 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
2nd Place Solution to Google Landmark Recognition Competition 2021
Oct 07, 2021
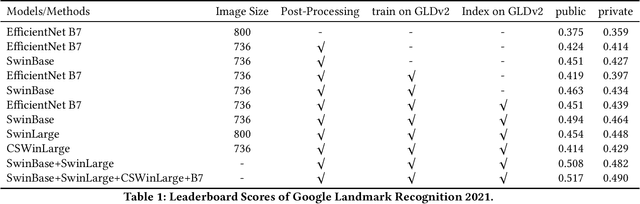
As Transformer-based architectures have recently shown encouraging progresses in computer vision. In this work, we present the solution to the Google Landmark Recognition 2021 Challenge held on Kaggle, which is an improvement on our last year's solution by changing three designs, including (1) Using Swin and CSWin as backbone for feature extraction, (2) Train on full GLDv2, and (3) Using full GLDv2 images as index image set for kNN search. With these modifications, our solution significantly improves last year solution on this year competition. Our full pipeline, after ensembling Swin, CSWin, EfficientNet B7 models, scores 0.4907 on the private leaderboard which help us to get the 2nd place in the competition.
Re-using Adversarial Mask Discriminators for Test-time Training under Distribution Shifts
Aug 26, 2021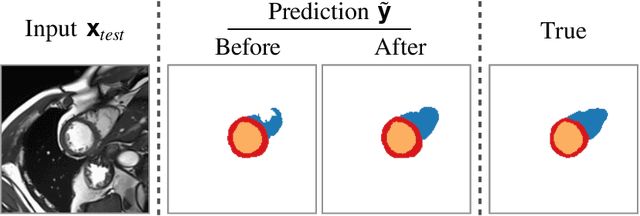

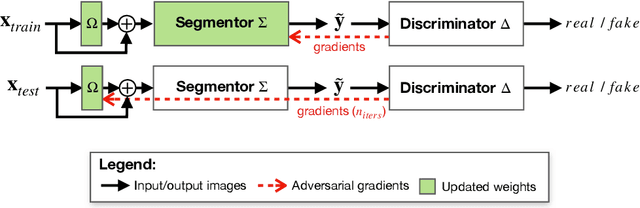

Thanks to their ability to learn flexible data-driven losses, Generative Adversarial Networks (GANs) are an integral part of many semi- and weakly-supervised methods for medical image segmentation. GANs jointly optimise a generator and an adversarial discriminator on a set of training data. After training has completed, the discriminator is usually discarded and only the generator is used for inference. But should we discard discriminators? In this work, we argue that training stable discriminators produces expressive loss functions that we can re-use at inference to detect and correct segmentation mistakes. First, we identify key challenges and suggest possible solutions to make discriminators re-usable at inference. Then, we show that we can combine discriminators with image reconstruction costs (via decoders) to further improve the model. Our method is simple and improves the test-time performance of pre-trained GANs. Moreover, we show that it is compatible with standard post-processing techniques and it has potentials to be used for Online Continual Learning. With our work, we open new research avenues for re-using adversarial discriminators at inference.
