 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Unsupervised MRI Super-Resolution Using Deep External Learning and Guided Residual Dense Network with Multimodal Image Priors
Oct 02, 2020
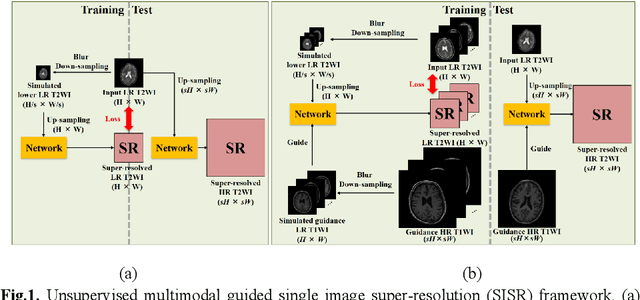
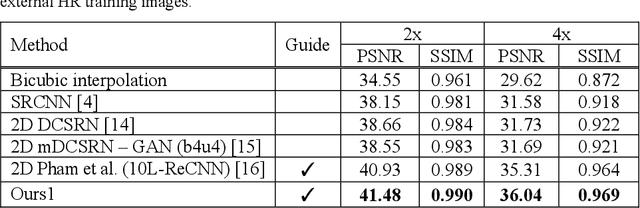
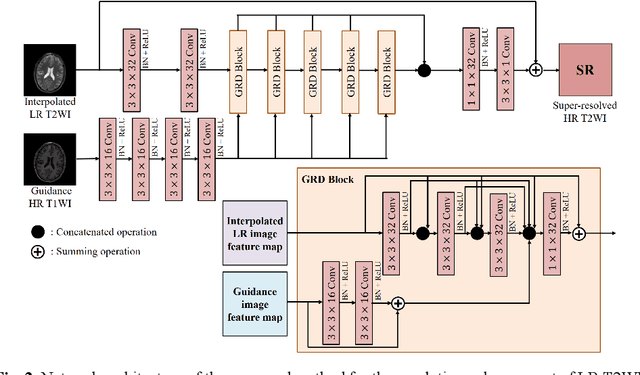
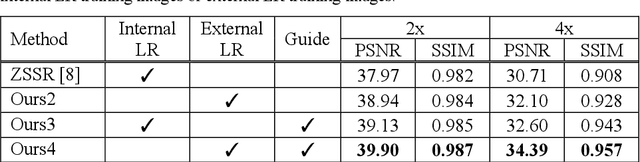
Deep learning techniques have led to state-of-the-art single image super-resolution (SISR) with natural images. Pairs of high-resolution (HR) and low-resolution (LR) images are used to train the deep learning model (mapping function). These techniques have also been applied to medical image super-resolution (SR). Compared with natural images, medical images have several unique characteristics. First, there are no HR images for training in real clinical applications because of the limitations of imaging systems and clinical requirements. Second, other modal HR images are available (e.g., HR T1-weighted images are available for enhancing LR T2-weighted images). In this paper, we propose an unsupervised SISR technique based on simple prior knowledge of the human anatomy; this technique does not require HR images for training. Furthermore, we present a guided residual dense network, which incorporates a residual dense network with a guided deep convolutional neural network for enhancing the resolution of LR images by referring to different HR images of the same subject. Experiments on a publicly available brain MRI database showed that our proposed method achieves better performance than the state-of-the-art methods.
