 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Scientific Discovery by Generating Counterfactuals using Image Translation
Jul 10, 2020

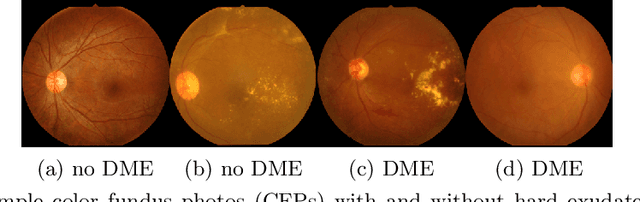
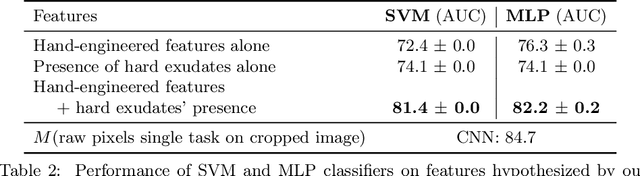
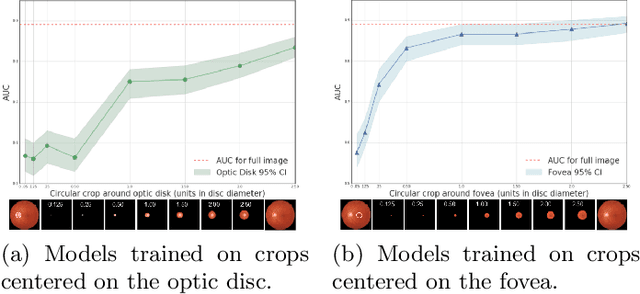
Model explanation techniques play a critical role in understanding the source of a model's performance and making its decisions transparent. Here we investigate if explanation techniques can also be used as a mechanism for scientific discovery. We make three contributions: first, we propose a framework to convert predictions from explanation techniques to a mechanism of discovery. Second, we show how generative models in combination with black-box predictors can be used to generate hypotheses (without human priors) that can be critically examined. Third, with these techniques we study classification models for retinal images predicting Diabetic Macular Edema (DME), where recent work showed that a CNN trained on these images is likely learning novel features in the image. We demonstrate that the proposed framework is able to explain the underlying scientific mechanism, thus bridging the gap between the model's performance and human understanding.
* Accepted at MICCAI 2020. This version combines camera-ready and supplement
Cross-Modality Fusion Transformer for Multispectral Object Detection
Oct 30, 2021
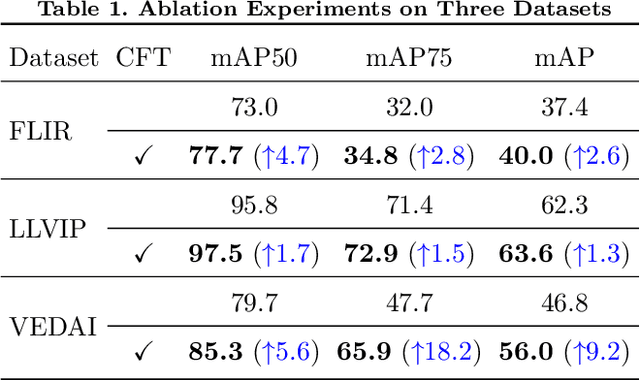
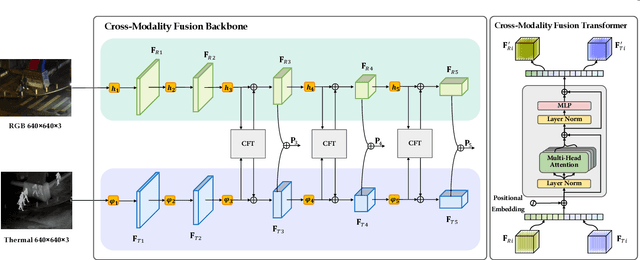
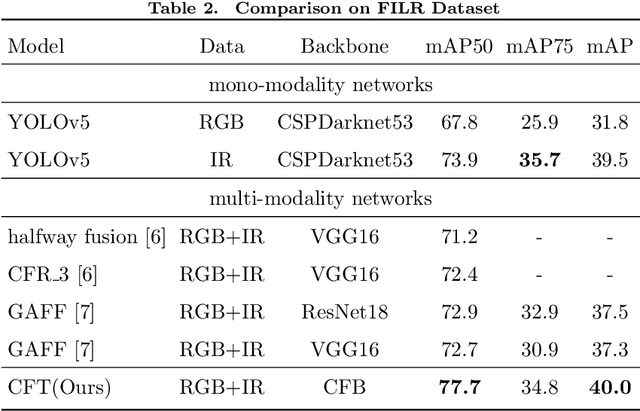
Multispectral image pairs can provide the combined information, making object detection applications more reliable and robust in the open world. To fully exploit the different modalities, we present a simple yet effective cross-modality feature fusion approach, named Cross-Modality Fusion Transformer (CFT) in this paper. Unlike prior CNNs-based works, guided by the transformer scheme, our network learns long-range dependencies and integrates global contextual information in the feature extraction stage. More importantly, by leveraging the self attention of the transformer, the network can naturally carry out simultaneous intra-modality and inter-modality fusion, and robustly capture the latent interactions between RGB and Thermal domains, thereby significantly improving the performance of multispectral object detection. Extensive experiments and ablation studies on multiple datasets demonstrate that our approach is effective and achieves state-of-the-art detection performance. Our code and models will be released soon at https://github.com/DocF/multispectral-object-detection.