F-CAM: Full Resolution CAM via Guided Parametric Upscaling
Sep 15, 2021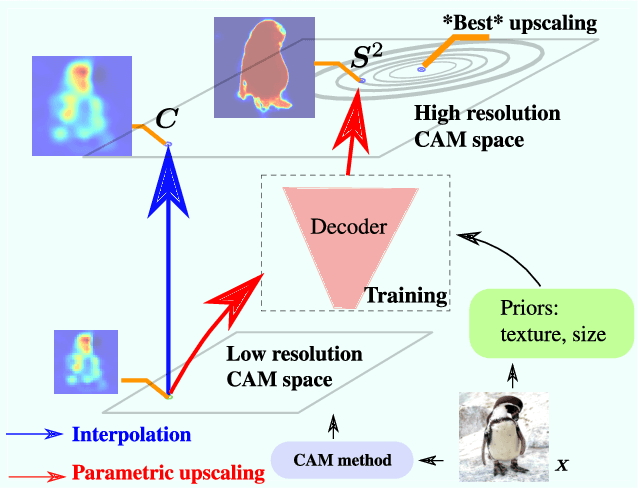
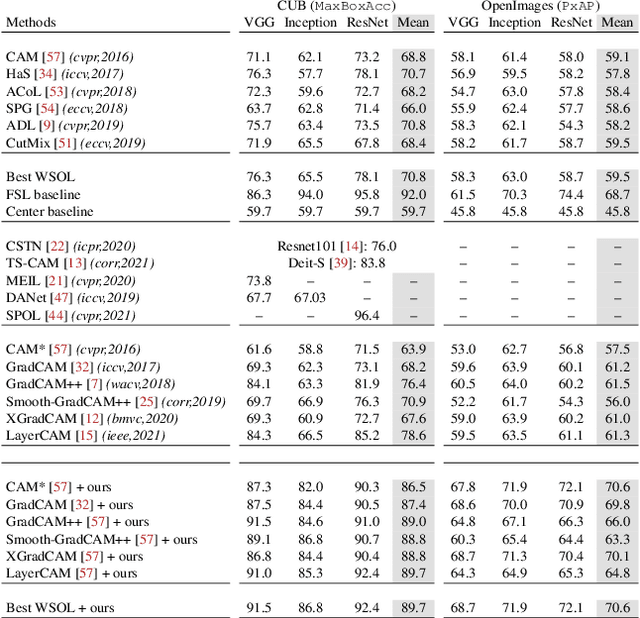
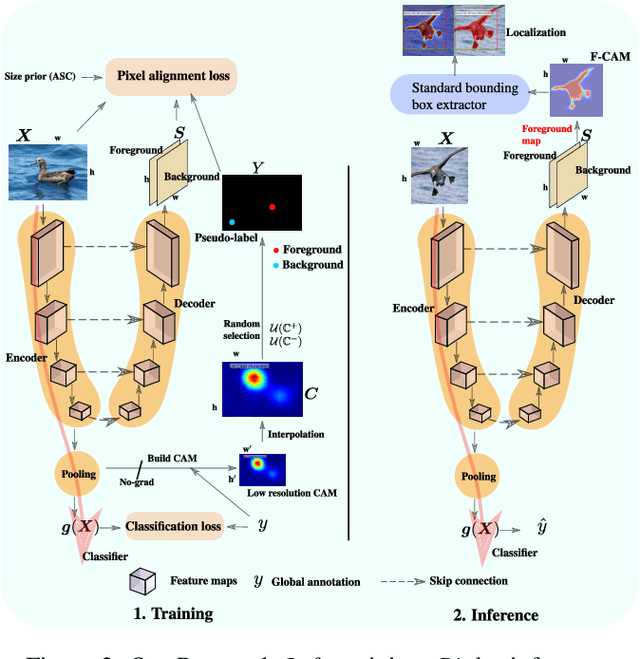
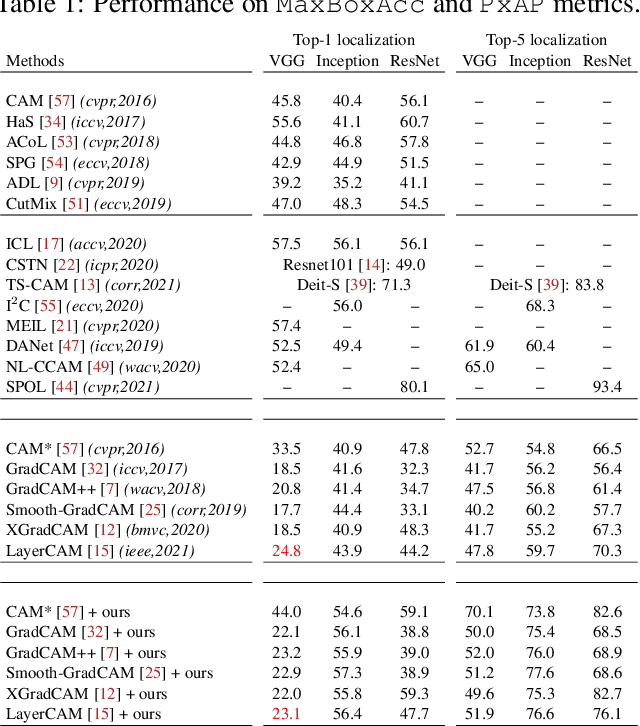
Class Activation Mapping (CAM) methods have recently gained much attention for weakly-supervised object localization (WSOL) tasks, allowing for CNN visualization and interpretation without training on fully annotated image datasets. CAM methods are typically integrated within off-the-shelf CNN backbones, such as ResNet50. Due to convolution and downsampling/pooling operations, these backbones yield low resolution CAMs with a down-scaling factor of up to 32, making accurate localization more difficult. Interpolation is required to restore a full size CAMs, but without considering the statistical properties of the objects, leading to activations with inconsistent boundaries and inaccurate localizations. As an alternative, we introduce a generic method for parametric upscaling of CAMs that allows constructing accurate full resolution CAMs (F-CAMs). In particular, we propose a trainable decoding architecture that can be connected to any CNN classifier to produce more accurate CAMs. Given an original (low resolution) CAM, foreground and background pixels are randomly sampled for fine-tuning the decoder. Additional priors such as image statistics, and size constraints are also considered to expand and refine object boundaries. Extensive experiments using three CNN backbones and six WSOL baselines on the CUB-200-2011 and OpenImages datasets, indicate that our F-CAM method yields a significant improvement in CAM localization accuracy. F-CAM performance is competitive with state-of-art WSOL methods, yet it requires fewer computational resources during inference.
