 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Enhancing Prototypical Few-Shot Learning by Leveraging the Local-Level Strategy
Nov 08, 2021


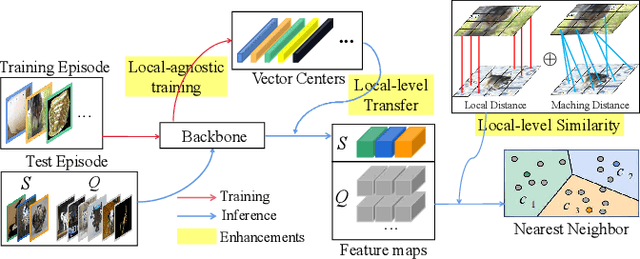
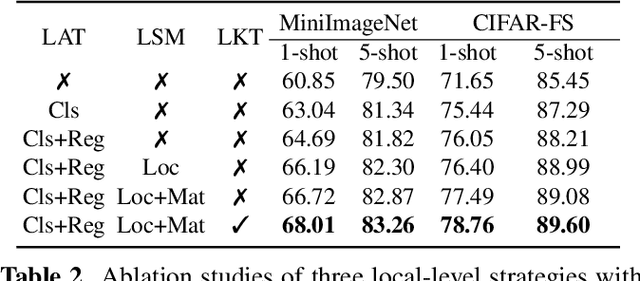
Aiming at recognizing the samples from novel categories with few reference samples, few-shot learning (FSL) is a challenging problem. We found that the existing works often build their few-shot model based on the image-level feature by mixing all local-level features, which leads to the discriminative location bias and information loss in local details. To tackle the problem, this paper returns the perspective to the local-level feature and proposes a series of local-level strategies. Specifically, we present (a) a local-agnostic training strategy to avoid the discriminative location bias between the base and novel categories, (b) a novel local-level similarity measure to capture the accurate comparison between local-level features, and (c) a local-level knowledge transfer that can synthesize different knowledge transfers from the base category according to different location features. Extensive experiments justify that our proposed local-level strategies can significantly boost the performance and achieve 2.8%-7.2% improvements over the baseline across different benchmark datasets, which also achieves state-of-the-art accuracy.
Complex Wavelet SSIM based Image Data Augmentation
Jul 11, 2020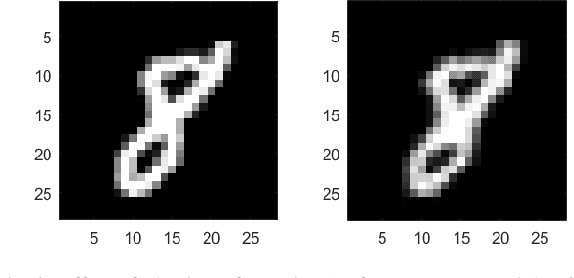
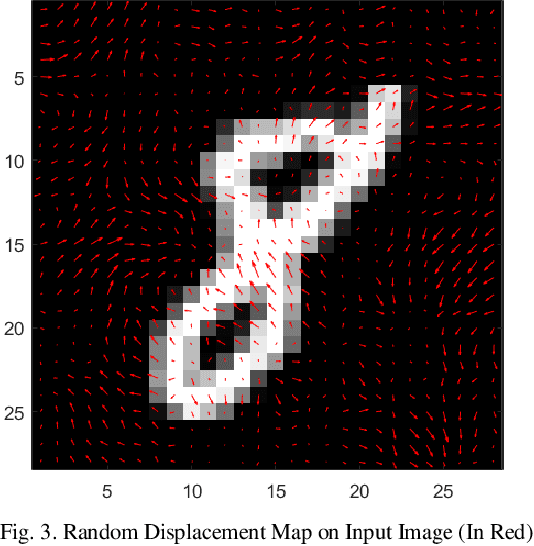

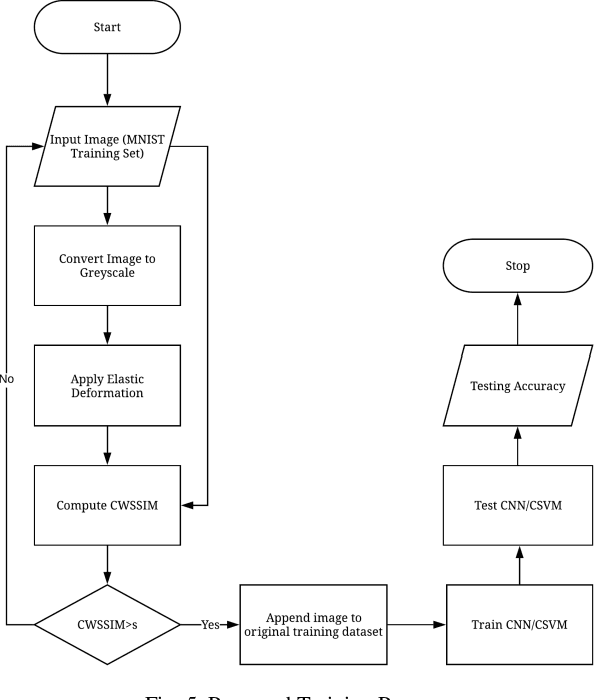
One of the biggest problems in neural learning networks is the lack of training data available to train the network. Data augmentation techniques over the past few years, have therefore been developed, aiming to increase the amount of artificial training data with the limited number of real world samples. In this paper, we look particularly at the MNIST handwritten