 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Structure-Preserving Multi-Domain Stain Color Augmentation using Style-Transfer with Disentangled Representations
Jul 26, 2021
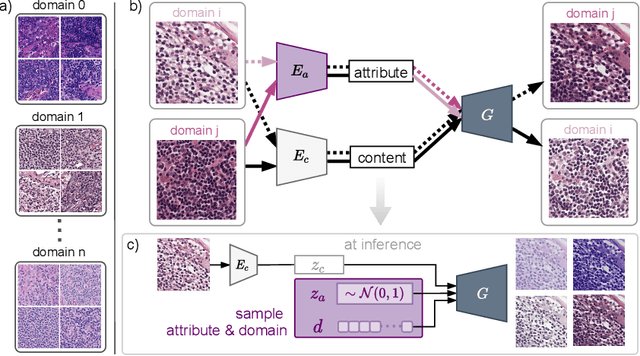
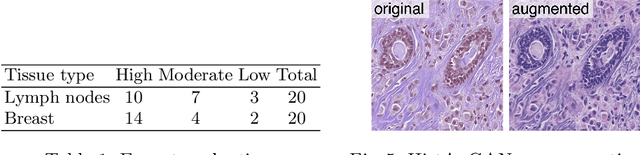
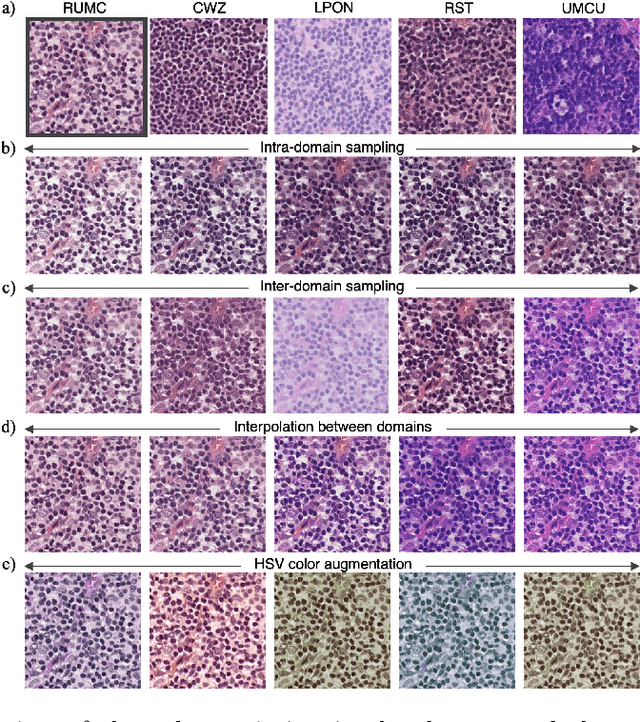
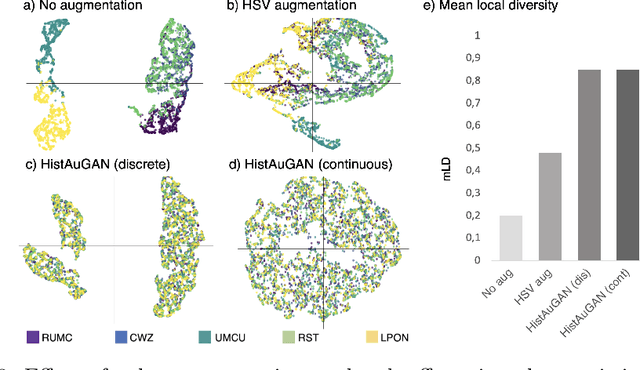
In digital pathology, different staining procedures and scanners cause substantial color variations in whole-slide images (WSIs), especially across different laboratories. These color shifts result in a poor generalization of deep learning-based methods from the training domain to external pathology data. To increase test performance, stain normalization techniques are used to reduce the variance between training and test domain. Alternatively, color augmentation can be applied during training leading to a more robust model without the extra step of color normalization at test time. We propose a novel color augmentation technique, HistAuGAN, that can simulate a wide variety of realistic histology stain colors, thus making neural networks stain-invariant when applied during training. Based on a generative adversarial network (GAN) for image-to-image translation, our model disentangles the content of the image, i.e., the morphological tissue structure, from the stain color attributes. It can be trained on multiple domains and, therefore, learns to cover different stain colors as well as other domain-specific variations introduced in the slide preparation and imaging process. We demonstrate that HistAuGAN outperforms conventional color augmentation techniques on a classification task on the publicly available dataset Camelyon17 and show that it is able to mitigate present batch effects.
