 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
EvDistill: Asynchronous Events to End-task Learning via Bidirectional Reconstruction-guided Cross-modal Knowledge Distillation
Nov 24, 2021
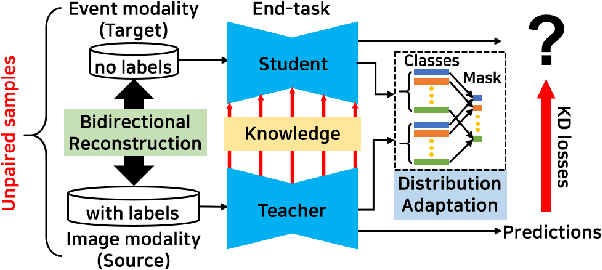
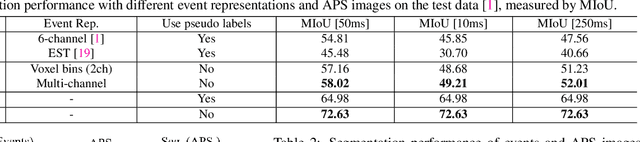
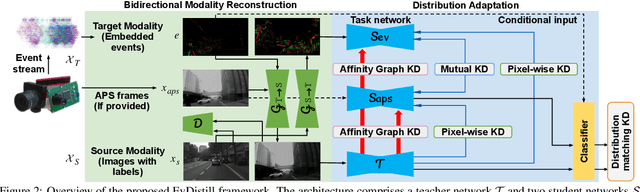

Event cameras sense per-pixel intensity changes and produce asynchronous event streams with high dynamic range and less motion blur, showing advantages over conventional cameras. A hurdle of training event-based models is the lack of large qualitative labeled data. Prior works learning end-tasks mostly rely on labeled or pseudo-labeled datasets obtained from the active pixel sensor (APS) frames; however, such datasets' quality is far from rivaling those based on the canonical images. In this paper, we propose a novel approach, called \textbf{EvDistill}, to learn a student network on the unlabeled and unpaired event data (target modality) via knowledge distillation (KD) from a teacher network trained with large-scale, labeled image data (source modality). To enable KD across the unpaired modalities, we first propose a bidirectional modality reconstruction (BMR) module to bridge both modalities and simultaneously exploit them to distill knowledge via the crafted pairs, causing no extra computation in the inference. The BMR is improved by the end-tasks and KD losses in an end-to-end manner. Second, we leverage the structural similarities of both modalities and adapt the knowledge by matching their distributions. Moreover, as most prior feature KD methods are uni-modality and less applicable to our problem, we propose to leverage an affinity graph KD loss to boost the distillation. Our extensive experiments on semantic segmentation and object recognition demonstrate that EvDistill achieves significantly better results than the prior works and KD with only events and APS frames.
Meta-Learning Sparse Implicit Neural Representations
Nov 07, 2021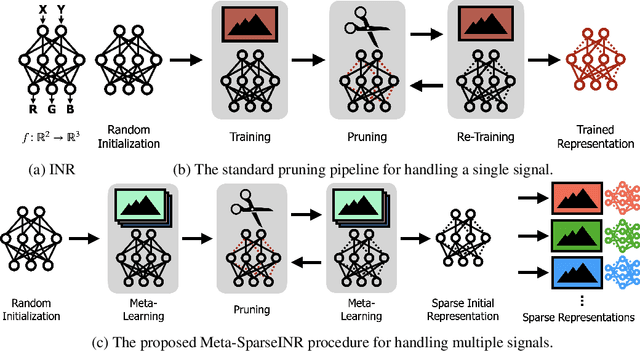

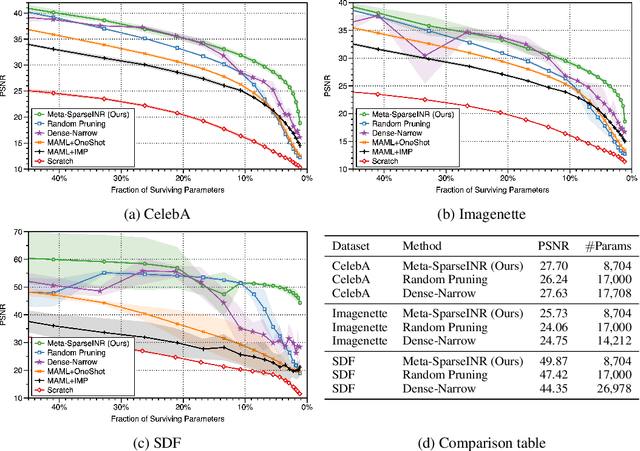
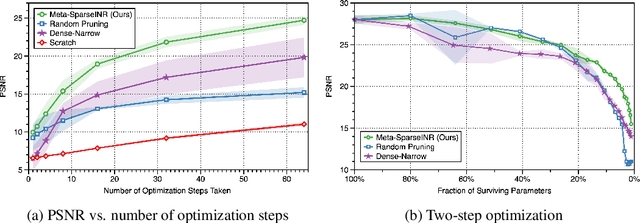
