 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Beyond Flatland: Pre-training with a Strong 3D Inductive Bias
Nov 30, 2021

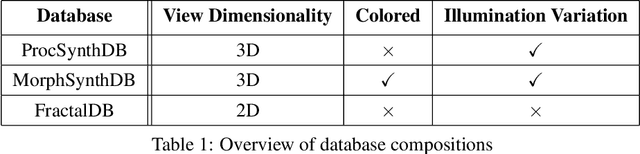

Pre-training on large-scale databases consisting of natural images and then fine-tuning them to fit the application at hand, or transfer-learning, is a popular strategy in computer vision. However, Kataoka et al., 2020 introduced a technique to eliminate the need for natural images in supervised deep learning by proposing a novel synthetic, formula-based method to generate 2D fractals as training corpus. Using one synthetically generated fractal for each class, they achieved transfer learning results comparable to models pre-trained on natural images. In this project, we take inspiration from their work and build on this idea -- using 3D procedural object renders. Since the image formation process in the natural world is based on its 3D structure, we expect pre-training with 3D mesh renders to provide an implicit bias leading to better generalization capabilities in a transfer learning setting and that invariances to 3D rotation and illumination are easier to be learned based on 3D data. Similar to the previous work, our training corpus will be fully synthetic and derived from simple procedural strategies; we will go beyond classic data augmentation and also vary illumination and pose which are controllable in our setting and study their effect on transfer learning capabilities in context to prior work. In addition, we will compare the 2D fractal and 3D procedural object networks to human and non-human primate brain data to learn more about the 2D vs. 3D nature of biological vision.
VCNet: A Robust Approach to Blind Image Inpainting
Mar 15, 2020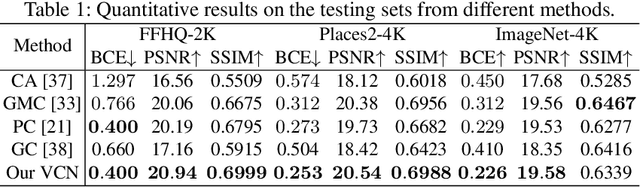
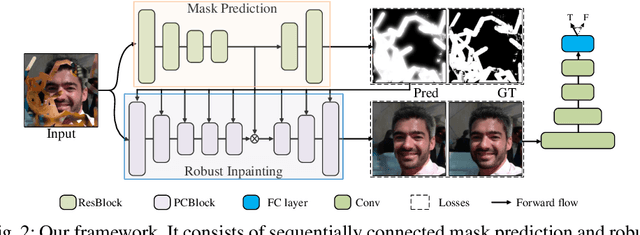
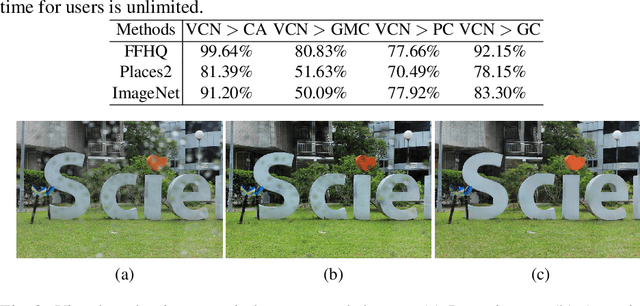

Blind inpainting is a task to automatically complete visual contents without specifying masks for missing areas in an image. Previous works assume missing region patterns are known, limiting its application scope. In this paper, we relax the assumption by defining a new blind inpainting setting, making training a blind inpainting neural system robust against various unknown missing region patterns. Specifically, we propose a two-stage visual consistency network (VCN), meant to estimate where to fill (via masks) and generate what to fill. In this procedure, the unavoidable potential mask prediction errors lead to severe artifacts in the subsequent repairing. To address it, our VCN predicts semantically inconsistent regions first, making mask prediction more tractable. Then it repairs these estimated missing regions using a new spatial normalization, enabling VCN to be robust to the mask prediction errors. In this way, semantically convincing and visually compelling content is thus generated. Extensive experiments are conducted, showing our method is effective and robust in blind image inpainting. And our VCN allows for a wide spectrum of applications.
