 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Self-Supervised Monocular Depth Estimation with Internal Feature Fusion
Oct 20, 2021
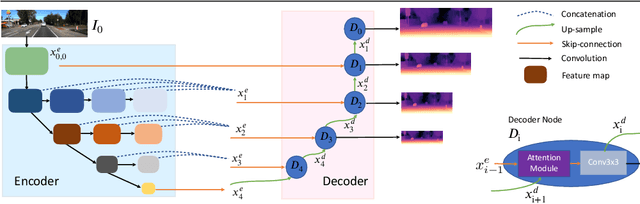
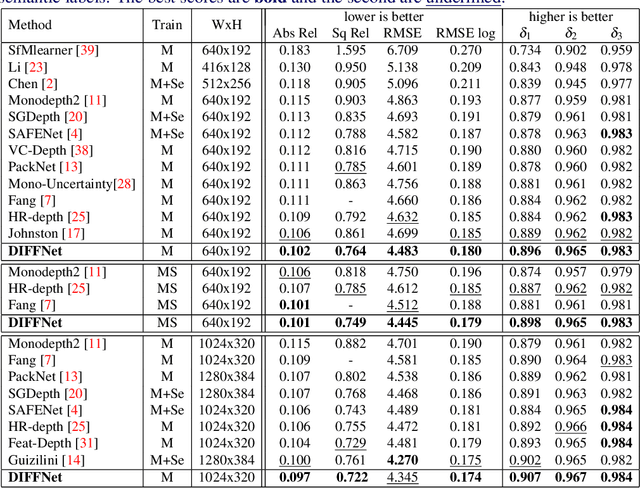

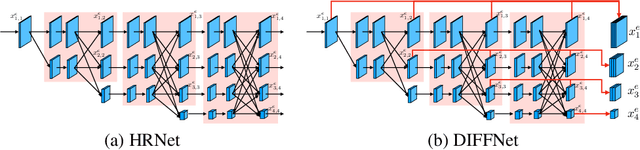
Self-supervised learning for depth estimation uses geometry in image sequences for supervision and shows promising results. Like many computer vision tasks, depth network performance is determined by the capability to learn accurate spatial and semantic representations from images. Therefore, it is natural to exploit semantic segmentation networks for depth estimation. In this work, based on a well-developed semantic segmentation network HRNet, we propose a novel depth estimation networkDIFFNet, which can make use of semantic information in down and upsampling procedures. By applying feature fusion and an attention mechanism, our proposed method outperforms the state-of-the-art monocular depth estimation methods on the KITTI benchmark. Our method also demonstrates greater potential on higher resolution training data. We propose an additional extended evaluation strategy by establishing a test set of challenging cases, empirically derived from the standard benchmark.
MarkupLM: Pre-training of Text and Markup Language for Visually-rich Document Understanding
Oct 16, 2021

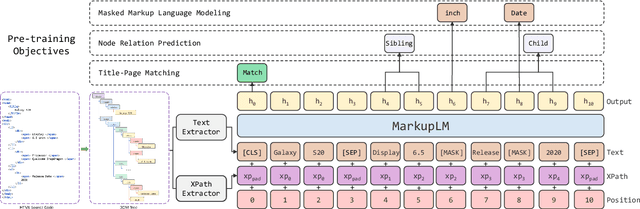
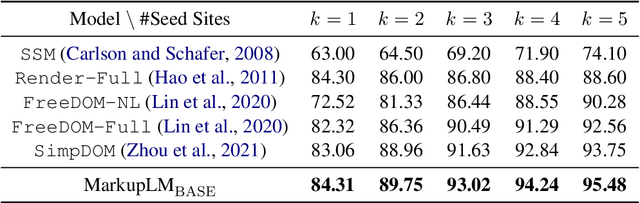
Multimodal pre-training with text, layout, and image has made significant progress for Visually-rich Document Understanding (VrDU), especially the fixed-layout documents such as scanned document images. While, there are still a large number of digital documents where the layout information is not fixed and needs to be interactively and dynamically rendered for visualization, making existing layout-based pre-training approaches not easy to apply. In this paper, we propose MarkupLM for document understanding tasks with markup languages as the backbone such as HTML/XML-based documents, where text and markup information is jointly pre-trained. Experiment results show that the pre-trained MarkupLM significantly outperforms the existing strong baseline models on several document understanding tasks. The pre-trained model and code will be publicly available at https://aka.ms/markuplm.