Implicit neural representations are a promising new avenue of representing general signals by learning a continuous function that, parameterized as a neural network, maps the domain of a signal to its codomain; the mapping from spatial coordinates of an image to its pixel values, for example. Being capable of conveying fine details in a high dimensional signal, unboundedly of its domain, implicit neural representations ensure many advantages over conventional discrete representations. However, the current approach is difficult to scale for a large number of signals or a data set, since learning a neural representation -- which is parameter heavy by itself -- for each signal individually requires a lot of memory and computations. To address this issue, we propose to leverage a meta-learning approach in combination with network compression under a sparsity constraint, such that it renders a well-initialized sparse parameterization that evolves quickly to represent a set of unseen signals in the subsequent training. We empirically demonstrate that meta-learned sparse neural representations achieve a much smaller loss than dense meta-learned models with the same number of parameters, when trained to fit each signal using the same number of optimization steps.
MUSE: Feature Self-Distillation with Mutual Information and Self-Information
Oct 25, 2021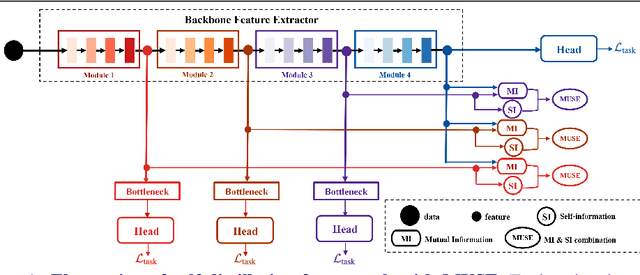
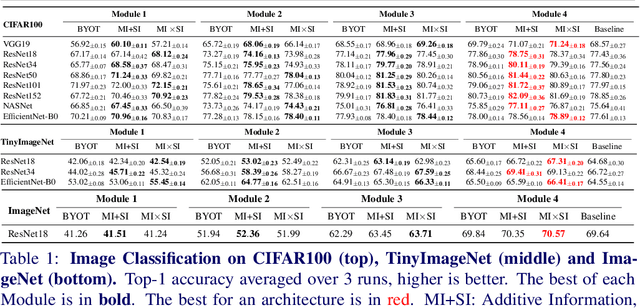

We present a novel information-theoretic approach to introduce dependency among features of a deep convolutional neural network (CNN). The core idea of our proposed method, called MUSE, is to combine MUtual information and SElf-information to jointly improve the expressivity of all features extracted from different layers in a CNN. We present two variants of the realization of MUSE -- Additive Information and Multiplicative Information. Importantly, we argue and empirically demonstrate that MUSE, compared to other feature discrepancy functions, is a more functional proxy to introduce dependency and effectively improve the expressivity of all features in the knowledge distillation framework. MUSE achieves superior performance over a variety of popular architectures and feature discrepancy functions for self-distillation and online distillation, and performs competitively with the state-of-the-art methods for offline distillation. MUSE is also demonstrably versatile that enables it to be easily extended to CNN-based models on tasks other than image classification such as object detection.
