 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Black-Box Test-Time Shape REFINEment for Single View 3D Reconstruction
Aug 23, 2021
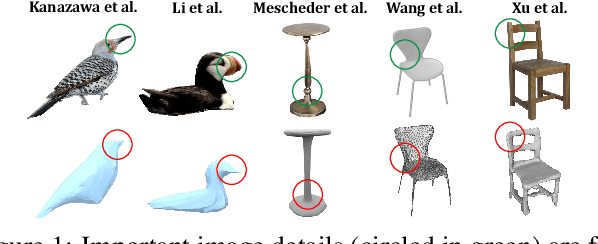
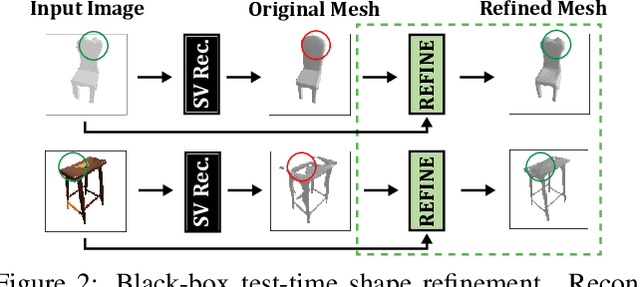
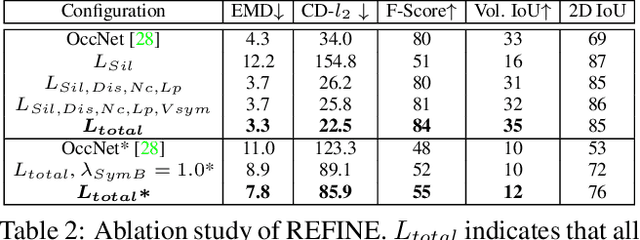
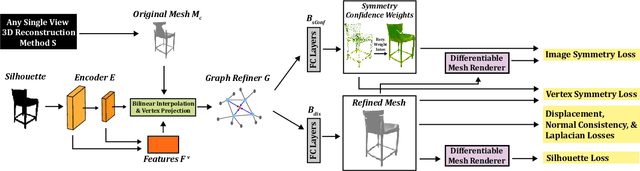
Much recent progress has been made in reconstructing the 3D shape of an object from an image of it, i.e. single view 3D reconstruction. However, it has been suggested that current methods simply adopt a "nearest-neighbor" strategy, instead of genuinely understanding the shape behind the input image. In this paper, we rigorously show that for many state of the art methods, this issue manifests as (1) inconsistencies between coarse reconstructions and input images, and (2) inability to generalize across domains. We thus propose REFINE, a postprocessing mesh refinement step that can be easily integrated into the pipeline of any black-box method in the literature. At test time, REFINE optimizes a network per mesh instance, to encourage consistency between the mesh and the given object view. This, along with a novel combination of regularizing losses, reduces the domain gap and achieves state of the art performance. We believe that this novel paradigm is an important step towards robust, accurate reconstructions, remaining relevant as new reconstruction networks are introduced.
Not Color Blind: AI Predicts Racial Identity from Black and White Retinal Vessel Segmentations
Sep 28, 2021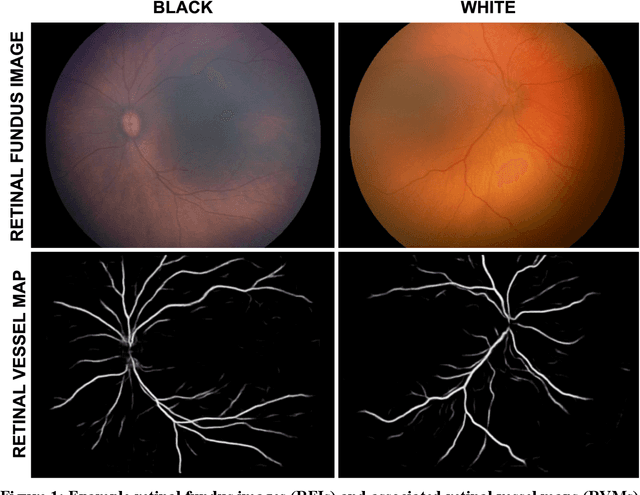
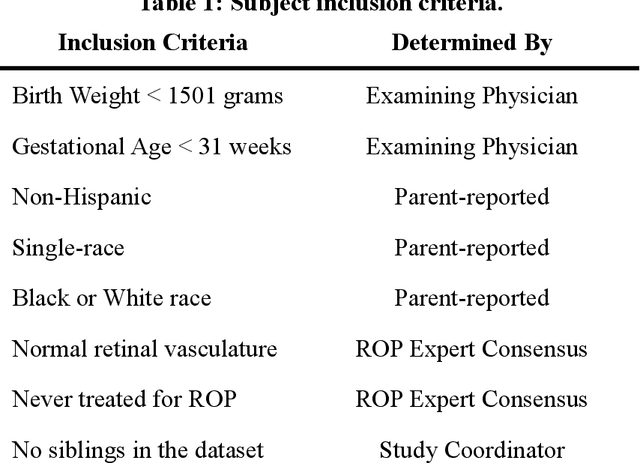
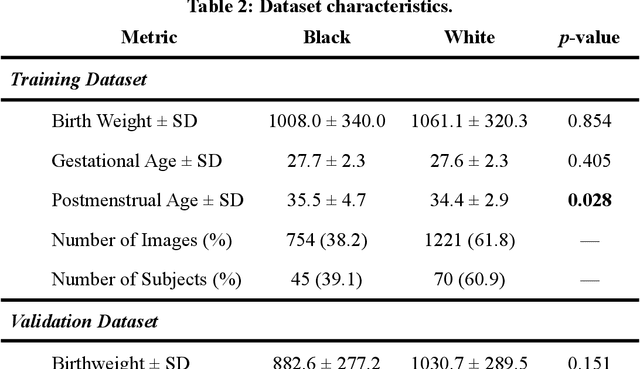
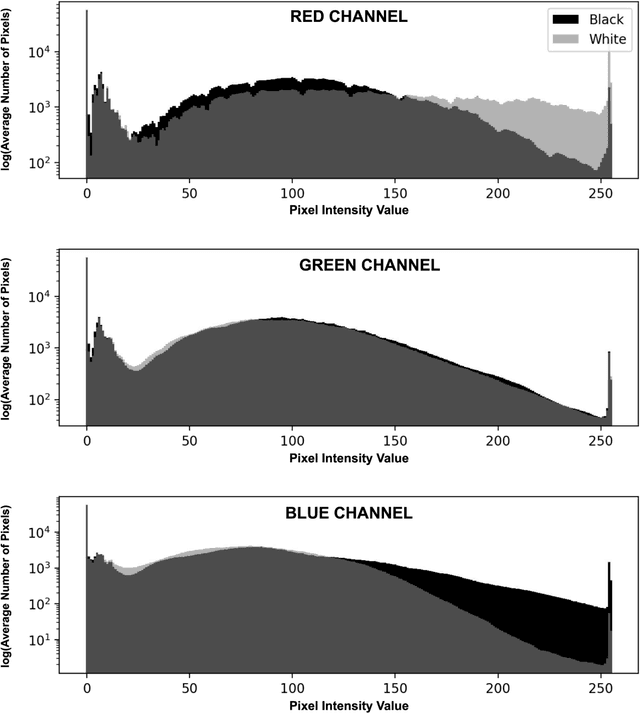