Vision Transformer for Classification of Breast Ultrasound Images
Oct 27, 2021
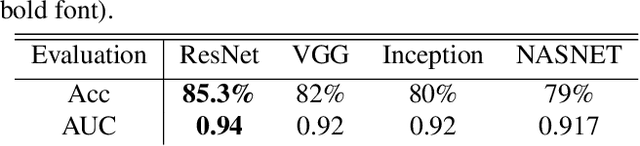
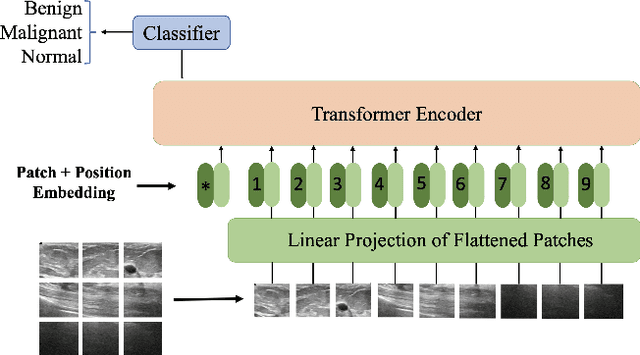

Medical ultrasound (US) imaging has become a prominent modality for breast cancer imaging due to its ease-of-use, low-cost and safety. In the past decade, convolutional neural networks (CNNs) have emerged as the method of choice in vision applications and have shown excellent potential in automatic classification of US images. Despite their success, their restricted local receptive field limits their ability to learn global context information. Recently, Vision Transformer (ViT) designs that are based on self-attention between image patches have shown great potential to be an alternative to CNNs. In this study, for the first time, we utilize ViT to classify breast US images using different augmentation strategies. The results are provided as classification accuracy and Area Under the Curve (AUC) metrics, and the performance is compared with the state-of-the-art CNNs. The results indicate that the ViT models have comparable efficiency with or even better than the CNNs in classification of US breast images.
