 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Utilizing Resource-Rich Language Datasets for End-to-End Scene Text Recognition in Resource-Poor Languages
Nov 24, 2021
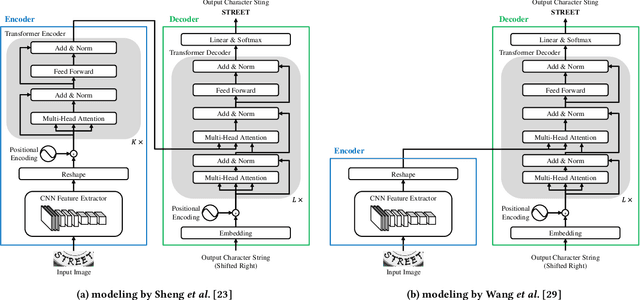
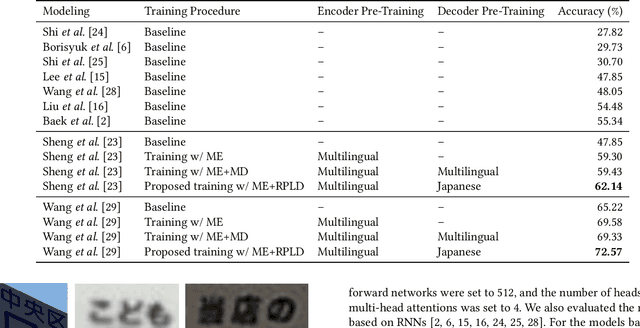
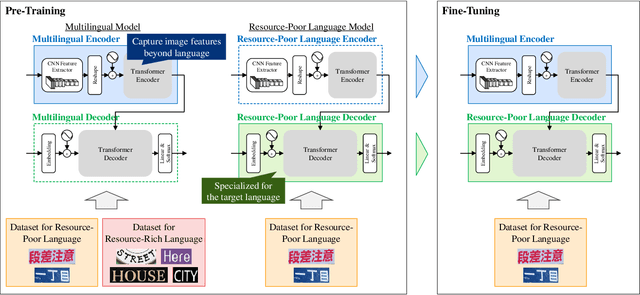
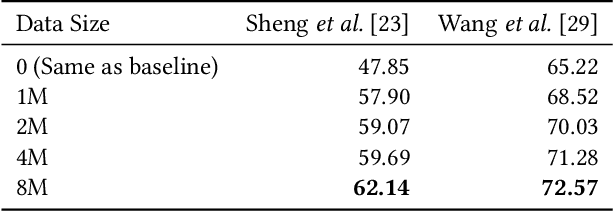
This paper presents a novel training method for end-to-end scene text recognition. End-to-end scene text recognition offers high recognition accuracy, especially when using the encoder-decoder model based on Transformer. To train a highly accurate end-to-end model, we need to prepare a large image-to-text paired dataset for the target language. However, it is difficult to collect this data, especially for resource-poor languages. To overcome this difficulty, our proposed method utilizes well-prepared large datasets in resource-rich languages such as English, to train the resource-poor encoder-decoder model. Our key idea is to build a model in which the encoder reflects knowledge of multiple languages while the decoder specializes in knowledge of just the resource-poor language. To this end, the proposed method pre-trains the encoder by using a multilingual dataset that combines the resource-poor language's dataset and the resource-rich language's dataset to learn language-invariant knowledge for scene text recognition. The proposed method also pre-trains the decoder by using the resource-poor language's dataset to make the decoder better suited to the resource-poor language. Experiments on Japanese scene text recognition using a small, publicly available dataset demonstrate the effectiveness of the proposed method.
