 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
On the Integration of Self-Attention and Convolution
Nov 29, 2021
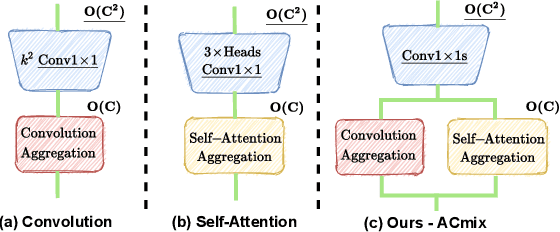
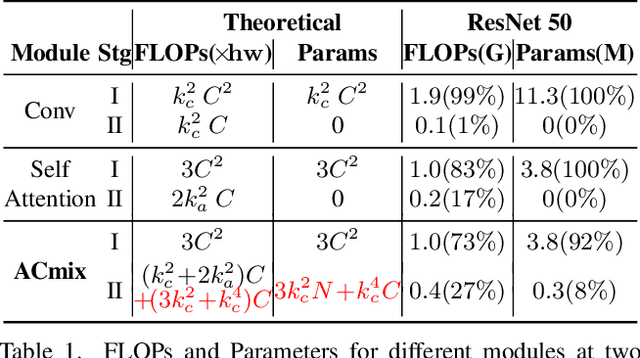
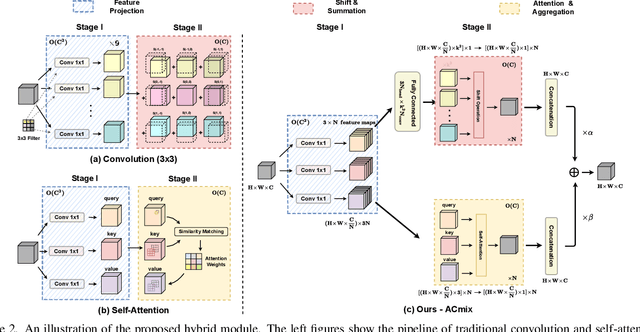
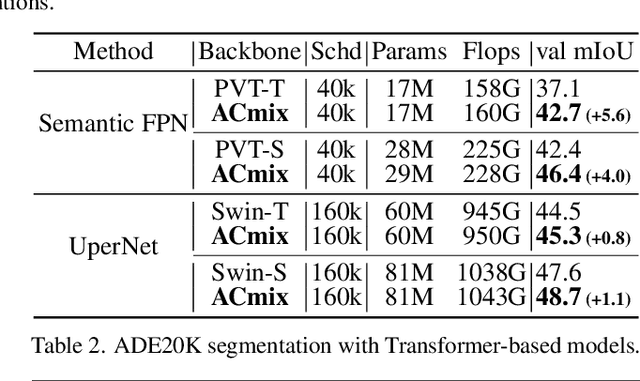
Convolution and self-attention are two powerful techniques for representation learning, and they are usually considered as two peer approaches that are distinct from each other. In this paper, we show that there exists a strong underlying relation between them, in the sense that the bulk of computations of these two paradigms are in fact done with the same operation. Specifically, we first show that a traditional convolution with kernel size k x k can be decomposed into k^2 individual 1x1 convolutions, followed by shift and summation operations. Then, we interpret the projections of queries, keys, and values in self-attention module as multiple 1x1 convolutions, followed by the computation of attention weights and aggregation of the values. Therefore, the first stage of both two modules comprises the similar operation. More importantly, the first stage contributes a dominant computation complexity (square of the channel size) comparing to the second stage. This observation naturally leads to an elegant integration of these two seemingly distinct paradigms, i.e., a mixed model that enjoys the benefit of both self-Attention and Convolution (ACmix), while having minimum computational overhead compared to the pure convolution or self-attention counterpart. Extensive experiments show that our model achieves consistently improved results over competitive baselines on image recognition and downstream tasks. Code and pre-trained models will be released at https://github.com/Panxuran/ACmix and https://gitee.com/mindspore/models.
