 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Multiclass non-Adversarial Image Synthesis, with Application to Classification from Very Small Sample
Dec 01, 2020

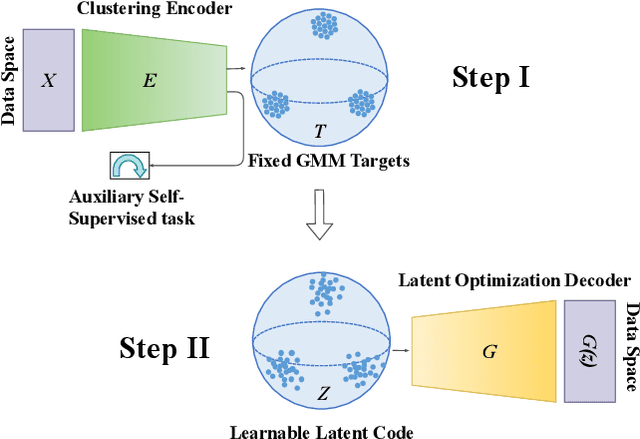
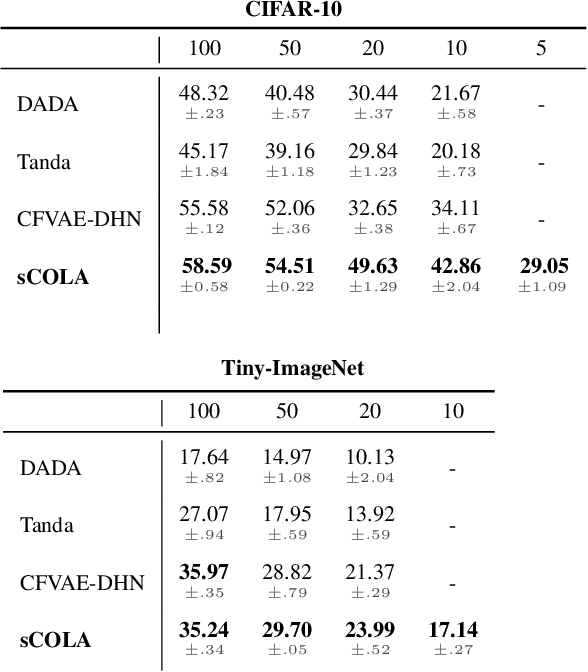
The generation of synthetic images is currently being dominated by Generative Adversarial Networks (GANs). Despite their outstanding success in generating realistic looking images, they still suffer from major drawbacks, including an unstable and highly sensitive training procedure, mode-collapse and mode-mixture, and dependency on large training sets. In this work we present a novel non-adversarial generative method - Clustered Optimization of LAtent space (COLA), which overcomes some of the limitations of GANs, and outperforms GANs when training data is scarce. In the full data regime, our method is capable of generating diverse multi-class images with no supervision, surpassing previous non-adversarial methods in terms of image quality and diversity. In the small-data regime, where only a small sample of labeled images is available for training with no access to additional unlabeled data, our results surpass state-of-the-art GAN models trained on the same amount of data. Finally, when utilizing our model to augment small datasets, we surpass the state-of-the-art performance in small-sample classification tasks on challenging datasets, including CIFAR-10, CIFAR-100, STL-10 and Tiny-ImageNet. A theoretical analysis supporting the essence of the method is presented.