Exploiting Robust Unsupervised Video Person Re-identification
Nov 18, 2021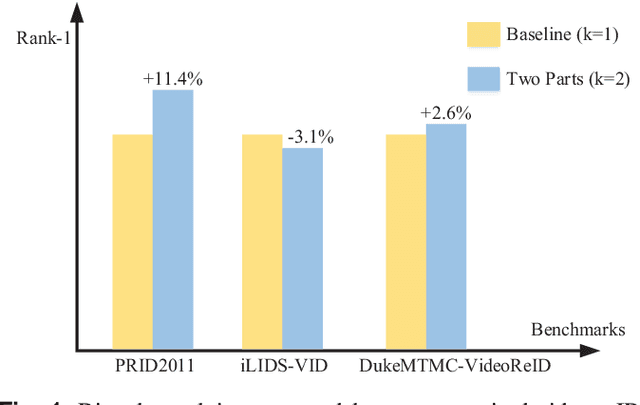
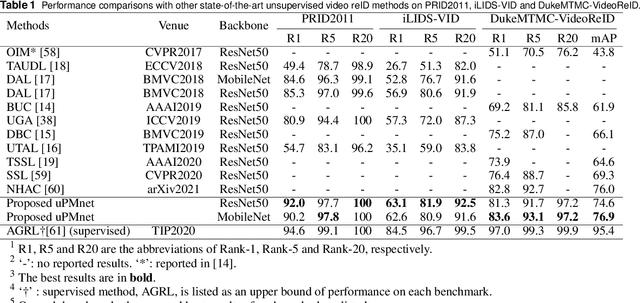


Unsupervised video person re-identification (reID) methods usually depend on global-level features. And many supervised reID methods employed local-level features and achieved significant performance improvements. However, applying local-level features to unsupervised methods may introduce an unstable performance. To improve the performance stability for unsupervised video reID, this paper introduces a general scheme fusing part models and unsupervised learning. In this scheme, the global-level feature is divided into equal local-level feature. A local-aware module is employed to explore the poentials of local-level feature for unsupervised learning. A global-aware module is proposed to overcome the disadvantages of local-level features. Features from these two modules are fused to form a robust feature representation for each input image. This feature representation has the advantages of local-level feature without suffering from its disadvantages. Comprehensive experiments are conducted on three benchmarks, including PRID2011, iLIDS-VID, and DukeMTMC-VideoReID, and the results demonstrate that the proposed approach achieves state-of-the-art performance. Extensive ablation studies demonstrate the effectiveness and robustness of proposed scheme, local-aware module and global-aware module.
APANet: Adaptive Prototypes Alignment Network for Few-Shot Semantic Segmentation
Nov 24, 2021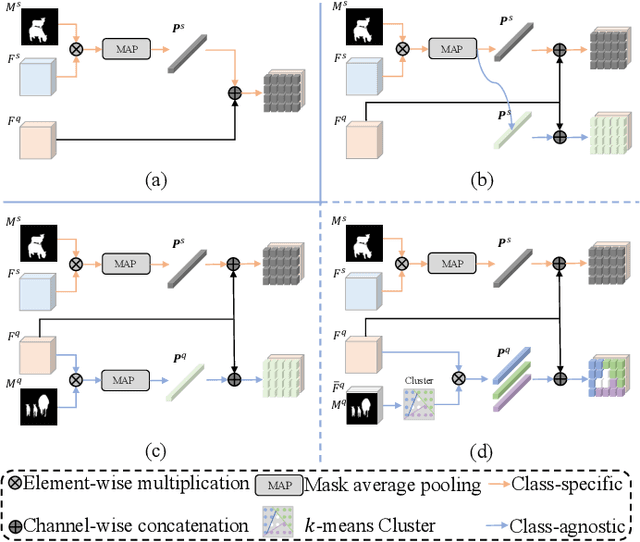
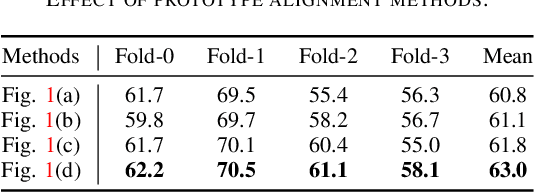

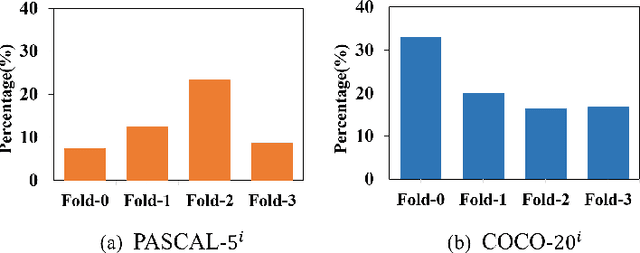
Few-shot semantic segmentation aims to segment novel-class objects in a given query image with only a few labeled support images. Most advanced solutions exploit a metric learning framework that performs segmentation through matching each query feature to a learned class-specific prototype. However, this framework suffers from biased classification due to incomplete feature comparisons. To address this issue, we present an adaptive prototype representation by introducing class-specific and class-agnostic prototypes and thus construct complete sample pairs for learning semantic