 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Patchy Image Structure Classification Using Multi-Orientation Region Transform
Dec 02, 2019
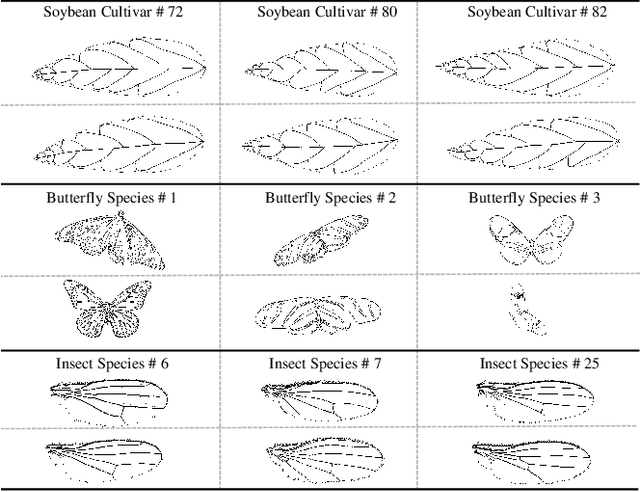
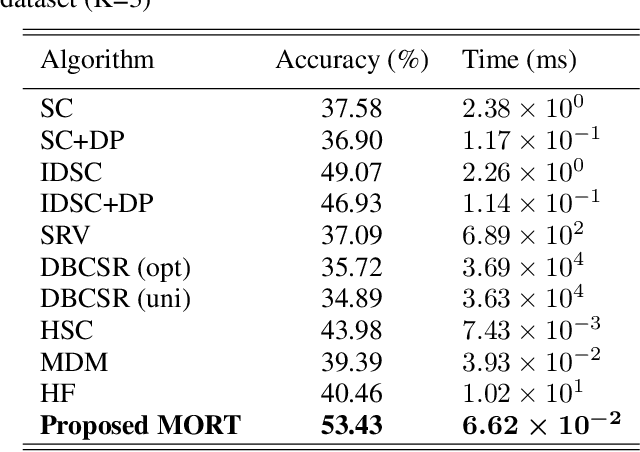


Exterior contour and interior structure are both vital features for classifying objects. However, most of the existing methods consider exterior contour feature and internal structure feature separately, and thus fail to function when classifying patchy image structures that have similar contours and flexible structures. To address above limitations, this paper proposes a novel Multi-Orientation Region Transform (MORT), which can effectively characterize both contour and structure features simultaneously, for patchy image structure classification. MORT is performed over multiple orientation regions at multiple scales to effectively integrate patchy features, and thus enables a better description of the shape in a coarse-to-fine manner. Moreover, the proposed MORT can be extended to combine with the deep convolutional neural network techniques, for further enhancement of classification accuracy. Very encouraging experimental results on the challenging ultra-fine-grained cultivar recognition task, insect wing recognition task, and large variation butterfly recognition task are obtained, which demonstrate the effectiveness and superiority of the proposed MORT over the state-of-the-art methods in classifying patchy image structures. Our code and three patchy image structure datasets are available at: https://github.com/XiaohanYu-GU/MReT2019.
Image Deconvolution via Noise-Tolerant Self-Supervised Inversion
Jun 11, 2020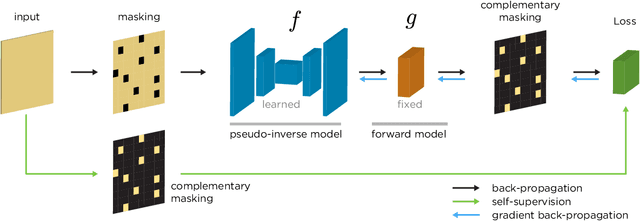
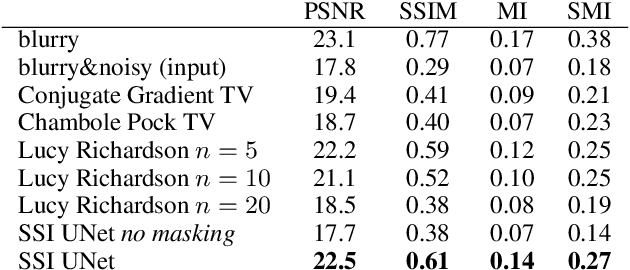
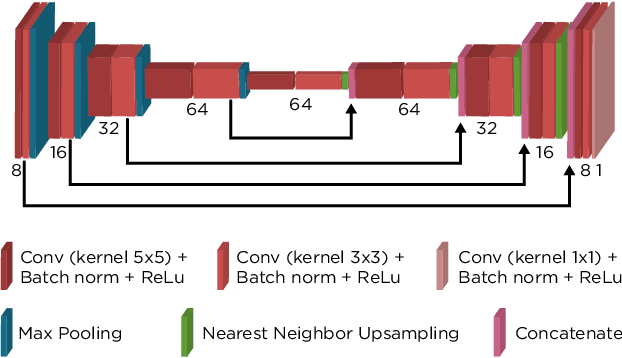
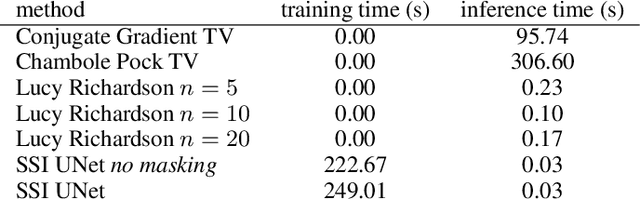
