 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
On the Effect of Selfie Beautification Filters on Face Detection and Recognition
Oct 17, 2021

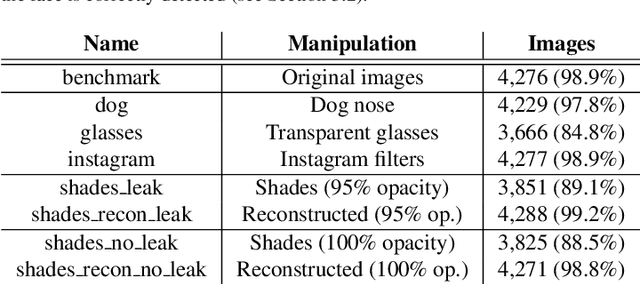

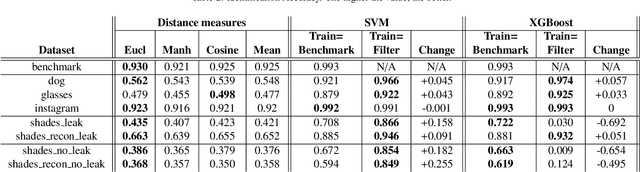
Beautification and augmented reality filters are very popular in applications that use selfie images captured with smartphones or personal devices. However, they can distort or modify biometric features, severely affecting the capability of recognizing individuals' identity or even detecting the face. Accordingly, we address the effect of such filters on the accuracy of automated face detection and recognition. The social media image filters studied either modify the image contrast or illumination or occlude parts of the face with for example artificial glasses or animal noses. We observe that the effect of some of these filters is harmful both to face detection and identity recognition, specially if they obfuscate the eye or (to a lesser extent) the nose. To counteract such effect, we develop a method to reconstruct the applied manipulation with a modified version of the U-NET segmentation network. This is observed to contribute to a better face detection and recognition accuracy. From a recognition perspective, we employ distance measures and trained machine learning algorithms applied to features extracted using a ResNet-34 network trained to recognize faces. We also evaluate if incorporating filtered images to the training set of machine learning approaches are beneficial for identity recognition. Our results show good recognition when filters do not occlude important landmarks, specially the eyes (identification accuracy >99%, EER<2%). The combined effect of the proposed approaches also allow to mitigate the effect produced by filters that occlude parts of the face, achieving an identification accuracy of >92% with the majority of perturbations evaluated, and an EER <8%. Although there is room for improvement, when neither U-NET reconstruction nor training with filtered images is applied, the accuracy with filters that severely occlude the eye is <72% (identification) and >12% (EER)
