 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Exemplar Guided Unsupervised Image-to-Image Translation with Semantic Consistency
Oct 13, 2018


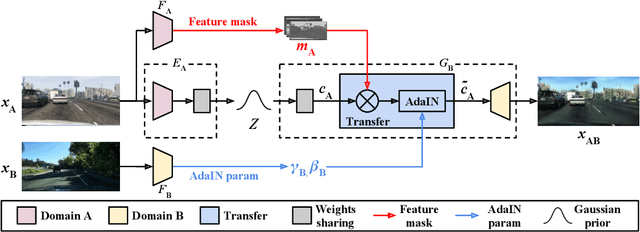

Image-to-image translation has recently received significant attention due to advances in deep learning. Most works focus on learning either a one-to-one mapping in an unsupervised way or a many-to-many mapping in a supervised way. However, a more practical setting is many-to-many mapping in an unsupervised way, which is harder due to the lack of supervision and the complex inner- and cross-domain variations. To alleviate these issues, we propose the Exemplar Guided & Semantically Consistent Image-to-image Translation (EGSC-IT) network which conditions the translation process on an exemplar image in the target domain. We assume that an image comprises of a content component which is shared across domains, and a style component specific to each domain. Under the guidance of an exemplar from the target domain we apply Adaptive Instance Normalization to the shared content component, which allows us to transfer the style information of the target domain to the source domain. To avoid semantic inconsistencies during translation that naturally appear due to the large inner- and cross-domain variations, we introduce the concept of feature masks that provide coarse semantic guidance without requiring the use of any semantic labels. Experimental results on various datasets show that EGSC-IT does not only translate the source image to diverse instances in the target domain, but also preserves the semantic consistency during the process.
Edge Prior Augmented Networks for Motion Deblurring on Naturally Blurry Images
Sep 18, 2021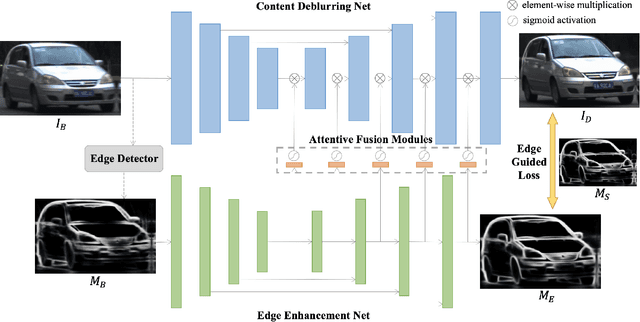



Motion deblurring has witnessed rapid development in recent years, and most of the recent methods address it by using deep learning techniques, with the help of different kinds of prior knowledge. Concerning that deblurring is essentially expected to improve the image sharpness, edge information can serve as an important prior. However, the edge has not yet been seriously taken into consideration in previous methods when designing deep models. To this end, we present a novel framework that incorporates edge prior knowledge into deep models, termed Edge Prior Augmented Networks (EPAN). EPAN has a content-based main branch and an edge-based auxiliary branch, which are constructed as a Content Deblurring Net (CDN) and an Edge Enhancement Net (EEN), respectively. EEN is designed to augment CDN in the deblurring process via an attentive fusion mechanism, where edge features are mapped as spatial masks to guide content features in a feature-based hierarchical manner. An edge-guided loss function is proposed to further regulate the optimization of EPAN by enforcing the focus on edge areas. Besides, we design a dual-camera-based image capturing setting to build a new dataset, Real Object Motion Blur (ROMB), with paired sharp and naturally blurry images of fast-moving cars, so as to better train motion deblurring models and benchmark the capability of motion deblurring algorithms in practice. Extensive experiments on the proposed ROMB and other existing datasets demonstrate that EPAN outperforms state-of-the-art approaches qualitatively and quantitatively.