2D Image Features Detector And Descriptor Selection Expert System
Jun 04, 2020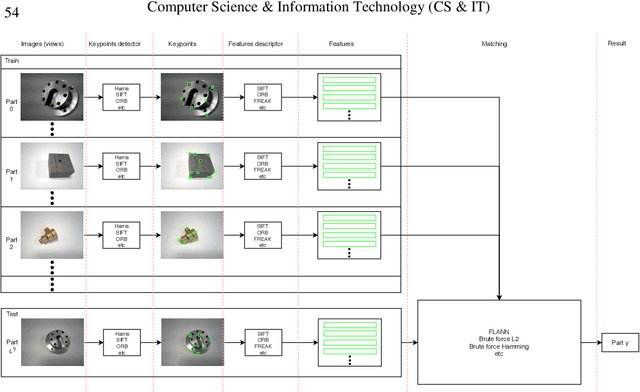
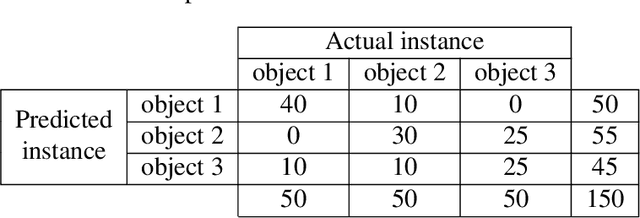

Detection and description of keypoints from an image is a well-studied problem in Computer Vision. Some methods like SIFT, SURF or ORB are computationally really efficient. This paper proposes a solution for a particular case study on object recognition of industrial parts based on hierarchical classification. Reducing the number of instances leads to better performance, indeed, that is what the use of the hierarchical classification is looking for. We demonstrate that this method performs better than using just one method like ORB, SIFT or FREAK, despite being fairly slower.
* 10 pages, 5 figures, 5 tables
Algorithm Fairness in AI for Medicine and Healthcare
Oct 01, 2021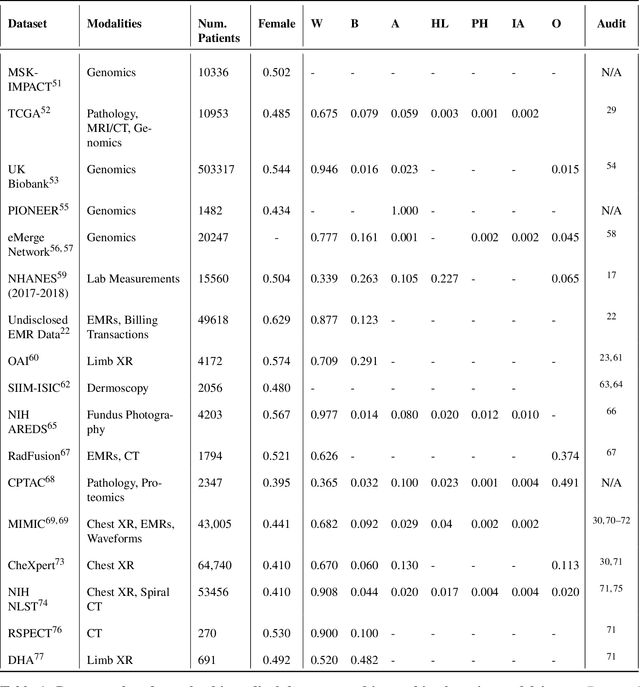
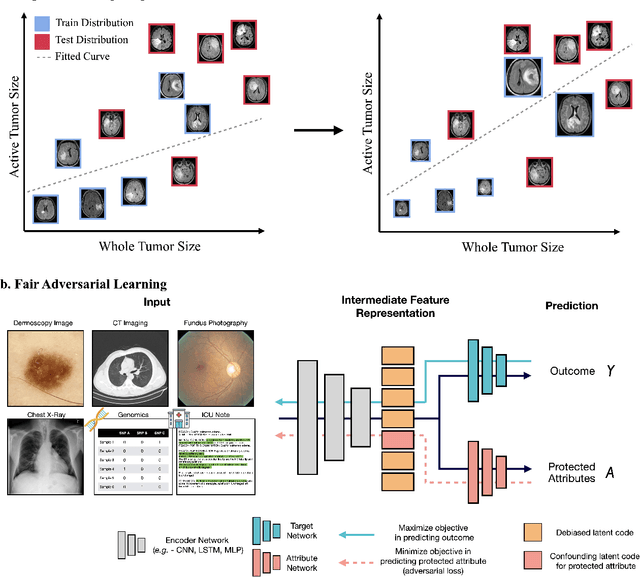
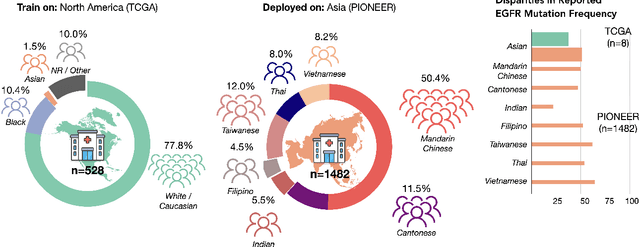
In the current development and deployment of many artificial intelligence (AI) systems in healthcare, algorithm fairness is a challenging problem in delivering equitable care. Recent evaluation of AI models stratified across race sub-populations have revealed enormous inequalities in how patients are diagnosed, given treatments, and billed for healthcare costs. In this perspective article, we summarize the intersectional field of fairness in machine learning through the context of current issues in healthcare, outline how algorithmic biases (e.g. - image acquisition, genetic variation, intra-observer labeling variability) arise in current clinical workflows and their resulting healthcare disparities. Lastly, we also review emerging strategies for mitigating bias via decentralized learning, disentanglement, and model explainability.
