 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Fast Training of Neural Lumigraph Representations using Meta Learning
Jun 28, 2021
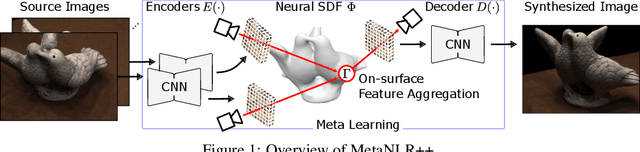


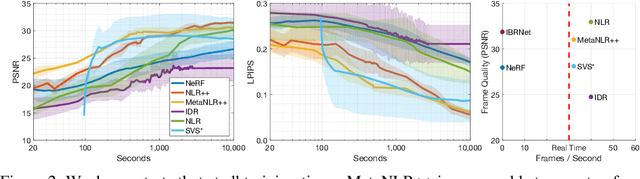
Novel view synthesis is a long-standing problem in machine learning and computer vision. Significant progress has recently been made in developing neural scene representations and rendering techniques that synthesize photorealistic images from arbitrary views. These representations, however, are extremely slow to train and often also slow to render. Inspired by neural variants of image-based rendering, we develop a new neural rendering approach with the goal of quickly learning a high-quality representation which can also be rendered in real-time. Our approach, MetaNLR++, accomplishes this by using a unique combination of a neural shape representation and 2D CNN-based image feature extraction, aggregation, and re-projection. To push representation convergence times down to minutes, we leverage meta learning to learn neural shape and image feature priors which accelerate training. The optimized shape and image features can then be extracted using traditional graphics techniques and rendered in real time. We show that MetaNLR++ achieves similar or better novel view synthesis results in a fraction of the time that competing methods require.
Early-exit deep neural networks for distorted images: providing an efficient edge offloading
Aug 25, 2021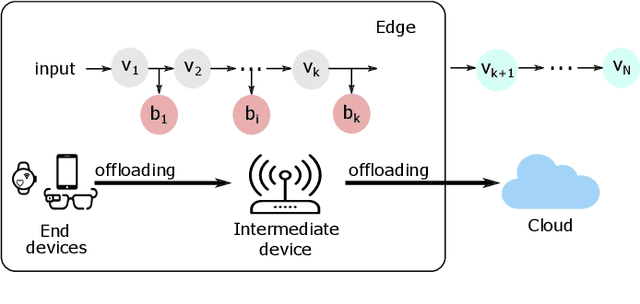
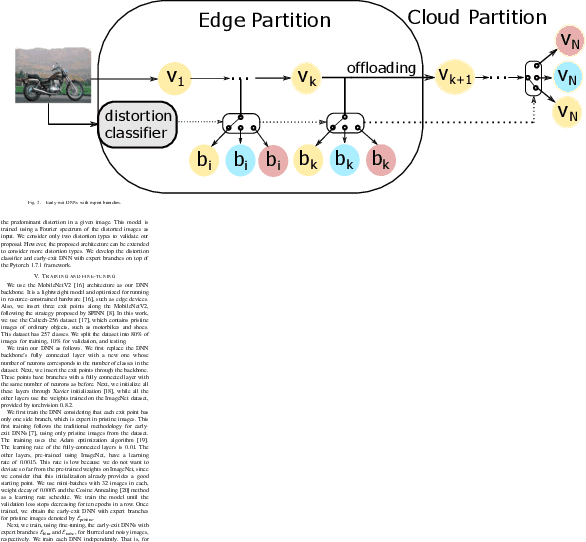
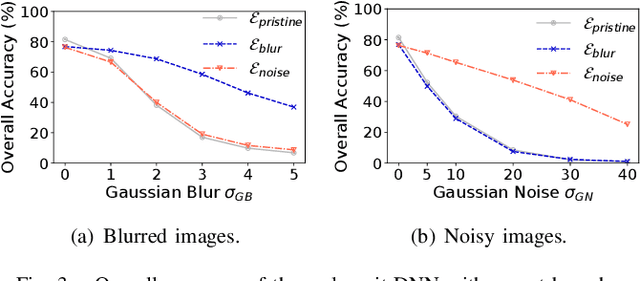
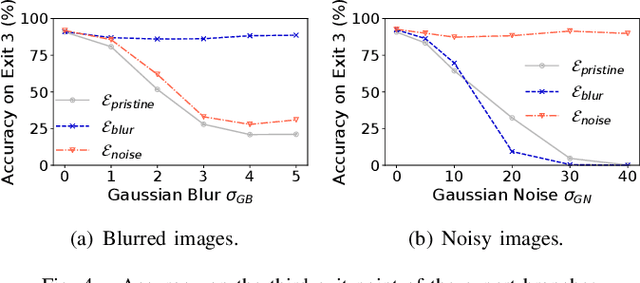
Edge offloading for deep neural networks (DNNs) can be adaptive to the input's complexity by using early-exit DNNs. These DNNs have side branches throughout their architecture, allowing the inference to end earlier in the edge. The branches estimate the accuracy for a given input. If this estimated accuracy reaches a threshold, the inference ends on the edge. Otherwise, the edge offloads the inference to the cloud to process the remaining DNN layers. However, DNNs for image classification deals with distorted images, which negatively impact the branches' estimated accuracy. Consequently, the edge offloads more inferences to the cloud. This work introduces expert side branches trained on a particular distortion type to improve robustness against image distortion. The edge detects the distortion type and selects appropriate expert branches to perform the inference. This approach increases the estimated accuracy on the edge, improving the offloading decisions. We validate our proposal in a realistic scenario, in which the edge offloads DNN inference to Amazon EC2 instances.
