 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep learning for cardiac image segmentation: A review
Nov 09, 2019
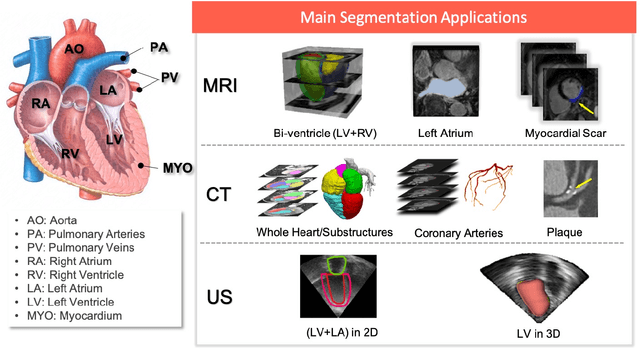
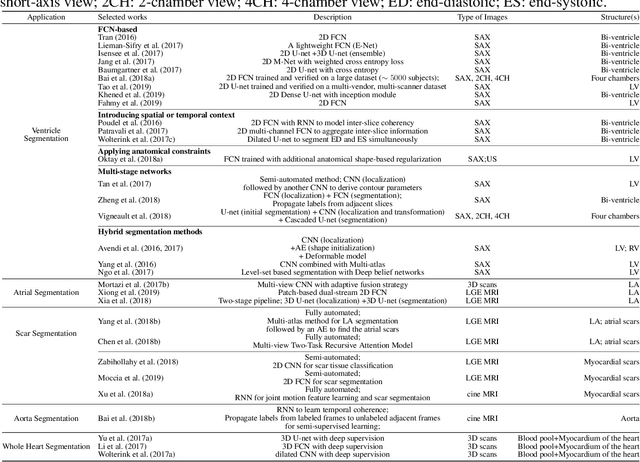
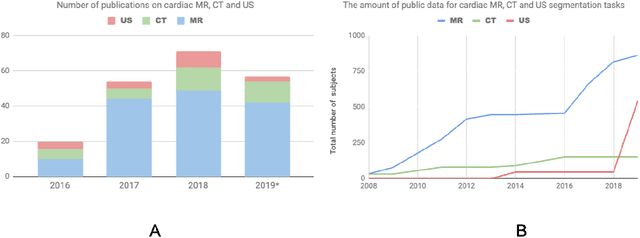

Deep learning has become the most widely used approach for cardiac image segmentation in recent years. In this paper, we provide a review of over 100 cardiac image segmentation papers using deep learning, which covers common imaging modalities including magnetic resonance imaging (MRI), computed tomography (CT), and ultrasound (US) and major anatomical structures of interest (ventricles, atria and vessels). In addition, a summary of publicly available cardiac image datasets and code repositories are included to provide a base for encouraging reproducible research. Finally, we discuss the challenges and limitations with current deep learning-based approaches (scarcity of labels, model generalizability across different domains, interpretability) and suggest potential directions for future research.
NAS-Bench-360: Benchmarking Diverse Tasks for Neural Architecture Search
Oct 16, 2021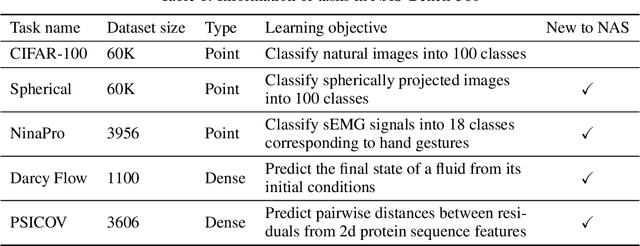
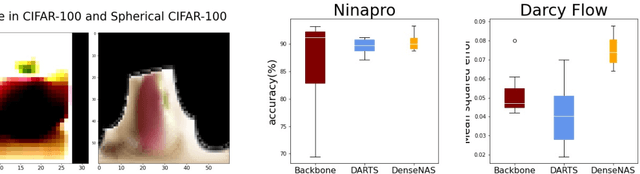
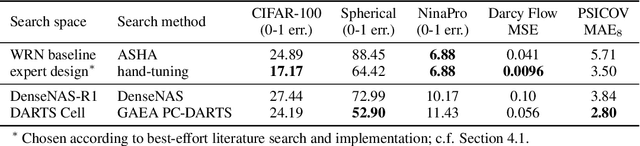
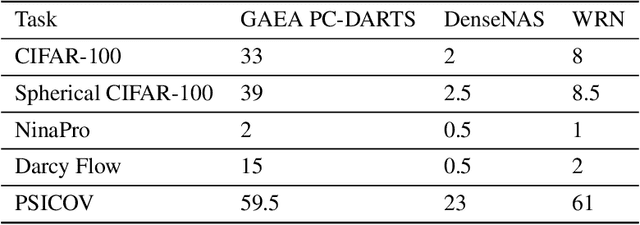
Most existing neural architecture search (NAS) benchmarks and algorithms prioritize performance on well-studied tasks, e.g., image classification on CIFAR and ImageNet. This makes the applicability of NAS approaches in more diverse areas inadequately understood. In this paper, we present NAS-Bench-360, a benchmark suite for evaluating state-of-the-art NAS methods for convolutional neural networks (CNNs). To construct it, we curate a collection of ten tasks spanning a diverse array of application domains, dataset sizes, problem dimensionalities, and learning objectives. By carefully selecting tasks that can both interoperate with modern CNN-based search methods but that are also far-afield from their original development domain, we can use NAS-Bench-360 to investigate the following central question: do existing state-of-the-art NAS methods perform well on diverse tasks? Our experiments show that a modern NAS procedure designed for image classification can indeed find good architectures for tasks with other dimensionalities and learning objectives; however, the same method struggles against more task-specific methods and performs catastrophically poorly on classification in non-vision domains. The case for NAS robustness becomes even more dire in a resource-constrained setting, where a recent NAS method provides little-to-no benefit over much simpler baselines. These results demonstrate the need for a benchmark such as NAS-Bench-360 to help develop NAS approaches that work well on a variety of tasks, a crucial component of a truly robust and automated pipeline. We conclude with a demonstration of the kind of future research our suite of tasks will enable. All data and code is made publicly available.
