 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
To be Critical: Self-Calibrated Weakly Supervised Learning for Salient Object Detection
Sep 04, 2021
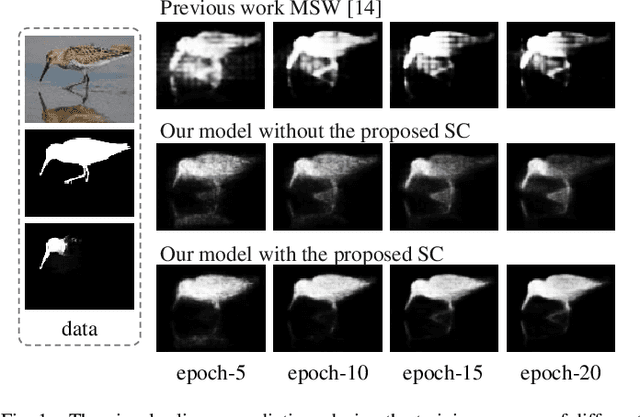
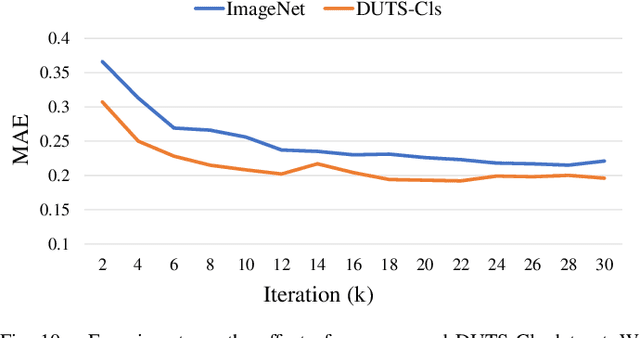
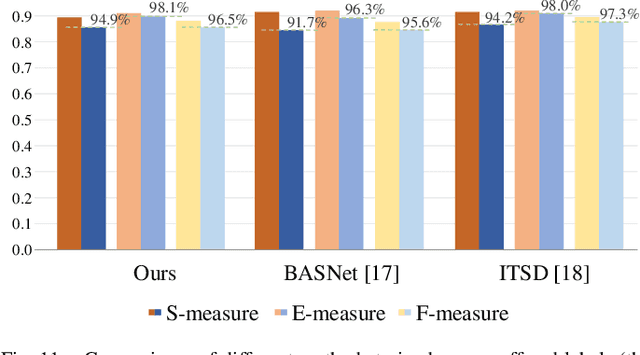
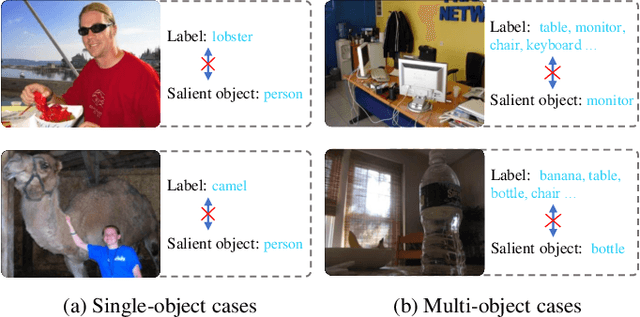
Weakly-supervised salient object detection (WSOD) aims to develop saliency models using image-level annotations. Despite of the success of previous works, explorations on an effective training strategy for the saliency network and accurate matches between image-level annotations and salient objects are still inadequate. In this work, 1) we propose a self-calibrated training strategy by explicitly establishing a mutual calibration loop between pseudo labels and network predictions, liberating the saliency network from error-prone propagation caused by pseudo labels. 2) we prove that even a much smaller dataset (merely 1.8% of ImageNet) with well-matched annotations can facilitate models to achieve better performance as well as generalizability. This sheds new light on the development of WSOD and encourages more contributions to the community. Comprehensive experiments demonstrate that our method outperforms all the existing WSOD methods by adopting the self-calibrated strategy only. Steady improvements are further achieved by training on the proposed dataset. Additionally, our method achieves 94.7% of the performance of fully-supervised methods on average. And what is more, the fully supervised models adopting our predicted results as "ground truths" achieve successful results (95.6% for BASNet and 97.3% for ITSD on F-measure), while costing only 0.32% of labeling time for pixel-level annotation.
