 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Convolutional Neural Network (CNN) vs Visual Transformer (ViT) for Digital Holography
Aug 20, 2021

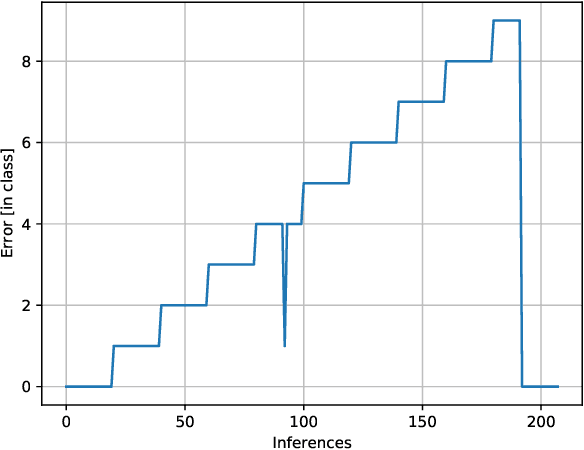

In Digital Holography (DH), it is crucial to extract the object distance from a hologram in order to reconstruct its amplitude and phase. This step is called auto-focusing and it is conventionally solved by first reconstructing a stack of images and then by sharpening each reconstructed image using a focus metric such as entropy or variance. The distance corresponding to the sharpest image is considered the focal position. This approach, while effective, is computationally demanding and time-consuming. In this paper, the determination of the distance is performed by Deep Learning (DL). Two deep learning (DL) architectures are compared: Convolutional Neural Network (CNN)and Visual transformer (ViT). ViT and CNN are used to cope with the problem of auto-focusing as a classification problem. Compared to a first attempt [11] in which the distance between two consecutive classes was 100{\mu}m, our proposal allows us to drastically reduce this distance to 1{\mu}m. Moreover, ViT reaches similar accuracy and is more robust than CNN.
TADA: Taxonomy Adaptive Domain Adaptation
Sep 10, 2021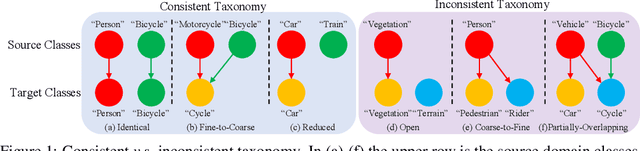
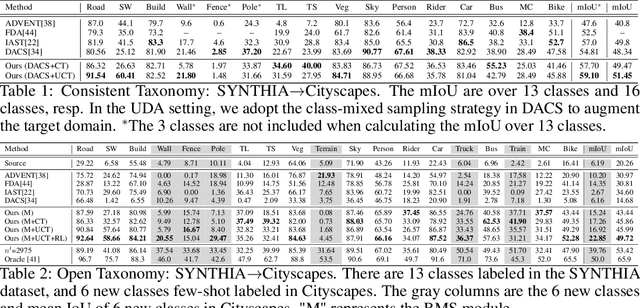
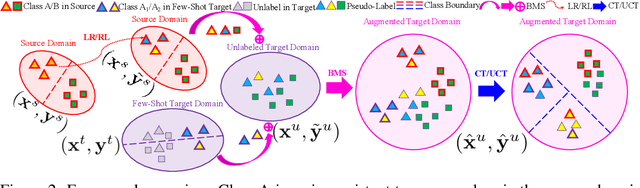
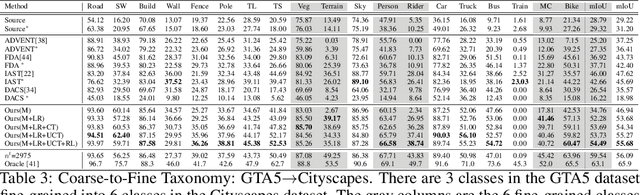
Traditional domain adaptation addresses the task of adapting a model to a novel target domain under limited or no additional supervision. While tackling the input domain gap, the standard domain adaptation settings assume no domain change in the output space. In semantic prediction tasks, different datasets are often labeled according to different semantic taxonomies. In many real-world settings, the target domain task requires a different taxonomy than the one imposed by the source domain. We therefore introduce the more general taxonomy adaptive domain adaptation (TADA) problem, allowing for inconsistent taxonomies between the two domains. We further propose an approach that jointly addresses the image-level and label-level domain adaptation. On the label-level, we employ a bilateral mixed sampling strategy to augment the target domain, and a relabelling method to unify and align the label spaces. We address the image-level domain gap by proposing an uncertainty-rectified contrastive learning method, leading to more domain-invariant and class discriminative features. We extensively evaluate the effectiveness of our framework under different TADA settings: open taxonomy, coarse-to-fine taxonomy, and partially-overlapping taxonomy. Our framework outperforms previous state-of-the-art by a large margin, while capable of adapting to new target domain taxonomies.
