 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A non-hierarchical attention network with modality dropout for textual response generation in multimodal dialogue systems
Oct 19, 2021

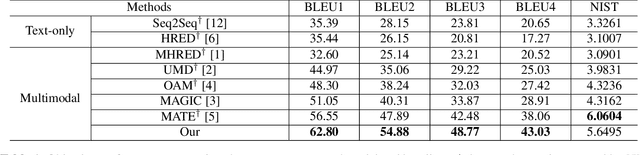
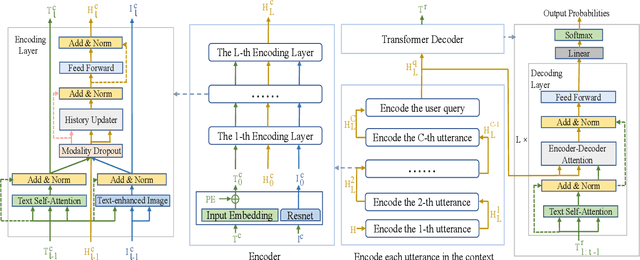

Existing text- and image-based multimodal dialogue systems use the traditional Hierarchical Recurrent Encoder-Decoder (HRED) framework, which has an utterance-level encoder to model utterance representation and a context-level encoder to model context representation. Although pioneer efforts have shown promising performances, they still suffer from the following challenges: (1) the interaction between textual features and visual features is not fine-grained enough. (2) the context representation can not provide a complete representation for the context. To address the issues mentioned above, we propose a non-hierarchical attention network with modality dropout, which abandons the HRED framework and utilizes attention modules to encode each utterance and model the context representation. To evaluate our proposed model, we conduct comprehensive experiments on a public multimodal dialogue dataset. Automatic and human evaluation demonstrate that our proposed model outperforms the existing methods and achieves state-of-the-art performance.
IFR: Iterative Fusion Based Recognizer For Low Quality Scene Text Recognition
Aug 13, 2021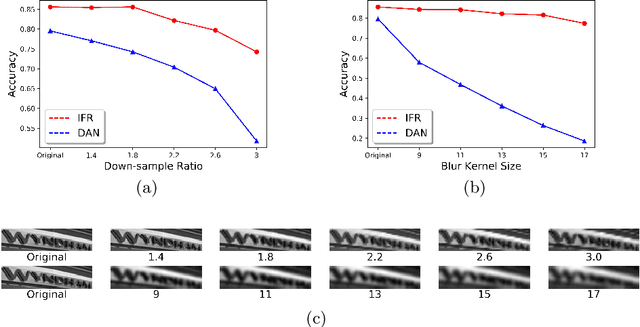
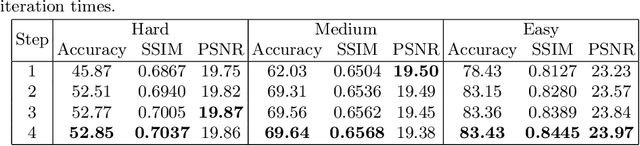


Although recent works based on deep learning have made progress in improving recognition accuracy on scene text recognition, how to handle low-quality text images in end-to-end deep networks remains a research challenge. In this paper, we propose an Iterative Fusion based Recognizer (IFR) for low quality scene text recognition, taking advantage of refined text images input and robust feature representation. IFR contains two branches which focus on scene text recognition and low quality scene text image recovery respectively. We utilize an iterative collaboration between two branches, which can effectively alleviate the impact of low quality input. A feature fusion module is proposed to strengthen the feature representation of the two branches, where the features from the Recognizer are Fused with image Restoration branch, referred to as RRF. Without changing the recognition network structure, extensive quantitative and qualitative experimental results show that the proposed method significantly outperforms the baseline methods in boosting the recognition accuracy of benchmark datasets and low resolution images in TextZoom dataset.