Fast-Slow Transformer for Visually Grounding Speech
Sep 16, 2021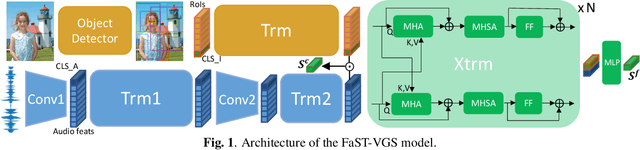
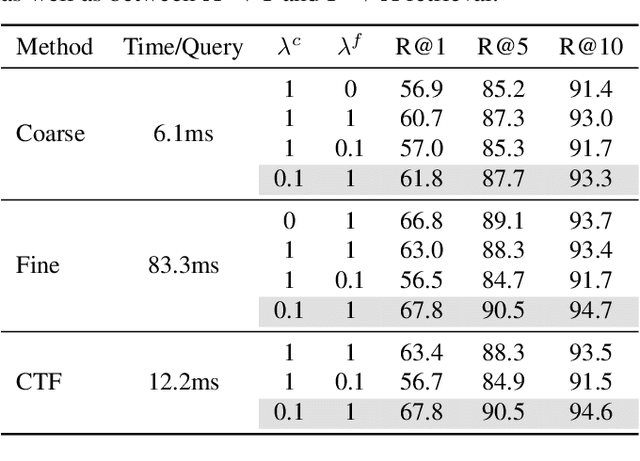
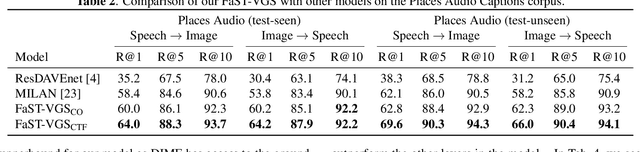
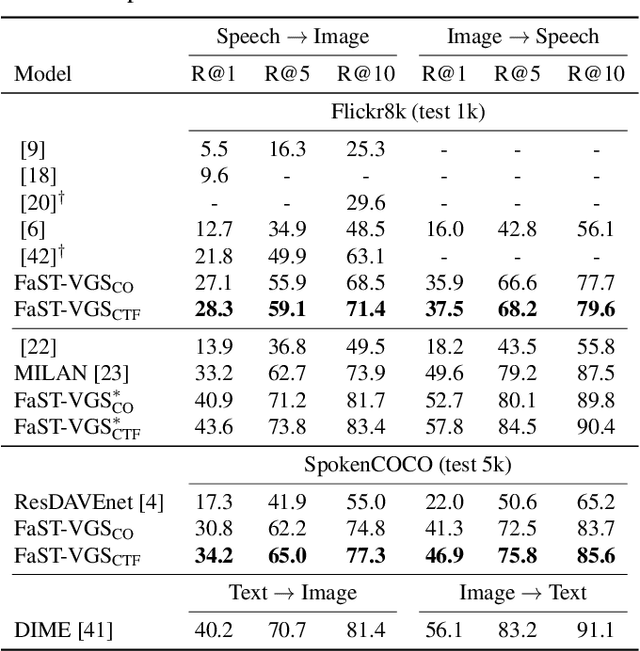
We present Fast-Slow Transformer for Visually Grounding Speech, or FaST-VGS. FaST-VGS is a Transformer-based model for learning the associations between raw speech waveforms and visual images. The model unifies dual-encoder and cross-attention architectures into a single model, reaping the superior retrieval speed of the former along with the accuracy of the latter. FaST-VGS achieves state-of-the-art speech-image retrieval accuracy on benchmark datasets, and its learned representations exhibit strong performance on the ZeroSpeech 2021 phonetic and semantic tasks.