dataset an image dataset used for digit recognition, and the methods of data augmentation done on this data set. We then take a detailed look into one of the most popular augmentation techniques used for this data set elastic deformation; and highlight its demerit of degradation in the quality of data, which introduces irrelevant data to the training set. To decrease this irrelevancy, we propose to use a similarity measure called Complex Wavelet Structural Similarity Index Measure (CWSSIM) to selectively filter out the irrelevant data before we augment the data set. We compare our observations with the existing augmentation technique and find our proposed method works yields better results than the existing technique.
Single-Item Fashion Recommender: Towards Cross-Domain Recommendations
Nov 01, 2021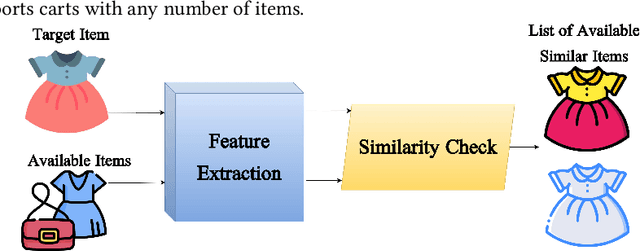
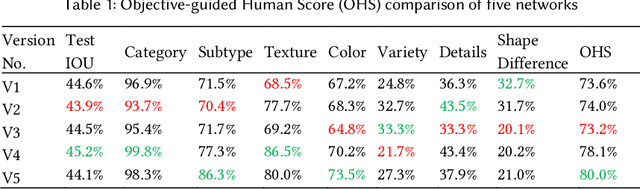
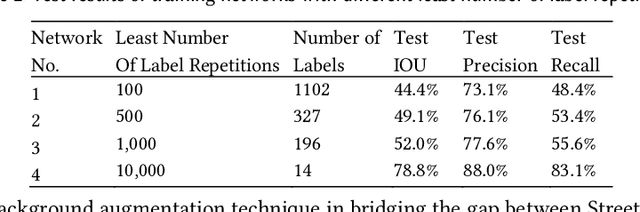
Nowadays, recommender systems and search engines play an integral role in fashion e-commerce. Still, many challenges lie ahead, and this study tries to tackle some. This article first suggests a content-based fashion recommender system that uses a parallel neural network to take a single fashion item shop image as input and make in-shop recommendations by listing similar items available in the store. Next, the same structure is enhanced to personalize the results based on user preferences. This work then introduces a background augmentation technique that makes the system more robust to out-of-domain queries, enabling it to make street-to-shop recommendations using only a training set of catalog shop images. Moreover, the last contribution of this paper is a new evaluation metric for recommendation tasks called objective-guided human score. This method is an entirely customizable framework that produces interpretable, comparable scores from subjective evaluations of human scorers.