Highly accelerated MR parametric mapping by undersampling the k-space and reducing the contrast number simultaneously with deep learning
Dec 01, 2021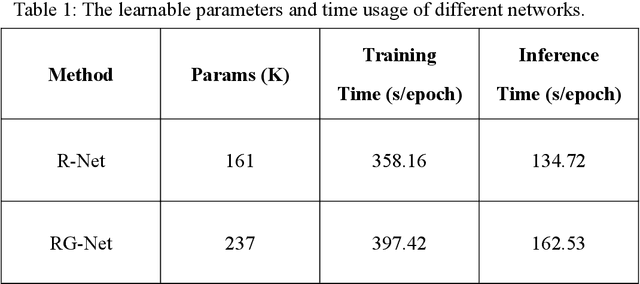
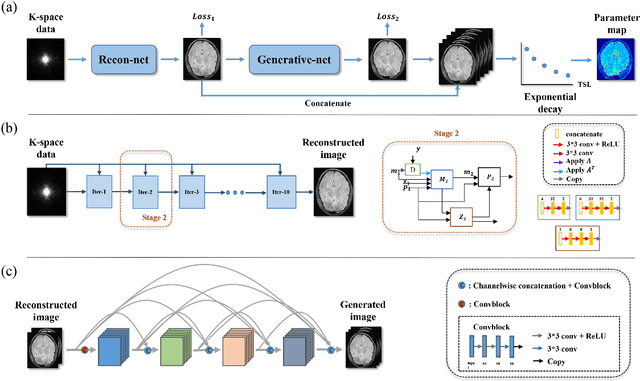
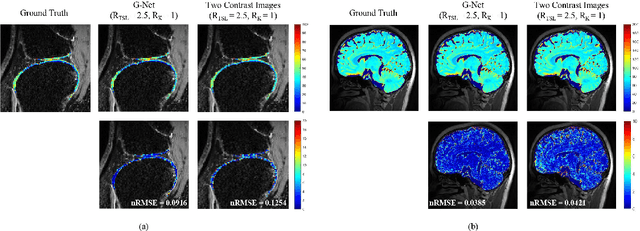
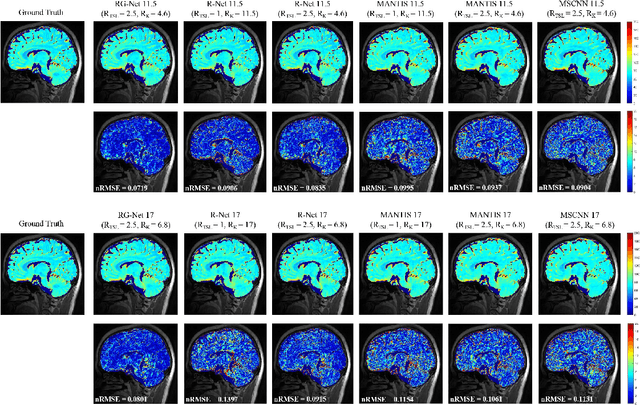
Purpose: To propose a novel deep learning-based method called RG-Net (reconstruction and generation network) for highly accelerated MR parametric mapping by undersampling k-space and reducing the acquired contrast number simultaneously. Methods: The proposed framework consists of a reconstruction module and a generative module. The reconstruction module reconstructs MR images from the acquired few undersampled k-space data with the help of a data prior. The generative module then synthesizes the remaining multi-contrast images from the reconstructed images, where the exponential model is implicitly incorporated into the image generation through the supervision of fully sampled labels. The RG-Net was evaluated on the T1\r{ho} mapping data of knee and brain at different acceleration rates. Regional T1\r{ho} analysis for cartilage and the brain was performed to access the performance of RG-Net. Results: RG-Net yields a high-quality T1\r{ho} map at a high acceleration rate of 17. Compared with the competing methods that only undersample k-space, our framework achieves better performance in T1\r{ho} value analysis. Our method also improves quality of T1\r{ho} maps on patient with glioma. Conclusion: The proposed RG-Net that adopted a new strategy by undersampling k-space and reducing the contrast number simultaneously for fast MR parametric mapping, can achieve a high acceleration rate while maintaining good reconstruction quality. The generative module of our framework can also be used as an insert module in other fast MR parametric mapping methods. Keywords: Deep learning, convolutional neural network, fast MR parametric mapping
CoVA: Context-aware Visual Attention for Webpage Information Extraction
Oct 24, 2021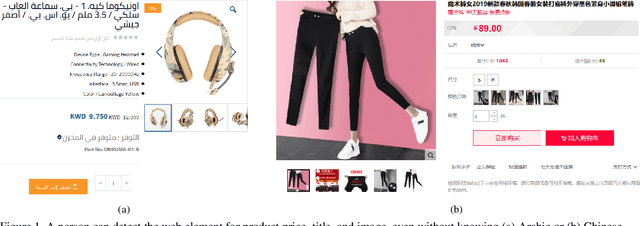
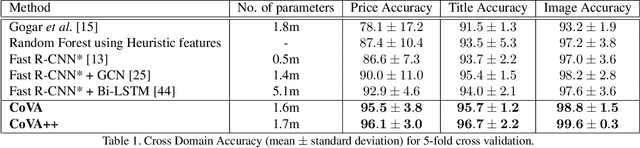
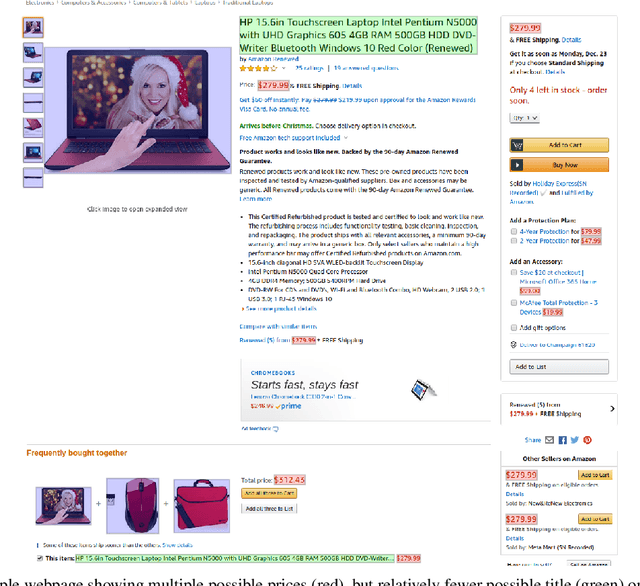
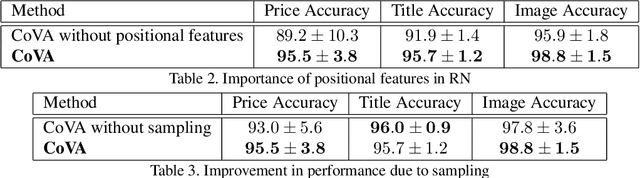
