 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Detecting AutoAttack Perturbations in the Frequency Domain
Nov 16, 2021
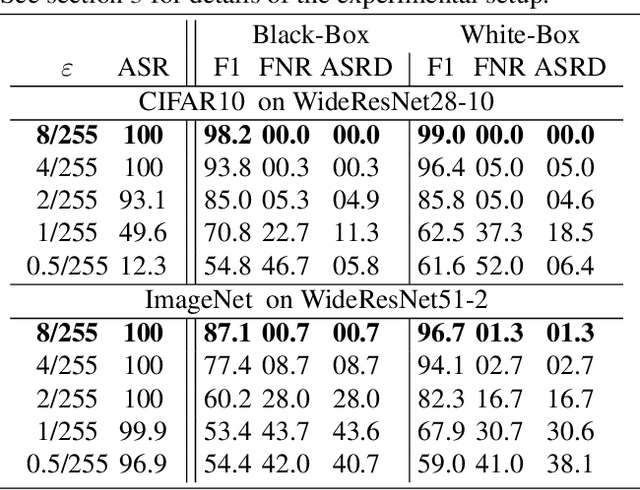
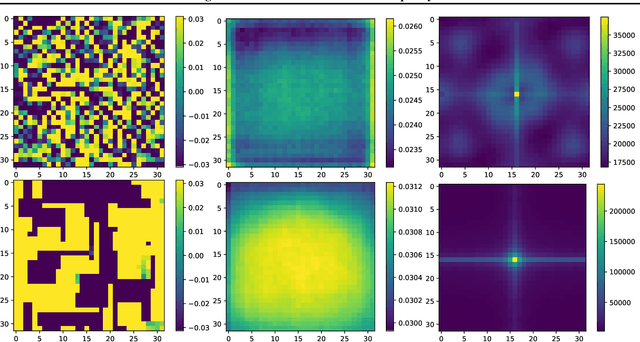

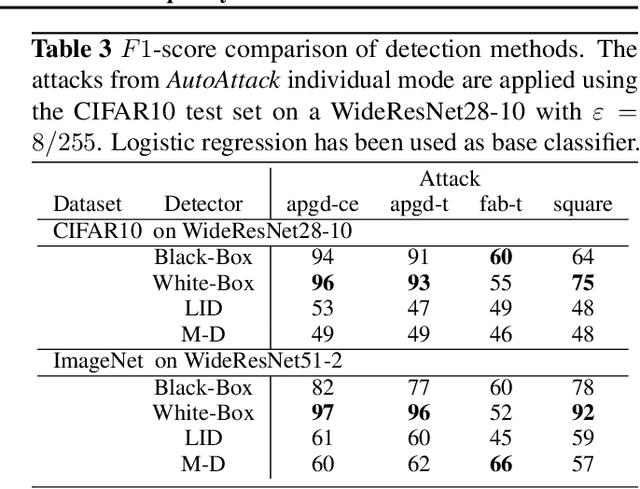
Recently, adversarial attacks on image classification networks by the AutoAttack (Croce and Hein, 2020b) framework have drawn a lot of attention. While AutoAttack has shown a very high attack success rate, most defense approaches are focusing on network hardening and robustness enhancements, like adversarial training. This way, the currently best-reported method can withstand about 66% of adversarial examples on CIFAR10. In this paper, we investigate the spatial and frequency domain properties of AutoAttack and propose an alternative defense. Instead of hardening a network, we detect adversarial attacks during inference, rejecting manipulated inputs. Based on a rather simple and fast analysis in the frequency domain, we introduce two different detection algorithms. First, a black box detector that only operates on the input images and achieves a detection accuracy of 100% on the AutoAttack CIFAR10 benchmark and 99.3% on ImageNet, for epsilon = 8/255 in both cases. Second, a whitebox detector using an analysis of CNN feature maps, leading to a detection rate of also 100% and 98.7% on the same benchmarks.