Nonlinear Tensor Ring Network
Nov 12, 2021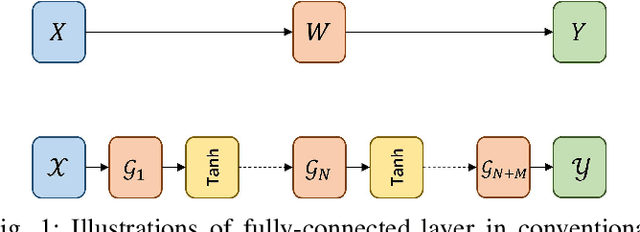
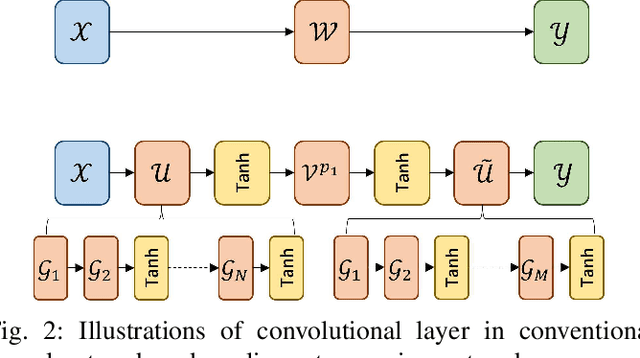
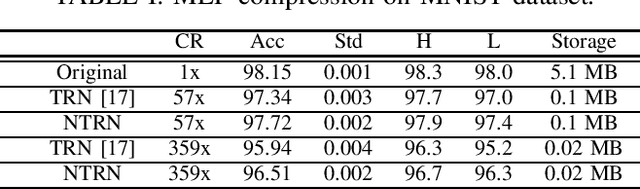
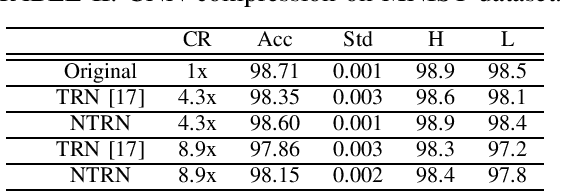
The state-of-the-art deep neural networks (DNNs) have been widely applied for various real-world applications, and achieved significant performance for cognitive problems. However, the increment of DNNs' width and depth in architecture results in a huge amount of parameters to challenge the storage and memory cost, limiting to the usage of DNNs on resource-constrained platforms, such as portable devices. By converting redundant models into compact ones, compression technique appears to be a practical solution to reducing the storage and memory consumption. In this paper, we develop a nonlinear tensor ring network (NTRN) in which both fullyconnected and convolutional layers are compressed via tensor ring decomposition. Furthermore, to mitigate the accuracy loss caused by compression, a nonlinear activation function is embedded into the tensor contraction and convolution operations inside the compressed layer. Experimental results demonstrate the effectiveness and superiority of the proposed NTRN for image classification using two basic neural networks, LeNet-5 and VGG-11 on three datasets, viz. MNIST, Fashion MNIST and Cifar-10.
Utilizing Resource-Rich Language Datasets for End-to-End Scene Text Recognition in Resource-Poor Languages
Nov 24, 2021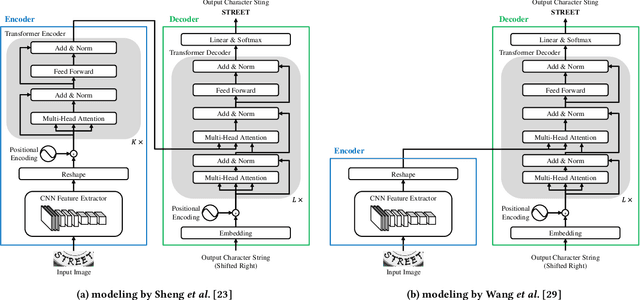
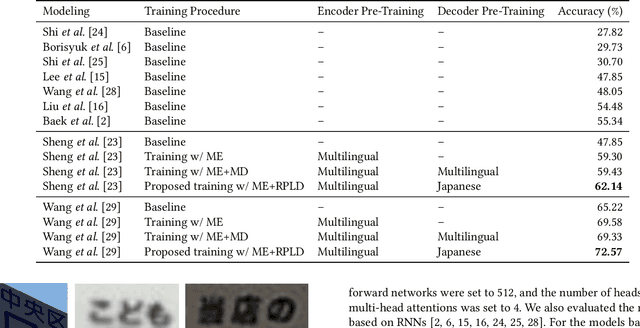
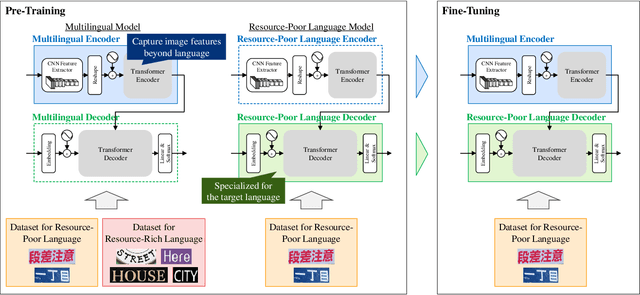
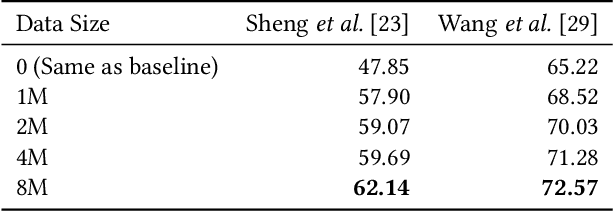
This paper presents a novel training method for end-to-end scene text recognition. End-to-end scene text recognition offers high recognition accuracy, especially when using the encoder-decoder model based on Transformer. To train a highly accurate end-to-end model, we need to prepare a large image-to-text paired dataset for the target language. However, it is difficult to collect this data, especially for resource-poor languages. To overcome this difficulty, our proposed method utilizes well-prepared large datasets in resource-rich languages such as English, to train the resource-poor encoder-decoder model. Our key idea is to build a model in which the encoder reflects knowledge of multiple languages while the decoder