Neural Fields in Visual Computing and Beyond
Nov 22, 2021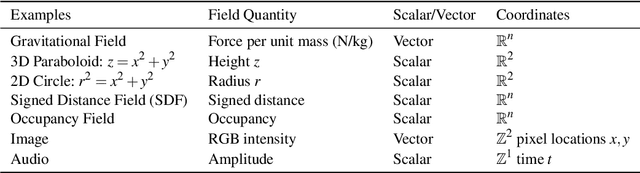
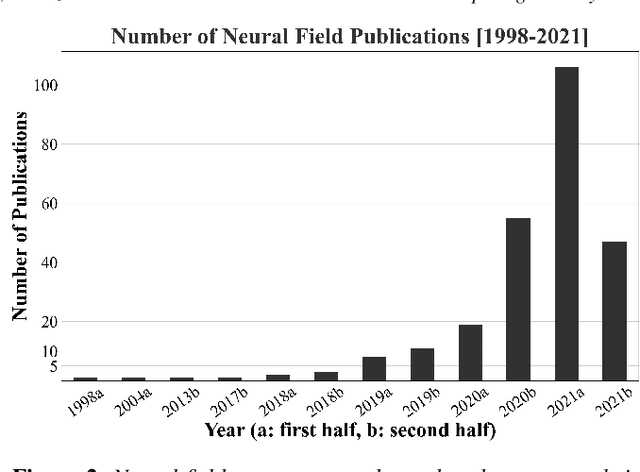

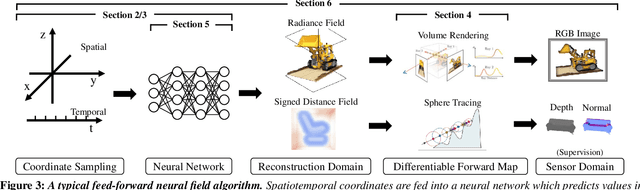
Recent advances in machine learning have created increasing interest in solving visual computing problems using a class of coordinate-based neural networks that parametrize physical properties of scenes or objects across space and time. These methods, which we call neural fields, have seen successful application in the synthesis of 3D shapes and image, animation of human bodies, 3D reconstruction, and pose estimation. However, due to rapid progress in a short time, many papers exist but a comprehensive review and formulation of the problem has not yet emerged. In this report, we address this limitation by providing context, mathematical grounding, and an extensive review of literature on neural fields. This report covers research along two dimensions. In Part I, we focus on techniques in neural fields by identifying common components of neural field methods, including different representations, architectures, forward mapping, and generalization methods. In Part II, we focus on applications of neural fields to different problems in visual computing, and beyond (e.g., robotics, audio). Our review shows the breadth of topics already covered in visual computing, both historically and in current incarnations, demonstrating the improved quality, flexibility, and capability brought by neural fields methods. Finally, we present a companion website that contributes a living version of this review that can be continually updated by the community.