Reversible Adversarial Example based on Reversible Image Transformation
Dec 05, 2019

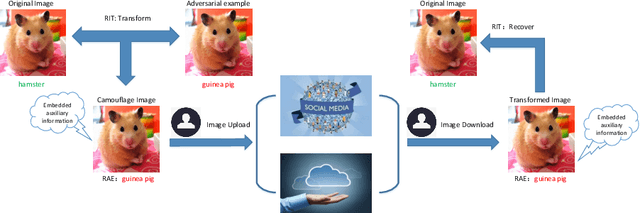

At present there are many companies that take the most advanced Deep Neural Networks (DNNs) to classify and analyze photos we upload to social networks or the cloud. In order to prevent users privacy from leakage, the attack characteristics of the adversarial example can be exploited to make these models misjudged. In this paper, we take advantage of reversible image transformation to construct reversible adversarial example, which is still an adversarial example to DNNs. It not only allows DNNs to extract the wrong information, but also can be recovered to its original image without any distortion. Experimental results show that reversible adversarial examples obtained by our method have higher attack success rates while ensuring that the reversible image quality is still high. Moreover, the proposed method is easy to operate, suitable for practical applications.
Backdoor Attack through Frequency Domain
Nov 30, 2021


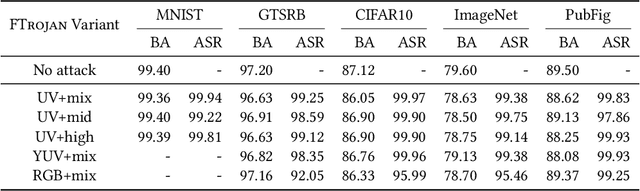
Backdoor attacks have been shown to be a serious threat against deep learning systems such as biometric authentication and autonomous driving. An effective backdoor attack could enforce the model misbehave under certain predefined conditions, i.e., triggers, but behave normally otherwise. However, the triggers of existing attacks are directly injected in the pixel space, which tend to be detectable by existing defenses and visually identifiable at both training and inference stages. In this paper, we propose a new backdoor attack FTROJAN through trojaning the frequency domain. The key intuition is that triggering perturbations in the frequency domain correspond to small pixel-wise perturbations dispersed across the entire image, breaking the underlying assumptions of existing defenses and making the poisoning images visually indistinguishable from clean ones. We evaluate FTROJAN in several datasets and tasks showing that it achieves a high attack success rate without significantly degrading the prediction accuracy on benign inputs. Moreover, the poisoning images are nearly invisible and retain high perceptual quality. We also evaluate FTROJAN against state-of-the-art defenses as well as several adaptive defenses that are designed on the frequency domain. The results show that FTROJAN can robustly elude or significantly degenerate the performance of these defenses.