Focusing on Persons: Colorizing Old Images Learning from Modern Historical Movies
Aug 14, 2021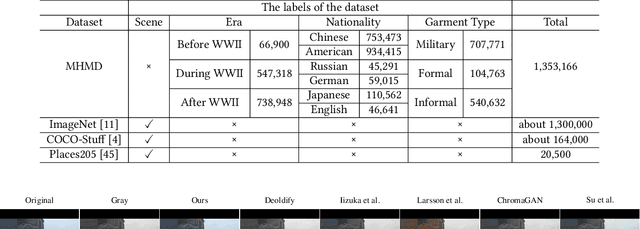
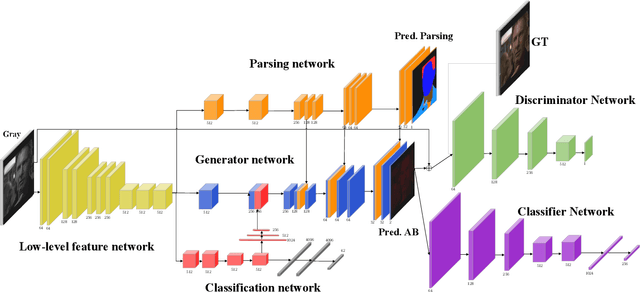
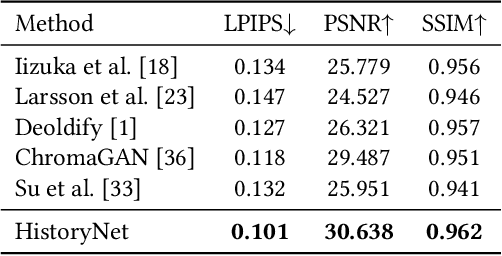
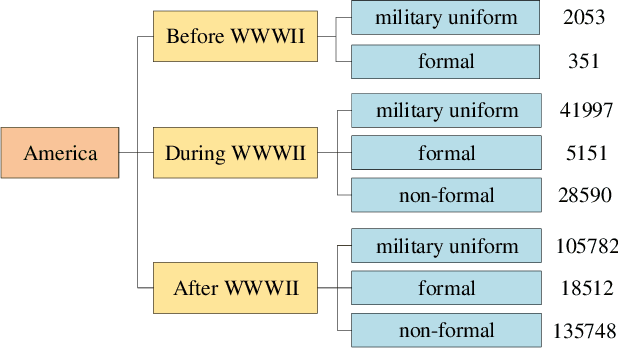
In industry, there exist plenty of scenarios where old gray photos need to be automatically colored, such as video sites and archives. In this paper, we present the HistoryNet focusing on historical person's diverse high fidelity clothing colorization based on fine grained semantic understanding and prior. Colorization of historical persons is realistic and practical, however, existing methods do not perform well in the regards. In this paper, a HistoryNet including three parts, namely, classification, fine grained semantic parsing and colorization, is proposed. Classification sub-module supplies classifying of images according to the eras, nationalities and garment types; Parsing sub-network supplies the semantic for person contours, clothing and background in the image to achieve more accurate colorization of clothes and persons and prevent color overflow. In the training process, we integrate classification and semantic parsing features into the coloring generation network to improve colorization. Through the design of classification and parsing subnetwork, the accuracy of image colorization can be improved and the boundary of each part of image can be more clearly. Moreover, we also propose a novel Modern Historical Movies Dataset (MHMD) containing 1,353,166 images and 42 labels of eras, nationalities, and garment types for automatic colorization from 147 historical movies or TV series made in modern time. Various quantitative and qualitative comparisons demonstrate that our method outperforms the state-of-the-art colorization methods, especially on military uniforms, which has correct colors according to the historical literatures.