specializes in knowledge of just the resource-poor language. To this end, the proposed method pre-trains the encoder by using a multilingual dataset that combines the resource-poor language's dataset and the resource-rich language's dataset to learn language-invariant knowledge for scene text recognition. The proposed method also pre-trains the decoder by using the resource-poor language's dataset to make the decoder better suited to the resource-poor language. Experiments on Japanese scene text recognition using a small, publicly available dataset demonstrate the effectiveness of the proposed method.
Feature-Filter: Detecting Adversarial Examples through Filtering off Recessive Features
Jul 19, 2021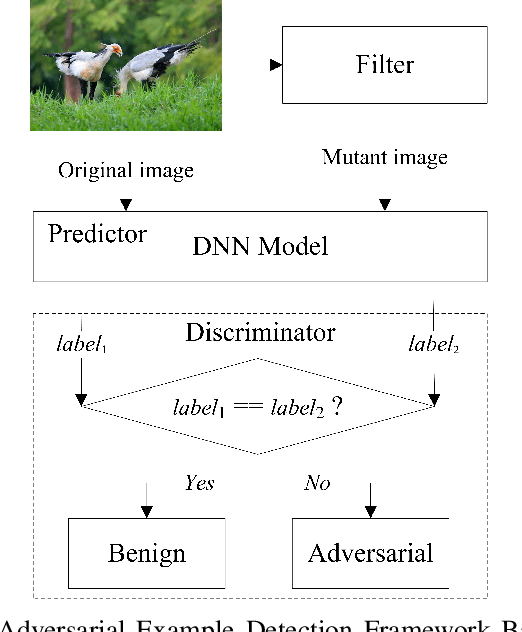

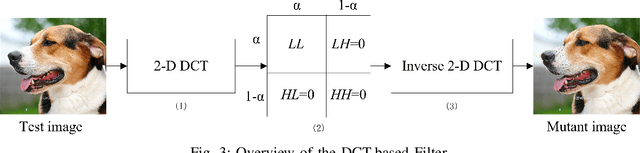

Deep neural networks (DNNs) are under threat from adversarial example attacks. The adversary can easily change the outputs of DNNs by adding small well-designed perturbations to inputs. Adversarial example detection is a fundamental work for robust DNNs-based service. Adversarial examples show the difference between humans and DNNs in image recognition. From a human-centric perspective, image features could be divided into dominant features that are comprehensible to humans, and recessive features that are incomprehensible to humans, yet are exploited by DNNs. In this paper, we reveal that imperceptible adversarial examples are the product of recessive features misleading neural networks, and an adversarial attack is essentially a kind of method to enrich these recessive features in the image. The imperceptibility of the adversarial examples indicates that the perturbations enrich recessive features, yet hardly affect dominant features. Therefore, adversarial examples are sensitive to filtering off recessive features, while benign examples are immune to such operation. Inspired by this idea, we propose a label-only adversarial detection approach that is referred to as feature-filter. Feature-filter utilizes discrete cosine transform to approximately separate recessive features from dominant features, and gets a mutant image that is filtered off recessive features. By only comparing DNN's prediction labels on the input and its mutant, feature-filter can real-time detect imperceptible adversarial examples at high accuracy and few false positives.