alignment with query features. The complementary features learning manner effectively enriches feature comparison and helps yield an unbiased segmentation model in the few-shot setting. It is implemented with a two-branch end-to-end network (\ie, a class-specific branch and a class-agnostic branch), which generates prototypes and then combines query features to perform comparisons. In addition, the proposed class-agnostic branch is simple yet effective. In practice, it can adaptively generate multiple class-agnostic prototypes for query images and learn feature alignment in a self-contrastive manner. Extensive experiments on PASCAL-5$^i$ and COCO-20$^i$ demonstrate the superiority of our method. At no expense of inference efficiency, our model achieves state-of-the-art results in both 1-shot and 5-shot settings for semantic segmentation.
Image Denoising by Gaussian Patch Mixture Model and Low Rank Patches
Nov 20, 2020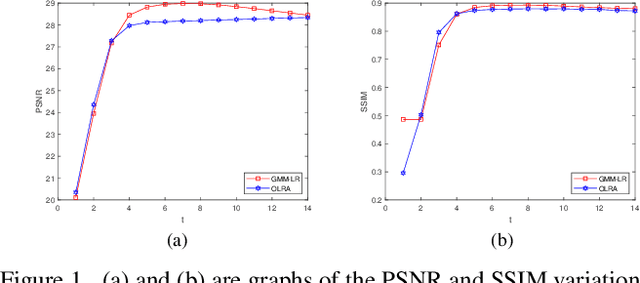

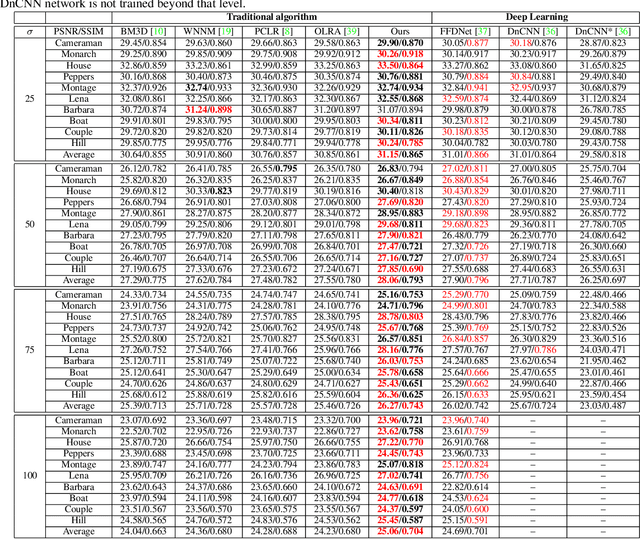
Non-local self-similarity based low rank algorithms are the state-of-the-art methods for image denoising. In this paper, a new method is proposed by solving two issues: how to improve similar patches matching accuracy and build an appropriate low rank matrix approximation model for Gaussian noise. For the first issue, similar patches can be found locally or globally. Local patch matching is to find similar patches in a large neighborhood which can alleviate noise effect, but the number of patches may be insufficient. Global patch matching is to determine enough similar patches but the error rate of patch matching may be higher. Based on this, we first use local patch matching method to reduce noise and then use Gaussian patch mixture model to achieve global patch matching. The second issue is that there is no low rank matrix approximation model to adapt to Gaussian noise. We build a new model according to the characteristics of Gaussian noise, then prove that there is a globally optimal solution of the model. By solving the two issues, experimental results are reported to show that the proposed approach outperforms the state-of-the-art denoising methods includes several deep learning ones in both PSNR / SSIM values and visual quality.