Unsupervised Image Super-Resolution with an Indirect Supervised Path
Oct 13, 2019



The task of single image super-resolution (SISR) aims at reconstructing a high-resolution (HR) image from a low-resolution (LR) image. Although significant progress has been made by deep learning models, they are trained on synthetic paired data in a supervised way and do not perform well on real data. There are several attempts that directly apply unsupervised image translation models to address such a problem. However, unsupervised low-level vision problem poses more challenge on the accuracy of translation. In this work,we propose a novel framework which is composed of two stages: 1) unsupervised image translation between real LR images and synthetic LR images; 2) supervised super-resolution from approximated real LR images to HR images. It takes the synthetic LR images as a bridge and creates an indirect supervised path from real LR images to HR images. Any existed deep learning based image super-resolution model can be integrated into the second stage of the proposed framework for further improvement. In addition it shows great flexibility in balancing between distortion and perceptual quality under unsupervised setting. The proposed method is evaluated on both NTIRE 2017 and 2018 challenge datasets and achieves favorable performance against supervised methods.
Human Perceptual Evaluations for Image Compression
Aug 09, 2019

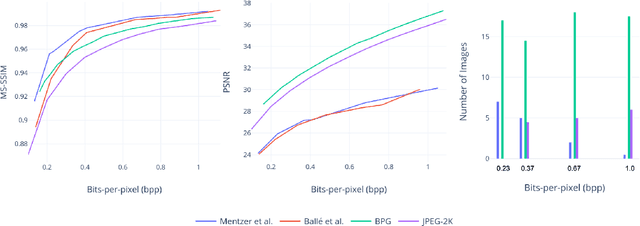
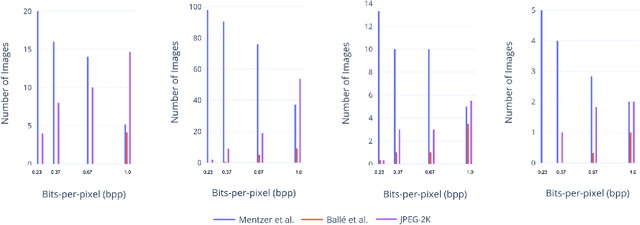
Recently, there has been much interest in deep learning techniques to do image compression and there have been claims that several of these produce better results than engineered compression schemes (such as JPEG, JPEG2000 or BPG). A standard way of comparing image compression schemes today is to use perceptual similarity metrics such as PSNR or MS-SSIM (multi-scale structural similarity). This has led to some deep learning techniques which directly optimize for MS-SSIM by choosing it as a loss function. While this leads to a higher MS-SSIM for such techniques, we demonstrate using user studies that the resulting improvement may be misleading. Deep learning techniques for image compression with a higher MS-SSIM may actually be perceptually worse than engineered compression schemes with a lower MS-SSIM.