Cycle-IR: Deep Cyclic Image Retargeting
May 09, 2019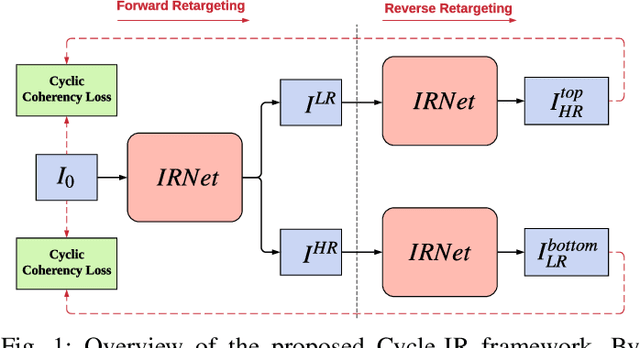



Supervised deep learning techniques have achieved great success in various fields due to getting rid of the limitation of handcrafted representations. However, most previous image retargeting algorithms still employ fixed design principles such as using gradient map or handcrafted features to compute saliency map, which inevitably restricts its generality. Deep learning techniques may help to address this issue, but the challenging problem is that we need to build a large-scale image retargeting dataset for the training of deep retargeting models. However, building such a dataset requires huge human efforts. In this paper, we propose a novel deep cyclic image retargeting approach, called Cycle-IR, to firstly implement image retargeting with a single deep model, without relying on any explicit user annotations. Our idea is built on the reverse mapping from the retargeted images to the given input images. If the retargeted image has serious distortion or excessive loss of important visual information, the reverse mapping is unlikely to restore the input image well. We constrain this forward-reverse consistency by introducing a cyclic perception coherence loss. In addition, we propose a simple yet effective image retargeting network (IRNet) to implement the image retargeting process. Our IRNet contains a spatial and channel attention layer, which is able to discriminate visually important regions of input images effectively, especially in cluttered images. Given arbitrary sizes of input images and desired aspect ratios, our Cycle-IR can produce visually pleasing target images directly. Extensive experiments on the standard RetargetMe dataset show the superiority of our Cycle-IR. In addition, our Cycle-IR outperforms the Multiop method and obtains the best result in the user study. Code is available at https://github.com/mintanwei/Cycle-IR.
Learning Stixel-based Instance Segmentation
Jul 07, 2021
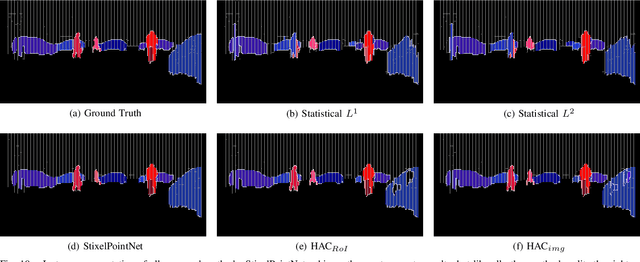
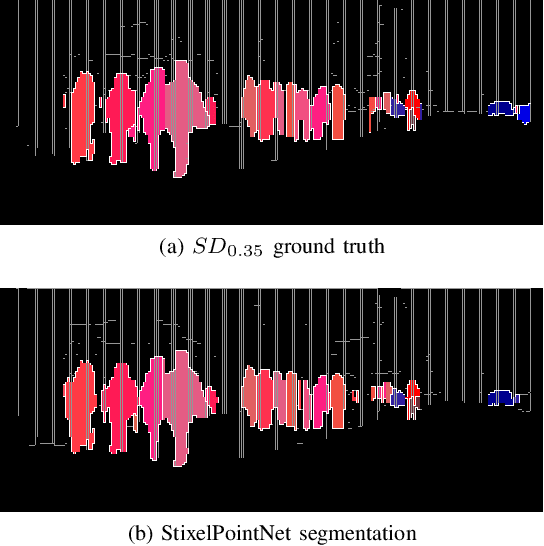
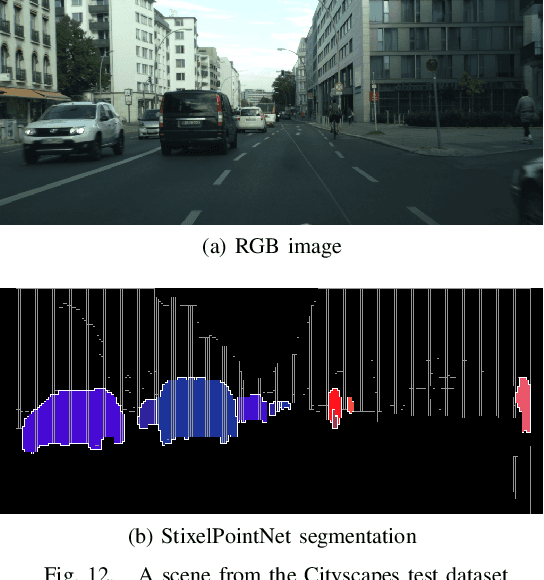