Structure-Preserving Deraining with Residue Channel Prior Guidance
Aug 20, 2021
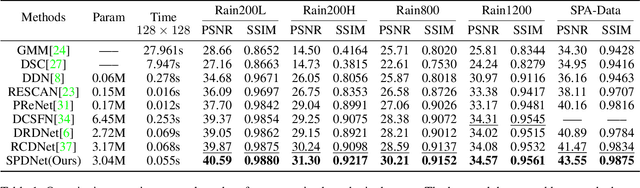


Single image deraining is important for many high-level computer vision tasks since the rain streaks can severely degrade the visibility of images, thereby affecting the recognition and analysis of the image. Recently, many CNN-based methods have been proposed for rain removal. Although these methods can remove part of the rain streaks, it is difficult for them to adapt to real-world scenarios and restore high-quality rain-free images with clear and accurate structures. To solve this problem, we propose a Structure-Preserving Deraining Network (SPDNet) with RCP guidance. SPDNet directly generates high-quality rain-free images with clear and accurate structures under the guidance of RCP but does not rely on any rain-generating assumptions. Specifically, we found that the RCP of images contains more accurate structural information than rainy images. Therefore, we introduced it to our deraining network to protect structure information of the rain-free image. Meanwhile, a Wavelet-based Multi-Level Module (WMLM) is proposed as the backbone for learning the background information of rainy images and an Interactive Fusion Module (IFM) is designed to make full use of RCP information. In addition, an iterative guidance strategy is proposed to gradually improve the accuracy of RCP, refining the result in a progressive path. Extensive experimental results on both synthetic and real-world datasets demonstrate that the proposed model achieves new state-of-the-art results. Code: https://github.com/Joyies/SPDNet
Mask Editor : an Image Annotation Tool for Image Segmentation Tasks
Sep 17, 2018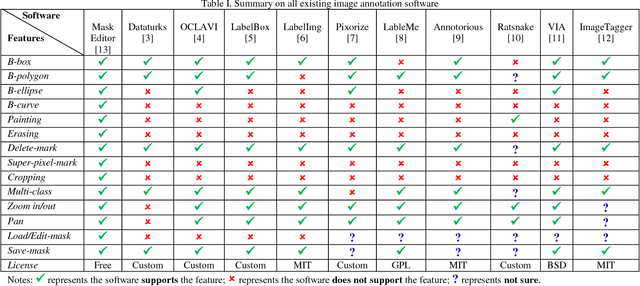
Deep convolutional neural network (DCNN) is the state-of-the-art method for image segmentation, which is one of key challenging computer vision tasks. However, DCNN requires a lot of training images with corresponding image masks to get a good segmentation result. Image annotation software which is easy to use and allows fast image mask generation is in great demand. To the best of our knowledge, all existing image annotation software support only drawing bounding polygons, bounding boxes, or bounding ellipses to mark target objects. These existing software are inefficient when targeting objects that have irregular shapes (e.g., defects in fabric images or tire images). In this paper we design an easy-to-use image annotation software called Mask Editor for image mask generation. Mask Editor allows drawing any bounding curve to mark objects and improves efficiency to mark objects with irregular shapes. Mask Editor also supports drawing bounding polygons, drawing bounding boxes, drawing bounding ellipses, painting, erasing, super-pixel-marking, image cropping, multi-class masks, mask loading, and mask modifying.