Few-shot learning with improved local representations via bias rectify module
Nov 01, 2021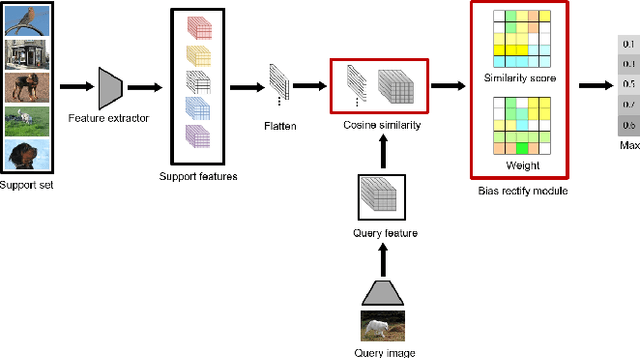
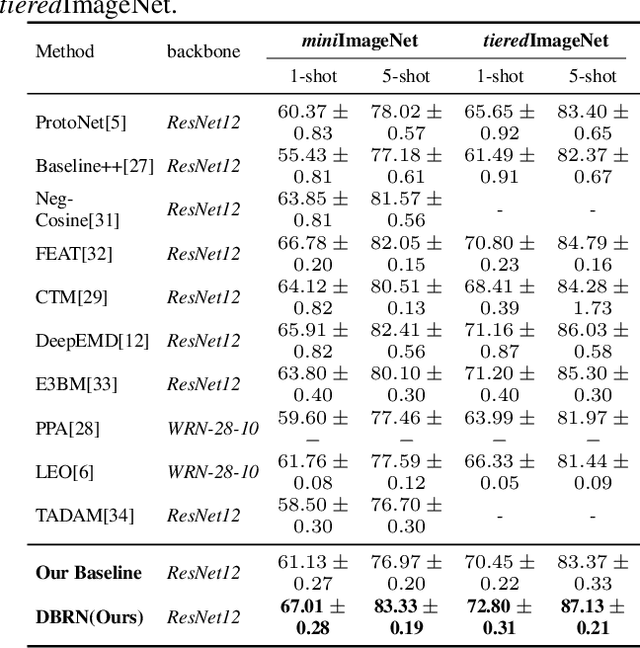

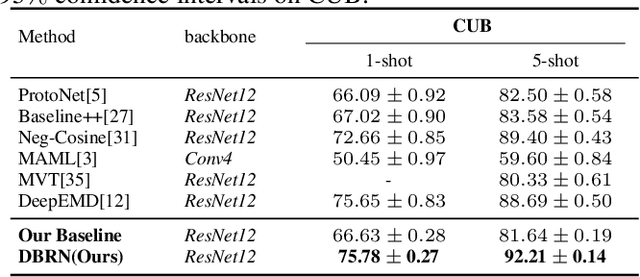
Recent approaches based on metric learning have achieved great progress in few-shot learning. However, most of them are limited to image-level representation manners, which fail to properly deal with the intra-class variations and spatial knowledge and thus produce undesirable performance. In this paper we propose a Deep Bias Rectify Network (DBRN) to fully exploit the spatial information that exists in the structure of the feature representations. We first employ a bias rectify module to alleviate the adverse impact caused by the intra-class variations. bias rectify module is able to focus on the features that are more discriminative for classification by given different weights. To make full use of the training data, we design a prototype augment mechanism that can make the prototypes generated from the support set to be more representative. To validate the effectiveness of our method, we conducted extensive experiments on various popular few-shot classification benchmarks and our methods can outperform state-of-the-art methods.