Variable Rate Deep Image Compression with Modulated Autoencoder
Dec 11, 2019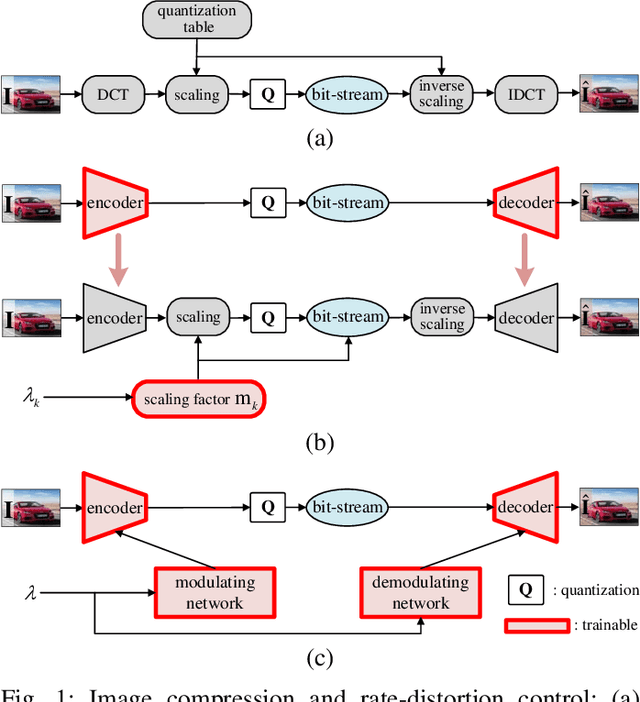
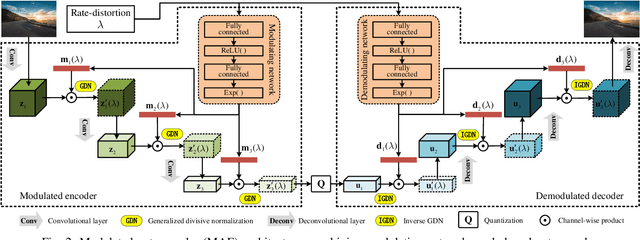
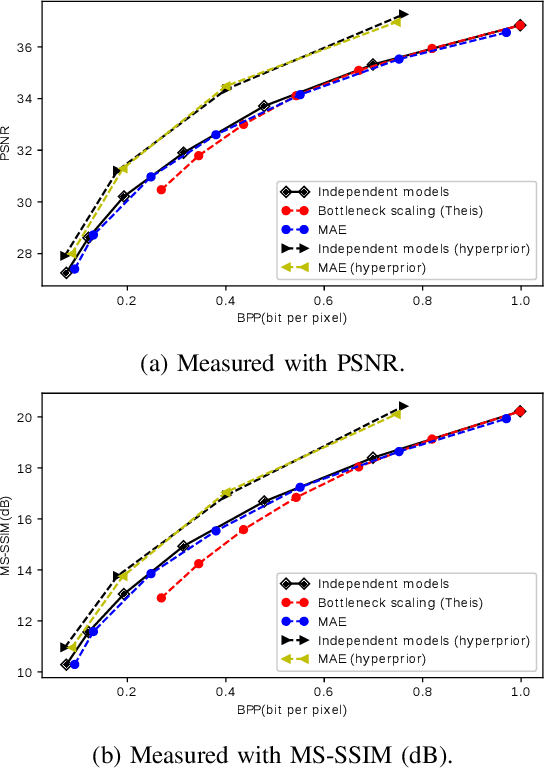
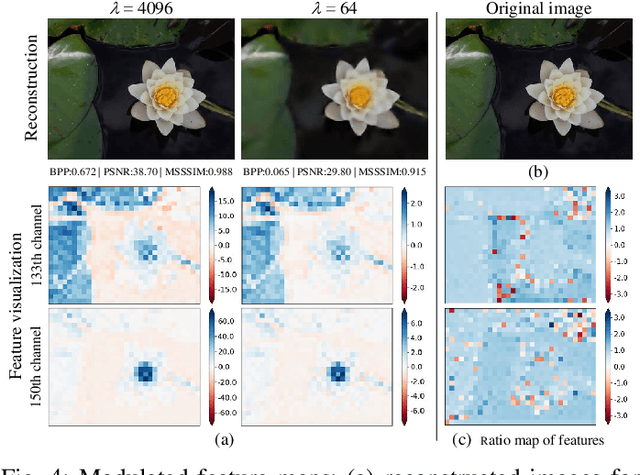
Variable rate is a requirement for flexible and adaptable image and video compression. However, deep image compression methods are optimized for a single fixed rate-distortion tradeoff. While this can be addressed by training multiple models for different tradeoffs, the memory requirements increase proportionally to the number of models. Scaling the bottleneck representation of a shared autoencoder can provide variable rate compression with a single shared autoencoder. However, the R-D performance using this simple mechanism degrades in low bitrates, and also shrinks the effective range of bit rates. Addressing these limitations, we formulate the problem of variable rate-distortion optimization for deep image compression, and propose modulated autoencoders (MAEs), where the representations of a shared autoencoder are adapted to the specific rate-distortion tradeoff via a modulation network. Jointly training this modulated autoencoder and modulation network provides an effective way to navigate the R-D operational curve. Our experiments show that the proposed method can achieve almost the same R-D performance of independent models with significantly fewer parameters.