Image Classification with Hierarchical Multigraph Networks
Jul 21, 2019
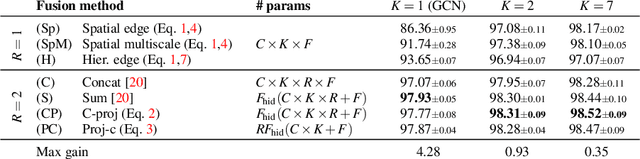
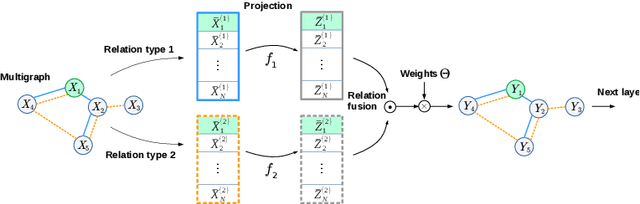
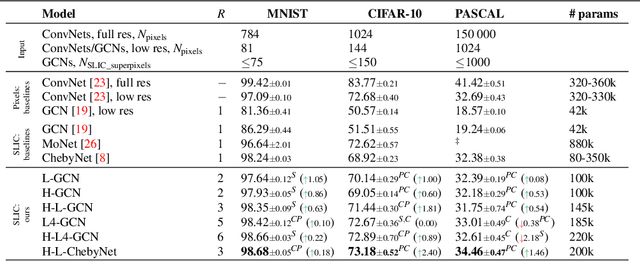
Graph Convolutional Networks (GCNs) are a class of general models that can learn from graph structured data. Despite being general, GCNs are admittedly inferior to convolutional neural networks (CNNs) when applied to vision tasks, mainly due to the lack of domain knowledge that is hardcoded into CNNs, such as spatially oriented translation invariant filters. However, a great advantage of GCNs is the ability to work on irregular inputs, such as superpixels of images. This could significantly reduce the computational cost of image reasoning tasks. Another key advantage inherent to GCNs is the natural ability to model multirelational data. Building upon these two promising properties, in this work, we show best practices for designing GCNs for image classification; in some cases even outperforming CNNs on the MNIST, CIFAR-10 and PASCAL image datasets.
Multiplication-Avoiding Variant of Power Iteration with Applications
Oct 22, 2021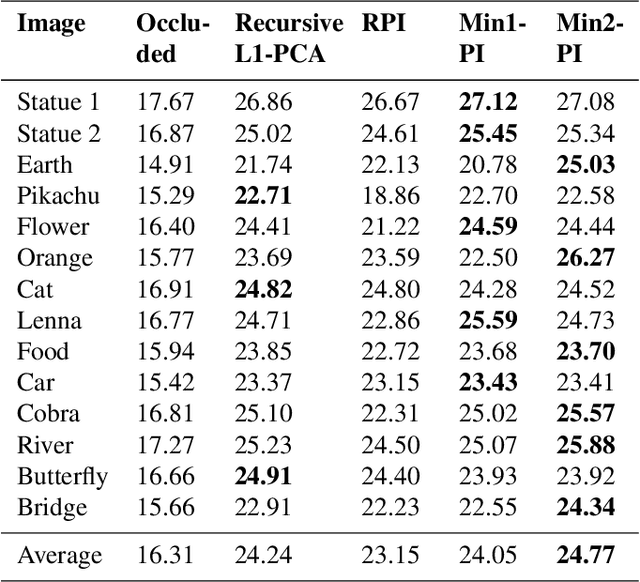

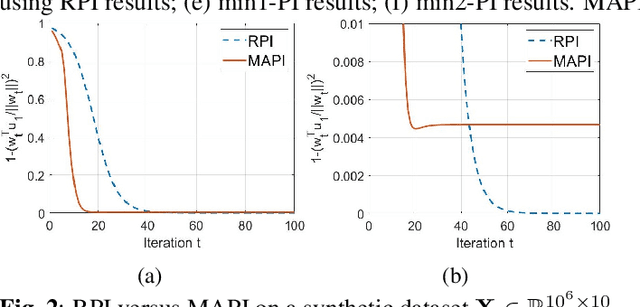
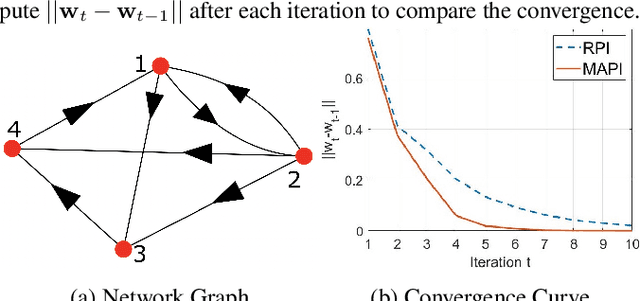
Power iteration is a fundamental algorithm in data analysis. It extracts the eigenvector corresponding to the largest eigenvalue of a given matrix. Applications include ranking algorithms, recommendation systems, principal component analysis (PCA), among many others. In this paper, We introduce multiplication-avoiding power iteration (MAPI), which replaces the standard $\ell_2$-inner products that appear at the regular power iteration (RPI) with multiplication-free vector products which are Mercer-type kernel operations related with the $\ell_1$ norm. Precisely, for an $n\times n$ matrix, MAPI requires $n$ multiplications, while RPI needs $n^2$ multiplications per iteration. Therefore, MAPI provides a significant reduction of the number of multiplication operations, which are known to be costly in terms of energy consumption. We provide applications of MAPI to PCA-based image reconstruction as well as to graph-based ranking algorithms. When compared to RPI, MAPI not only typically converges much faster, but also provides superior performance.