Simulating Realistic MRI variations to Improve Deep Learning model and visual explanations using GradCAM
Nov 01, 2021
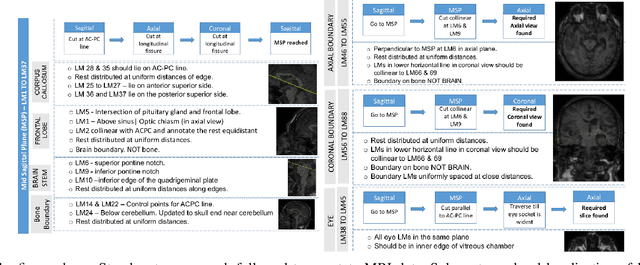
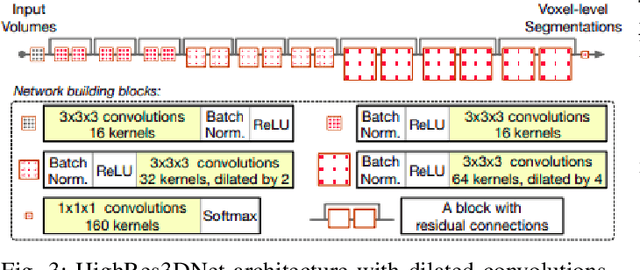
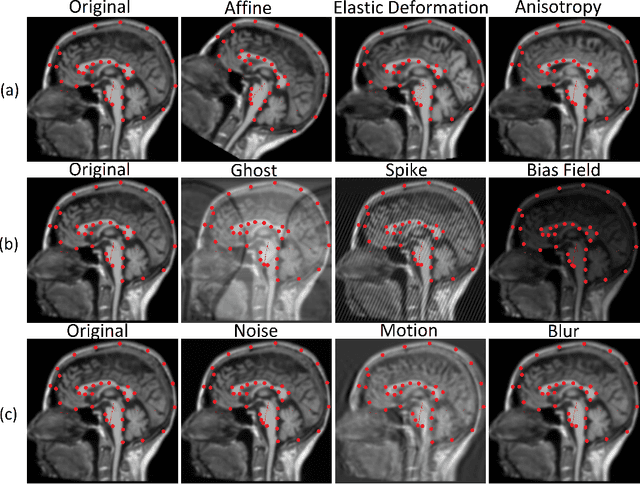
In the medical field, landmark detection in MRI plays an important role in reducing medical technician efforts in tasks like scan planning, image registration, etc. First, 88 landmarks spread across the brain anatomy in the three respective views -- sagittal, coronal, and axial are manually annotated, later guidelines from the expert clinical technicians are taken sub-anatomy-wise, for better localization of the existing landmarks, in order to identify and locate the important atlas landmarks even in oblique scans. To overcome limited data availability, we implement realistic data augmentation to generate synthetic 3D volumetric data. We use a modified HighRes3DNet model for solving brain MRI volumetric landmark detection problem. In order to visually explain our trained model on unseen data, and discern a stronger model from a weaker model, we implement Gradient-weighted Class Activation Mapping (Grad-CAM) which produces a coarse localization map highlighting the regions the model is focusing. Our experiments show that the proposed method shows favorable results, and the overall pipeline can be extended to a variable number of landmarks and other anatomies.
EvDistill: Asynchronous Events to End-task Learning via Bidirectional Reconstruction-guided Cross-modal Knowledge Distillation
Nov 24, 2021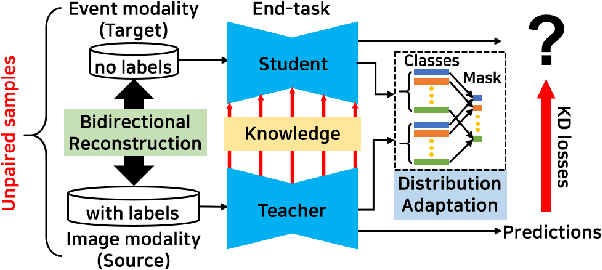
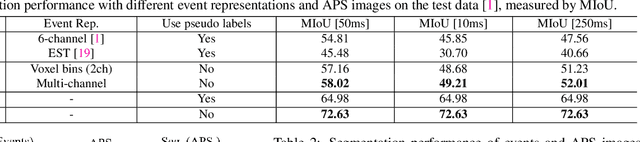
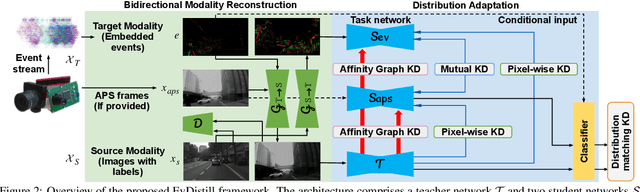

Event cameras sense per-pixel intensity changes and produce asynchronous event streams with high dynamic range and less motion blur, showing advantages over conventional cameras. A hurdle of training event-based models is the lack of large qualitative labeled data. Prior works learning end-tasks mostly rely on labeled or pseudo-labeled datasets obtained from the active pixel sensor (APS) frames; however, such datasets' quality is far from rivaling those based on the canonical images. In this paper, we propose a novel approach, called \textbf{EvDistill}, to learn a student network on the unlabeled and unpaired event data (target modality) via knowledge distillation (KD) from a teacher network trained with large-scale, labeled image data (source modality). To enable KD across the unpaired modalities, we first propose a bidirectional modality reconstruction (BMR) module to bridge both modalities and simultaneously exploit them to distill knowledge via the crafted pairs, causing no extra computation in the inference. The BMR is improved by the end-tasks and KD losses in an end-to-end manner. Second, we leverage the structural similarities of both modalities and adapt the knowledge by matching their distributions. Moreover, as most prior feature KD methods are uni-modality and less applicable to our problem, we propose to leverage an affinity graph KD loss to boost the distillation. Our extensive experiments on semantic segmentation and object recognition demonstrate that EvDistill achieves significantly better results than the prior works and KD with only events and APS frames.