Detecting Backdoor in Deep Neural Networks via Intentional Adversarial Perturbations
May 29, 2021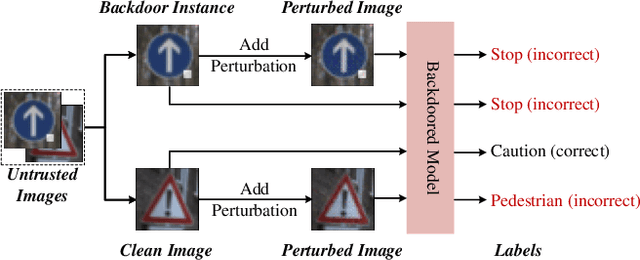
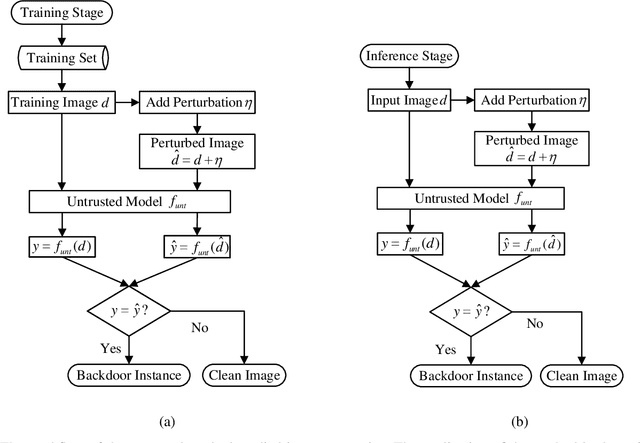


Recent researches show that deep learning model is susceptible to backdoor attacks where the backdoor embedded in the model will be triggered when a backdoor instance arrives. In this paper, a novel backdoor detection method based on adversarial examples is proposed. The proposed method leverages intentional adversarial perturbations to detect whether the image contains a trigger, which can be applied in two scenarios (sanitize the training set in training stage and detect the backdoor instances in inference stage). Specifically, given an untrusted image, the adversarial perturbation is added to the input image intentionally, if the prediction of model on the perturbed image is consistent with that on the unperturbed image, the input image will be considered as a backdoor instance. The proposed adversarial perturbation based method requires low computational resources and maintains the visual quality of the images. Experimental results show that, the proposed defense method reduces the backdoor attack success rates from 99.47%, 99.77% and 97.89% to 0.37%, 0.24% and 0.09% on Fashion-MNIST, CIFAR-10 and GTSRB datasets, respectively. Besides, the proposed method maintains the visual quality of the image as the added perturbation is very small. In addition, for attacks under different settings (trigger transparency, trigger size and trigger pattern), the false acceptance rates of the proposed method are as low as 1.2%, 0.3% and 0.04% on Fashion-MNIST, CIFAR-10 and GTSRB datasets, respectively, which demonstrates that the proposed method can achieve high defense performance against backdoor attacks under different attack settings.