Selective Light Field Refocusing for Camera Arrays Using Bokeh Rendering and Superresolution
Aug 09, 2021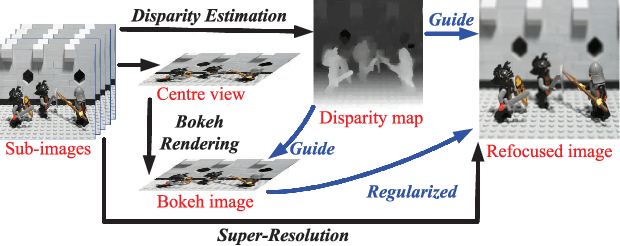


Camera arrays provide spatial and angular information within a single snapshot. With refocusing methods, focal planes can be altered after exposure. In this letter, we propose a light field refocusing method to improve the imaging quality of camera arrays. In our method, the disparity is first estimated. Then, the unfocused region (bokeh) is rendered by using a depth-based anisotropic filter. Finally, the refocused image is produced by a reconstruction-based superresolution approach where the bokeh image is used as a regularization term. Our method can selectively refocus images with focused region being superresolved and bokeh being aesthetically rendered. Our method also enables postadjustment of depth of field. We conduct experiments on both public and self-developed datasets. Our method achieves superior visual performance with acceptable computational cost as compared to other state-of-the-art methods. Code is available at https://github.com/YingqianWang/Selective-LF-Refocusing.
A Simple Baseline for Low-Budget Active Learning
Oct 22, 2021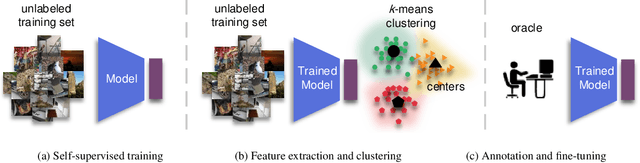
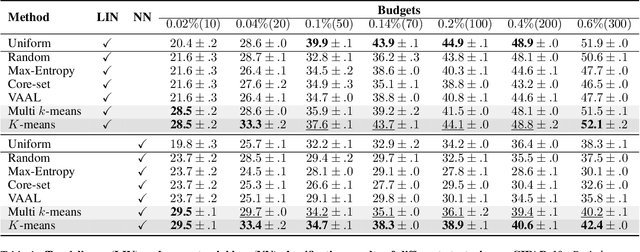

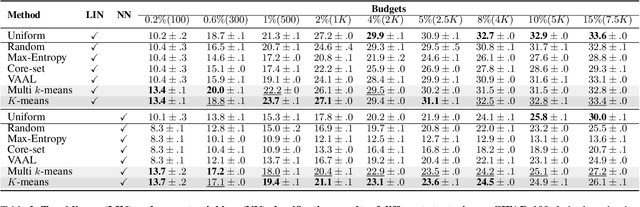
Active learning focuses on choosing a subset of unlabeled data to be labeled. However, most such methods assume that a large subset of the data can be annotated. We are interested in low-budget active learning where only a small subset (e.g., 0.2% of ImageNet) can be annotated. Instead of proposing a new query strategy to iteratively sample batches of unlabeled data given an initial pool, we learn rich features by an off-the-shelf self-supervised learning method only once and then study the effectiveness of different sampling strategies given a low budget on a variety of datasets as well as ImageNet dataset. We show that although the state-of-the-art active learning methods work well given a large budget of data labeling, a simple k-means clustering algorithm can outperform them on low budgets. We believe this method can be used as a simple baseline for low-budget active learning on image classification. Code is available at: https://github.com/UCDvision/low-budget-al
