 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Neural Image Captioning
Jul 02, 2019
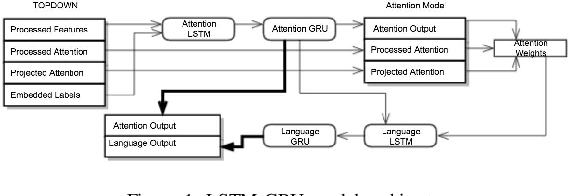



In recent years, the biggest advances in major Computer Vision tasks, such as object recognition, handwritten-digit identification, facial recognition, and many others., have all come through the use of Convolutional Neural Networks (CNNs). Similarly, in the domain of Natural Language Processing, Recurrent Neural Networks (RNNs), and Long Short Term Memory networks (LSTMs) in particular, have been crucial to some of the biggest breakthroughs in performance for tasks such as machine translation, part-of-speech tagging, sentiment analysis, and many others. These individual advances have greatly benefited tasks even at the intersection of NLP and Computer Vision, and inspired by this success, we studied some existing neural image captioning models that have proven to work well. In this work, we study some existing captioning models that provide near state-of-the-art performances, and try to enhance one such model. We also present a simple image captioning model that makes use of a CNN, an LSTM, and the beam search1 algorithm, and study its performance based on various qualitative and quantitative metrics.
BIAS: Transparent reporting of biomedical image analysis challenges
Oct 23, 2019The number of biomedical image analysis challenges organized per year is steadily increasing. These international competitions have the purpose of benchmarking algorithms on common data sets, typically to identify the best method for a given problem. Recent research, however, revealed that common practice related to challenge reporting does not allow for adequate interpretation and reproducibility of results. To address the discrepancy between the impact of challenges and the quality (control), the Biomedical I mage Analysis ChallengeS (BIAS) initiative developed a set of recommendations for the reporting of challenges. The BIAS statement aims to improve the transparency of the reporting of a biomedical image analysis challenge regardless of field of application, image modality or task category assessed. This article describes how the BIAS statement was developed and presents a checklist which authors of biomedical image analysis challenges are encouraged to include in their submission when giving a paper on a challenge into review. The purpose of the checklist is to standardize and facilitate the review process and raise interpretability and reproducibility of challenge results by making relevant information explicit.
Deep Poisoning Functions: Towards Robust Privacy-safe Image Data Sharing