DeepTracks: Geopositioning Maritime Vehicles in Video Acquired from a Moving Platform
Sep 02, 2021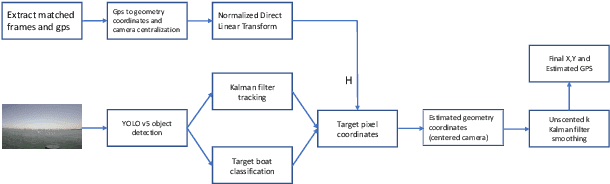
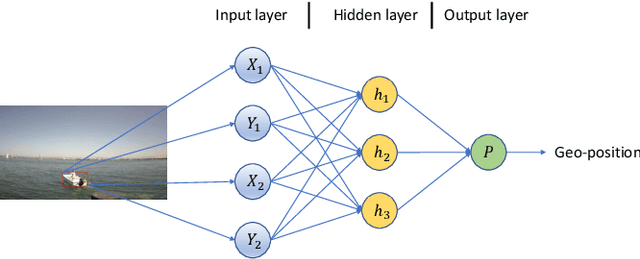
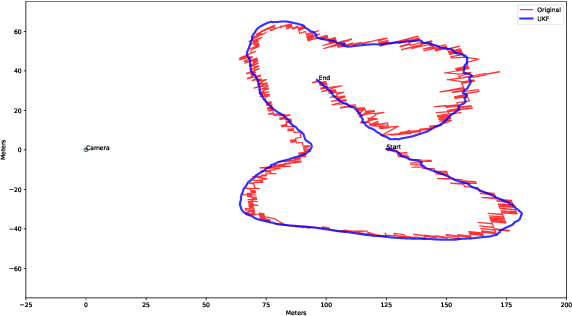
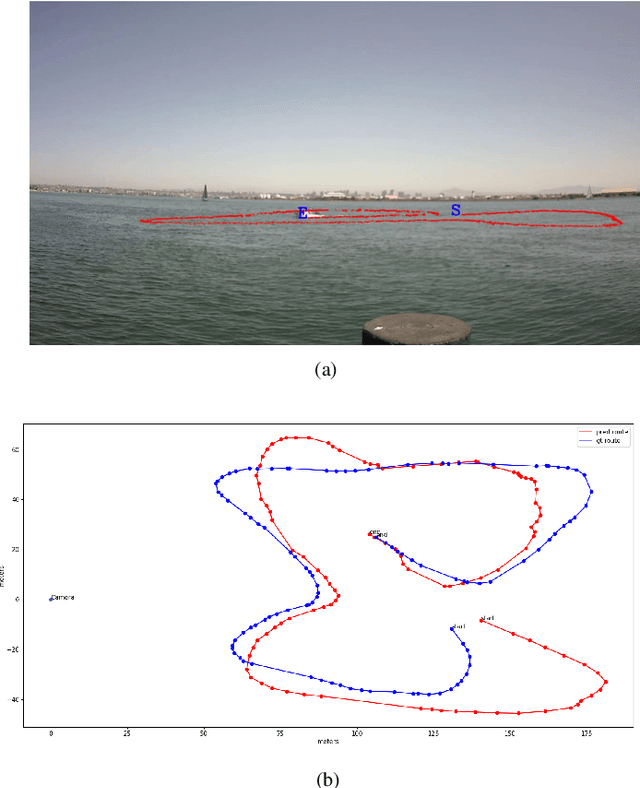
Geopositioning and tracking a moving boat at sea is a very challenging problem, requiring boat detection, matching and estimating its GPS location from imagery with no common features. The problem can be stated as follows: given imagery from a camera mounted on a moving platform with known GPS location as the only valid sensor, we predict the geoposition of a target boat visible in images. Our solution uses recent ML algorithms, the camera-scene geometry and Bayesian filtering. The proposed pipeline first detects and tracks the target boat's location in the image with the strategy of tracking by detection. This image location is then converted to geoposition to the local sea coordinates referenced to the camera GPS location using plane projective geometry. Finally, target boat local coordinates are transformed to global GPS coordinates to estimate the geoposition. To achieve a smooth geotrajectory, we apply unscented Kalman filter (UKF) which implicitly overcomes small detection errors in the early stages of the pipeline. We tested the performance of our approach using GPS ground truth and show the accuracy and speed of the estimated geopositions. Our code is publicly available at https://github.com/JianliWei1995/AI-Track-at-Sea.