CycleMLP: A MLP-like Architecture for Dense Prediction
Jul 21, 2021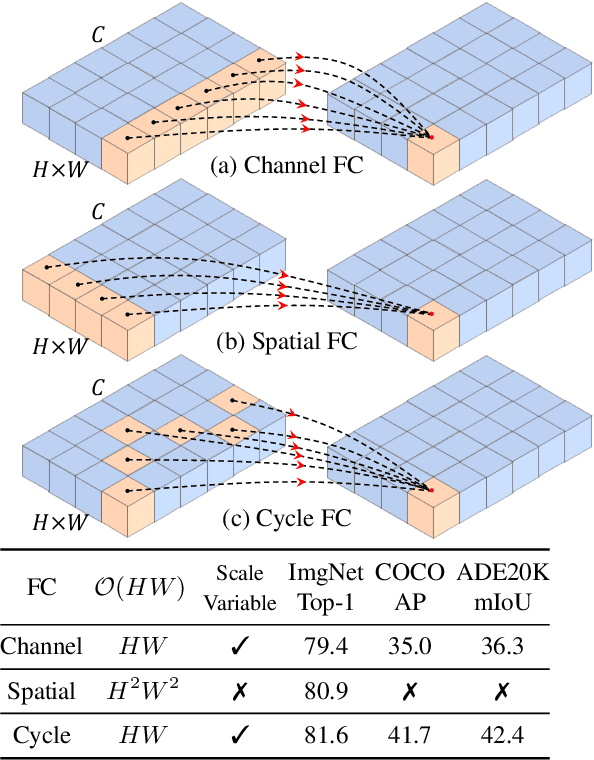
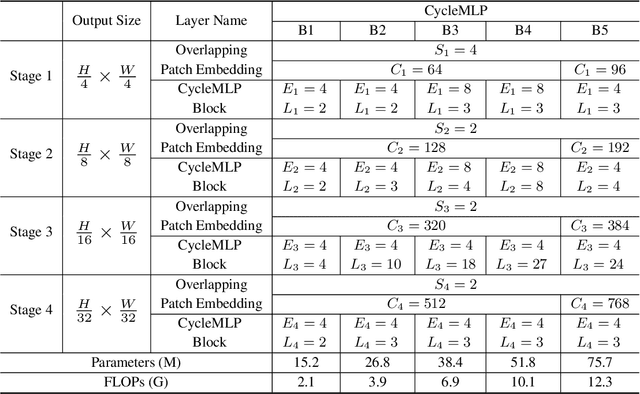
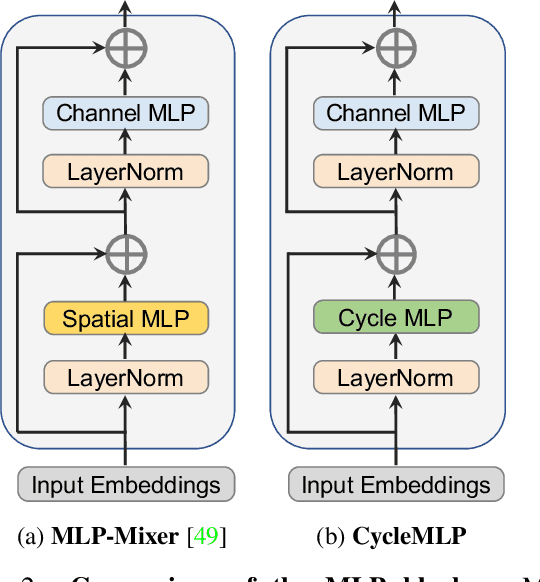
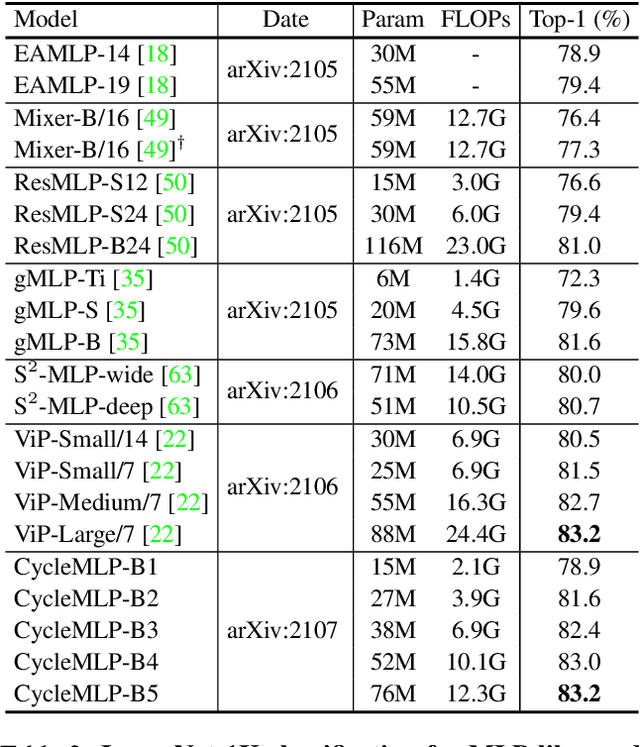
This paper presents a simple MLP-like architecture, CycleMLP, which is a versatile backbone for visual recognition and dense predictions, unlike modern MLP architectures, e.g., MLP-Mixer, ResMLP, and gMLP, whose architectures are correlated to image size and thus are infeasible in object detection and segmentation. CycleMLP has two advantages compared to modern approaches. (1) It can cope with various image sizes. (2) It achieves linear computational complexity to image size by using local windows. In contrast, previous MLPs have quadratic computations because of their fully spatial connections. We build a family of models that surpass existing MLPs and achieve a comparable accuracy (83.2%) on ImageNet-1K classification compared to the state-of-the-art Transformer such as Swin Transformer (83.3%) but using fewer parameters and FLOPs. We expand the MLP-like models' applicability, making them a versatile backbone for dense prediction tasks. CycleMLP aims to provide a competitive baseline on object detection, instance segmentation, and semantic segmentation for MLP models. In particular, CycleMLP achieves 45.1 mIoU on ADE20K val, comparable to Swin (45.2 mIOU). Code is available at \url{https://github.com/ShoufaChen/CycleMLP}.