Dec 14, 2019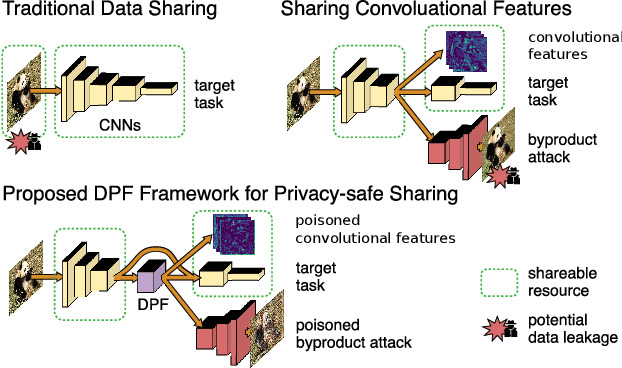
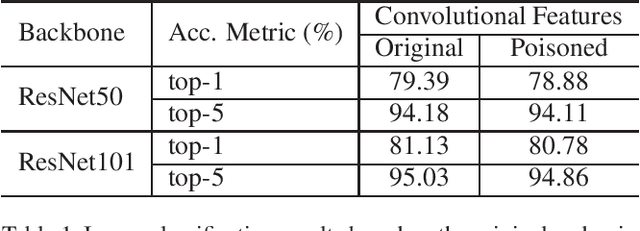
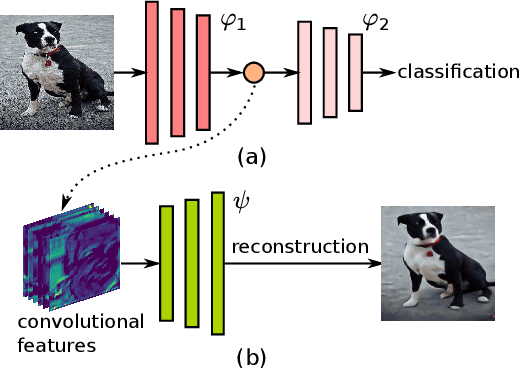
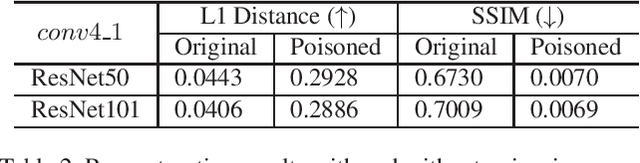
As deep networks are applied to an ever-expanding set of computer vision tasks, protecting general privacy in image data has become a critically important goal. This paper presents a new framework for privacy-preserving data sharing that is robust to adversarial attacks and overcomes the known issues existing in previous approaches. We introduce the concept of a Deep Poisoning Function (DPF), which is a module inserted into a pre-trained deep network designed to perform a specific vision task. The DPF is optimized to deliberately poison image data to prevent known adversarial attacks, while ensuring that the altered image data is functionally equivalent to the non-poisoned data for the original task. Given this equivalence, both poisoned and non-poisoned data can be used for further retraining or fine-tuning. Experimental results on image classification and face recognition tasks prove the efficacy of the proposed method.
Image Captioning with Visual Object Representations Grounded in the Textual Modality
Oct 19, 2020
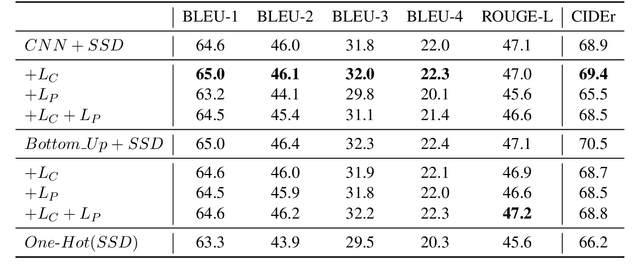
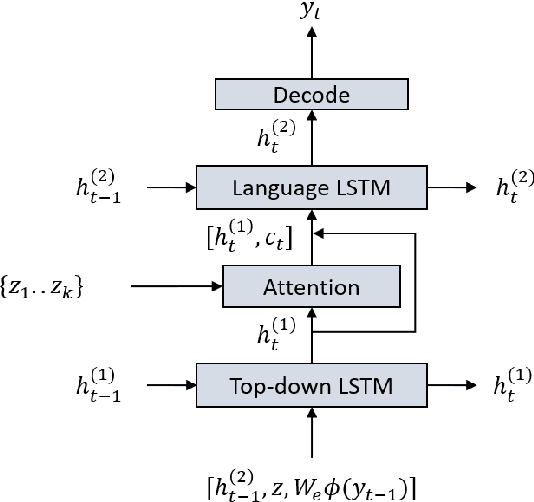
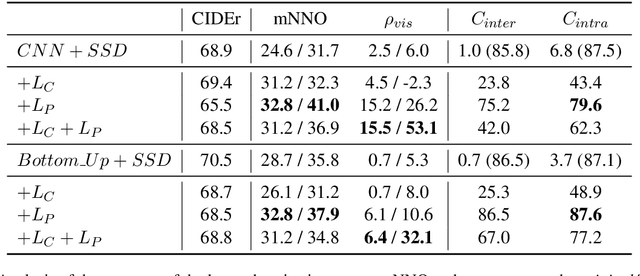
We present our work in progress exploring the possibilities of a shared embedding space between textual and visual modality. Leveraging the textual nature of object detection labels and the hypothetical expressiveness of extracted visual object representations, we propose an approach opposite to the current trend, grounding of the representations in the word embedding space of the captioning system instead of grounding words or sentences in their associated images. Based on the previous work, we apply additional grounding losses to the image captioning training objective aiming to force visual object representations to create more heterogeneous clusters based on their class label and copy a semantic structure of the word embedding space. In addition, we provide an analysis of the learned object vector space projection and its impact on the IC system performance. With only slight change in performance, grounded models reach the stopping criterion during training faster than the unconstrained model, needing about two to three times less training updates. Additionally, an improvement in structural correlation between the word embeddings and both original and projected object vectors suggests that the grounding is actually mutual.