Boosting EfficientNets Ensemble Performance via Pseudo-Labels and Synthetic Images by pix2pixHD for Infection and Ischaemia Classification in Diabetic Foot Ulcers
Nov 30, 2021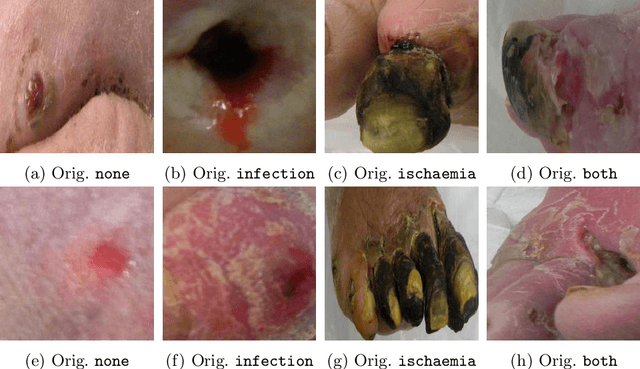
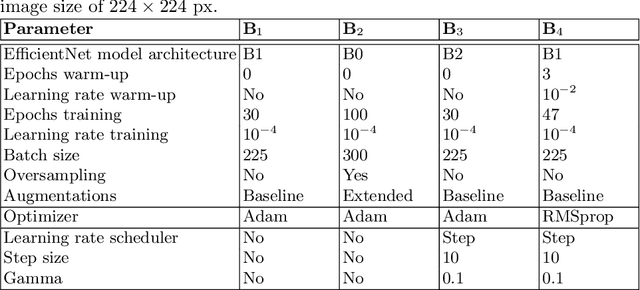
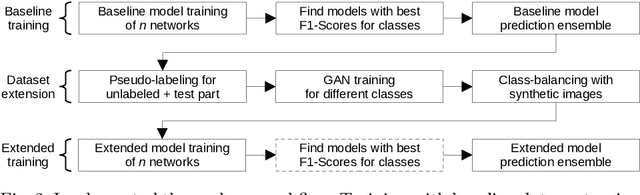
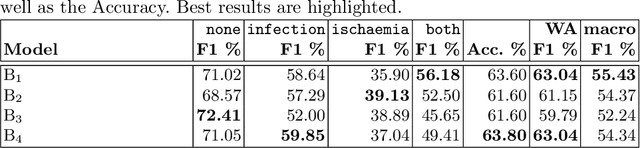
Diabetic foot ulcers are a common manifestation of lesions on the diabetic foot, a syndrome acquired as a long-term complication of diabetes mellitus. Accompanying neuropathy and vascular damage promote acquisition of pressure injuries and tissue death due to ischaemia. Affected areas are prone to infections, hindering the healing progress. The research at hand investigates an approach on classification of infection and ischaemia, conducted as part of the Diabetic Foot Ulcer Challenge (DFUC) 2021. Different models of the EfficientNet family are utilized in ensembles. An extension strategy for the training data is applied, involving pseudo-labeling for unlabeled images, and extensive generation of synthetic images via pix2pixHD to cope with severe class imbalances. The resulting extended training dataset features $8.68$ times the size of the baseline and shows a real to synthetic image ratio of $1:3$. Performances of models and ensembles trained on the baseline and extended training dataset are compared. Synthetic images featured a broad qualitative variety. Results show that models trained on the extended training dataset as well as their ensemble benefit from the large extension. F1-Scores for rare classes receive outstanding boosts, while those for common classes are either not harmed or boosted moderately. A critical discussion concretizes benefits and identifies limitations, suggesting improvements. The work concludes that classification performance of individual models as well as that of ensembles can be boosted utilizing synthetic images. Especially performance for rare classes benefits notably.
Deep Learning-based Frozen Section to FFPE Translation