Mask Editor : an Image Annotation Tool for Image Segmentation Tasks
Sep 17, 2018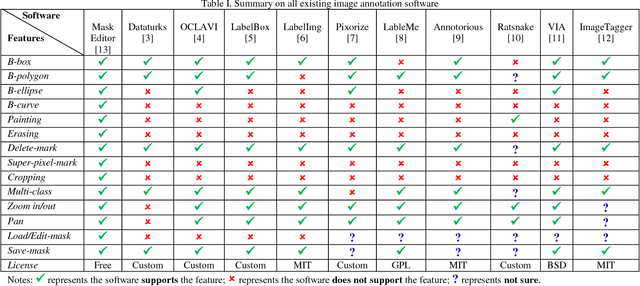
Deep convolutional neural network (DCNN) is the state-of-the-art method for image segmentation, which is one of key challenging computer vision tasks. However, DCNN requires a lot of training images with corresponding image masks to get a good segmentation result. Image annotation software which is easy to use and allows fast image mask generation is in great demand. To the best of our knowledge, all existing image annotation software support only drawing bounding polygons, bounding boxes, or bounding ellipses to mark target objects. These existing software are inefficient when targeting objects that have irregular shapes (e.g., defects in fabric images or tire images). In this paper we design an easy-to-use image annotation software called Mask Editor for image mask generation. Mask Editor allows drawing any bounding curve to mark objects and improves efficiency to mark objects with irregular shapes. Mask Editor also supports drawing bounding polygons, drawing bounding boxes, drawing bounding ellipses, painting, erasing, super-pixel-marking, image cropping, multi-class masks, mask loading, and mask modifying.
Deep Learning for HDR Imaging: State-of-the-Art and Future Trends
Nov 02, 2021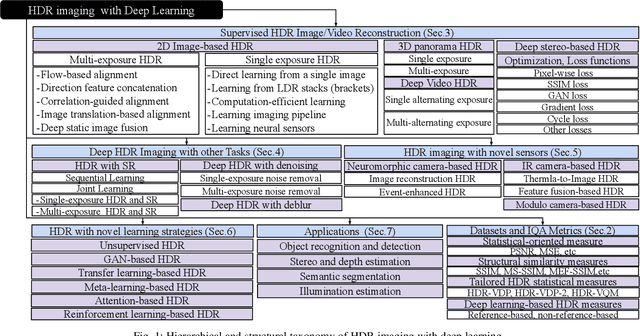
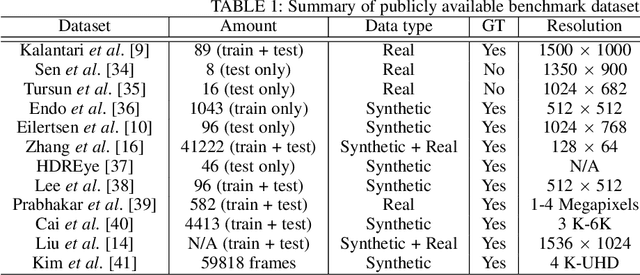
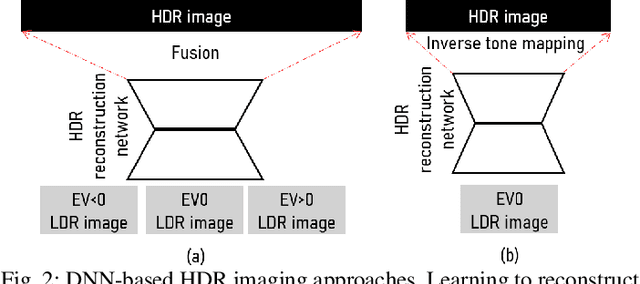
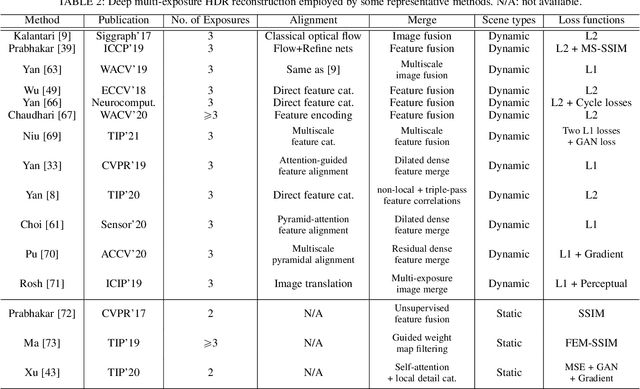
High dynamic range (HDR) imaging is a technique that allows an extensive dynamic range of exposures, which is important in image processing, computer graphics, and computer vision. In recent years, there has been a significant advancement in HDR imaging using deep learning (DL). This study conducts a comprehensive and insightful survey and analysis of recent developments in deep HDR imaging methodologies. We hierarchically and structurally group existing deep HDR imaging methods into five categories based on (1) number/domain of input exposures, (2) number of learning tasks, (3) novel sensor data, (4) novel learning strategies, and (5) applications. Importantly, we provide a constructive discussion on each category regarding its potential and challenges. Moreover, we review some crucial aspects of deep HDR imaging, such as datasets and evaluation metrics. Finally, we highlight some open problems and point out future research directions.