Deep Learning-based Frozen Section to FFPE Translation
Jul 27, 2021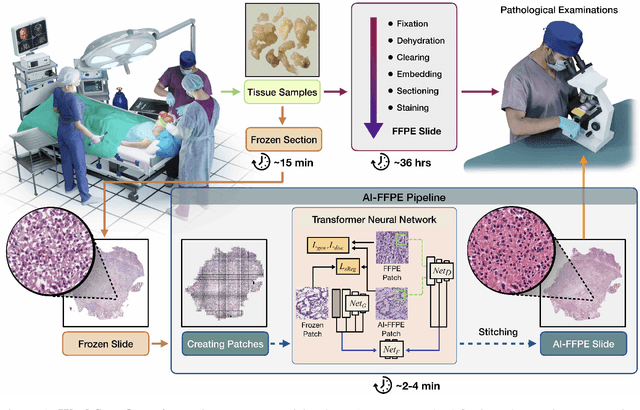
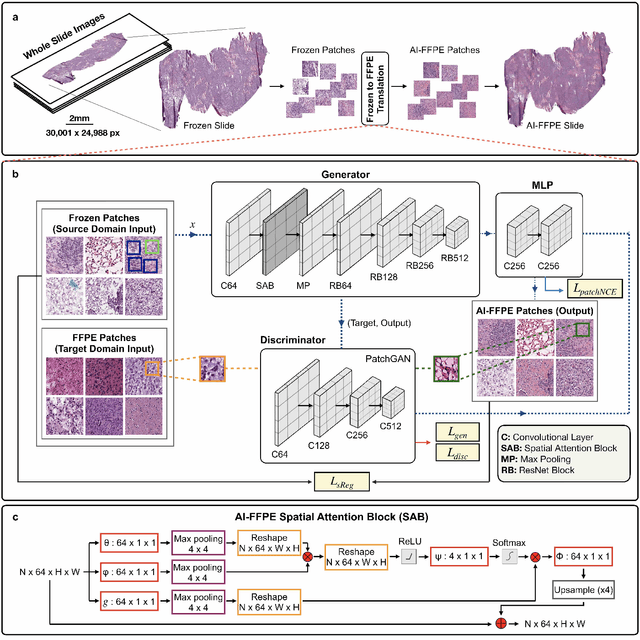
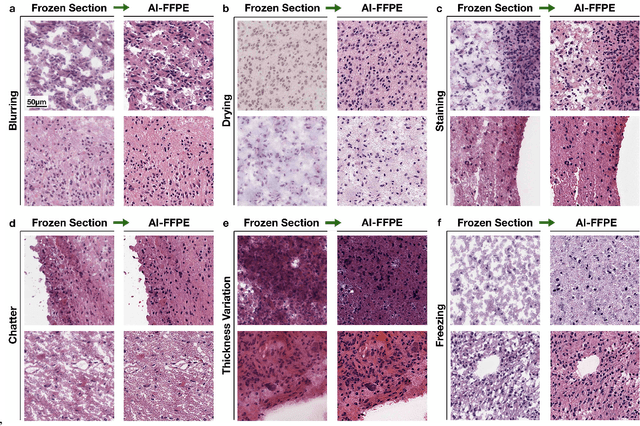
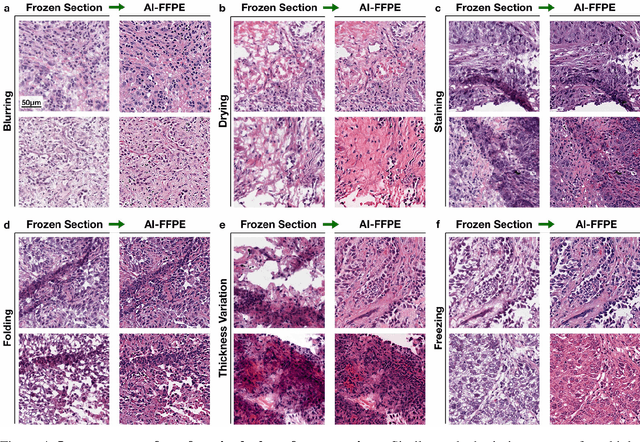
Frozen sectioning (FS) is the preparation method of choice for microscopic evaluation of tissues during surgical operations. The high speed of the procedure allows pathologists to rapidly assess the key microscopic features, such as tumour margins and malignant status to guide surgical decision-making and minimise disruptions to the course of the operation. However, FS is prone to introducing many misleading artificial structures (histological artefacts), such as nuclear ice crystals, compression, and cutting artefacts, hindering timely and accurate diagnostic judgement of the pathologist. Additional training and prolonged experience is often required to make highly effective and time-critical diagnosis on frozen sections. On the other hand, the gold standard tissue preparation technique of formalin-fixation and paraffin-embedding (FFPE) provides significantly superior image quality, but is a very time-consuming process (12-48 hours), making it unsuitable for intra-operative use. In this paper, we propose an artificial intelligence (AI) method that improves FS image quality by computationally transforming frozen-sectioned whole-slide images (FS-WSIs) into whole-slide FFPE-style images in minutes. AI-FFPE rectifies FS artefacts with the guidance of an attention mechanism that puts a particular emphasis on artefacts while utilising a self-regularization mechanism established between FS input image and synthesized FFPE-style image that preserves clinically relevant features. As a result, AI-FFPE method successfully generates FFPE-style images without significantly extending tissue processing time and consequently improves diagnostic accuracy. We demonstrate the efficacy of AI-FFPE on lung and brain frozen sections using a variety of different qualitative and quantitative metrics including visual Turing tests from 20 board certified pathologists.