Deep-learning-driven Reliable Single-pixel Imaging with Uncertainty Approximation
Jul 24, 2021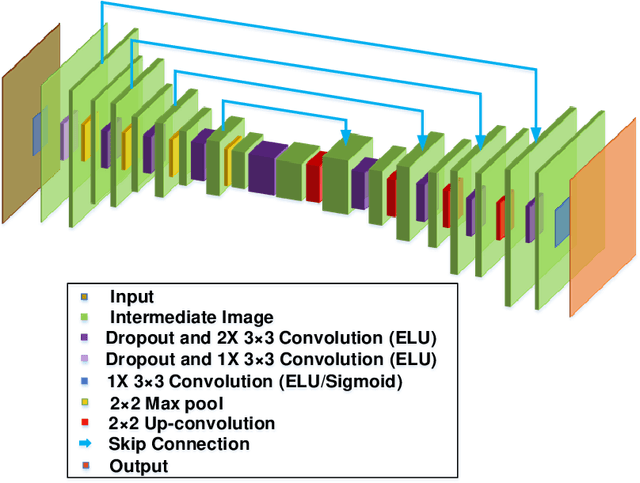
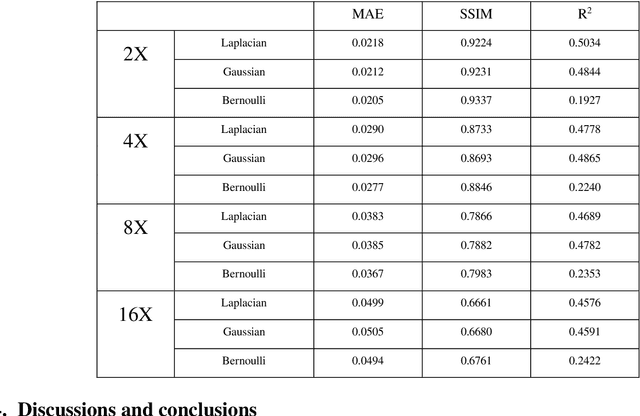
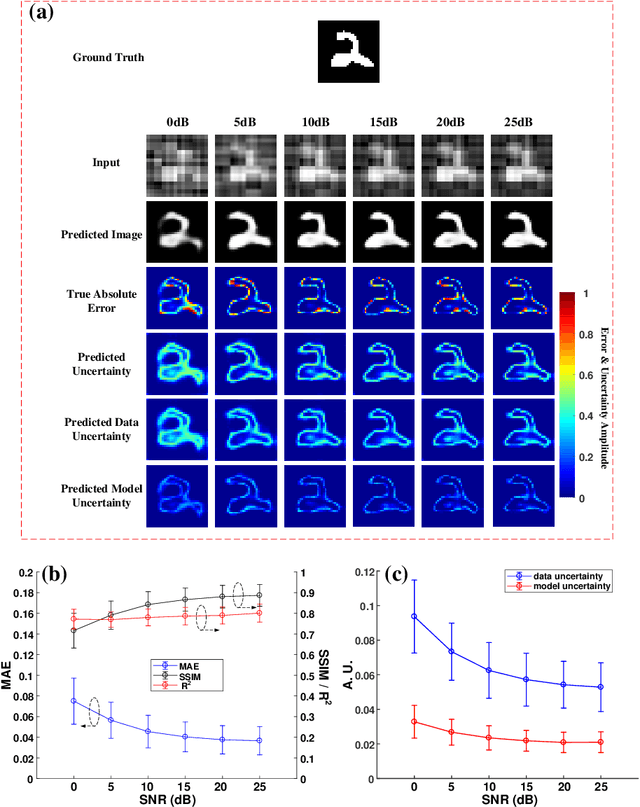
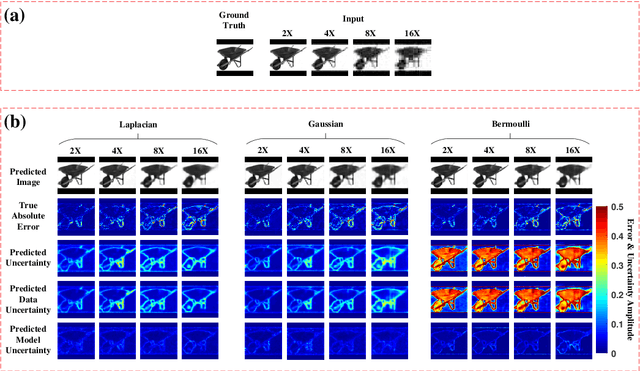
Single-pixel imaging (SPI) has the advantages of high-speed acquisition over a broad wavelength range and system compactness, which are difficult to achieve by conventional imaging sensors. However, a common challenge is low image quality arising from undersampling. Deep learning (DL) is an emerging and powerful tool in computational imaging for many applications and researchers have applied DL in SPI to achieve higher image quality than conventional reconstruction approaches. One outstanding challenge, however, is that the accuracy of DL predictions in SPI cannot be assessed in practical applications where the ground truths are unknown. Here, we propose the use of the Bayesian convolutional neural network (BCNN) to approximate the uncertainty (coming from finite training data and network model) of the DL predictions in SPI. Each pixel in the predicted result from BCNN represents the parameter of a probability distribution rather than the image intensity value. Then, the uncertainty can be approximated with BCNN by minimizing a negative log-likelihood loss function in the training stage and Monte Carlo dropout in the prediction stage. The results show that the BCNN can reliably approximate the uncertainty of the DL predictions in SPI with varying compression ratios and noise levels. The predicted uncertainty from BCNN in SPI reveals that most of the reconstruction errors in deep-learning-based SPI come from the edges of the image features. The results show that the proposed BCNN can provide a reliable tool to approximate the uncertainty of DL predictions in SPI and can be widely used in many applications of SPI.
