 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Universal Lesion Detection in CT Scans using NeuralNetwork Ensembles
Nov 09, 2021
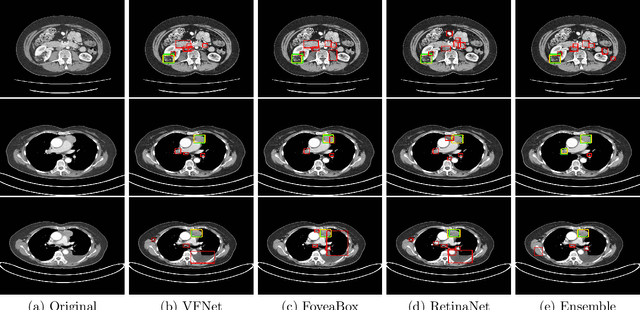
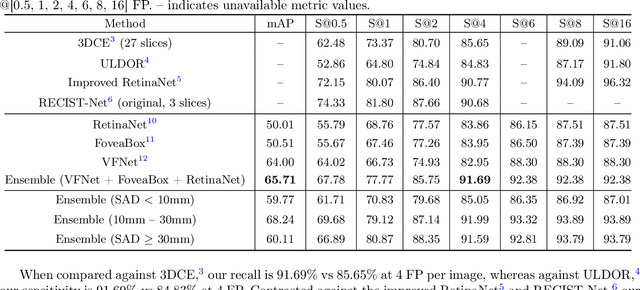
In clinical practice, radiologists are reliant on the lesion size when distinguishing metastatic from non-metastaticlesions. A prerequisite for lesion sizing is their detection, as it promotes the downstream assessment of tumorspread. However, lesions vary in their size and appearance in CT scans, and radiologists often miss small lesionsduring a busy clinical day. To overcome these challenges, we propose the use of state-of-the-art detection neuralnetworks to flag suspicious lesions present in the NIH DeepLesion dataset for sizing. Additionally, we incorporatea bounding box fusion technique to minimize false positives (FP) and improve detection accuracy. Finally, toresemble clinical usage, we constructed an ensemble of the best detection models to localize lesions for sizingwith a precision of 65.17% and sensitivity of 91.67% at 4 FP per image. Our results improve upon or maintainthe performance of current state-of-the-art methods for lesion detection in challenging CT scans.
Towards robustness under occlusion for face recognition
Sep 19, 2021


In this paper, we evaluate the effects of occlusions in the performance of a face recognition pipeline that uses a ResNet backbone. The classifier was trained on a subset of the CelebA-HQ dataset containing 5,478 images from 307 classes, to achieve top-1 error rate of 17.91%. We designed 8 different occlusion masks which were applied to the input images. This caused a significant drop in the classifier performance: its error rate for each mask became at least two times worse than before. In order to increase robustness under occlusions, we followed two approaches. The first is image inpainting using the pre-trained pluralistic image completion network. The second is Cutmix, a regularization strategy consisting of mixing training images and their labels using rectangular patches, making the classifier more robust against input corruptions. Both strategies revealed effective and interesting results were observed. In particular, the Cutmix approach makes the network more robust without requiring additional steps at the application time, though its training time is considerably longer. Our datasets containing the different occlusion masks as well as their inpainted counterparts are made publicly available to promote research on the field.