Paint4Poem: A Dataset for Artistic Visualization of Classical Chinese Poems
Sep 23, 2021

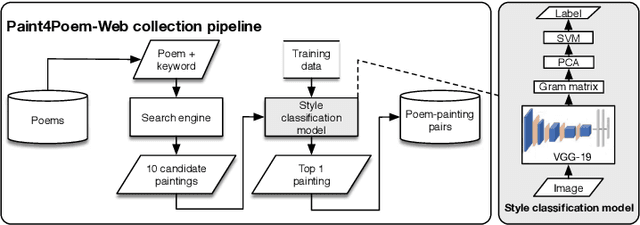
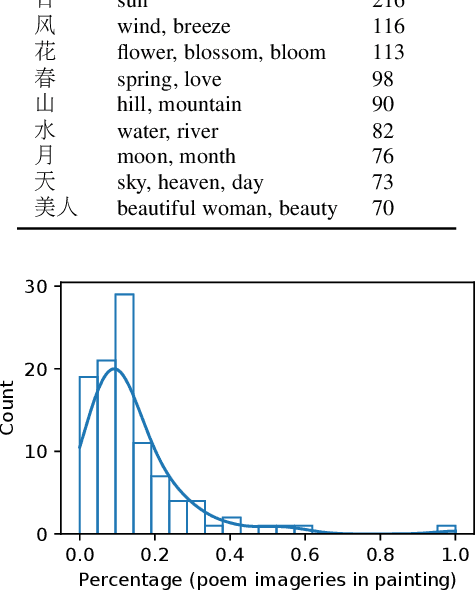
In this work we propose a new task: artistic visualization of classical Chinese poems, where the goal is to generatepaintings of a certain artistic style for classical Chinese poems. For this purpose, we construct a new dataset called Paint4Poem. Thefirst part of Paint4Poem consists of 301 high-quality poem-painting pairs collected manually from an influential modern Chinese artistFeng Zikai. As its small scale poses challenges for effectively training poem-to-painting generation models, we introduce the secondpart of Paint4Poem, which consists of 3,648 caption-painting pairs collected manually from Feng Zikai's paintings and 89,204 poem-painting pairs collected automatically from the web. We expect the former to help learning the artist painting style as it containshis most paintings, and the latter to help learning the semantic relevance between poems and paintings. Further, we analyze Paint4Poem regarding poem diversity, painting style, and the semantic relevance between poems and paintings. We create abenchmark for Paint4Poem: we train two representative text-to-image generation models: AttnGAN and MirrorGAN, and evaluate theirperformance regarding painting pictorial quality, painting stylistic relevance, and semantic relevance between poems and paintings.The results indicate that the models are able to generate paintings that have good pictorial quality and mimic Feng Zikai's style, but thereflection of poem semantics is limited. The dataset also poses many interesting research directions on this task, including transferlearning, few-shot learning, text-to-image generation for low-resource data etc. The dataset is publicly available.(https://github.com/paint4poem/paint4poem)