Meta-Learning Sparse Implicit Neural Representations
Nov 07, 2021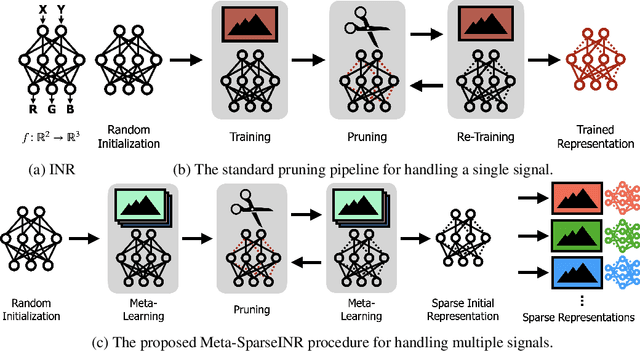

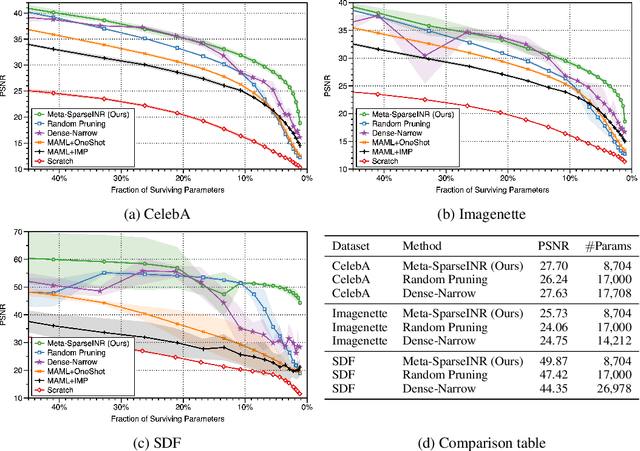
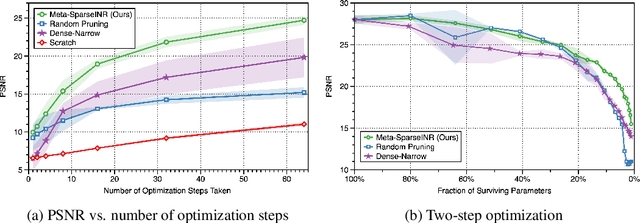
Implicit neural representations are a promising new avenue of representing general signals by learning a continuous function that, parameterized as a neural network, maps the domain of a signal to its codomain; the mapping from spatial coordinates of an image to its pixel values, for example. Being capable of conveying fine details in a high dimensional signal, unboundedly of its domain, implicit neural representations ensure many advantages over conventional discrete representations. However, the current approach is difficult to scale for a large number of signals or a data set, since learning a neural representation -- which is parameter heavy by itself -- for each signal individually requires a lot of memory and computations. To address this issue, we propose to leverage a meta-learning approach in combination with network compression under a sparsity constraint, such that it renders a well-initialized sparse parameterization that evolves quickly to represent a set of unseen signals in the subsequent training. We empirically demonstrate that meta-learned sparse neural representations achieve a much smaller loss than dense meta-learned models with the same number of parameters, when trained to fit each signal using the same number of optimization steps.