Investigating Tradeoffs in Real-World Video Super-Resolution
Nov 24, 2021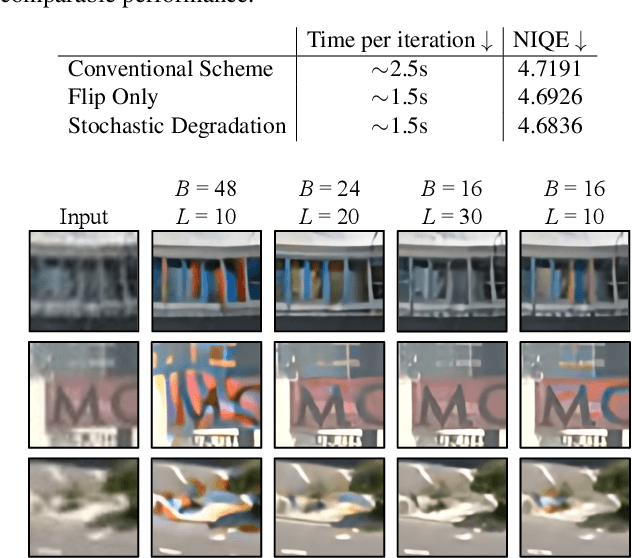


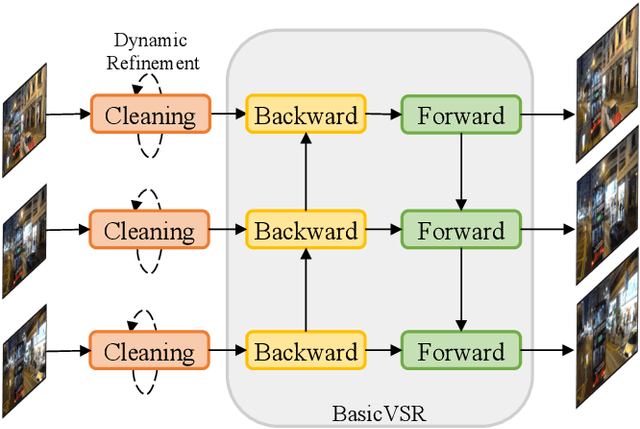
The diversity and complexity of degradations in real-world video super-resolution (VSR) pose non-trivial challenges in inference and training. First, while long-term propagation leads to improved performance in cases of mild degradations, severe in-the-wild degradations could be exaggerated through propagation, impairing output quality. To balance the tradeoff between detail synthesis and artifact suppression, we found an image pre-cleaning stage indispensable to reduce noises and artifacts prior to propagation. Equipped with a carefully designed cleaning module, our RealBasicVSR outperforms existing methods in both quality and efficiency. Second, real-world VSR models are often trained with diverse degradations to improve generalizability, requiring increased batch size to produce a stable gradient. Inevitably, the increased computational burden results in various problems, including 1) speed-performance tradeoff and 2) batch-length tradeoff. To alleviate the first tradeoff, we propose a stochastic degradation scheme that reduces up to 40\% of training time without sacrificing performance. We then analyze different training settings and suggest that employing longer sequences rather than larger batches during training allows more effective uses of temporal information, leading to more stable performance during inference. To facilitate fair comparisons, we propose the new VideoLQ dataset, which contains a large variety of real-world low-quality video sequences containing rich textures and patterns. Our dataset can serve as a common ground for benchmarking. Code, models, and the dataset will be made publicly available.