Webpage information extraction (WIE) is an important step to create knowledge bases. For this, classical WIE methods leverage the Document Object Model (DOM) tree of a website. However, use of the DOM tree poses significant challenges as context and appearance are encoded in an abstract manner. To address this challenge we propose to reformulate WIE as a context-aware Webpage Object Detection task. Specifically, we develop a Context-aware Visual Attention-based (CoVA) detection pipeline which combines appearance features with syntactical structure from the DOM tree. To study the approach we collect a new large-scale dataset of e-commerce websites for which we manually annotate every web element with four labels: product price, product title, product image and background. On this dataset we show that the proposed CoVA approach is a new challenging baseline which improves upon prior state-of-the-art methods.
Improved Few-shot Segmentation by Redefinition of the Roles of Multi-level CNN Features
Sep 15, 2021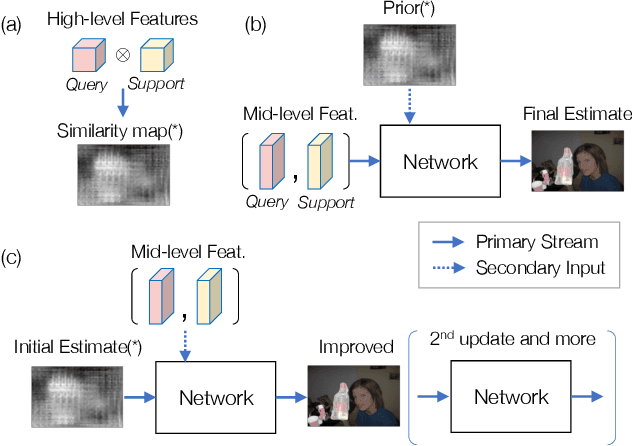

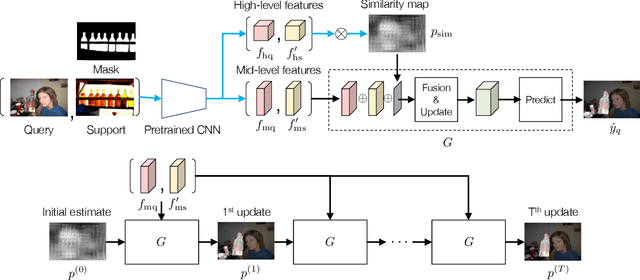
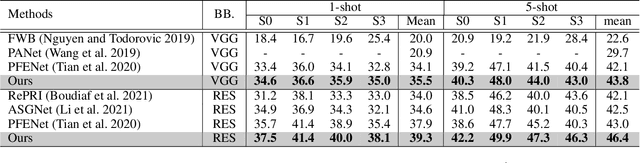
This study is concerned with few-shot segmentation, i.e., segmenting the region of an unseen object class in a query image, given support image(s) of its instances. The current methods rely on the pretrained CNN features of the support and query images. The key to good performance depends on the proper fusion of their mid-level and high-level features; the former contains shape-oriented information, while the latter has class-oriented information. Current state-of-the-art methods follow the approach of Tian et al., which gives the mid-level features the primary role and the high-level features the secondary role. In this paper, we reinterpret this widely employed approach by redifining the roles of the multi-level features; we swap the primary and secondary roles. Specifically, we regard that the current methods improve the initial estimate generated from the high-level features using the mid-level features. This reinterpretation suggests a new application of the current methods: to apply the same network multiple times to iteratively update the estimate of the object's region, starting from its initial estimate. Our experiments show that this method is effective and has updated the previous state-of-the-art on COCO-20$^i$ in the 1-shot and 5-shot settings and on PASCAL-5$^i$ in the 1-shot setting.