Reversible Adversarial Examples based on Reversible Image Transformation
Nov 06, 2019

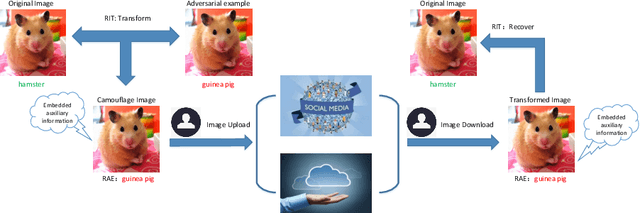

Recent studies show that widely used deep neural networks (DNNs) are vulnerable to carefully crafted adversarial examples, it inevitably brings some security challenges. However, the attack characteristic of adversarial examples can be taken advantage to do privacy-preserving image research. In this paper, we make use of Reversible Image Transformation to construct reversible adversarial examples, which are still misclassified by DNNs that are utilized by illegal organizations to steal privacy of image content that we upload to the cloud or social platforms. Most importantly, the proposed method can recover original images from downloaded reversible adversarial examples with no distortion. The experimental results show that the attack success rate of the reversible adversarial examples obtained by this method can reach more than 95 % on MNIST and more than 60 % on ImageNet.
Towards Efficient Cross-Modal Visual Textual Retrieval using Transformer-Encoder Deep Features
Jun 01, 2021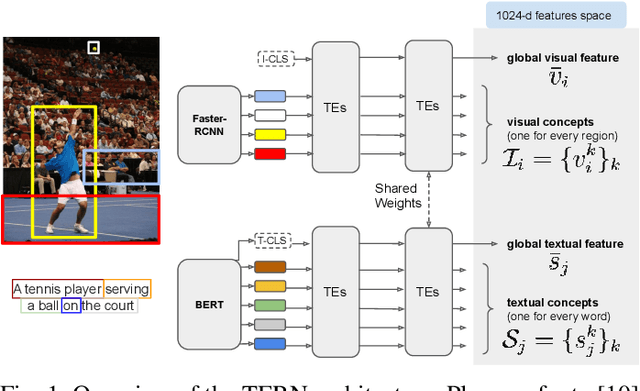
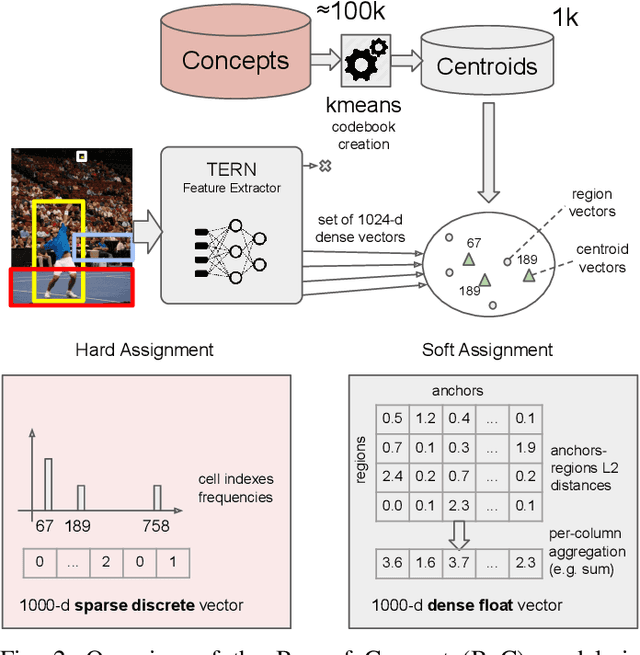
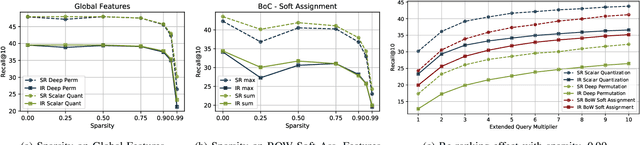
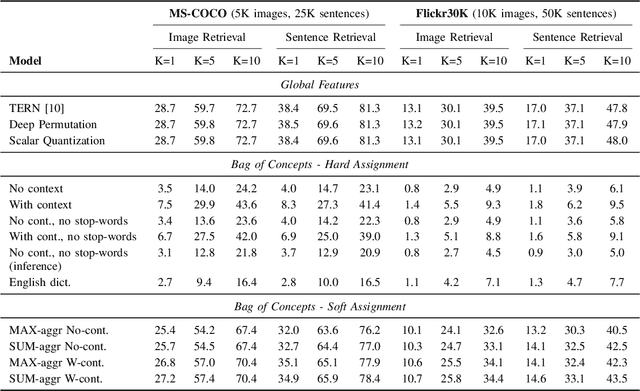
Cross-modal retrieval is an important functionality in modern search engines, as it increases the user experience by allowing queries and retrieved objects to pertain to different modalities. In this paper, we focus on the image-sentence retrieval task, where the objective is to efficiently find relevant images for a given sentence (image-retrieval) or the relevant sentences for a given image (sentence-retrieval). Computer vision literature reports the best results on the image-sentence matching task using deep neural networks equipped with attention and self-attention mechanisms. They evaluate the matching performance on the retrieval task by performing sequential scans of the whole dataset. This method does not scale well with an increasing amount of images or captions. In this work, we explore different preprocessing techniques to produce sparsified deep multi-modal features extracting them from state-of-the-art deep-learning architectures for image-text