 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
On the Role of Receptive Field in Unsupervised Sim-to-Real Image Translation
Jan 25, 2020
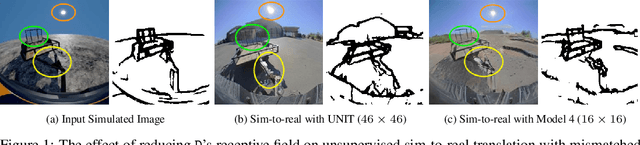
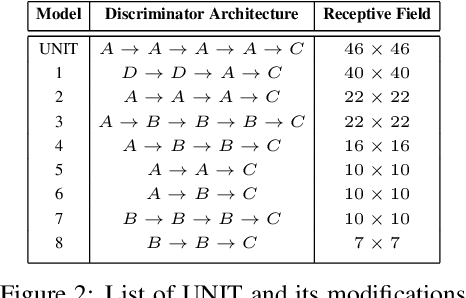
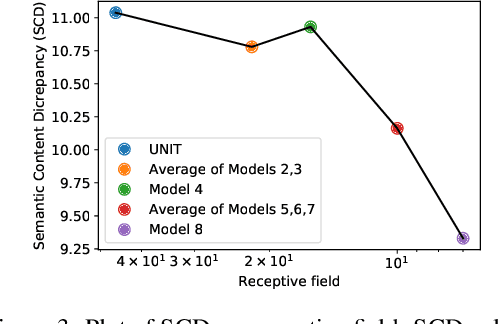

Generative Adversarial Networks (GANs) are now widely used for photo-realistic image synthesis. In applications where a simulated image needs to be translated into a realistic image (sim-to-real), GANs trained on unpaired data from the two domains are susceptible to failure in semantic content retention as the image is translated from one domain to the other. This failure mode is more pronounced in cases where the real data lacks content diversity, resulting in a content \emph{mismatch} between the two domains - a situation often encountered in real-world deployment. In this paper, we investigate the role of the discriminator's receptive field in GANs for unsupervised image-to-image translation with mismatched data, and study its effect on semantic content retention. Experiments with the discriminator architecture of a state-of-the-art coupled Variational Auto-Encoder (VAE) - GAN model on diverse, mismatched datasets show that the discriminator receptive field is directly correlated with semantic content discrepancy of the generated image.
A Better Loss for Visual-Textual Grounding
Aug 11, 2021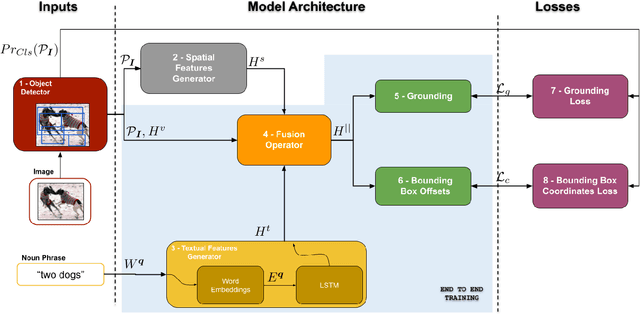
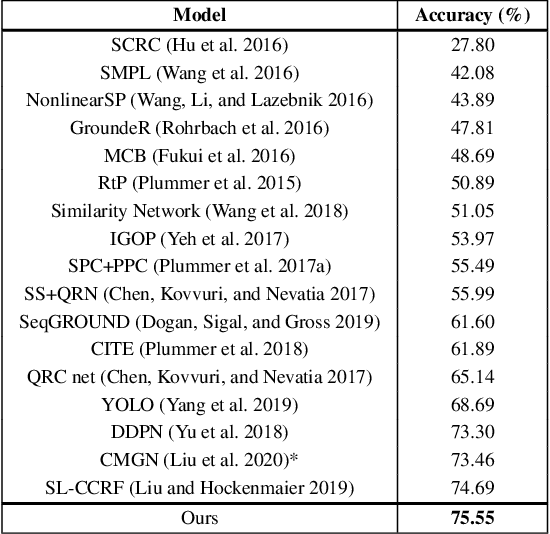

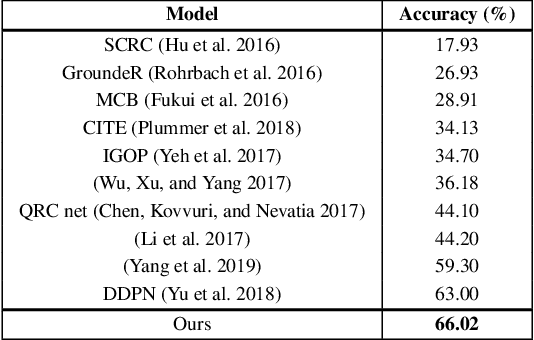
Given a textual phrase and an image, the visual grounding problem is defined as the task of locating the content of the image referenced by the sentence. It is a challenging task that has several real-world applications in human-computer interaction, image-text reference resolution, and video-text reference resolution. In the last years, several works have addressed this problem with heavy and complex models that try to capture visual-textual dependencies better than before. These models are typically constituted by two main components that