Dual-level Semantic Transfer Deep Hashing for Efficient Social Image Retrieval
Jun 10, 2020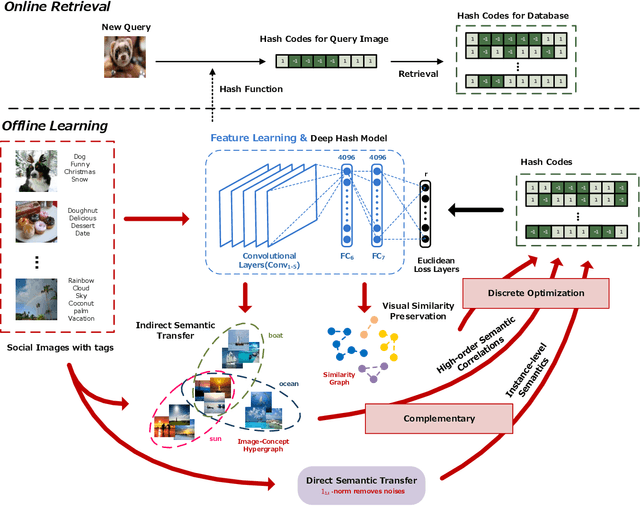
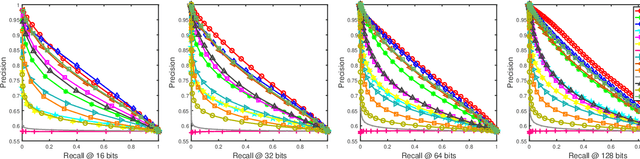
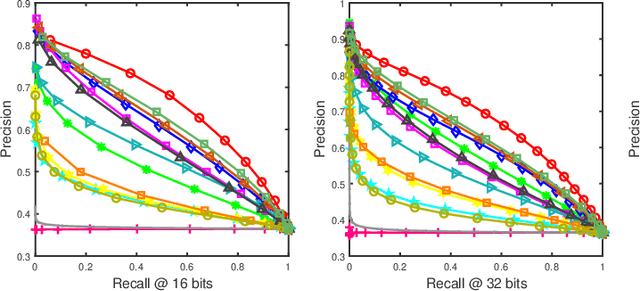
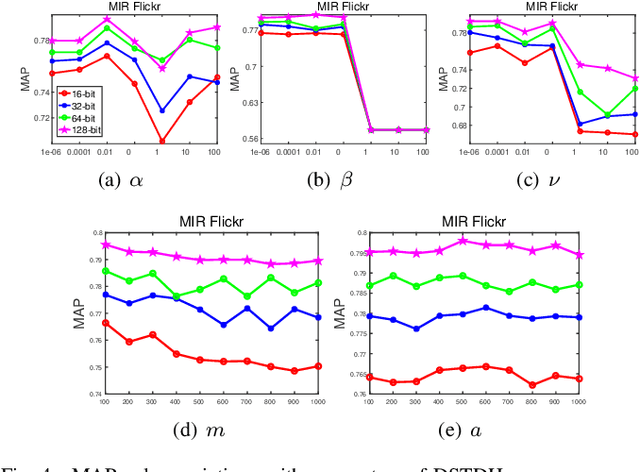
Social network stores and disseminates a tremendous amount of user shared images. Deep hashing is an efficient indexing technique to support large-scale social image retrieval, due to its deep representation capability, fast retrieval speed and low storage cost. Particularly, unsupervised deep hashing has well scalability as it does not require any manually labelled data for training. However, owing to the lacking of label guidance, existing methods suffer from severe semantic shortage when optimizing a large amount of deep neural network parameters. Differently, in this paper, we propose a Dual-level Semantic Transfer Deep Hashing (DSTDH) method to alleviate this problem with a unified deep hash learning framework. Our model targets at learning the semantically enhanced deep hash codes by specially exploiting the user-generated tags associated with the social images. Specifically, we design a complementary dual-level semantic transfer mechanism to efficiently discover the potential semantics of tags and seamlessly transfer them into binary hash codes. On the one hand, instance-level semantics are directly preserved into hash codes from the associated tags with adverse noise removing. Besides, an image-concept hypergraph is constructed for indirectly transferring the latent high-order semantic correlations of images and tags into hash codes. Moreover, the hash codes are obtained simultaneously with the deep representation learning by the discrete hash optimization strategy. Extensive experiments on two public social image retrieval datasets validate the superior performance of our method compared with state-of-the-art hashing methods. The source codes of our method can be obtained at https://github.com/research2020-1/DSTDH