matching. Our main objective is to lay down the paths for efficient indexing of complex multi-modal descriptions. We use the recently introduced TERN architecture as an image-sentence features extractor. It is designed for producing fixed-size 1024-d vectors describing whole images and sentences, as well as variable-length sets of 1024-d vectors describing the various building components of the two modalities (image regions and sentence words respectively). All these vectors are enforced by the TERN design to lie into the same common space. Our experiments show interesting preliminary results on the explored methods and suggest further experimentation in this important research direction.
Determining Sequence of Image Processing Technique (IPT) to Detect Adversarial Attacks
Jul 01, 2020

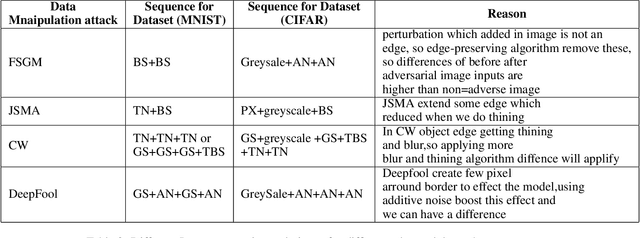
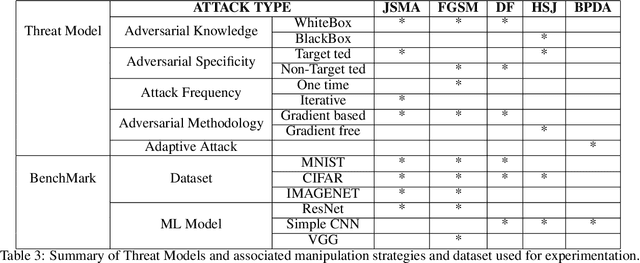
Developing secure machine learning models from adversarial examples is challenging as various methods are continually being developed to generate adversarial attacks. In this work, we propose an evolutionary approach to automatically determine Image Processing Techniques Sequence (IPTS) for detecting malicious inputs. Accordingly, we first used a diverse set of attack methods including adaptive attack methods (on our defense) to generate adversarial samples from the clean dataset. A detection framework based on a genetic algorithm (GA) is developed to find the optimal IPTS, where the optimality is estimated by different fitness measures such as Euclidean distance, entropy loss, average histogram, local binary pattern and loss functions. The "image difference" between the original and processed images is used to extract the features, which are then fed to a classification scheme in order to determine whether the input sample is adversarial or clean. This paper described our methodology and performed experiments using multiple data-sets tested with several adversarial attacks. For each attack-type and dataset, it generates unique IPTS. A set of IPTS selected dynamically in testing time which works as a filter for the adversarial attack. Our empirical experiments exhibited promising results indicating the approach can efficiently be used as processing for any AI model.
