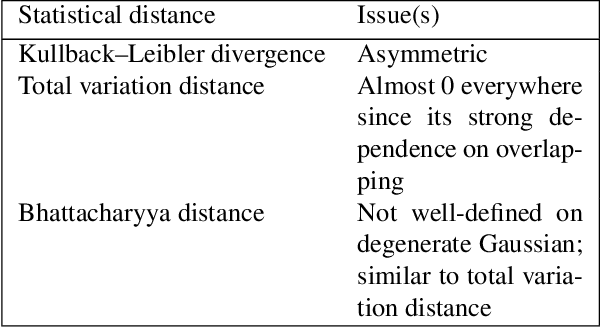
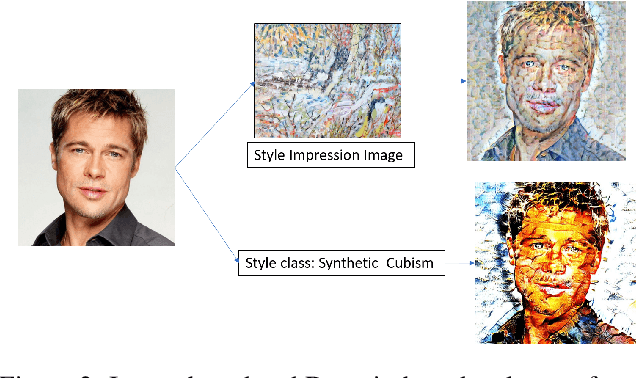

Currently, it is hard to compare and evaluate different style transfer algorithms due to chaotic definitions of style and the absence of agreed objective validation methods in the study of style transfer. In this paper, a novel approach, the Unified Style Transfer (UST) model, is proposed. With the introduction of a generative model for internal style representation, UST can transfer images in two approaches, i.e., Domain-based and Image-based, simultaneously. At the same time, a new philosophy based on the human sense of art and style distributions for evaluating the transfer model is presented and demonstrated, called Statistical Style Analysis. It provides a new path to validate style transfer models' feasibility by validating the general consistency between internal style representation and art facts. Besides, the translation-invariance of AdaIN features is also discussed.
Pseudo-Spherical Contrastive Divergence
Nov 01, 2021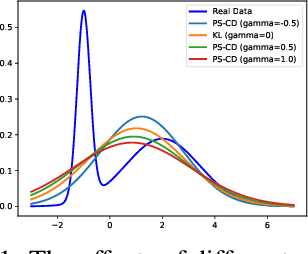
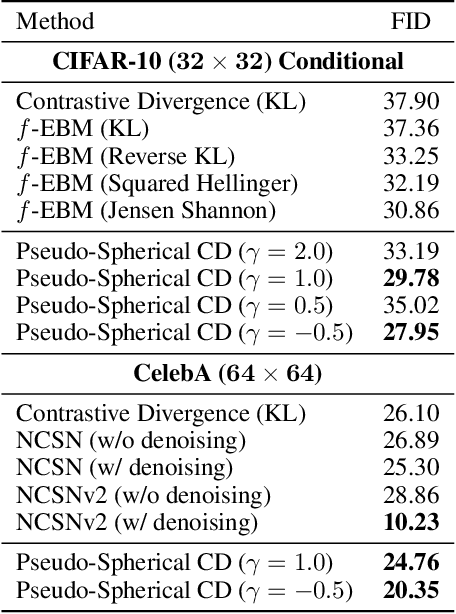