TALISMAN: Targeted Active Learning for Object Detection with Rare Classes and Slices using Submodular Mutual Information
Nov 30, 2021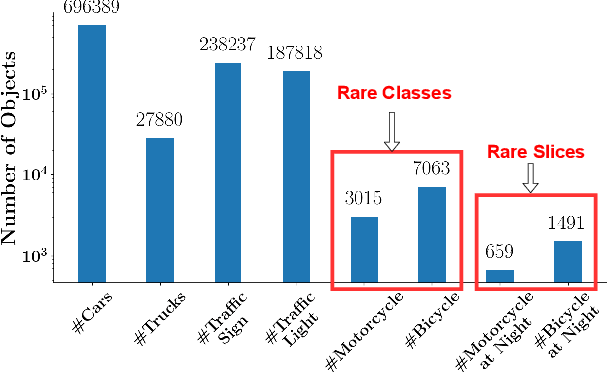
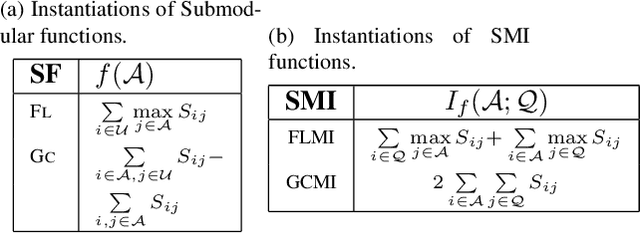
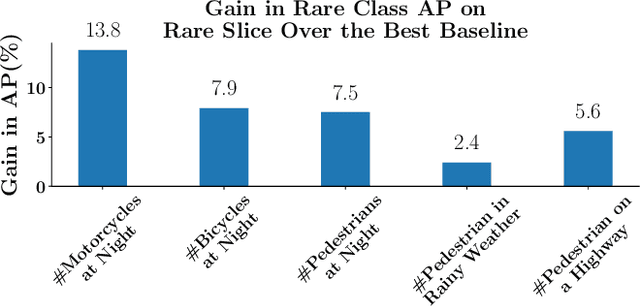
Deep neural networks based object detectors have shown great success in a variety of domains like autonomous vehicles, biomedical imaging, etc. It is known that their success depends on a large amount of data from the domain of interest. While deep models often perform well in terms of overall accuracy, they often struggle in performance on rare yet critical data slices. For example, data slices like "motorcycle at night" or "bicycle at night" are often rare but very critical slices for self-driving applications and false negatives on such rare slices could result in ill-fated failures and accidents. Active learning (AL) is a well-known paradigm to incrementally and adaptively build training datasets with a human in the loop. However, current AL based acquisition functions are not well-equipped to tackle real-world datasets with rare slices, since they are based on uncertainty scores or global descriptors of the image. We propose TALISMAN, a novel framework for Targeted Active Learning or object detectIon with rare slices using Submodular MutuAl iNformation. Our method uses the submodular mutual information functions instantiated using features of the region of interest (RoI) to efficiently target and acquire data points with rare slices. We evaluate our framework on the standard PASCAL VOC07+12 and BDD100K, a real-world self-driving dataset. We observe that TALISMAN outperforms other methods by in terms of average precision on rare slices, and in terms of mAP.