focus on how to learn useful multi-modal features for grounding and how to improve the predicted bounding box of the visual mention, respectively. Finding the right learning balance between these two sub-tasks is not easy, and the current models are not necessarily optimal with respect to this issue. In this work, we propose a model that, although using a simple multi-modal feature fusion component, is able to achieve a higher accuracy than state-of-the-art models thanks to the adoption of a more effective loss function, based on the classes probabilities, that reach, in the considered datasets, a better learning balance between the two sub-tasks mentioned above.
Multi-centred Strong Augmentation via Contrastive Learning for Unsupervised Lesion Detection and Segmentation
Sep 03, 2021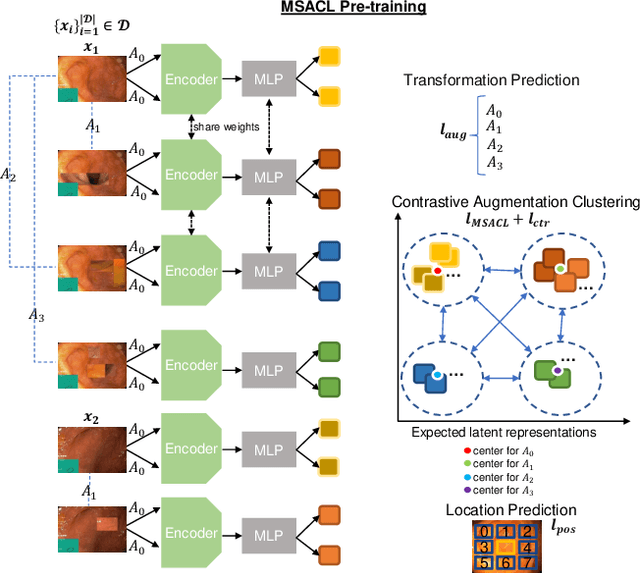
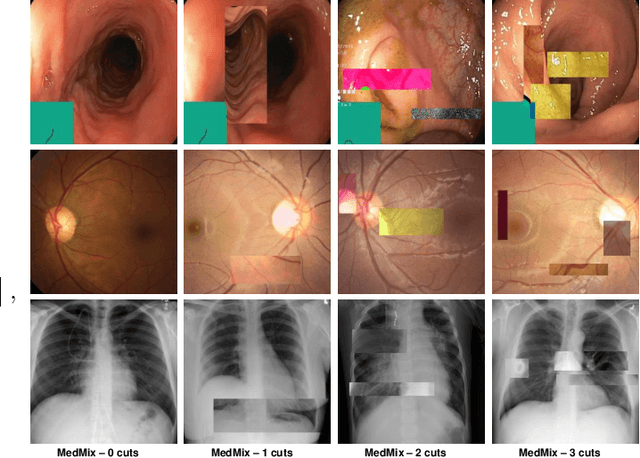
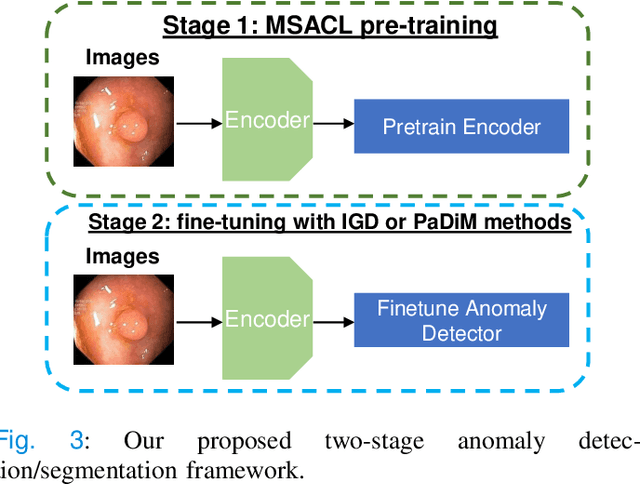
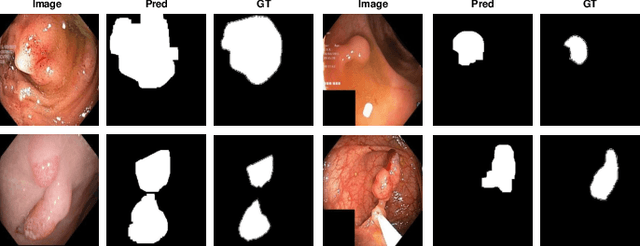
The scarcity of high quality medical image annotations hinders the implementation of accurate clinical applications for detecting and segmenting abnormal lesions. To mitigate this issue, the scientific community is working on the development of unsupervised anomaly detection (UAD) systems that learn from a training set containing only normal (i.e., healthy) images, where abnormal samples (i.e., unhealthy) are detected and segmented based on how much they deviate from the learned distribution of normal samples. One significant challenge faced by UAD methods is how to learn effective low-dimensional image representations that are sensitive enough to detect and segment abnormal lesions of varying size, appearance and shape. To address this challenge, we propose a novel self-supervised UAD pre-training algorithm, named Multi-centred Strong Augmentation via Contrastive Learning (MSACL). MSACL learns representations by separating several types of strong and weak augmentations of normal image samples, where the weak augmentations represent normal images and strong augmentations