 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Introducing the structural bases of typicality effects in deep learning
Jul 07, 2021
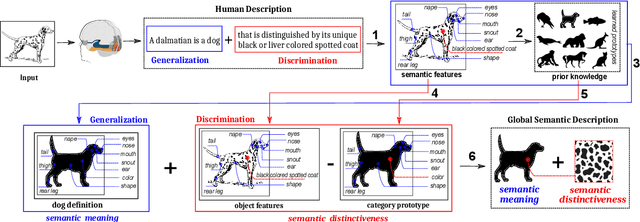
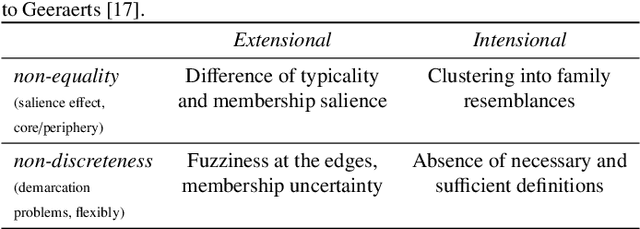
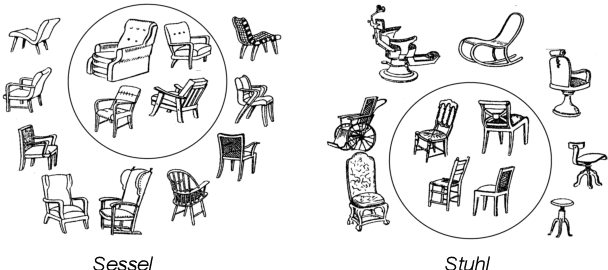
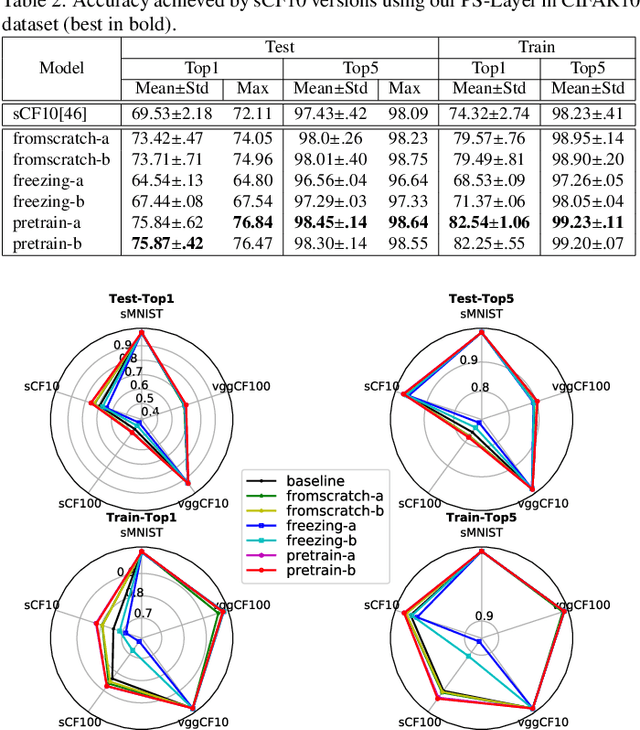
In this paper, we hypothesize that the effects of the degree of typicality in natural semantic categories can be generated based on the structure of artificial categories learned with deep learning models. Motivated by the human approach to representing natural semantic categories and based on the Prototype Theory foundations, we propose a novel Computational Prototype Model (CPM) to represent the internal structure of semantic categories. Unlike other prototype learning approaches, our mathematical framework proposes a first approach to provide deep neural networks with the ability to model abstract semantic concepts such as category central semantic meaning, typicality degree of an object's image, and family resemblance relationship. We proposed several methodologies based on the typicality's concept to evaluate our CPM-model in image semantic processing tasks such as image classification, a global semantic description, and transfer learning. Our experiments on different image datasets, such as ImageNet and Coco, showed that our approach might be an admissible proposition in the effort to endow machines with greater power of abstraction for the semantic representation of objects' categories.