Stomach 3D Reconstruction Based on Virtual Chromoendoscopic Image Generation
Apr 26, 2020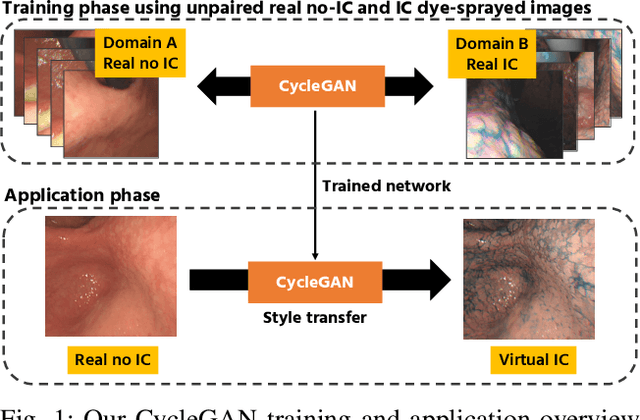
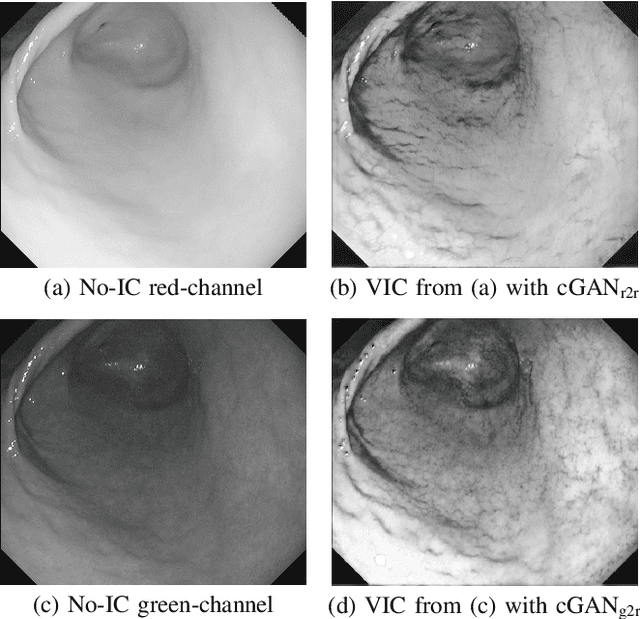
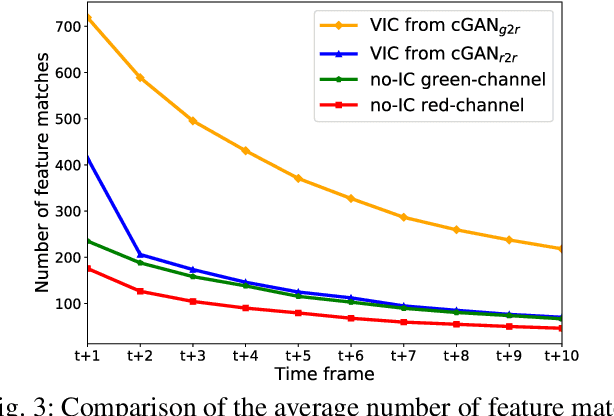

Gastric endoscopy is a standard clinical process that enables medical practitioners to diagnose various lesions inside a patient's stomach. If any lesion is found, it is very important to perceive the location of the lesion relative to the global view of the stomach. Our previous research showed that this could be addressed by reconstructing the whole stomach shape from chromoendoscopic images using a structure-from-motion (SfM) pipeline, in which indigo carmine (IC) blue dye sprayed images were used to increase feature matches for SfM by enhancing stomach surface's textures. However, spraying the IC dye to the whole stomach requires additional time, labor, and cost, which is not desirable for patients and practitioners. In this paper, we propose an alternative way to achieve whole stomach 3D reconstruction without the need of the IC dye by generating virtual IC-sprayed (VIC) images based on image-to-image style translation trained on unpaired real no-IC and IC-sprayed images. We have specifically investigated the effect of input and output color channel selection for generating the VIC images and found that translating no-IC green-channel images to IC-sprayed red-channel images gives the best SfM reconstruction result.