Revisiting Image Aesthetic Assessment via Self-Supervised Feature Learning
Nov 26, 2019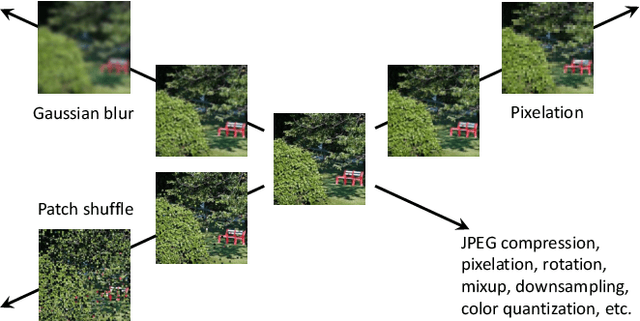
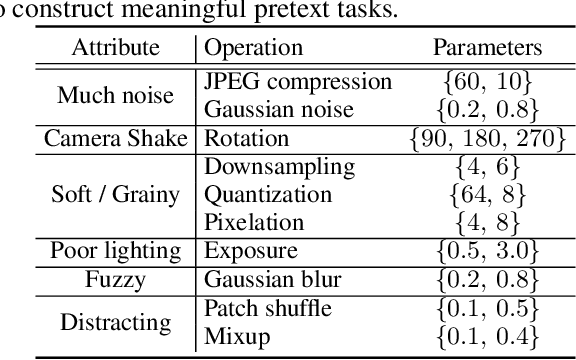

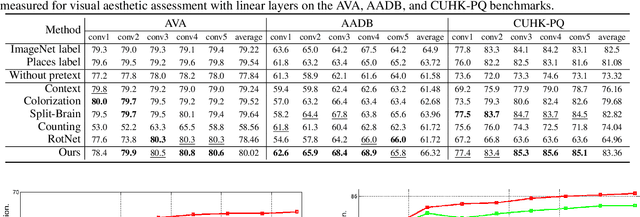
Visual aesthetic assessment has been an active research field for decades. Although latest methods have achieved promising performance on benchmark datasets, they typically rely on a large number of manual annotations including both aesthetic labels and related image attributes. In this paper, we revisit the problem of image aesthetic assessment from the self-supervised feature learning perspective. Our motivation is that a suitable feature representation for image aesthetic assessment should be able to distinguish different expert-designed image manipulations, which have close relationships with negative aesthetic effects. To this end, we design two novel pretext tasks to identify the types and parameters of editing operations applied to synthetic instances. The features from our pretext tasks are then adapted for a one-layer linear classifier to evaluate the performance in terms of binary aesthetic classification. We conduct extensive quantitative experiments on three benchmark datasets and demonstrate that our approach can faithfully extract aesthetics-aware features and outperform alternative pretext schemes. Moreover, we achieve comparable results to state-of-the-art supervised methods that use 10 million labels from ImageNet.
