 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Robustness in Deep Learning for Computer Vision: Mind the gap?
Dec 01, 2021
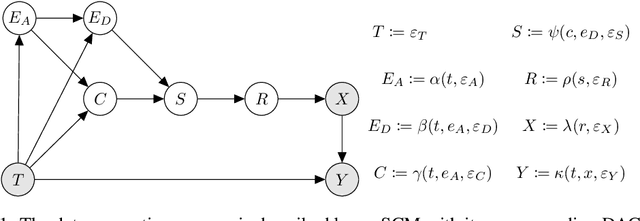

Deep neural networks for computer vision tasks are deployed in increasingly safety-critical and socially-impactful applications, motivating the need to close the gap in model performance under varied, naturally occurring imaging conditions. Robustness, ambiguously used in multiple contexts including adversarial machine learning, here then refers to preserving model performance under naturally-induced image corruptions or alterations. We perform a systematic review to identify, analyze, and summarize current definitions and progress towards non-adversarial robustness in deep learning for computer vision. We find that this area of research has received disproportionately little attention relative to adversarial machine learning, yet a significant robustness gap exists that often manifests in performance degradation similar in magnitude to adversarial conditions. To provide a more transparent definition of robustness across contexts, we introduce a structural causal model of the data generating process and interpret non-adversarial robustness as pertaining to a model's behavior on corrupted images which correspond to low-probability samples from the unaltered data distribution. We then identify key architecture-, data augmentation-, and optimization tactics for improving neural network robustness. This causal view of robustness reveals that common practices in the current literature, both in regards to robustness tactics and evaluations, correspond to causal concepts, such as soft interventions resulting in a counterfactually-altered distribution of imaging conditions. Through our findings and analysis, we offer perspectives on how future research may mind this evident and significant non-adversarial robustness gap.
Equivariant $Q$ Learning in Spatial Action Spaces
Oct 28, 2021



Recently, a variety of new equivariant neural network model architectures have been proposed that generalize better over rotational and reflectional symmetries than standard models. These models are relevant to robotics because many robotics problems can be expressed in a rotationally symmetric way. This paper focuses on equivariance over a visual state space and a spatial action space -- the setting where the robot action space includes a subset of $\rm{SE}(2)$. In this situation, we know a priori that rotations and translations in the