FAST: Searching for a Faster Arbitrarily-Shaped Text Detector with Minimalist Kernel Representation
Nov 03, 2021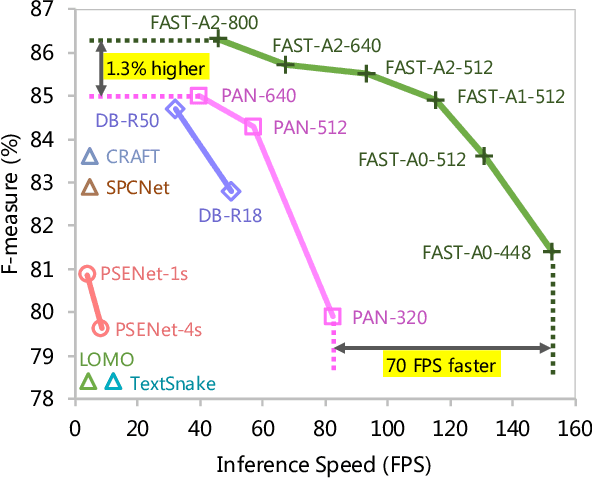
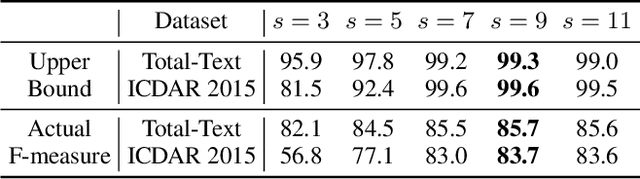
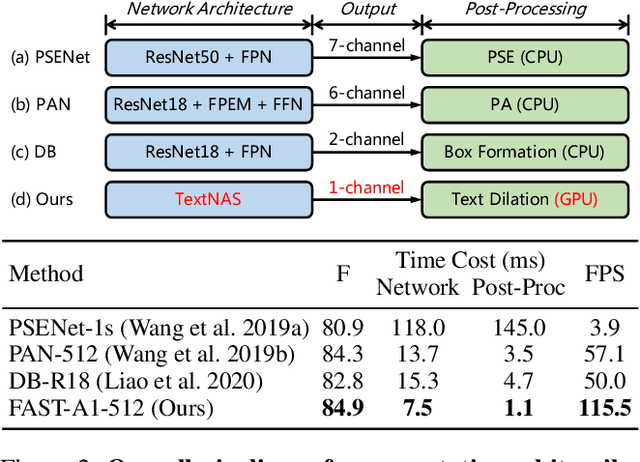
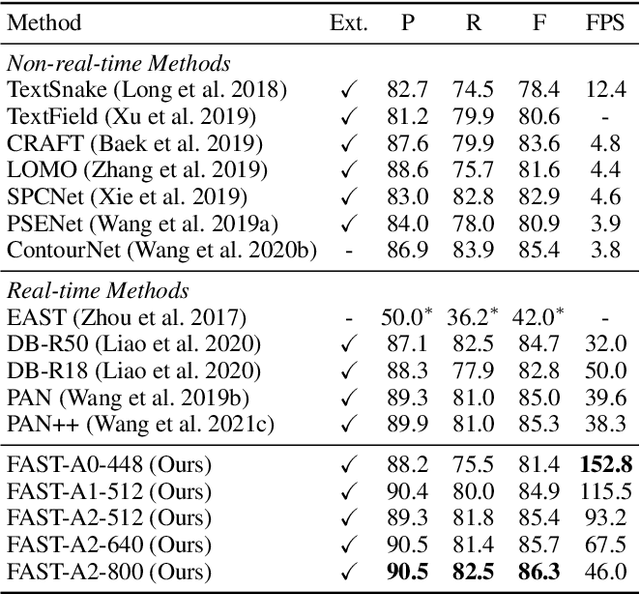
We propose an accurate and efficient scene text detection framework, termed FAST (i.e., faster arbitrarily-shaped text detector). Different from recent advanced text detectors that used hand-crafted network architectures and complicated post-processing, resulting in low inference speed, FAST has two new designs. (1) We search the network architecture by designing a network search space and reward function carefully tailored for text detection, leading to more powerful features than most networks that are searched for image classification. (2) We design a minimalist representation (only has 1-channel output) to model text with arbitrary shape, as well as a GPU-parallel post-processing to efficiently assemble text lines with negligible time overhead. Benefiting from these two designs, FAST achieves an excellent trade-off between accuracy and efficiency on several challenging datasets. For example, FAST-A0 yields 81.4% F-measure at 152 FPS on Total-Text, outperforming the previous fastest method by 1.5 points and 70 FPS in terms of accuracy and speed. With TensorRT optimization, the inference speed can be further accelerated to over 600 FPS.