We propose a general framework for solving inverse problems in the presence of noise that requires no signal prior, no noise estimate, and no clean training data. We only require that the forward model be available and that the noise be statistically independent across measurement dimensions. We build upon the theory of $\mathcal{J}$-invariant functions (Batson & Royer 2019, arXiv:1901.11365) and show how self-supervised denoising \emph{\`a la} Noise2Self is a special case of learning a noise-tolerant pseudo-inverse of the identity. We demonstrate our approach by showing how a convolutional neural network can be taught in a self-supervised manner to deconvolve images and surpass in image quality classical inversion schemes such as Lucy-Richardson deconvolution.
DualGAN: Unsupervised Dual Learning for Image-to-Image Translation
Oct 09, 2018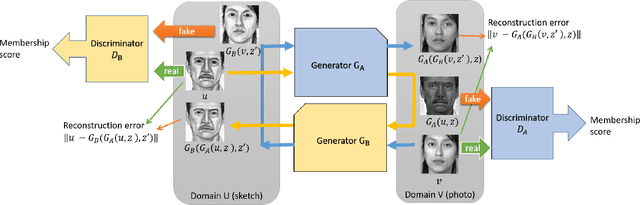
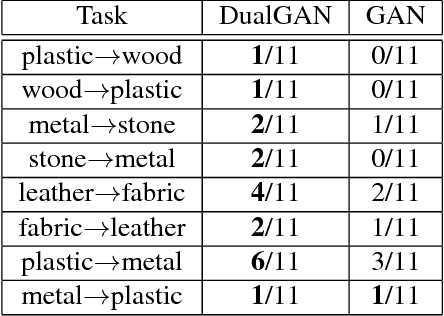

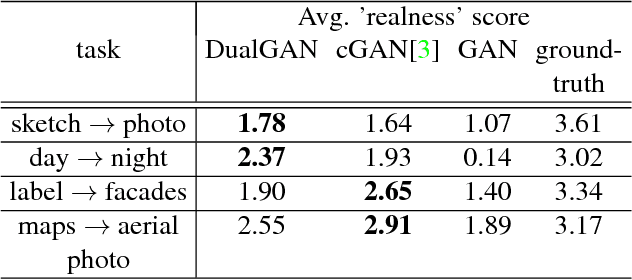
Conditional Generative Adversarial Networks (GANs) for cross-domain image-to-image translation have made much progress recently. Depending on the task complexity, thousands to millions of labeled image pairs are needed to train a conditional GAN. However, human labeling is expensive, even impractical, and large quantities of data may not always be available. Inspired by dual learning from natural language translation, we develop a novel dual-GAN mechanism, which enables image translators to be trained from two sets of unlabeled images from two domains. In our architecture, the primal GAN learns to translate images from domain U to those in domain V, while the dual GAN learns to invert the task. The closed loop made by the primal and dual tasks allows images from either domain to be translated and then reconstructed. Hence a loss function that accounts for the reconstruction error of images can be used to train the translators. Experiments on multiple image translation tasks with unlabeled data show considerable performance gain of DualGAN over a single GAN. For some tasks, DualGAN can even achieve comparable or slightly better results than conditional GAN trained on fully labeled data.