Towards Unsupervised Learning of Generative Models for 3D Controllable Image Synthesis
Dec 11, 2019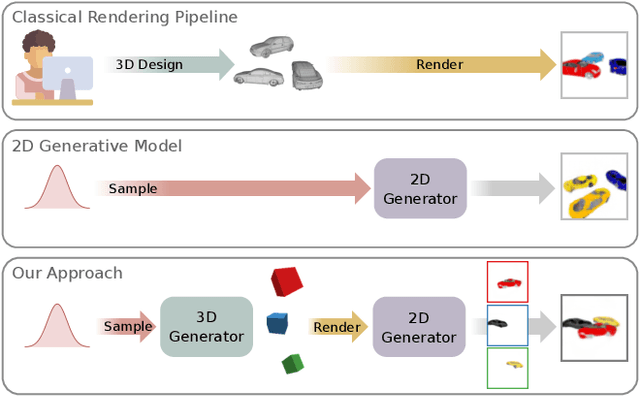
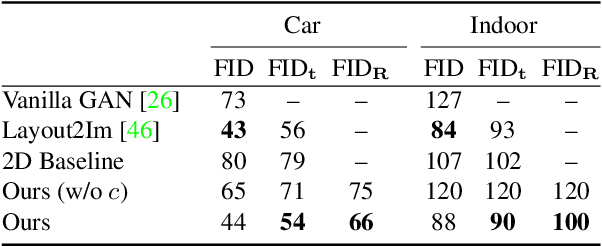


In recent years, Generative Adversarial Networks have achieved impressive results in photorealistic image synthesis. This progress nurtures hopes that one day the classical rendering pipeline can be replaced by efficient models that are learned directly from images. However, current image synthesis models operate in the 2D domain where disentangling 3D properties such as camera viewpoint or object pose is challenging. Furthermore, they lack an interpretable and controllable representation. Our key hypothesis is that the image generation process should be modeled in 3D space as the physical world surrounding us is intrinsically three-dimensional. We define the new task of 3D controllable image synthesis and propose an approach for solving it by reasoning both in 3D space and in the 2D image domain. We demonstrate that our model is able to disentangle latent 3D factors of simple multi-object scenes in an unsupervised fashion from raw images. Compared to pure 2D baselines, it allows for synthesizing scenes that are consistent wrt. changes in viewpoint or object pose. We further evaluate various 3D representations in terms of their usefulness for this challenging task.
Medical Image Registration Using Deep Neural Networks: A Comprehensive Review
Feb 09, 2020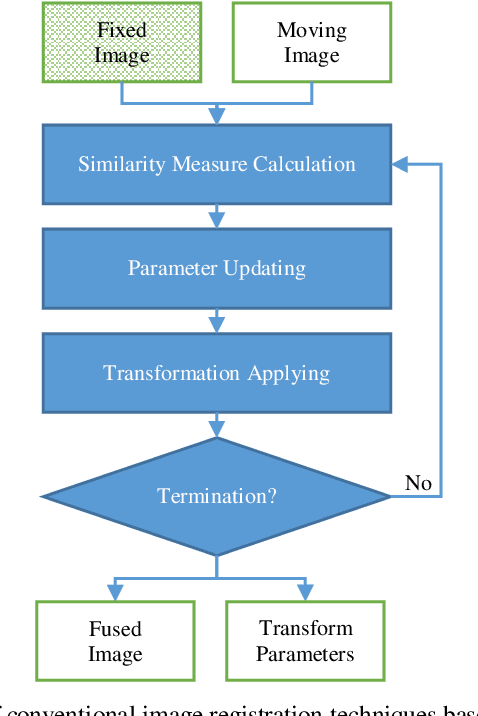
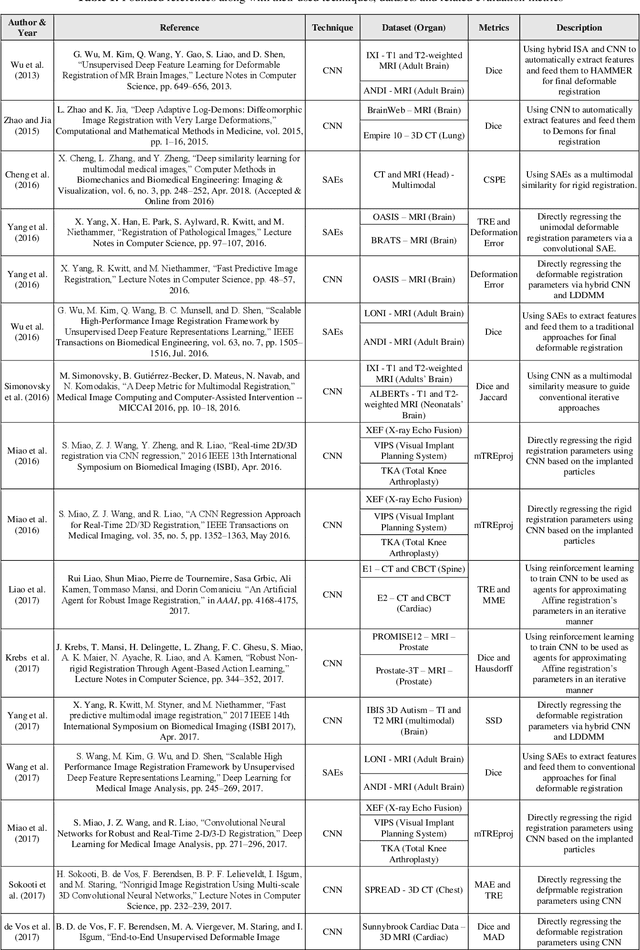
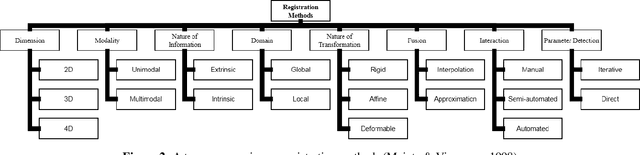
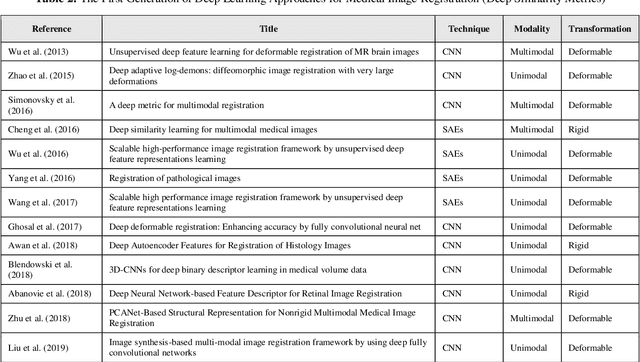
Image-guided interventions are saving the lives of a large number of patients where the image registration problem should indeed be considered as the most complex and complicated issue to be tackled. On the other hand, the recently huge progress in the field of machine learning made by the possibility of implementing deep neural networks on the contemporary many-core GPUs opened up a promising window to challenge with many medical applications, where the registration is not an exception. In this paper, a comprehensive