Cross-modal Attention for MRI and Ultrasound Volume Registration
Jul 12, 2021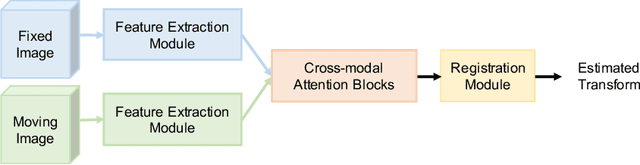
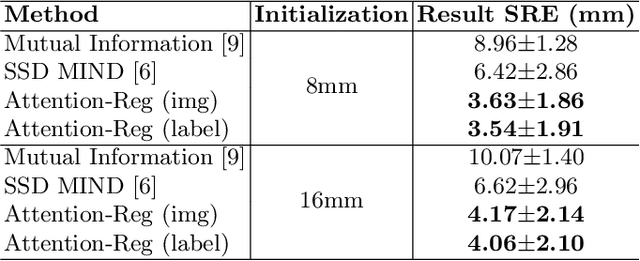
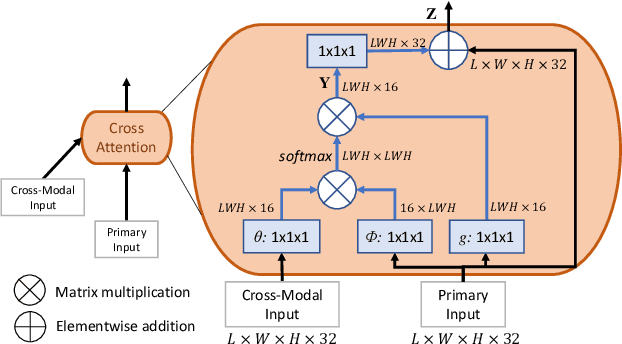
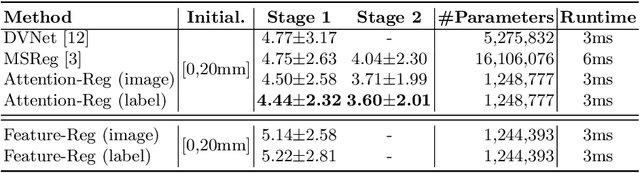
Prostate cancer biopsy benefits from accurate fusion of transrectal ultrasound (TRUS) and magnetic resonance (MR) images. In the past few years, convolutional neural networks (CNNs) have been proved powerful in extracting image features crucial for image registration. However, challenging applications and recent advances in computer vision suggest that CNNs are quite limited in its ability to understand spatial correspondence between features, a task in which the self-attention mechanism excels. This paper aims to develop a self-attention mechanism specifically for cross-modal image registration. Our proposed cross-modal attention block effectively maps each of the features in one volume to all features in the corresponding volume. Our experimental results demonstrate that a CNN network designed with the cross-modal attention block embedded outperforms an advanced CNN network 10 times of its size. We also incorporated visualization techniques to improve the interpretability of our network. The source code of our work is available at https://github.com/DIAL-RPI/Attention-Reg .