Simulating Realistic MRI variations to Improve Deep Learning model and visual explanations using GradCAM
Nov 01, 2021
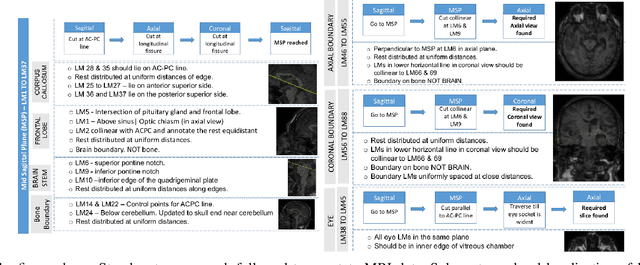
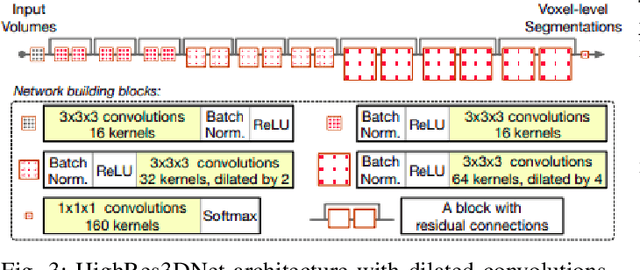
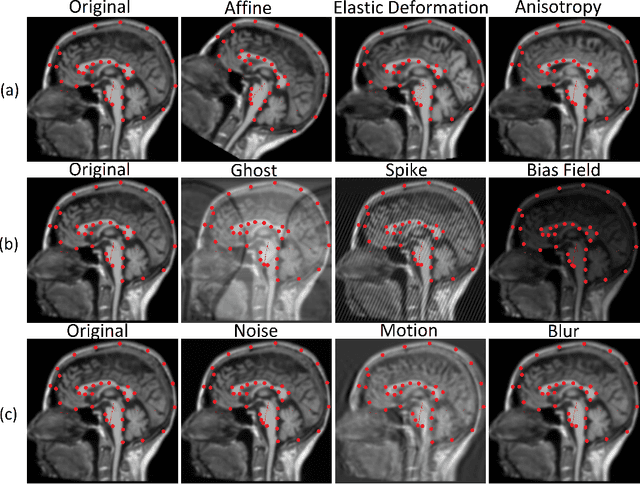
In the medical field, landmark detection in MRI plays an important role in reducing medical technician efforts in tasks like scan planning, image registration, etc. First, 88 landmarks spread across the brain anatomy in the three respective views -- sagittal, coronal, and axial are manually annotated, later guidelines from the expert clinical technicians are taken sub-anatomy-wise, for better localization of the existing landmarks, in order to identify and locate the important atlas landmarks even in oblique scans. To overcome limited data availability, we implement realistic data augmentation to generate synthetic 3D volumetric data. We use a modified HighRes3DNet model for solving brain MRI volumetric landmark detection problem. In order to visually explain our trained model on unseen data, and discern a stronger model from a weaker model, we implement Gradient-weighted Class Activation Mapping (Grad-CAM) which produces a coarse localization map highlighting the regions the model is focusing. Our experiments show that the proposed method shows favorable results, and the overall pipeline can be extended to a variable number of landmarks and other anatomies.
Reasoning Graph Networks for Kinship Verification: from Star-shaped to Hierarchical
Sep 06, 2021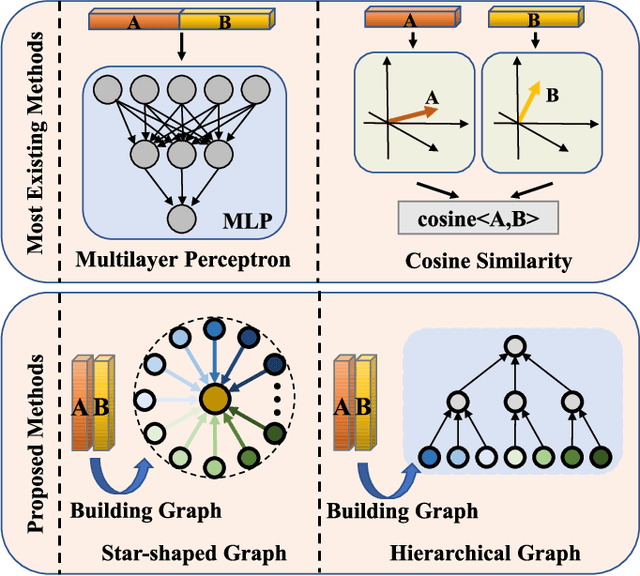
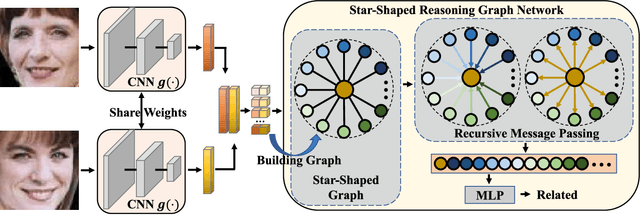

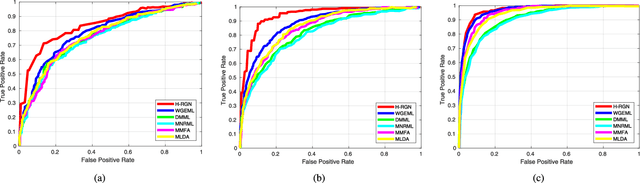
In this paper, we investigate the problem of facial kinship verification by learning hierarchical reasoning graph networks. Conventional methods usually focus on learning discriminative features for each facial image of a paired sample and neglect how to fuse the obtained two facial image features and reason about the relations between them. To address this, we propose a Star-shaped Reasoning Graph Network (S-RGN). Our S-RGN first constructs a star-shaped graph where each surrounding node encodes the information of comparisons in a feature dimension and the central node is employed as the bridge for the interaction of surrounding nodes. Then we perform relational reasoning on this star graph