denote synthetic abnormal images. To produce such strong augmentations, we introduce MedMix, a novel data augmentation strategy that creates new training images with realistic looking lesions (i.e., anomalies) in normal images. The pre-trained representations from MSACL are generic and can be used to improve the efficacy of different types of off-the-shelf state-of-the-art (SOTA) UAD models. Comprehensive experimental results show that the use of MSACL largely improves these SOTA UAD models on four medical imaging datasets from diverse organs, namely colonoscopy, fundus screening and covid-19 chest-ray datasets.
Teaching Undergraduate Students to Think Like Real-World Systems Engineers: A Technology-Based Hybrid Learning Approach
Nov 26, 2021

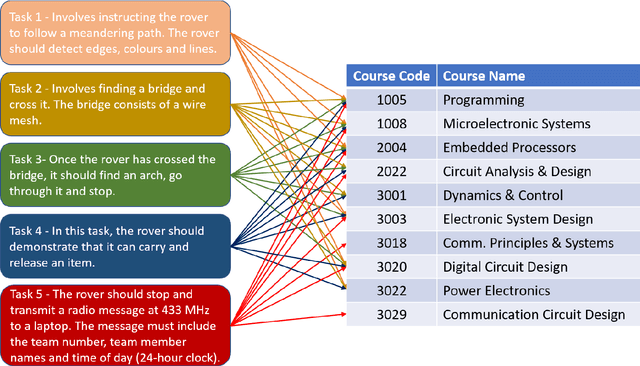

A hybrid teaching approach that relied on combining Project Based Learning with Team Based Learning was trialled in an engineering module during the past five years. Our motivation was to expose students to real-world authentic engineering problems and to steer them away from the classical 'banking' approach, with a view to developing their systems engineering skills via deeper and more collaborative learning. Our third year module was called Team Design and Project Skills and was concerned with 320 students dividing themselves in teams to develop a smart electronic system. We reveal module design details and discuss the effectiveness of our teaching approach via analysis of student grades during the past five years, as well as data from surveys that were completed by 68 students. 64% of surveyed students agreed that the module helped broaden their perspective in electronic systems design. Moreover, 84% recognised that this module was a valuable component in their degree programme. Adopting this approach in an engineering curriculum enabled students to integrate knowledge in areas that included control systems, image processing, embedded systems, sensors, as well as team working, decision making, trouble shooting and project planning.