Towards robust vision by multi-task learning on monkey visual cortex
Jul 29, 2021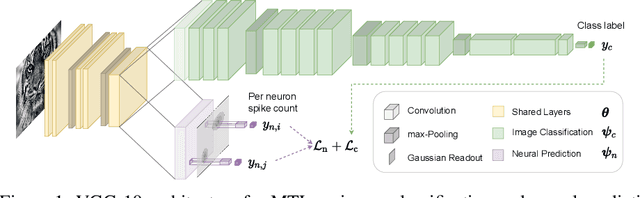
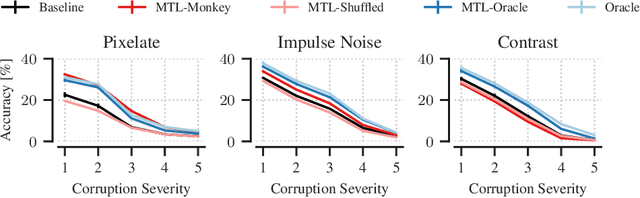
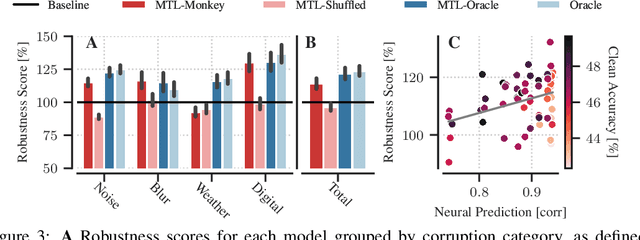
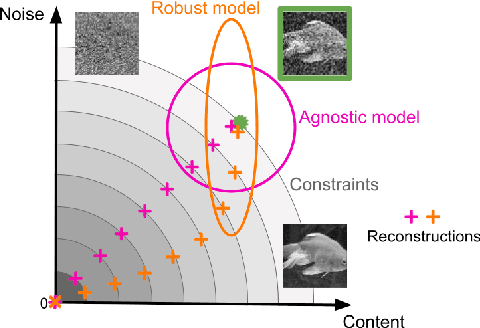
Deep neural networks set the state-of-the-art across many tasks in computer vision, but their generalization ability to image distortions is surprisingly fragile. In contrast, the mammalian visual system is robust to a wide range of perturbations. Recent work suggests that this generalization ability can be explained by useful inductive biases encoded in the representations of visual stimuli throughout the visual cortex. Here, we successfully leveraged these inductive biases with a multi-task learning approach: we jointly trained a deep network to perform image classification and to predict neural activity in macaque primary visual cortex (V1). We measured the out-of-distribution generalization abilities of our network by testing its robustness to image distortions. We found that co-training on monkey V1 data leads to increased robustness despite the absence of those distortions during training. Additionally, we showed that our network's robustness is very close to that of an Oracle network where parts of the architecture are directly trained on noisy images. Our results also demonstrated that the network's representations become more brain-like as their robustness improves. Using a novel constrained reconstruction analysis, we investigated what makes our brain-regularized network more robust. We found that our co-trained network is more sensitive to content than noise when compared to a Baseline network that we trained for image classification alone. Using DeepGaze-predicted saliency maps for ImageNet images, we found that our monkey co-trained network tends to be more sensitive to salient regions in a scene, reminiscent of existing theories on the role of V1 in the detection of object borders and bottom-up saliency. Overall, our work expands the promising research avenue of transferring inductive biases from the brain, and provides a novel analysis of the effects of our transfer.