with iterative message passing. The proposed S-RGN uses only one central node to analyze and process information from all surrounding nodes, which limits its reasoning capacity. We further develop a Hierarchical Reasoning Graph Network (H-RGN) to exploit more powerful and flexible capacity. More specifically, our H-RGN introduces a set of latent reasoning nodes and constructs a hierarchical graph with them. Then bottom-up comparative information abstraction and top-down comprehensive signal propagation are iteratively performed on the hierarchical graph to update the node features. Extensive experimental results on four widely used kinship databases show that the proposed methods achieve very competitive results.
* Accepted by IEEE Transactions on Image Processing (TIP)
VIPose: Real-time Visual-Inertial 6D Object Pose Tracking
Jul 27, 2021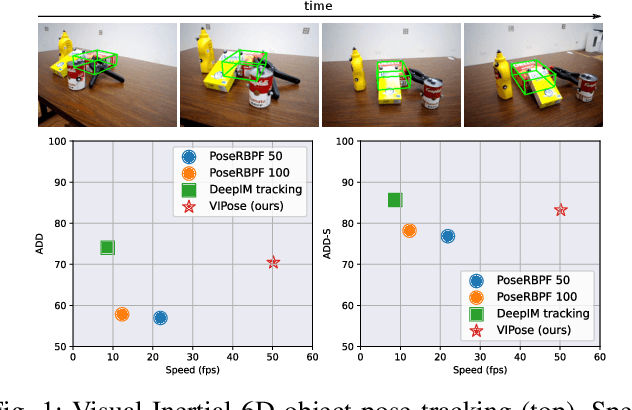
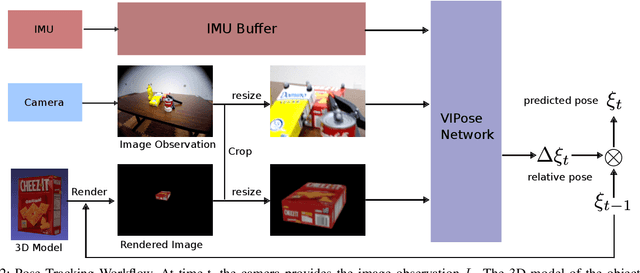
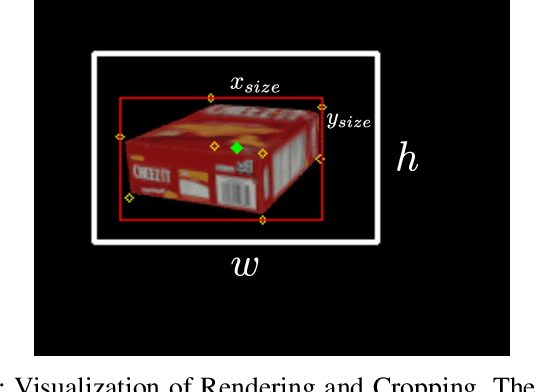

Estimating the 6D pose of objects is beneficial for robotics tasks such as transportation, autonomous navigation, manipulation as well as in scenarios beyond robotics like virtual and augmented reality. With respect to single image pose estimation, pose tracking takes into account the temporal information across multiple frames to overcome possible detection inconsistencies and to improve the pose estimation efficiency. In this work, we introduce a novel Deep Neural Network (DNN) called VIPose, that combines inertial and camera data to address the object pose tracking problem in real-time. The key contribution is the design of a novel DNN architecture which fuses visual and inertial features to predict the objects' relative 6D pose between consecutive image frames. The overall 6D pose is then estimated by consecutively combining relative poses. Our approach shows remarkable pose estimation results for heavily occluded objects that are well known to be very challenging to handle by existing state-of-the-art solutions. The effectiveness of the proposed approach is validated on a new dataset called VIYCB with RGB image, IMU data, and accurate 6D pose annotations created by employing an automated labeling technique. The approach presents accuracy performances comparable to state-of-the-art techniques, but with additional benefit to be real-time.
