 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Sci-Net: a Scale Invariant Model for Building Detection from Aerial Images
Nov 18, 2021
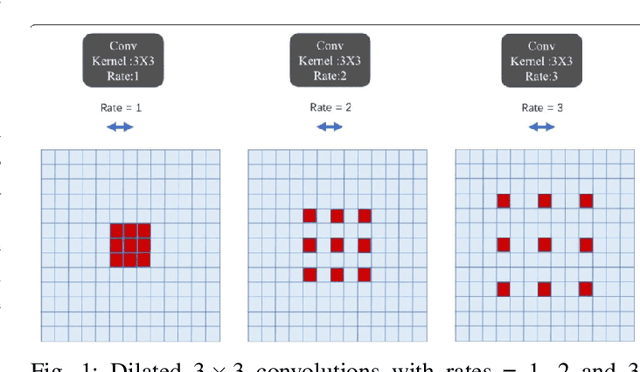
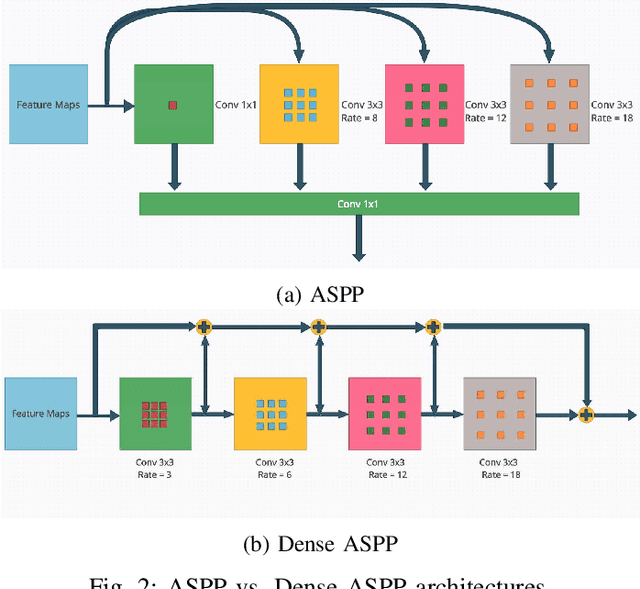
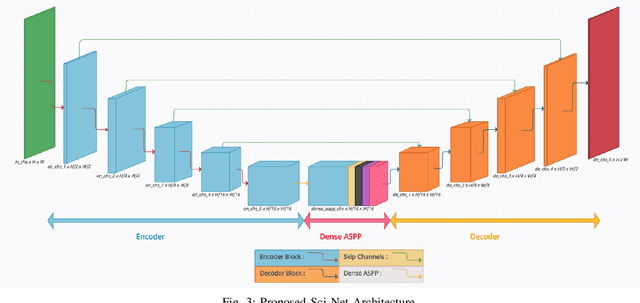
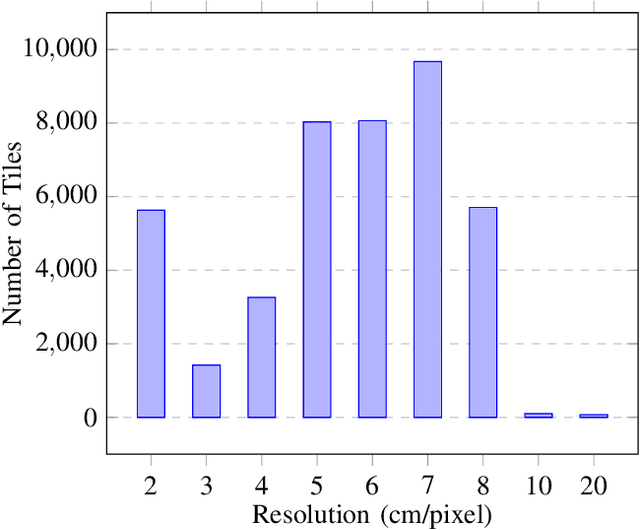
Buildings' segmentation is a fundamental task in the field of earth observation and aerial imagery analysis. Most existing deep learning based algorithms in the literature can be applied on fixed or narrow-ranged spatial resolution imagery. In practical scenarios, users deal with a wide spectrum of images resolution and thus, often need to resample a given aerial image to match the spatial resolution of the dataset used to train the deep learning model. This however, would result in a severe degradation in the quality of the output segmentation masks. To deal with this issue, we propose in this research a Scale-invariant neural network (Sci-Net) that is able to segment buildings present in aerial images at different spatial resolutions. Specifically, we modified the U-Net architecture and fused it with dense Atrous Spatial Pyramid Pooling (ASPP) to extract fine-grained multi-scale representations. We compared the performance of our proposed model against several state of the art models on the Open Cities AI dataset, and showed that Sci-Net provides a steady improvement margin in performance across all resolutions available in the dataset.