A Semantic-based Medical Image Fusion Approach
Jun 01, 2019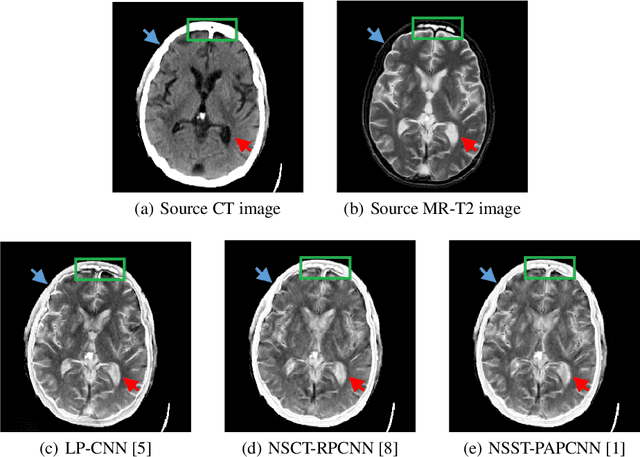
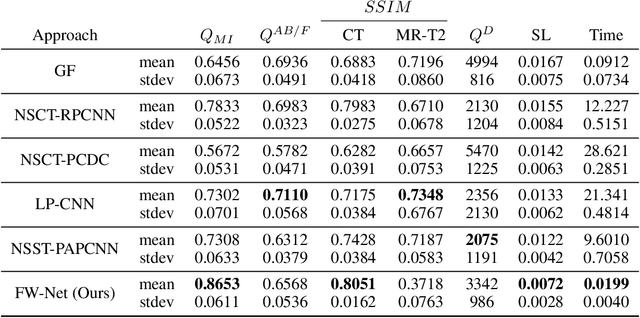
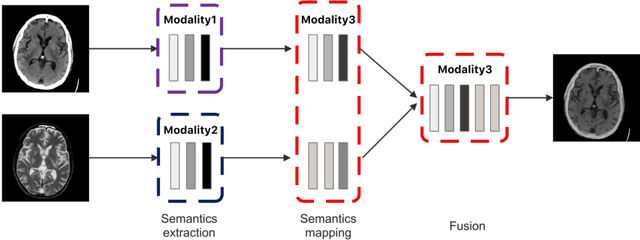
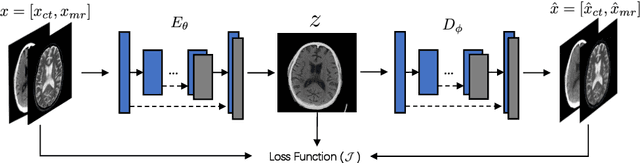
It is necessary for clinicians to comprehensively analyze patient information from different sources. Medical image fusion is a promising approach to providing overall information from medical images of different modalities. However, existing medical image fusion approaches ignore the semantics of images, making the fused image difficult to understand. In this paper, we put forward a semantic-based medical image fusion methodology, and as an implementation, we propose a Fusion W-Net (FW-Net) for multimodal medical image fusion. The experimental results are promising: the fused image generated by our approach greatly reduces the semantic information loss, and has comparable visual effects in contrast to the state-of-art approaches. Our approach and tool have great potential to be applied in the clinical setting. The source code of FW-Net is available at https://github.com/fanfanda/Medical-Image-Fusion.