A high performance fingerprint liveness detection method based on quality related features
Nov 02, 2021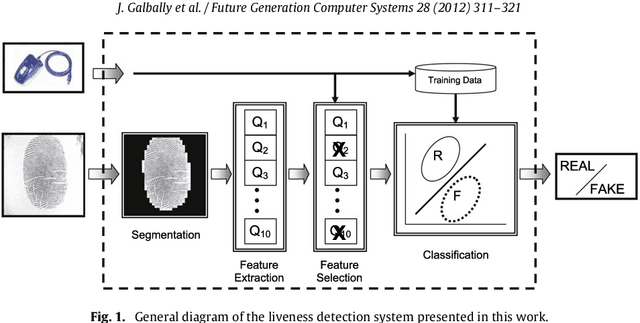
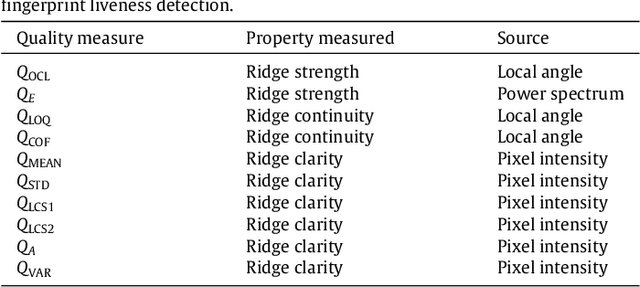


A new software-based liveness detection approach using a novel fingerprint parameterization based on quality related features is proposed. The system is tested on a highly challenging database comprising over 10,500 real and fake images acquired with five sensors of different technologies and covering a wide range of direct attack scenarios in terms of materials and procedures followed to generate the gummy fingers. The proposed solution proves to be robust to the multi-scenario dataset, and presents an overall rate of 90% correctly classified samples. Furthermore, the liveness detection method presented has the added advantage over previously studied techniques of needing just one image from a finger to decide whether it is real or fake. This last characteristic provides the method with very valuable features as it makes it less intrusive, more user friendly, faster and reduces its implementation costs.
Unsupervised High-Fidelity Facial Texture Generation and Reconstruction
Oct 10, 2021
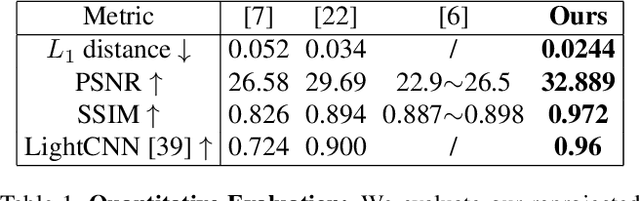
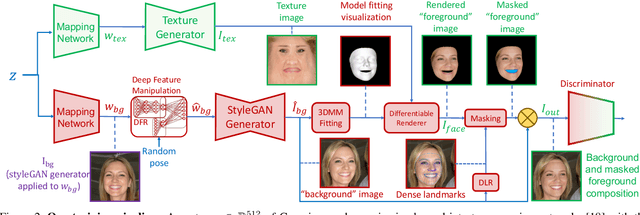

Many methods have been proposed over the years to tackle the task of facial 3D geometry and texture recovery from a single image. Such methods often fail to provide high-fidelity texture without relying on 3D facial scans during training. In contrast, the complementary task of 3D facial generation has not received as much attention. As opposed to the 2D texture domain, where GANs have proven to produce highly realistic facial images, the more challenging 3D geometry domain has not yet caught up to the same levels of realism and diversity. In this paper, we propose a novel unified pipeline for both tasks, generation of both geometry and texture, and recovery of high-fidelity texture. Our texture model is learned, in an unsupervised fashion, from natural images as opposed to scanned texture maps. To the best of our knowledge, this is the first such unified framework independent of scanned textures. Our novel training pipeline incorporates a pre-trained 2D facial generator coupled with a deep feature manipulation methodology. By applying precise 3DMM fitting, we can seamlessly integrate our modeled textures into synthetically generated background images forming a realistic composition of our textured model with background, hair, teeth, and body. This enables us to apply transfer learning from the domain of 2D image generation, thus, benefiting greatly from the impressive results obtained in this domain. We provide a comprehensive study on several recent methods comparing our model in generation and reconstruction tasks. As the extensive qualitative, as well as quantitative analysis, demonstrate, we achieve state-of-the-art results for both tasks.