Jul 27, 2021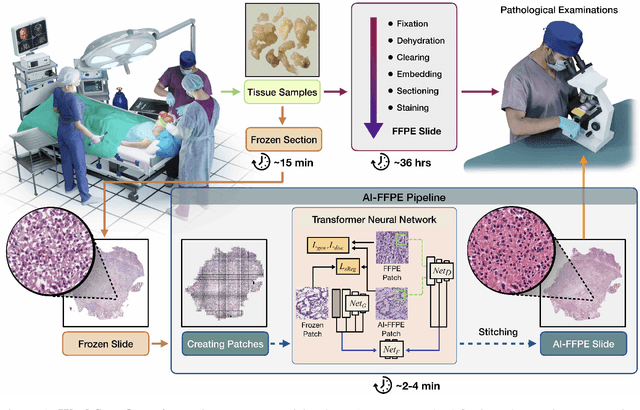
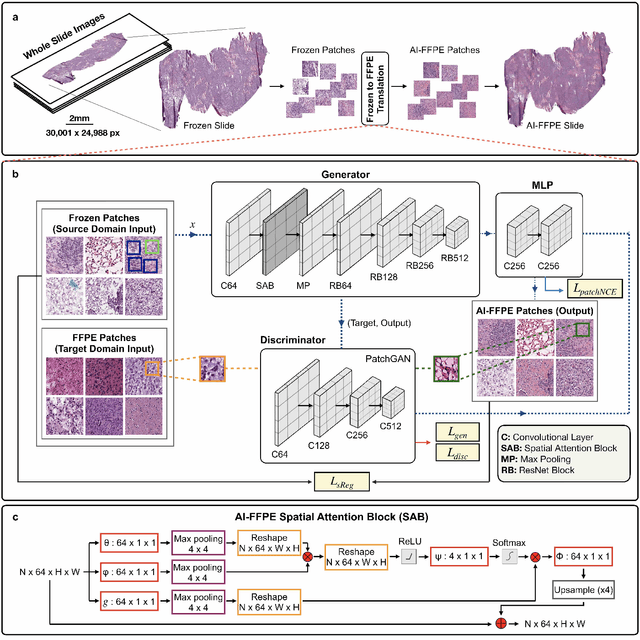
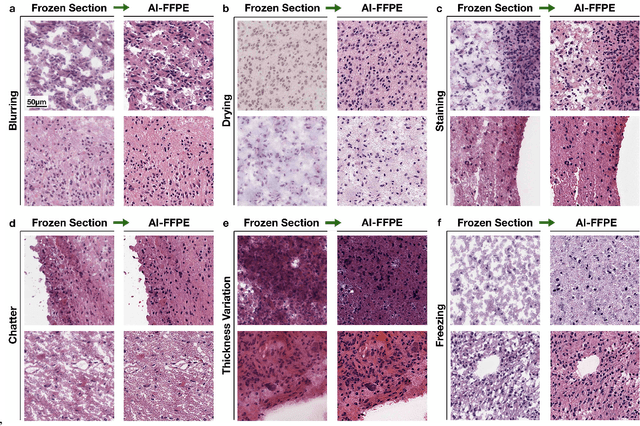
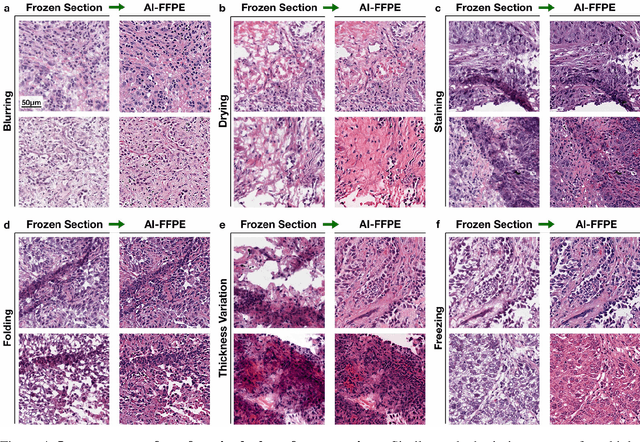
Frozen sectioning (FS) is the preparation method of choice for microscopic evaluation of tissues during surgical operations. The high speed of the procedure allows pathologists to rapidly assess the key microscopic features, such as tumour margins and malignant status to guide surgical decision-making and minimise disruptions to the course of the operation. However, FS is prone to introducing many misleading artificial structures (histological artefacts), such as nuclear ice crystals, compression, and cutting artefacts, hindering timely and accurate diagnostic judgement of the pathologist. Additional training and prolonged experience is often required to make highly effective and time-critical diagnosis on frozen sections. On the other hand, the gold standard tissue preparation technique of formalin-fixation and paraffin-embedding (FFPE) provides significantly superior image quality, but is a very time-consuming process (12-48 hours), making it unsuitable for intra-operative use. In this paper, we propose an artificial intelligence (AI) method that improves FS image quality by computationally transforming frozen-sectioned whole-slide images (FS-WSIs) into whole-slide FFPE-style images in minutes. AI-FFPE rectifies FS artefacts with the guidance of an attention mechanism that puts a particular emphasis on artefacts while utilising a self-regularization mechanism established between FS input image and synthesized FFPE-style image that preserves clinically relevant features. As a result, AI-FFPE method successfully generates FFPE-style images without significantly extending tissue processing time and consequently improves diagnostic accuracy. We demonstrate the efficacy of AI-FFPE on lung and brain frozen sections using a variety of different qualitative and quantitative metrics including visual Turing tests from 20 board certified pathologists.