WarpedGANSpace: Finding non-linear RBF paths in GAN latent space
Sep 27, 2021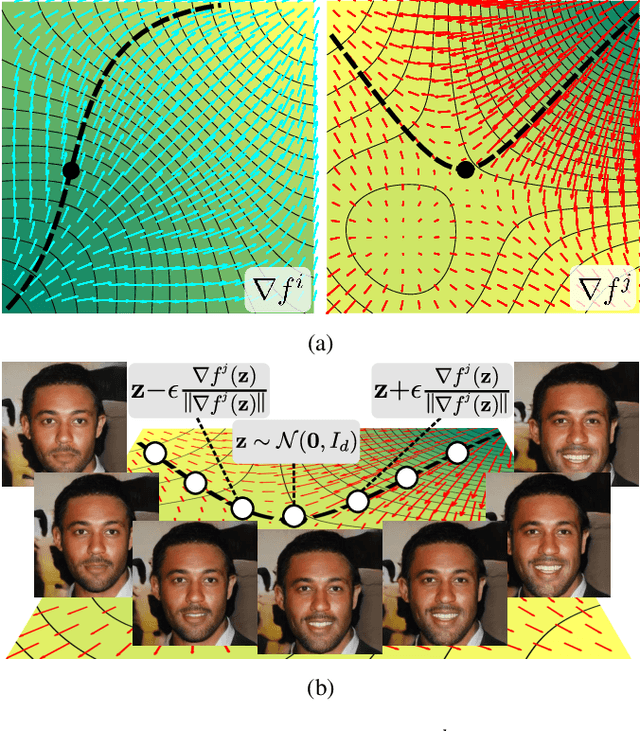
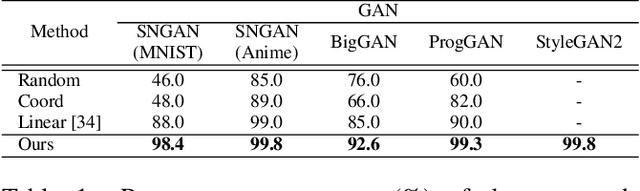
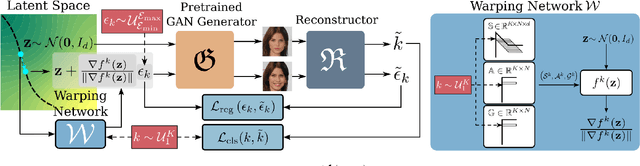
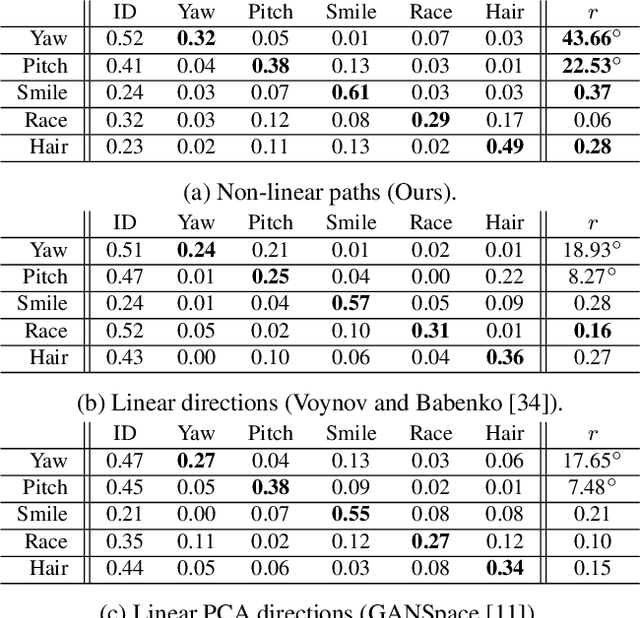
This work addresses the problem of discovering, in an unsupervised manner, interpretable paths in the latent space of pretrained GANs, so as to provide an intuitive and easy way of controlling the underlying generative factors. In doing so, it addresses some of the limitations of the state-of-the-art works, namely, a) that they discover directions that are independent of the latent code, i.e., paths that are linear, and b) that their evaluation relies either on visual inspection or on laborious human labeling. More specifically, we propose to learn non-linear warpings on the latent space, each one parametrized by a set of RBF-based latent space warping functions, and where each warping gives rise to a family of non-linear paths via the gradient of the function. Building on the work of Voynov and Babenko, that discovers linear paths, we optimize the trainable parameters of the set of RBFs, so as that images that are generated by codes along different paths, are easily distinguishable by a discriminator network. This leads to easily distinguishable image transformations, such as pose and facial expressions in facial images. We show that linear paths can be derived as a special case of our method, and show experimentally that non-linear paths in the latent space lead to steeper, more disentangled and interpretable changes in the image space than in state-of-the art methods, both qualitatively and quantitatively. We make the code and the pretrained models publicly available at: https://github.com/chi0tzp/WarpedGANSpace.