Exploring Explicit Domain Supervision for Latent Space Disentanglement in Unpaired Image-to-Image Translation
Mar 26, 2019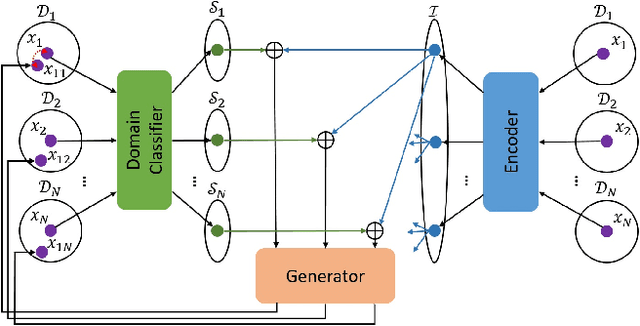
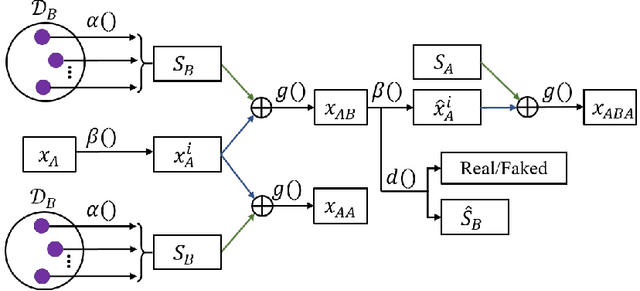

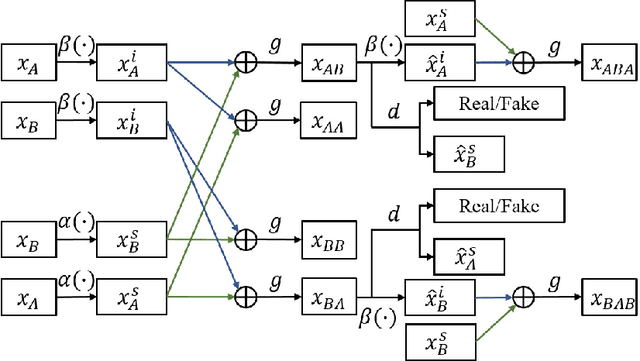
Image-to-image translation tasks have been widely investigated with Generative Adversarial Networks (GANs). However, existing approaches are mostly designed in an unsupervised manner while little attention has been paid to domain information within unpaired data. In this paper, we treat domain information as explicit supervision and design an unpaired image-to-image translation framework, Domain-supervised GAN (DosGAN), which takes the first step towards the exploration of explicit domain supervision. In contrast to representing domain characteristics using different generators in CycleGAN or multiple domain codes in StarGAN, we pre-train a classification network to explicitly classify the domain of an image. After pre-training, this network is used to extract the domain-specific features of each image by using the output of its second-to-last layer. Such features, together with the domain-independent features extracted by another encoder (shared across different domains), are used to generate an image in the target domain. Extensive experiments on multiple hair color translation, multiple identity translation, multiple season translation and conditional edges-to-shoes/handbags demonstrate the effectiveness of our method. In addition, we can transfer the domain-specific feature extractor obtained on the Facescrub dataset with domain supervision information to unseen domains, such as faces in the CelebA dataset. We also succeed in achieving conditional translation with any two images in CelebA, while previous models like StarGAN cannot handle this task.
Counterfactual Attention Learning for Fine-Grained Visual Categorization and Re-identification
Aug 19, 2021
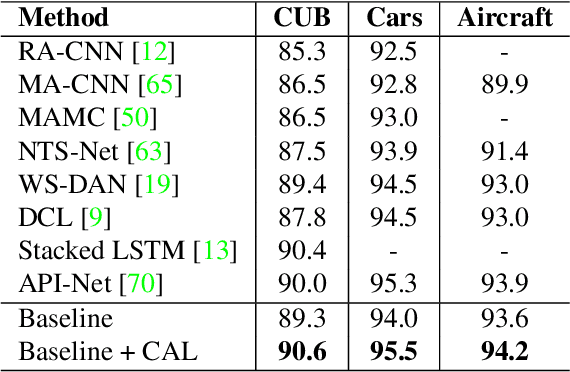
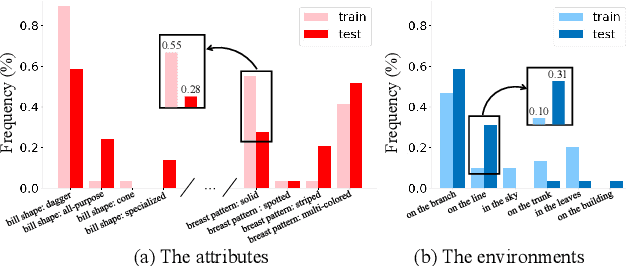
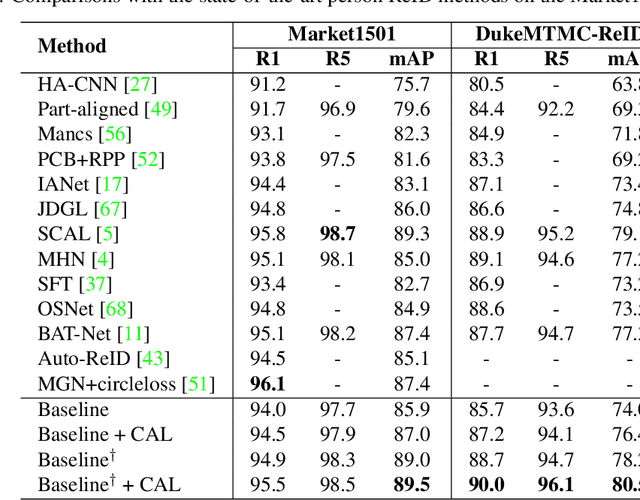