state image should result in the same rotations and translations in the spatial action dimensions of the optimal policy. Therefore, we can use equivariant model architectures to make $Q$ learning more sample efficient. This paper identifies when the optimal $Q$ function is equivariant and proposes $Q$ network architectures for this setting. We show experimentally that this approach outperforms standard methods in a set of challenging manipulation problems.
Determining Sequence of Image Processing Technique (IPT) to Detect Adversarial Attacks
Jul 07, 2020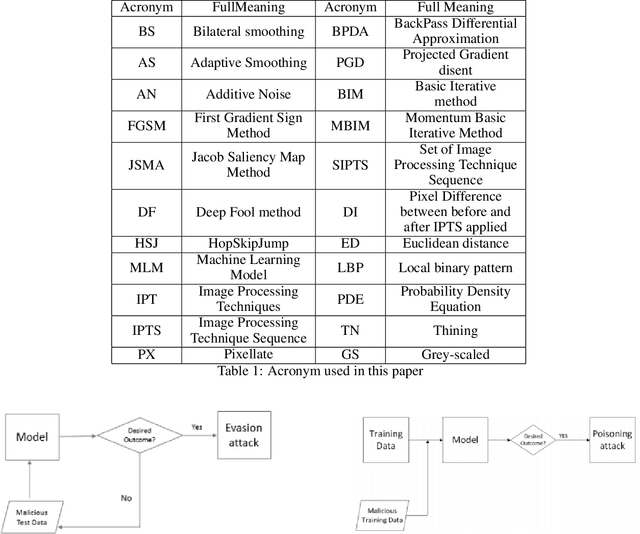

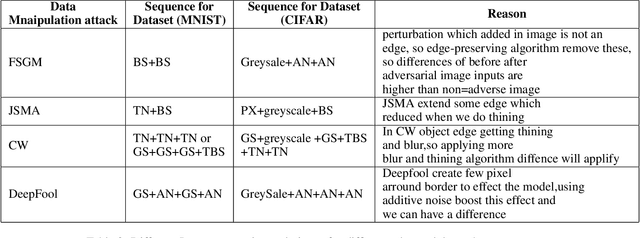
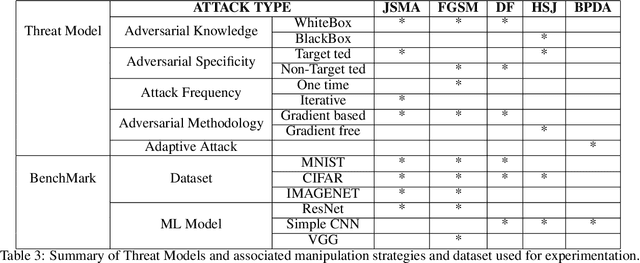
Developing secure machine learning models from adversarial examples is challenging as various methods are continually being developed to generate adversarial attacks. In this work, we propose an evolutionary approach to automatically determine Image Processing Techniques Sequence (IPTS) for detecting malicious inputs. Accordingly, we first used a diverse set of attack methods including adaptive attack methods (on our defense) to generate adversarial samples from the clean dataset. A detection framework based on a genetic algorithm (GA) is developed to find the optimal IPTS, where the optimality is estimated by different fitness measures such as Euclidean distance, entropy loss, average histogram, local binary pattern and loss functions. The "image difference" between the original and processed images is used to extract the features, which are then fed to a classification scheme in order to determine whether the input sample is adversarial or clean. This paper described our methodology and performed experiments using multiple data-sets tested with several adversarial attacks. For each attack-type and dataset, it generates unique IPTS. A set of IPTS selected dynamically in testing time which works as a filter for the adversarial attack. Our empirical experiments exhibited promising results indicating the approach can efficiently be used as processing for any AI model.
TCDesc: Learning Topology Consistent Descriptors for Image Matching
Sep 13, 2020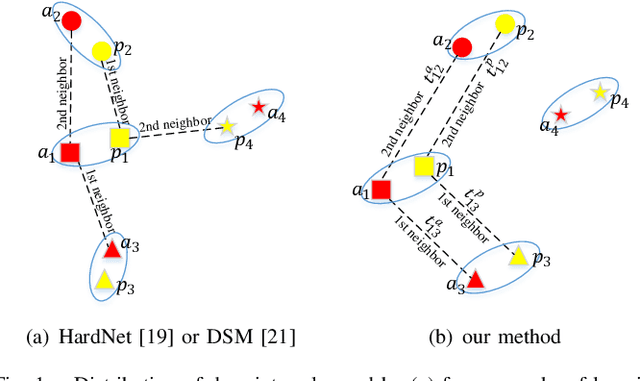
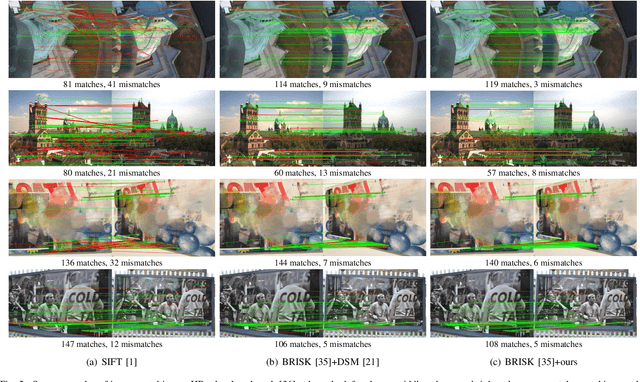
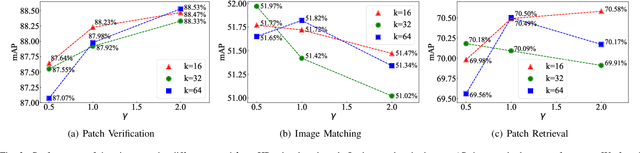