Light Lies: Optical Adversarial Attack
Jun 18, 2021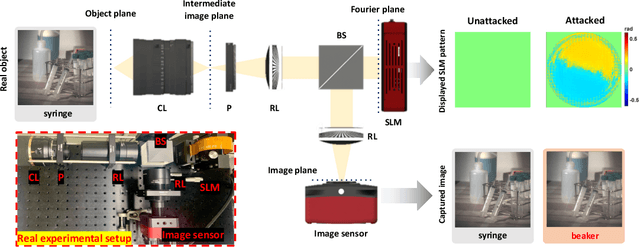

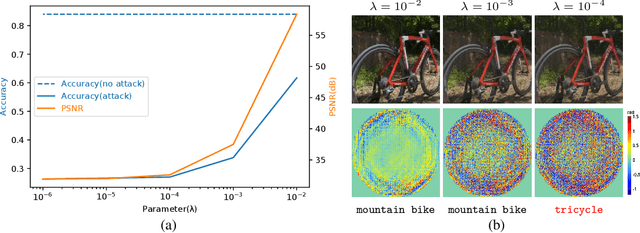
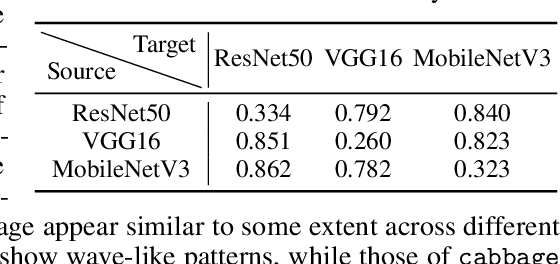
A significant amount of work has been done on adversarial attacks that inject imperceptible noise to images to deteriorate the image classification performance of deep models. However, most of the existing studies consider attacks in the digital (pixel) domain where an image acquired by an image sensor with sampling and quantization has been recorded. This paper, for the first time, introduces an optical adversarial attack, which physically alters the light field information arriving at the image sensor so that the classification model yields misclassification. More specifically, we modulate the phase of the light in the Fourier domain using a spatial light modulator placed in the photographic system. The operative parameters of the modulator are obtained by gradient-based optimization to maximize cross-entropy and minimize distortions. We present experiments based on both simulation and a real hardware optical system, from which the feasibility of the proposed optical attack is demonstrated. It is also verified that the proposed attack is completely different from common optical-domain distortions such as spherical aberration, defocus, and astigmatism in terms of both perturbation patterns and classification results.
Precise Object Placement with Pose Distance Estimations for Different Objects and Grippers
Oct 03, 2021



This paper introduces a novel approach for the grasping and precise placement of various known rigid objects using multiple grippers within highly cluttered scenes. Using a single depth image of the scene, our method estimates multiple 6D object poses together with an object class, a pose distance for object pose estimation, and a pose distance from a target pose for object placement for each automatically obtained grasp pose with a single forward pass of a neural network. By incorporating model knowledge into the system, our approach has higher success rates for grasping than state-of-the-art model-free approaches. Furthermore, our method chooses grasps that result in significantly more precise object placements than prior model-based work.