Navigation-Oriented Scene Understanding for Robotic Autonomy: Learning to Segment Driveability in Egocentric Images
Sep 15, 2021


This work tackles scene understanding for outdoor robotic navigation, solely relying on images captured by an on-board camera. Conventional visual scene understanding interprets the environment based on specific descriptive categories. However, such a representation is not directly interpretable for decision-making and constrains robot operation to a specific domain. Thus, we propose to segment egocentric images directly in terms of how a robot can navigate in them, and tailor the learning problem to an autonomous navigation task. Building around an image segmentation network, we present a generic and scalable affordance-based definition consisting of 3 driveability levels which can be applied to arbitrary scenes. By encoding these levels with soft ordinal labels, we incorporate inter-class distances during learning which improves segmentation compared to standard one-hot labelling. In addition, we propose a navigation-oriented pixel-wise loss weighting method which assigns higher importance to safety-critical areas. We evaluate our approach on large-scale public image segmentation datasets spanning off-road and urban scenes. In a zero-shot cross-dataset generalization experiment, we show that our affordance learning scheme can be applied across a diverse mix of datasets and improves driveability estimation in unseen environments compared to general-purpose, single-dataset segmentation.
Spatial-Frequency Domain Nonlocal Total Variation for Image Denoising
Dec 05, 2019
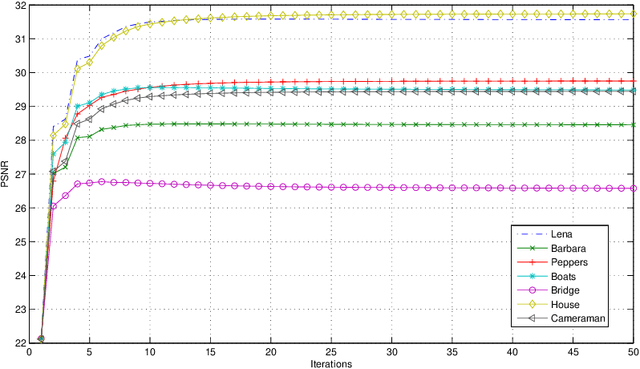
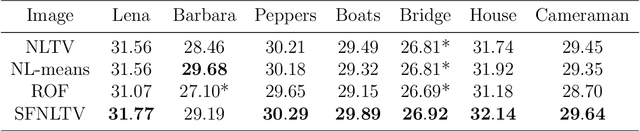
Following the pioneering works of Rudin, Osher and Fatemi on total variation (TV) and of Buades, Coll and Morel on non-local means (NL-means), the last decade has seen a large number of denoising methods mixing these two approaches, starting with the nonlocal total variation (NLTV) model. The present article proposes an analysis of the NLTV model for image denoising as well as a number of improvements, the most important of which being to apply the denoising both in the space domain and in the Fourier domain, in order to exploit the complementarity of the representation of image data in both domains. A local version obtained by a regionwise implementation followed by an aggregation process, called Local Spatial-Frequency NLTV (L- SFNLTV) model, is finally proposed as a new reference algorithm for image denoising among the family of approaches mixing TV and NL operators. The experiments show the great performance of L-SFNLTV, both in terms of image quality and of computational speed, comparing with other recently proposed NLTV-related methods.
DSP: Dual Soft-Paste for Unsupervised Domain Adaptive Semantic Segmentation
Jul 20, 2021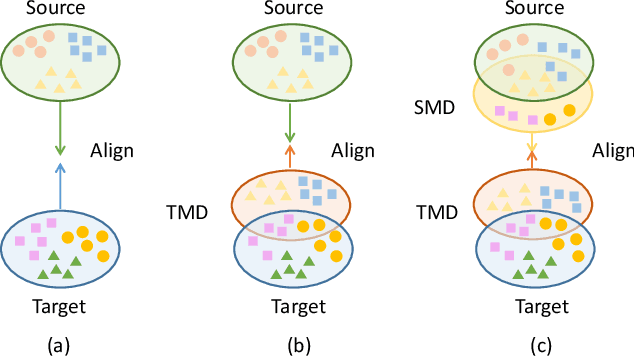
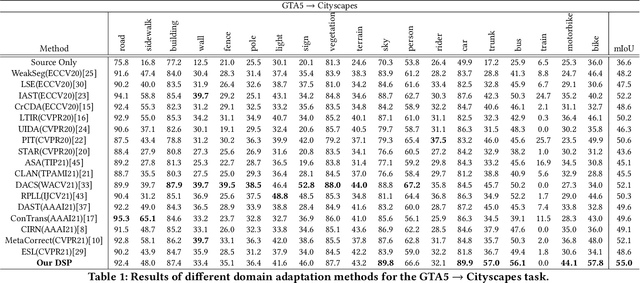
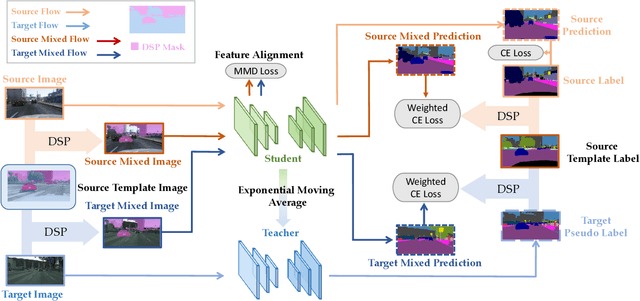
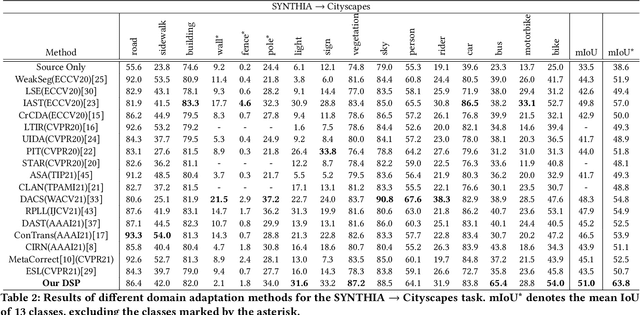
