 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Neural Fields in Visual Computing and Beyond
Nov 23, 2021
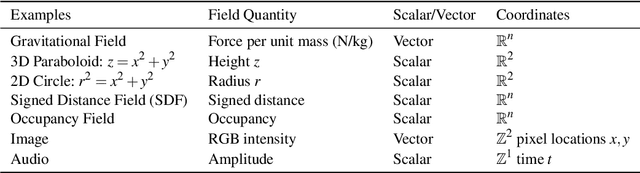
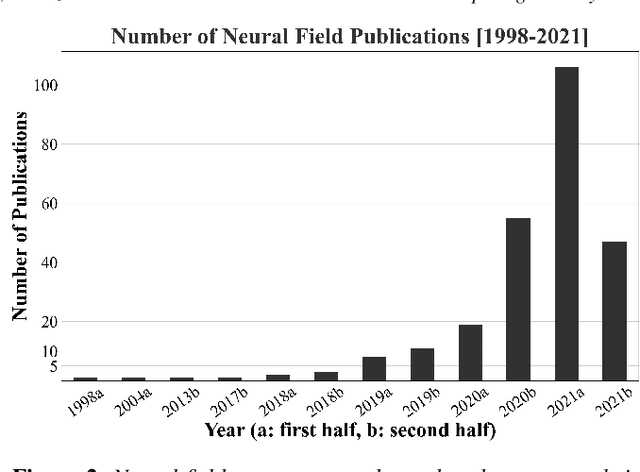

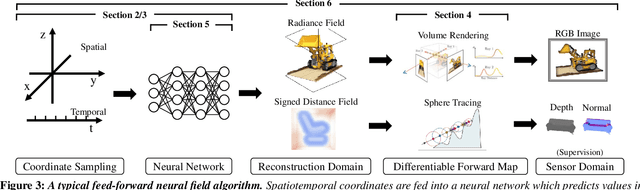
Recent advances in machine learning have created increasing interest in solving visual computing problems using a class of coordinate-based neural networks that parametrize physical properties of scenes or objects across space and time. These methods, which we call neural fields, have seen successful application in the synthesis of 3D shapes and image, animation of human bodies, 3D reconstruction, and pose estimation. However, due to rapid progress in a short time, many papers exist but a comprehensive review and formulation of the problem has not yet emerged. In this report, we address this limitation by providing context, mathematical grounding, and an extensive review of literature on neural fields. This report covers research along two dimensions. In Part I, we focus on techniques in neural fields by identifying common components of neural field methods, including different representations, architectures, forward mapping, and generalization methods. In Part II, we focus on applications of neural fields to different problems in visual computing, and beyond (e.g., robotics, audio). Our review shows the breadth of topics already covered in visual computing, both historically and in current incarnations, demonstrating the improved quality, flexibility, and capability brought by neural fields methods. Finally, we present a companion website that contributes a living version of this review that can be continually updated by the community.
ChebLieNet: Invariant Spectral Graph NNs Turned Equivariant by Riemannian Geometry on Lie Groups
Nov 23, 2021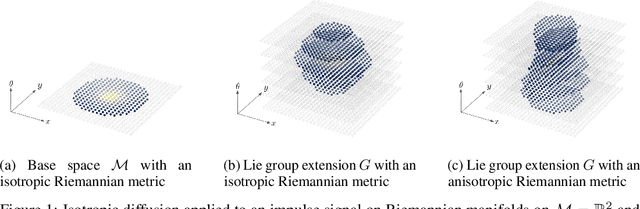

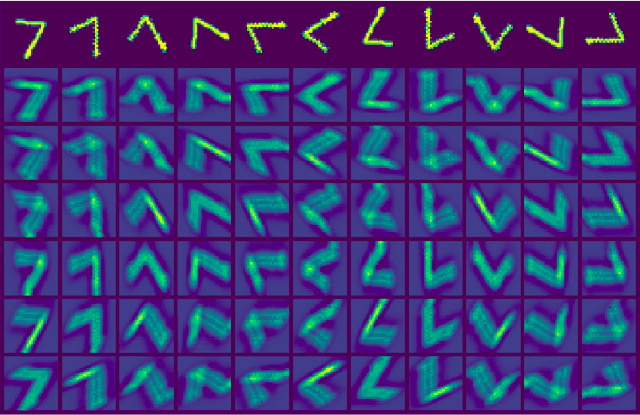

We introduce ChebLieNet, a group-equivariant method on (anisotropic) manifolds. Surfing on the success of graph- and group-based neural networks, we take advantage of the recent developments in the geometric deep learning field to derive a new approach to exploit any anisotropies in data. Via discrete approximations of Lie groups, we