UIT-ViIC: A Dataset for the First Evaluation on Vietnamese Image Captioning
Feb 01, 2020
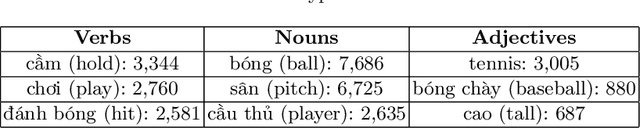
Image Captioning, the task of automatic generation of image captions, has attracted attentions from researchers in many fields of computer science, being computer vision, natural language processing and machine learning in recent years. This paper contributes to research on Image Captioning task in terms of extending dataset to a different language - Vietnamese. So far, there is no existed Image Captioning dataset for Vietnamese language, so this is the foremost fundamental step for developing Vietnamese Image Captioning. In this scope, we first build a dataset which contains manually written captions for images from Microsoft COCO dataset relating to sports played with balls, we called this dataset UIT-ViIC. UIT-ViIC consists of 19,250 Vietnamese captions for 3,850 images. Following that, we evaluate our dataset on deep neural network models and do comparisons with English dataset and two Vietnamese datasets built by different methods. UIT-ViIC is published on our lab website for research purposes.
Exploiting Robust Unsupervised Video Person Re-identification
Nov 18, 2021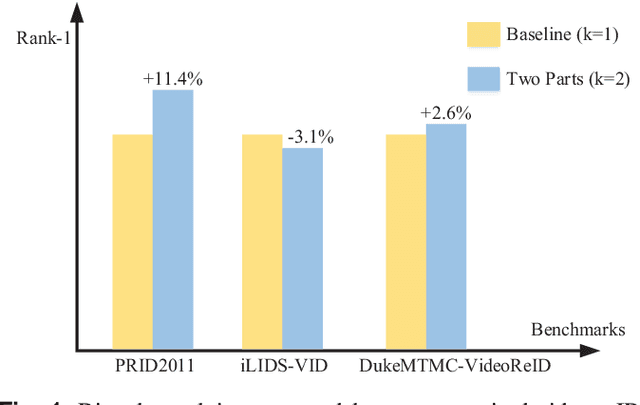
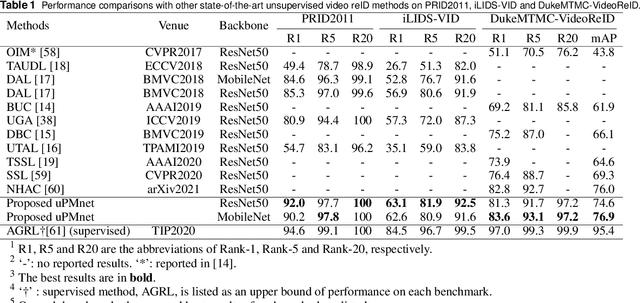


Unsupervised video person re-identification (reID) methods usually depend on global-level features. And many supervised reID methods employed local-level features and achieved significant performance improvements. However, applying local-level features to unsupervised methods may introduce an unstable performance. To improve the performance stability for unsupervised video reID, this paper introduces a general scheme fusing part models and unsupervised learning. In this scheme, the global-level feature is divided into equal local-level feature. A local-aware module is employed to explore the poentials of local-level feature for unsupervised learning. A global-aware module is proposed to overcome the disadvantages of local-level features. Features from these two modules are fused to form a robust feature representation for each input image. This feature representation has the advantages of local-level feature without suffering from its disadvantages. Comprehensive experiments are conducted on three benchmarks, including PRID2011, iLIDS-VID, and DukeMTMC-VideoReID, and the results demonstrate that the proposed approach achieves state-of-the-art performance. Extensive ablation studies demonstrate the effectiveness and robustness of proposed scheme, local-aware module and global-aware module.