Investigating a Baseline Of Self Supervised Learning Towards Reducing Labeling Costs For Image Classification
Aug 17, 2021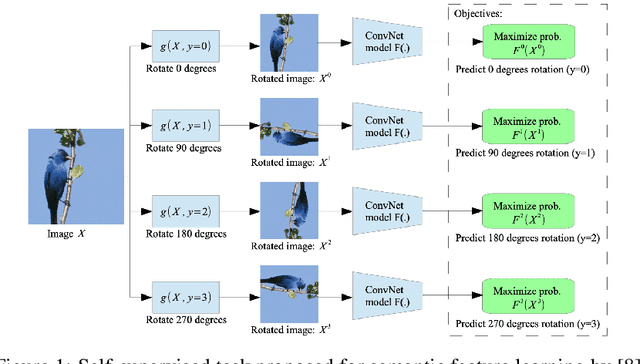
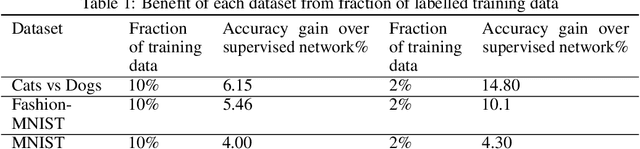
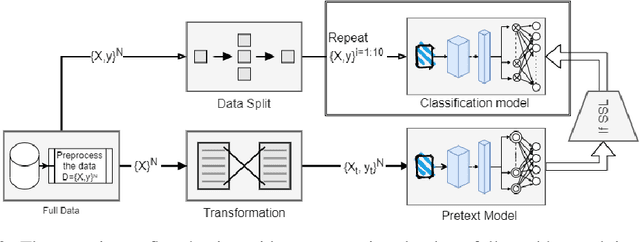
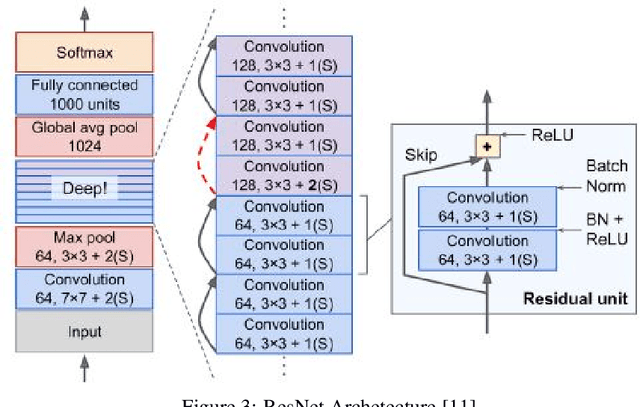
Data labeling in supervised learning is considered an expensive and infeasible tool in some conditions. The self-supervised learning method is proposed to tackle the learning effectiveness with fewer labeled data, however, there is a lack of confidence in the size of labeled data needed to achieve adequate results. This study aims to draw a baseline on the proportion of the labeled data that models can appreciate to yield competent accuracy when compared to training with additional labels. The study implements the kaggle.com' cats-vs-dogs dataset, Mnist and Fashion-Mnist to investigate the self-supervised learning task by implementing random rotations augmentation on the original datasets. To reveal the true effectiveness of the pretext process in self-supervised learning, the original dataset is divided into smaller batches, and learning is repeated on each batch with and without the pretext pre-training. Results show that the pretext process in the self-supervised learning improves the accuracy around 15% in the downstream classification task when compared to the plain supervised learning.