High-throughput Phenotyping of Nematode Cysts
Oct 13, 2021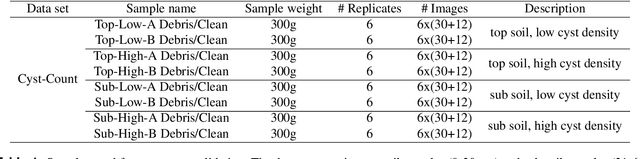
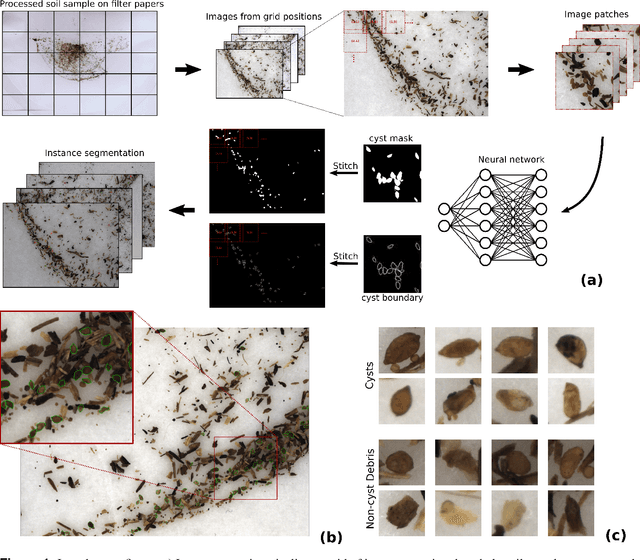
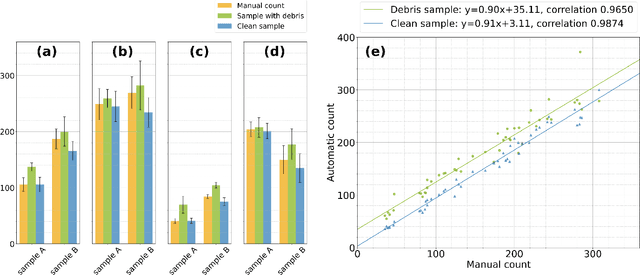
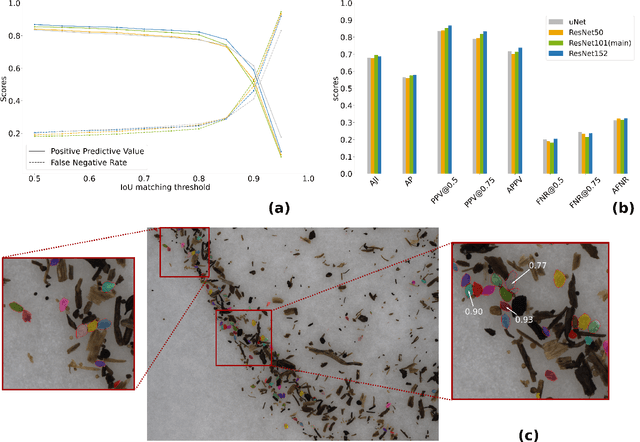
The beet cyst nematode (BCN) Heterodera schachtii is a plant pest responsible for crop loss on a global scale. Here, we introduce a high-throughput system based on computer vision that allows quantifying BCN infestation and characterizing nematode cysts through phenotyping. After recording microscopic images of soil extracts in a standardized setting, an instance segmentation algorithm serves to detect nematode cysts in these samples. Going beyond fast and precise cyst counting, the image-based approach enables quantification of cyst density and phenotyping of morphological features of cysts under different conditions, providing the basis for high-throughput applications in agriculture and plant breeding research.