Gradient Inversion Attack: Leaking Private Labels in Two-Party Split Learning
Nov 25, 2021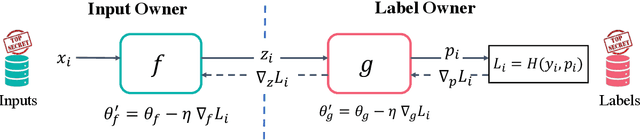
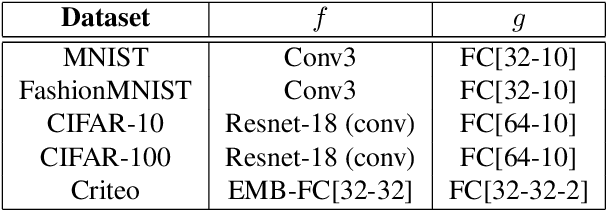
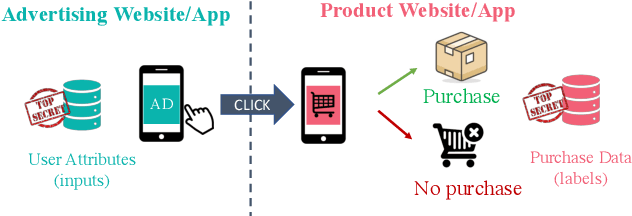
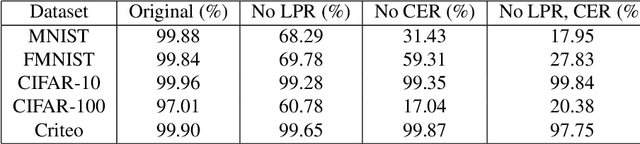
Split learning is a popular technique used to perform vertical federated learning, where the goal is to jointly train a model on the private input and label data held by two parties. To preserve privacy of the input and label data, this technique uses a split model and only requires the exchange of intermediate representations (IR) of the inputs and gradients of the IR between the two parties during the learning process. In this paper, we propose Gradient Inversion Attack (GIA), a label leakage attack that allows an adversarial input owner to learn the label owner's private labels by exploiting the gradient information obtained during split learning. GIA frames the label leakage attack as a supervised learning problem by developing a novel loss function using certain key properties of the dataset and models. Our attack can uncover the private label data on several multi-class image classification problems and a binary conversion prediction task with near-perfect accuracy (97.01% - 99.96%), demonstrating that split learning provides negligible privacy benefits to the label owner. Furthermore, we evaluate the use of gradient noise to defend against GIA. While this technique is effective for simpler datasets, it significantly degrades utility for datasets with higher input dimensionality. Our findings underscore the need for better privacy-preserving training techniques for vertically split data.