DeepMeshFlow: Content Adaptive Mesh Deformation for Robust Image Registration
Dec 11, 2019
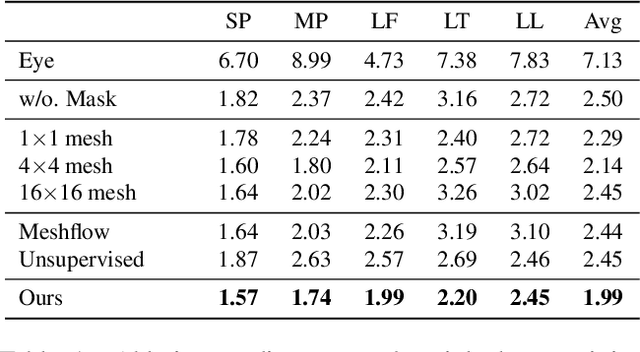
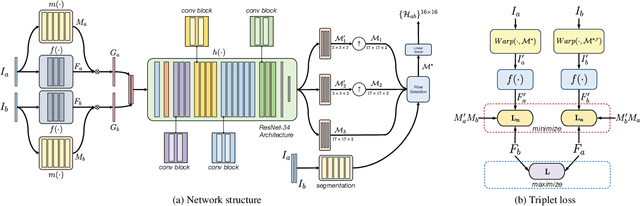

Image alignment by mesh warps, such as meshflow, is a fundamental task which has been widely applied in various vision applications(e.g., multi-frame HDR/denoising, video stabilization). Traditional mesh warp methods detect and match image features, where the quality of alignment highly depends on the quality of image features. However, the image features are not robust in occurrence of low-texture and low-light scenes. Deep homography methods, on the other hand, are free from such problem by learning deep features for robust performance. However, a homography is limited to plane motions. In this work, we present a deep meshflow motion model, which takes two images as input and output a sparse motion field with motions located at mesh vertexes. The deep meshflow enjoys the merics of meshflow that can describe nonlinear motions while also shares advantage of deep homography that is robust against challenging textureless scenarios. In particular, a new unsupervised network structure is presented with content-adaptive capability. On one hand, the image content that cannot be aligned under mesh representation are rejected by our learned mask, similar to the RANSAC procedure. On the other hand, we learn multiple mesh resolutions, combining to a non-uniform mesh division. Moreover, a comprehensive dataset is presented, covering various scenes for training and testing. The comparison between both traditional mesh warp methods and deep based methods show the effectiveness of our deep meshflow motion model.