Sibling Neural Estimators: Improving Iterative Image Decoding with Gradient Communication
Nov 20, 2019
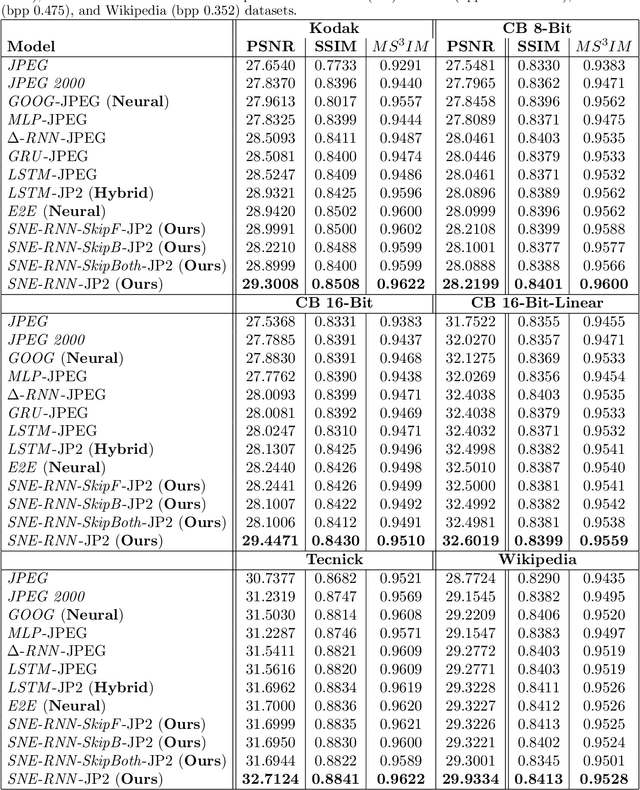
For lossy image compression, we develop a neural-based system which learns a nonlinear estimator for decoding from quantized representations. The system links two recurrent networks that \help" each other reconstruct same target image patches using complementary portions of spatial context that communicate via gradient signals. This dual agent system builds upon prior work that proposed the iterative refinement algorithm for recurrent neural network (RNN)based decoding which improved image reconstruction compared to standard decoding techniques. Our approach, which works with any encoder, neural or non-neural, This system progressively reduces image patch reconstruction error over a fixed number of steps. Experiment with variants of RNN memory cells, with and without future information, find that our model consistently creates lower distortion images of higher perceptual quality compared to other approaches. Specifically, on the Kodak Lossless True Color Image Suite, we observe as much as a 1:64 decibel (dB) gain over JPEG, a 1:46 dB gain over JPEG 2000, a 1:34 dB gain over the GOOG neural baseline, 0:36 over E2E (a modern competitive neural compression model), and 0:37 over a single iterative neural decoder.
Deep Graphics Encoder for Real-Time Video Makeup Synthesis from Example
May 12, 2021

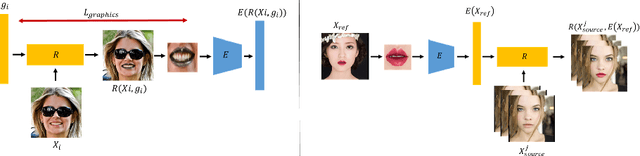
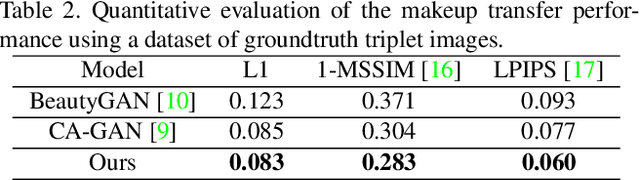
While makeup virtual-try-on is now widespread, parametrizing a computer graphics rendering engine for synthesizing images of a given cosmetics product remains a challenging task. In this paper, we introduce an inverse computer graphics method for automatic makeup synthesis from a reference image, by learning a model that maps an example portrait image with makeup to the space of rendering parameters. This method can be used by artists to automatically create realistic virtual cosmetics image samples, or by consumers, to virtually try-on a makeup extracted from their favorite reference image.