AdaCon: Adaptive Context-Aware Object Detection for Resource-Constrained Embedded Devices
Aug 16, 2021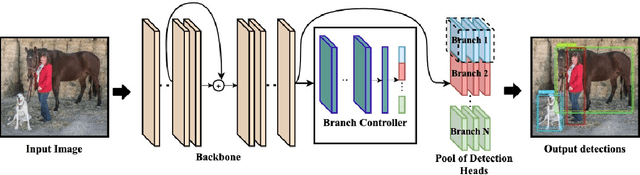
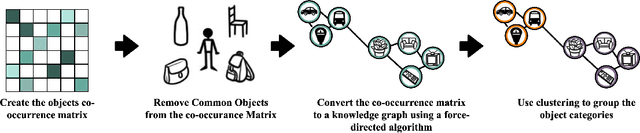
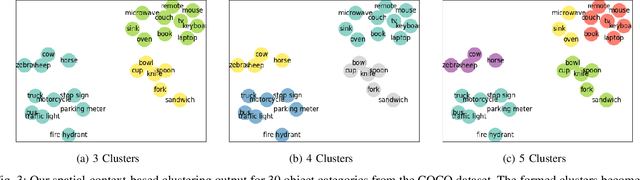
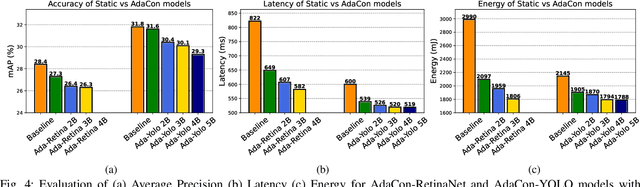
Convolutional Neural Networks achieve state-of-the-art accuracy in object detection tasks. However, they have large computational and energy requirements that challenge their deployment on resource-constrained edge devices. Object detection takes an image as an input, and identifies the existing object classes as well as their locations in the image. In this paper, we leverage the prior knowledge about the probabilities that different object categories can occur jointly to increase the efficiency of object detection models. In particular, our technique clusters the object categories based on their spatial co-occurrence probability. We use those clusters to design an adaptive network. During runtime, a branch controller decides which part(s) of the network to execute based on the spatial context of the input frame. Our experiments using COCO dataset show that our adaptive