review on the state-of-the-art literature known as medical image registration using deep neural networks is presented. The review is systematic and encompasses all the related works previously published in the field. Key concepts, statistical analysis from different points of view, confiding challenges, novelties and main contributions, key-enabling techniques, future directions and prospective trends all are discussed and surveyed in details in this comprehensive review. This review allows a deep understanding and insight for the readers active in the field who are investigating the state-of-the-art and seeking to contribute the future literature.
Efficient Folded Attention for 3D Medical Image Reconstruction and Segmentation
Sep 13, 2020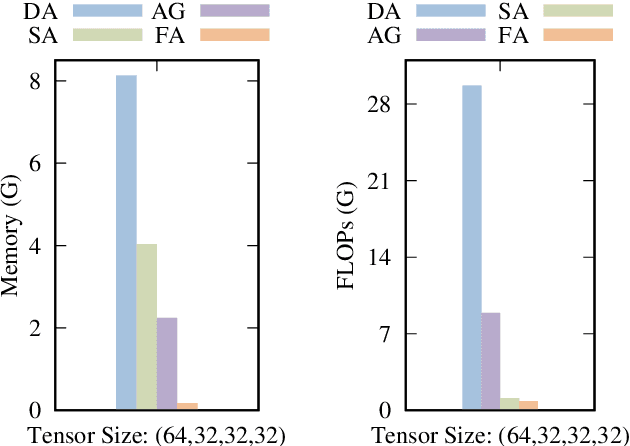
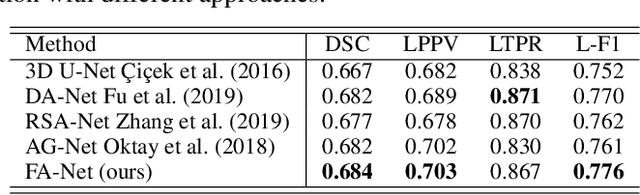
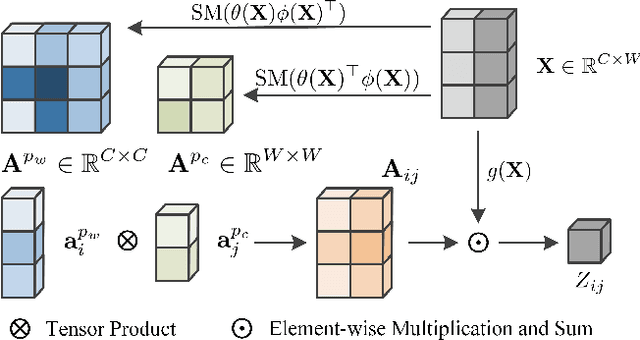
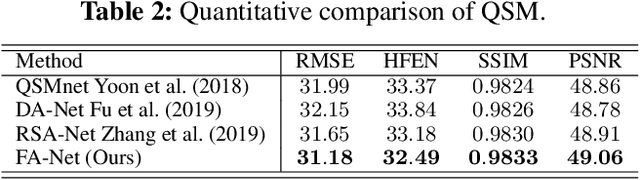
Recently, 3D medical image reconstruction (MIR) and segmentation (MIS) based on deep neural networks have been developed with promising results, and attention mechanism has been further designed to capture global contextual information for performance enhancement. However, the large size of 3D volume images poses a great computational challenge to traditional attention methods. In this paper, we propose a folded attention (FA) approach to improve the computational efficiency of traditional attention methods on 3D medical images. The main idea is that we apply tensor folding and unfolding operations with four permutations to build four small sub-affinity matrices to approximate the original affinity matrix. Through four consecutive sub-attention modules of FA, each element in the feature tensor can aggregate spatial-channel information from all other elements. Compared to traditional attention methods, with moderate improvement of accuracy, FA can substantially reduce the computational complexity and GPU memory consumption. We demonstrate the superiority of our method on two challenging tasks for 3D MIR and MIS, which are quantitative susceptibility mapping and multiple sclerosis lesion segmentation.