Unified Multi-scale Feature Abstraction for Medical Image Segmentation
Oct 24, 2019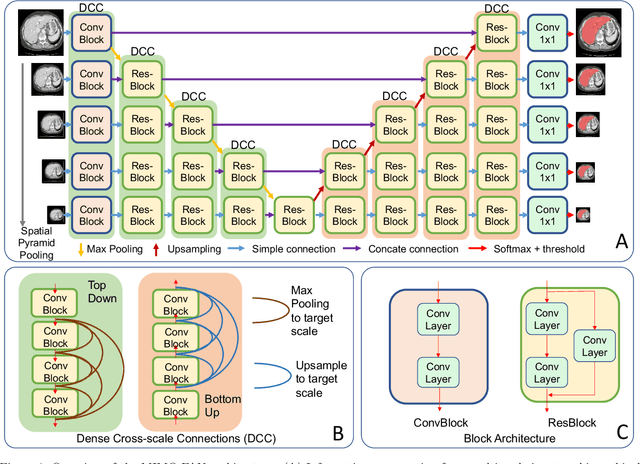
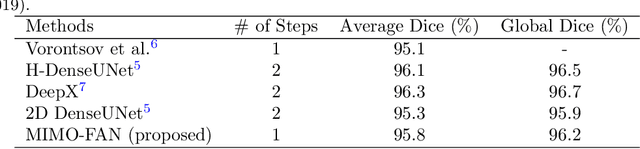
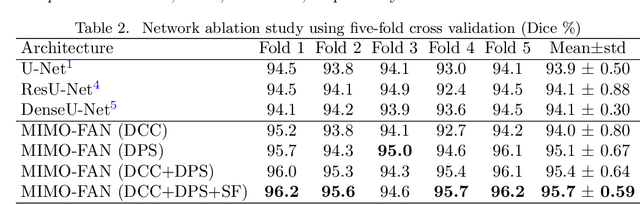
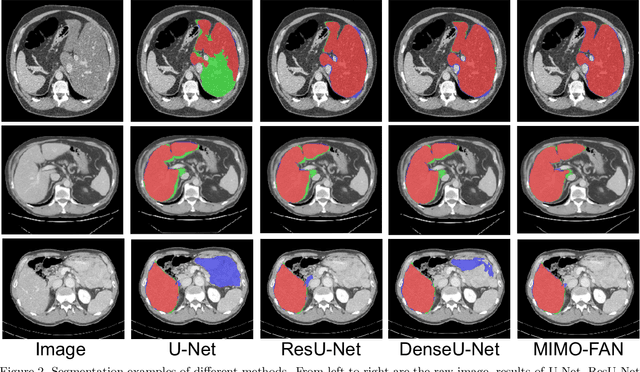
Automatic medical image segmentation, an essential component of medical image analysis, plays an importantrole in computer-aided diagnosis. For example, locating and segmenting the liver can be very helpful in livercancer diagnosis and treatment. The state-of-the-art models in medical image segmentation are variants ofthe encoder-decoder architecture such as fully convolutional network (FCN) and U-Net.1A major focus ofthe FCN based segmentation methods has been on network structure engineering by incorporating the latestCNN structures such as ResNet2and DenseNet.3In addition to exploring new network structures for efficientlyabstracting high level features, incorporating structures for multi-scale image feature extraction in FCN hashelped to improve performance in segmentation tasks. In this paper, we design a new multi-scale networkarchitecture, which takes multi-scale inputs with dedicated convolutional paths to efficiently combine featuresfrom different scales to better utilize the hierarchical information.