Automatic image-based identification and biomass estimation of invertebrates
Feb 05, 2020
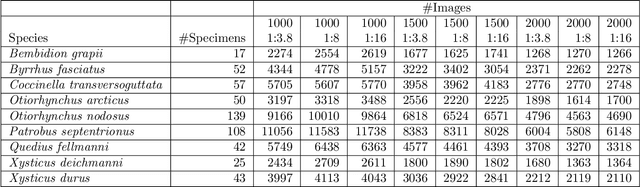
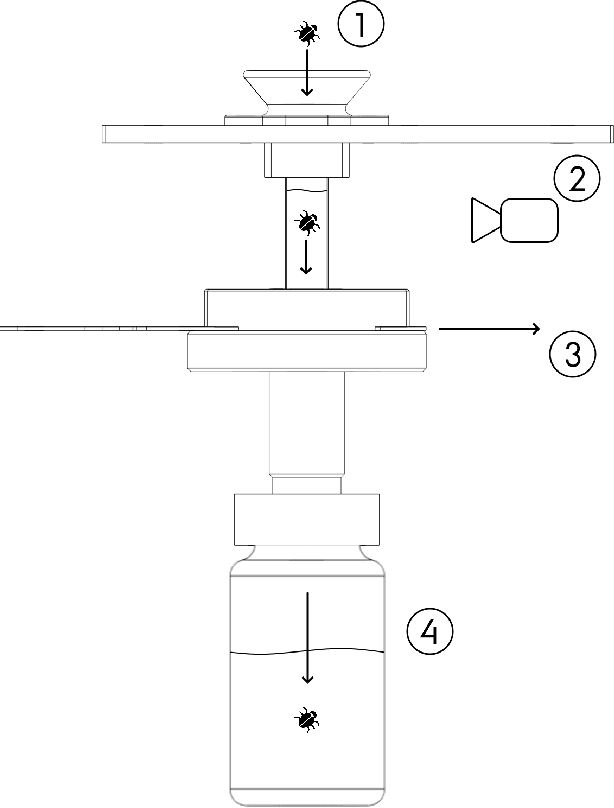

Understanding how biological communities respond to environmental changes is a key challenge in ecology and ecosystem management. The apparent decline of insect populations necessitates more biomonitoring but the time-consuming sorting and identification of taxa pose strong limitations on how many insect samples can be processed. In turn, this affects the scale of efforts to map invertebrate diversity altogether. Given recent advances in computer vision, we propose to replace the standard manual approach of human expert-based sorting and identification with an automatic image-based technology. We describe a robot-enabled image-based identification machine, which can automate the process of invertebrate identification, biomass estimation and sample sorting. We use the imaging device to generate a comprehensive image database of terrestrial arthropod species. We use this database to test the classification accuracy i.e. how well the species identity of a specimen can be predicted from images taken by the machine. We also test sensitivity of the classification accuracy to the camera settings (aperture and exposure time) in order to move forward with the best possible image quality. We use state-of-the-art Resnet-50 and InceptionV3 CNNs for the classification task. The results for the initial dataset are very promising ($\overline{ACC}=0.980$). The system is general and can easily be used for other groups of invertebrates as well. As such, our results pave the way for generating more data on spatial and temporal variation in invertebrate abundance, diversity and biomass.