develop a graph neural network made of anisotropic convolutional layers (Chebyshev convolutions), spatial pooling and unpooling layers, and global pooling layers. Group equivariance is achieved via equivariant and invariant operators on graphs with anisotropic left-invariant Riemannian distance-based affinities encoded on the edges. Thanks to its simple form, the Riemannian metric can model any anisotropies, both in the spatial and orientation domains. This control on anisotropies of the Riemannian metrics allows to balance equivariance (anisotropic metric) against invariance (isotropic metric) of the graph convolution layers. Hence we open the doors to a better understanding of anisotropic properties. Furthermore, we empirically prove the existence of (data-dependent) sweet spots for anisotropic parameters on CIFAR10. This crucial result is evidence of the benefice we could get by exploiting anisotropic properties in data. We also evaluate the scalability of this approach on STL10 (image data) and ClimateNet (spherical data), showing its remarkable adaptability to diverse tasks.
A Systematical Solution for Face De-identification
Jul 19, 2021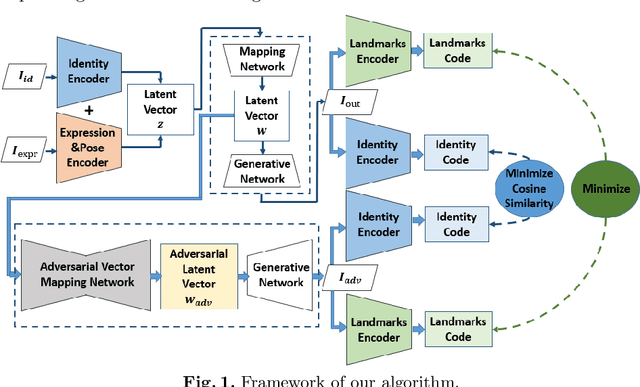



With the identity information in face data more closely related to personal credit and property security, people pay increasing attention to the protection of face data privacy. In different tasks, people have various requirements for face de-identification (De-ID), so we propose a systematical solution compatible for these De-ID operations. Firstly, an attribute disentanglement and generative network is constructed to encode two parts of the face, which are the identity (facial features like mouth, nose and eyes) and expression (including expression, pose and illumination). Through face swapping, we can remove the original ID completely. Secondly, we add an adversarial vector mapping network to perturb the latent code of the face image, different from previous traditional adversarial methods. Through this, we can construct unrestricted adversarial image to decrease ID similarity recognized by model. Our method can flexibly de-identify the face data in various ways and the processed images have high image quality.