Poison Ink: Robust and Invisible Backdoor Attack
Aug 14, 2021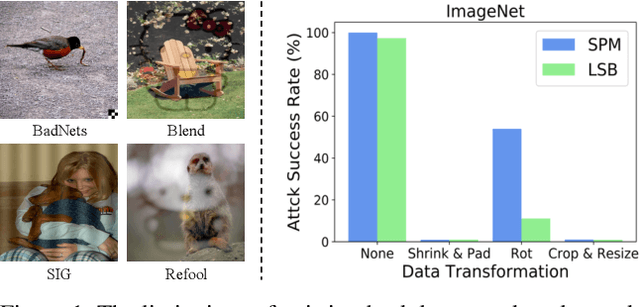
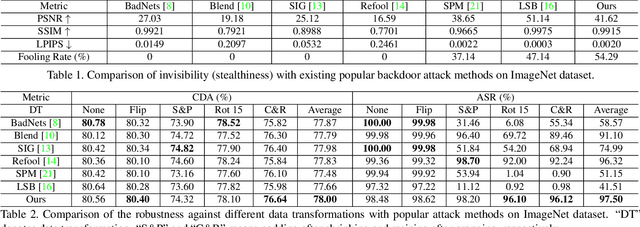
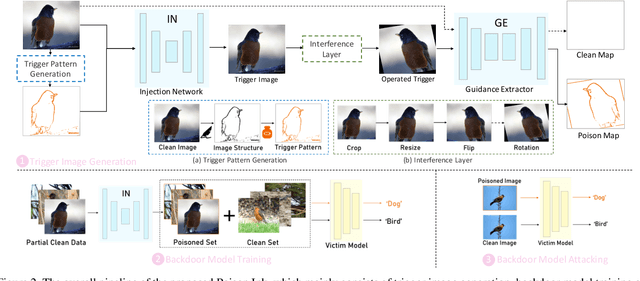

Recent research shows deep neural networks are vulnerable to different types of attacks, such as adversarial attack, data poisoning attack and backdoor attack. Among them, backdoor attack is the most cunning one and can occur in almost every stage of deep learning pipeline. Therefore, backdoor attack has attracted lots of interests from both academia and industry. However, most existing backdoor attack methods are either visible or fragile to some effortless pre-processing such as common data transformations. To address these limitations, we propose a robust and invisible backdoor attack called "Poison Ink". Concretely, we first leverage the image structures as target poisoning areas, and fill them with poison ink (information) to generate the trigger pattern. As the image structure can keep its semantic meaning during the data transformation, such trigger pattern is inherently robust to data transformations. Then we leverage a deep injection network to embed such trigger pattern into the cover image to achieve stealthiness. Compared to existing popular backdoor attack methods, Poison Ink outperforms both in stealthiness and robustness. Through extensive experiments, we demonstrate Poison Ink is not only general to different datasets and network architectures, but also flexible for different attack scenarios. Besides, it also has very strong resistance against many state-of-the-art defense techniques.