Attention mechanism has demonstrated great potential in fine-grained visual recognition tasks. In this paper, we present a counterfactual attention learning method to learn more effective attention based on causal inference. Unlike most existing methods that learn visual attention based on conventional likelihood, we propose to learn the attention with counterfactual causality, which provides a tool to measure the attention quality and a powerful supervisory signal to guide the learning process. Specifically, we analyze the effect of the learned visual attention on network prediction through counterfactual intervention and maximize the effect to encourage the network to learn more useful attention for fine-grained image recognition. Empirically, we evaluate our method on a wide range of fine-grained recognition tasks where attention plays a crucial role, including fine-grained image categorization, person re-identification, and vehicle re-identification. The consistent improvement on all benchmarks demonstrates the effectiveness of our method. Code is available at https://github.com/raoyongming/CAL
Hierarchical Attention Networks for Medical Image Segmentation
Nov 20, 2019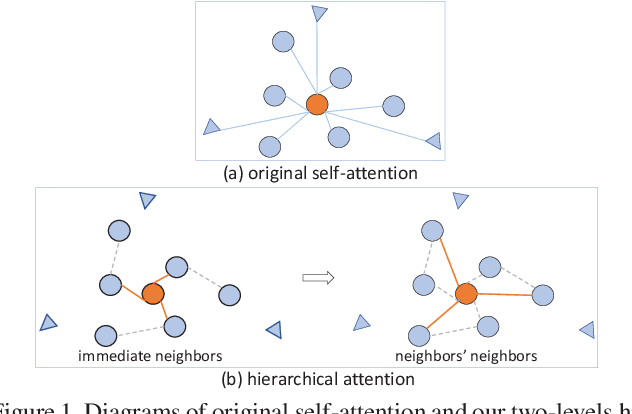
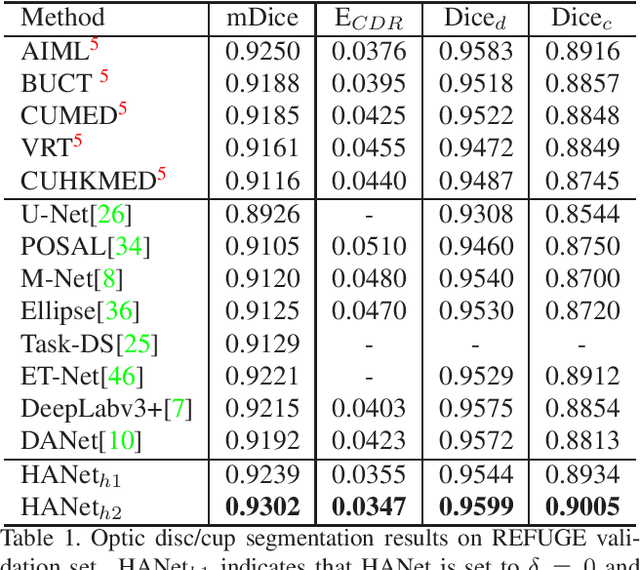
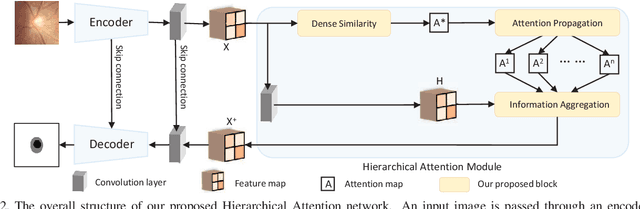
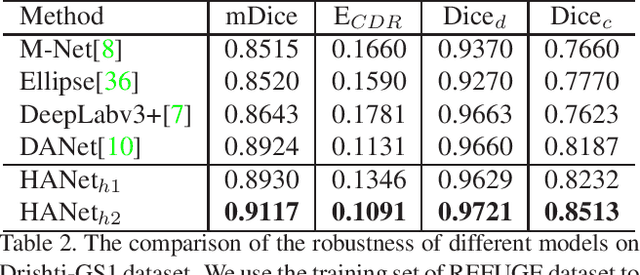
The medical image is characterized by the inter-class indistinction, high variability, and noise, where the recognition of pixels is challenging. Unlike previous self-attention based methods that capture context information from one level, we reformulate the self-attention mechanism from the view of the high-order graph and propose a novel method, namely Hierarchical Attention Network (HANet), to address the problem of medical image segmentation. Concretely, an HA module embedded in the HANet captures context information from neighbors of multiple levels, where these neighbors are extracted from the high-order graph. In the high-order graph, there will be an edge between two nodes only if the correlation between them is high enough, which naturally reduces the noisy attention information caused by the inter-class indistinction. The proposed HA module is robust to the variance of input and can be flexibly inserted into the existing convolution neural networks. We conduct experiments on three medical image segmentation tasks including optic disc/cup segmentation, blood vessel segmentation, and lung segmentation. Extensive results show our method is more effective and robust than the existing state-of-the-art methods.