Knowledge Distillation for Object Detection via Rank Mimicking and Prediction-guided Feature Imitation
Dec 09, 2021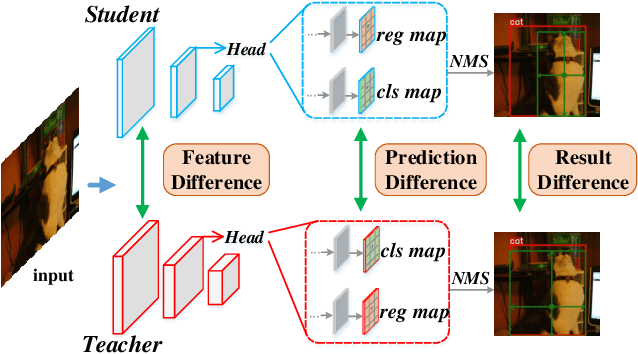
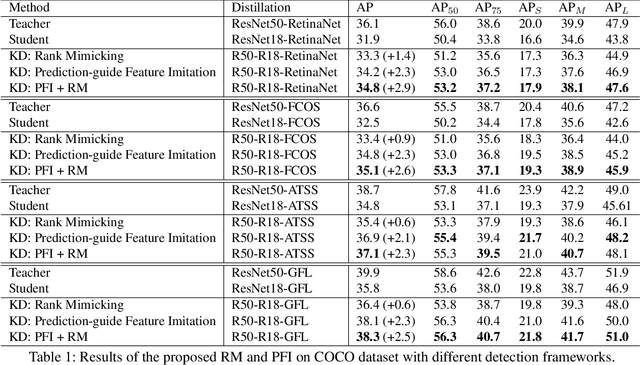
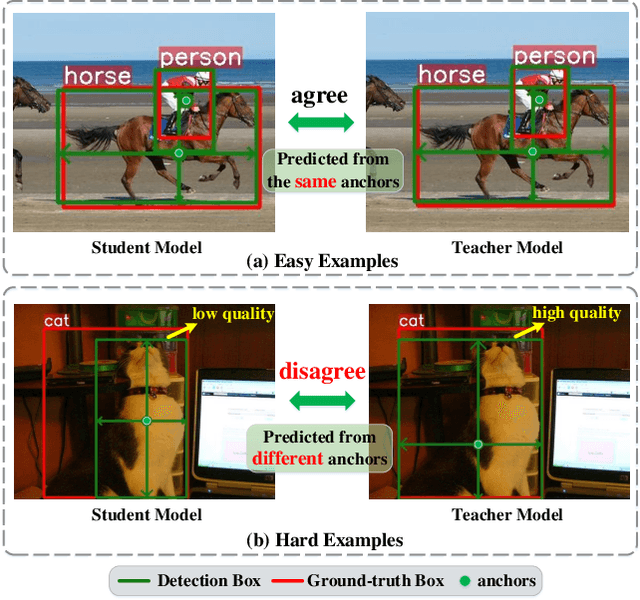
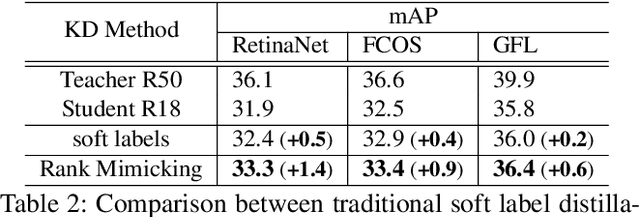
Knowledge Distillation (KD) is a widely-used technology to inherit information from cumbersome teacher models to compact student models, consequently realizing model compression and acceleration. Compared with image classification, object detection is a more complex task, and designing specific KD methods for object detection is non-trivial. In this work, we elaborately study the behaviour difference between the teacher and student detection models, and obtain two intriguing observations: First, the teacher and student rank their detected candidate boxes quite differently, which results in their precision discrepancy. Second, there is a considerable gap between the feature response differences and prediction differences between teacher and student, indicating that equally imitating all the feature maps of the teacher is the sub-optimal choice for improving the student's accuracy. Based on the two observations, we propose Rank Mimicking (RM) and Prediction-guided Feature Imitation (PFI) for distilling one-stage detectors, respectively. RM takes the rank of candidate boxes from teachers as a new form of knowledge to distill, which consistently outperforms the traditional soft label distillation. PFI attempts to correlate feature differences with prediction differences, making feature imitation directly help to improve the student's accuracy. On MS COCO and PASCAL VOC benchmarks, extensive experiments are conducted on various detectors with different backbones to validate the effectiveness of our method. Specifically, RetinaNet with ResNet50 achieves 40.4% mAP in MS COCO, which is 3.5% higher than its baseline, and also outperforms previous KD methods.