Feature Detection for Hand Hygiene Stages
Aug 06, 2021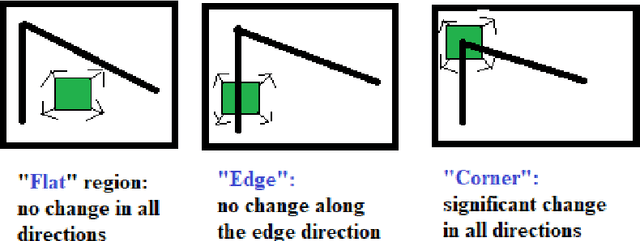
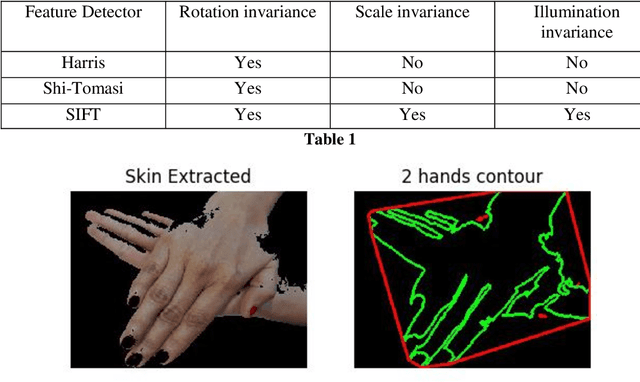
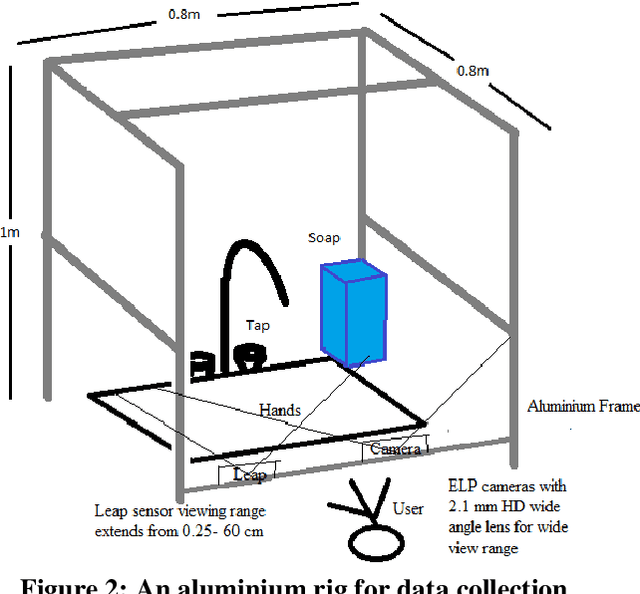
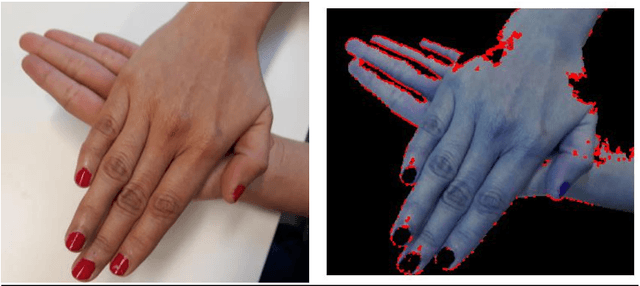
The process of hand washing involves complex hand movements. There are six principal sequential steps for washing hands as per the World Health Organisation (WHO) guidelines. In this work, a detailed description of an aluminium rig construction for creating a robust hand-washing dataset is discussed. The preliminary results with the help of image processing and computer vision algorithms for hand pose extraction and feature detection such as Harris detector, Shi-Tomasi and SIFT are demonstrated. The hand hygiene pose- Rub hands palm to palm was captured as an input image for running all the experiments. The future work will focus upon processing the video recordings of hand movements captured and applying deep-learning solutions for the classification of hand-hygiene stages.
Image Captioning with Visual Object Representations Grounded in the Textual Modality
Oct 20, 2020
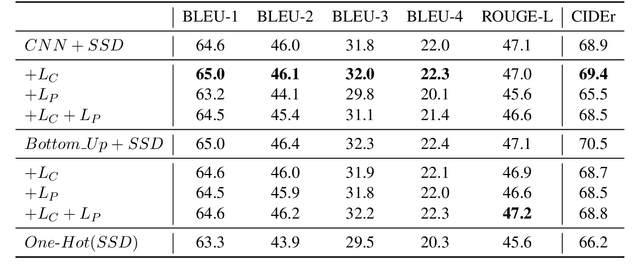
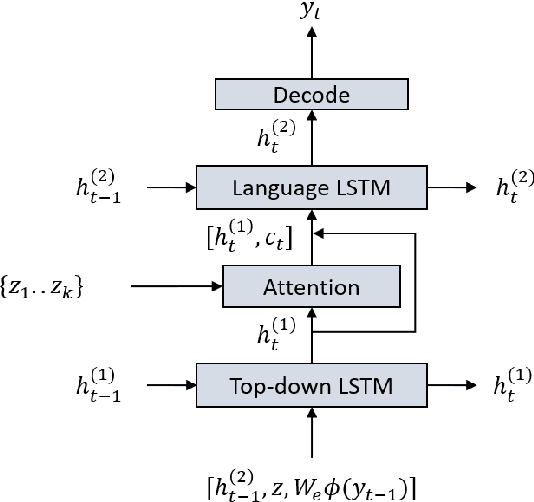
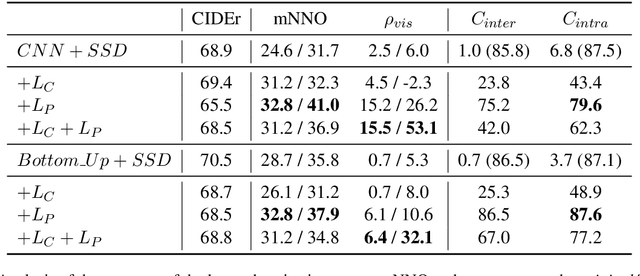
We present our work in progress exploring the possibilities of a shared embedding space between textual and visual modality. Leveraging the textual nature of object detection labels and the hypothetical expressiveness of extracted visual object representations, we propose an approach opposite to the current trend, grounding of the representations in the word embedding space of the captioning system instead of grounding words or sentences in their associated images. Based on the previous work, we apply additional grounding losses to the image captioning training objective aiming to force visual object representations to create more heterogeneous clusters based on their class label and copy