Neural Fields in Visual Computing and Beyond
Nov 29, 2021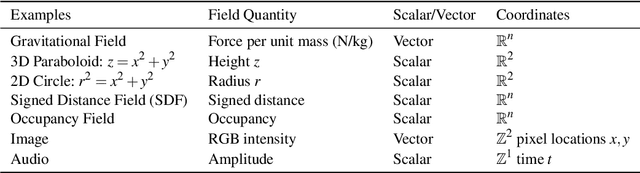
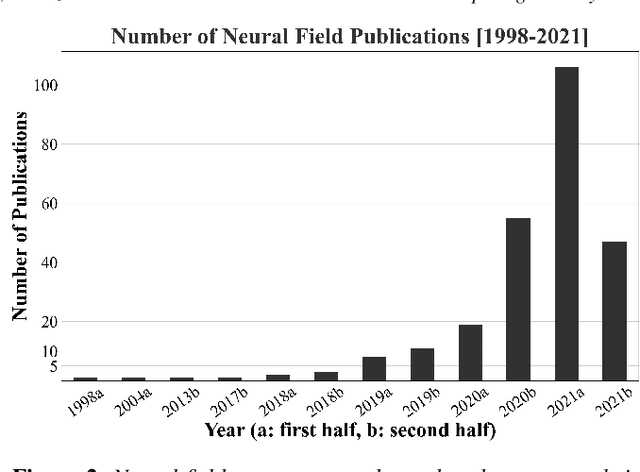

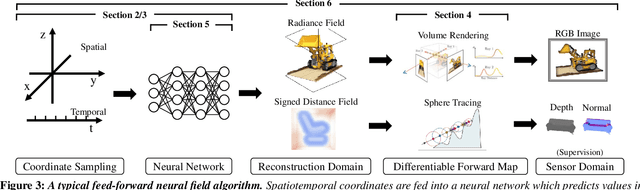
Recent advances in machine learning have created increasing interest in solving visual computing problems using a class of coordinate-based neural networks that parametrize physical properties of scenes or objects across space and time. These methods, which we call neural fields, have seen successful application in the synthesis of 3D shapes and image, animation of human bodies, 3D reconstruction, and pose estimation. However, due to rapid progress in a short time, many papers exist but a comprehensive review and formulation of the problem has not yet emerged. In this report, we address this limitation by providing context, mathematical grounding, and an extensive review of literature on neural fields. This report covers research along two dimensions. In Part I, we focus on techniques in neural fields by identifying common components of neural field methods, including different representations, architectures, forward mapping, and generalization methods. In Part II, we focus on applications of neural fields to different problems in visual computing, and beyond (e.g., robotics, audio). Our review shows the breadth of topics already covered in visual computing, both historically and in current incarnations, demonstrating the improved quality, flexibility, and capability brought by neural fields methods. Finally, we present a companion website that contributes a living version of this review that can be continually updated by the community.
Coherent Reconstruction of Multiple Humans from a Single Image
Jun 15, 2020
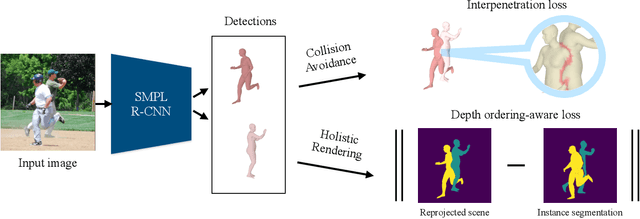
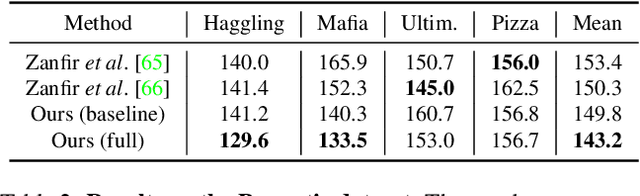
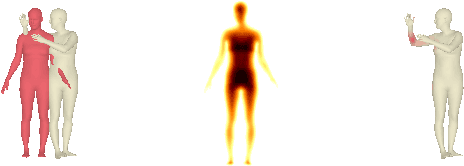
In this work, we address the problem of multi-person 3D pose estimation from a single image. A typical regression approach in the top-down setting of this problem would first detect all humans and then reconstruct each one of them independently. However, this type of prediction suffers from incoherent results, e.g., interpenetration and inconsistent depth ordering between the people in the scene. Our goal is to train a single network that learns to avoid these problems and generate a coherent 3D reconstruction of all the humans in the scene. To this end, a key design choice is the incorporation of the SMPL parametric body model in our top-down framework, which enables the use of two novel losses. First, a distance field-based collision loss penalizes interpenetration among the reconstructed people. Second, a depth ordering-aware loss reasons about occlusions and promotes a