Evaluation Metrics for Conditional Image Generation
Apr 26, 2020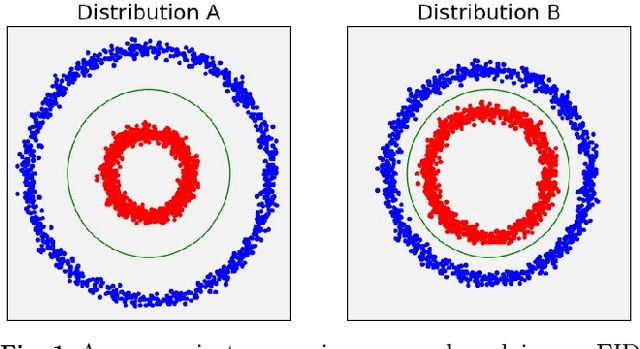
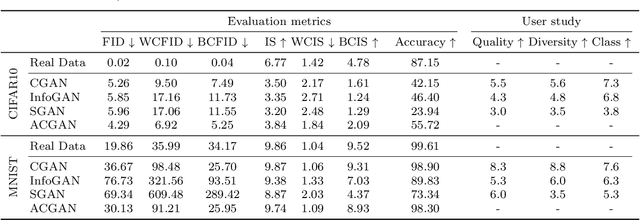
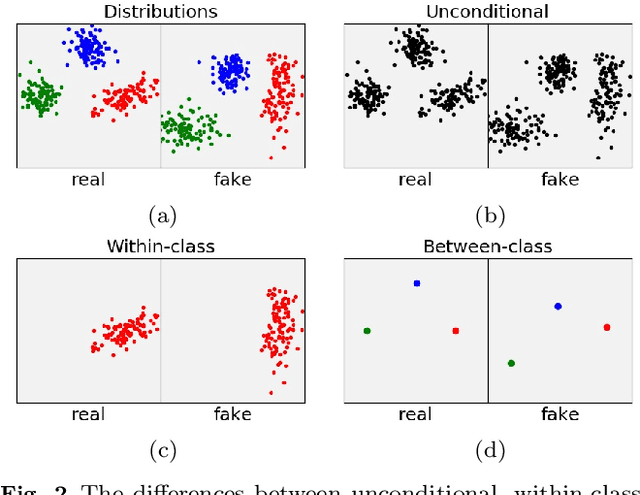
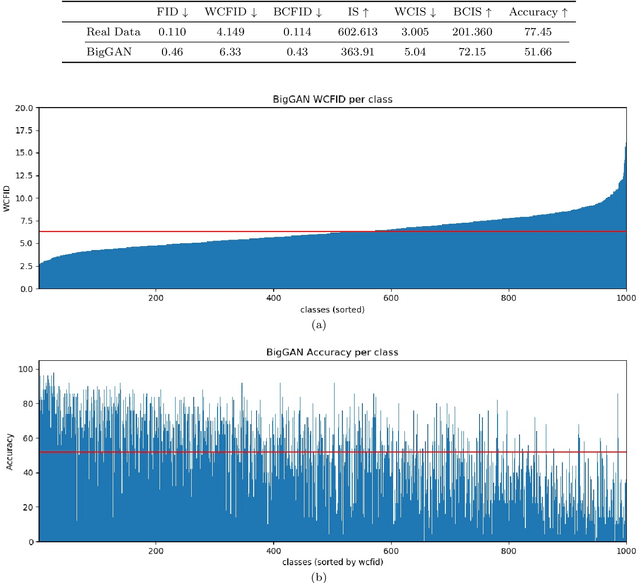
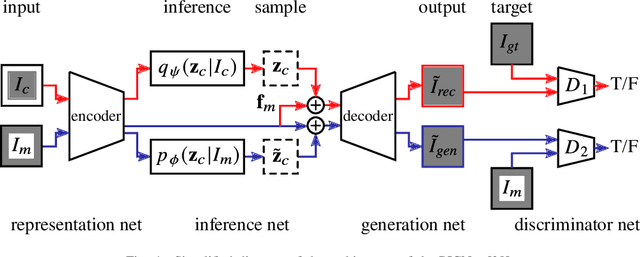
We present two new metrics for evaluating generative models in the class-conditional image generation setting. These metrics are obtained by generalizing the two most popular unconditional metrics: the Inception Score (IS) and the Fr\'{e}chet Inception Distance (FID). A theoretical analysis shows the motivation behind each proposed metric and links the novel metrics to their unconditional counterparts. The link takes the form of a product in the case of IS or an upper bound in the FID case. We provide an extensive empirical evaluation, comparing the metrics to their unconditional variants and to other metrics, and utilize them to analyze existing generative models, thus providing additional insights about their performance, from unlearned classes to mode collapse.