Agent-Centric Relation Graph for Object Visual Navigation
Nov 29, 2021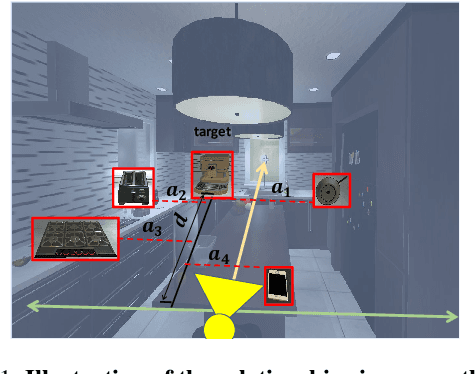
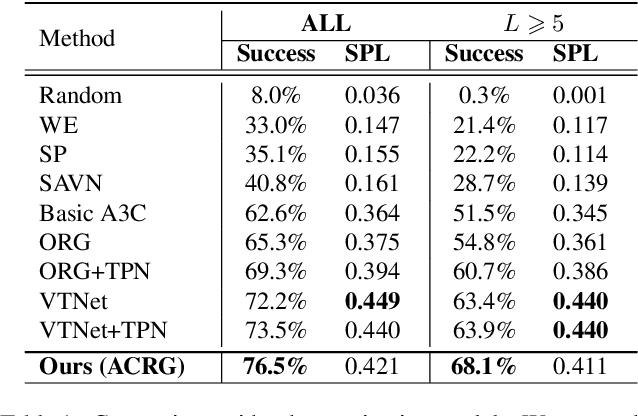
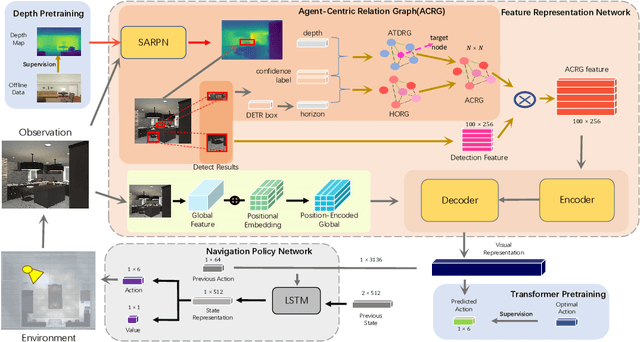
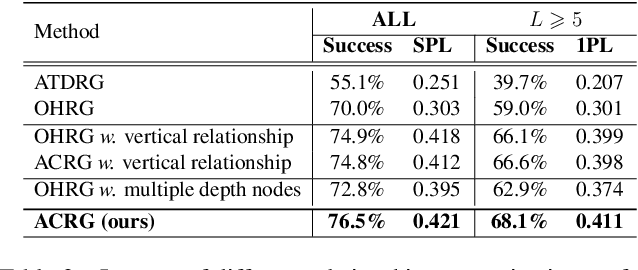
Object visual navigation aims to steer an agent towards a target object based on visual observations of the agent. It is highly desirable to reasonably perceive the environment and accurately control the agent. In the navigation task, we introduce an Agent-Centric Relation Graph (ACRG) for learning the visual representation based on the relationships in the environment. ACRG is a highly effective and reasonable structure that consists of two relationships, i.e., the relationship among objects and the relationship between the agent and the target. On the one hand, we design the Object Horizontal Relationship Graph (OHRG) that stores the relative horizontal location among objects. Note that the vertical relationship is not involved in OHRG, and we argue that OHRG is suitable for the control strategy. On the other hand, we propose the Agent-Target Depth Relationship Graph (ATDRG) that enables the agent to perceive the distance to the target. To achieve ATDRG, we utilize image depth to represent the distance. Given the above relationships, the agent can perceive the environment and output navigation actions. Given the visual representations constructed by ACRG and position-encoded global features, the agent can capture the target position to perform navigation actions. Experimental results in the artificial environment AI2-Thor demonstrate that ACRG significantly outperforms other state-of-the-art methods in unseen testing environments.