Rethinking Drone-Based Search and Rescue with Aerial Person Detection
Nov 17, 2021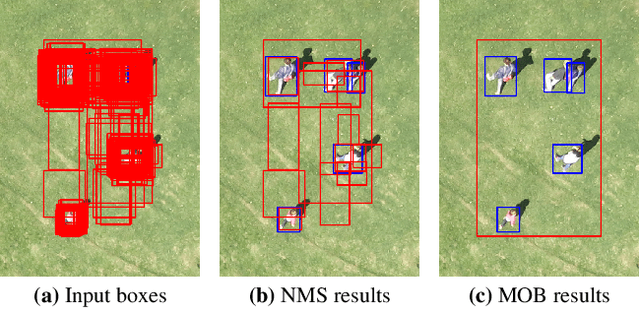
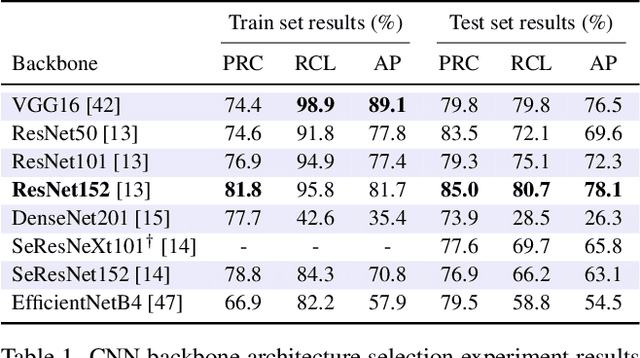
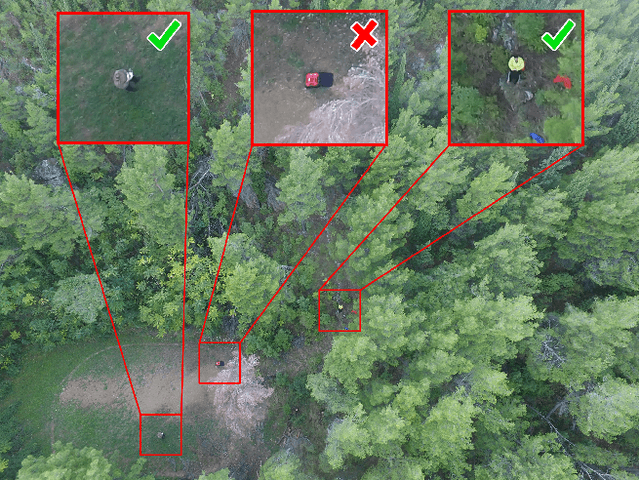
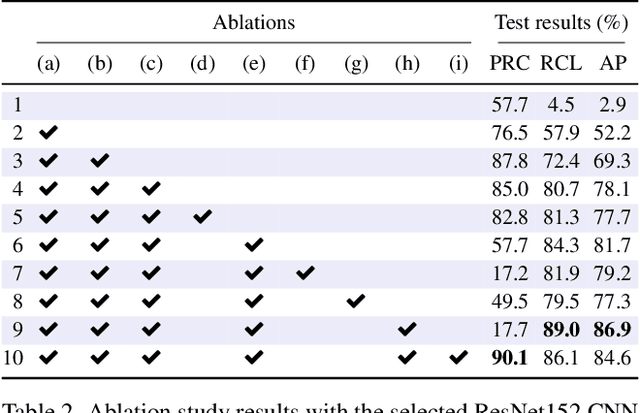
The visual inspection of aerial drone footage is an integral part of land search and rescue (SAR) operations today. Since this inspection is a slow, tedious and error-prone job for humans, we propose a novel deep learning algorithm to automate this aerial person detection (APD) task. We experiment with model architecture selection, online data augmentation, transfer learning, image tiling and several other techniques to improve the test performance of our method. We present the novel Aerial Inspection RetinaNet (AIR) algorithm as the combination of these contributions. The AIR detector demonstrates state-of-the-art performance on a commonly used SAR test data set in terms of both precision (~21 percentage point increase) and speed. In addition, we provide a new formal definition for the APD problem in SAR missions. That is, we propose a novel evaluation scheme that ranks detectors in terms of real-world SAR localization requirements. Finally, we propose a novel postprocessing method for robust, approximate object localization: the merging of overlapping bounding boxes (MOB) algorithm. This final processing stage used in the AIR detector significantly improves its performance and usability in the face of real-world aerial SAR missions.