Background: Artificial intelligence (AI) may demonstrate racial bias when skin or choroidal pigmentation is present in medical images. Recent studies have shown that convolutional neural networks (CNNs) can predict race from images that were not previously thought to contain race-specific features. We evaluate whether grayscale retinal vessel maps (RVMs) of patients screened for retinopathy of prematurity (ROP) contain race-specific features. Methods: 4095 retinal fundus images (RFIs) were collected from 245 Black and White infants. A U-Net generated RVMs from RFIs, which were subsequently thresholded, binarized, or skeletonized. To determine whether RVM differences between Black and White eyes were physiological, CNNs were trained to predict race from color RFIs, raw RVMs, and thresholded, binarized, or skeletonized RVMs. Area under the precision-recall curve (AUC-PR) was evaluated. Findings: CNNs predicted race from RFIs near perfectly (image-level AUC-PR: 0.999, subject-level AUC-PR: 1.000). Raw RVMs were almost as informative as color RFIs (image-level AUC-PR: 0.938, subject-level AUC-PR: 0.995). Ultimately, CNNs were able to detect whether RFIs or RVMs were from Black or White babies, regardless of whether images contained color, vessel segmentation brightness differences were nullified, or vessel segmentation widths were normalized. Interpretation: AI can detect race from grayscale RVMs that were not thought to contain racial information. Two potential explanations for these findings are that: retinal vessels physiologically differ between Black and White babies or the U-Net segments the retinal vasculature differently for various fundus pigmentations. Either way, the implications remain the same: AI algorithms have potential to demonstrate racial bias in practice, even when preliminary attempts to remove such information from the underlying images appear to be successful.