Learning Visual Affordance Grounding from Demonstration Videos
Aug 12, 2021
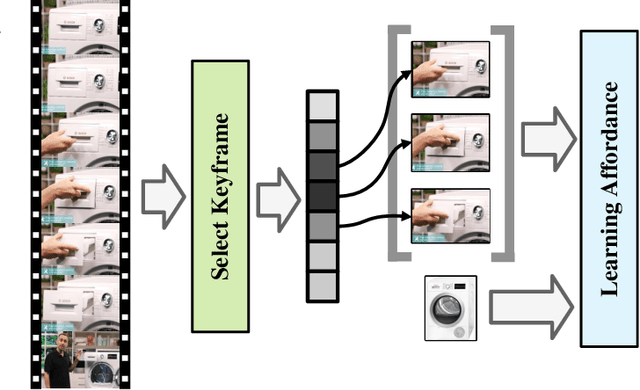
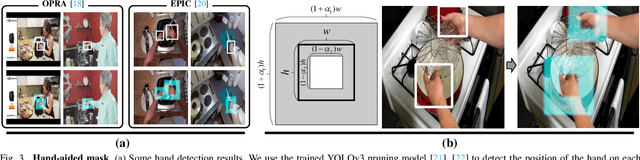
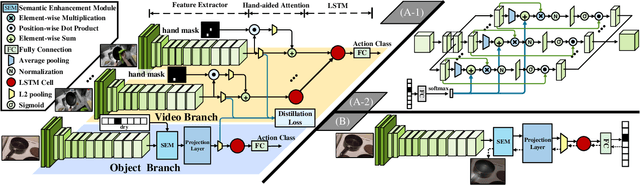
Visual affordance grounding aims to segment all possible interaction regions between people and objects from an image/video, which is beneficial for many applications, such as robot grasping and action recognition. However, existing methods mainly rely on the appearance feature of the objects to segment each region of the image, which face the following two problems: (i) there are multiple possible regions in an object that people interact with; and (ii) there are multiple possible human interactions in the same object region. To address these problems, we propose a Hand-aided Affordance Grounding Network (HAGNet) that leverages the aided clues provided by the position and action of the hand in demonstration videos to eliminate the multiple possibilities and better locate the interaction regions in the object. Specifically, HAG-Net has a dual-branch structure to process the demonstration video and object image. For the video branch, we introduce hand-aided attention to enhance the region around the hand in each video frame and then use the LSTM network to aggregate the action features. For the object branch, we introduce a semantic enhancement module (SEM) to make the network focus on different parts of the object according to the action classes and utilize a distillation loss to align the output features of the object branch with that of the video branch and transfer the knowledge in the video branch to the object branch. Quantitative and qualitative evaluations on two challenging datasets show that our method has achieved stateof-the-art results for affordance grounding. The source code will be made available to the public.