Stixels have been successfully applied to a wide range of vision tasks in autonomous driving, recently including instance segmentation. However, due to their sparse occurrence in the image, until now Stixels seldomly served as input for Deep Learning algorithms, restricting their utility for such approaches. In this work we present StixelPointNet, a novel method to perform fast instance segmentation directly on Stixels. By regarding the Stixel representation as unstructured data similar to point clouds, architectures like PointNet are able to learn features from Stixels. We use a bounding box detector to propose candidate instances, for which the relevant Stixels are extracted from the input image. On these Stixels, a PointNet models learns binary segmentations, which we then unify throughout the whole image in a final selection step. StixelPointNet achieves state-of-the-art performance on Stixel-level, is considerably faster than pixel-based segmentation methods, and shows that with our approach the Stixel domain can be introduced to many new 3D Deep Learning tasks.
Text-to-Image Synthesis Based on Machine Generated Captions
Oct 09, 2019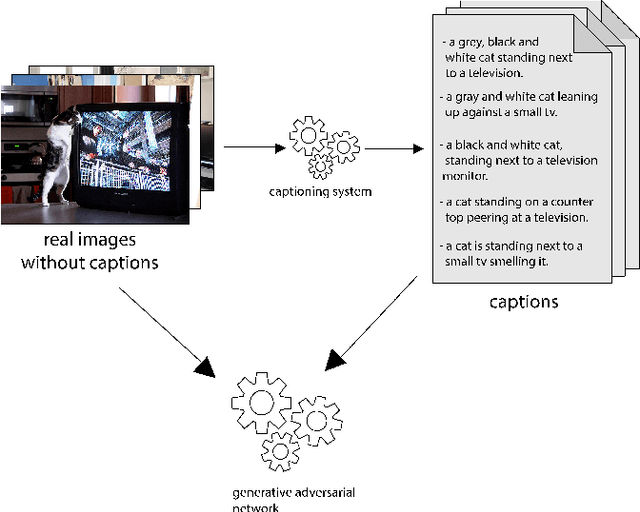
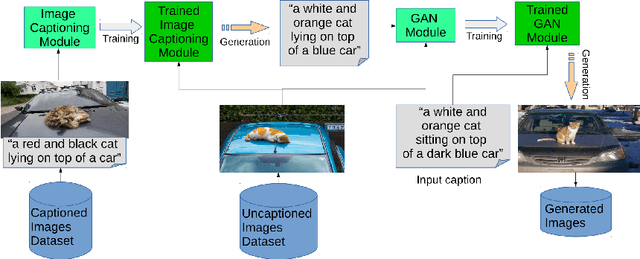


Text to Image Synthesis refers to the process of automatic generation of a photo-realistic image starting from a given text and is revolutionizing many real-world applications. In order to perform such process it is necessary to exploit datasets containing captioned images, meaning that each image is associated with one (or more) captions describing it. Despite the abundance of uncaptioned images datasets, the number of captioned datasets is limited. To address this issue, in this paper we propose an approach capable of generating images starting from a given text using conditional GANs trained on uncaptioned images dataset. In particular, uncaptioned images are fed to an Image Captioning Module to generate the descriptions. Then, the GAN Module is trained on both the input image and the machine-generated caption. To evaluate the results, the performance of our solution is compared with the results obtained by the unconditional GAN. For the experiments, we chose to use the uncaptioned dataset LSUN bedroom. The results obtained in our study are preliminary but still promising.