Application of Tilt Correlation Statistics to Anisoplanatic Optical Turbulence Modeling and Mitigation
Aug 01, 2021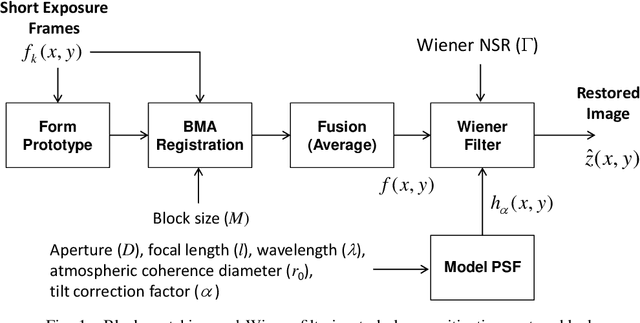
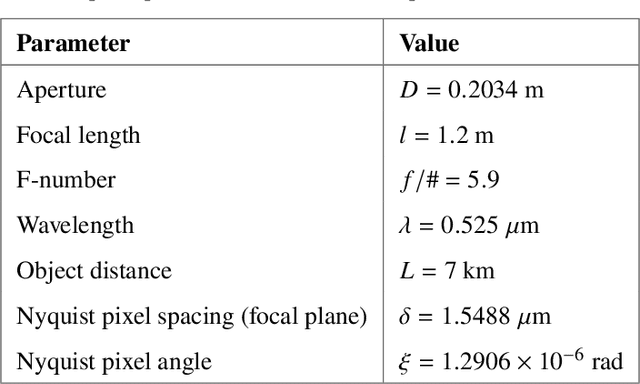
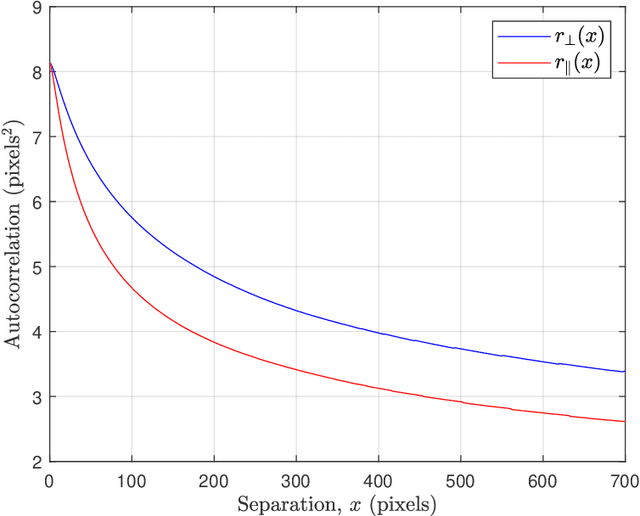
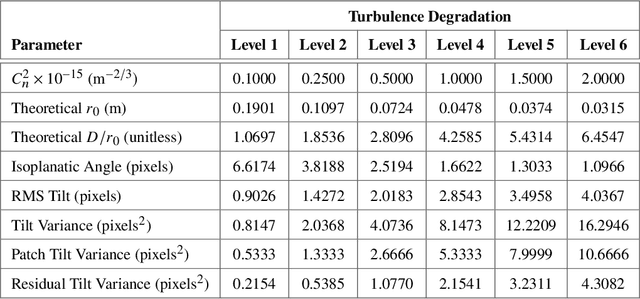
Atmospheric optical turbulence can be a significant source of image degradation, particularly in long range imaging applications. Many turbulence mitigation algorithms rely on an optical transfer function (OTF) model that includes the Fried parameter. We present anisoplanatic tilt statistics for spherical wave propagation. We transform these into 2D autocorrelation functions that can inform turbulence modeling and mitigation algorithms. Using these, we construct an OTF model that accounts for image registration. We also propose a spectral-ratio Fried parameter estimation algorithm that is robust to camera motion and requires no specialized scene content or sources. We employ the Fried parameter estimation and OTF model for turbulence mitigation. A numerical wave-propagation turbulence simulator is used to generate data to quantitatively validate the proposed methods. Results with real camera data are also presented.