Learning Statistical Representation with Joint Deep Embedded Clustering
Sep 11, 2021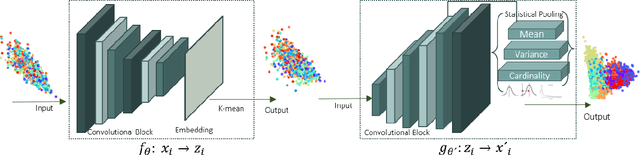
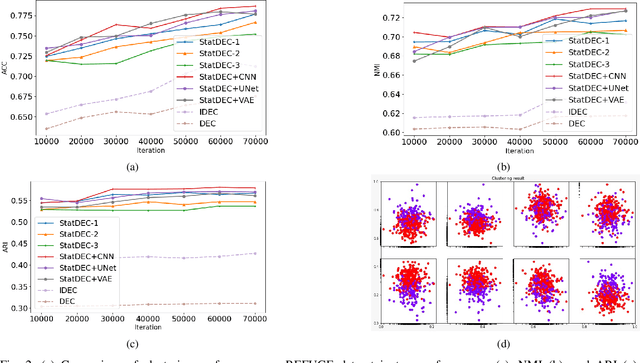
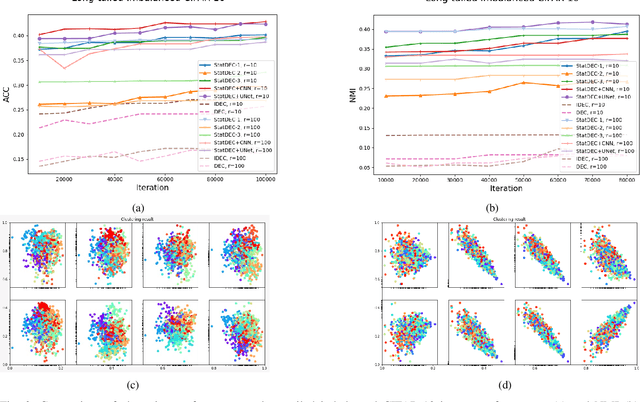
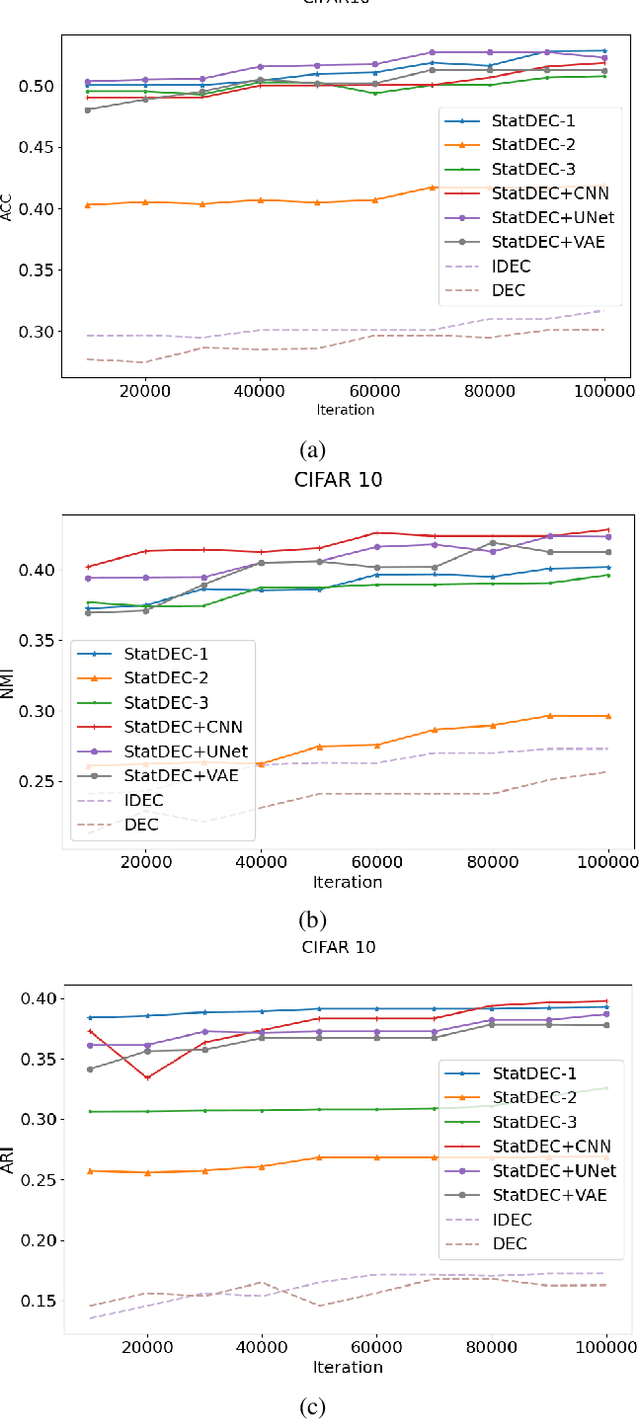
One of the most promising approaches for unsupervised learning is combining deep representation learning and deep clustering. Some recent works propose to simultaneously learn representation using deep neural networks and perform clustering by defining a clustering loss on top of embedded features. However, these approaches are sensitive to imbalanced data and out-of-distribution samples. Hence, these methods optimize clustering by pushing data close to randomly initialized cluster centers. This is problematic when the number of instances varies largely in different classes or a cluster with few samples has less chance to be assigned a good centroid. To overcome these limitations, we introduce StatDEC, a new unsupervised framework for joint statistical representation learning and clustering. StatDEC simultaneously trains two deep learning models, a deep statistics network that captures the data distribution, and a deep clustering network that learns embedded features and performs clustering by explicitly defining a clustering loss. Specifically, the clustering network and representation network both take advantage of our proposed statistics pooling layer that represents mean, variance, and cardinality to handle the out-of-distribution samples as well as a class imbalance. Our experiments show that using these representations, one can considerably improve results on imbalanced image clustering across a variety of image datasets. Moreover, the learned representations generalize well when transferred to the out-of-distribution dataset.