Algorithmic Fairness in Face Morphing Attack Detection
Nov 23, 2021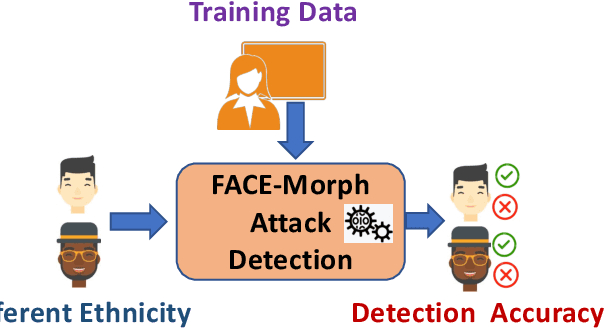
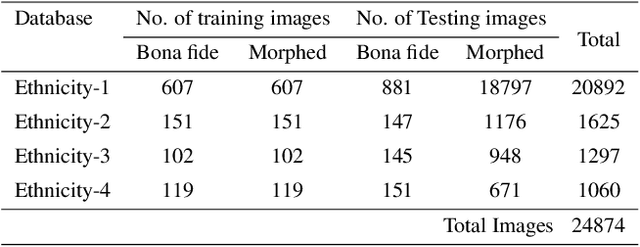

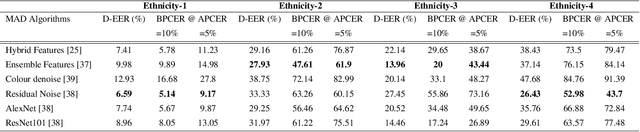
Face morphing attacks can compromise Face Recognition System (FRS) by exploiting their vulnerability. Face Morphing Attack Detection (MAD) techniques have been developed in recent past to deter such attacks and mitigate risks from morphing attacks. MAD algorithms, as any other algorithms should treat the images of subjects from different ethnic origins in an equal manner and provide non-discriminatory results. While the promising MAD algorithms are tested for robustness, there is no study comprehensively bench-marking their behaviour against various ethnicities. In this paper, we study and present a comprehensive analysis of algorithmic fairness of the existing Single image-based Morph Attack Detection (S-MAD) algorithms. We attempt to better understand the influence of ethnic bias on MAD algorithms and to this extent, we study the performance of MAD algorithms on a newly created dataset consisting of four different ethnic groups. With Extensive experiments using six different S-MAD techniques, we first present benchmark of detection performance and then measure the quantitative value of the algorithmic fairness for each of them using Fairness Discrepancy Rate (FDR). The results indicate the lack of fairness on all six different S-MAD methods when trained and tested on different ethnic groups suggesting the need for reliable MAD approaches to mitigate the algorithmic bias.
Contrastive Learning with Temporal Correlated Medical Images: A Case Study using Lung Segmentation in Chest X-Rays
Sep 16, 2021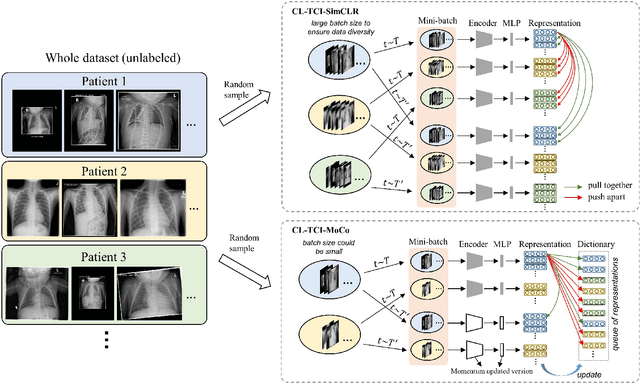
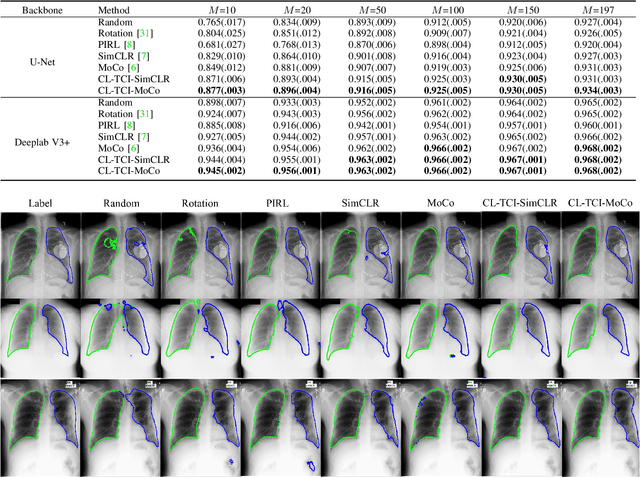
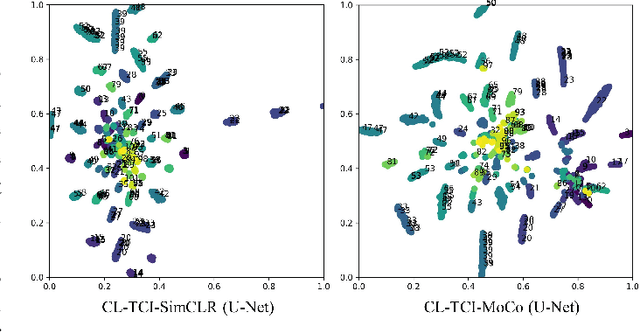
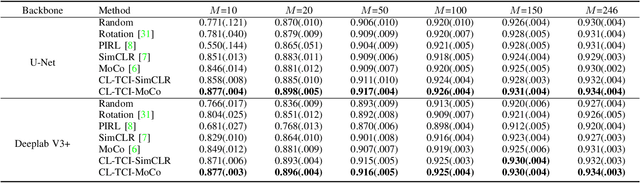