Off-Policy Actor-Critic with Emphatic Weightings
Nov 16, 2021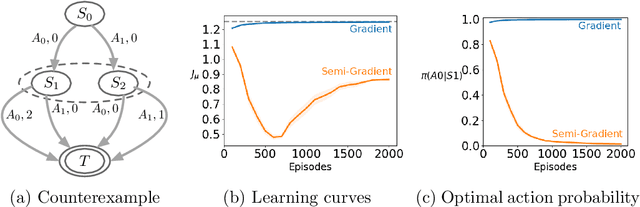
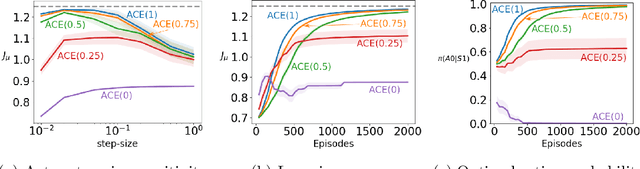
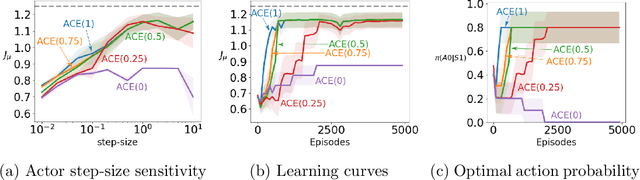
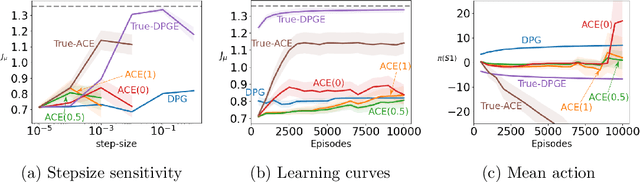
A variety of theoretically-sound policy gradient algorithms exist for the on-policy setting due to the policy gradient theorem, which provides a simplified form for the gradient. The off-policy setting, however, has been less clear due to the existence of multiple objectives and the lack of an explicit off-policy policy gradient theorem. In this work, we unify these objectives into one off-policy objective, and provide a policy gradient theorem for this unified objective. The derivation involves emphatic weightings and interest functions. We show multiple strategies to approximate the gradients, in an algorithm called Actor Critic with Emphatic weightings (ACE). We prove in a counterexample that previous (semi-gradient) off-policy actor-critic methods--particularly OffPAC and DPG--converge to the wrong solution whereas ACE finds the optimal solution. We also highlight why these semi-gradient approaches can still perform well in practice, suggesting strategies for variance reduction in ACE. We empirically study several variants of ACE on two classic control environments and an image-based environment designed to illustrate the tradeoffs made by each gradient approximation. We find that by approximating the emphatic weightings directly, ACE performs as well as or better than OffPAC in all settings tested.