Comparing concepts of quantum and classical neural network models for image classification task
Aug 19, 2021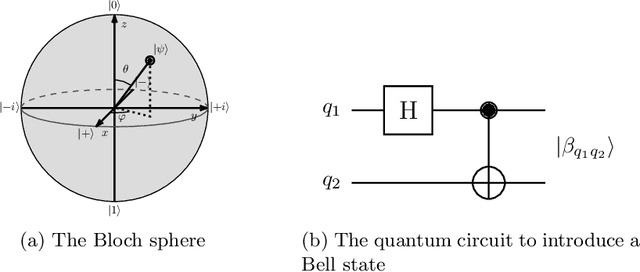

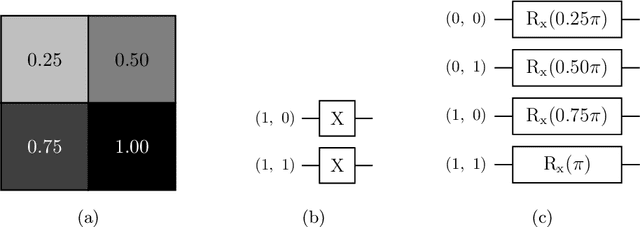
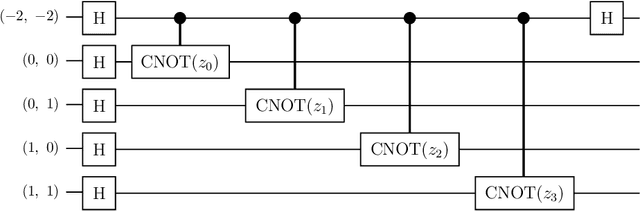
While quantum architectures are still under development, when available, they will only be able to process quantum data when machine learning algorithms can only process numerical data. Therefore, in the issues of classification or regression, it is necessary to simulate and study quantum systems that will transfer the numerical input data to a quantum form and enable quantum computers to use the available methods of machine learning. This material includes the results of experiments on training and performance of a hybrid quantum-classical neural network developed for the problem of classification of handwritten digits from the MNIST data set. The comparative results of two models: classical and quantum neural networks of a similar number of training parameters, indicate that the quantum network, although its simulation is time-consuming, overcomes the classical network (it has better convergence and achieves higher training and testing accuracy).
* 11 pages, 6 figures. The final publication is available via https://doi.org/10.1007/978-3-030-81523-3_6
VAE/WGAN-Based Image Representation Learning For Pose-Preserving Seamless Identity Replacement In Facial Images
Mar 02, 2020We present a novel variational generative adversarial network (VGAN) based on Wasserstein loss to learn a latent representation from a face image that is invariant to identity but preserves head-pose information. This facilitates synthesis of a realistic face image with the same head pose as a given input image, but with a different identity. One application of this network is in privacy-sensitive scenarios; after identity replacement in an image, utility, such as head pose, can still be recovered. Extensive experimental validation on synthetic and real human-face image datasets performed under 3 threat scenarios confirms the ability of the proposed network to preserve head pose of the input