Segmentation in Style: Unsupervised Semantic Image Segmentation with Stylegan and CLIP
Jul 26, 2021

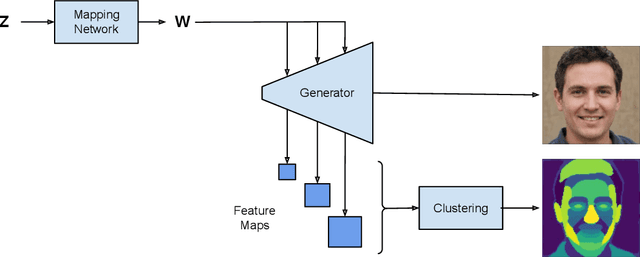
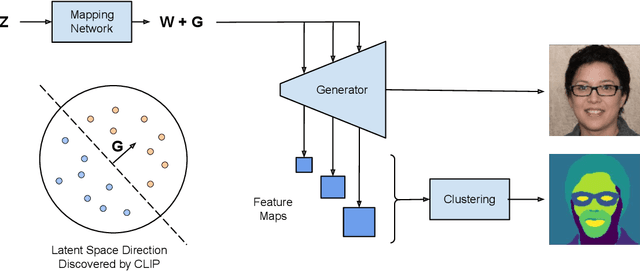
We introduce a method that allows to automatically segment images into semantically meaningful regions without human supervision. Derived regions are consistent across different images and coincide with human-defined semantic classes on some datasets. In cases where semantic regions might be hard for human to define and consistently label, our method is still able to find meaningful and consistent semantic classes. In our work, we use pretrained StyleGAN2~\cite{karras2020analyzing} generative model: clustering in the feature space of the generative model allows to discover semantic classes. Once classes are discovered, a synthetic dataset with generated images and corresponding segmentation masks can be created. After that a segmentation model is trained on the synthetic dataset and is able to generalize to real images. Additionally, by using CLIP~\cite{radford2021learning} we are able to use prompts defined in a natural language to discover some desired semantic classes. We test our method on publicly available datasets and show state-of-the-art results.
Synthetic Image Rendering Solves Annotation Problem in Deep Learning Nanoparticle Segmentation
Nov 20, 2020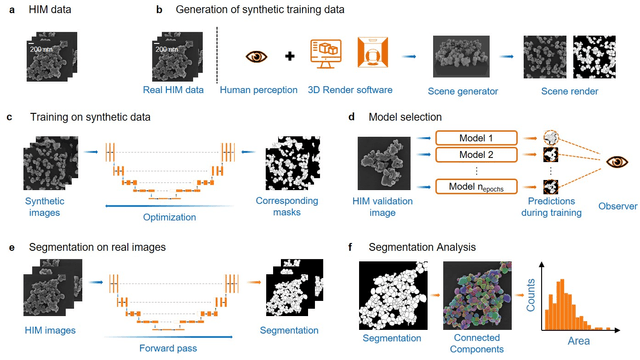
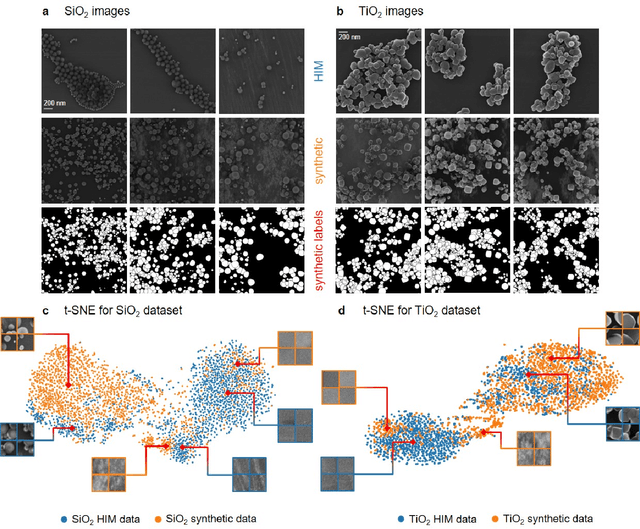