Validating uncertainty in medical image translation
Feb 11, 2020
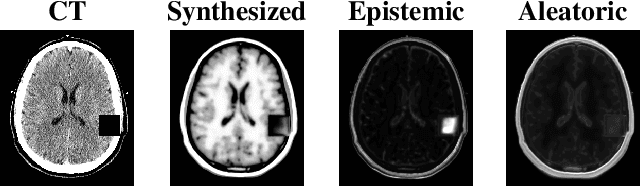
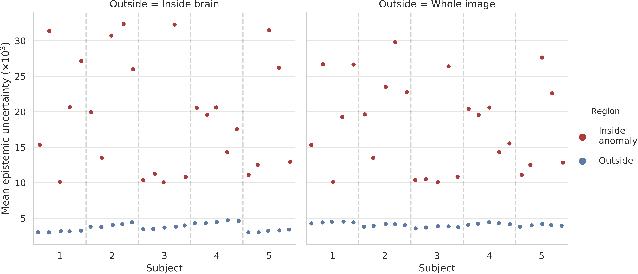
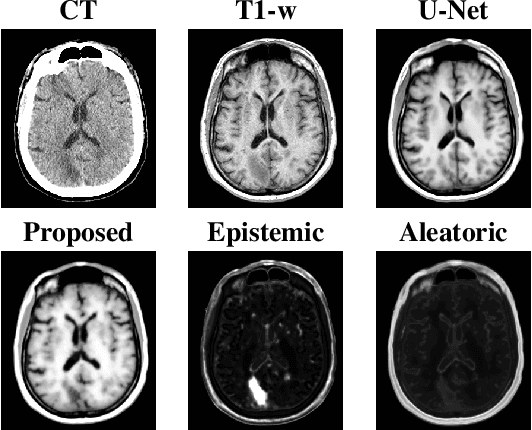
Medical images are increasingly used as input to deep neural networks to produce quantitative values that aid researchers and clinicians. However, standard deep neural networks do not provide a reliable measure of uncertainty in those quantitative values. Recent work has shown that using dropout during training and testing can provide estimates of uncertainty. In this work, we investigate using dropout to estimate epistemic and aleatoric uncertainty in a CT-to-MR image translation task. We show that both types of uncertainty are captured, as defined, providing confidence in the output uncertainty estimates.
Multiclass Wound Image Classification using an Ensemble Deep CNN-based Classifier
Oct 19, 2020
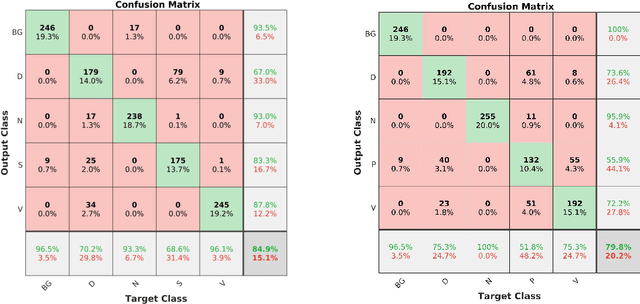
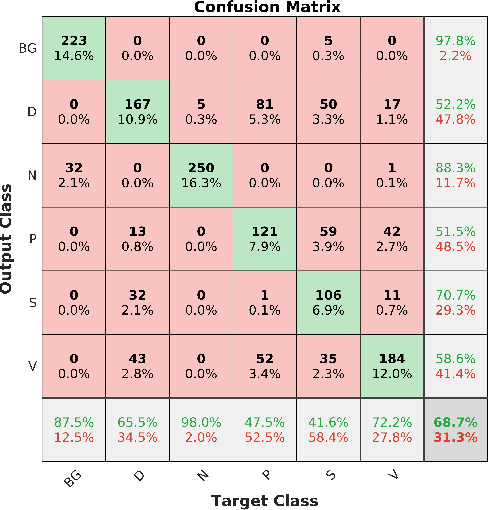
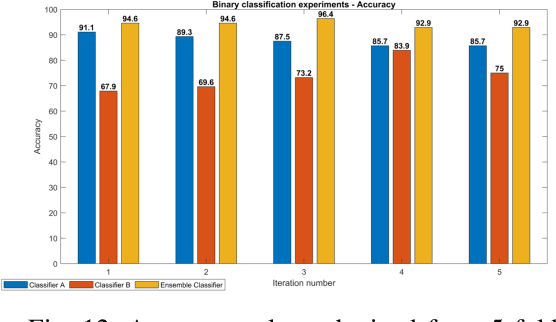
Acute and chronic wounds are a challenge to healthcare systems around the world and affect many people's lives annually. Wound classification is a key step in wound diagnosis that would help clinicians to identify an optimal treatment procedure. Hence, having a high-performance classifier assists the specialists in the field to classify the wounds with less financial and time costs. Different machine learning and deep learning-based wound classification methods have been proposed in the literature. In this study, we have developed an ensemble Deep Convolutional Neural Network-based classifier to classify wound images including surgical, diabetic, and venous ulcers, into multi-classes. The output classification scores of two classifiers (patch-wise and image-wise) are fed into a Multi-Layer Perceptron to provide a superior classification performance. A 5-fold cross-validation approach is used to evaluate the proposed method. We obtained maximum and average classification accuracy values of 96.4% and 94.28% for binary and 91.9\% and 87.7\% for 3-class classification problems. The results show that our proposed method can be used effectively as a decision support system in classification of wound images or other related clinical applications.