Unsupervised domain adaptation (UDA) for semantic segmentation aims to adapt a segmentation model trained on the labeled source domain to the unlabeled target domain. Existing methods try to learn domain invariant features while suffering from large domain gaps that make it difficult to correctly align discrepant features, especially in the initial training phase. To address this issue, we propose a novel Dual Soft-Paste (DSP) method in this paper. Specifically, DSP selects some classes from a source domain image using a long-tail class first sampling strategy and softly pastes the corresponding image patch on both the source and target training images with a fusion weight. Technically, we adopt the mean teacher framework for domain adaptation, where the pasted source and target images go through the student network while the original target image goes through the teacher network. Output-level alignment is carried out by aligning the probability maps of the target fused image from both networks using a weighted cross-entropy loss. In addition, feature-level alignment is carried out by aligning the feature maps of the source and target images from student network using a weighted maximum mean discrepancy loss. DSP facilitates the model learning domain-invariant features from the intermediate domains, leading to faster convergence and better performance. Experiments on two challenging benchmarks demonstrate the superiority of DSP over state-of-the-art methods. Code is available at \url{https://github.com/GaoLii/DSP}.
Diff-Net: Image Feature Difference based High-Definition Map Change Detection
Jul 14, 2021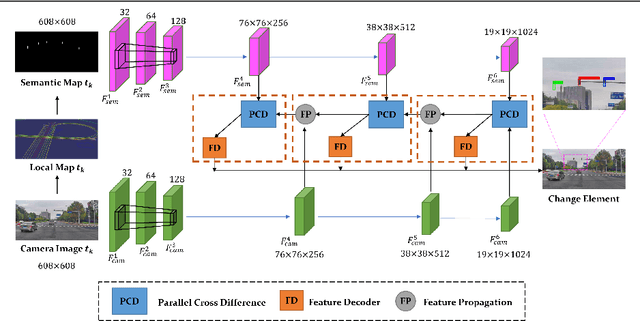

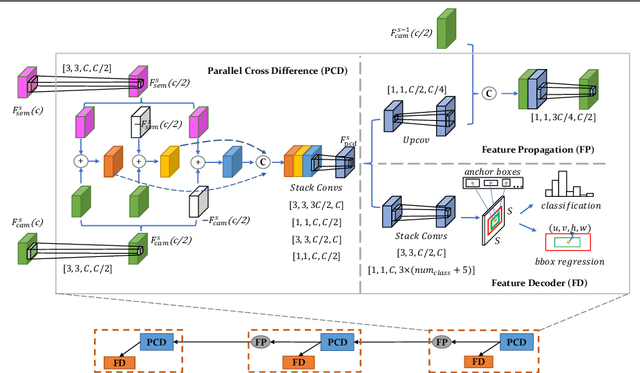

Up-to-date High-Definition (HD) maps are essential for self-driving cars. To achieve constantly updated HD maps, we present a deep neural network (DNN), Diff-Net, to detect changes in them. Compared to traditional methods based on object detectors, the essential design in our work is a parallel feature difference calculation structure that infers map changes by comparing features extracted from the camera and rasterized images. To generate these rasterized images, we project map elements onto images in the camera view, yielding meaningful map representations that can be consumed by a DNN accordingly. As we formulate the change detection task as an object detection problem, we leverage the anchor-based structure that predicts bounding boxes with different change status categories. Furthermore, rather than relying on single frame input, we introduce a spatio-temporal fusion module that fuses features from history frames into the current, thus improving the overall performance. Finally, we comprehensively validate our method's effectiveness using freshly collected datasets. Results demonstrate that our Diff-Net achieves better performance than the baseline methods and is ready to be integrated into a map production pipeline maintaining an up-to-date HD map.