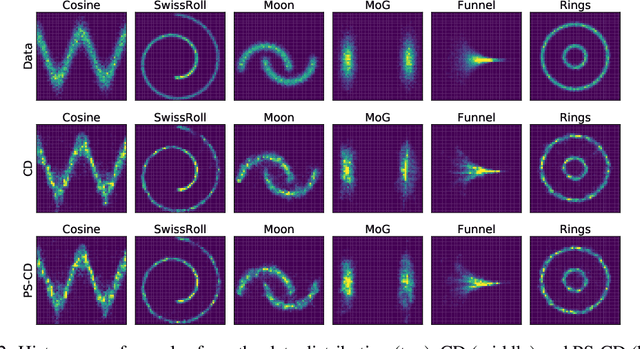
Energy-based models (EBMs) offer flexible distribution parametrization. However, due to the intractable partition function, they are typically trained via contrastive divergence for maximum likelihood estimation. In this paper, we propose pseudo-spherical contrastive divergence (PS-CD) to generalize maximum likelihood learning of EBMs. PS-CD is derived from the maximization of a family of strictly proper homogeneous scoring rules, which avoids the computation of the intractable partition function and provides a generalized family of learning objectives that include contrastive divergence as a special case. Moreover, PS-CD allows us to flexibly choose various learning objectives to train EBMs without additional computational cost or variational minimax optimization. Theoretical analysis on the proposed method and extensive experiments on both synthetic data and commonly used image datasets demonstrate the effectiveness and modeling flexibility of PS-CD, as well as its robustness to data contamination, thus showing its superiority over maximum likelihood and $f$-EBMs.
Single-Item Fashion Recommender: Towards Cross-Domain Recommendations
Nov 01, 2021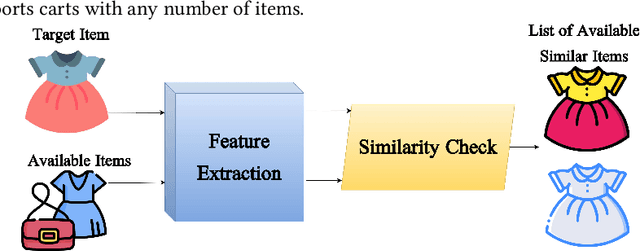
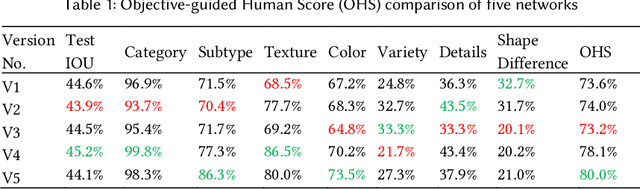
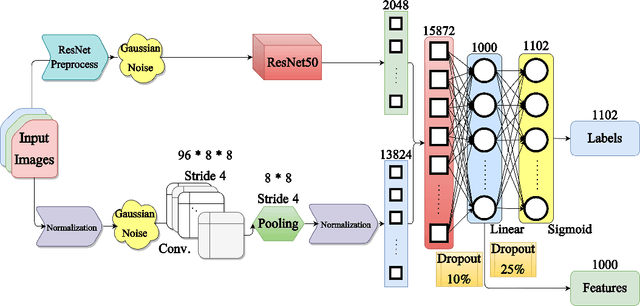
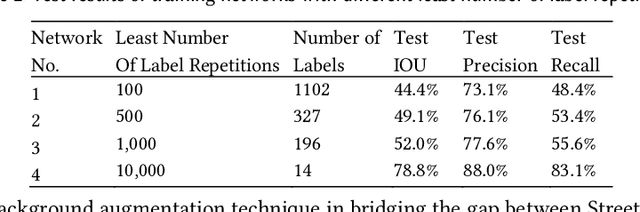
Nowadays, recommender systems and search engines play an integral role in fashion e-commerce. Still, many challenges lie ahead, and this study tries to tackle some. This article first suggests a content-based fashion recommender system that uses a parallel neural network to take a single fashion item shop image as input and make in-shop recommendations by listing similar items available in the store. Next, the same structure is enhanced to personalize the results based on user preferences. This work then introduces a background augmentation technique that makes the system more robust to out-of-domain queries, enabling it to make street-to-shop recommendations using only a training set of catalog shop images. Moreover, the last contribution of this paper is a new evaluation metric for recommendation tasks called objective-guided human score. This method is an entirely customizable framework that produces interpretable, comparable scores from subjective evaluations of human scorers.
Few-shot learning with improved local representations via bias rectify module
Nov 01, 2021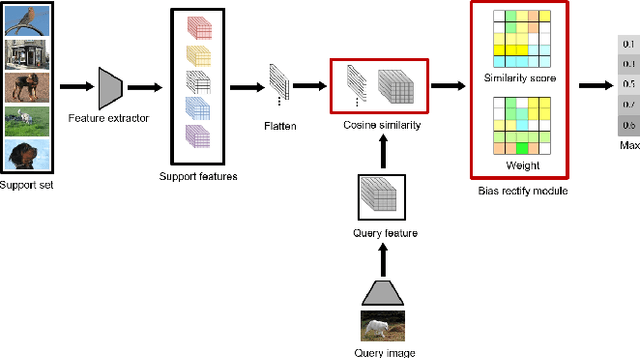
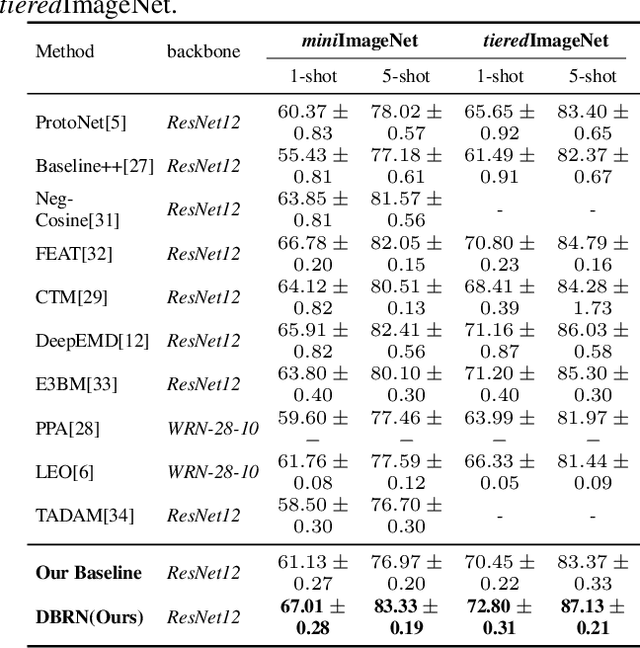

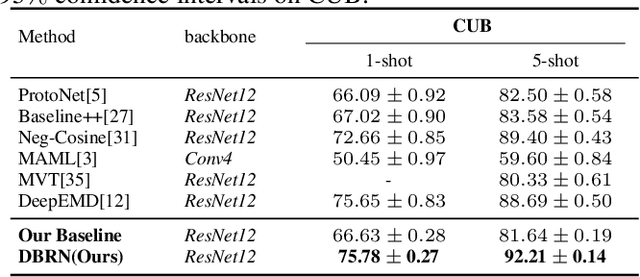
Recent approaches based on metric learning have achieved great progress in few-shot learning. However, most of them are limited to image-level representation manners, which fail to properly deal with the intra-class variations and spatial knowledge and thus produce undesirable performance. In this paper we propose a Deep Bias Rectify Network (DBRN) to fully exploit the spatial information that exists in the structure of the feature representations. We first employ a bias rectify module to alleviate the adverse impact caused by the intra-class variations. bias rectify module is able to focus on the features that are more discriminative for classification by given different weights. To make full use of the training data, we design a prototype augment mechanism that can make the prototypes generated from the support set to be more representative. To validate the effectiveness of our method, we conducted extensive experiments on various popular few-shot classification benchmarks and our methods can outperform state-of-the-art methods.