Contrastive learning has been proved to be a promising technique for image-level representation learning from unlabeled data. Many existing works have demonstrated improved results by applying contrastive learning in classification and object detection tasks for either natural images or medical images. However, its application to medical image segmentation tasks has been limited. In this work, we use lung segmentation in chest X-rays as a case study and propose a contrastive learning framework with temporal correlated medical images, named CL-TCI, to learn superior encoders for initializing the segmentation network. We adapt CL-TCI from two state-of-the-art contrastive learning methods-MoCo and SimCLR. Experiment results on three chest X-ray datasets show that under two different segmentation backbones, U-Net and Deeplab-V3, CL-TCI can outperform all baselines that do not incorporate any temporal correlation in both semi-supervised learning setting and transfer learning setting with limited annotation. This suggests that information among temporal correlated medical images can indeed improve contrastive learning performance. Between the two variations of CL-TCI, CL-TCI adapted from MoCo outperforms CL-TCI adapted from SimCLR in most settings, indicating that more contrastive samples can benefit the learning process and help the network learn high-quality representations.
Reversible Adversarial Examples based on Reversible Image Transformation
Nov 19, 2019

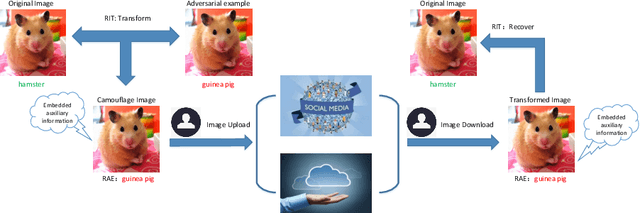

Recent studies show that widely used deep neural networks (DNNs) are vulnerable to carefully crafted adversarial examples, it inevitably brings some security challenges. However, the attack characteristic of adversarial examples can be taken advantage to do privacy-preserving image research. In this paper, we make use of Reversible Image Transformation to construct reversible adversarial examples, which are still misclassified by DNNs that are utilized by illegal organizations to steal privacy of image content that we upload to the cloud or social platforms. Most importantly, the proposed method can recover original images from downloaded reversible adversarial examples with no distortion. The experimental results show that the attack success rate of the reversible adversarial examples obtained by this method can reach more than 95 % on MNIST and more than 60 % on ImageNet.