Deep learning-based attenuation correction in the image domain for myocardial perfusion SPECT imaging
Feb 10, 2021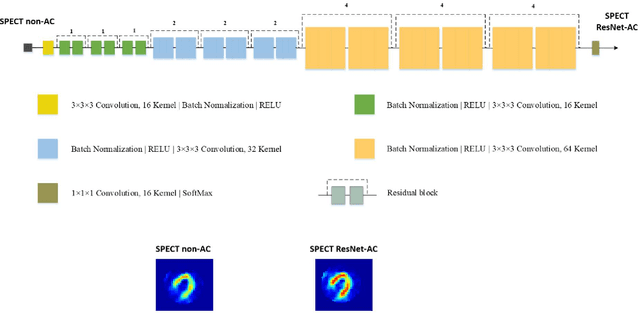
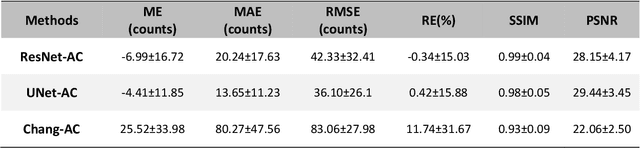
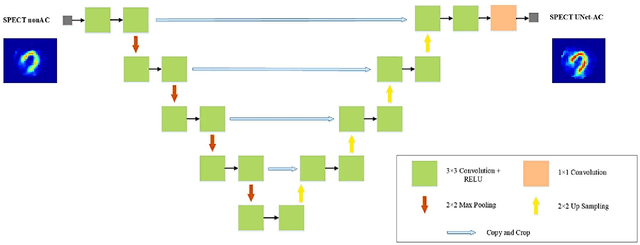
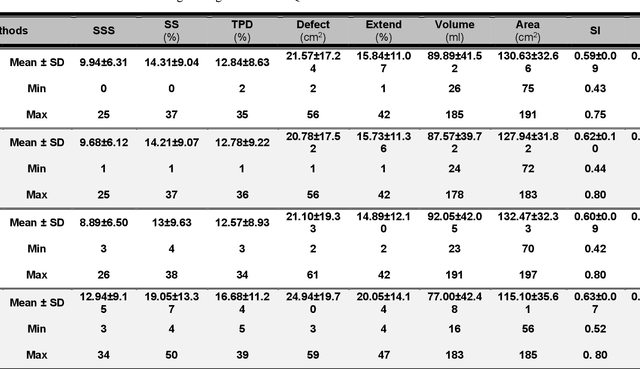
Objective: In this work, we set out to investigate the accuracy of direct attenuation correction (AC) in the image domain for the myocardial perfusion SPECT imaging (MPI-SPECT) using two residual (ResNet) and UNet deep convolutional neural networks. Methods: The MPI-SPECT 99mTc-sestamibi images of 99 participants were retrospectively examined. UNet and ResNet networks were trained using SPECT non-attenuation corrected images as input and CT-based attenuation corrected SPECT images (CT-AC) as reference. The Chang AC approach, considering a uniform attenuation coefficient within the body contour, was also implemented. Quantitative and clinical evaluation of the proposed methods were performed considering SPECT CT-AC images of 19 subjects as reference using the mean absolute error (MAE), structural similarity index (SSIM) metrics, as well as relevant clinical indices such as perfusion deficit (TPD). Results: Overall, the deep learning solution exhibited good agreement with the CT-based AC, noticeably outperforming the Chang method. The ResNet and UNet models resulted in the ME (count) of ${-6.99\pm16.72}$ and ${-4.41\pm11.8}$ and SSIM of ${0.99\pm0.04}$ and ${0.98\pm0.05}$, respectively. While the Change approach led to ME and SSIM of ${25.52\pm33.98}$ and ${0.93\pm0.09}$, respectively. Similarly, the clinical evaluation revealed a mean TPD of ${12.78\pm9.22}$ and ${12.57\pm8.93}$ for the ResNet and UNet models, respectively, compared to ${12.84\pm8.63}$ obtained from the reference SPECT CT-AC images. On the other hand, the Chang approach led to a mean TPD of ${16.68\pm11.24}$. Conclusion: We evaluated two deep convolutional neural networks to estimate SPECT-AC images directly from the non-attenuation corrected images. The deep learning solutions exhibited the promising potential to generate reliable attenuation corrected SPECT images without the use of transmission scanning.