The constraint of neighborhood consistency or local consistency is widely used for robust image matching. In this paper, we focus on learning neighborhood topology consistent descriptors (TCDesc), while former works of learning descriptors, such as HardNet and DSM, only consider point-to-point Euclidean distance among descriptors and totally neglect neighborhood information of descriptors. To learn topology consistent descriptors, first we propose the linear combination weights to depict the topological relationship between center descriptor and its kNN descriptors, where the difference between center descriptor and the linear combination of its kNN descriptors is minimized. Then we propose the global mapping function which maps the local linear combination weights to the global topology vector and define the topology distance of matching descriptors as l1 distance between their topology vectors. Last we employ adaptive weighting strategy to jointly minimize topology distance and Euclidean distance, which automatically adjust the weight or attention of two distances in triplet loss. Our method has the following two advantages: (1) We are the first to consider neighborhood information of descriptors, while former works mainly focus on neighborhood consistency of feature points; (2) Our method can be applied in any former work of learning descriptors by triplet loss. Experimental results verify the generalization of our method: We can improve the performances of both HardNet and DSM on several benchmarks.
Segmentation of Lungs COVID Infected Regions by Attention Mechanism and Synthetic Data
Aug 19, 2021
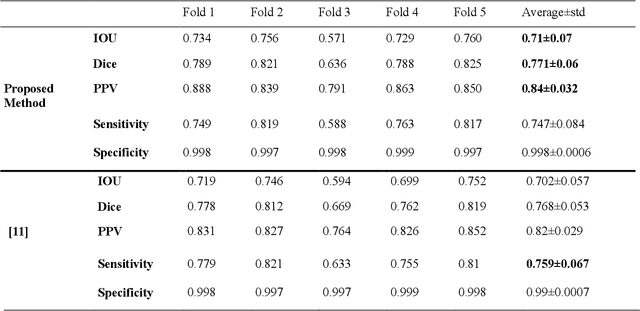
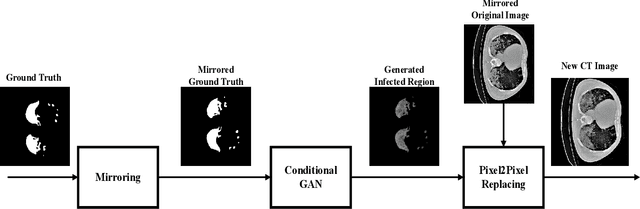
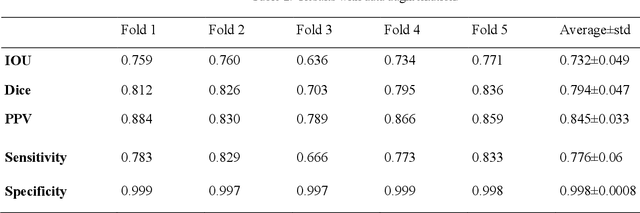
Coronavirus has caused hundreds of thousands of deaths. Fatalities could decrease if every patient could get suitable treatment by the healthcare system. Machine learning, especially computer vision methods based on deep learning, can help healthcare professionals diagnose and treat COVID-19 infected cases more efficiently. Hence, infected patients can get better service from the healthcare system and decrease the number of deaths caused by the coronavirus. This research proposes a method for segmenting infected lung regions in a CT image. For this purpose, a convolutional neural network with an attention mechanism is used to detect infected areas with complex patterns. Attention blocks improve the segmentation accuracy by focusing on informative parts of the image. Furthermore, a generative adversarial network generates synthetic images for data augmentation and expansion of small available datasets. Experimental results show the superiority of the proposed method compared to some existing procedures.