a semantic structure of the word embedding space. In addition, we provide an analysis of the learned object vector space projection and its impact on the IC system performance. With only slight change in performance, grounded models reach the stopping criterion during training faster than the unconstrained model, needing about two to three times less training updates. Additionally, an improvement in structural correlation between the word embeddings and both original and projected object vectors suggests that the grounding is actually mutual.
Leveraging Frequency Analysis for Deep Fake Image Recognition
Mar 19, 2020
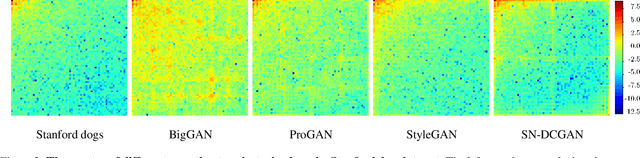
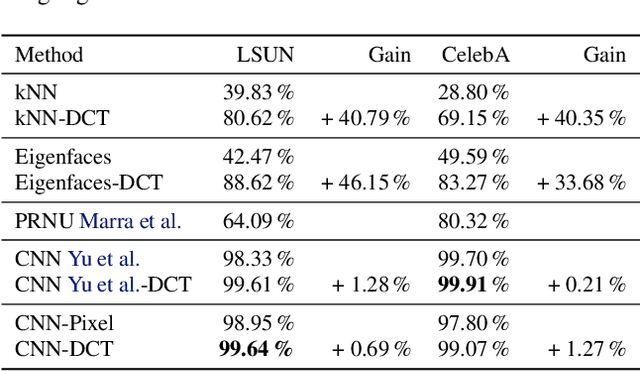
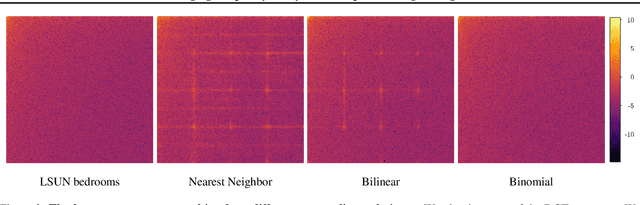
Deep neural networks can generate images that are astonishingly realistic, so much so that it is often hard for humans to distinguish them from actual photos. These achievements have been largely made possible by Generative Adversarial Networks (GANs). While these deep fake images have been thoroughly investigated in the image domain-a classical approach from the area of image forensics-an analysis in the frequency domain has been missing so far. In this paper, we address this shortcoming and our results reveal that in frequency space, GAN-generated images exhibit severe artifacts that can be easily identified. We perform a comprehensive analysis, showing that these artifacts are consistent across different neural network architectures, data sets, and resolutions. In a further investigation, we demonstrate that these artifacts are caused by upsampling operations found in all current GAN architectures, indicating a structural and fundamental problem in the way images are generated via GANs. Based on this analysis, we demonstrate how the frequency representation can be used to identify deep fake images in an automated way, surpassing state-of-the-art methods.