image, mask the input identity, and synthesize a good-quality realistic face image of a desired identity. We also show that our network can be used to perform pose-preserving identity morphing and identity-preserving pose morphing. The proposed method improves over a recent state-of-the-art method in terms of quantitative metrics as well as synthesized image quality.
* 6 pages, 5 figures, 2019 IEEE 29th International Workshop on Machine Learning for Signal Processing (MLSP)
COVID-19 CT Image Synthesis with a Conditional Generative Adversarial Network
Jul 29, 2020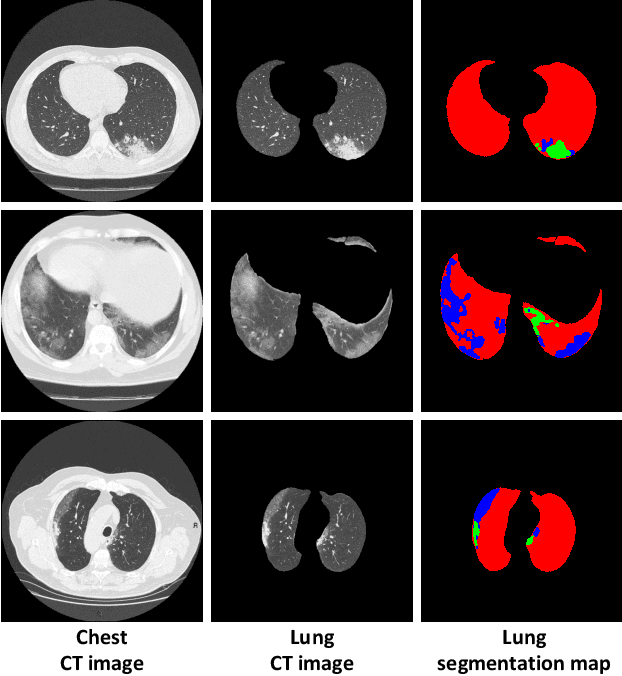
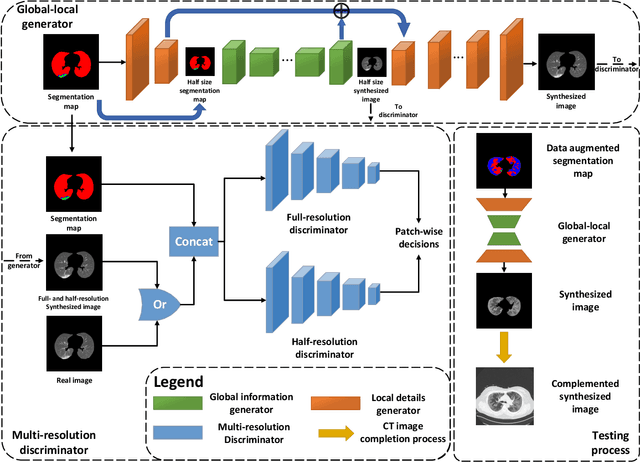
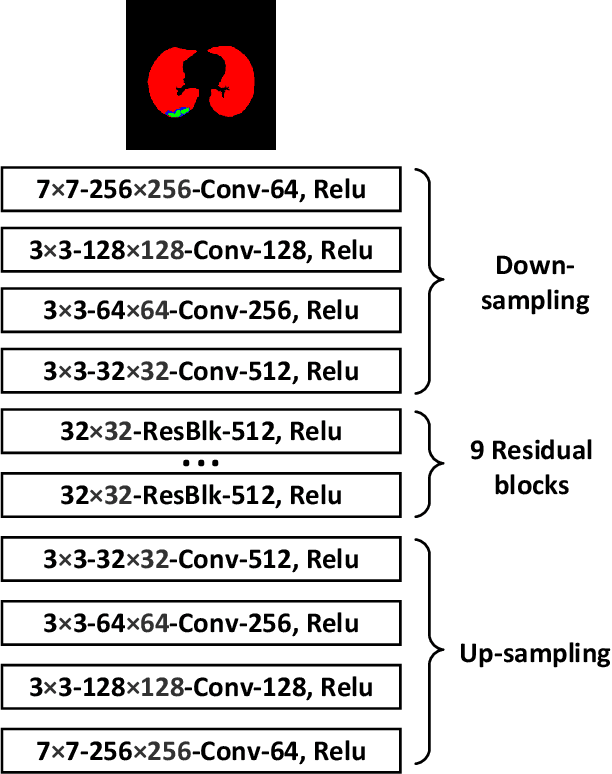
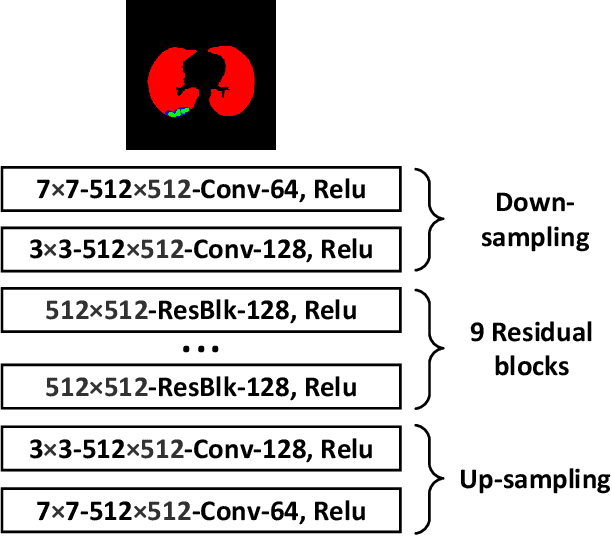
Coronavirus disease 2019 (COVID-19) is an ongoing global pandemic that has spread rapidly since December 2019. Real-time reverse transcription polymerase chain reaction (rRT-PCR) and chest computed tomography (CT) imaging both play an important role in COVID-19 diagnosis. Chest CT imaging offers the benefits of quick reporting, a low cost, and high sensitivity for the detection of pulmonary infection. Recently, deep-learning-based computer vision methods have demonstrated great promise for use in medical imaging applications, including X-rays, magnetic resonance imaging, and CT imaging. However, training a deep-learning model requires large volumes of data, and medical staff faces a high risk when collecting COVID-19 CT data due to the high infectivity of the disease. Another issue is the lack of experts available for data labeling. In order to meet the data requirements for COVID-19 CT imaging, we propose a CT image synthesis approach based on a conditional generative adversarial network that can effectively generate high-quality and realistic COVID-19 CT images for use in deep-learning-based medical imaging tasks. Experimental results show that the proposed method outperforms other state-of-the-art image synthesis methods with the generated COVID-19 CT images and indicates promising for various machine learning applications including semantic segmentation and classification.