Beyond Flatland: Pre-training with a Strong 3D Inductive Bias
Nov 30, 2021
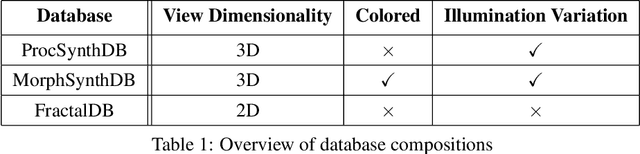

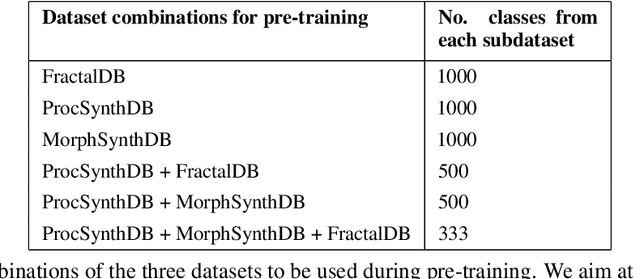
Pre-training on large-scale databases consisting of natural images and then fine-tuning them to fit the application at hand, or transfer-learning, is a popular strategy in computer vision. However, Kataoka et al., 2020 introduced a technique to eliminate the need for natural images in supervised deep learning by proposing a novel synthetic, formula-based method to generate 2D fractals as training corpus. Using one synthetically generated fractal for each class, they achieved transfer learning results comparable to models pre-trained on natural images. In this project, we take inspiration from their work and build on this idea -- using 3D procedural object renders. Since the image formation process in the natural world is based on its 3D structure, we expect pre-training with 3D mesh renders to provide an implicit bias leading to better generalization capabilities in a transfer learning setting and that invariances to 3D rotation and illumination are easier to be learned based on 3D data. Similar to the previous work, our training corpus will be fully synthetic and derived from simple procedural strategies; we will go beyond classic data augmentation and also vary illumination and pose which are controllable in our setting and study their effect on transfer learning capabilities in context to prior work. In addition, we will compare the 2D fractal and 3D procedural object networks to human and non-human primate brain data to learn more about the 2D vs. 3D nature of biological vision.
Unified Style Transfer
Oct 20, 2021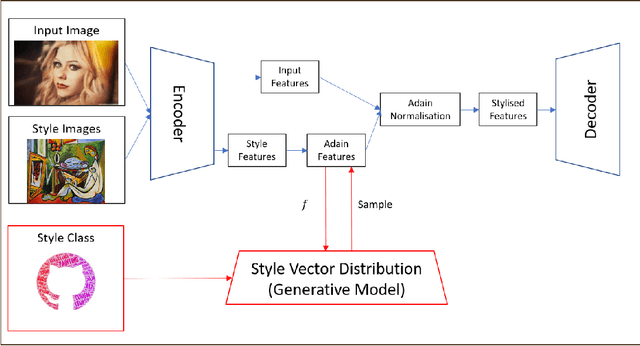
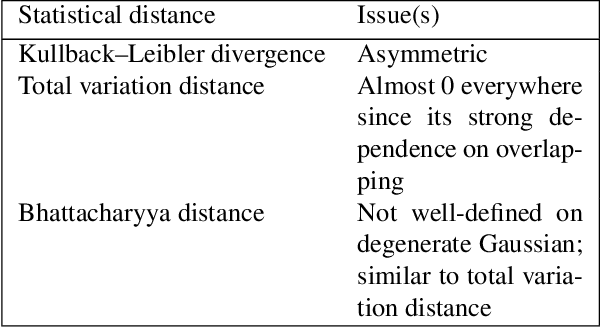
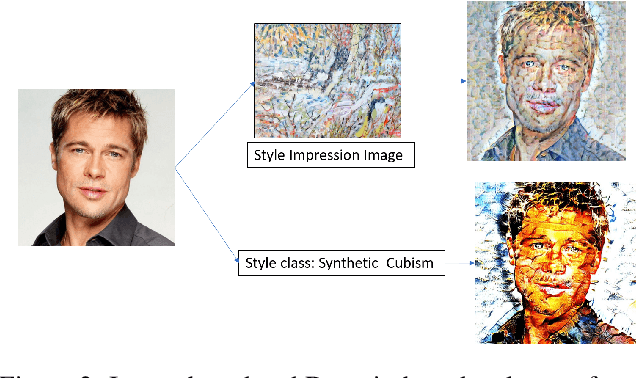

Currently, it is hard to compare and evaluate different style transfer algorithms due to chaotic definitions of style and the absence of agreed objective validation methods in the study of style transfer. In this paper, a novel approach, the Unified Style Transfer (UST) model, is proposed. With the introduction of a generative model for internal style representation, UST can transfer images in two approaches, i.e., Domain-based and Image-based, simultaneously. At the same time, a new philosophy based on the human sense of art and style distributions for evaluating the transfer model is presented and demonstrated, called Statistical Style Analysis. It provides a new path to validate style transfer models' feasibility by validating the general consistency between internal style representation and art facts. Besides, the translation-invariance of AdaIN features is also discussed.