Improved Fine-tuning by Leveraging Pre-training Data: Theory and Practice
Nov 24, 2021
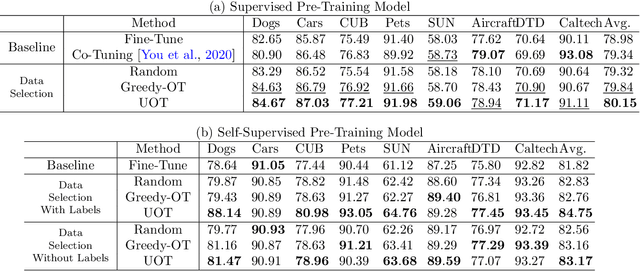
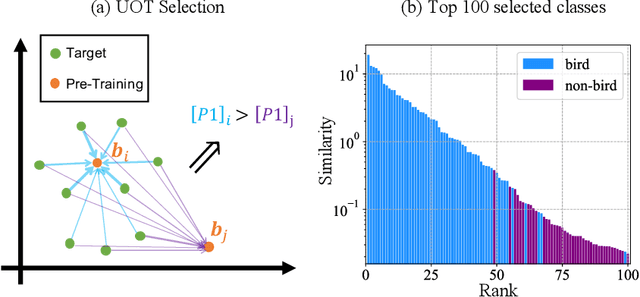

As a dominant paradigm, fine-tuning a pre-trained model on the target data is widely used in many deep learning applications, especially for small data sets. However, recent studies have empirically shown that training from scratch has the final performance that is no worse than this pre-training strategy once the number of training iterations is increased in some vision tasks. In this work, we revisit this phenomenon from the perspective of generalization analysis which is popular in learning theory. Our result reveals that the final prediction precision may have a weak dependency on the pre-trained model especially in the case of large training iterations. The observation inspires us to leverage pre-training data for fine-tuning, since this data is also available for fine-tuning. The generalization result of using pre-training data shows that the final performance on a target task can be improved when the appropriate pre-training data is included in fine-tuning. With the insight of the theoretical finding, we propose a novel selection strategy to select a subset from pre-training data to help improve the generalization on the target task. Extensive experimental results for image classification tasks on 8 benchmark data sets verify the effectiveness of the proposed data selection based fine-tuning pipeline.
Joint Calibrationless Reconstruction and Segmentation of Parallel MRI
May 19, 2021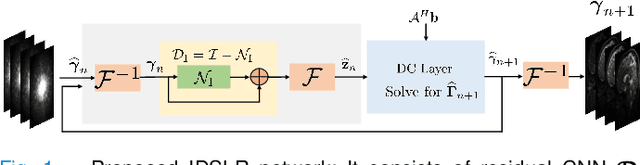
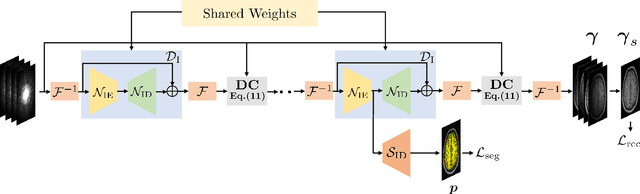
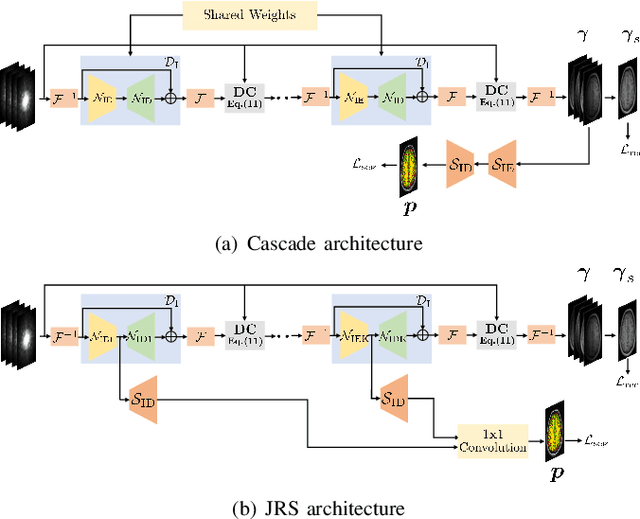
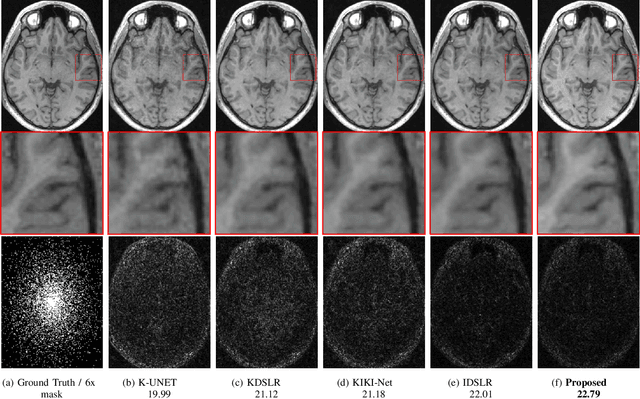
The volume estimation of brain regions from MRI data is a key problem in many clinical applications, where the acquisition of data at high spatial resolution is desirable. While parallel MRI and constrained image reconstruction algorithms can accelerate the scans, image reconstruction artifacts are inevitable, especially