DASGIL: Domain Adaptation for Semantic and Geometric-aware Image-based Localization
Oct 01, 2020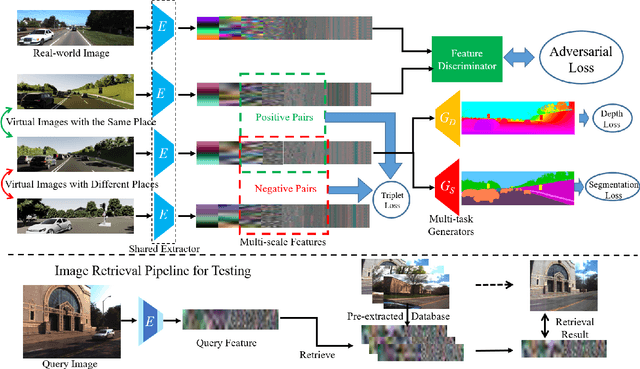
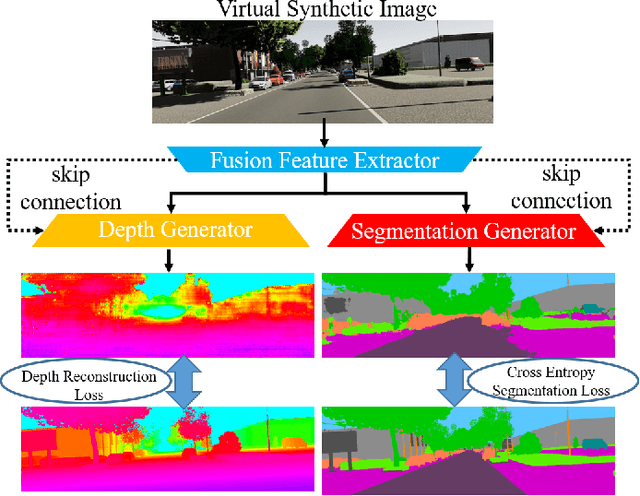
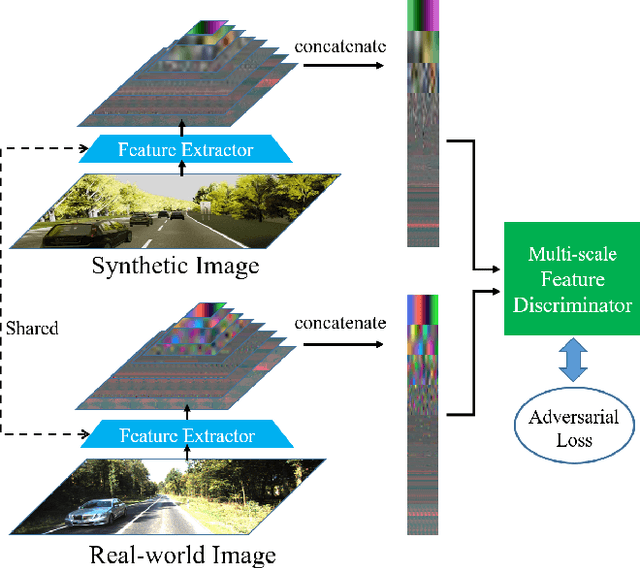
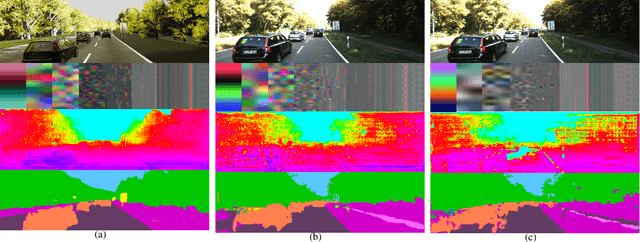
Long-Term visual localization under changing environments is a challenging problem in autonomous driving and mobile robotics due to season, illumination variance, etc. Image retrieval for localization is an efficient and effective solution to the problem. In this paper, we propose a novel multi-task architecture to fuse the geometric and semantic information into the multi-scale latent embedding representation for visual place recognition. To use the high-quality ground truths without any human effort, depth and segmentation generator model is trained on virtual synthetic dataset and domain adaptation is adopted from synthetic to real-world dataset. The multi-scale model presents the strong generalization ability on real-world KITTI dataset though trained on the virtual KITTI 2 dataset. The proposed approach is validated on the Extended CMU-Seasons dataset through a series of crucial comparison experiments, where our performance outperforms state-of-the-art baselines for retrieval-based localization under the challenging environment.