Multimodal Image Outpainting With Regularized Normalized Diversification
Oct 25, 2019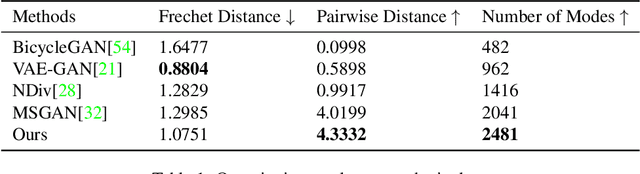
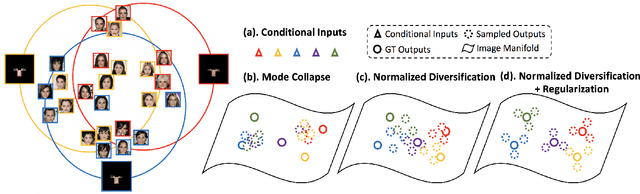
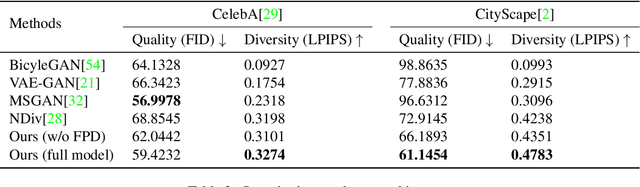
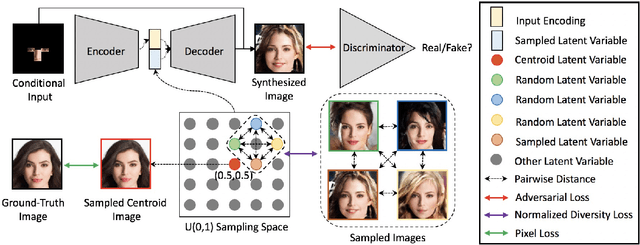
In this paper, we study the problem of generating a set ofrealistic and diverse backgrounds when given only a smallforeground region. We refer to this task as image outpaint-ing. The technical challenge of this task is to synthesize notonly plausible but also diverse image outputs. Traditionalgenerative adversarial networks suffer from mode collapse.While recent approaches propose to maximize orpreserve the pairwise distance between generated sampleswith respect to their latent distance, they do not explicitlyprevent the diverse samples of different conditional inputsfrom collapsing. Therefore, we propose a new regulariza-tion method to encourage diverse sampling in conditionalsynthesis. In addition, we propose a feature pyramid dis-criminator to improve the image quality. Our experimen-tal results show that our model can produce more diverseimages without sacrificing visual quality compared to state-of-the-arts approaches in both the CelebA face dataset and the Cityscape scene dataset.
Deblur-NeRF: Neural Radiance Fields from Blurry Images
Nov 29, 2021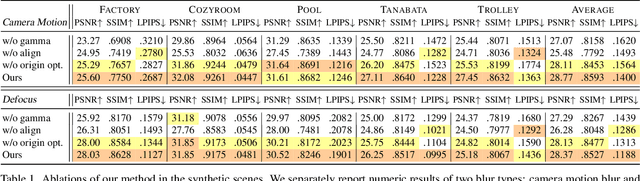
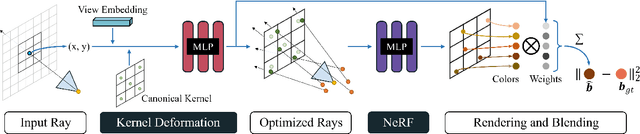
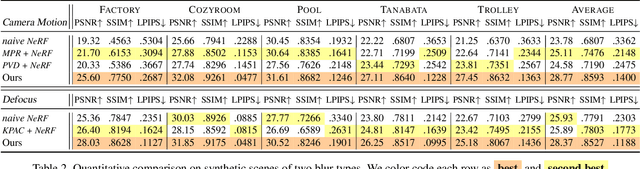
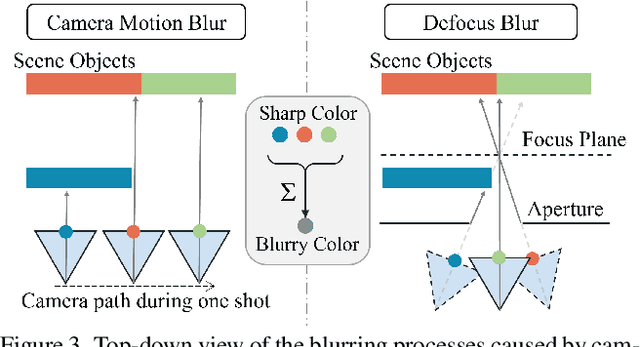
Neural Radiance Field (NeRF) has gained considerable attention recently for 3D scene reconstruction and novel view synthesis due to its remarkable synthesis quality. However, image blurriness caused by defocus or motion, which often occurs when capturing scenes in the wild, significantly degrades its reconstruction quality. To address this problem, We propose Deblur-NeRF, the first method that can recover a sharp NeRF from blurry input. We adopt an analysis-by-synthesis approach that reconstructs blurry views by simulating the blurring process, thus making NeRF robust to blurry inputs. The core of this simulation is a novel Deformable Sparse Kernel (DSK) module that models spatially-varying blur kernels by deforming a canonical sparse kernel at each spatial location. The ray origin of each kernel point is jointly optimized, inspired by the physical blurring process. This module is parameterized as an MLP that has the ability to be generalized to various blur types. Jointly optimizing the NeRF and the DSK module allows us to restore a sharp NeRF. We demonstrate that our method can be used on both camera motion blur and defocus blur: the two most common types of blur in real scenes. Evaluation results on both synthetic and real-world data show that our method outperforms several baselines. The synthetic and real datasets along with the source code will be made publicly available to facilitate future research.