Reducing Tactile Sim2Real Domain Gaps via Deep Texture Generation Networks
Dec 03, 2021
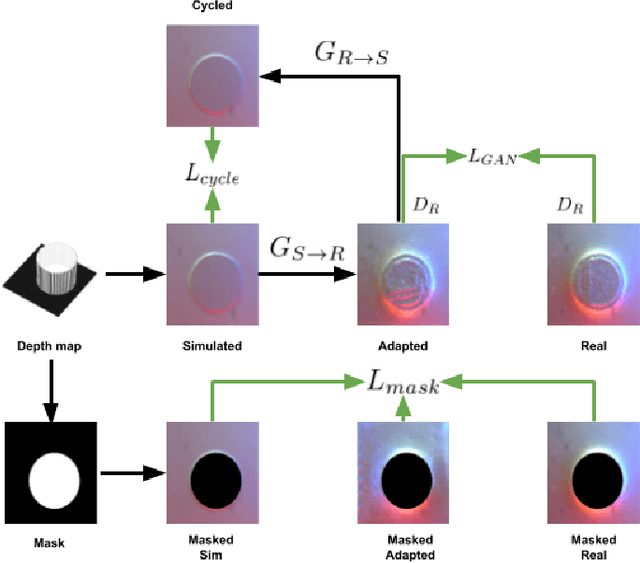


Recently simulation methods have been developed for optical tactile sensors to enable the Sim2Real learning, i.e., firstly training models in simulation before deploying them on the real robot. However, some artefacts in the real objects are unpredictable, such as imperfections caused by fabrication processes, or scratches by the natural wear and tear, and thus cannot be represented in the simulation, resulting in a significant gap between the simulated and real tactile images. To address this Sim2Real gap, we propose a novel texture generation network that maps the simulated images into photorealistic tactile images that resemble a real sensor contacting a real imperfect object. Each simulated tactile image is first divided into two types of regions: areas that are in contact with the object and areas that are not. The former is applied with generated textures learned from real textures in the real tactile images, whereas the latter maintains its appearance as when the sensor is not in contact with any object. This makes sure that the artefacts are only applied to the deformed regions of the sensor. Our extensive experiments show that the proposed texture generation network can generate these realistic artefacts on the deformed regions of the sensor, while avoiding leaking the textures into areas of no contact. Quantitative experiments further reveal that when using the adapted images generated by our proposed network for a Sim2Real classification task, the drop in accuracy caused by the Sim2Real gap is reduced from 38.43% to merely 0.81%. As such, this work has the potential to accelerate the Sim2Real learning for robotic tasks requiring tactile sensing.
Determining Sequence of Image Processing Technique (IPT) to Detect Adversarial Attacks
Jul 01, 2020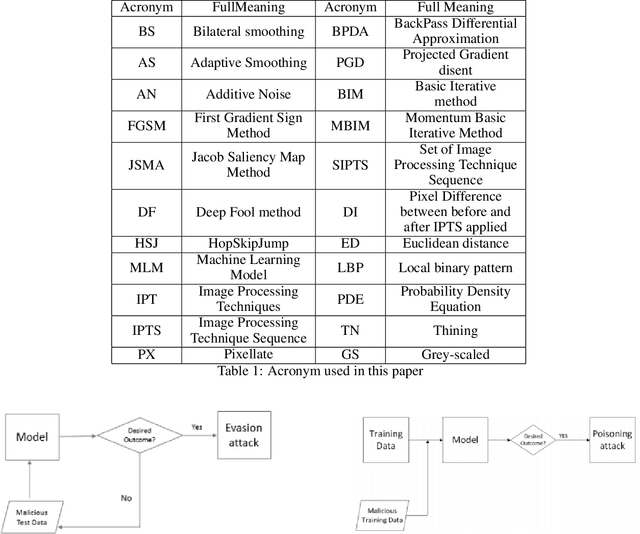

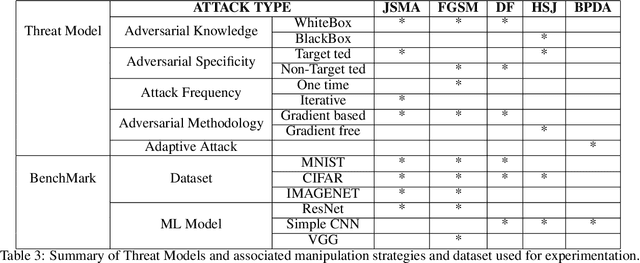
Developing secure machine learning models from adversarial examples is challenging as various methods are continually being developed to generate adversarial attacks. In this work, we propose an evolutionary approach to automatically determine Image Processing Techniques Sequence (IPTS) for detecting malicious inputs. Accordingly, we first used a diverse set of attack methods including adaptive attack methods (on our defense) to generate adversarial samples from the clean dataset. A detection framework based on a genetic algorithm (GA) is developed to find the optimal IPTS, where the optimality is estimated by different fitness measures such as Euclidean distance, entropy loss, average histogram, local binary pattern and loss functions. The "image difference" between the original and processed images is used to extract the features, which are then fed to a classification scheme in order to determine whether the input sample is adversarial or clean. This paper described our methodology and performed experiments using multiple data-sets tested with several adversarial attacks. For each attack-type and dataset, it generates unique IPTS. A set of IPTS selected dynamically in testing time which works as a filter for the adversarial attack. Our empirical experiments exhibited promising results indicating the approach can efficiently be used as processing for any AI model.