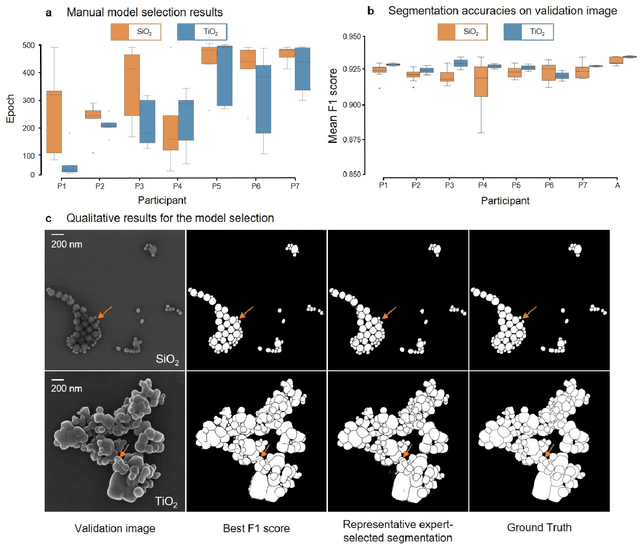
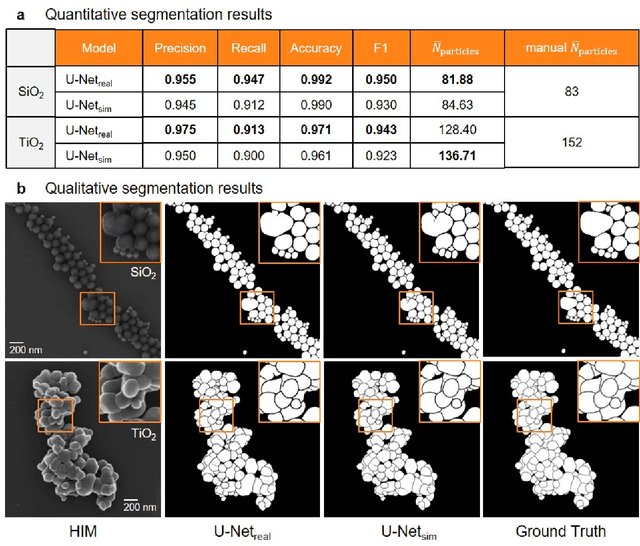
Nanoparticles occur in various environments as a consequence of man-made processes, which raises concerns about their impact on the environment and human health. To allow for proper risk assessment, a precise and statistically relevant analysis of particle characteristics (such as e.g. size, shape and composition) is required that would greatly benefit from automated image analysis procedures. While deep learning shows impressive results in object detection tasks, its applicability is limited by the amount of representative, experimentally collected and manually annotated training data. Here, we present an elegant, flexible and versatile method to bypass this costly and tedious data acquisition process. We show that using a rendering software allows to generate realistic, synthetic training data to train a state-of-the art deep neural network. Using this approach, we derive a segmentation accuracy that is comparable to man-made annotations for toxicologically relevant metal-oxide nanoparticle ensembles which we chose as examples. Our study paves the way towards the use of deep learning for automated, high-throughput particle detection in a variety of imaging techniques such as microscopies and spectroscopies, for a wide variety of studies and applications, including the detection of plastic micro- and nanoparticles.