Feature Detection for Hand Hygiene Stages
Aug 06, 2021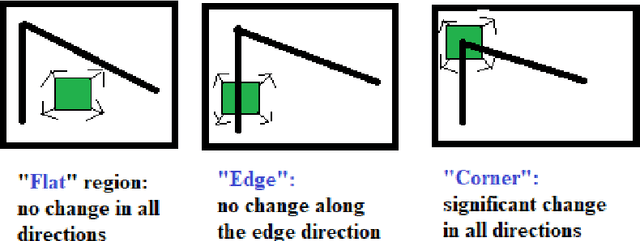
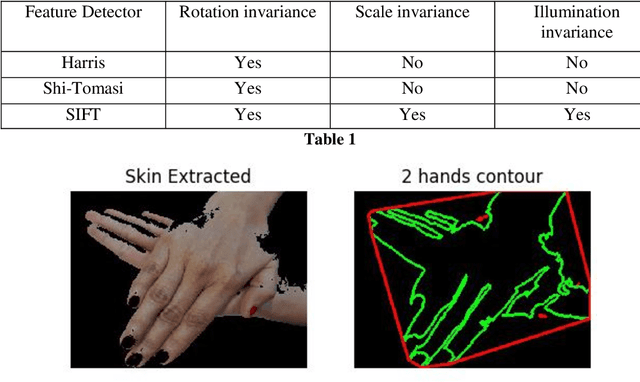
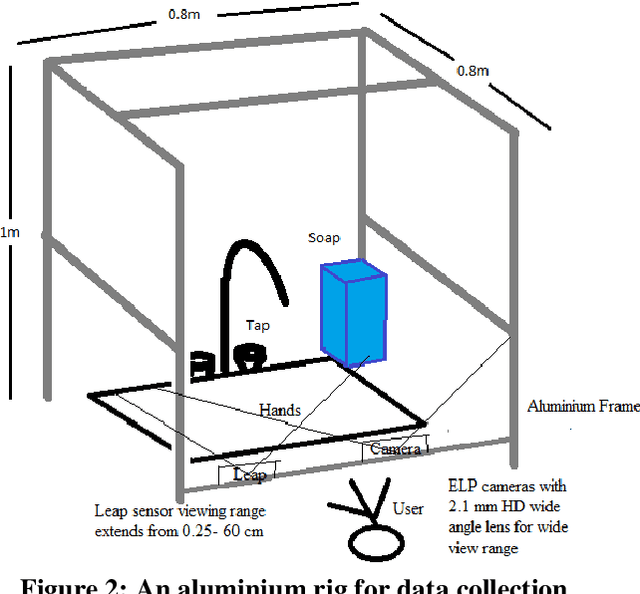
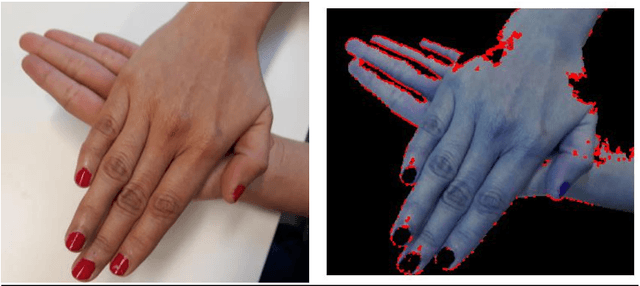
The process of hand washing involves complex hand movements. There are six principal sequential steps for washing hands as per the World Health Organisation (WHO) guidelines. In this work, a detailed description of an aluminium rig construction for creating a robust hand-washing dataset is discussed. The preliminary results with the help of image processing and computer vision algorithms for hand pose extraction and feature detection such as Harris detector, Shi-Tomasi and SIFT are demonstrated. The hand hygiene pose- Rub hands palm to palm was captured as an input image for running all the experiments. The future work will focus upon processing the video recordings of hand movements captured and applying deep-learning solutions for the classification of hand-hygiene stages.