Homogeneous and Heterogeneous Relational Graph for Visible-infrared Person Re-identification
Sep 18, 2021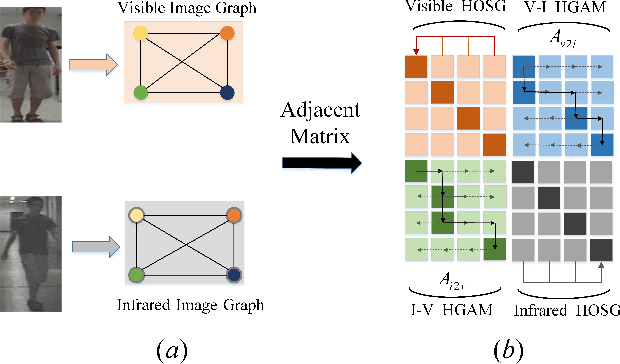
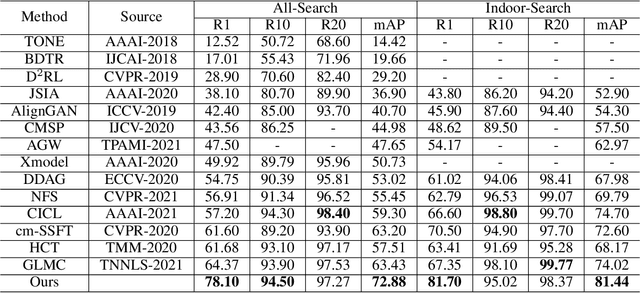
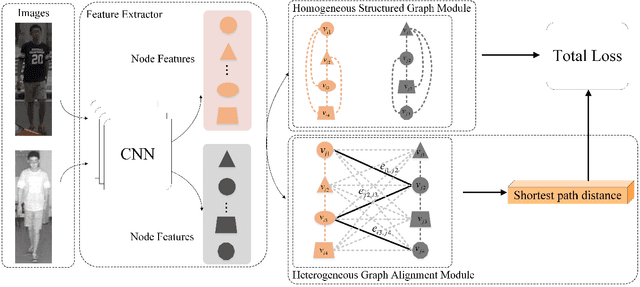
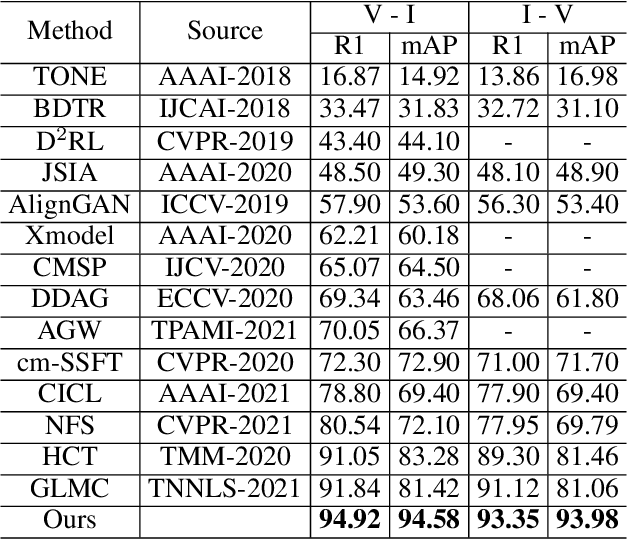
Visible-infrared person re-identification (VI Re-ID) aims to match person images between the visible and infrared modalities. Existing VI Re-ID methods mainly focus on extracting homogeneous structural relationships from a single image, while ignoring the heterogeneous correlation between cross-modality images. The homogenous and heterogeneous structured relationships are crucial to learning effective identity representation and cross-modality matching. In this paper, we separately model the homogenous structural relationship by a modality-specific graph within individual modality and then mine the heterogeneous structural correlation in these two modality-specific graphs. First, the homogeneous structured graph (HOSG) mines one-vs.-rest relation between an arbitrary node (local feature) and all the rest nodes within a visible or infrared image to learn effective identity representation. Second, to find cross-modality identity-consistent correspondence, the heterogeneous graph alignment module (HGAM) further measures the relational edge strength by route search between two-modality local node features. Third, we propose the cross-modality cross-correlation (CMCC) loss to extract the modality invariance in heterogeneous global graph representation. CMCC computes the mutual information between modalities and expels semantic redundancy. Extensive experiments on SYSU-MM01 and RegDB datasets demonstrate that our method outperforms state-of-the-arts with a gain of 13.73\% and 9.45\% Rank1/mAP. The code is available at https://github.com/fegnyujian/Homogeneous-and-Heterogeneous-Relational-Graph.