Learning Structure-Appearance Joint Embedding for Indoor Scene Image Synthesis
Dec 09, 2019
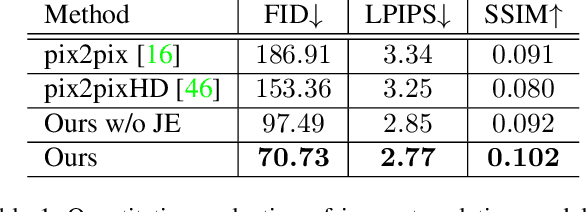

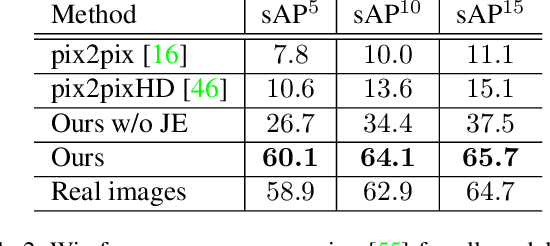
Advanced image synthesis methods can generate photo-realistic images for faces, birds, bedrooms, and more. However, these methods do not explicitly model and preserve essential structural constraints such as junctions, parallel lines, and planar surfaces. In this paper, we study the problem of structured indoor image generation for design applications. We utilize a small-scale dataset that contains both images of various indoor scenes and their corresponding ground-truth wireframe annotations. While existing image synthesis models trained on the dataset are insufficient in preserving structural integrity, we propose a novel model based on a structure-appearance joint embedding learned from both images and wireframes. In our model, structural constraints are explicitly enforced by learning a joint embedding in a shared encoder network that must support the generation of both images and wireframes. We demonstrate the effectiveness of the joint embedding learning scheme on the indoor scene wireframe to image translation task. While wireframes as input contain less semantic information than inputs of other traditional image translation tasks, our model can generate high fidelity indoor scene renderings that match well with input wireframes. Experiments on a wireframe-scene dataset show that our proposed translation model significantly outperforms existing state-of-the-art methods in both visual quality and structural integrity of generated images.