Image Restoration using Plug-and-Play CNN MAP Denoisers
Dec 18, 2019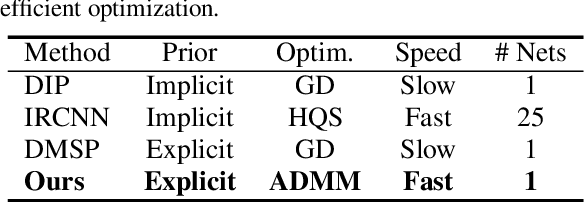
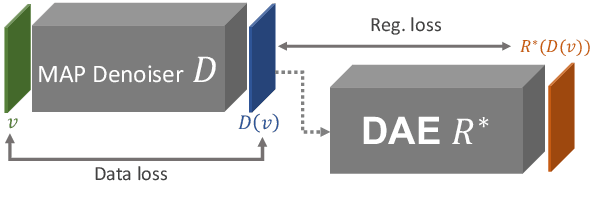

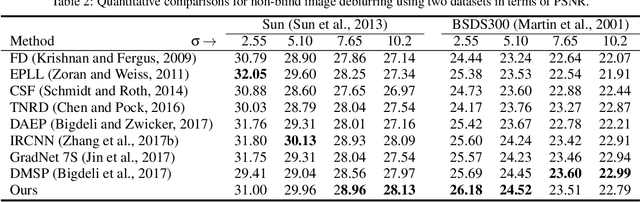
Plug-and-play denoisers can be used to perform generic image restoration tasks independent of the degradation type. These methods build on the fact that the Maximum a Posteriori (MAP) optimization can be solved using smaller sub-problems, including a MAP denoising optimization. We present the first end-to-end approach to MAP estimation for image denoising using deep neural networks. We show that our method is guaranteed to minimize the MAP denoising objective, which is then used in an optimization algorithm for generic image restoration. We provide theoretical analysis of our approach and show the quantitative performance of our method in several experiments. Our experimental results show that the proposed method can achieve 70x faster performance compared to the state-of-the-art, while maintaining the theoretical perspective of MAP.
MimicGAN: Robust Projection onto Image Manifolds with Corruption Mimicking
Feb 07, 2020
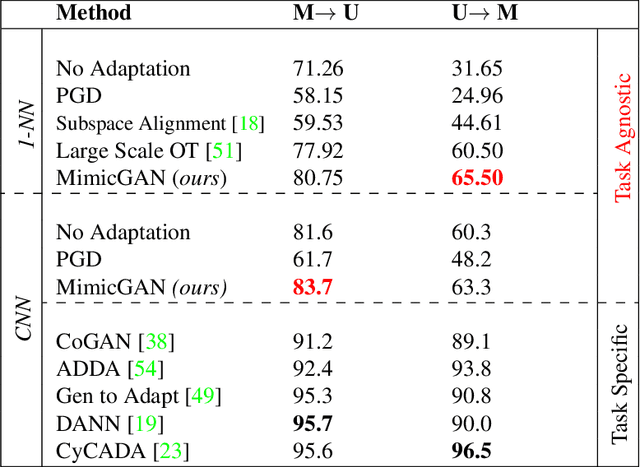
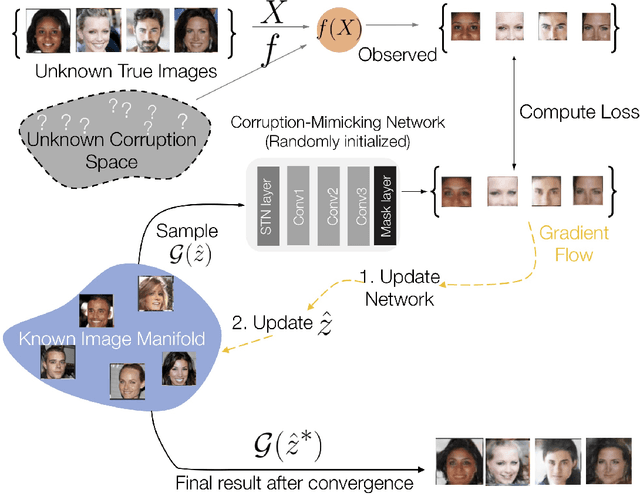
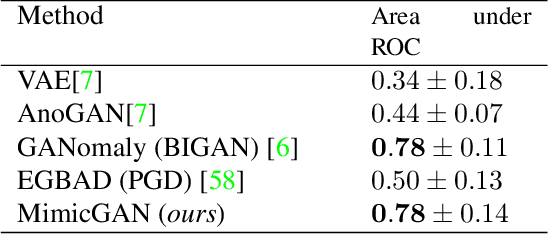
In the past few years, Generative Adversarial Networks (GANs) have dramatically advanced our ability to represent and parameterize high-dimensional, non-linear image manifolds. As a result, they have been widely adopted across a variety of applications, ranging from challenging inverse problems like image completion, to problems such as anomaly detection and adversarial defense. A recurring theme in many of these applications is the notion of projecting an image observation onto the manifold that is inferred by the generator. In this context, Projected Gradient Descent (PGD) has been the most popular approach, which essentially optimizes for a latent vector that minimizes the discrepancy between a