Similarity-preserving Image-image Domain Adaptation for Person Re-identification
Nov 26, 2018

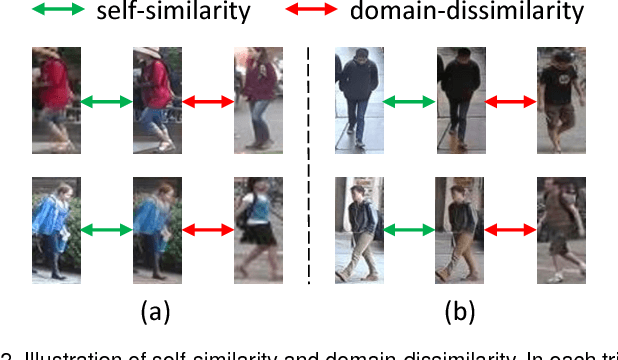

This article studies the domain adaptation problem in person re-identification (re-ID) under a "learning via translation" framework, consisting of two components, 1) translating the labeled images from the source to the target domain in an unsupervised manner, 2) learning a re-ID model using the translated images. The objective is to preserve the underlying human identity information after image translation, so that translated images with labels are effective for feature learning on the target domain. To this end, we propose a similarity preserving generative adversarial network (SPGAN) and its end-to-end trainable version, eSPGAN. Both aiming at similarity preserving, SPGAN enforces this property by heuristic constraints, while eSPGAN does so by optimally facilitating the re-ID model learning. More specifically, SPGAN separately undertakes the two components in the "learning via translation" framework. It first preserves two types of unsupervised similarity, namely, self-similarity of an image before and after translation, and domain-dissimilarity of a translated source image and a target image. It then learns a re-ID model using existing networks. In comparison, eSPGAN seamlessly integrates image translation and re-ID model learning. During the end-to-end training of eSPGAN, re-ID learning guides image translation to preserve the underlying identity information of an image. Meanwhile, image translation improves re-ID learning by providing identity-preserving training samples of the target domain style. In the experiment, we show that identities of the fake images generated by SPGAN and eSPGAN are well preserved. Based on this, we report the new state-of-the-art domain adaptation results on two large-scale person re-ID datasets.
GraN-GAN: Piecewise Gradient Normalization for Generative Adversarial Networks
Nov 04, 2021
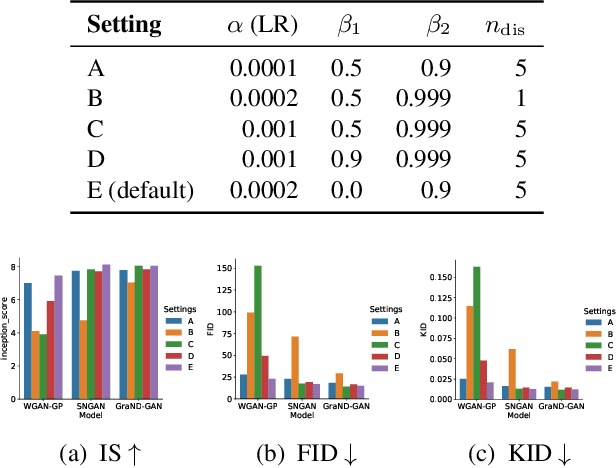
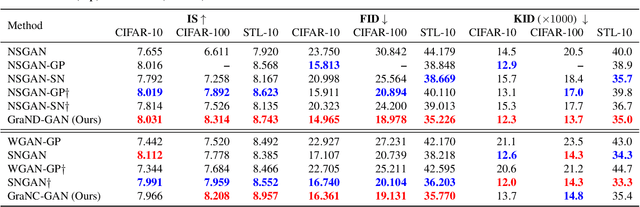
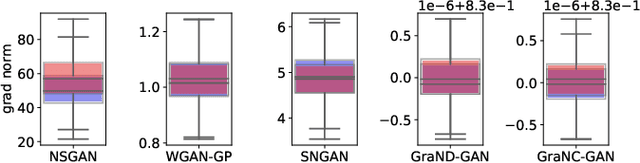
Modern generative adversarial networks (GANs) predominantly use piecewise linear activation functions in discriminators (or critics), including ReLU and LeakyReLU. Such models learn piecewise linear mappings, where each piece handles a subset of the input space, and the gradients per subset are piecewise constant. Under such a class of discriminator (or critic) functions, we present Gradient Normalization (GraN), a novel input-dependent normalization method, which guarantees a piecewise K-Lipschitz constraint in the input space. In contrast to spectral normalization, GraN does not constrain processing at the individual network layers, and, unlike gradient penalties, strictly enforces a piecewise Lipschitz constraint almost everywhere. Empirically, we demonstrate improved image generation performance across multiple datasets (incl. CIFAR-10/100, STL-10, LSUN bedrooms, and CelebA), GAN loss functions, and metrics. Further, we analyze altering the often untuned Lipschitz constant K in several standard GANs, not only attaining significant performance gains, but also finding connections between K and training dynamics, particularly in low-gradient loss plateaus, with the common Adam optimizer.