Attribute Guided Unpaired Image-to-Image Translation with Semi-supervised Learning
Apr 29, 2019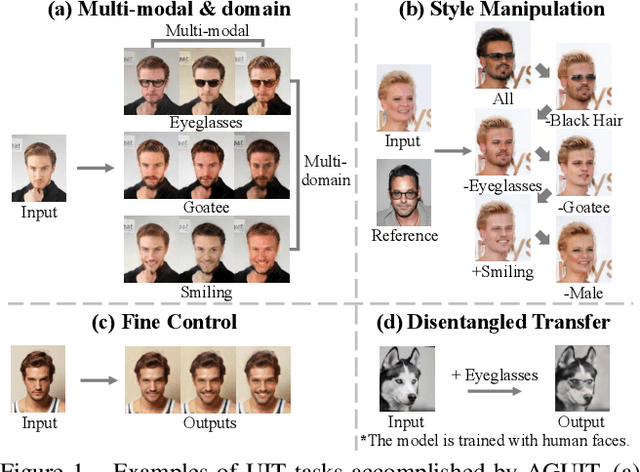

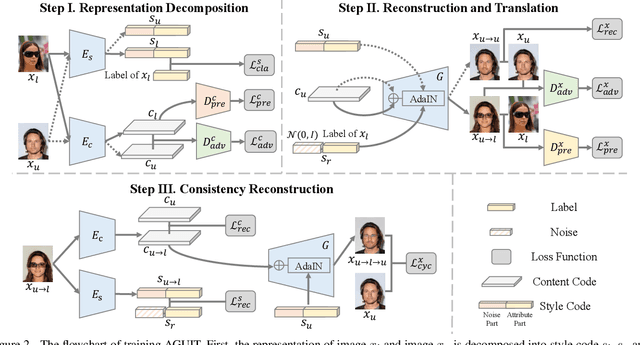
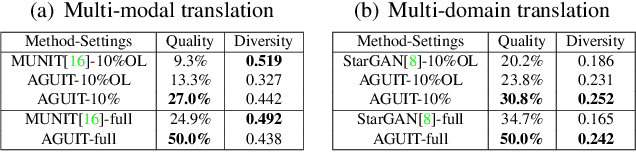
Unpaired Image-to-Image Translation (UIT) focuses on translating images among different domains by using unpaired data, which has received increasing research focus due to its practical usage. However, existing UIT schemes defect in the need of supervised training, as well as the lack of encoding domain information. In this paper, we propose an Attribute Guided UIT model termed AGUIT to tackle these two challenges. AGUIT considers multi-modal and multi-domain tasks of UIT jointly with a novel semi-supervised setting, which also merits in representation disentanglement and fine control of outputs. Especially, AGUIT benefits from two-fold: (1) It adopts a novel semi-supervised learning process by translating attributes of labeled data to unlabeled data, and then reconstructing the unlabeled data by a cycle consistency operation. (2) It decomposes image representation into domain-invariant content code and domain-specific style code. The redesigned style code embeds image style into two variables drawn from standard Gaussian distribution and the distribution of domain label, which facilitates the fine control of translation due to the continuity of both variables. Finally, we introduce a new challenge, i.e., disentangled transfer, for UIT models, which adopts the disentangled representation to translate data less related with the training set. Extensive experiments demonstrate the capacity of AGUIT over existing state-of-the-art models.