Camera Condition Monitoring and Readjustment by means of Noise and Blur
Dec 10, 2021

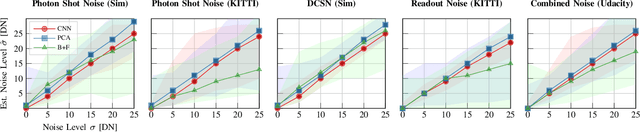
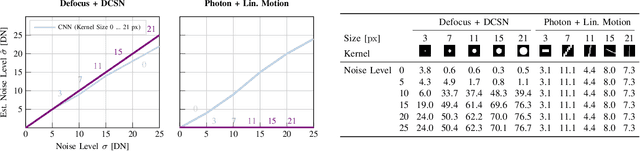
Autonomous vehicles and robots require increasingly more robustness and reliability to meet the demands of modern tasks. These requirements specially apply to cameras because they are the predominant sensors to acquire information about the environment and support actions. A camera must maintain proper functionality and take automatic countermeasures if necessary. However, there is little work that examines the practical use of a general condition monitoring approach for cameras and designs countermeasures in the context of an envisaged high-level application. We propose a generic and interpretable self-health-maintenance framework for cameras based on data- and physically-grounded models. To this end, we determine two reliable, real-time capable estimators for typical image effects of a camera in poor condition (defocus blur, motion blur, different noise phenomena and most common combinations) by comparing traditional and retrained machine learning-based approaches in extensive experiments. Furthermore, we demonstrate how one can adjust the camera parameters (e.g., exposure time and ISO gain) to achieve optimal whole-system capability based on experimental (non-linear and non-monotonic) input-output performance curves, using object detection, motion blur and sensor noise as examples. Our framework not only provides a practical ready-to-use solution to evaluate and maintain the health of cameras, but can also serve as a basis for extensions to tackle more sophisticated problems that combine additional data sources (e.g., sensor or environment parameters) empirically in order to attain fully reliable and robust machines.
Hole-robust Wireframe Detection
Nov 30, 2021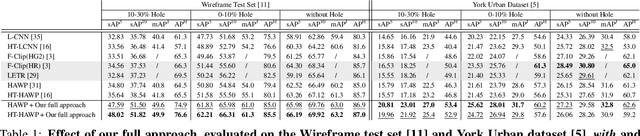
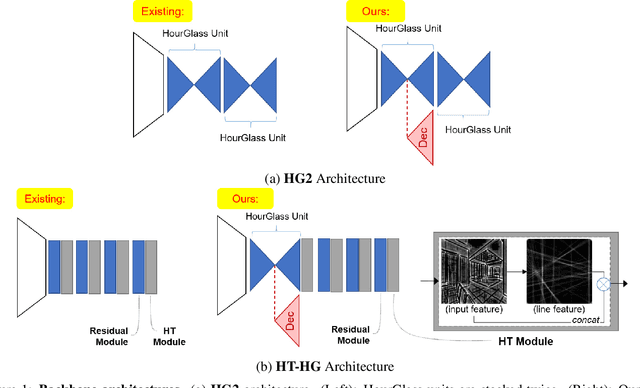
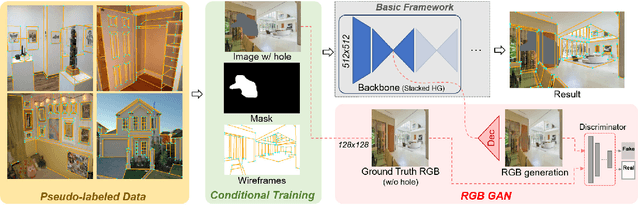
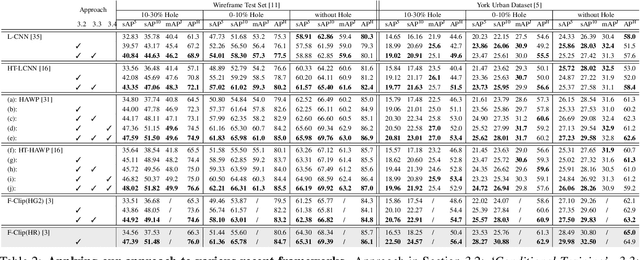
"Wireframe" is a line segment based representation designed to well capture large-scale visual properties of regular, structural shaped man-made scenes surrounding us. Unlike the wireframes, conventional edges or line segments focus on all visible edges and lines without particularly distinguishing which of them are more salient to man-made structural information. Existing wireframe detection models rely on supervising the annotated data but do not explicitly pay attention to understand how to compose the structural shapes of the scene. In addition, we often face that many foreground objects occluding the background scene interfere with proper inference of the full scene structure behind them. To resolve these problems, we first time in the field, propose new conditional data generation and training that help the model understand how to ignore occlusion indicated by holes, such as foreground object regions masked out on the image. In addition, we first time combine GAN in the model to let the model better predict underlying scene structure even beyond large holes. We also introduce pseudo labeling to further enlarge the model capacity to overcome small-scale labeled data. We show qualitatively and quantitatively that our approach significantly outperforms previous works unable to handle holes, as well as improves ordinary detection without holes given.