at high acceleration factors. We introduce a novel image domain deep-learning framework for calibrationless parallel MRI reconstruction, coupled with a segmentation network to improve image quality and to reduce the vulnerability of current segmentation algorithms to image artifacts resulting from acceleration. The combination of the proposed image domain deep calibrationless approach with the segmentation algorithm offers improved image quality, while increasing the accuracy of the segmentations. The novel architecture with an encoder shared between the reconstruction and segmentation tasks is seen to reduce the need for segmented training datasets. In particular, the proposed few-shot training strategy requires only 10% of segmented datasets to offer good performance.
Combating Noise: Semi-supervised Learning by Region Uncertainty Quantification
Nov 01, 2021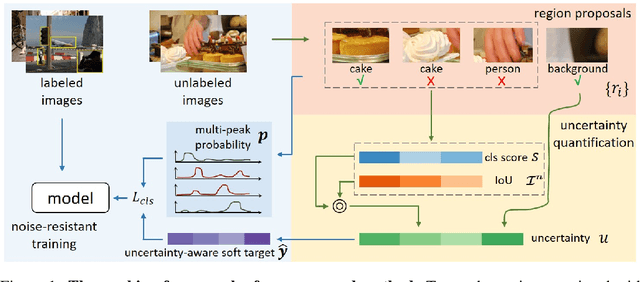
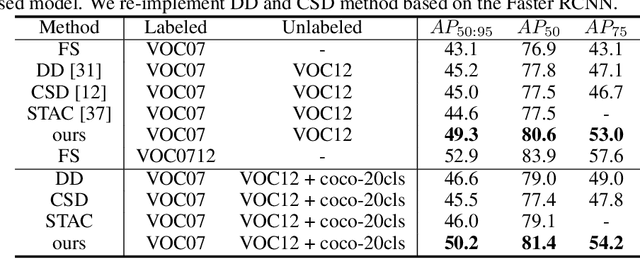
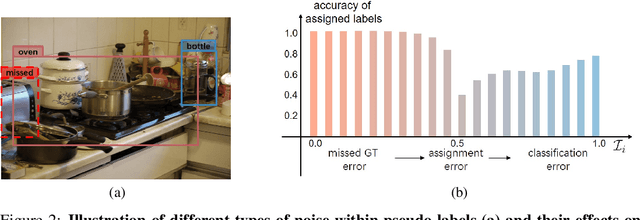
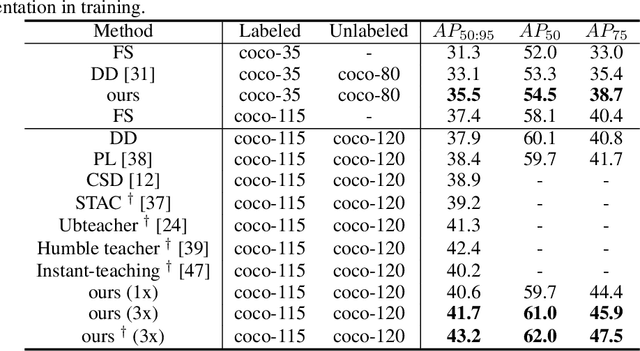
Semi-supervised learning aims to leverage a large amount of unlabeled data for performance boosting. Existing works primarily focus on image classification. In this paper, we delve into semi-supervised learning for object detection, where labeled data are more labor-intensive to collect. Current methods are easily distracted by noisy regions generated by pseudo labels. To combat the noisy labeling, we propose noise-resistant semi-supervised learning by quantifying the region uncertainty. We first investigate the adverse effects brought by different forms of noise associated with pseudo labels. Then we propose to quantify the uncertainty of regions by identifying the noise-resistant properties of regions over different strengths. By importing the region uncertainty quantification and promoting multipeak probability distribution output, we introduce uncertainty into training and further achieve noise-resistant learning. Experiments on both PASCAL VOC and MS COCO demonstrate the extraordinary performance of our method.