Aerial Map-Based Navigation Using Semantic Segmentation and Pattern Matching
Jul 01, 2021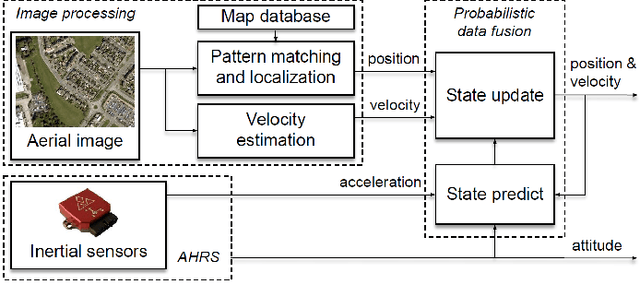
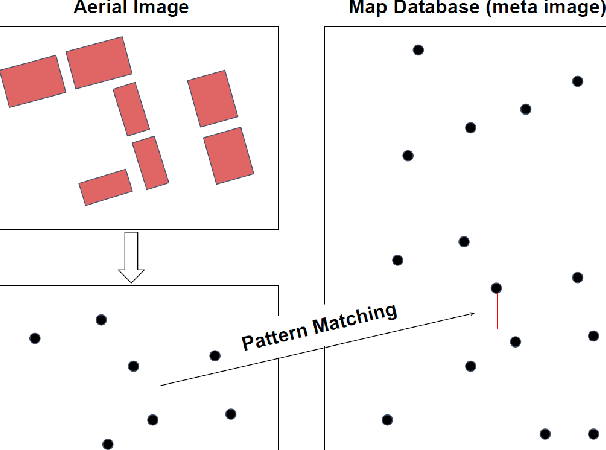
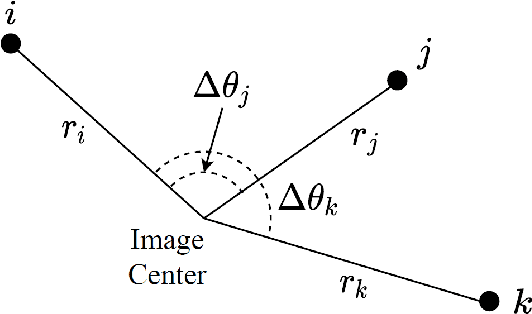
This paper proposes a novel approach to map-based navigation system for unmanned aircraft. The proposed system attempts label-to-label matching, not image-to-image matching between aerial images and a map database. By using semantic segmentation, the ground objects are labelled and the configuration of the objects is used to find the corresponding location in the map database. The use of the deep learning technique as a tool for extracting high-level features reduces the image-based localization problem to a pattern matching problem. This paper proposes a pattern matching algorithm which does not require altitude information or a camera model to estimate the absolute horizontal position. The feasibility analysis with simulated images shows the proposed map-based navigation can be realized with the proposed pattern matching algorithm and it is able to provide positions given the labelled objects.
PGGANet: Pose Guided Graph Attention Network for Person Re-identification
Nov 29, 2021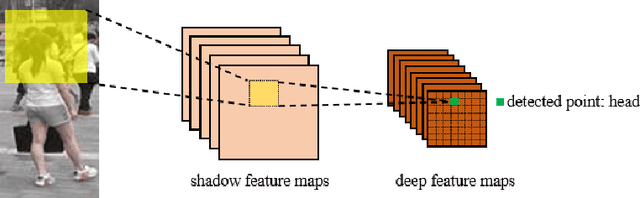
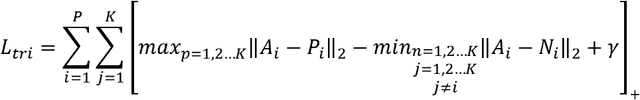
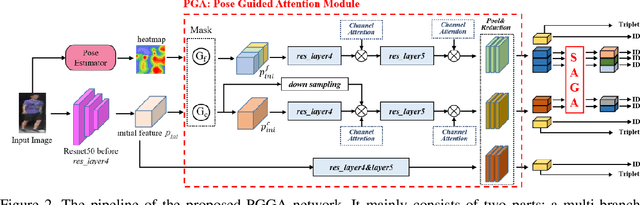
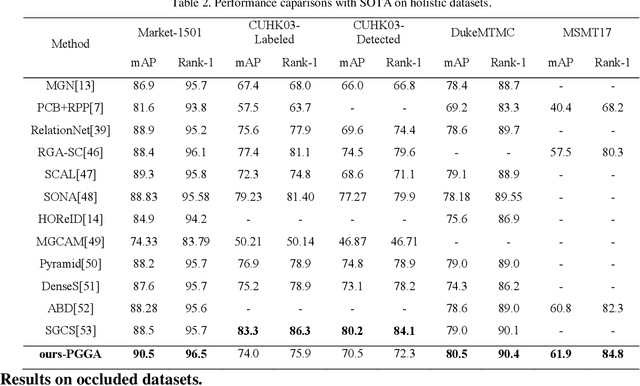
Person re-identification (ReID) aims at retrieving a person from images captured by different cameras. For deep-learning-based ReID methods, it has been proved that using local features together with global feature of person image could help to give robust feature representations for person retrieval. Human pose information could provide the locations of human skeleton to effectively guide the network to pay more attention on these key areas and could also help to reduce the noise distractions from background or occlusions. However, methods proposed by previous pose-related works might not be able to fully exploit the benefits of pose information and did not take into consideration the different contributions of different local features. In this paper, we propose a pose guided graph attention network, a