Superpixel-based Domain-Knowledge Infusion in Computer Vision
May 20, 2021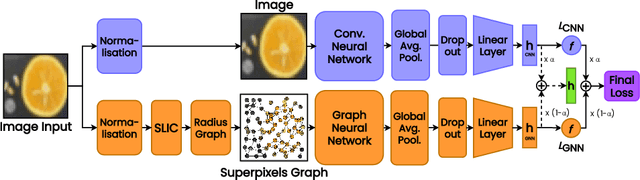

Superpixels are higher-order perceptual groups of pixels in an image, often carrying much more information than raw pixels. There is an inherent relational structure to the relationship among different superpixels of an image. This relational information can convey some form of domain information about the image, e.g. relationship between superpixels representing two eyes in a cat image. Our interest in this paper is to construct computer vision models, specifically those based on Deep Neural Networks (DNNs) to incorporate these superpixels information. We propose a methodology to construct a hybrid model that leverages (a) Convolutional Neural Network (CNN) to deal with spatial information in an image, and (b) Graph Neural Network (GNN) to deal with relational superpixel information in the image. The proposed deep model is learned using a generic hybrid loss function that we call a `hybrid' loss. We evaluate the predictive performance of our proposed hybrid vision model on four popular image classification datasets: MNIST, FMNIST, CIFAR-10 and CIFAR-100. Moreover, we evaluate our method on three real-world classification tasks: COVID-19 X-Ray Detection, LFW Face Recognition, and SOCOFing Fingerprint Identification. The results demonstrate that the relational superpixel information provided via a GNN could improve the performance of standard CNN-based vision systems.
Stomach 3D Reconstruction Based on Virtual Chromoendoscopic Image Generation
Apr 26, 2020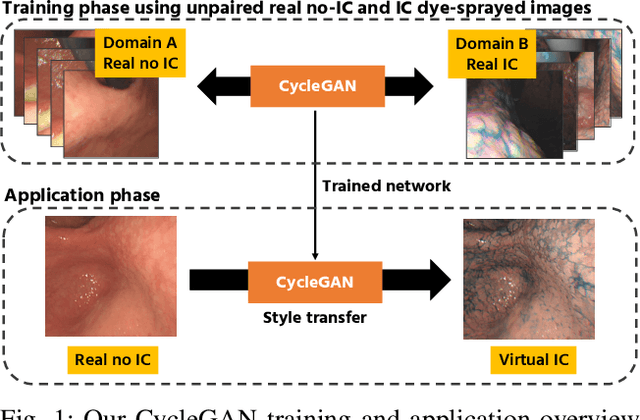
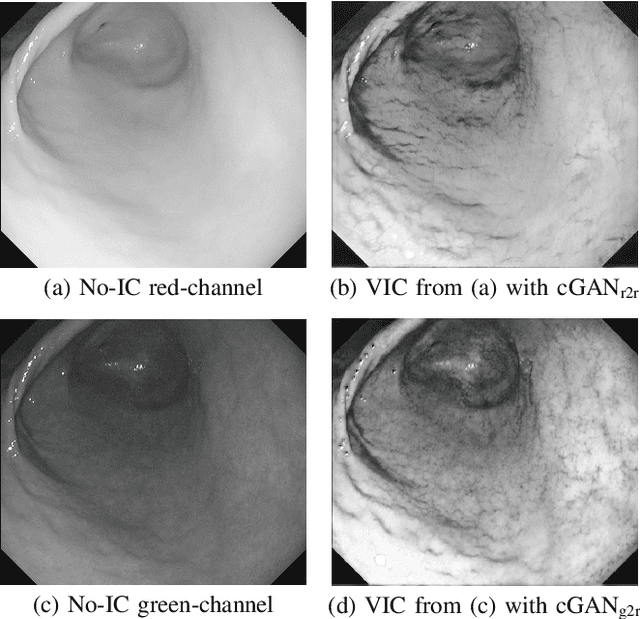
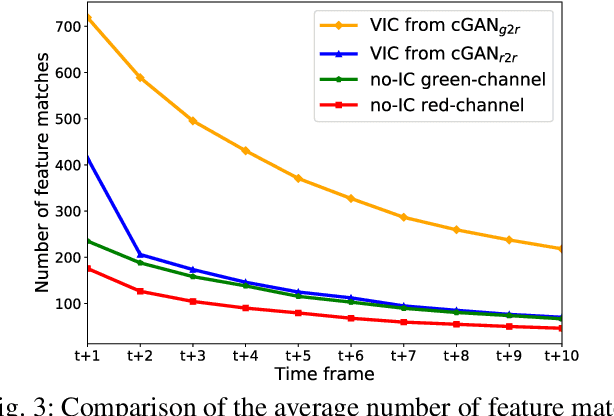

Gastric endoscopy is a standard clinical process that enables medical practitioners to diagnose various lesions inside a patient's stomach. If any lesion is found, it is very important to perceive the location of the lesion relative to the global view of the stomach. Our previous research showed that this could be addressed by reconstructing the whole stomach shape from chromoendoscopic images using a structure-from-motion (SfM) pipeline, in which indigo carmine (IC) blue dye sprayed images were used to increase feature matches for SfM by enhancing stomach surface's textures. However, spraying the IC dye to the whole stomach requires additional time, labor, and cost, which is not desirable for patients and practitioners. In this paper, we propose an alternative way to achieve whole stomach 3D reconstruction without the need of the IC dye by generating virtual IC-sprayed (VIC) images based on image-to-image style translation trained on unpaired real no-IC and IC-sprayed images. We have specifically investigated the effect of input and output color channel selection for generating the VIC images and found that translating no-IC green-channel images to IC-sprayed red-channel images gives the best SfM reconstruction result.