Towards Photo-Realistic Virtual Try-On by Adaptively Generating$\leftrightarrow$Preserving Image Content
Mar 12, 2020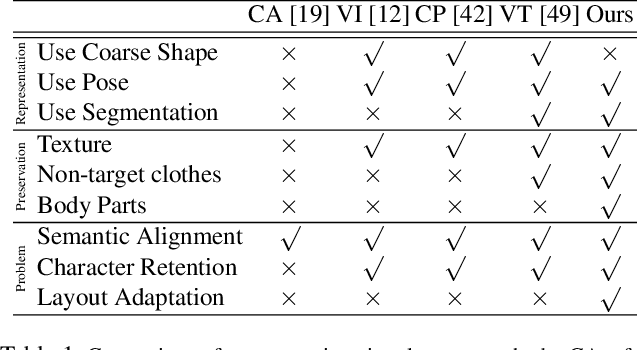
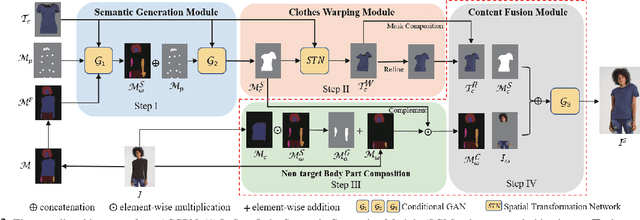
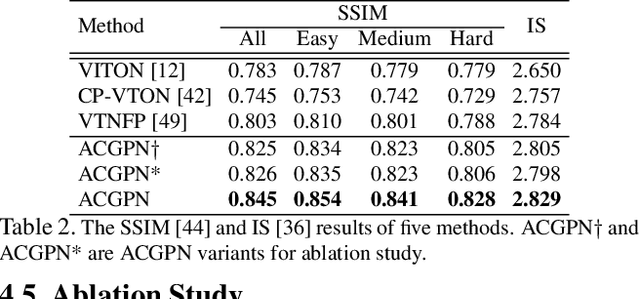

Image visual try-on aims at transferring a target clothing image onto a reference person, and has become a hot topic in recent years. Prior arts usually focus on preserving the character of a clothing image (e.g. texture, logo, embroidery) when warping it to arbitrary human pose. However, it remains a big challenge to generate photo-realistic try-on images when large occlusions and human poses are presented in the reference person. To address this issue, we propose a novel visual try-on network, namely Adaptive Content Generating and Preserving Network (ACGPN). In particular, ACGPN first predicts semantic layout of the reference image that will be changed after try-on (e.g. long sleeve shirt$\rightarrow$arm, arm$\rightarrow$jacket), and then determines whether its image content needs to be generated or preserved according to the predicted semantic layout, leading to photo-realistic try-on and rich clothing details. ACGPN generally involves three major modules. First, a semantic layout generation module utilizes semantic segmentation of the reference image to progressively predict the desired semantic layout after try-on. Second, a clothes warping module warps clothing images according to the generated semantic layout, where a second-order difference constraint is introduced to stabilize the warping process during training. Third, an inpainting module for content fusion integrates all information (e.g. reference image, semantic layout, warped clothes) to adaptively produce each semantic part of human body. In comparison to the state-of-the-art methods, ACGPN can generate photo-realistic images with much better perceptual quality and richer fine-details.
A Dual Adversarial Calibration Framework for Automatic Fetal Brain Biometry
Aug 28, 2021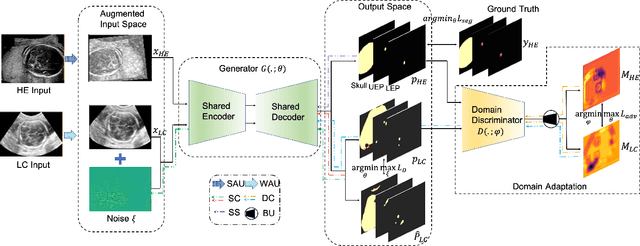

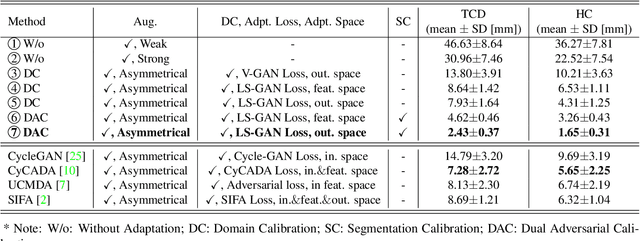
This paper presents a novel approach to automatic fetal brain biometry motivated by needs in low- and medium- income countries. Specifically, we leverage high-end (HE) ultrasound images to build a biometry solution for low-cost (LC) point-of-care ultrasound images. We propose a novel unsupervised domain adaptation approach to train deep models to be invariant to significant image distribution shift between the image types. Our proposed method, which employs a Dual Adversarial Calibration (DAC) framework, consists of adversarial pathways which enforce model invariance to; i) adversarial perturbations in the feature space derived from LC images, and ii) appearance domain discrepancy. Our Dual Adversarial Calibration method estimates transcerebellar diameter and head circumference on images from low-cost ultrasound devices with a mean absolute error (MAE) of 2.43mm and 1.65mm, compared with 7.28 mm and 5.65 mm respectively for SOTA.