Light Lies: Optical Adversarial Attack
Jun 18, 2021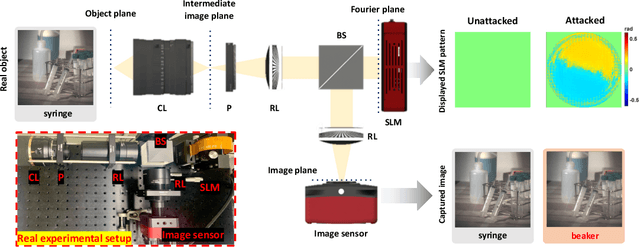

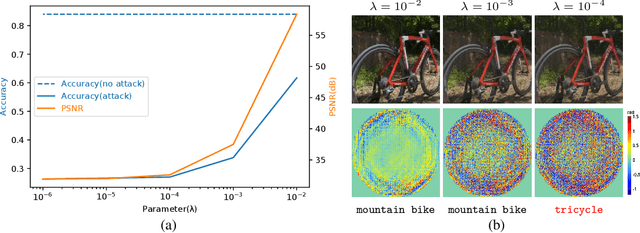
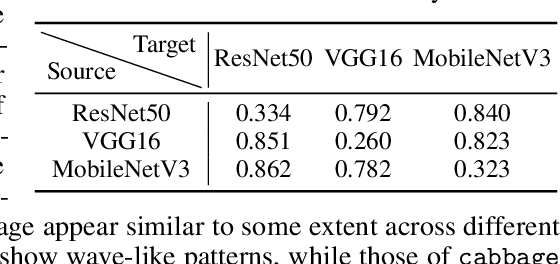
A significant amount of work has been done on adversarial attacks that inject imperceptible noise to images to deteriorate the image classification performance of deep models. However, most of the existing studies consider attacks in the digital (pixel) domain where an image acquired by an image sensor with sampling and quantization has been recorded. This paper, for the first time, introduces an optical adversarial attack, which physically alters the light field information arriving at the image sensor so that the classification model yields misclassification. More specifically, we modulate the phase of the light in the Fourier domain using a spatial light modulator placed in the photographic system. The operative parameters of the modulator are obtained by gradient-based optimization to maximize cross-entropy and minimize distortions. We present experiments based on both simulation and a real hardware optical system, from which the feasibility of the proposed optical attack is demonstrated. It is also verified that the proposed attack is completely different from common optical-domain distortions such as spherical aberration, defocus, and astigmatism in terms of both perturbation patterns and classification results.