UAV-based Crowd Surveillance in Post COVID-19 Era
Nov 28, 2021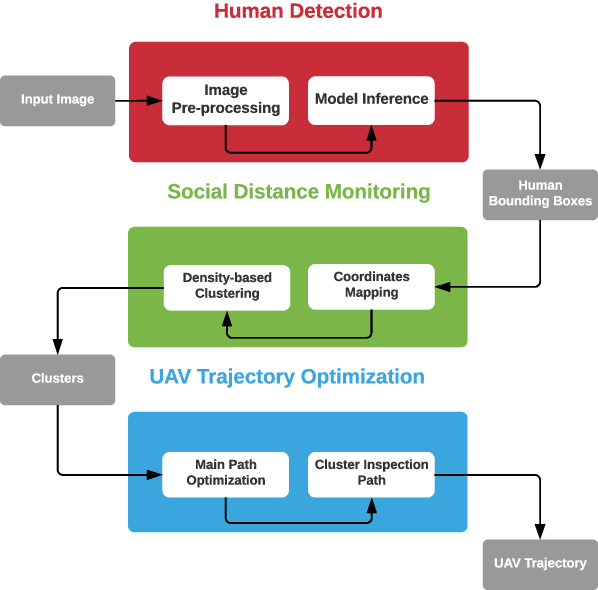
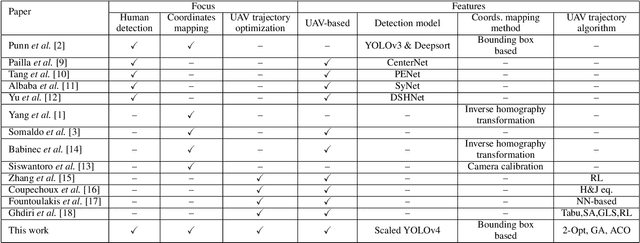


To cope with the current pandemic situation and reinstate pseudo-normal daily life, several measures have been deployed and maintained, such as mask wearing, social distancing, hands sanitizing, etc. Since outdoor cultural events, concerts, and picnics, are gradually allowed, a close monitoring of the crowd activity is needed to avoid undesired contact and disease transmission. In this context, intelligent unmanned aerial vehicles (UAVs) can be occasionally deployed to ensure the surveillance of these activities, that health restriction measures are applied, and to trigger alerts when the latter are not respected. Consequently, we propose in this paper a complete UAV framework for intelligent monitoring of post COVID-19 outdoor activities. Specifically, we propose a three steps approach. In the first step, captured images by a UAV are analyzed using machine learning to detect and locate individuals. The second step consists of a novel coordinates mapping approach to evaluate distances among individuals, then cluster them, while the third step provides an energy-efficient and/or reliable UAV trajectory to inspect clusters for restrictions violation such as mask wearing. Obtained results provide the following insights: 1) Efficient detection of individuals depends on the angle from which the image was captured, 2) coordinates mapping is very sensitive to the estimation error in individuals' bounding boxes, and 3) UAV trajectory design algorithm 2-Opt is recommended for practical real-time deployments due to its low-complexity and near-optimal performance.