VC-Net: Deep Volume-Composition Networks for Segmentation and Visualization of Highly Sparse and Noisy Image Data
Sep 14, 2020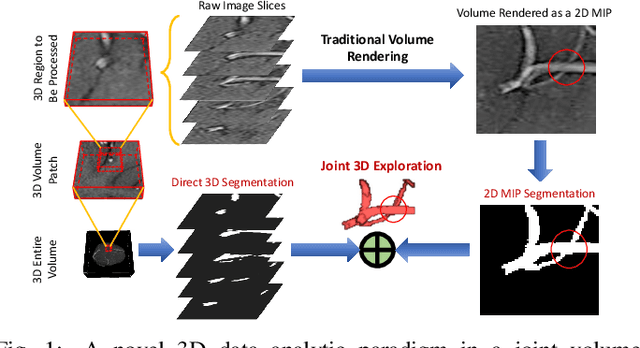
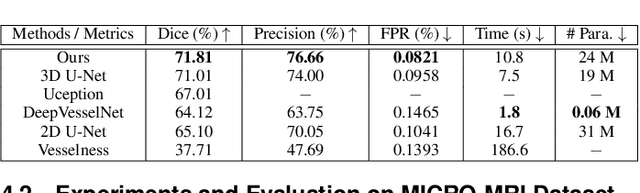


The motivation of our work is to present a new visualization-guided computing paradigm to combine direct 3D volume processing and volume rendered clues for effective 3D exploration such as extracting and visualizing microstructures in-vivo. However, it is still challenging to extract and visualize high fidelity 3D vessel structure due to its high sparseness, noisiness, and complex topology variations. In this paper, we present an end-to-end deep learning method, VC-Net, for robust extraction of 3D microvasculature through embedding the image composition, generated by maximum intensity projection (MIP), into 3D volume image learning to enhance the performance. The core novelty is to automatically leverage the volume visualization technique (MIP) to enhance the 3D data exploration at deep learning level. The MIP embedding features can enhance the local vessel signal and are adaptive to the geometric variability and scalability of vessels, which is crucial in microvascular tracking. A multi-stream convolutional neural network is proposed to learn the 3D volume and 2D MIP features respectively and then explore their inter-dependencies in a joint volume-composition embedding space by unprojecting the MIP features into 3D volume embedding space. The proposed framework can better capture small / micro vessels and improve vessel connectivity. To our knowledge, this is the first deep learning framework to construct a joint convolutional embedding space, where the computed vessel probabilities from volume rendering based 2D projection and 3D volume can be explored and integrated synergistically. Experimental results are compared with the traditional 3D vessel segmentation methods and the deep learning state-of-the-art on public and real patient (micro-)cerebrovascular image datasets. Our method demonstrates the potential in a powerful MR arteriogram and venogram diagnosis of vascular diseases.
Recurrence along Depth: Deep Convolutional Neural Networks with Recurrent Layer Aggregation
Oct 22, 2021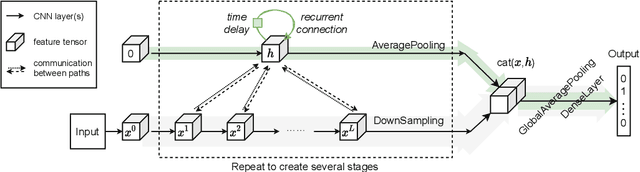
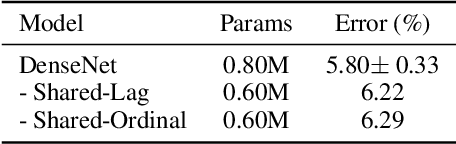
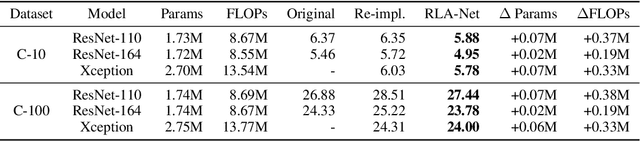
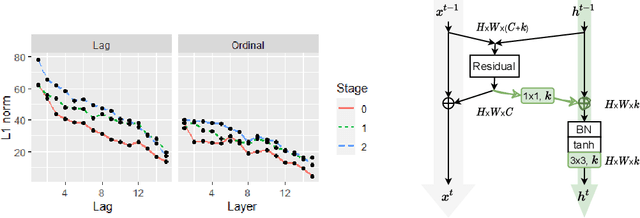
This paper introduces a concept of layer aggregation to describe how information from previous layers can be reused to better extract features at the current layer. While DenseNet is a typical example of the layer aggregation mechanism, its redundancy has been commonly criticized in the literature. This motivates us to propose a very light-weighted module, called recurrent layer aggregation (RLA), by making use of the sequential structure of layers in a deep CNN. Our RLA module is compatible with many mainstream deep CNNs, including ResNets, Xception and MobileNetV2, and its effectiveness is verified by our extensive experiments on image classification, object detection and instance segmentation tasks. Specifically, improvements can be uniformly observed on CIFAR, ImageNet and MS COCO datasets, and the corresponding RLA-Nets can surprisingly boost the performances by 2-3% on the object detection task. This evidences the power of our RLA module in helping main CNNs better learn structural information in images.