Semantic Image Completion and Enhancement using Deep Learning
Nov 06, 2019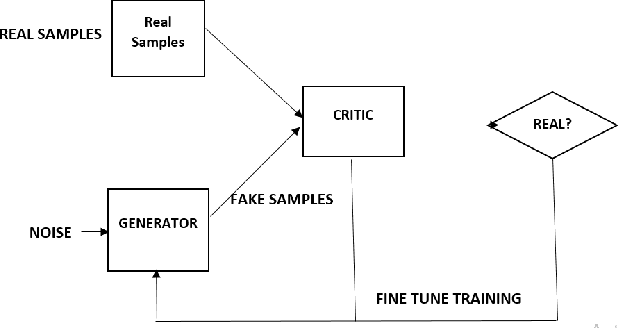
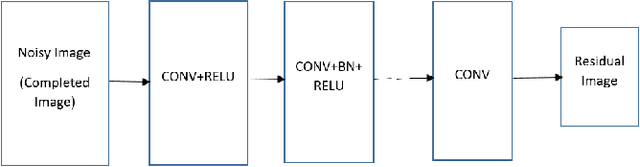
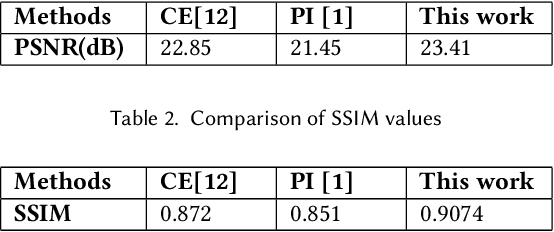
In real-life applications, certain images utilized are corrupted in which the image pixels are damaged or missing, which increases the complexity of computer vision tasks. In this paper, a deep learning architecture is proposed to deal with image completion and enhancement. Generative Adversarial Networks (GAN), has been turned out to be helpful in picture completion tasks. Therefore, in GANs, Wasserstein GAN architecture is used for image completion which creates the coarse patches to filling the missing region in the distorted picture, and the enhancement network will additionally refine the resultant pictures utilizing residual learning procedures and hence give better complete pictures for computer vision applications. Experimental outcomes show that the proposed approach improves the Peak Signal to Noise ratio and Structural Similarity Index values by 2.45% and 4% respectively when compared to the recently reported data.
Black-Box Test-Time Shape REFINEment for Single View 3D Reconstruction
Aug 23, 2021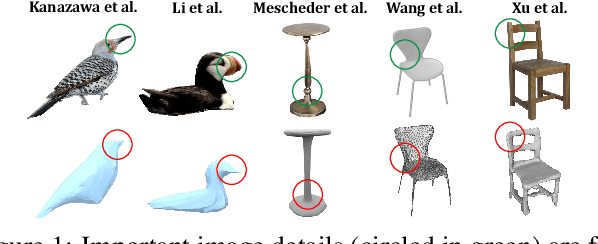
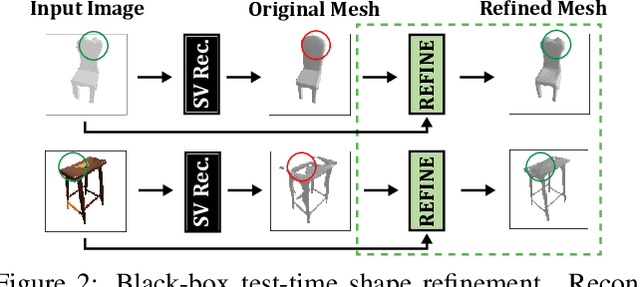
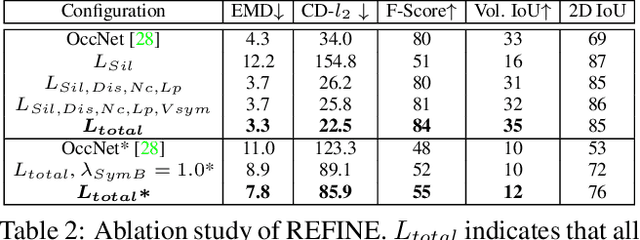
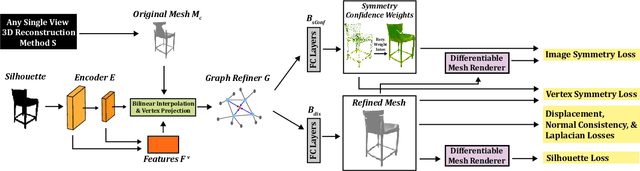
Much recent progress has been made in reconstructing the 3D shape of an object from an image of it, i.e. single view 3D reconstruction. However, it has been suggested that current methods simply adopt a "nearest-neighbor" strategy, instead of genuinely understanding the shape behind the input image. In this paper, we rigorously show that for many state of the art methods, this issue manifests as (1) inconsistencies between coarse reconstructions and input images, and (2) inability to generalize across domains. We thus propose REFINE, a postprocessing mesh refinement step that can be easily integrated into the pipeline of any black-box method in the literature. At test time, REFINE optimizes a network per mesh instance, to encourage consistency between the mesh and the given object view. This, along with a novel combination of regularizing losses, reduces the domain gap and achieves state of the art performance. We believe that this novel paradigm is an important step towards robust, accurate reconstructions, remaining relevant as new reconstruction networks are introduced.