Utilizing Resource-Rich Language Datasets for End-to-End Scene Text Recognition in Resource-Poor Languages
Nov 24, 2021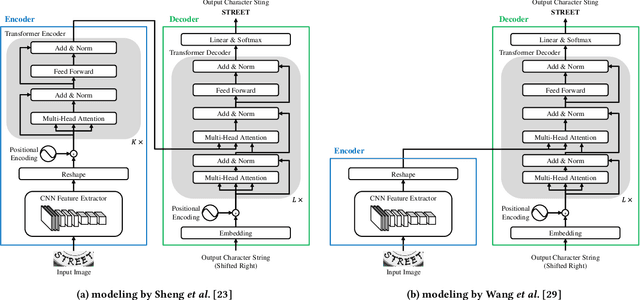
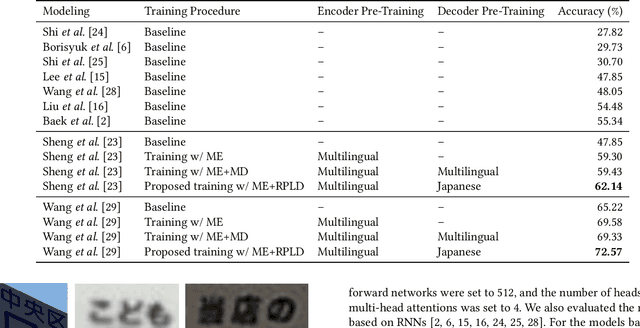
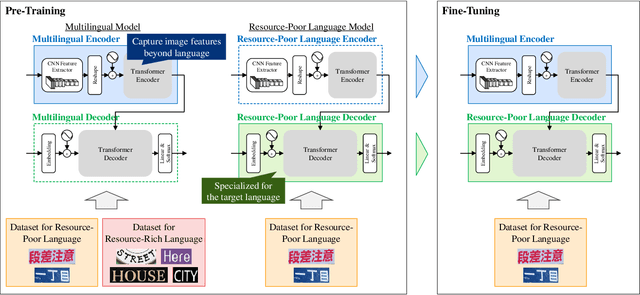
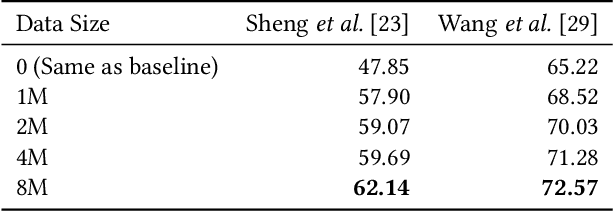
This paper presents a novel training method for end-to-end scene text recognition. End-to-end scene text recognition offers high recognition accuracy, especially when using the encoder-decoder model based on Transformer. To train a highly accurate end-to-end model, we need to prepare a large image-to-text paired dataset for the target language. However, it is difficult to collect this data, especially for resource-poor languages. To overcome this difficulty, our proposed method utilizes well-prepared large datasets in resource-rich languages such as English, to train the resource-poor encoder-decoder model. Our key idea is to build a model in which the encoder reflects knowledge of multiple languages while the decoder specializes in knowledge of just the resource-poor language. To this end, the proposed method pre-trains the encoder by using a multilingual dataset that combines the resource-poor language's dataset and the resource-rich language's dataset to learn language-invariant knowledge for scene text recognition. The proposed method also pre-trains the decoder by using the resource-poor language's dataset to make the decoder better suited to the resource-poor language. Experiments on Japanese scene text recognition using a small, publicly available dataset demonstrate the effectiveness of the proposed method.