The state-of-the-art in text-based automatic personality prediction
Oct 04, 2021
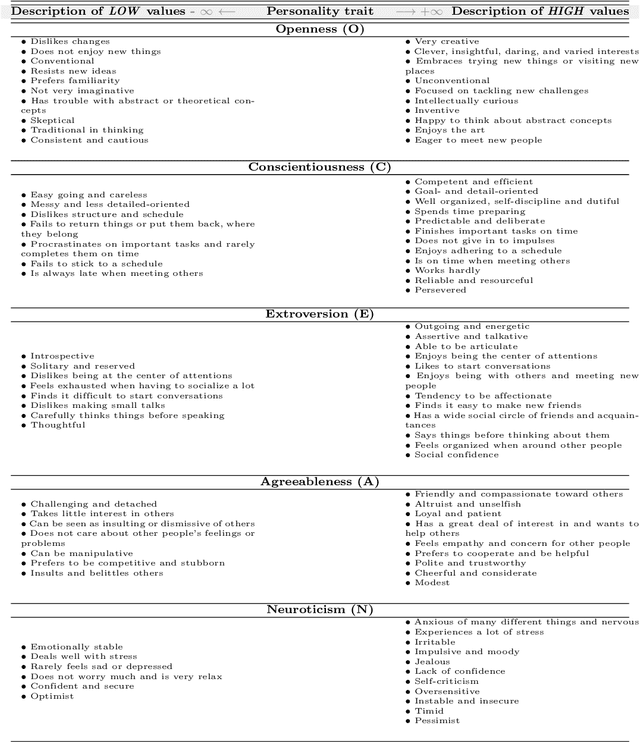
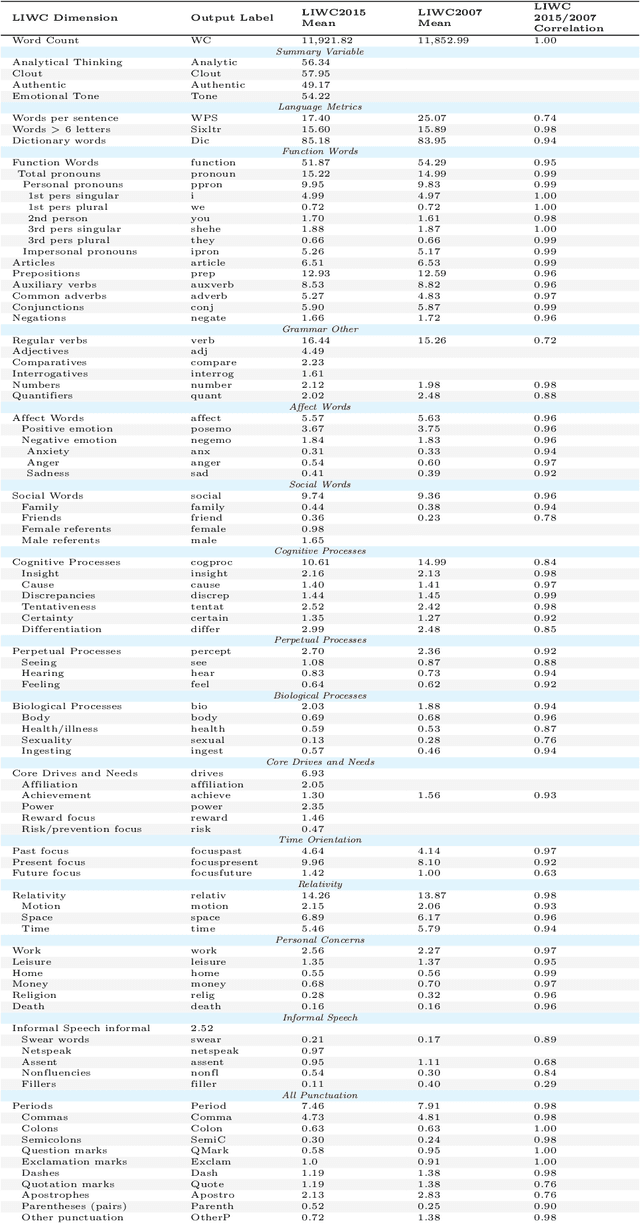
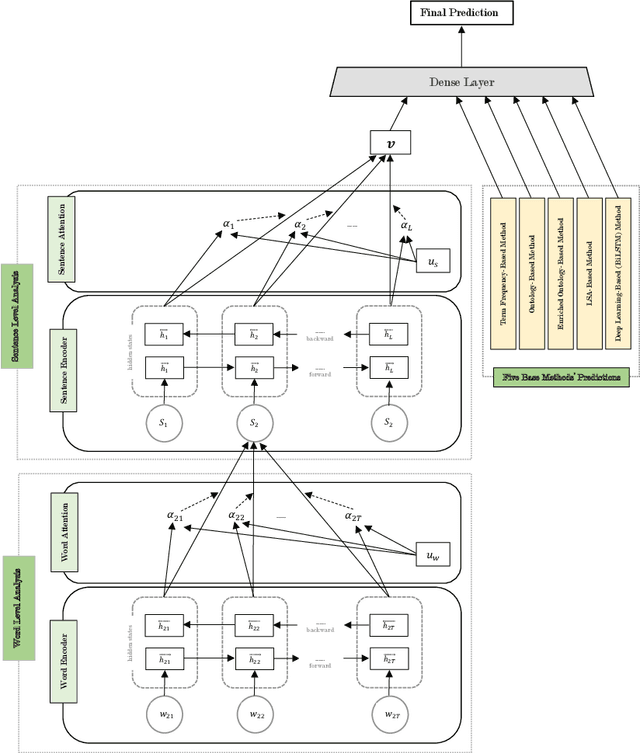
Personality detection is an old topic in psychology and Automatic Personality Prediction (or Perception) (APP) is the automated (computationally) forecasting of the personality on different types of human generated/exchanged contents (such as text, speech, image, video). The principal objective of this study is to offer a shallow (overall) review of natural language processing approaches on APP since 2010. With the advent of deep learning and following it transfer-learning and pre-trained model in NLP, APP research area has been a hot topic, so in this review, methods are categorized into three; pre-trained independent, pre-trained model based, multimodal approaches. Also, to achieve a comprehensive comparison, reported results are informed by datasets.
Edge AI without Compromise: Efficient, Versatile and Accurate Neurocomputing in Resistive Random-Access Memory
Aug 17, 2021
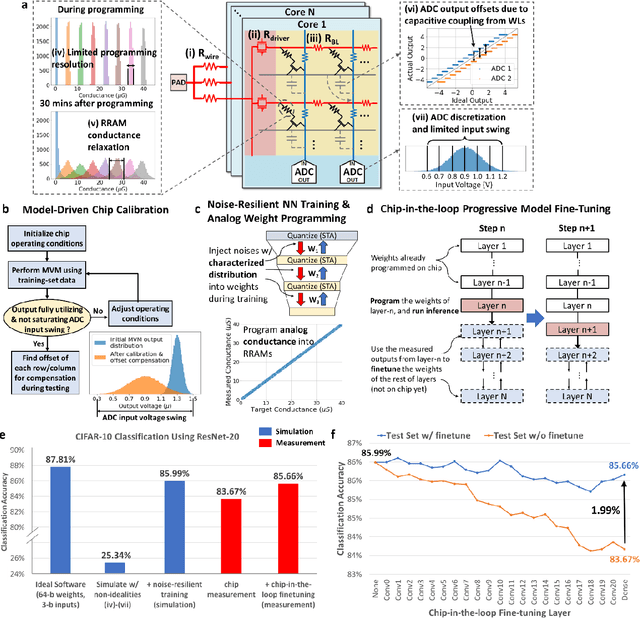
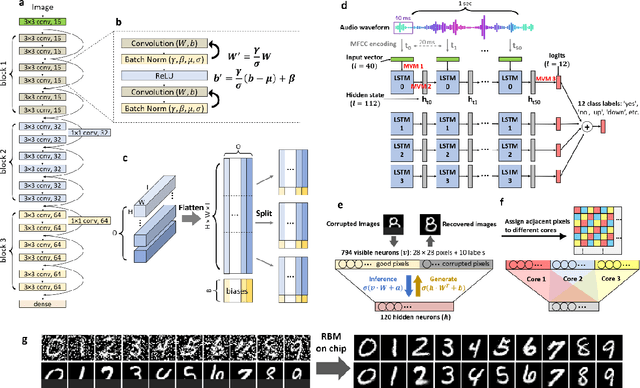
Realizing today's cloud-level artificial intelligence functionalities directly on devices distributed at the edge of the internet calls for edge hardware capable of processing multiple modalities of sensory data (e.g. video, audio) at unprecedented energy-efficiency. AI hardware architectures today cannot meet the demand due to a fundamental "memory wall": data movement between separate compute and memory units consumes large energy and incurs long