Diversity Matters When Learning From Ensembles
Oct 27, 2021
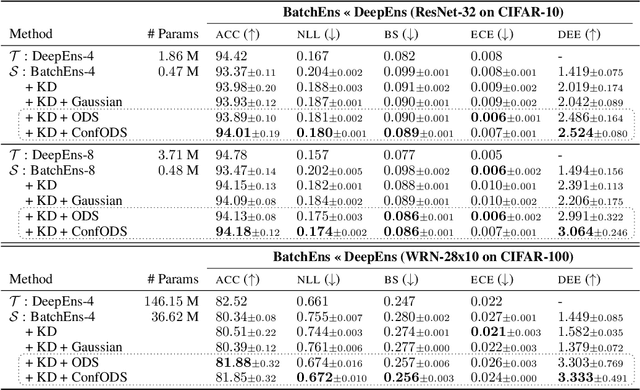
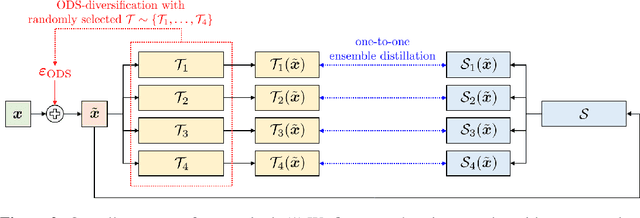
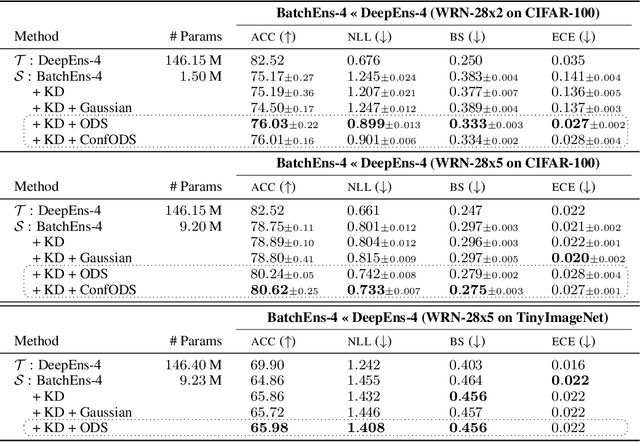
Deep ensembles excel in large-scale image classification tasks both in terms of prediction accuracy and calibration. Despite being simple to train, the computation and memory cost of deep ensembles limits their practicability. While some recent works propose to distill an ensemble model into a single model to reduce such costs, there is still a performance gap between the ensemble and distilled models. We propose a simple approach for reducing this gap, i.e., making the distilled performance close to the full ensemble. Our key assumption is that a distilled model should absorb as much function diversity inside the ensemble as possible. We first empirically show that the typical distillation procedure does not effectively transfer such diversity, especially for complex models that achieve near-zero training error. To fix this, we propose a perturbation strategy for distillation that reveals diversity by seeking inputs for which ensemble member outputs disagree. We empirically show that a model distilled with such perturbed samples indeed exhibits enhanced diversity, leading to improved performance.