FathomNet: An underwater image training database for ocean exploration and discovery
Jul 10, 2020

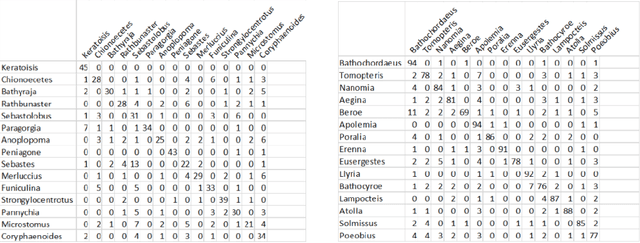

Thousands of hours of marine video data are collected annually from remotely operated vehicles (ROVs) and other underwater assets. However, current manual methods of analysis impede the full utilization of collected data for real time algorithms for ROV and large biodiversity analyses. FathomNet is a novel baseline image training set, optimized to accelerate development of modern, intelligent, and automated analysis of underwater imagery. Our seed data set consists of an expertly annotated and continuously maintained database with more than 26,000 hours of videotape, 6.8 million annotations, and 4,349 terms in the knowledge base. FathomNet leverages this data set by providing imagery, localizations, and class labels of underwater concepts in order to enable machine learning algorithm development. To date, there are more than 80,000 images and 106,000 localizations for 233 different classes, including midwater and benthic organisms. Our experiments consisted of training various deep learning algorithms with approaches to address weakly supervised localization, image labeling, object detection and classification which prove to be promising. While we find quality results on prediction for this new dataset, our results indicate that we are ultimately in need of a larger data set for ocean exploration.
APANet: Adaptive Prototypes Alignment Network for Few-Shot Semantic Segmentation
Nov 24, 2021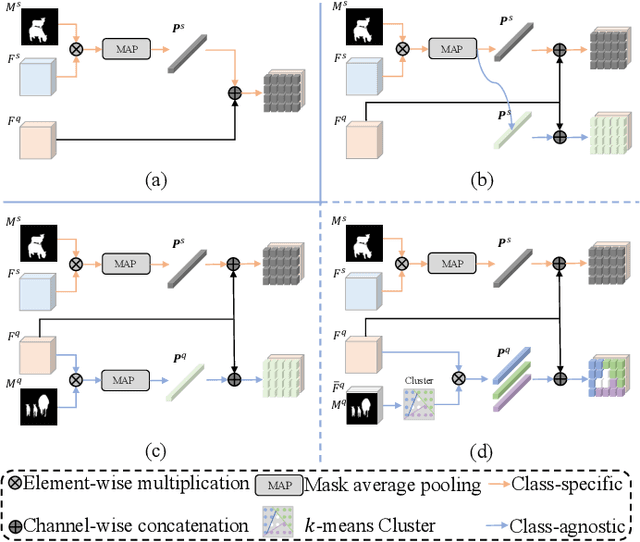
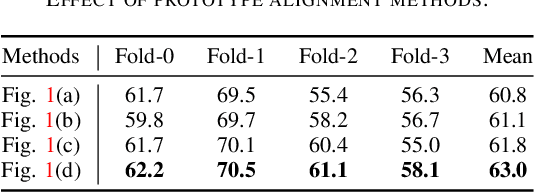

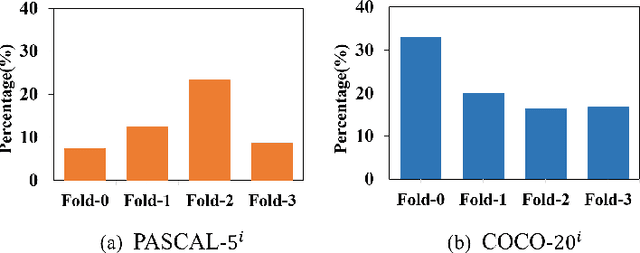
Few-shot semantic segmentation aims to segment novel-class objects in a given query image with only a few labeled support images. Most advanced solutions exploit a metric learning framework that performs segmentation through matching each query feature to a learned class-specific prototype. However, this framework suffers from biased classification due to incomplete feature comparisons. To address this issue, we present an adaptive prototype representation by introducing class-specific and class-agnostic prototypes and thus construct complete sample pairs for learning semantic alignment with query features. The complementary features learning manner effectively enriches feature comparison and helps yield an unbiased segmentation model in the few-shot setting. It is implemented with a two-branch end-to-end network (\ie, a class-specific branch and a class-agnostic branch), which generates prototypes and then combines query features to perform comparisons. In addition, the proposed class-agnostic branch is simple yet effective. In practice, it can adaptively generate multiple class-agnostic prototypes for query images and learn feature alignment in a self-contrastive manner. Extensive experiments on PASCAL-5$^i$ and COCO-20$^i$ demonstrate the superiority of our method. At no expense of inference efficiency, our model achieves state-of-the-art results in both 1-shot and 5-shot settings for semantic segmentation.