Edge AI without Compromise: Efficient, Versatile and Accurate Neurocomputing in Resistive Random-Access Memory
Aug 17, 2021
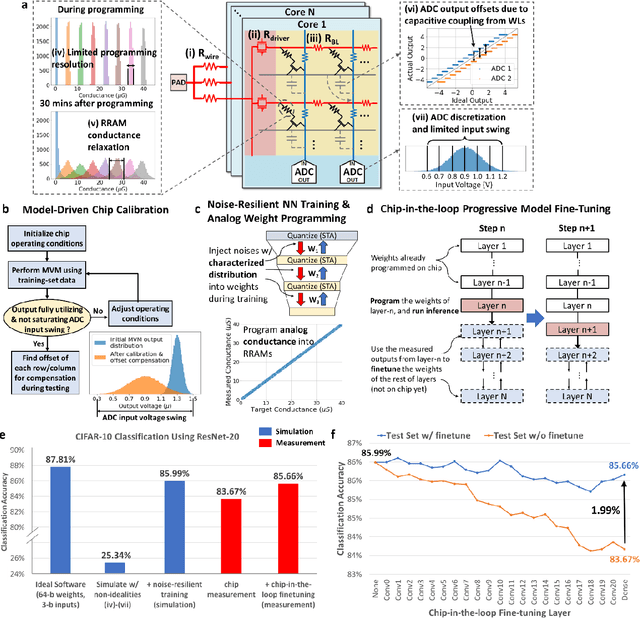
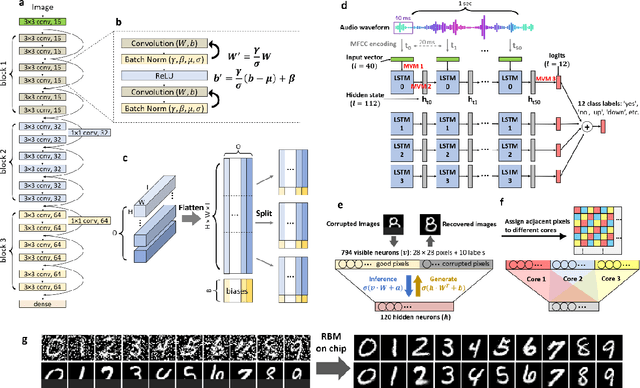
Realizing today's cloud-level artificial intelligence functionalities directly on devices distributed at the edge of the internet calls for edge hardware capable of processing multiple modalities of sensory data (e.g. video, audio) at unprecedented energy-efficiency. AI hardware architectures today cannot meet the demand due to a fundamental "memory wall": data movement between separate compute and memory units consumes large energy and incurs long latency. Resistive random-access memory (RRAM) based compute-in-memory (CIM) architectures promise to bring orders of magnitude energy-efficiency improvement by performing computation directly within memory. However, conventional approaches to CIM hardware design limit its functional flexibility necessary for processing diverse AI workloads, and must overcome hardware imperfections that degrade inference accuracy. Such trade-offs between efficiency, versatility and accuracy cannot be addressed by isolated improvements on any single level of the design. By co-optimizing across all hierarchies of the design from algorithms and architecture to circuits and devices, we present NeuRRAM - the first multimodal edge AI chip using RRAM CIM to simultaneously deliver a high degree of versatility for diverse model architectures, record energy-efficiency $5\times$ - $8\times$ better than prior art across various computational bit-precisions, and inference accuracy comparable to software models with 4-bit weights on all measured standard AI benchmarks including accuracy of 99.0% on MNIST and 85.7% on CIFAR-10 image classification, 84.7% accuracy on Google speech command recognition, and a 70% reduction in image reconstruction error on a Bayesian image recovery task. This work paves a way towards building highly efficient and reconfigurable edge AI hardware platforms for the more demanding and heterogeneous AI applications of the future.