latency. Resistive random-access memory (RRAM) based compute-in-memory (CIM) architectures promise to bring orders of magnitude energy-efficiency improvement by performing computation directly within memory. However, conventional approaches to CIM hardware design limit its functional flexibility necessary for processing diverse AI workloads, and must overcome hardware imperfections that degrade inference accuracy. Such trade-offs between efficiency, versatility and accuracy cannot be addressed by isolated improvements on any single level of the design. By co-optimizing across all hierarchies of the design from algorithms and architecture to circuits and devices, we present NeuRRAM - the first multimodal edge AI chip using RRAM CIM to simultaneously deliver a high degree of versatility for diverse model architectures, record energy-efficiency $5\times$ - $8\times$ better than prior art across various computational bit-precisions, and inference accuracy comparable to software models with 4-bit weights on all measured standard AI benchmarks including accuracy of 99.0% on MNIST and 85.7% on CIFAR-10 image classification, 84.7% accuracy on Google speech command recognition, and a 70% reduction in image reconstruction error on a Bayesian image recovery task. This work paves a way towards building highly efficient and reconfigurable edge AI hardware platforms for the more demanding and heterogeneous AI applications of the future.
Investigating Tradeoffs in Real-World Video Super-Resolution
Nov 24, 2021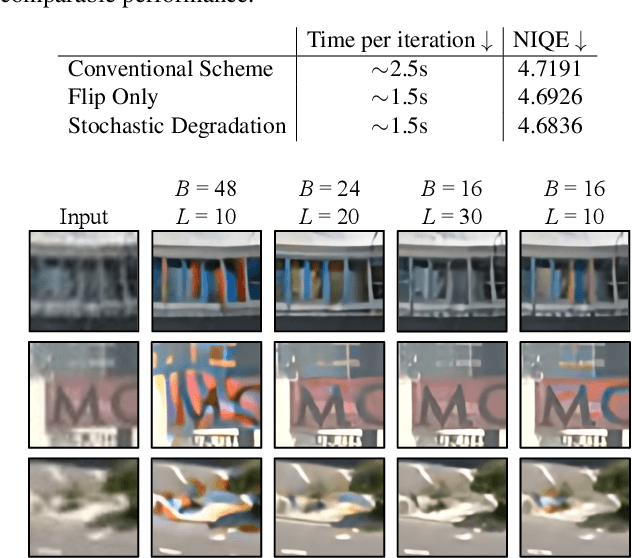


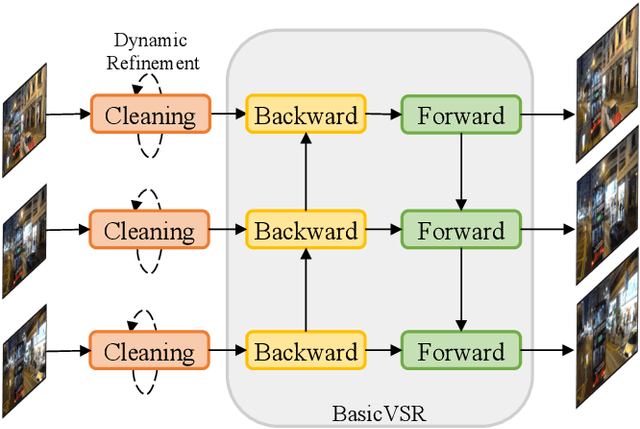
The diversity and complexity of degradations in real-world video super-resolution (VSR) pose non-trivial challenges in inference and training. First, while long-term propagation leads to improved performance in cases of mild degradations, severe in-the-wild degradations could be exaggerated through propagation, impairing output quality. To balance the tradeoff between detail synthesis and artifact suppression, we found an image pre-cleaning stage indispensable to reduce noises and artifacts prior to propagation. Equipped with a carefully designed cleaning module, our RealBasicVSR outperforms existing methods in both quality and efficiency. Second, real-world VSR models are often trained with diverse degradations to improve generalizability, requiring increased batch size to produce a stable gradient. Inevitably, the increased computational burden results in various problems, including 1) speed-performance tradeoff and 2) batch-length tradeoff. To alleviate the first tradeoff, we propose a stochastic degradation scheme that reduces up to 40\% of training time without sacrificing performance. We then analyze different training settings and suggest that employing longer sequences rather than larger batches during training allows more effective uses of temporal information, leading to more stable performance during inference. To facilitate fair comparisons, we propose the new VideoLQ dataset, which contains a large variety of real-world low-quality video sequences containing rich textures and patterns. Our dataset can serve as a common ground for benchmarking. Code, models, and the dataset will be made publicly available.