Learned Variable-Rate Image Compression with Residual Divisive Normalization
Dec 11, 2019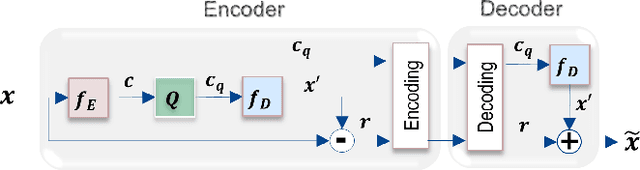
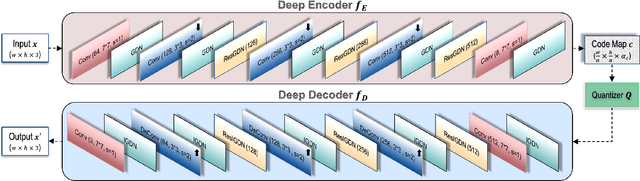
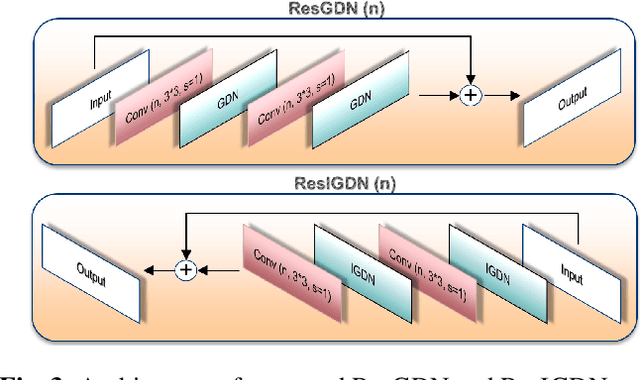
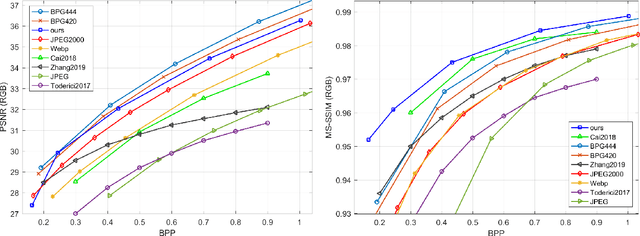
Recently it has been shown that deep learning-based image compression has shown the potential to outperform traditional codecs. However, most existing methods train multiple networks for multiple bit rates, which increases the implementation complexity. In this paper, we propose a variable-rate image compression framework, which employs more Generalized Divisive Normalization (GDN) layers than previous GDN-based methods. Novel GDN-based residual sub-networks are also developed in the encoder and decoder networks. Our scheme also uses a stochastic rounding-based scalable quantization. To further improve the performance, we encode the residual between the input and the reconstructed image from the decoder network as an enhancement layer. To enable a single model to operate with different bit rates and to learn multi-rate image features, a new objective function is introduced. Experimental results show that the proposed framework trained with variable-rate objective function outperforms all standard codecs such as H.265/HEVC-based BPG and state-of-the-art learning-based variable-rate methods.