WOOD: Wasserstein-based Out-of-Distribution Detection
Dec 13, 2021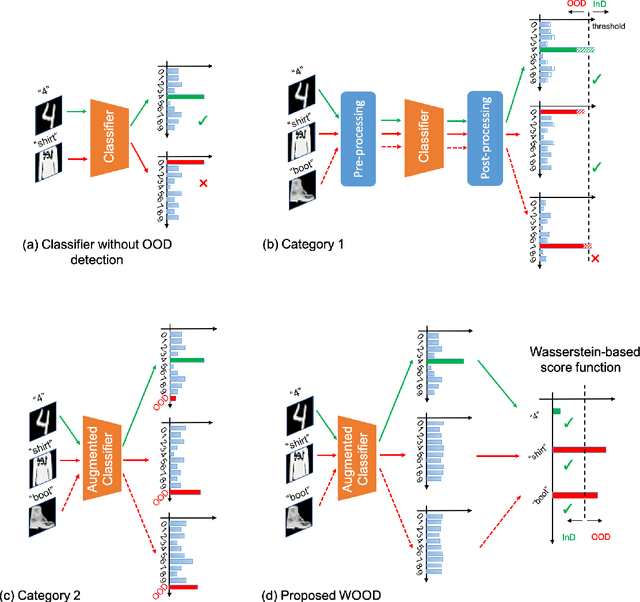

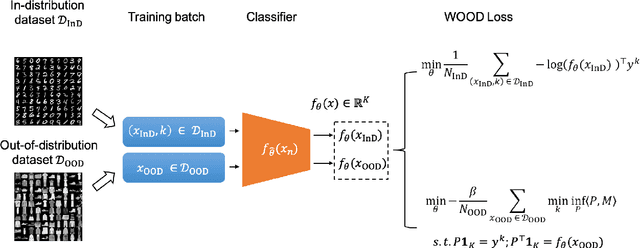
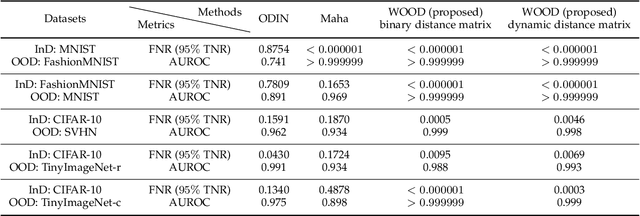
The training and test data for deep-neural-network-based classifiers are usually assumed to be sampled from the same distribution. When part of the test samples are drawn from a distribution that is sufficiently far away from that of the training samples (a.k.a. out-of-distribution (OOD) samples), the trained neural network has a tendency to make high confidence predictions for these OOD samples. Detection of the OOD samples is critical when training a neural network used for image classification, object detection, etc. It can enhance the classifier's robustness to irrelevant inputs, and improve the system resilience and security under different forms of attacks. Detection of OOD samples has three main challenges: (i) the proposed OOD detection method should be compatible with various architectures of classifiers (e.g., DenseNet, ResNet), without significantly increasing the model complexity and requirements on computational resources; (ii) the OOD samples may come from multiple distributions, whose class labels are commonly unavailable; (iii) a score function needs to be defined to effectively separate OOD samples from in-distribution (InD) samples. To overcome these challenges, we propose a Wasserstein-based out-of-distribution detection (WOOD) method. The basic idea is to define a Wasserstein-distance-based score that evaluates the dissimilarity between a test sample and the distribution of InD samples. An optimization problem is then formulated and solved based on the proposed score function. The statistical learning bound of the proposed method is investigated to guarantee that the loss value achieved by the empirical optimizer approximates the global optimum. The comparison study results demonstrate that the proposed WOOD consistently outperforms other existing OOD detection methods.