Background Activation Suppression for Weakly Supervised Object Localization
Dec 01, 2021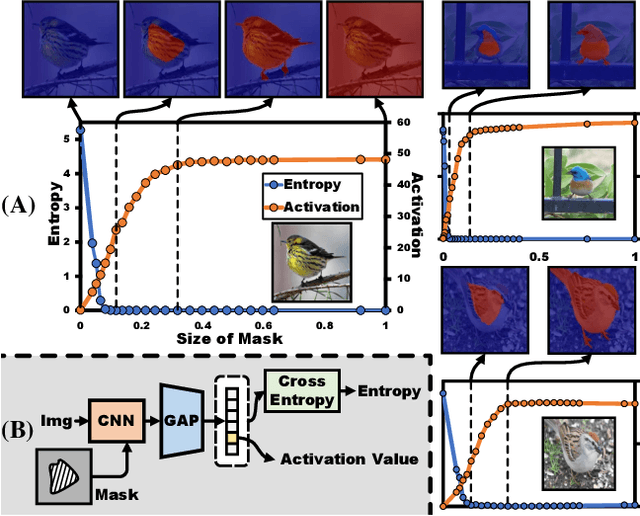
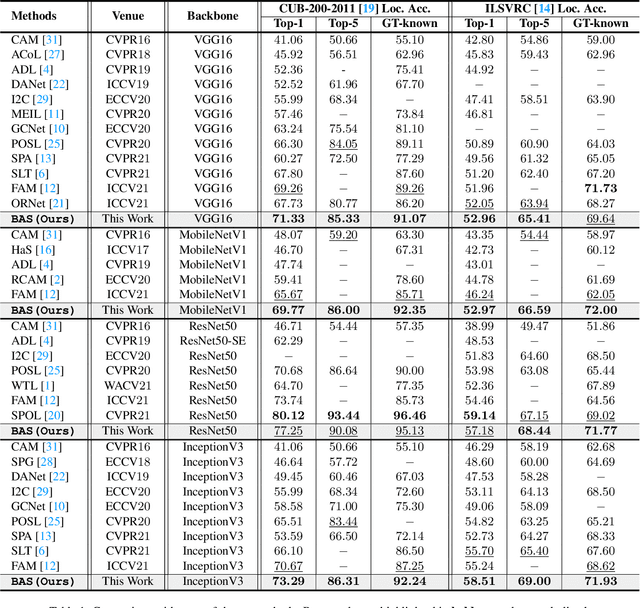
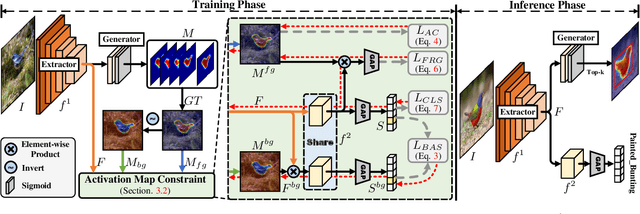
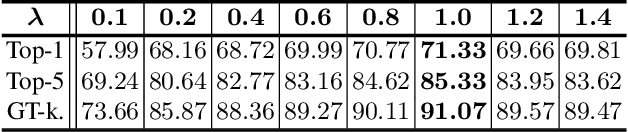
Weakly supervised object localization (WSOL) aims to localize the object region using only image-level labels as supervision. Recently a new paradigm has emerged by generating a foreground prediction map (FPM) to achieve the localization task. Existing FPM-based methods use cross-entropy (CE) to evaluate the foreground prediction map and to guide the learning of generator. We argue for using activation value to achieve more efficient learning. It is based on the experimental observation that, for a trained network, CE converges to zero when the foreground mask covers only part of the object region. While activation value increases until the mask expands to the object boundary, which indicates that more object areas can be learned by using activation value. In this paper, we propose a Background Activation Suppression (BAS) method. Specifically, an Activation Map Constraint module (AMC) is designed to facilitate the learning of generator by suppressing the background activation values. Meanwhile, by using the foreground region guidance and the area constraint, BAS can learn the whole region of the object. Furthermore, in the inference phase, we consider the prediction maps of different categories together to obtain the final localization results. Extensive experiments show that BAS achieves significant and consistent improvement over the baseline methods on the CUB-200-2011 and ILSVRC datasets.