AssistSR: Affordance-centric Question-driven Video Segment Retrieval
Nov 30, 2021
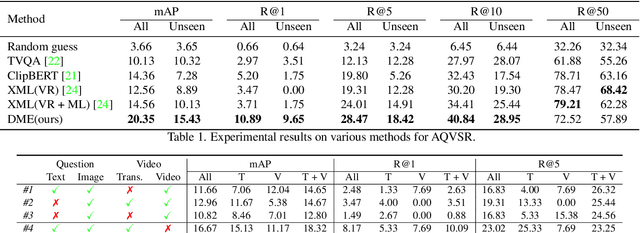
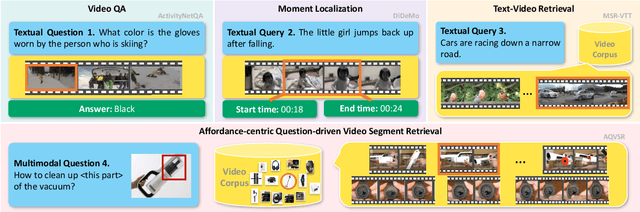
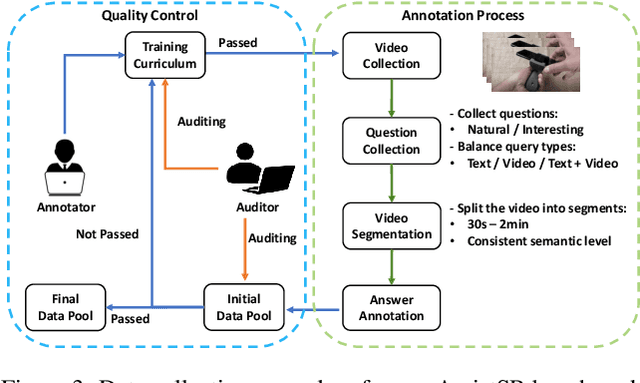
It is still a pipe dream that AI assistants on phone and AR glasses can assist our daily life in addressing our questions like "how to adjust the date for this watch?" and "how to set its heating duration? (while pointing at an oven)". The queries used in conventional tasks (i.e. Video Question Answering, Video Retrieval, Moment Localization) are often factoid and based on pure text. In contrast, we present a new task called Affordance-centric Question-driven Video Segment Retrieval (AQVSR). Each of our questions is an image-box-text query that focuses on affordance of items in our daily life and expects relevant answer segments to be retrieved from a corpus of instructional video-transcript segments. To support the study of this AQVSR task, we construct a new dataset called AssistSR. We design novel guidelines to create high-quality samples. This dataset contains 1.4k multimodal questions on 1k video segments from instructional videos on diverse daily-used items. To address AQVSR, we develop a straightforward yet effective model called Dual Multimodal Encoders (DME) that significantly outperforms several baseline methods while still having large room for improvement in the future. Moreover, we present detailed ablation analyses. Our codes and data are available at https://github.com/StanLei52/AQVSR.
Real-MFF Dataset: A Large Realistic Multi-focus Image Dataset with Ground Truth
Mar 28, 2020



Multi-focus image fusion, a technique to generate an all-in-focus image from two or more source images, can benefit many computer vision tasks. However, currently there is no large and realistic dataset to perform convincing evaluation and comparison for exiting multi-focus image fusion. For deep learning methods, it is difficult to train a network without a suitable dataset. In this paper, we introduce a large and realistic multi-focus dataset containing 800 pairs of source images with the corresponding ground truth images. The dataset is generated using a light field camera, consequently, the source images as well as the ground truth images are realistic. Moreover, the dataset contains a variety of scenes, including buildings, plants, humans, shopping malls, squares and so on, to serve as a well-founded benchmark for multi-focus image fusion tasks. For illustration, we evaluate 10 typical multi-focus algorithms on this dataset.
Counting Objects by Diffused Index: geometry-free and training-free approach
Oct 15, 2021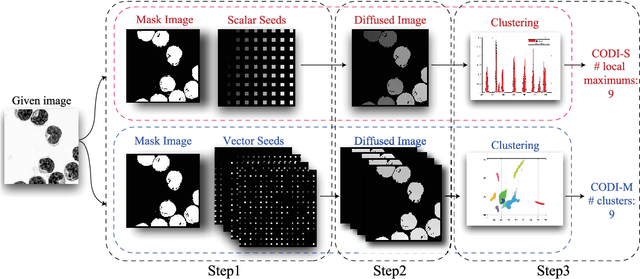



Counting objects is a fundamental but challenging problem. In this paper, we propose diffusion-based, geometry-free, and learning-free methodologies to count the number of objects in images. The main idea is to represent each object by a unique index value regardless of its intensity or size, and to simply count the number of index values. First, we place different vectors, refer to as seed vectors, uniformly throughout the mask image. The mask image has boundary information of the objects to be counted. Secondly, the seeds are diffused using an edge-weighted harmonic variational optimization model within each object. We propose an efficient algorithm based on an operator splitting approach and alternating direction minimization method, and theoretical analysis of this algorithm is given. An optimal solution of the model is obtained when the distributed seeds are completely diffused such that there is a unique intensity within each object, which we refer to as an index. For computational efficiency, we stop the diffusion process before a full convergence, and propose to cluster these diffused index values. We refer to this approach as Counting Objects by Diffused Index (CODI). We explore scalar and multi-dimensional seed vectors. For Scalar seeds, we use Gaussian fitting in histogram to count, while for vector seeds, we exploit a high-dimensional clustering method for the final step of counting via clustering. The proposed method is flexible even if the boundary of the object is not clear nor fully enclosed. We present counting results in various applications such as biological cells, agriculture, concert crowd, and transportation. Some comparisons with existing methods are presented.