Leveraging Frequency Analysis for Deep Fake Image Recognition
Mar 19, 2020
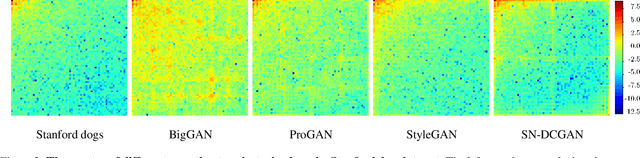
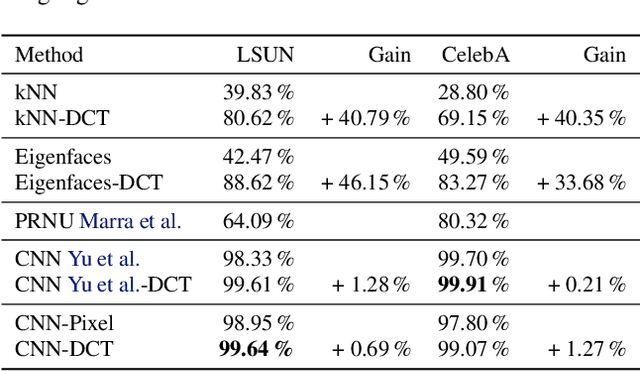
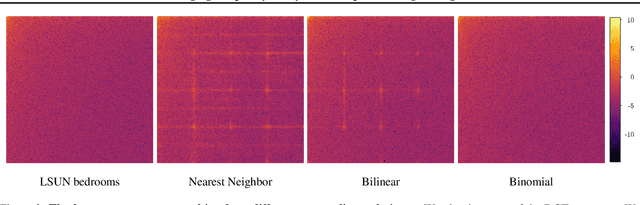
Deep neural networks can generate images that are astonishingly realistic, so much so that it is often hard for humans to distinguish them from actual photos. These achievements have been largely made possible by Generative Adversarial Networks (GANs). While these deep fake images have been thoroughly investigated in the image domain-a classical approach from the area of image forensics-an analysis in the frequency domain has been missing so far. In this paper, we address this shortcoming and our results reveal that in frequency space, GAN-generated images exhibit severe artifacts that can be easily identified. We perform a comprehensive analysis, showing that these artifacts are consistent across different neural network architectures, data sets, and resolutions. In a further investigation, we demonstrate that these artifacts are caused by upsampling operations found in all current GAN architectures, indicating a structural and fundamental problem in the way images are generated via GANs. Based on this analysis, we demonstrate how the frequency representation can be used to identify deep fake images in an automated way, surpassing state-of-the-art methods.