* 32 pages, 23 figures, Copyright 2021 Optical Society of America. One print or electronic copy may be made for personal use only. Systematic reproduction and distribution, duplication of any material in this paper for a fee or for commercial purposes, or modifications of the content of this paper are prohibited. https://doi.org/10.1364/AO.418458
Unsupervised Image Regression for Heterogeneous Change Detection
Sep 07, 2019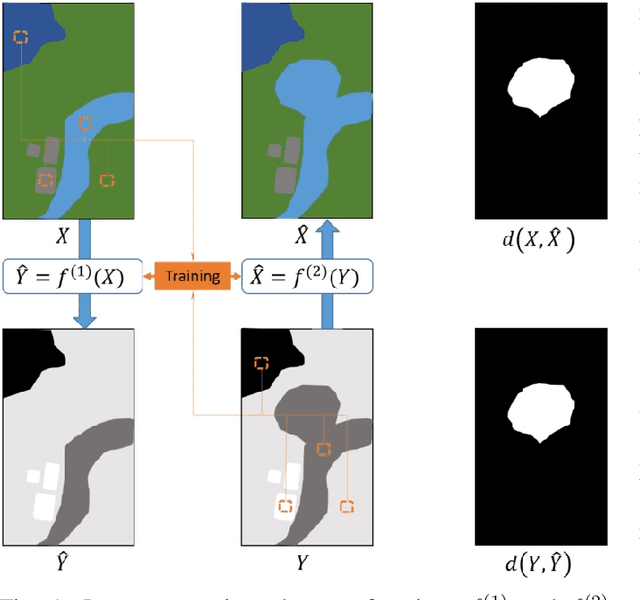
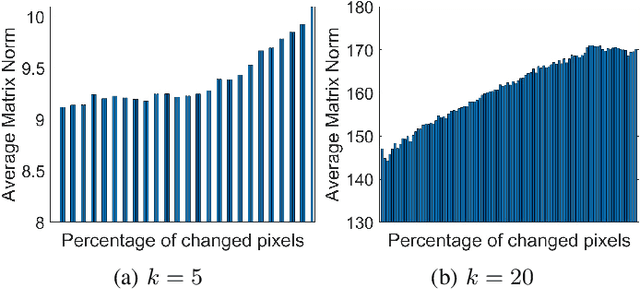
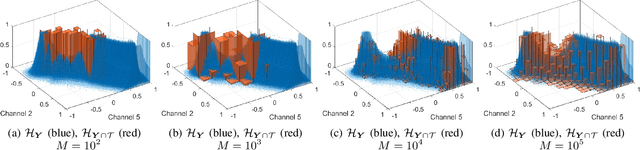
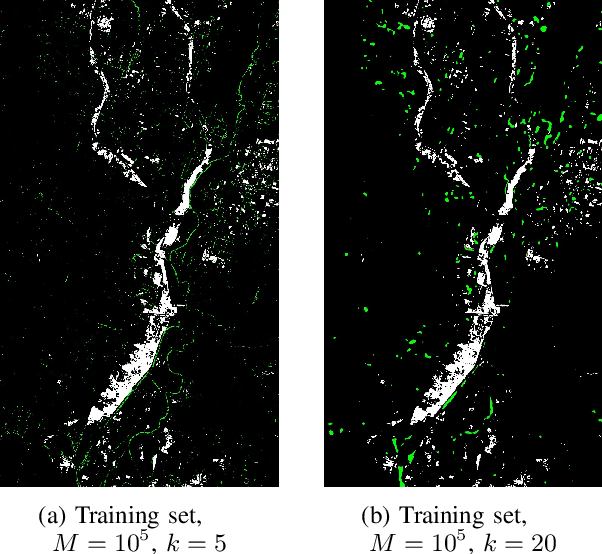
Change detection in heterogeneous multitemporal satellite images is an emerging and challenging topic in remote sensing. In particular, one of the main challenges is to tackle the problem in an unsupervised manner. In this paper we propose an unsupervised framework for bitemporal heterogeneous change detection based on the comparison of affinity matrices and image regression. First, our method quantifies the similarity of affinity matrices computed from co-located image patches in the two images. This is done to automatically identify pixels that are likely to be unchanged. With the identified pixels as pseudo-training data, we learn a transformation to map the first image to the domain of the other image, and vice versa. Four regression methods are selected to carry out the transformation: Gaussian process regression, support vector regression, random forest regression, and a recently proposed kernel regression method called homogeneous pixel transformation. To evaluate the potentials and limitations of our framework, and also the benefits and disadvantages of each regression method, we perform experiments on two real data sets. The results indicate that the comparison of the affinity matrices can already be considered a change detection method by itself. However, image regression is shown to improve the results obtained by the previous step alone and produces accurate change detection maps despite of the heterogeneity of the multitemporal input data. Notably, the random forest regression approach excels by achieving similar accuracy as the other methods, but with a significantly lower computational cost and with fast and robust tuning of hyperparameters.