Image biomarker standardisation initiative
Sep 17, 2018
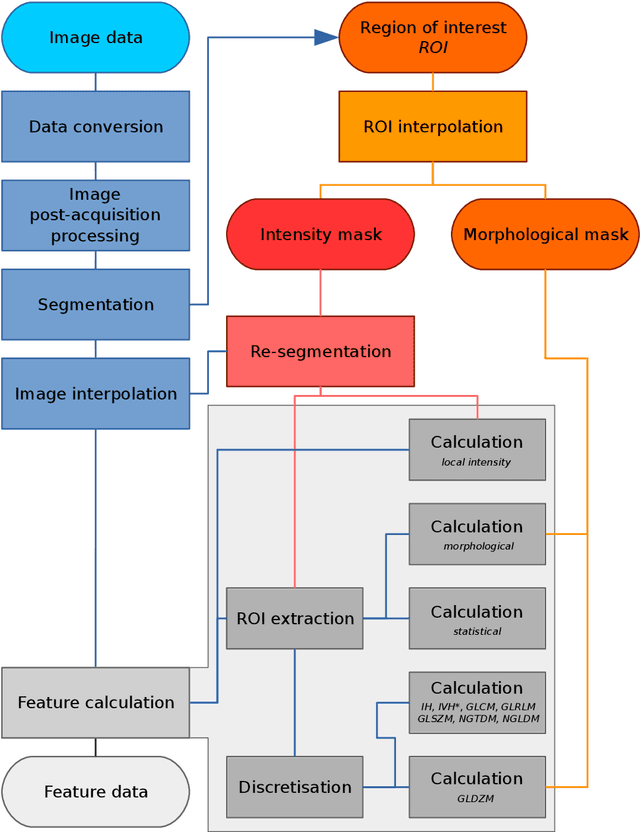

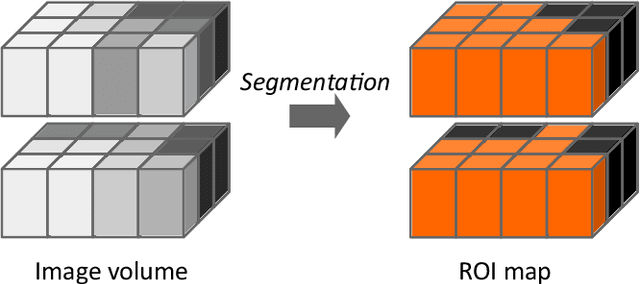
The image biomarker standardisation initiative (IBSI) is an independent international collaboration which works towards standardising the extraction of image biomarkers from acquired imaging for the purpose of high-throughput quantitative image analysis (radiomics). Lack of reproducibility and validation of high-throughput quantitative image analysis studies is considered to be a major challenge for the field. Part of this challenge lies in the scantiness of consensus-based guidelines and definitions for the process of translating acquired imaging into high-throughput image biomarkers. The IBSI therefore seeks to provide image biomarker nomenclature and definitions, benchmark data sets, and benchmark values to verify image processing and image biomarker calculations, as well as reporting guidelines, for high-throughput image analysis.