Deep Direct Visual Servoing of Tendon-Driven Continuum Robots
Nov 04, 2021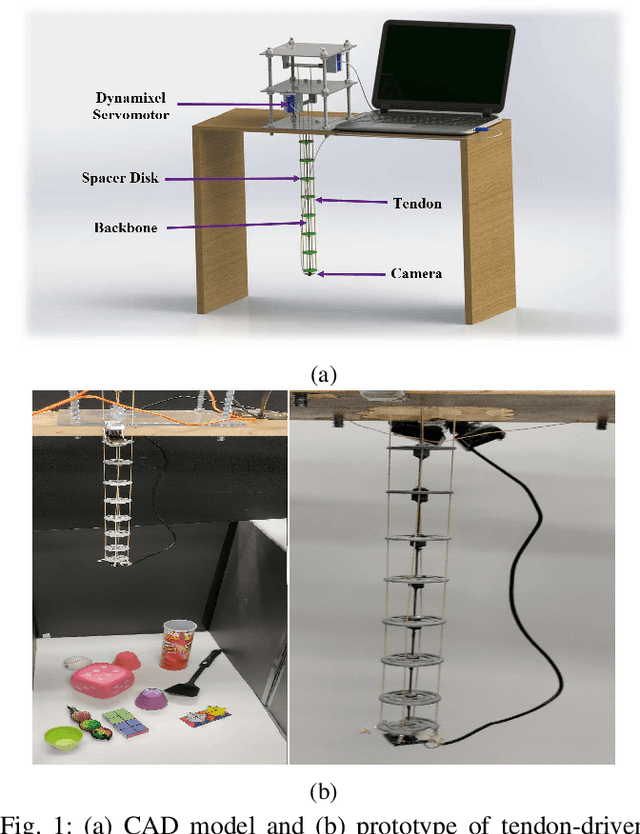

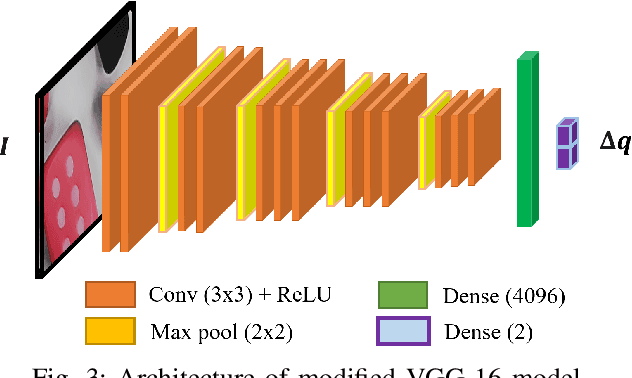

Vision-based control has found a key place in the research to tackle the requirement of the state feedback when controlling a continuum robot under physical sensing limitations. Traditional visual servoing requires feature extraction and tracking while the imaging device captures the images, which limits the controller's efficiency. We hypothesize that employing deep learning models and implementing direct visual servoing can effectively resolve the issue by eliminating the tracking requirement and controlling the continuum robot without requiring an exact system model. In this paper, we control a single-section tendon-driven continuum robot utilizing a modified VGG-16 deep learning network and an eye-in-hand direct visual servoing approach. The proposed algorithm is first developed in Blender using only one input image of the target and then implemented on a real robot. The convergence and accuracy of the results in normal, shadowed, and occluded scenes reflected by the sum of absolute difference between the normalized target and captured images prove the effectiveness and robustness of the proposed controller.