depth ordering of people that leads to a rendering which is consistent with the annotated instance segmentation. This provides depth supervision signals to the network, even if the image has no explicit 3D annotations. The experiments show that our approach outperforms previous methods on standard 3D pose benchmarks, while our proposed losses enable more coherent reconstruction in natural images. The project website with videos, results, and code can be found at: https://jiangwenpl.github.io/multiperson
FabricFlowNet: Bimanual Cloth Manipulation with a Flow-based Policy
Nov 10, 2021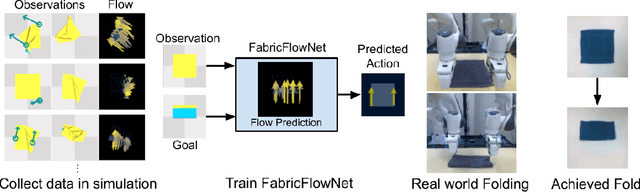

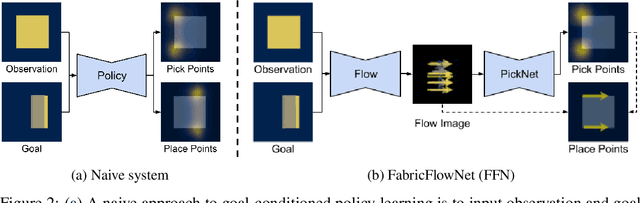

We address the problem of goal-directed cloth manipulation, a challenging task due to the deformability of cloth. Our insight is that optical flow, a technique normally used for motion estimation in video, can also provide an effective representation for corresponding cloth poses across observation and goal images. We introduce FabricFlowNet (FFN), a cloth manipulation policy that leverages flow as both an input and as an action representation to improve performance. FabricFlowNet also elegantly switches between bimanual and single-arm actions based on the desired goal. We show that FabricFlowNet significantly outperforms state-of-the-art model-free and model-based cloth manipulation policies that take image input. We also present real-world experiments on a bimanual system, demonstrating effective sim-to-real transfer. Finally, we show that our method generalizes when trained on a single square cloth to other cloth shapes, such as T-shirts and rectangular cloths. Video and other supplementary materials are available at: https://sites.google.com/view/fabricflownet.
Low-resource Learning with Knowledge Graphs: A Comprehensive Survey
Dec 22, 2021
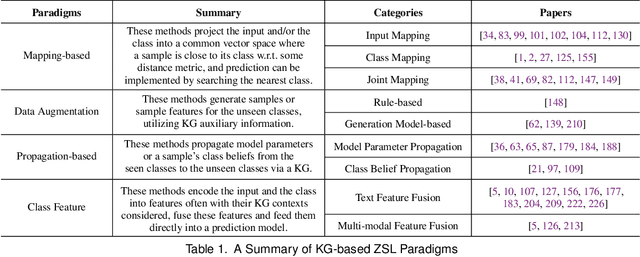
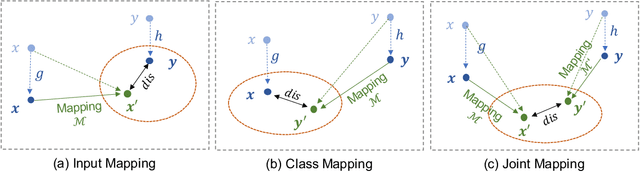
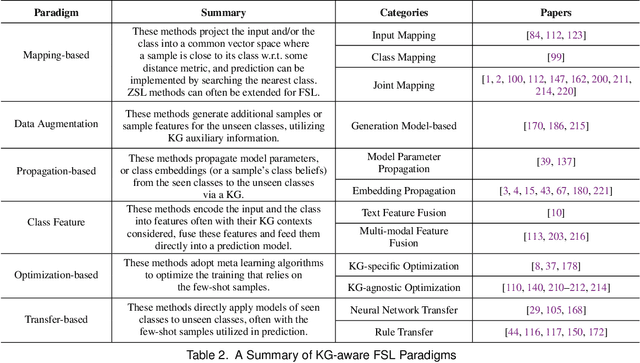
Machine learning methods especially deep neural networks have achieved great success but many of them often rely on a number of labeled samples for training. In real-world applications, we often need to address sample shortage due to e.g., dynamic contexts with emerging prediction targets and costly sample annotation. Therefore, low-resource learning, which aims to learn robust prediction models with no enough resources (especially training samples), is now being widely investigated. Among all the low-resource learning studies, many prefer to utilize some auxiliary information in the form of Knowledge Graph (KG), which is becoming more and more popular for knowledge representation, to reduce the reliance on labeled samples. In this survey, we very comprehensively