Validate on Sim, Detect on Real -- Model Selection for Domain Randomization
Dec 01, 2021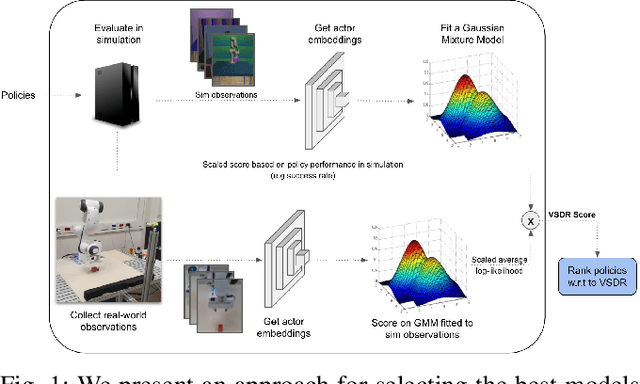
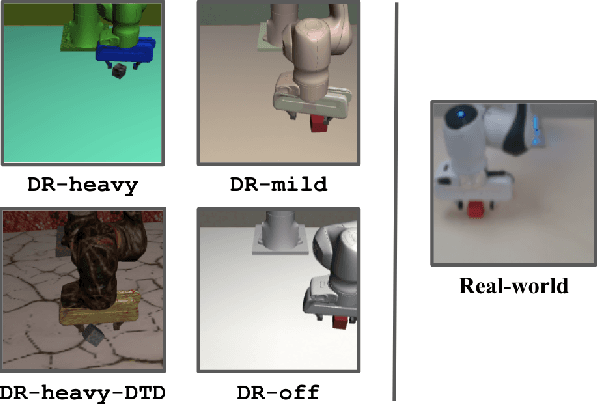
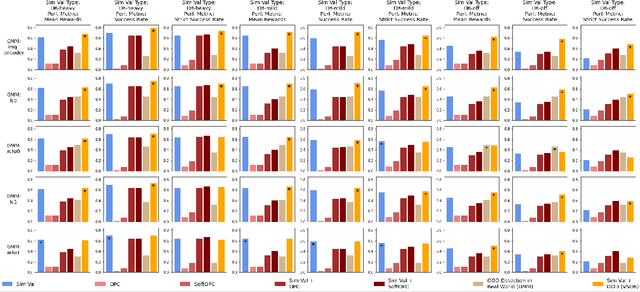
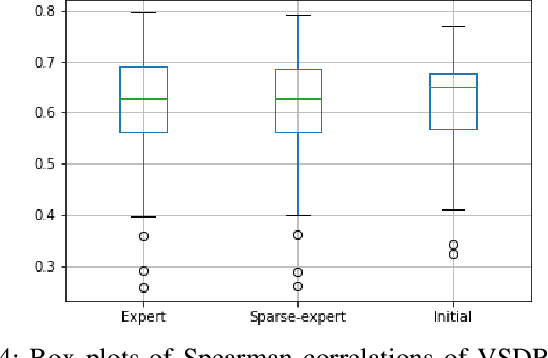
A practical approach to learning robot skills, often termed sim2real, is to train control policies in simulation and then deploy them on a real robot. Popular techniques to improve the sim2real transfer build on domain randomization (DR): Training the policy on a diverse set of randomly generated domains with the hope of better generalization to the real world. Due to the large number of hyper-parameters in both the policy learning and DR algorithms, one often ends up with a large number of trained models, where choosing the best model among them demands costly evaluation on the real robot. In this work we ask: Can we rank the policies without running them in the real world? Our main idea is that a predefined set of real world data can be used to evaluate all policies, using out-of-distribution detection (OOD) techniques. In a sense, this approach can be seen as a "unit test" to evaluate policies before any real world execution. However, we find that by itself, the OOD score can be inaccurate and very sensitive to the particular OOD method. Our main contribution is a simple-yet-effective policy score that combines OOD with an evaluation in simulation. We show that our score - VSDR - can significantly improve the accuracy of policy ranking without requiring additional real world data. We evaluate the effectiveness of VSDR on sim2real transfer in a robotic grasping task with image inputs. We extensively evaluate different DR parameters and OOD methods, and show that VSDR improves policy selection across the board. More importantly, our method achieves significantly better ranking, and uses significantly less data compared to baselines.