Multi-Scale High-Resolution Vision Transformer for Semantic Segmentation
Nov 23, 2021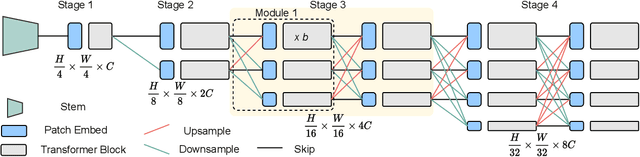

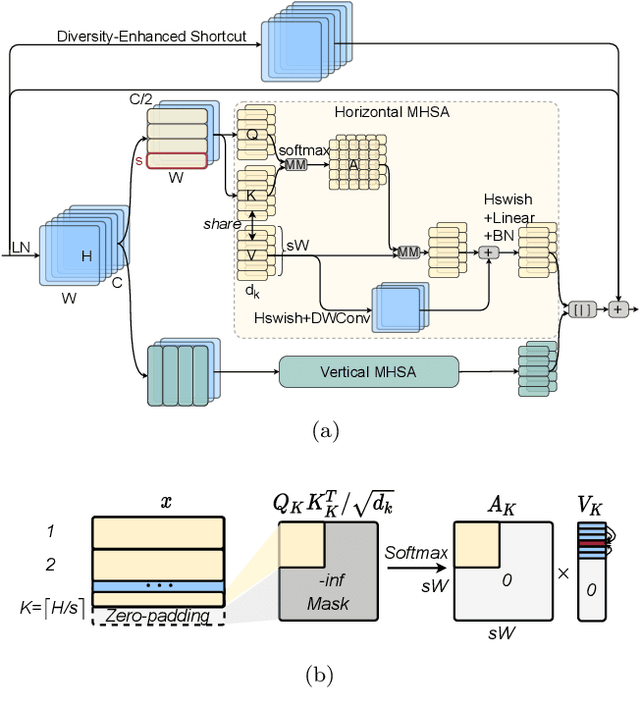
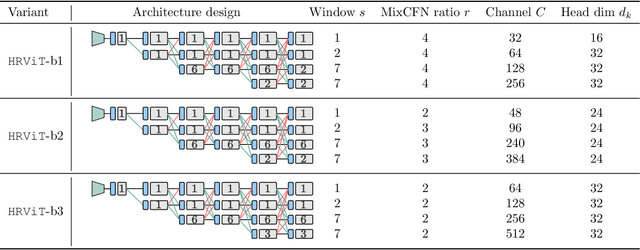
Vision Transformers (ViTs) have emerged with superior performance on computer vision tasks compared to convolutional neural network (CNN)-based models. However, ViTs are mainly designed for image classification that generate single-scale low-resolution representations, which makes dense prediction tasks such as semantic segmentation challenging for ViTs. Therefore, we propose HRViT, which enhances ViTs to learn semantically-rich and spatially-precise multi-scale representations by integrating high-resolution multi-branch architectures with ViTs. We balance the model performance and efficiency of HRViT by various branch-block co-optimization techniques. Specifically, we explore heterogeneous branch designs, reduce the redundancy in linear layers, and augment the attention block with enhanced expressiveness. Those approaches enabled HRViT to push the Pareto frontier of performance and efficiency on semantic segmentation to a new level, as our evaluation results on ADE20K and Cityscapes show. HRViT achieves 50.20% mIoU on ADE20K and 83.16% mIoU on Cityscapes, surpassing state-of-the-art MiT and CSWin backbones with an average of +1.78 mIoU improvement, 28% parameter saving, and 21% FLOPs reduction, demonstrating the potential of HRViT as a strong vision backbone for semantic segmentation.