generated image and the given observation. However, PGD is a brittle optimization technique that fails to identify the right projection (or latent vector) when the observation is corrupted, or perturbed even by a small amount. Such corruptions are common in the real world, for example images in the wild come with unknown crops, rotations, missing pixels, or other kinds of non-linear distributional shifts which break current encoding methods, rendering downstream applications unusable. To address this, we propose corruption mimicking -- a new robust projection technique, that utilizes a surrogate network to approximate the unknown corruption directly at test time, without the need for additional supervision or data augmentation. The proposed method is significantly more robust than PGD and other competing methods under a wide variety of corruptions, thereby enabling a more effective use of GANs in real-world applications. More importantly, we show that our approach produces state-of-the-art performance in several GAN-based applications -- anomaly detection, domain adaptation, and adversarial defense, that benefit from an accurate projection.
Hyperspectral Image Denoising with Log-Based Robust PCA
May 25, 2021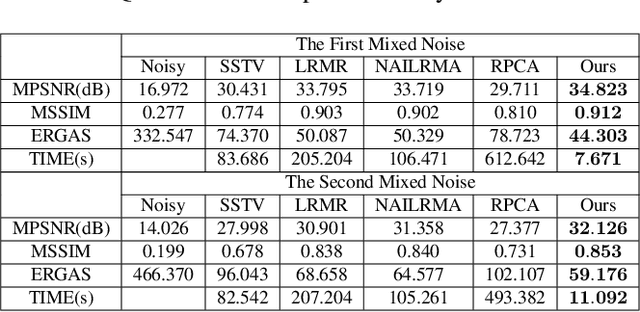


It is a challenging task to remove heavy and mixed types of noise from Hyperspectral images (HSIs). In this paper, we propose a novel nonconvex approach to RPCA for HSI denoising, which adopts the log-determinant rank approximation and a novel $\ell_{2,\log}$ norm, to restrict the low-rank or column-wise sparse properties for the component matrices, respectively.For the $\ell_{2,\log}$-regularized shrinkage problem, we develop an efficient, closed-form solution, which is named $\ell_{2,\log}$-shrinkage operator, which can be generally used in other problems. Extensive experiments on both simulated and real HSIs demonstrate the effectiveness of the proposed method in denoising HSIs.