multi-branch architecture consisting of one branch for global feature, one branch for mid-granular body features and one branch for fine-granular key point features. We use a pre-trained pose estimator to generate the key-point heatmap for local feature learning and carefully design a graph attention convolution layer to re-evaluate the contribution weights of extracted local features by modeling the similarities relations. Experiments results demonstrate the effectiveness of our approach on discriminative feature learning and we show that our model achieves state-of-the-art performances on several mainstream evaluation datasets. We also conduct a plenty of ablation studies and design different kinds of comparison experiments for our network to prove its effectiveness and robustness, including holistic datasets, partial datasets, occluded datasets and cross-domain tests.
Spectral unmixing of Raman microscopic images of single human cells using Independent Component Analysis
Oct 25, 2021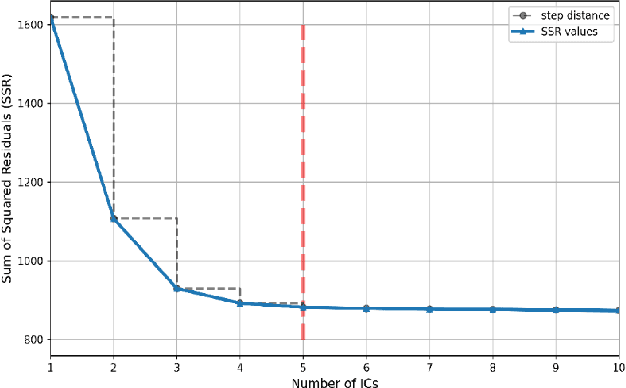
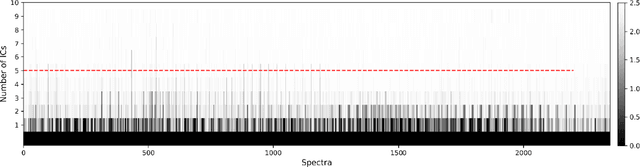
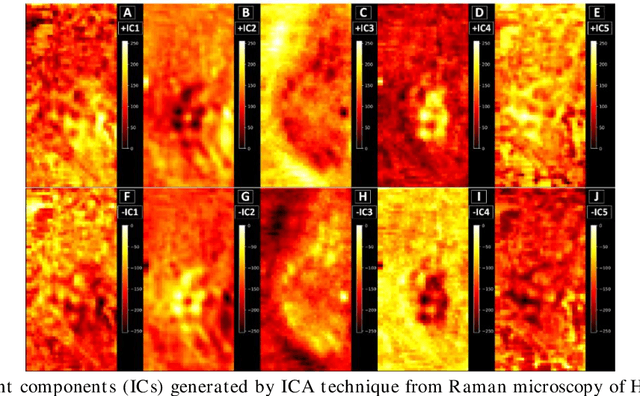
Application of independent component analysis (ICA) as an unmixing and image clustering technique for high spatial resolution Raman maps is reported. A hyperspectral map of a fixed human cell was collected by a Raman micro spectrometer in a raster pattern on a 0.5um grid. Unlike previously used unsupervised machine learning techniques such as principal component analysis, ICA is based on non-Gaussianity and statistical independence of data which is the case for mixture Raman spectra. Hence, ICA is a great candidate for assembling pseudo-colour maps from the spectral hypercube of Raman spectra. Our experimental results revealed that ICA is capable of reconstructing false colour maps of Raman hyperspectral data of human cells, showing the nuclear region constituents as well as subcellular organelle in the cytoplasm and distribution of mitochondria in the perinuclear region. Minimum preprocessing requirements and label-free nature of the ICA method make it a great unmixed method for extraction of endmembers in Raman hyperspectral maps of living cells.