Learning Context-Based Non-local Entropy Modeling for Image Compression
May 10, 2020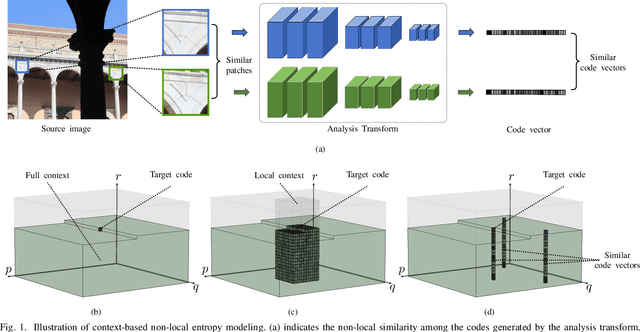
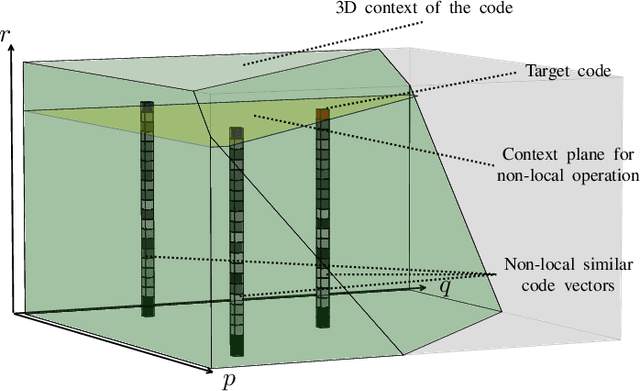
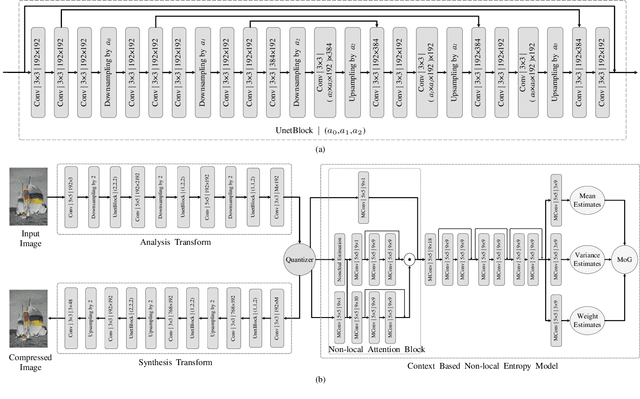
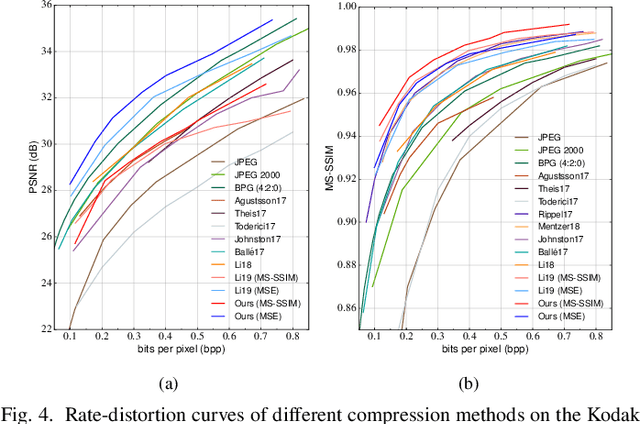
The entropy of the codes usually serves as the rate loss in the recent learned lossy image compression methods. Precise estimation of the probabilistic distribution of the codes plays a vital role in the performance. However, existing deep learning based entropy modeling methods generally assume the latent codes are statistically independent or depend on some side information or local context, which fails to take the global similarity within the context into account and thus hinder the accurate entropy estimation. To address this issue, we propose a non-local operation for context modeling by employing the global similarity within the context. Specifically, we first introduce the proxy similarity functions and spatial masks to handle the missing reference problem in context modeling. Then, we combine the local and the global context via a non-local attention block and employ it in masked convolutional networks for entropy modeling. The entropy model is further adopted as the rate loss in a joint rate-distortion optimization to guide the training of the analysis transform and the synthesis transform network in transforming coding framework. Considering that the width of the transforms is essential in training low distortion models, we finally produce a U-Net block in the transforms to increase the width with manageable memory consumption and time complexity. Experiments on Kodak and Tecnick datasets demonstrate the superiority of the proposed context-based non-local attention block in entropy modeling and the U-Net block in low distortion compression against the existing image compression standards and recent deep image compression models.