Semi-Supervised Surface Anomaly Detection of Composite Wind Turbine Blades From Drone Imagery
Dec 01, 2021
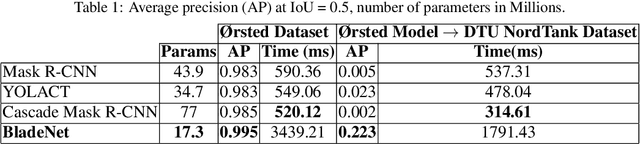
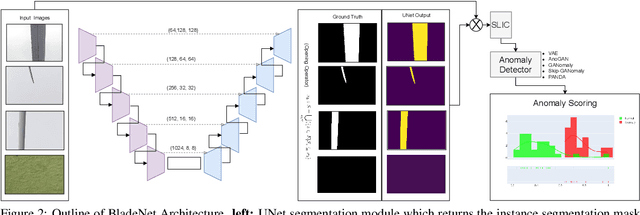
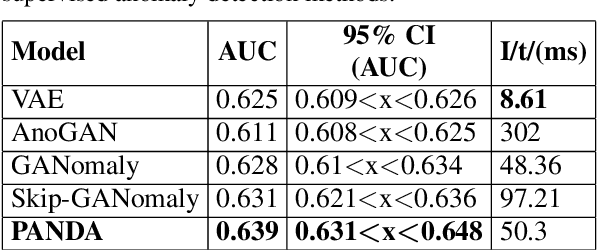
Within commercial wind energy generation, the monitoring and predictive maintenance of wind turbine blades in-situ is a crucial task, for which remote monitoring via aerial survey from an Unmanned Aerial Vehicle (UAV) is commonplace. Turbine blades are susceptible to both operational and weather-based damage over time, reducing the energy efficiency output of turbines. In this study, we address automating the otherwise time-consuming task of both blade detection and extraction, together with fault detection within UAV-captured turbine blade inspection imagery. We propose BladeNet, an application-based, robust dual architecture to perform both unsupervised turbine blade detection and extraction, followed by super-pixel generation using the Simple Linear Iterative Clustering (SLIC) method to produce regional clusters. These clusters are then processed by a suite of semi-supervised detection methods. Our dual architecture detects surface faults of glass fibre composite material blades with high aptitude while requiring minimal prior manual image annotation. BladeNet produces an Average Precision (AP) of 0.995 across our {\O}rsted blade inspection dataset for offshore wind turbines and 0.223 across the Danish Technical University (DTU) NordTank turbine blade inspection dataset. BladeNet also obtains an AUC of 0.639 for surface anomaly detection across the {\O}rsted blade inspection dataset.