VC-Net: Deep Volume-Composition Networks for Segmentation and Visualization of Highly Sparse and Noisy Image Data
Sep 14, 2020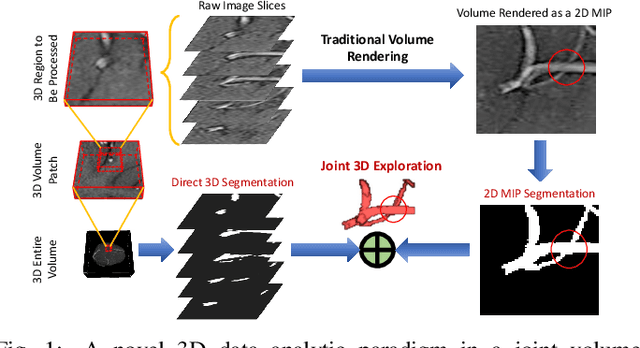
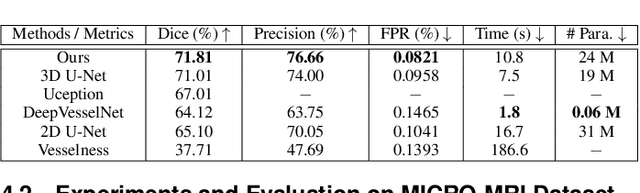


The motivation of our work is to present a new visualization-guided computing paradigm to combine direct 3D volume processing and volume rendered clues for effective 3D exploration such as extracting and visualizing microstructures in-vivo. However, it is still challenging to extract and visualize high fidelity 3D vessel structure due to its high sparseness, noisiness, and complex topology variations. In this paper, we present an end-to-end deep learning method, VC-Net, for robust extraction of 3D microvasculature through embedding the image composition, generated by maximum intensity projection (MIP), into 3D volume image learning to enhance the performance. The core novelty is to automatically leverage the volume visualization technique (MIP) to enhance the 3D data exploration at deep learning level. The MIP embedding features can enhance the local vessel signal and are adaptive to the geometric variability and scalability of vessels, which is crucial in microvascular tracking. A multi-stream convolutional neural network is proposed to learn the 3D volume and 2D MIP features respectively and then explore their inter-dependencies in a joint volume-composition embedding space by unprojecting the MIP features into 3D volume embedding space. The proposed framework can better capture small / micro vessels and improve vessel connectivity. To our knowledge, this is the first deep learning framework to construct a joint convolutional embedding space, where the computed vessel probabilities from volume rendering based 2D projection and 3D volume can be explored and integrated synergistically. Experimental results are compared with the traditional 3D vessel segmentation methods and the deep learning state-of-the-art on public and real patient (micro-)cerebrovascular image datasets. Our method demonstrates the potential in a powerful MR arteriogram and venogram diagnosis of vascular diseases.
Dataset Growth in Medical Image Analysis Research
Aug 21, 2019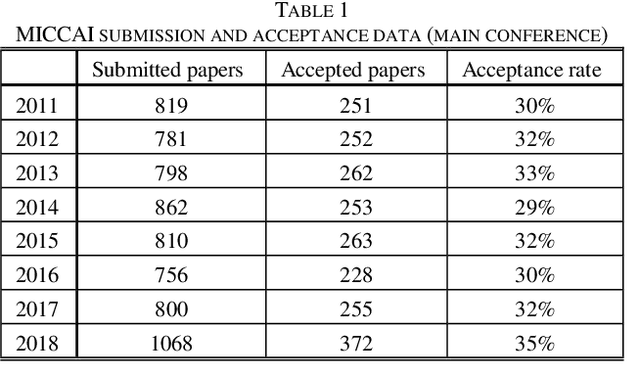
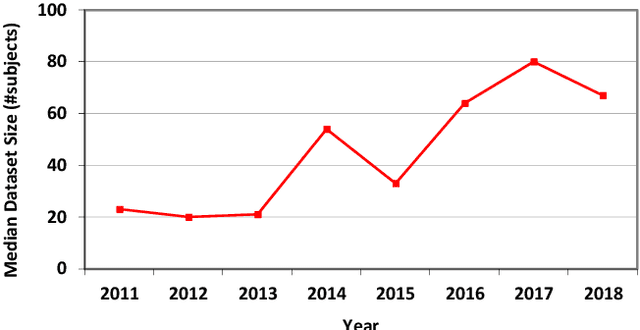
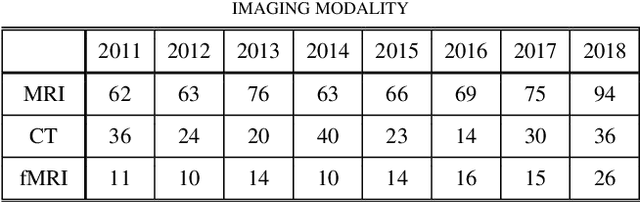
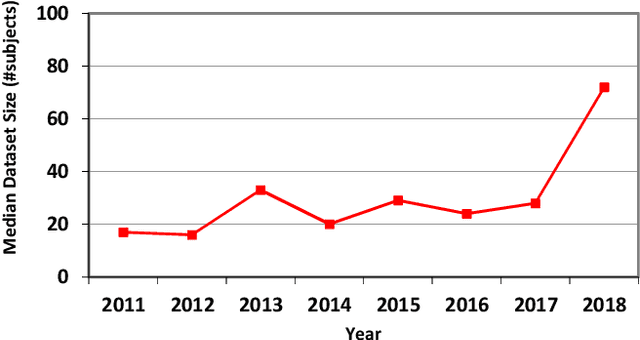
Medical image analysis studies usually require medical image datasets for training, testing and validation of algorithms. The need is underscored by the deep learning revolution and the dominance of machine learning in recent medical image analysis research. Nevertheless, due to ethical and legal constraints, commercial conflicts and the dependence on busy medical professionals, medical image analysis researchers have been described as "data starved". Due to the lack of objective criteria for sufficiency of dataset size, the research community implicitly sets ad-hoc standards by means of the peer review process. We hypothesize that peer review