APANet: Adaptive Prototypes Alignment Network for Few-Shot Semantic Segmentation
Nov 24, 2021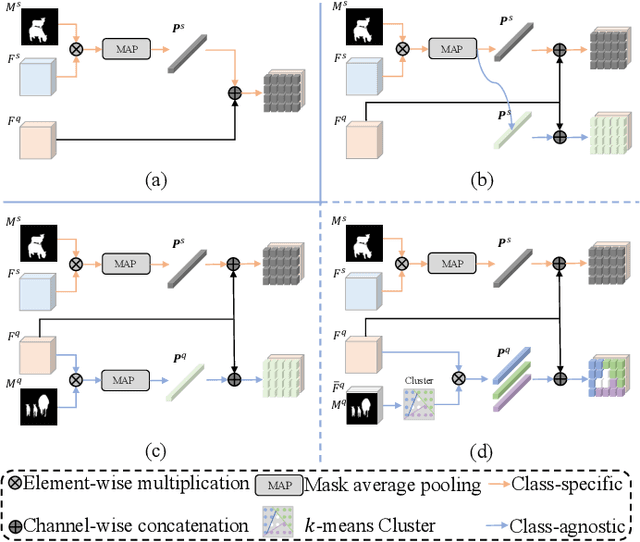
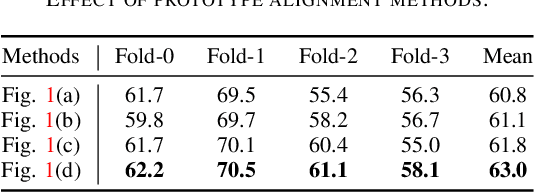

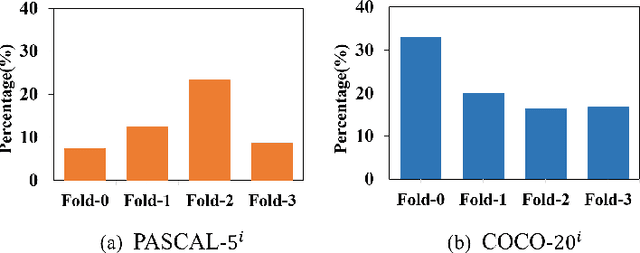
Few-shot semantic segmentation aims to segment novel-class objects in a given query image with only a few labeled support images. Most advanced solutions exploit a metric learning framework that performs segmentation through matching each query feature to a learned class-specific prototype. However, this framework suffers from biased classification due to incomplete feature comparisons. To address this issue, we present an adaptive prototype representation by introducing class-specific and class-agnostic prototypes and thus construct complete sample pairs for learning semantic alignment with query features. The complementary features learning manner effectively enriches feature comparison and helps yield an unbiased segmentation model in the few-shot setting. It is implemented with a two-branch end-to-end network (\ie, a class-specific branch and a class-agnostic branch), which generates prototypes and then combines query features to perform comparisons. In addition, the proposed class-agnostic branch is simple yet effective. In practice, it can adaptively generate multiple class-agnostic prototypes for query images and learn feature alignment in a self-contrastive manner. Extensive experiments on PASCAL-5$^i$ and COCO-20$^i$ demonstrate the superiority of our method. At no expense of inference efficiency, our model achieves state-of-the-art results in both 1-shot and 5-shot settings for semantic segmentation.