A CNN based method for Sub-pixel Urban Land Cover Classification using Landsat-5 TM and Resourcesat-1 LISS-IV Imagery
Dec 16, 2021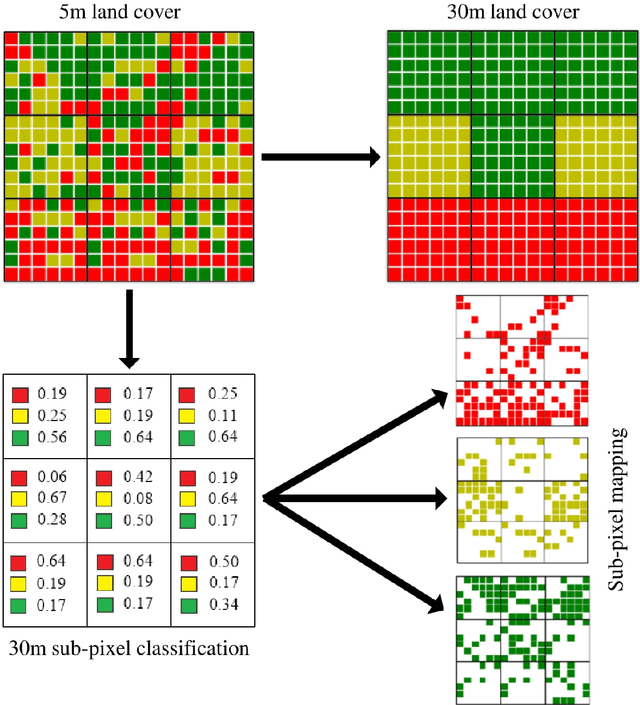
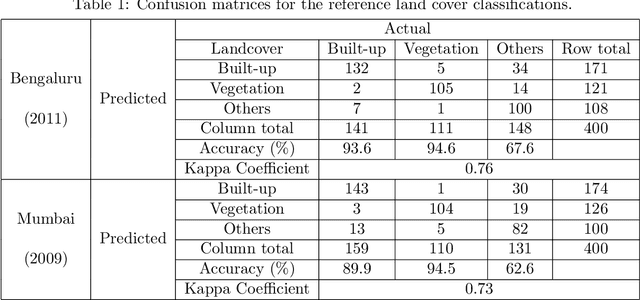
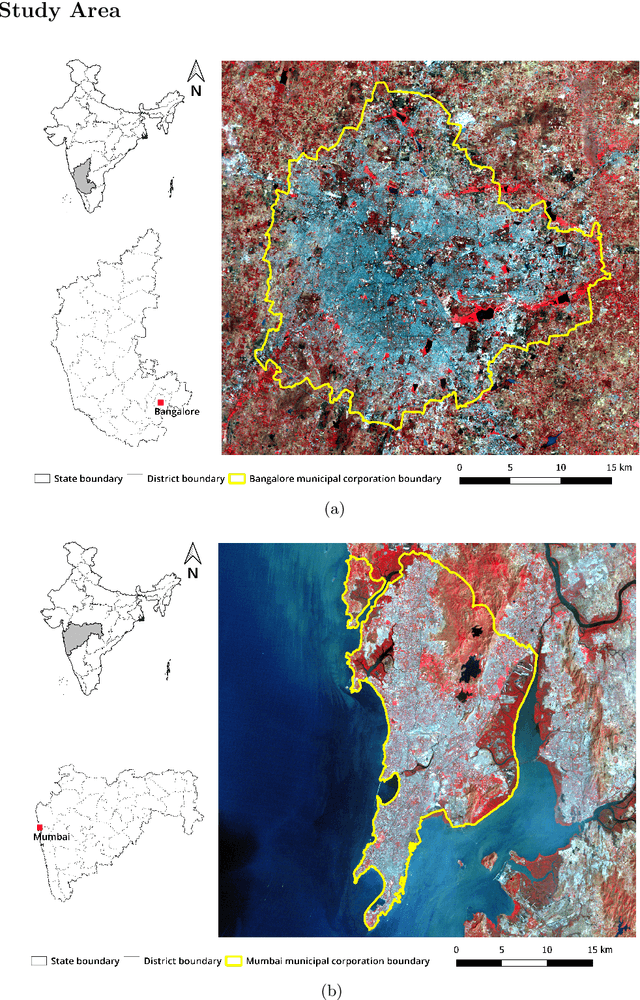
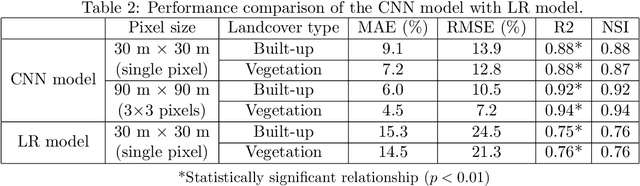
Time series data of urban land cover is of great utility in analyzing urban growth patterns, changes in distribution of impervious surface and vegetation and resulting impacts on urban micro climate. While Landsat data is ideal for such analysis due to the long time series of free imagery, traditional per-pixel hard classification fails to yield full potential of the Landsat data. This paper proposes a sub-pixel classification method that leverages the temporal overlap of Landsat-5 TM and Resourcesat-1 LISS-IV sensors. We train a convolutional neural network to predict fractional land cover maps from 30m Landsat-5 TM data. The reference land cover fractions are estimated from a hard-classified 5.8m LISS-IV image for Bengaluru from 2011. Further, we demonstrate the generalizability and superior performance of the proposed model using data for Mumbai from 2009 and comparing it to the results obtained using a Random Forest classifier. For both Bengaluru (2011) and Mumbai (2009) data, Mean Absolute Percentage Error of our CNN model is in the range of 7.2 to 11.3 for both built-up and vegetation fraction prediction at the 30m cell level. Unlike most recent studies where validation is conducted using data for a limited spatial extent, our model has been trained and validated using data for the complete spatial extent of two mega cities for two different time periods. Hence it can reliably generate 30m built-up and vegetation fraction maps from Landsat-5 TM time series data to analyze long term urban growth patterns.