Nonlinear Tensor Ring Network
Nov 12, 2021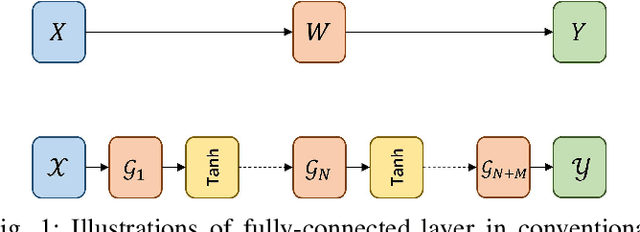
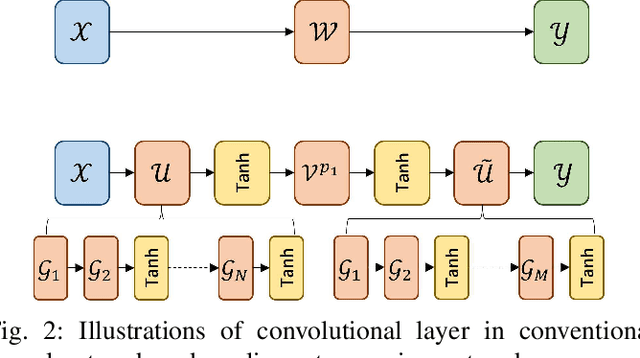
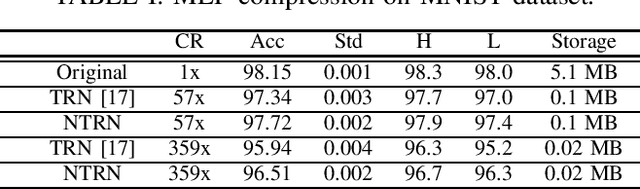
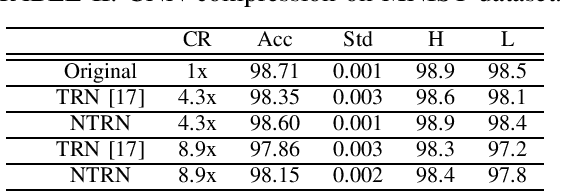
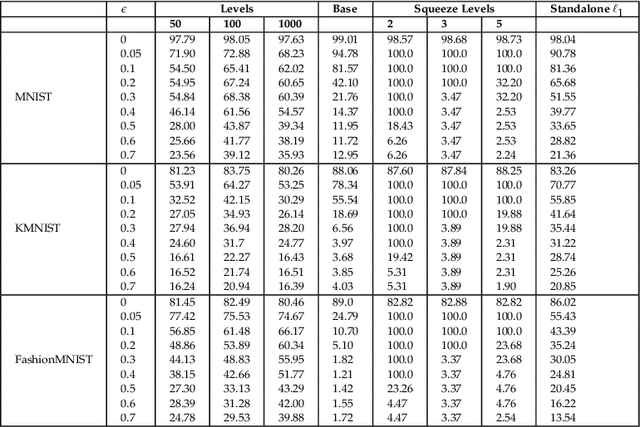
The state-of-the-art deep neural networks (DNNs) have been widely applied for various real-world applications, and achieved significant performance for cognitive problems. However, the increment of DNNs' width and depth in architecture results in a huge amount of parameters to challenge the storage and memory cost, limiting to the usage of DNNs on resource-constrained platforms, such as portable devices. By converting redundant models into compact ones, compression technique appears to be a practical solution to reducing the storage and memory consumption. In this paper, we develop a nonlinear tensor ring network (NTRN) in which both fullyconnected and convolutional layers are compressed via tensor ring decomposition. Furthermore, to mitigate the accuracy loss caused by compression, a nonlinear activation function is embedded into the tensor contraction and convolution operations inside the compressed layer. Experimental results demonstrate the effectiveness and superiority of the proposed NTRN for image classification using two basic neural networks, LeNet-5 and VGG-11 on three datasets, viz. MNIST, Fashion MNIST and Cifar-10.