Sem-GAN: Semantically-Consistent Image-to-Image Translation
Jul 12, 2018
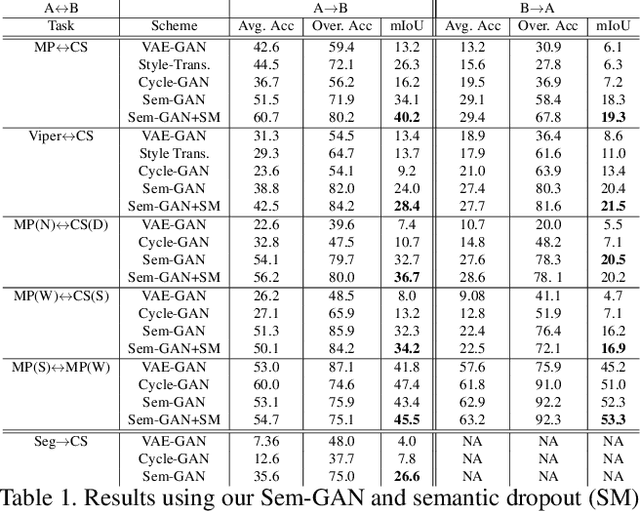
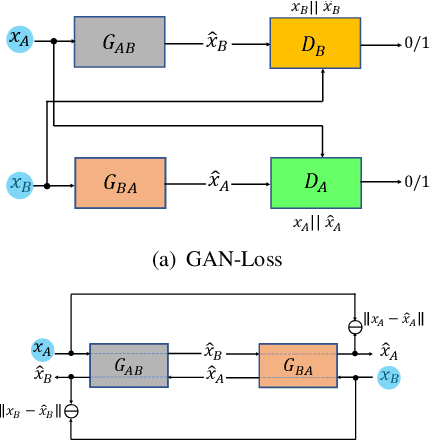
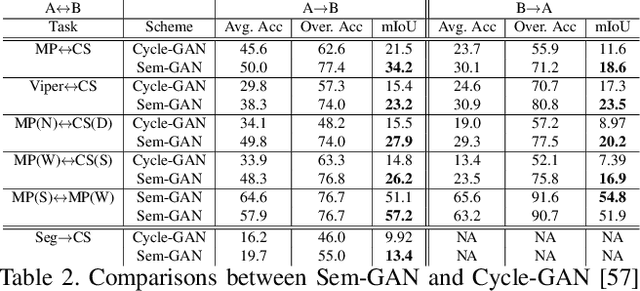
Unpaired image-to-image translation is the problem of mapping an image in the source domain to one in the target domain, without requiring corresponding image pairs. To ensure the translated images are realistically plausible, recent works, such as Cycle-GAN, demands this mapping to be invertible. While, this requirement demonstrates promising results when the domains are unimodal, its performance is unpredictable in a multi-modal scenario such as in an image segmentation task. This is because, invertibility does not necessarily enforce semantic correctness. To this end, we present a semantically-consistent GAN framework, dubbed Sem-GAN, in which the semantics are defined by the class identities of image segments in the source domain as produced by a semantic segmentation algorithm. Our proposed framework includes consistency constraints on the translation task that, together with the GAN loss and the cycle-constraints, enforces that the images when translated will inherit the appearances of the target domain, while (approximately) maintaining their identities from the source domain. We present experiments on several image-to-image translation tasks and demonstrate that Sem-GAN improves the quality of the translated images significantly, sometimes by more than 20% on the FCN score. Further, we show that semantic segmentation models, trained with synthetic images translated via Sem-GAN, leads to significantly better segmentation results than other variants.
FathomNet: An underwater image training database for ocean exploration and discovery
Jul 10, 2020

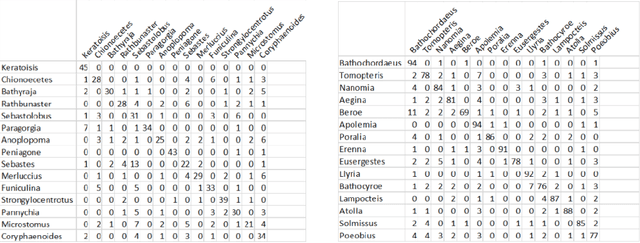

Thousands of hours of marine video data are collected annually from remotely operated vehicles (ROVs) and other underwater assets. However, current manual methods of analysis impede the full utilization of collected data for real time algorithms for ROV and large biodiversity analyses. FathomNet is a novel baseline image training set, optimized to accelerate development of modern, intelligent, and automated analysis of underwater imagery. Our seed data set consists of an expertly annotated and continuously maintained database with more than 26,000 hours of videotape, 6.8 million annotations, and 4,349 terms in the knowledge base. FathomNet leverages this data set by providing imagery, localizations, and class labels of underwater concepts in order to enable machine learning algorithm development. To date, there are more than 80,000 images and 106,000 localizations for 233 different classes, including midwater and benthic organisms. Our experiments consisted of training various deep learning algorithms with approaches to address weakly supervised localization, image labeling, object detection and classification which prove to be promising. While we find quality results on prediction for this new dataset, our results indicate that we are ultimately in need of a larger data set for ocean exploration.