Shadow Removal via Shadow Image Decomposition
Aug 23, 2019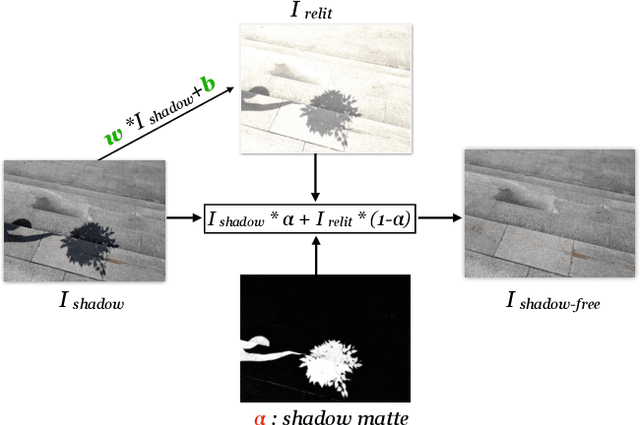
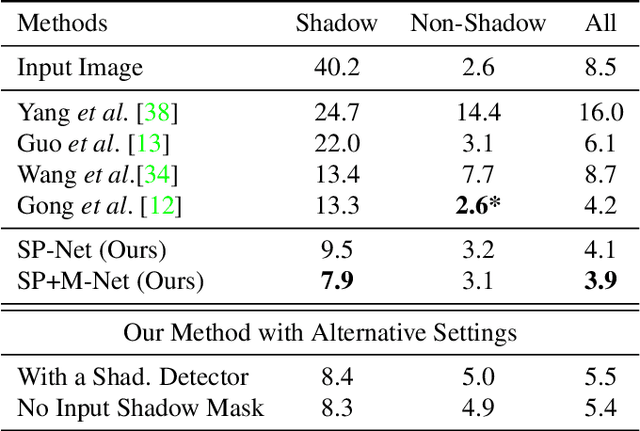
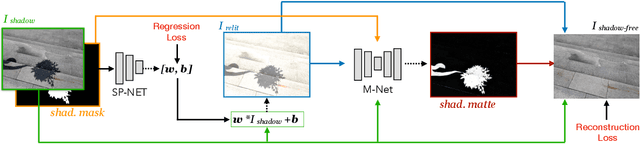
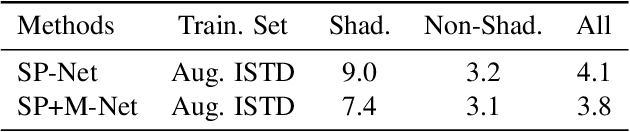
We propose a novel deep learning method for shadow removal. Inspired by physical models of shadow formation, we use a linear illumination transformation to model the shadow effects in the image that allows the shadow image to be expressed as a combination of the shadow-free image, the shadow parameters, and a matte layer. We use two deep networks, namely SP-Net and M-Net, to predict the shadow parameters and the shadow matte respectively. This system allows us to remove the shadow effects on the images. We train and test our framework on the most challenging shadow removal dataset (ISTD). Compared to the state-of-the-art method, our model achieves a 40% error reduction in terms of root mean square error (RMSE) for the shadow area, reducing RMSE from 13.3 to 7.9. Moreover, we create an augmented ISTD dataset based on an image decomposition system by modifying the shadow parameters to generate new synthetic shadow images. Training our model on this new augmented ISTD dataset further lowers the RMSE on the shadow area to 7.4.