requires researchers to report the use of ever-increasing datasets as one condition for acceptance of their work to reputable publication venues. To test this hypothesis, we scanned the proceedings of the eminent MICCAI (Medical Image Computing and Computer-Assisted Intervention) conferences from 2011 to 2018. From a total of 2136 articles, we focused on 907 papers involving human datasets of MRI (Magnetic Resonance Imaging), CT (Computed Tomography) and fMRI (functional MRI) images. For each modality, for each of the years 2011-2018 we calculated the average, geometric mean and median number of human subjects used in that year's MICCAI articles. The results corroborate the dataset growth hypothesis. Specifically, the annual median dataset size in MICCAI articles has grown roughly 3-10 times from 2011 to 2018, depending on the imaging modality. Statistical analysis further supports the dataset growth hypothesis and reveals exponential growth of the geometric mean dataset size, with annual growth of about 21% for MRI, 24% for CT and 31% for fMRI. In slight analogy to Moore's law, the results can provide guidance about trends in the expectations of the medical image analysis community regarding dataset size.
Adaptive Image Sampling using Deep Learning and its Application on X-Ray Fluorescence Image Reconstruction
Jan 04, 2019
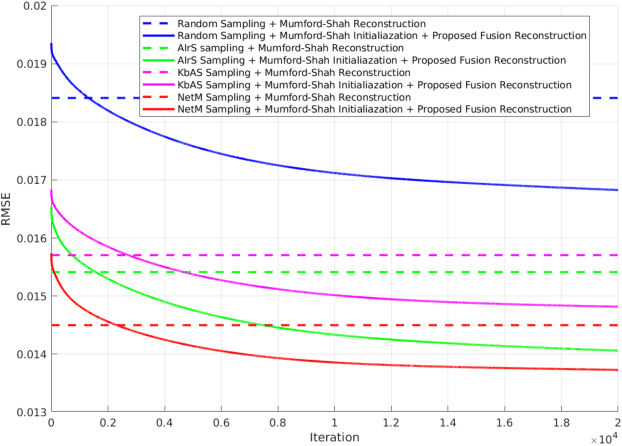
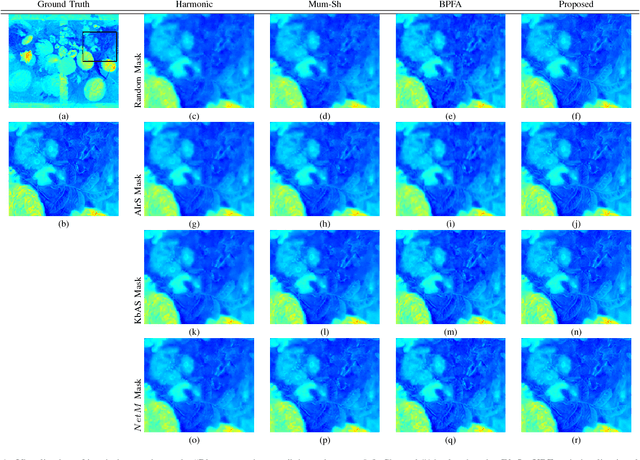

This paper presents an adaptive image sampling algorithm based on Deep Learning (DL). The adaptive sampling mask generation network is jointly trained with an image inpainting network. The sampling rate is controlled in the mask generation network, and a binarization strategy is investigated to make the sampling mask binary. Besides the image sampling and reconstruction application, we show that the proposed adaptive sampling algorithm is able to speed up raster scan processes such as the X-Ray fluorescence (XRF) image scanning process. Recently XRF laboratory-based systems have evolved to lightweight and portable instruments thanks to technological advancements in both X-Ray generation and detection. However, the scanning time of an XRF image is usually long due to the long exposures requires (e.g., $100 \mu s-1ms$ per point). We propose an XRF image inpainting approach to address the issue of long scanning time, thus speeding up the scanning process while still maintaining the possibility to reconstruct a high quality XRF image. The proposed adaptive image sampling algorithm is applied to the RGB image of the scanning target to generate the sampling mask. The XRF scanner is then driven according to the sampling mask to scan a subset of the total image pixels. Finally, we inpaint the scanned XRF image by fusing the RGB image to reconstruct the full scan XRF image. The experiments show that the proposed adaptive sampling algorithm is able to effectively sample the image and achieve a better reconstruction accuracy than that of the existing methods.