Semi-Supervised Learning with Taxonomic Labels
Nov 23, 2021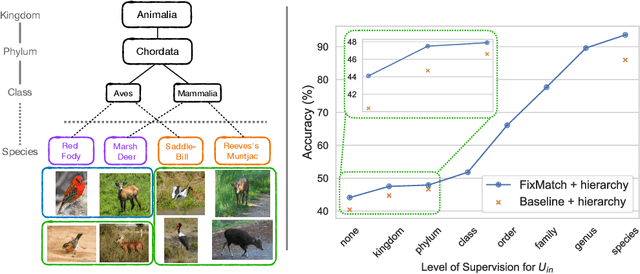
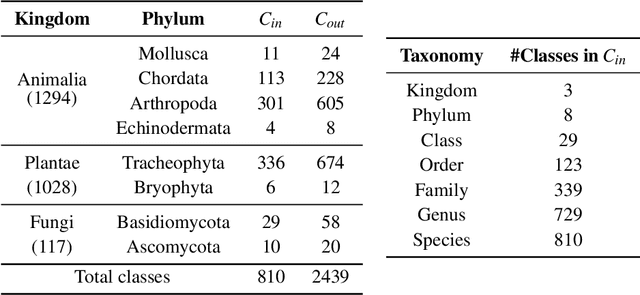
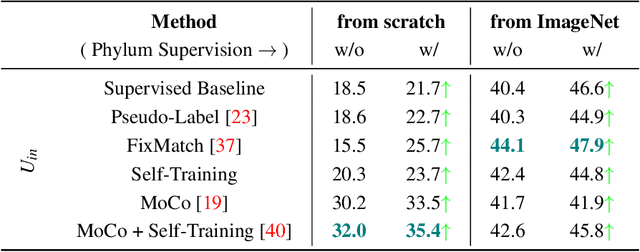
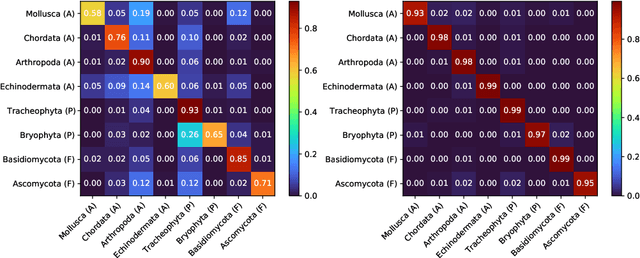
We propose techniques to incorporate coarse taxonomic labels to train image classifiers in fine-grained domains. Such labels can often be obtained with a smaller effort for fine-grained domains such as the natural world where categories are organized according to a biological taxonomy. On the Semi-iNat dataset consisting of 810 species across three Kingdoms, incorporating Phylum labels improves the Species level classification accuracy by 6% in a transfer learning setting using ImageNet pre-trained models. Incorporating the hierarchical label structure with a state-of-the-art semi-supervised learning algorithm called FixMatch improves the performance further by 1.3%. The relative gains are larger when detailed labels such as Class or Order are provided, or when models are trained from scratch. However, we find that most methods are not robust to the presence of out-of-domain data from novel classes. We propose a technique to select relevant data from a large collection of unlabeled images guided by the hierarchy which improves the robustness. Overall, our experiments show that semi-supervised learning with coarse taxonomic labels are practical for training classifiers in fine-grained domains.