reviewed over $90$ papers about KG-aware research for two major low-resource learning settings -- zero-shot learning (ZSL) where new classes for prediction have never appeared in training, and few-shot learning (FSL) where new classes for prediction have only a small number of labeled samples that are available. We first introduced the KGs used in ZSL and FSL studies as well as the existing and potential KG construction solutions, and then systematically categorized and summarized KG-aware ZSL and FSL methods, dividing them into different paradigms such as the mapping-based, the data augmentation, the propagation-based and the optimization-based. We next presented different applications, including not only KG augmented tasks in Computer Vision and Natural Language Processing (e.g., image classification, text classification and knowledge extraction), but also tasks for KG curation (e.g., inductive KG completion), and some typical evaluation resources for each task. We eventually discussed some challenges and future directions on aspects such as new learning and reasoning paradigms, and the construction of high quality KGs.
Visual Commonsense Graphs: Reasoning about the Dynamic Context of a Still Image
Apr 22, 2020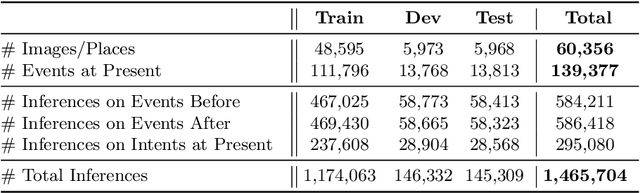
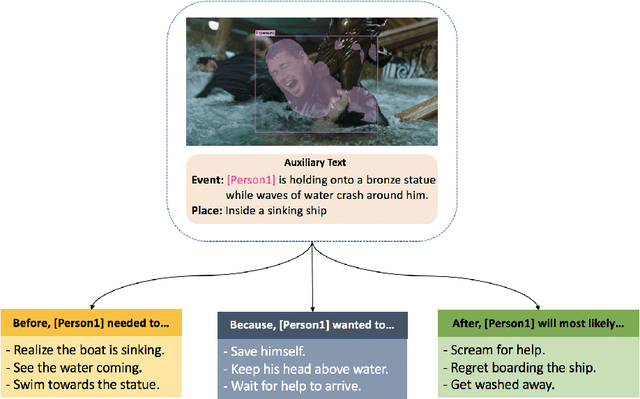
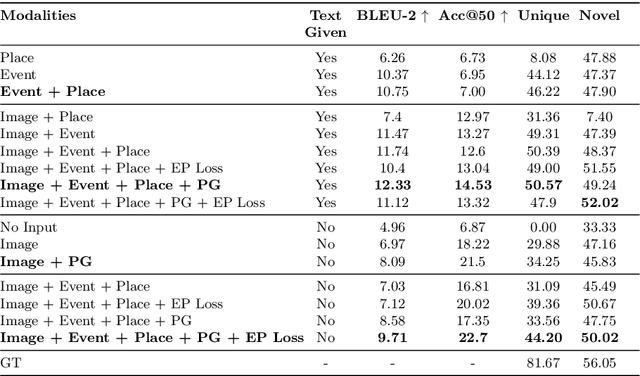

Even from a single frame of a still image, people can reason about the dynamic story of the image before, after, and beyond the frame. For example, given an image of a man struggling to stay afloat in water, we can reason that the man fell into the water sometime in the past, the intent of that man at the moment is to stay alive, and he will need help in the near future or else he will get washed away. We propose VisualComet, the novel framework of visual commonsense reasoning tasks to predict events that might have happened before, events that might happen next, and the intents of the people at present. To support research toward visual commonsense reasoning, we introduce the first large-scale repository of Visual Commonsense Graphs that consists of over 1.4 million textual descriptions of visual commonsense inferences carefully annotated over a diverse set of 60,000 images, each paired with short video summaries of before and after. In addition, we provide person-grounding (i.e., co-reference links) between people appearing in the image and people mentioned in the textual commonsense descriptions, allowing for tighter integration between images and text. We establish strong baseline performances on this task and demonstrate that integration between visual and textual commonsense reasoning is the key and wins over non-integrative alternatives.