Online Range Image-based Pole Extractor for Long-term LiDAR Localization in Urban Environments
Aug 19, 2021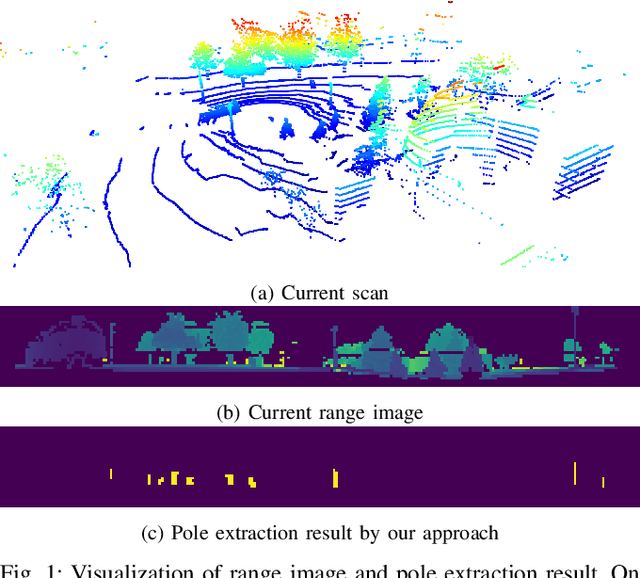
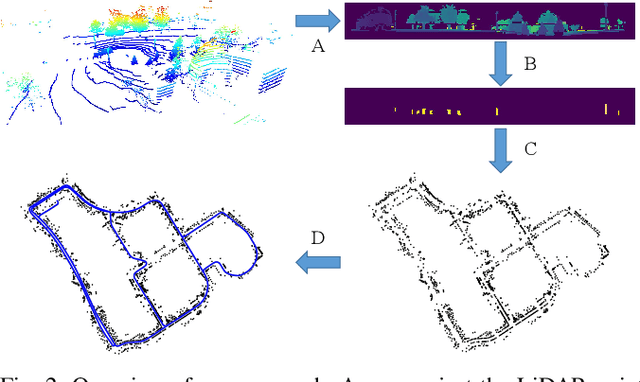
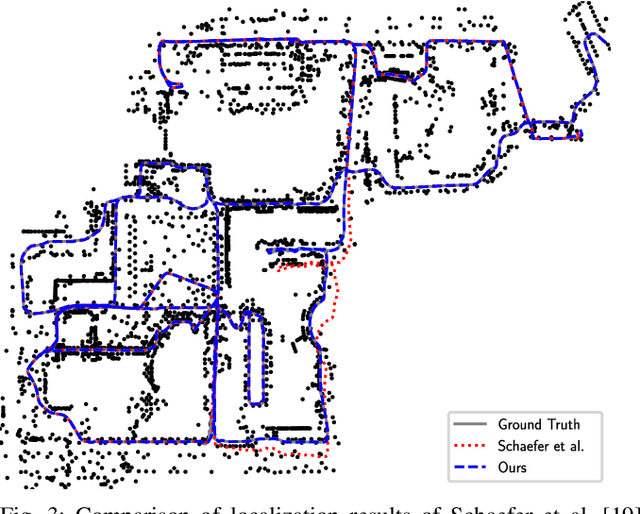
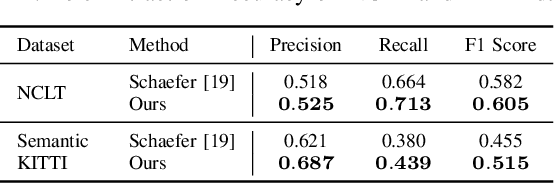
Reliable and accurate localization is crucial for mobile autonomous systems. Pole-like objects, such as traffic signs, poles, lamps, etc., are ideal landmarks for localization in urban environments due to their local distinctiveness and long-term stability. In this paper, we present a novel, accurate, and fast pole extraction approach that runs online and has little computational demands such that this information can be used for a localization system. Our method performs all computations directly on range images generated from 3D LiDAR scans, which avoids processing 3D point cloud explicitly and enables fast pole extraction for each scan. We test the proposed pole extraction and localization approach on different datasets with different LiDAR scanners, weather conditions, routes, and seasonal changes. The experimental results show that our approach outperforms other state-of-the-art approaches, while running online without a GPU. Besides, we release our pole dataset to the public for evaluating the performance of pole extractor, as well as the implementation of our approach.
Randomness Evaluation of a Genetic Algorithm for Image Encryption: A Signal Processing Approach
Aug 09, 2020In this paper a randomness evaluation of a block cipher for secure image communication is presented. The GFHT cipher is a genetic algorithm, that combines gene fusion (GF) and horizontal gene transfer (HGT) both inspired from antibiotic resistance in bacteria. The symmetric encryption key is generated by four pairs of chromosomes with multi-layer random sequences. The encryption starts by a GF of the principal key-agent in a single block, then HGT performs obfuscation where the genes are pixels and the chromosomes are the rows and columns. A Salt extracted from the image hash-value is used to implement one-time pad (OTP) scheme, hence a modification of one pixel generates a different encryption key without changing the main passphrase or key. Therefore, an extreme avalanche effect of 99% is achieved. Randomness evaluation based on random matrix theory, power spectral density, avalanche effect, 2D auto-correlation, pixels randomness tests and chi-square hypotheses testing show that encrypted images adopt the statistical behavior of uniform white noise; hence validating the theoretical model by experimental results. Moreover, performance comparison with chaos-genetic ciphers shows the merit of the GFHT algorithm.