Multimodal Deep Unfolding for Guided Image Super-Resolution
Jan 21, 2020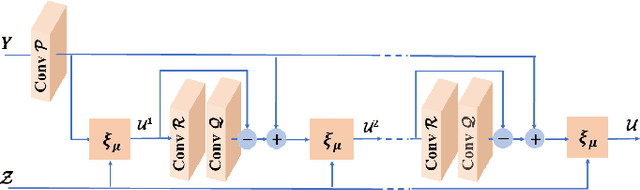
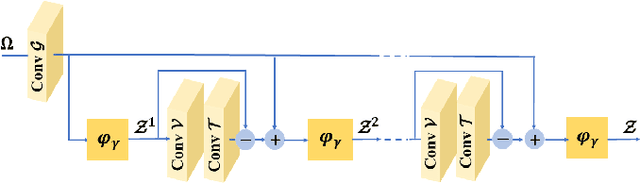
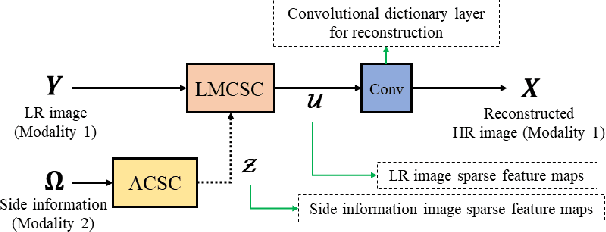
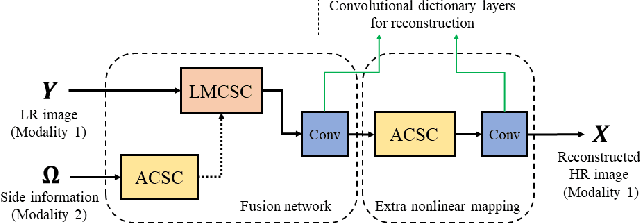
The reconstruction of a high resolution image given a low resolution observation is an ill-posed inverse problem in imaging. Deep learning methods rely on training data to learn an end-to-end mapping from a low-resolution input to a high-resolution output. Unlike existing deep multimodal models that do not incorporate domain knowledge about the problem, we propose a multimodal deep learning design that incorporates sparse priors and allows the effective integration of information from another image modality into the network architecture. Our solution relies on a novel deep unfolding operator, performing steps similar to an iterative algorithm for convolutional sparse coding with side information; therefore, the proposed neural network is interpretable by design. The deep unfolding architecture is used as a core component of a multimodal framework for guided image super-resolution. An alternative multimodal design is investigated by employing residual learning to improve the training efficiency. The presented multimodal approach is applied to super-resolution of near-infrared and multi-spectral images as well as depth upsampling using RGB images as side information. Experimental results show that our model outperforms state-of-the-art methods.
Fast whole-slide cartography in colon cancer histology using superpixels and CNN classification
Jun 30, 2021
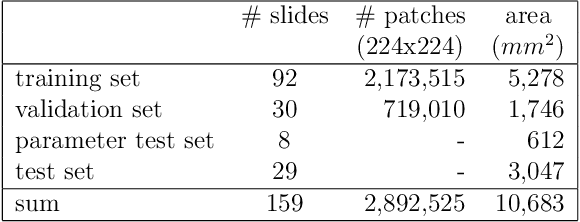
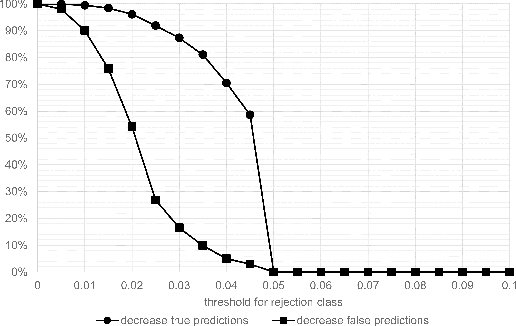
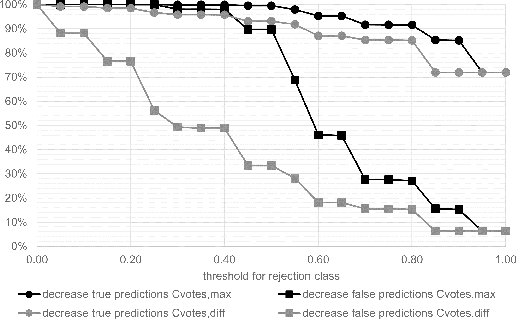
Whole-slide-image cartography is the process of automatically detecting and outlining different tissue types in digitized histological specimen. This semantic segmentation provides a basis for many follow-up analyses and can potentially guide subsequent medical decisions. Due to their large size, whole-slide-images typically have to be divided into smaller patches which are then analyzed individually using machine learning-based approaches. Thereby, local dependencies of image regions get lost and since a whole-slide-image comprises many thousands of such patches this process is inherently slow. We propose to subdivide the image into coherent regions prior to classification by grouping visually similar adjacent image pixels into larger segments, i.e. superpixels. Afterwards, only a random subset of patches per superpixel is classified and patch labels are combined into a single superpixel label. The algorithm has been developed and validated on a dataset of 159 hand-annotated whole-slide-images of colon resections and its performance has been compared to a standard patch-based approach. The algorithm shows an average speed-up of 41% on the test data and the overall accuracy is increased from 93.8% to 95.7%. We additionally propose a metric for identifying superpixels with an uncertain classification so they can be excluded from further analysis. Finally, we evaluate two potential medical applications, namely tumor area estimation including tumor invasive margin generation and tumor composition analysis.