RevPHiSeg: A Memory-Efficient Neural Network for Uncertainty Quantification in Medical Image Segmentation
Aug 18, 2020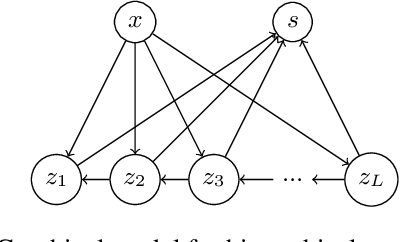
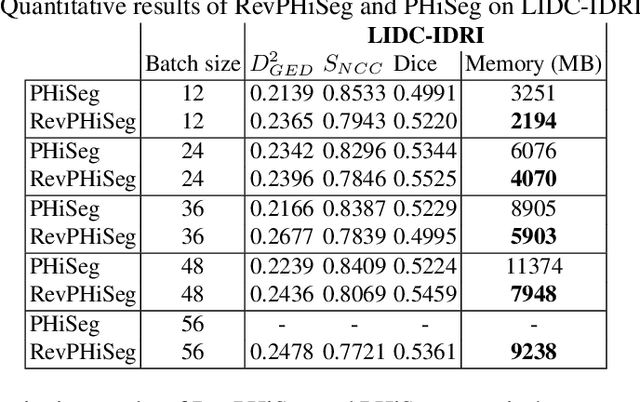
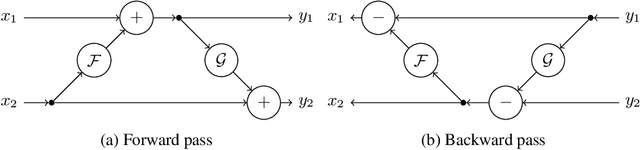
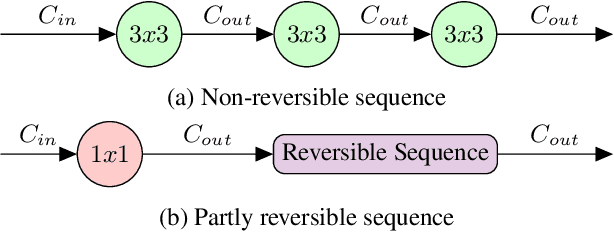
Quantifying segmentation uncertainty has become an important issue in medical image analysis due to the inherent ambiguity of anatomical structures and its pathologies. Recently, neural network-based uncertainty quantification methods have been successfully applied to various problems. One of the main limitations of the existing techniques is the high memory requirement during training; which limits their application to processing smaller field-of-views (FOVs) and/or using shallower architectures. In this paper, we investigate the effect of using reversible blocks for building memory-efficient neural network architectures for quantification of segmentation uncertainty. The reversible architecture achieves memory saving by exactly computing the activations from the outputs of the subsequent layers during backpropagation instead of storing the activations for each layer. We incorporate the reversible blocks into a recently proposed architecture called PHiSeg that is developed for uncertainty quantification in medical image segmentation. The reversible architecture, RevPHiSeg, allows training neural networks for quantifying segmentation uncertainty on GPUs with limited memory and processing larger FOVs. We perform experiments on the LIDC-IDRI dataset and an in-house prostate dataset, and present comparisons with PHiSeg. The results demonstrate that RevPHiSeg consumes ~30% less memory compared to PHiSeg while achieving very similar segmentation accuracy.
Can adversarial training learn image captioning ?
Oct 31, 2019

Recently, generative adversarial networks (GAN) have gathered a lot of interest. Their efficiency in generating unseen samples of high quality, especially images, has improved over the years. In the field of Natural Language Generation (NLG), the use of the adversarial setting to generate meaningful sentences has shown to be difficult for two reasons: the lack of existing architectures to produce realistic sentences and the lack of evaluation tools. In this paper, we propose an adversarial architecture related to the conditional GAN (cGAN) that generates sentences according to a given image (also called image captioning). This attempt is the first that uses no pre-training or reinforcement methods. We also explain why our experiment settings can be safely evaluated and interpreted for further works.