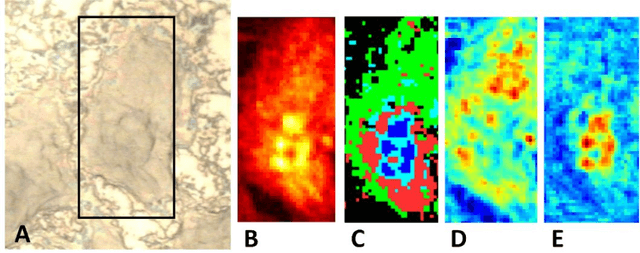
Image Restoration using Total Variation Regularized Deep Image Prior
Oct 30, 2018
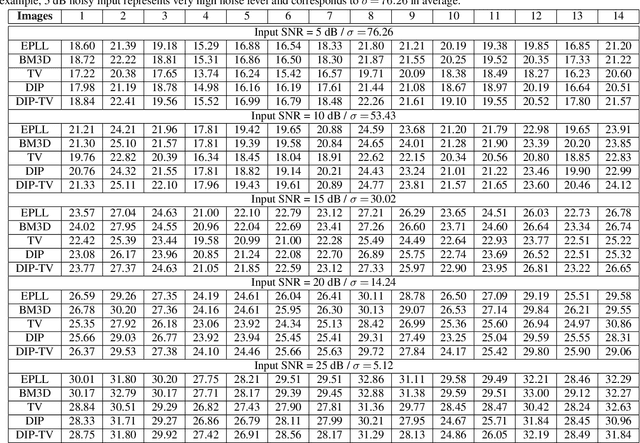

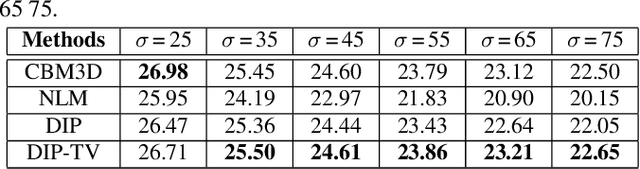
In the past decade, sparsity-driven regularization has led to significant improvements in image reconstruction. Traditional regularizers, such as total variation (TV), rely on analytical models of sparsity. However, increasingly the field is moving towards trainable models, inspired from deep learning. Deep image prior (DIP) is a recent regularization framework that uses a convolutional neural network (CNN) architecture without data-driven training. This paper extends the DIP framework by combining it with the traditional TV regularization. We show that the inclusion of TV leads to considerable performance gains when tested on several traditional restoration tasks such as image denoising and deblurring.