object detection model achieves up to 45% reduction in the energy consumption, and up to 27% reduction in the latency, with a small loss in the average precision (AP) of object detection.
The state-of-the-art in text-based automatic personality prediction
Oct 04, 2021
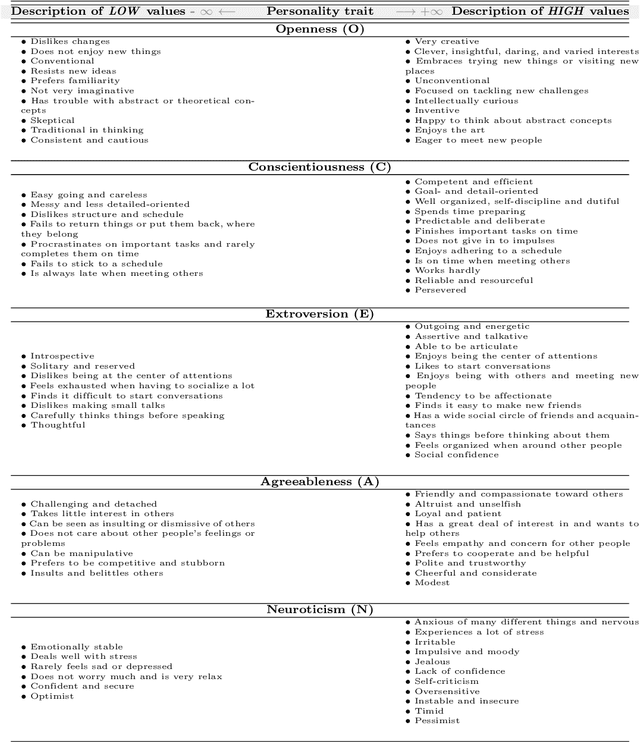
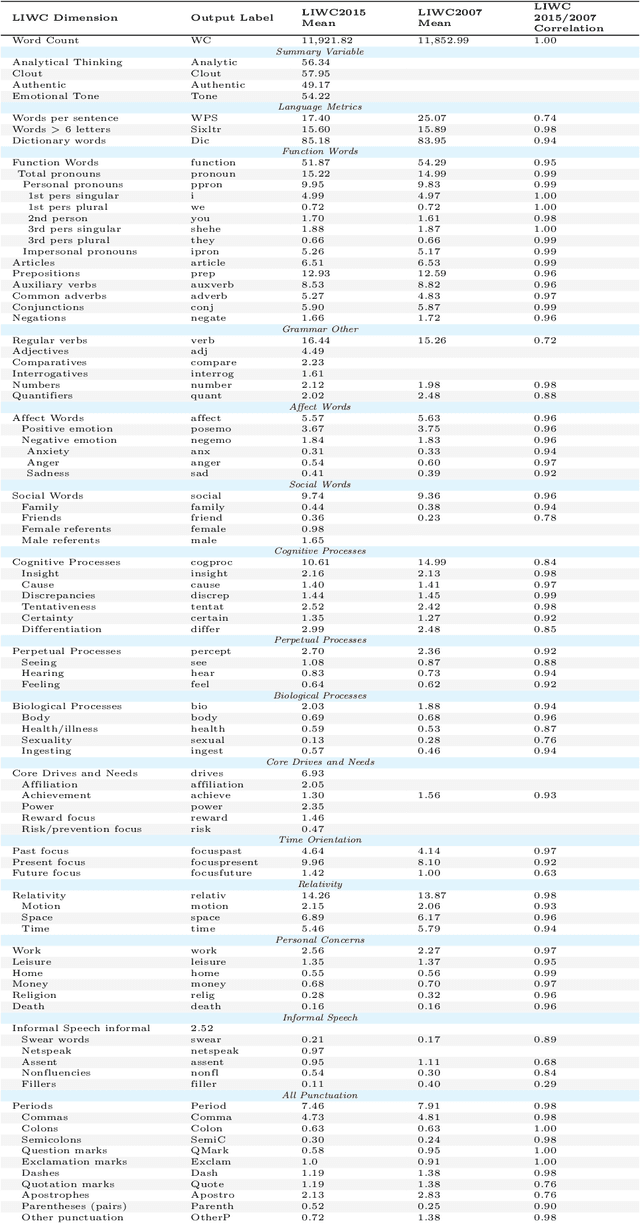
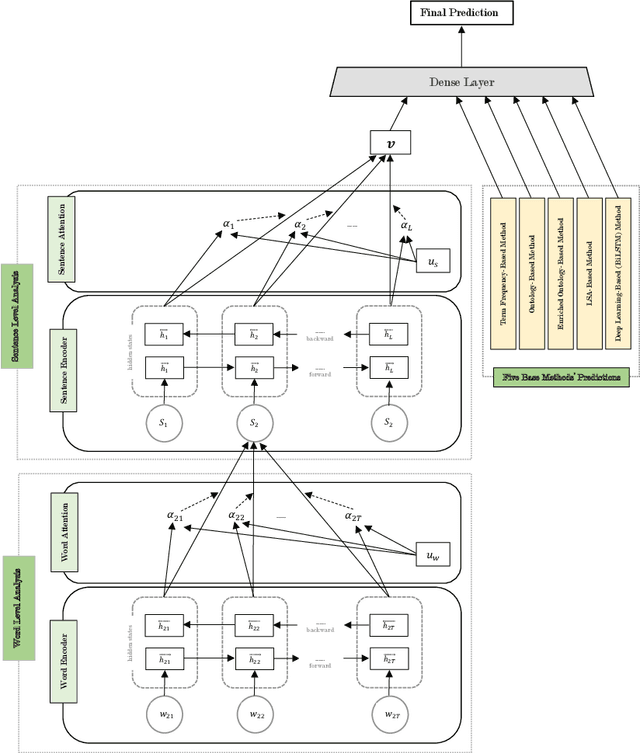
Personality detection is an old topic in psychology and Automatic Personality Prediction (or Perception) (APP) is the automated (computationally) forecasting of the personality on different types of human generated/exchanged contents (such as text, speech, image, video). The principal objective of this study is to offer a shallow (overall) review of natural language processing approaches on APP since 2010. With the advent of deep learning and following it transfer-learning and pre-trained model in NLP, APP research area has been a hot topic, so in this review, methods are categorized into three; pre-trained independent, pre-trained model based, multimodal approaches. Also, to achieve a comprehensive comparison, reported results are informed by datasets.