DASGIL: Domain Adaptation for Semantic and Geometric-aware Image-based Localization
Oct 01, 2020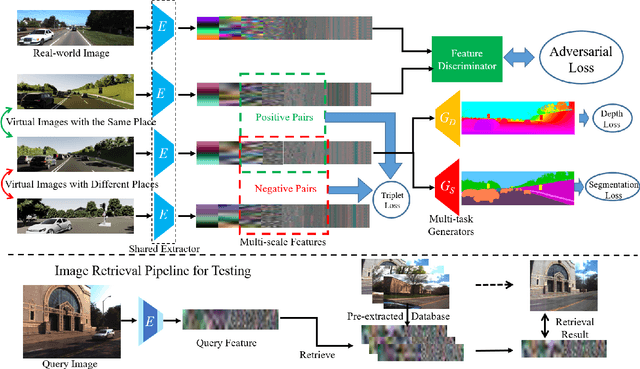
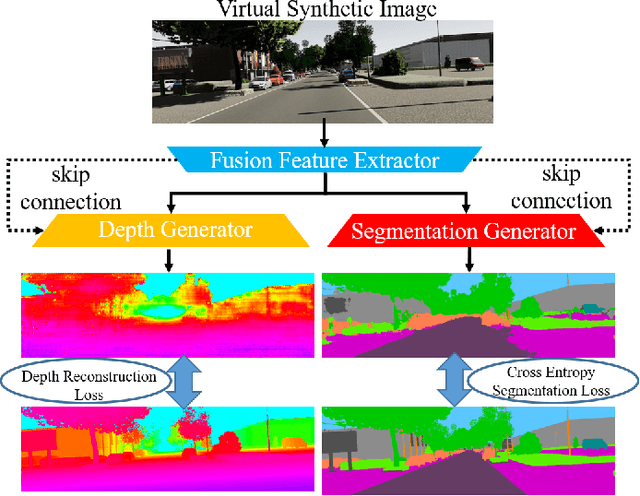
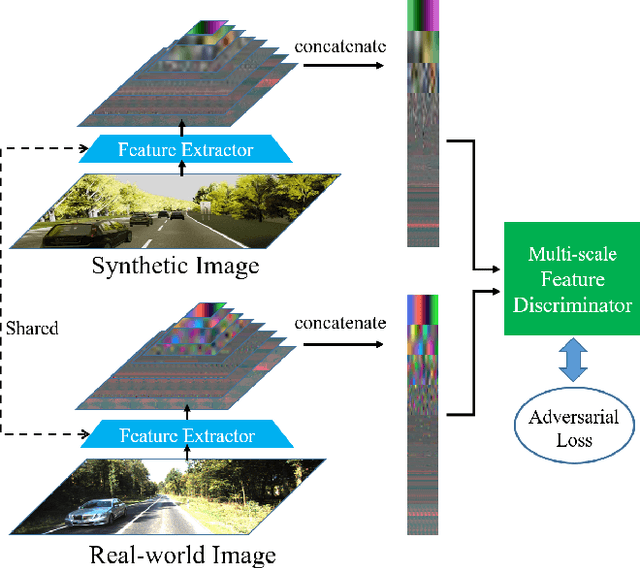
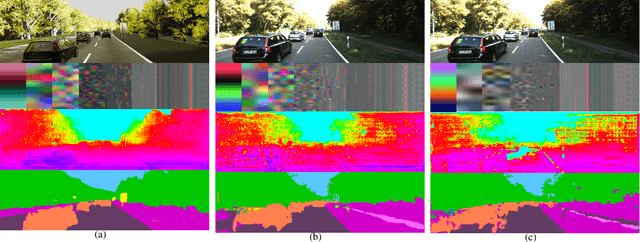
Long-Term visual localization under changing environments is a challenging problem in autonomous driving and mobile robotics due to season, illumination variance, etc. Image retrieval for localization is an efficient and effective solution to the problem. In this paper, we propose a novel multi-task architecture to fuse the geometric and semantic information into the multi-scale latent embedding representation for visual place recognition. To use the high-quality ground truths without any human effort, depth and segmentation generator model is trained on virtual synthetic dataset and domain adaptation is adopted from synthetic to real-world dataset. The multi-scale model presents the strong generalization ability on real-world KITTI dataset though trained on the virtual KITTI 2 dataset. The proposed approach is validated on the Extended CMU-Seasons dataset through a series of crucial comparison experiments, where our performance outperforms state-of-the-art baselines for retrieval-based localization under the challenging environment.