Simulating Realistic MRI variations to Improve Deep Learning model and visual explanations using GradCAM
Nov 01, 2021
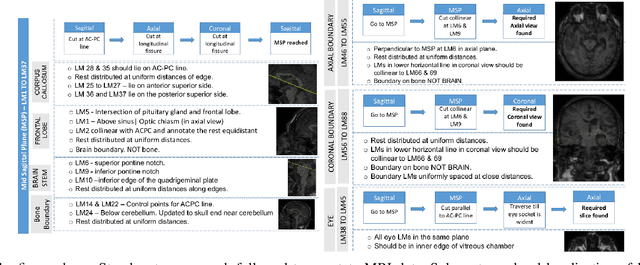
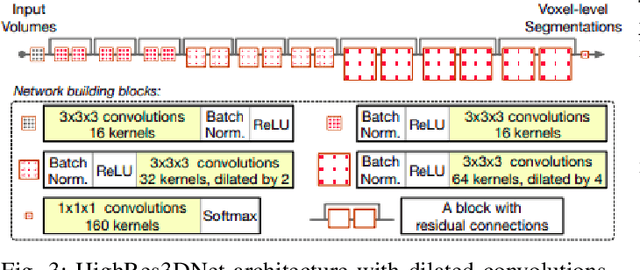
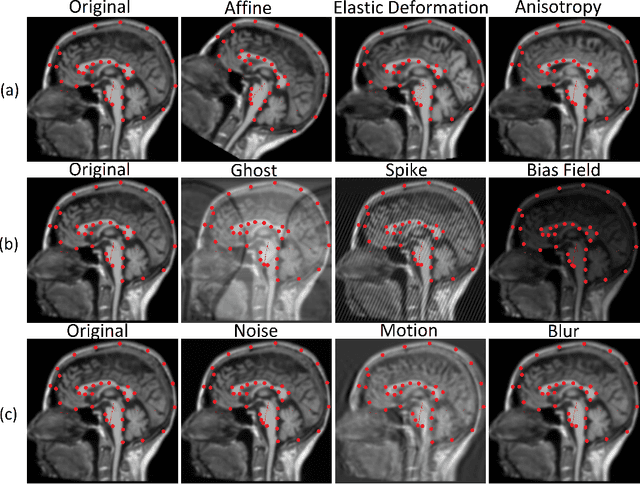
In the medical field, landmark detection in MRI plays an important role in reducing medical technician efforts in tasks like scan planning, image registration, etc. First, 88 landmarks spread across the brain anatomy in the three respective views -- sagittal, coronal, and axial are manually annotated, later guidelines from the expert clinical technicians are taken sub-anatomy-wise, for better localization of the existing landmarks, in order to identify and locate the important atlas landmarks even in oblique scans. To overcome limited data availability, we implement realistic data augmentation to generate synthetic 3D volumetric data. We use a modified HighRes3DNet model for solving brain MRI volumetric landmark detection problem. In order to visually explain our trained model on unseen data, and discern a stronger model from a weaker model, we implement Gradient-weighted Class Activation Mapping (Grad-CAM) which produces a coarse localization map highlighting the regions the model is focusing. Our experiments show that the proposed method shows favorable results, and the overall pipeline can be extended to a variable number of landmarks and other anatomies.