Shape from Blur: Recovering Textured 3D Shape and Motion of Fast Moving Objects
Jun 16, 2021
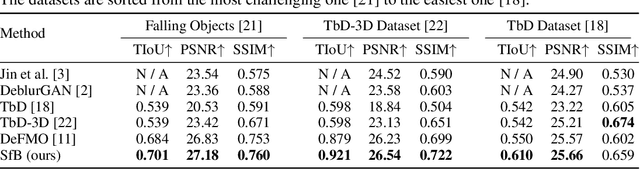
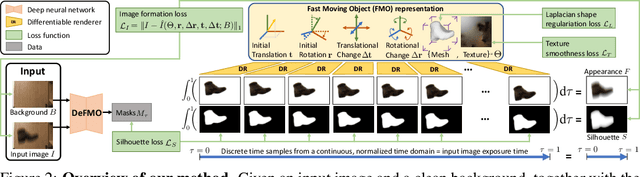
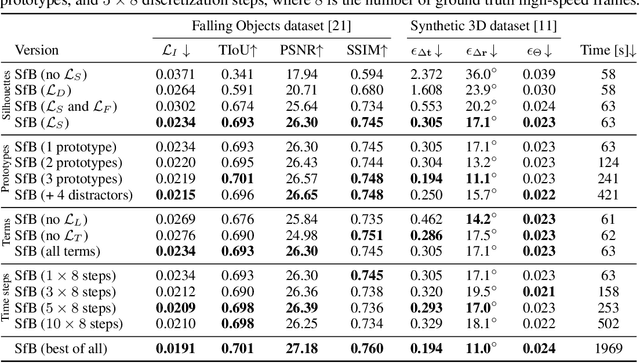
We address the novel task of jointly reconstructing the 3D shape, texture, and motion of an object from a single motion-blurred image. While previous approaches address the deblurring problem only in the 2D image domain, our proposed rigorous modeling of all object properties in the 3D domain enables the correct description of arbitrary object motion. This leads to significantly better image decomposition and sharper deblurring results. We model the observed appearance of a motion-blurred object as a combination of the background and a 3D object with constant translation and rotation. Our method minimizes a loss on reconstructing the input image via differentiable rendering with suitable regularizers. This enables estimating the textured 3D mesh of the blurred object with high fidelity. Our method substantially outperforms competing approaches on several benchmarks for fast moving objects deblurring. Qualitative results show that the reconstructed 3D mesh generates high-quality temporal super-resolution and novel views of the deblurred object.
Batch Curation for Unsupervised Contrastive Representation Learning
Aug 19, 2021
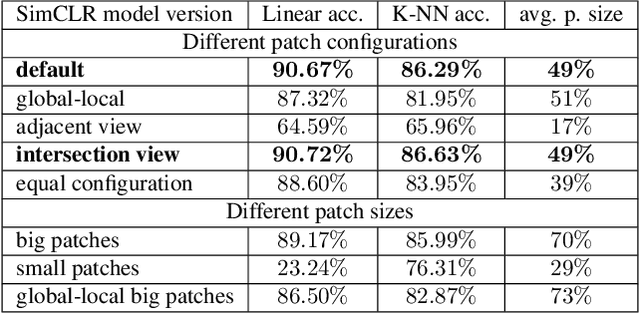

The state-of-the-art unsupervised contrastive visual representation learning methods that have emerged recently (SimCLR, MoCo, SwAV) all make use of data augmentations in order to construct a pretext task of instant discrimination consisting of similar and dissimilar pairs of images. Similar pairs are constructed by randomly extracting patches from the same image and applying several other transformations such as color jittering or blurring, while transformed patches from different image instances in a given batch are regarded as dissimilar pairs. We argue that this approach can result similar pairs that are \textit{semantically} dissimilar. In this work, we address this problem by introducing a \textit{batch curation} scheme that selects batches during the training process that are more inline with the underlying contrastive objective. We provide insights into what constitutes beneficial similar and dissimilar pairs as well as validate \textit{batch curation} on CIFAR10 by integrating it in the SimCLR model.