Bird's-Eye-View Panoptic Segmentation Using Monocular Frontal View Images
Aug 06, 2021
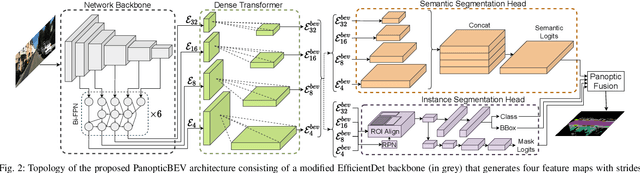
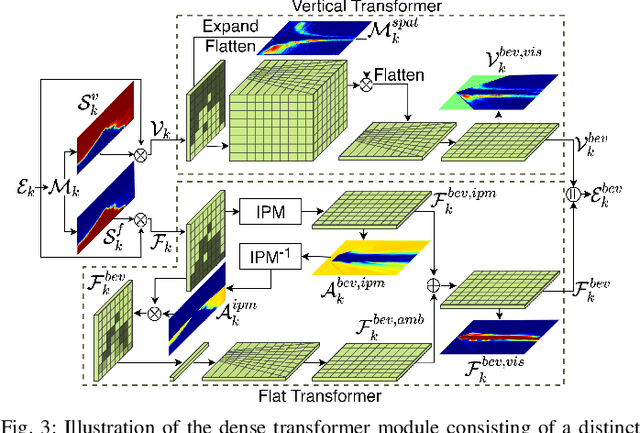
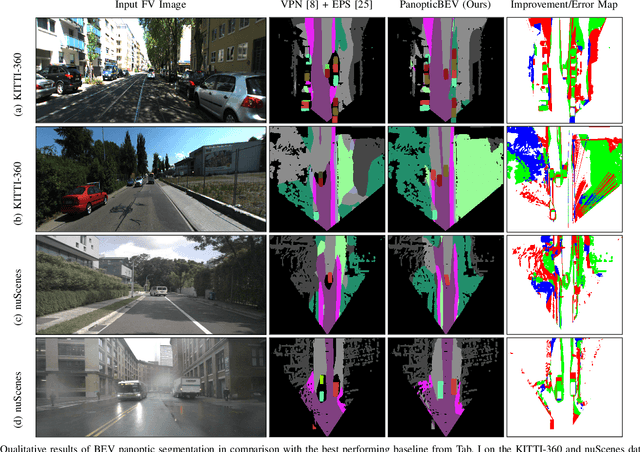
Bird's-Eye-View (BEV) maps have emerged as one of the most powerful representations for scene understanding due to their ability to provide rich spatial context while being easy to interpret and process. However, generating BEV maps requires complex multi-stage paradigms that encapsulate a series of distinct tasks such as depth estimation, ground plane estimation, and semantic segmentation. These sub-tasks are often learned in a disjoint manner which prevents the model from holistic reasoning and results in erroneous BEV maps. Moreover, existing algorithms only predict the semantics in the BEV space, which limits their use in applications where the notion of object instances is critical. In this work, we present the first end-to-end learning approach for directly predicting dense panoptic segmentation maps in the BEV, given a single monocular image in the frontal view (FV). Our architecture follows the top-down paradigm and incorporates a novel dense transformer module consisting of two distinct transformers that learn to independently map vertical and flat regions in the input image from the FV to the BEV. Additionally, we derive a mathematical formulation for the sensitivity of the FV-BEV transformation which allows us to intelligently weight pixels in the BEV space to account for the varying descriptiveness across the FV image. Extensive evaluations on the KITTI-360 and nuScenes datasets demonstrate that our approach exceeds the state-of-the-art in the PQ metric by 3.61 pp and 4.93 pp respectively.
Can neural networks predict dynamics they have never seen?