RAFT-Stereo: Multilevel Recurrent Field Transforms for Stereo Matching
Sep 15, 2021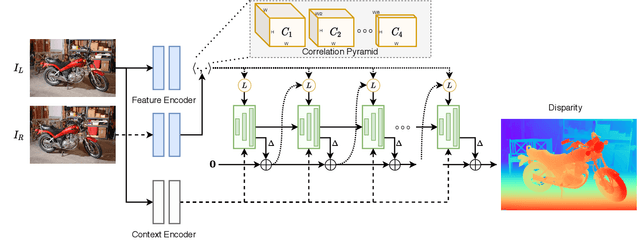
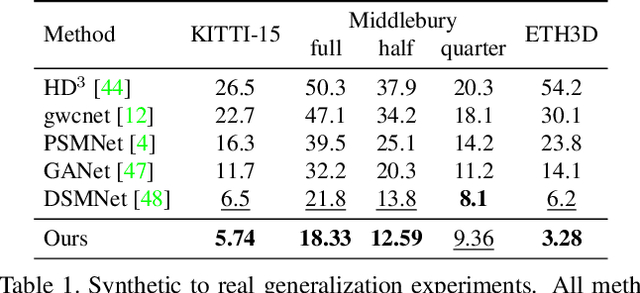
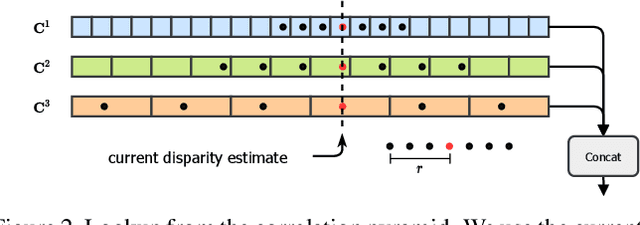
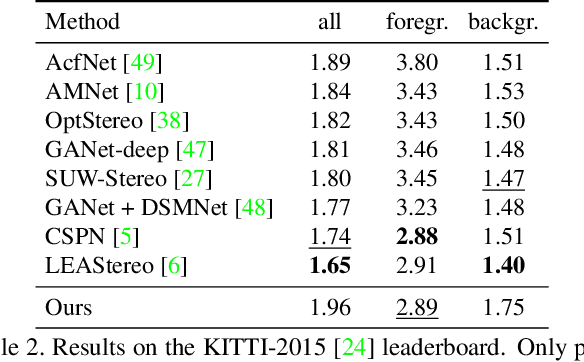
We introduce RAFT-Stereo, a new deep architecture for rectified stereo based on the optical flow network RAFT. We introduce multi-level convolutional GRUs, which more efficiently propagate information across the image. A modified version of RAFT-Stereo can perform accurate real-time inference. RAFT-stereo ranks first on the Middlebury leaderboard, outperforming the next best method on 1px error by 29% and outperforms all published work on the ETH3D two-view stereo benchmark. Code is available at https://github.com/princeton-vl/RAFT-Stereo.
Not Color Blind: AI Predicts Racial Identity from Black and White Retinal Vessel Segmentations
Sep 28, 2021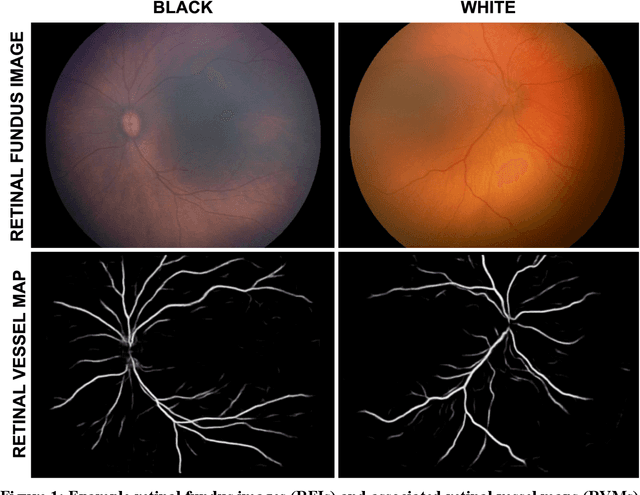
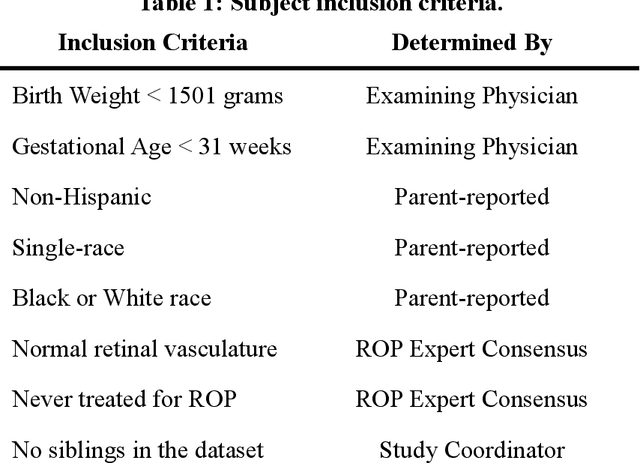
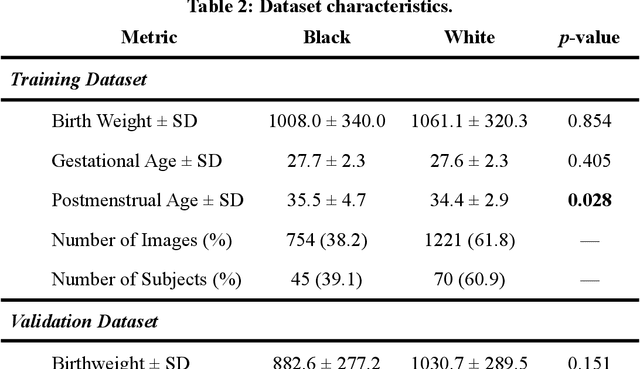
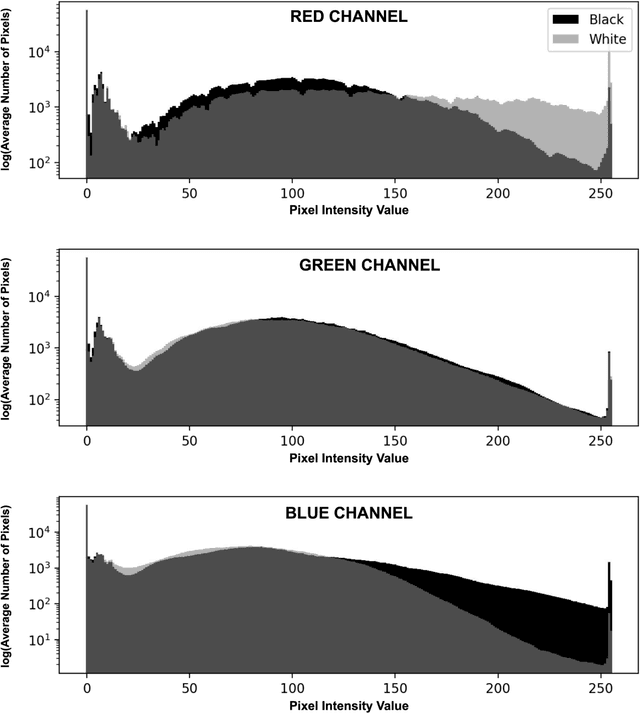
Background: Artificial intelligence (AI) may demonstrate racial bias when skin or choroidal pigmentation is present in medical images. Recent studies have shown that convolutional neural networks (CNNs) can predict race from images that were not previously thought to contain race-specific features. We evaluate whether grayscale retinal vessel maps (RVMs) of patients screened for retinopathy of prematurity (ROP) contain