A Review of Web Infodemic Analysis and Detection Trends across Multi-modalities using Deep Neural Networks
Nov 23, 2021
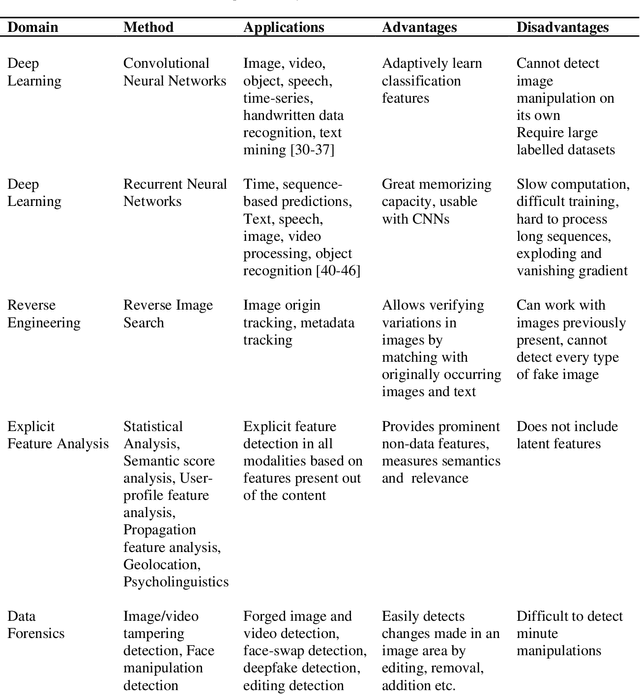

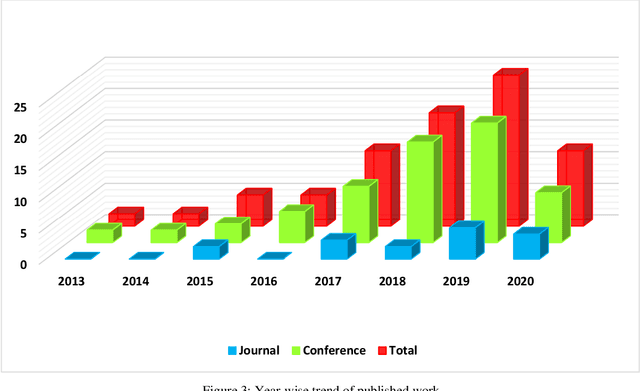
Fake news and misinformation are a matter of concern for people around the globe. Users of the internet and social media sites encounter content with false information much frequently. Fake news detection is one of the most analyzed and prominent areas of research. These detection techniques apply popular machine learning and deep learning algorithms. Previous work in this domain covers fake news detection vastly among text circulating online. Platforms that have extensively been observed and analyzed include news websites and Twitter. Facebook, Reddit, WhatsApp, YouTube, and other social applications are gradually gaining attention in this emerging field. Researchers are analyzing online data based on multiple modalities composed of text, image, video, speech, and other contributing factors. The combination of various modalities has resulted in efficient fake news detection. At present, there is an abundance of surveys consolidating textual fake news detection algorithms. This review primarily deals with multi-modal fake news detection techniques that include images, videos, and their combinations with text. We provide a comprehensive literature survey of eighty articles presenting state-of-the-art detection techniques, thereby identifying research gaps and building a pathway for researchers to further advance this domain.