AI Online Filters to Real World Image Recognition
Feb 11, 2020
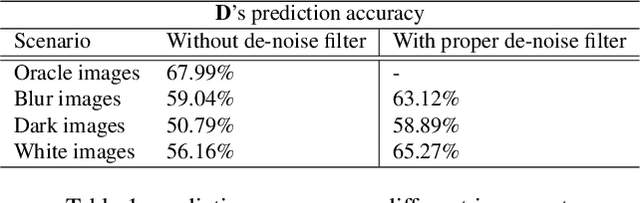

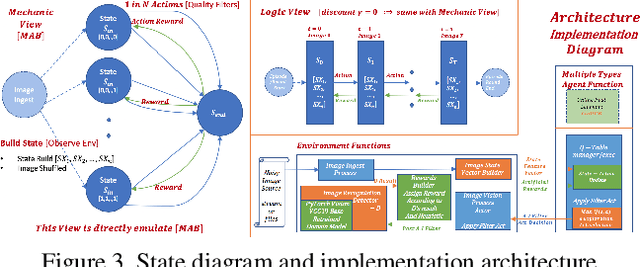
Deep artificial neural networks, trained with labeled data sets are widely used in numerous vision and robotics applications today. In terms of AI, these are called reflex models, referring to the fact that they do not self-evolve or actively adapt to environmental changes. As demand for intelligent robot control expands to many high level tasks, reinforcement learning and state based models play an increasingly important role. Herein, in computer vision and robotics domain, we study a novel approach to add reinforcement controls onto the image recognition reflex models to attain better overall performance, specifically to a wider environment range beyond what is expected of the task reflex models. Follow a common infrastructure with environment sensing and AI based modeling of self-adaptive agents, we implement multiple types of AI control agents. To the end, we provide comparative results of these agents with baseline, and an insightful analysis of their benefit to improve overall image recognition performance in real world.
Learning Visual Affordance Grounding from Demonstration Videos
Aug 12, 2021
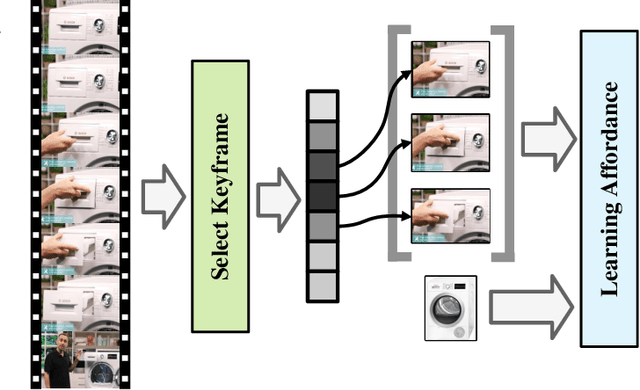
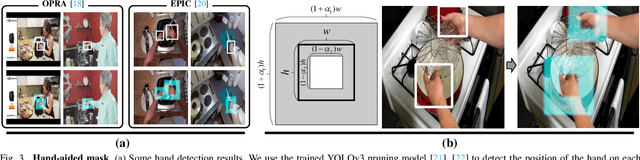
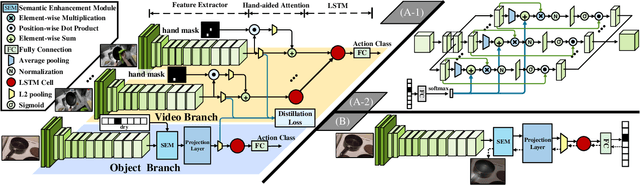
Visual affordance grounding aims to segment all possible interaction regions between people and objects from an image/video, which is beneficial for many applications, such as robot grasping and action recognition. However, existing methods mainly rely on the appearance feature of the objects to segment each region of the image, which face the following two problems: (i) there are multiple possible regions in an object that people interact with; and (ii) there are multiple possible human interactions in the same object region. To address these problems, we propose a Hand-aided Affordance Grounding Network (HAGNet) that leverages the aided clues provided by the position and action of the hand in demonstration videos to eliminate the multiple possibilities and better locate the interaction regions in the object. Specifically, HAG-Net has a dual-branch structure to process the demonstration video and object image. For the video branch, we introduce hand-aided attention to enhance the region around the hand in each video frame and then use the LSTM network to aggregate the action features. For the object branch, we introduce a semantic enhancement module (SEM) to make the network focus on different parts of the object according to the action classes and utilize a distillation loss to align the output features of the object branch with that of the video branch and transfer the knowledge in the video branch to the object branch. Quantitative and qualitative evaluations on two challenging datasets show that our method has achieved stateof-the-art results for affordance grounding. The source code will be made available to the public.