Nov 12, 2021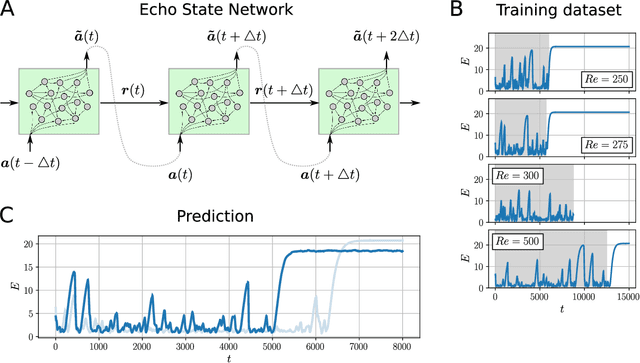
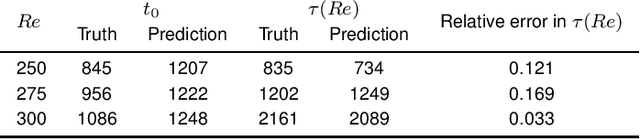
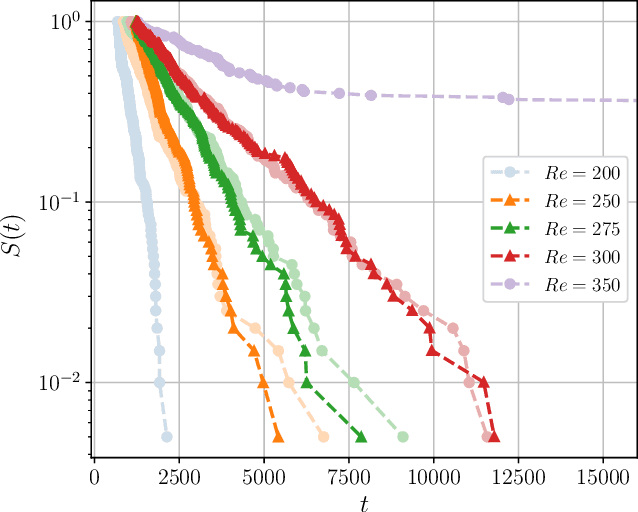
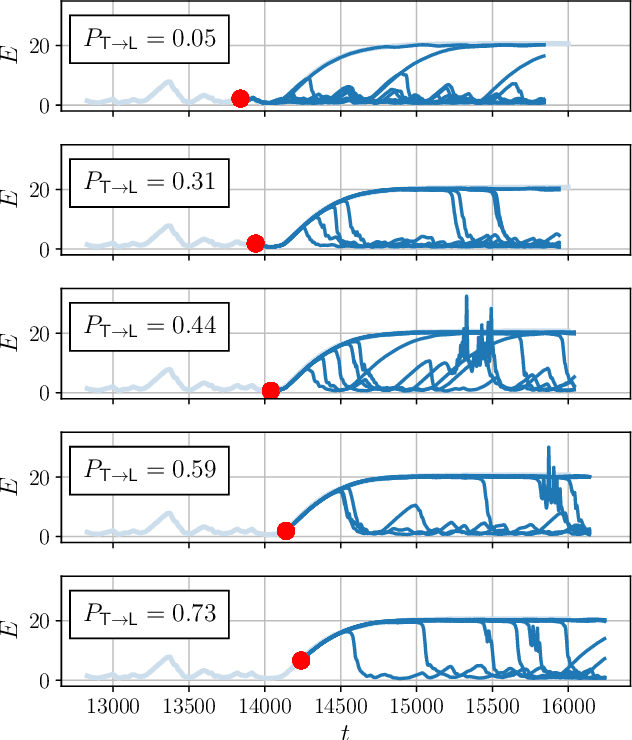
Neural networks have proven to be remarkably successful for a wide range of complicated tasks, from image recognition and object detection to speech recognition and machine translation. One of their successes is the skill in prediction of future dynamics given a suitable training set of data. Previous studies have shown how Echo State Networks (ESNs), a subset of Recurrent Neural Networks, can successfully predict even chaotic systems for times longer than the Lyapunov time. This study shows that, remarkably, ESNs can successfully predict dynamical behavior that is qualitatively different from any behavior contained in the training set. Evidence is provided for a fluid dynamics problem where the flow can transition between laminar (ordered) and turbulent (disordered) regimes. Despite being trained on the turbulent regime only, ESNs are found to predict laminar behavior. Moreover, the statistics of turbulent-to-laminar and laminar-to-turbulent transitions are also predicted successfully, and the utility of ESNs in acting as an early-warning system for transition is discussed. These results are expected to be widely applicable to data-driven modelling of temporal behaviour in a range of physical, climate, biological, ecological and finance models characterized by the presence of tipping points and sudden transitions between several competing states.