Reinforcement Explanation Learning
Nov 26, 2021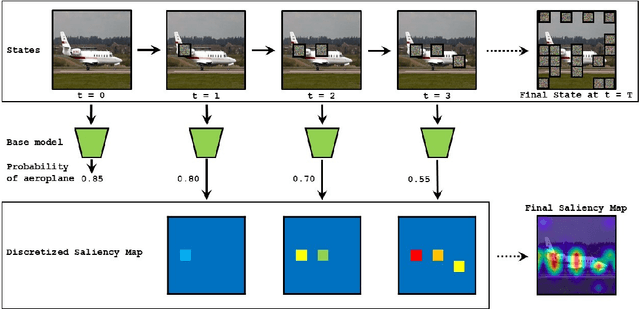
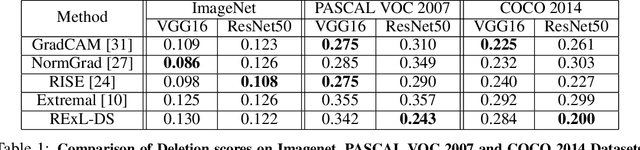
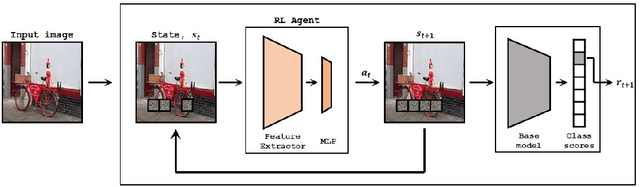
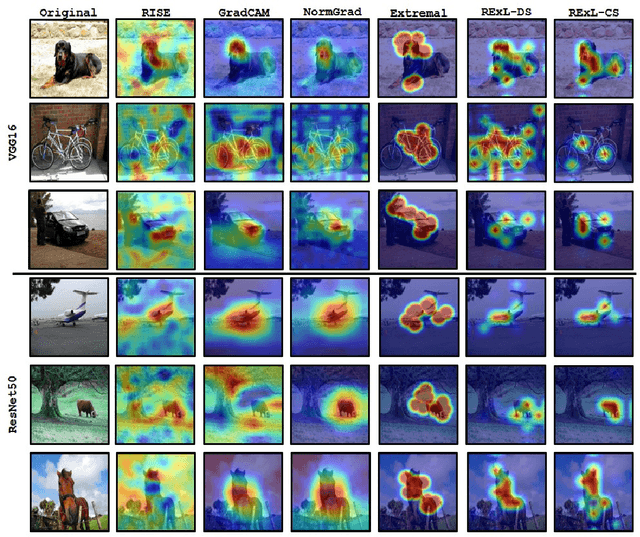
Deep Learning has become overly complicated and has enjoyed stellar success in solving several classical problems like image classification, object detection, etc. Several methods for explaining these decisions have been proposed. Black-box methods to generate saliency maps are particularly interesting due to the fact that they do not utilize the internals of the model to explain the decision. Most black-box methods perturb the input and observe the changes in the output. We formulate saliency map generation as a sequential search problem and leverage upon Reinforcement Learning (RL) to accumulate evidence from input images that most strongly support decisions made by a classifier. Such a strategy encourages to search intelligently for the perturbations that will lead to high-quality explanations. While successful black box explanation approaches need to rely on heavy computations and suffer from small sample approximation, the deterministic policy learned by our method makes it a lot more efficient during the inference. Experiments on three benchmark datasets demonstrate the superiority of the proposed approach in inference time over state-of-the-arts without hurting the performance. Project Page: https://cvir.github.io/projects/rexl.html