Unsupervised Image Super-Resolution with an Indirect Supervised Path
Oct 13, 2019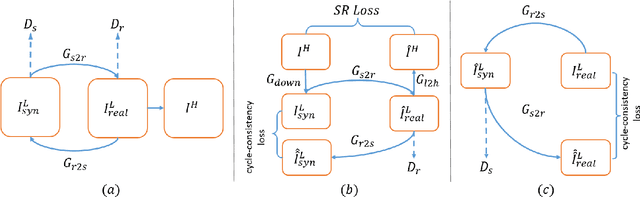



The task of single image super-resolution (SISR) aims at reconstructing a high-resolution (HR) image from a low-resolution (LR) image. Although significant progress has been made by deep learning models, they are trained on synthetic paired data in a supervised way and do not perform well on real data. There are several attempts that directly apply unsupervised image translation models to address such a problem. However, unsupervised low-level vision problem poses more challenge on the accuracy of translation. In this work,we propose a novel framework which is composed of two stages: 1) unsupervised image translation between real LR images and synthetic LR images; 2) supervised super-resolution from approximated real LR images to HR images. It takes the synthetic LR images as a bridge and creates an indirect supervised path from real LR images to HR images. Any existed deep learning based image super-resolution model can be integrated into the second stage of the proposed framework for further improvement. In addition it shows great flexibility in balancing between distortion and perceptual quality under unsupervised setting. The proposed method is evaluated on both NTIRE 2017 and 2018 challenge datasets and achieves favorable performance against supervised methods.
Human Perceptual Evaluations for Image Compression
Aug 09, 2019

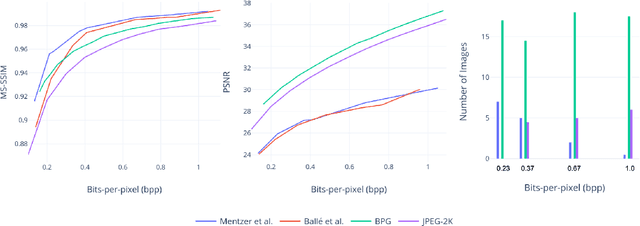
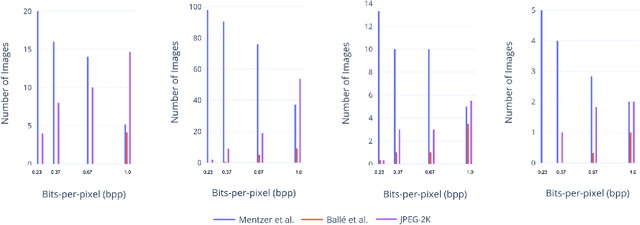
Recently, there has been much interest in deep learning techniques to do image compression and there have been claims that several of these produce better results than engineered compression schemes (such as JPEG, JPEG2000 or BPG). A standard way of comparing image compression schemes today is to use perceptual similarity metrics such as PSNR or MS-SSIM (multi-scale structural similarity). This has led to some deep learning techniques which directly optimize for MS-SSIM by choosing it as a loss function. While this leads to a higher MS-SSIM for such techniques, we demonstrate using user studies that the resulting improvement may be misleading. Deep learning techniques for image compression with a higher MS-SSIM may actually be perceptually worse than engineered compression schemes with a lower MS-SSIM.