race-specific features. Methods: 4095 retinal fundus images (RFIs) were collected from 245 Black and White infants. A U-Net generated RVMs from RFIs, which were subsequently thresholded, binarized, or skeletonized. To determine whether RVM differences between Black and White eyes were physiological, CNNs were trained to predict race from color RFIs, raw RVMs, and thresholded, binarized, or skeletonized RVMs. Area under the precision-recall curve (AUC-PR) was evaluated. Findings: CNNs predicted race from RFIs near perfectly (image-level AUC-PR: 0.999, subject-level AUC-PR: 1.000). Raw RVMs were almost as informative as color RFIs (image-level AUC-PR: 0.938, subject-level AUC-PR: 0.995). Ultimately, CNNs were able to detect whether RFIs or RVMs were from Black or White babies, regardless of whether images contained color, vessel segmentation brightness differences were nullified, or vessel segmentation widths were normalized. Interpretation: AI can detect race from grayscale RVMs that were not thought to contain racial information. Two potential explanations for these findings are that: retinal vessels physiologically differ between Black and White babies or the U-Net segments the retinal vasculature differently for various fundus pigmentations. Either way, the implications remain the same: AI algorithms have potential to demonstrate racial bias in practice, even when preliminary attempts to remove such information from the underlying images appear to be successful.