The magnitude vector of images
Oct 28, 2021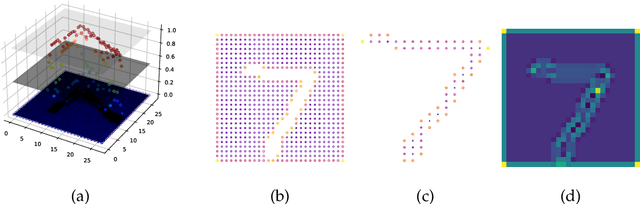

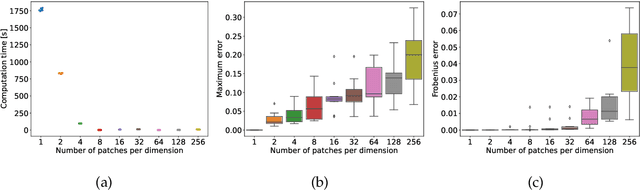
The magnitude of a finite metric space is a recently-introduced invariant quantity. Despite beneficial theoretical and practical properties, such as a general utility for outlier detection, and a close connection to Laplace radial basis kernels, magnitude has received little attention by the machine learning community so far. In this work, we investigate the properties of magnitude on individual images, with each image forming its own metric space. We show that the known properties of outlier detection translate to edge detection in images and we give supporting theoretical justifications. In addition, we provide a proof of concept of its utility by using a novel magnitude layer to defend against adversarial attacks. Since naive magnitude calculations may be computationally prohibitive, we introduce an algorithm that leverages the regular structure of images to dramatically reduce the computational cost.
Exploiting Robust Unsupervised Video Person Re-identification
Nov 18, 2021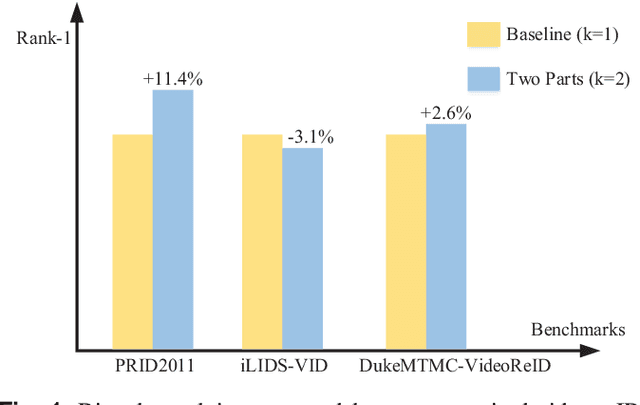
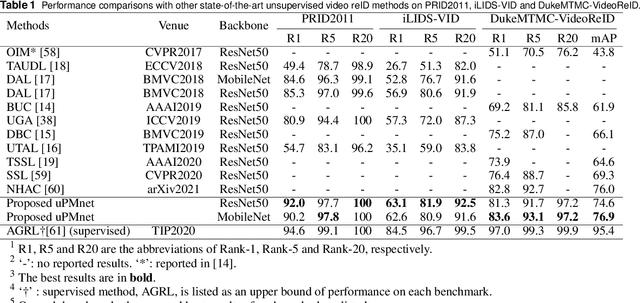


Unsupervised video person re-identification (reID) methods usually depend on global-level features. And many supervised reID methods employed local-level features and achieved significant performance improvements. However, applying local-level features to unsupervised methods may introduce an unstable performance. To improve the performance stability for unsupervised video reID, this paper introduces a general scheme fusing part models and unsupervised learning. In this scheme, the global-level feature is divided into equal local-level feature. A local-aware module is employed to explore the poentials of local-level feature for unsupervised learning. A global-aware module is proposed to overcome the disadvantages of local-level features. Features from these two modules are fused to form a robust feature representation for each input image. This feature representation has the advantages of local-level feature without suffering from its disadvantages. Comprehensive experiments are conducted on three benchmarks, including PRID2011, iLIDS-VID, and DukeMTMC-VideoReID, and the results demonstrate that the proposed approach achieves state-of-the-art performance. Extensive ablation studies demonstrate the effectiveness and robustness of proposed scheme, local-aware module and global-aware module.