Spatial and Semantic Consistency Regularizations for Pedestrian Attribute Recognition
Sep 13, 2021
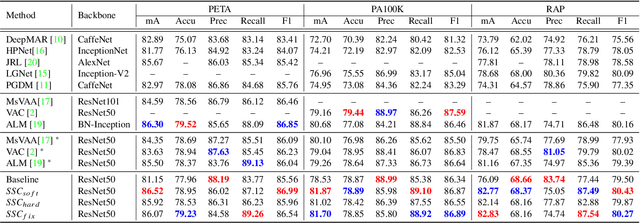


While recent studies on pedestrian attribute recognition have shown remarkable progress in leveraging complicated networks and attention mechanisms, most of them neglect the inter-image relations and an important prior: spatial consistency and semantic consistency of attributes under surveillance scenarios. The spatial locations of the same attribute should be consistent between different pedestrian images, \eg, the ``hat" attribute and the ``boots" attribute are always located at the top and bottom of the picture respectively. In addition, the inherent semantic feature of the ``hat" attribute should be consistent, whether it is a baseball cap, beret, or helmet. To fully exploit inter-image relations and aggregate human prior in the model learning process, we construct a Spatial and Semantic Consistency (SSC) framework that consists of two complementary regularizations to achieve spatial and semantic consistency for each attribute. Specifically, we first propose a spatial consistency regularization to focus on reliable and stable attribute-related regions. Based on the precise attribute locations, we further propose a semantic consistency regularization to extract intrinsic and discriminative semantic features. We conduct extensive experiments on popular benchmarks including PA100K, RAP, and PETA. Results show that the proposed method performs favorably against state-of-the-art methods without increasing parameters.
VCNet: A Robust Approach to Blind Image Inpainting
Mar 15, 2020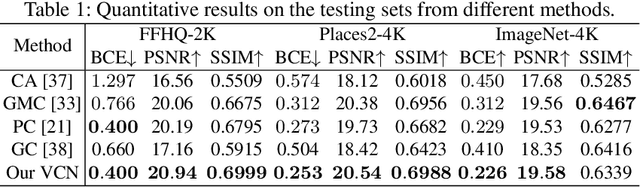
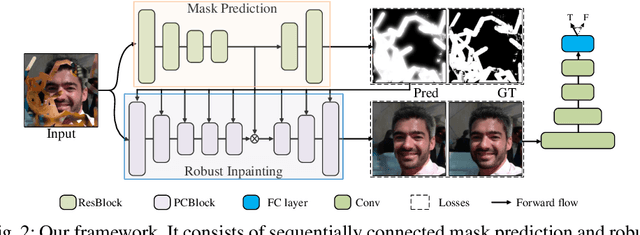
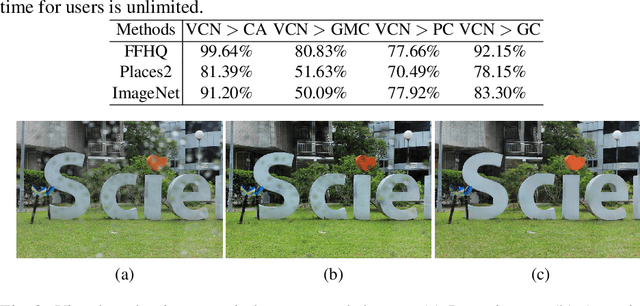

Blind inpainting is a task to automatically complete visual contents without specifying masks for missing areas in an image. Previous works assume missing region patterns are known, limiting its application scope. In this paper, we relax the assumption by defining a new blind inpainting setting, making training a blind inpainting neural system robust against various unknown missing region patterns. Specifically, we propose a two-stage visual consistency network (VCN), meant to estimate where to fill (via masks) and generate what to fill. In this procedure, the unavoidable potential mask prediction errors lead to severe artifacts in the subsequent repairing. To address it, our VCN predicts semantically inconsistent regions first, making mask prediction more tractable. Then it repairs these estimated missing regions using a new spatial normalization, enabling VCN to be robust to the mask prediction errors. In this way, semantically convincing and visually compelling content is thus generated. Extensive experiments are conducted, showing our method is effective and robust in blind image inpainting. And our VCN allows for a wide spectrum of applications.