PoseGAN: A Pose-to-Image Translation Framework for Camera Localization
Jun 23, 2020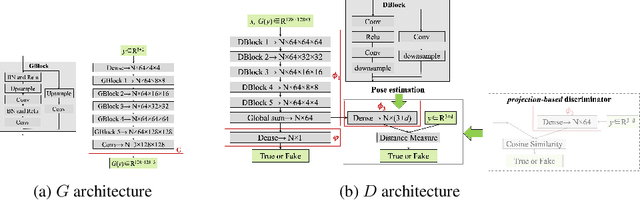
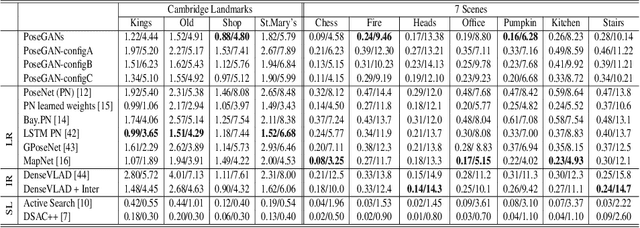


Camera localization is a fundamental requirement in robotics and computer vision. This paper introduces a pose-to-image translation framework to tackle the camera localization problem. We present PoseGANs, a conditional generative adversarial networks (cGANs) based framework for the implementation of pose-to-image translation. PoseGANs feature a number of innovations including a distance metric based conditional discriminator to conduct camera localization and a pose estimation technique for generated camera images as a stronger constraint to improve camera localization performance. Compared with learning-based regression methods such as PoseNet, PoseGANs can achieve better performance with model sizes that are 70% smaller. In addition, PoseGANs introduce the view synthesis technique to establish the correspondence between the 2D images and the scene, \textit{i.e.}, given a pose, PoseGANs are able to synthesize its corresponding camera images. Furthermore, we demonstrate that PoseGANs differ in principle from structure-based localization and learning-based regressions for camera localization, and show that PoseGANs exploit the geometric structures to accomplish the camera localization task, and is therefore more stable than and superior to learning-based regressions which rely on local texture features instead. In addition to camera localization and view synthesis, we also demonstrate that PoseGANs can be successfully used for other interesting applications such as moving object elimination and frame interpolation in video sequences.
A Point Cloud Generative Model via Tree-Structured Graph Convolutions for 3D Brain Shape Reconstruction
Jul 21, 2021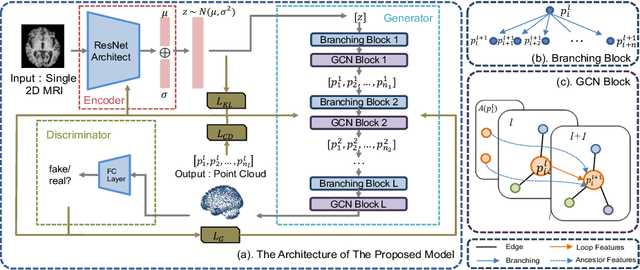

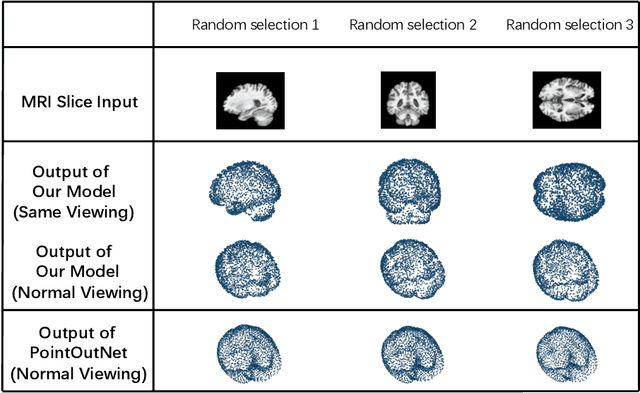

Fusing medical images and the corresponding 3D shape representation can provide complementary information and microstructure details to improve the operational performance and accuracy in brain surgery. However, compared to the substantial image data, it is almost impossible to obtain the intraoperative 3D shape information by using physical methods such as sensor scanning, especially in minimally invasive surgery and robot-guided surgery. In this paper, a general generative adversarial network (GAN) architecture based on graph convolutional networks is proposed to reconstruct the 3D point clouds (PCs) of brains by using one single 2D image, thus relieving the limitation of acquiring 3D shape data during surgery. Specifically, a tree-structured generative mechanism is constructed to use the latent vector effectively and transfer features between hidden layers accurately. With the proposed generative model, a spontaneous image-to-PC conversion is finished in real-time. Competitive qualitative and quantitative experimental results have been achieved on our model. In multiple evaluation methods, the proposed model outperforms another common point cloud generative model PointOutNet.