LayoutLM: Pre-training of Text and Layout for Document Image Understanding
Dec 31, 2019
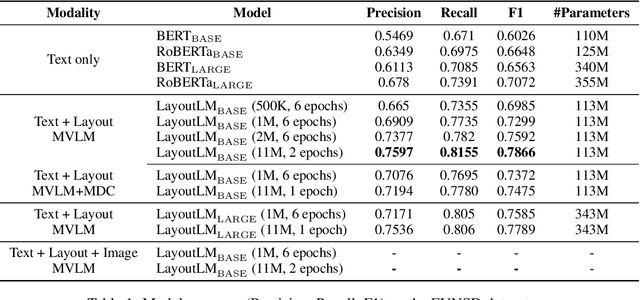
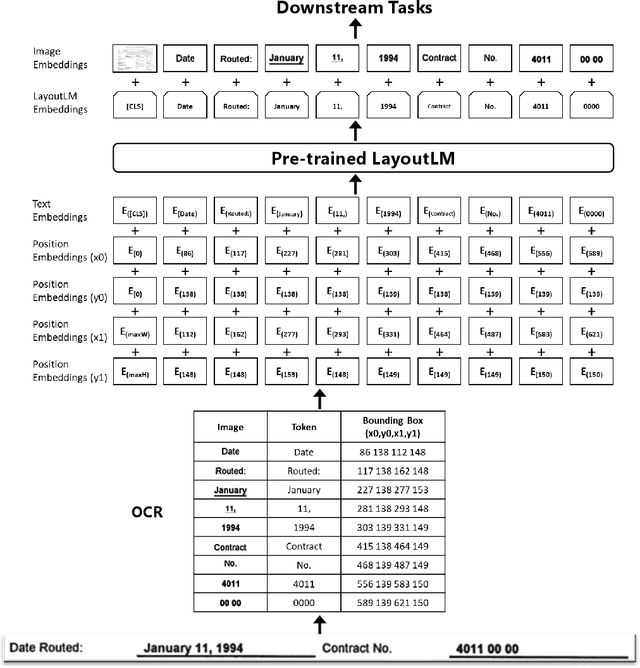
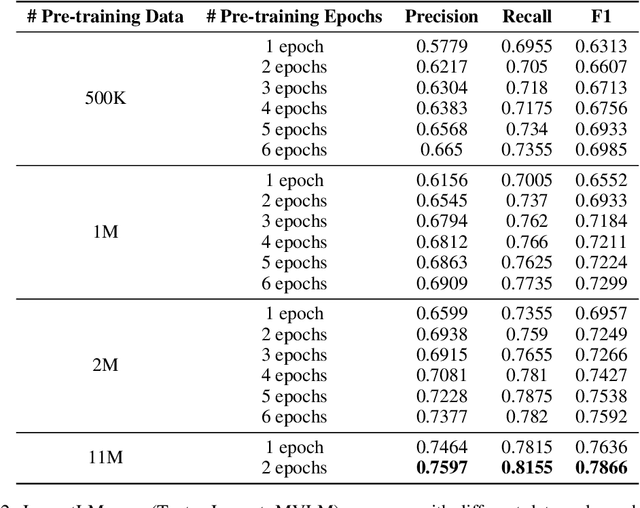
Pre-training techniques have been verified successfully in a variety of NLP tasks in recent years. Despite the wide spread of pre-training models for NLP applications, they almost focused on text-level manipulation, while neglecting the layout and style information that is vital for document image understanding. In this paper, we propose \textbf{LayoutLM} to jointly model the interaction between text and layout information across scanned document images, which is beneficial for a great number of real-world document image understanding tasks such as information extraction from scanned documents. We also leverage the image features to incorporate the style information of words in LayoutLM. To the best of our knowledge, this is the first time that text and layout are jointly learned in a single framework for document-level pre-training, leading to significant performance improvement in downstream tasks for document image understanding.