PGGANet: Pose Guided Graph Attention Network for Person Re-identification
Nov 29, 2021
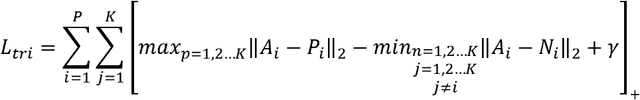
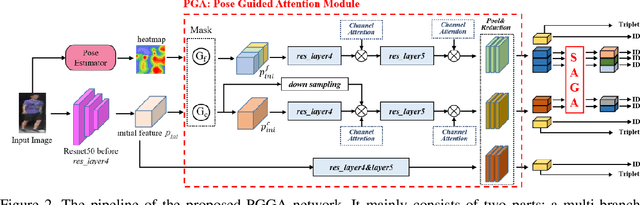
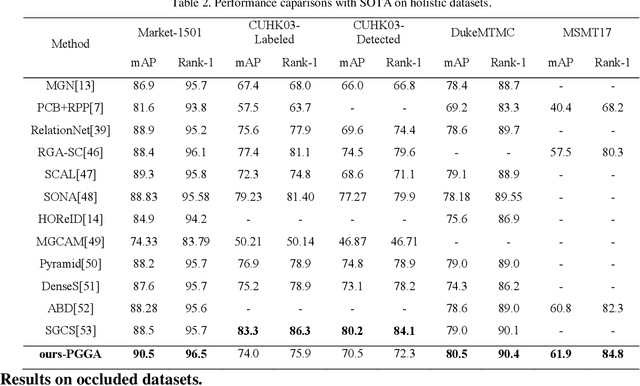
Person re-identification (ReID) aims at retrieving a person from images captured by different cameras. For deep-learning-based ReID methods, it has been proved that using local features together with global feature of person image could help to give robust feature representations for person retrieval. Human pose information could provide the locations of human skeleton to effectively guide the network to pay more attention on these key areas and could also help to reduce the noise distractions from background or occlusions. However, methods proposed by previous pose-related works might not be able to fully exploit the benefits of pose information and did not take into consideration the different contributions of different local features. In this paper, we propose a pose guided graph attention network, a multi-branch architecture consisting of one branch for global feature, one branch for mid-granular body features and one branch for fine-granular key point features. We use a pre-trained pose estimator to generate the key-point heatmap for local feature learning and carefully design a graph attention convolution layer to re-evaluate the contribution weights of extracted local features by modeling the similarities relations. Experiments results demonstrate the effectiveness of our approach on discriminative feature learning and we show that our model achieves state-of-the-art performances on several mainstream evaluation datasets. We also conduct a plenty of ablation studies and design different kinds of comparison experiments for our network to prove its effectiveness and robustness, including holistic datasets, partial datasets, occluded datasets and cross-domain tests.
MUSE: Feature Self-Distillation with Mutual Information and Self-Information
Oct 25, 2021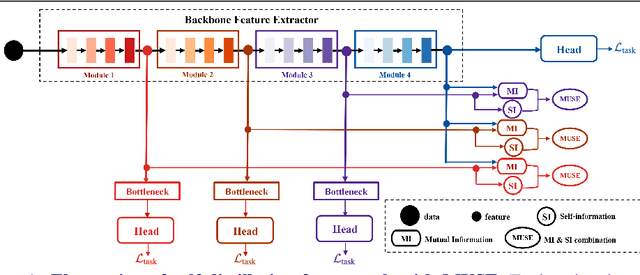
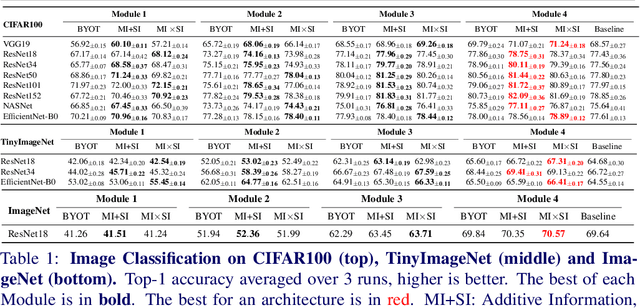

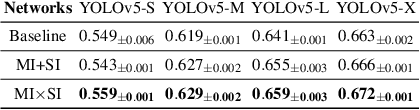
We present a novel information-theoretic approach to introduce dependency among features of a deep convolutional neural network (CNN). The core idea of our proposed method, called MUSE, is to combine MUtual information and SElf-information to jointly improve the expressivity of all features extracted from different layers in a CNN. We present two variants of the realization of MUSE -- Additive Information and Multiplicative Information. Importantly, we argue and empirically demonstrate that MUSE, compared to other feature discrepancy functions, is a more functional proxy to introduce dependency and effectively improve the expressivity of all features in the knowledge distillation framework. MUSE achieves superior performance over a variety of popular architectures and feature discrepancy functions for self-distillation and online distillation, and performs competitively with the state-of-the-art methods for offline distillation. MUSE is also demonstrably versatile that enables it to be easily extended to CNN-based models on tasks other than image classification such as object detection.