Image Deconvolution via Noise-Tolerant Self-Supervised Inversion
Jun 11, 2020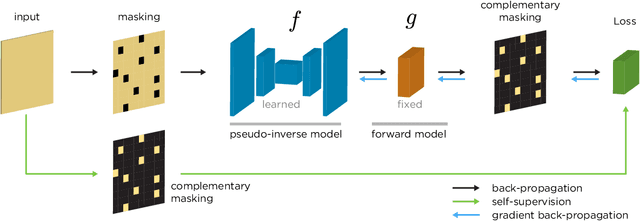
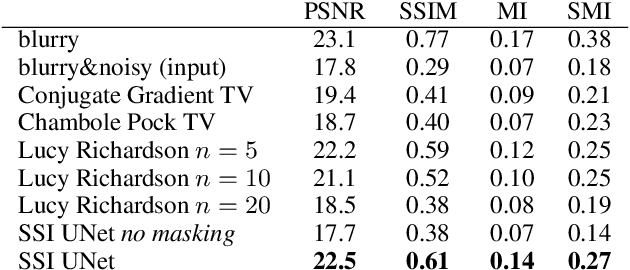
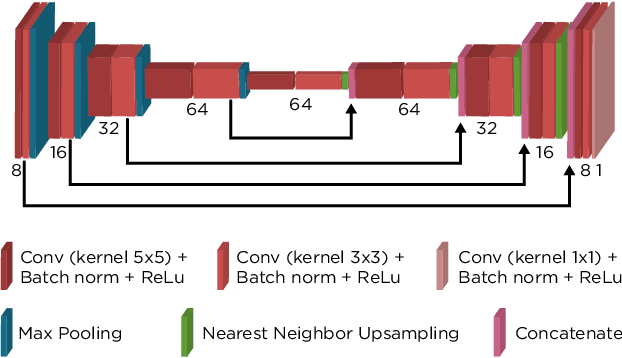
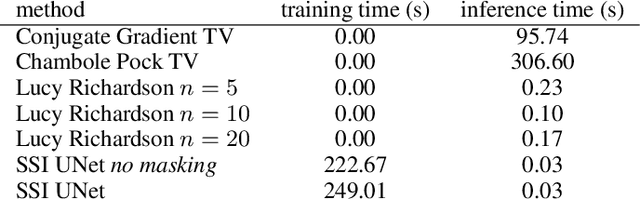
We propose a general framework for solving inverse problems in the presence of noise that requires no signal prior, no noise estimate, and no clean training data. We only require that the forward model be available and that the noise be statistically independent across measurement dimensions. We build upon the theory of $\mathcal{J}$-invariant functions (Batson & Royer 2019, arXiv:1901.11365) and show how self-supervised denoising \emph{\`a la} Noise2Self is a special case of learning a noise-tolerant pseudo-inverse of the identity. We demonstrate our approach by showing how a convolutional neural network can be taught in a self-supervised manner to deconvolve images and surpass in image quality classical inversion schemes such as Lucy-Richardson deconvolution.
MUSE: Feature Self-Distillation with Mutual Information and Self-Information
Oct 25, 2021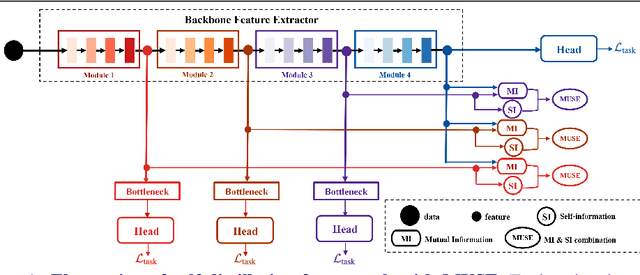
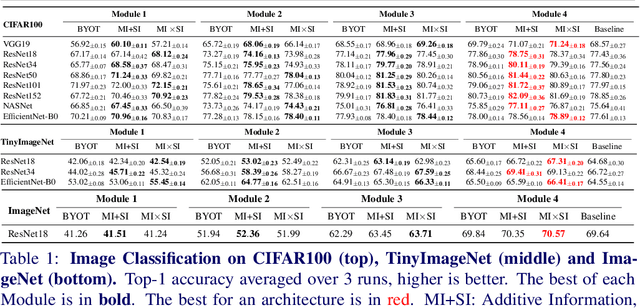

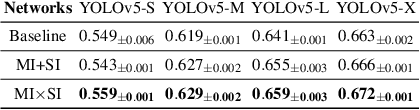
We present a novel information-theoretic approach to introduce dependency among features of a deep convolutional neural network (CNN). The core idea of our proposed method, called MUSE, is to combine MUtual information and SElf-information to jointly improve the expressivity of all features extracted from different layers in a CNN. We present two variants of the realization of MUSE -- Additive Information and Multiplicative Information. Importantly, we argue and empirically demonstrate that MUSE, compared to other feature discrepancy functions, is a more functional proxy to introduce dependency and effectively improve the expressivity of all features in the knowledge distillation framework. MUSE achieves superior performance over a variety of popular architectures and feature discrepancy functions for self-distillation and online distillation, and performs competitively with the state-of-the-art methods for offline distillation. MUSE is also demonstrably versatile that enables it to be easily extended to CNN-based models on tasks other than image classification such as object detection.