Investigating a Baseline Of Self Supervised Learning Towards Reducing Labeling Costs For Image Classification
Aug 17, 2021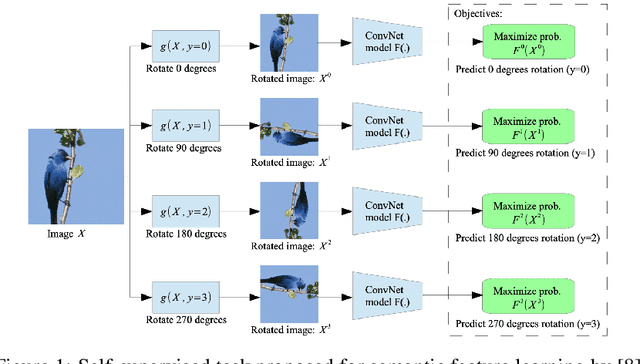
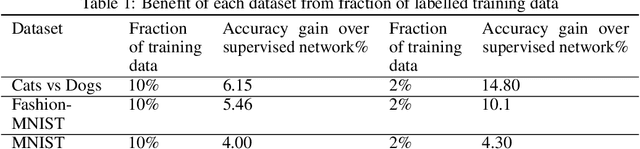
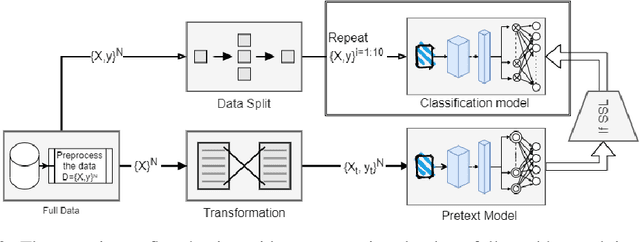
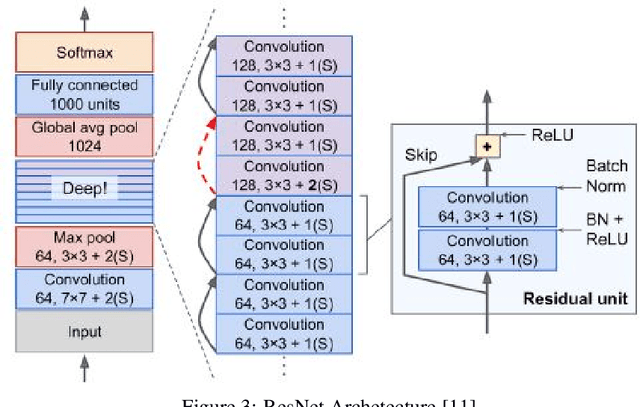
Data labeling in supervised learning is considered an expensive and infeasible tool in some conditions. The self-supervised learning method is proposed to tackle the learning effectiveness with fewer labeled data, however, there is a lack of confidence in the size of labeled data needed to achieve adequate results. This study aims to draw a baseline on the proportion of the labeled data that models can appreciate to yield competent accuracy when compared to training with additional labels. The study implements the kaggle.com' cats-vs-dogs dataset, Mnist and Fashion-Mnist to investigate the self-supervised learning task by implementing random rotations augmentation on the original datasets. To reveal the true effectiveness of the pretext process in self-supervised learning, the original dataset is divided into smaller batches, and learning is repeated on each batch with and without the pretext pre-training. Results show that the pretext process in the self-supervised learning improves the accuracy around 15% in the downstream classification task when compared to the plain supervised learning.