Exemplar Guided Unsupervised Image-to-Image Translation with Semantic Consistency
Oct 13, 2018

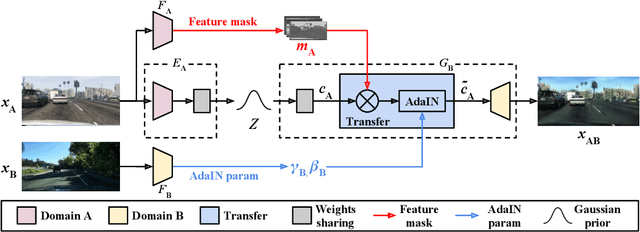

Image-to-image translation has recently received significant attention due to advances in deep learning. Most works focus on learning either a one-to-one mapping in an unsupervised way or a many-to-many mapping in a supervised way. However, a more practical setting is many-to-many mapping in an unsupervised way, which is harder due to the lack of supervision and the complex inner- and cross-domain variations. To alleviate these issues, we propose the Exemplar Guided & Semantically Consistent Image-to-image Translation (EGSC-IT) network which conditions the translation process on an exemplar image in the target domain. We assume that an image comprises of a content component which is shared across domains, and a style component specific to each domain. Under the guidance of an exemplar from the target domain we apply Adaptive Instance Normalization to the shared content component, which allows us to transfer the style information of the target domain to the source domain. To avoid semantic inconsistencies during translation that naturally appear due to the large inner- and cross-domain variations, we introduce the concept of feature masks that provide coarse semantic guidance without requiring the use of any semantic labels. Experimental results on various datasets show that EGSC-IT does not only translate the source image to diverse instances in the target domain, but also preserves the semantic consistency during the process.
Resolution Switchable Networks for Runtime Efficient Image Recognition
Jul 29, 2020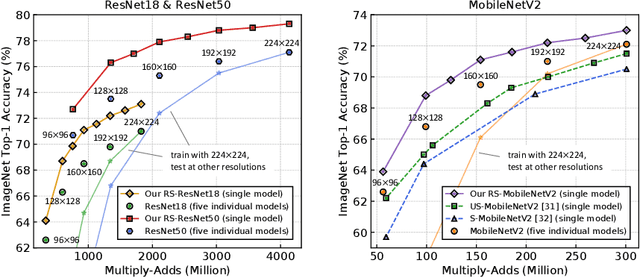
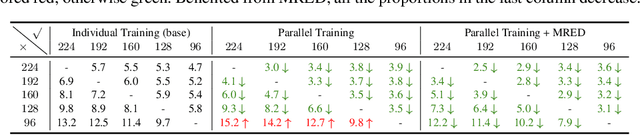
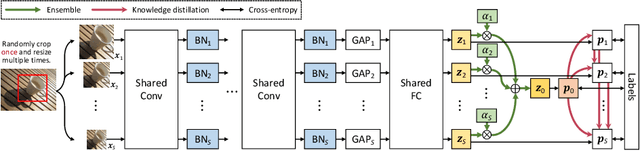
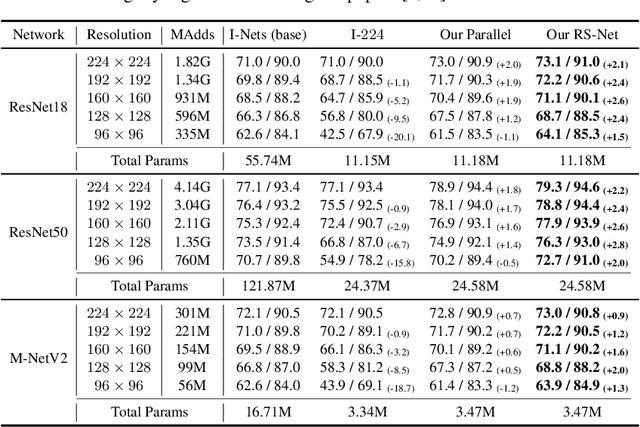
We propose a general method to train a single convolutional neural network which is capable of switching image resolutions at inference. Thus the running speed can be selected to meet various computational resource limits. Networks trained with the proposed method are named Resolution Switchable Networks (RS-Nets). The basic training framework shares network parameters for handling images which differ in resolution, yet keeps separate batch normalization layers. Though it is parameter-efficient in design, it leads to inconsistent accuracy variations at different resolutions, for which we provide a detailed analysis from the aspect of the train-test recognition discrepancy. A multi-resolution ensemble distillation is further designed, where a teacher is learnt on the fly as a weighted ensemble over resolutions. Thanks to the ensemble and knowledge distillation, RS-Nets enjoy accuracy improvements at a wide range of resolutions compared with individually trained models. Extensive experiments on the ImageNet dataset are provided, and we additionally consider quantization problems. Code and models are available at https://github.com/yikaiw/RS-Nets.