Object Shell Reconstruction: Camera-centric Object Representation for Robotic Grasping
Sep 14, 2021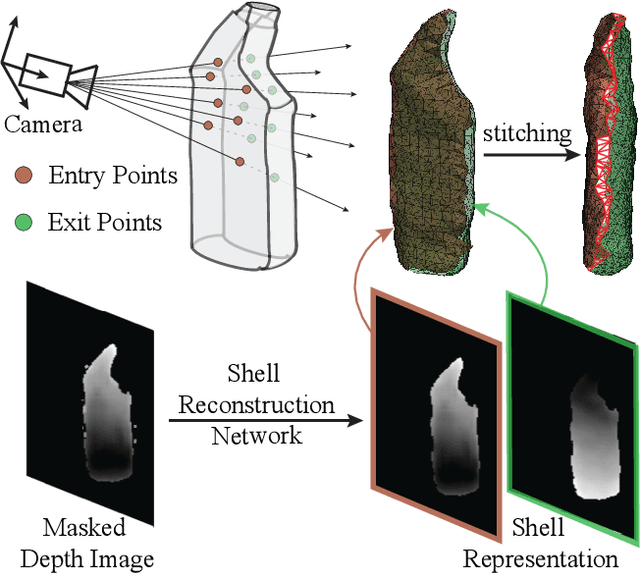
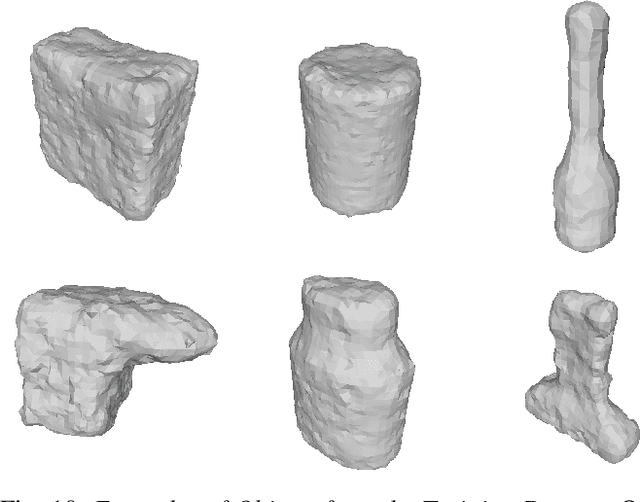

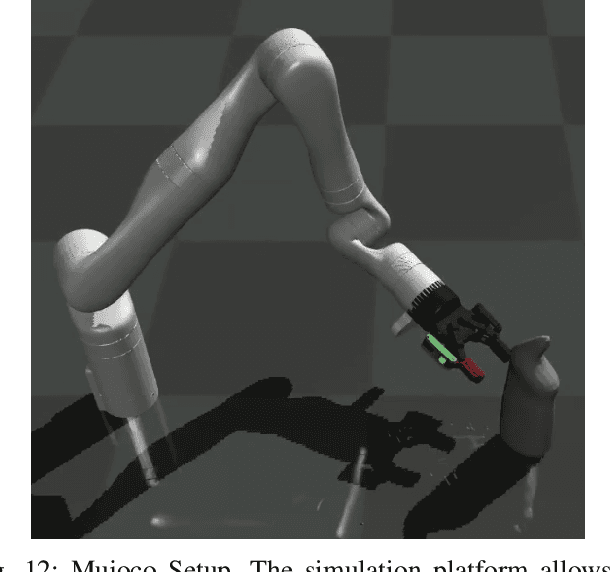
Robots can effectively grasp and manipulate objects using their 3D models. In this paper, we propose a simple shape representation and a reconstruction method that outperforms state-of-the-art methods in terms of geometric metrics and enables grasp generation with high precision and success. Our reconstruction method models the object geometry as a pair of depth images, composing the "shell" of the object. This representation allows using image-to-image residual ConvNet architectures for 3D reconstruction, generates object reconstruction directly in the camera frame, and generalizes well to novel object types. Moreover, an object shell can be converted into an object mesh in a fraction of a second, providing time and memory efficient alternative to voxel or implicit representations. We explore the application of shell representation for grasp planning. With rigorous experimental validation, both in simulation and on a real setup, we show that shell reconstruction encapsulates sufficient geometric information to generate precise grasps and the associated grasp quality with over 90% accuracy. Diverse grasps computed on shell reconstructions allow the robot to select and execute grasps in cluttered scenes with more than 93% success rate.
DSP: Dual Soft-Paste for Unsupervised Domain Adaptive Semantic Segmentation
Jul 27, 2021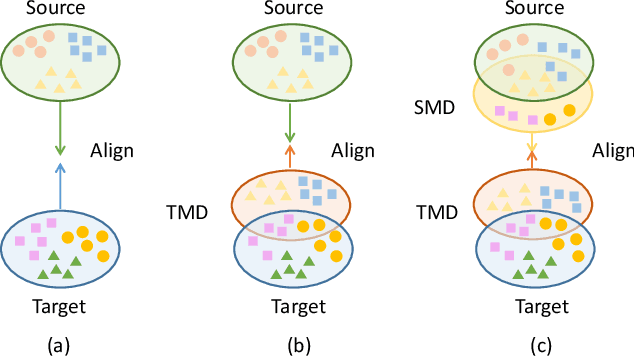
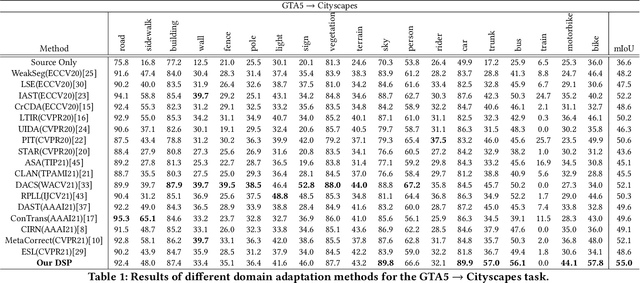
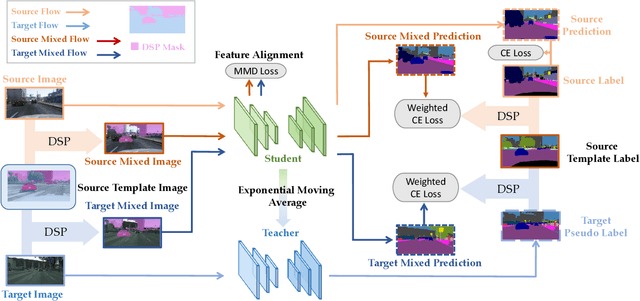
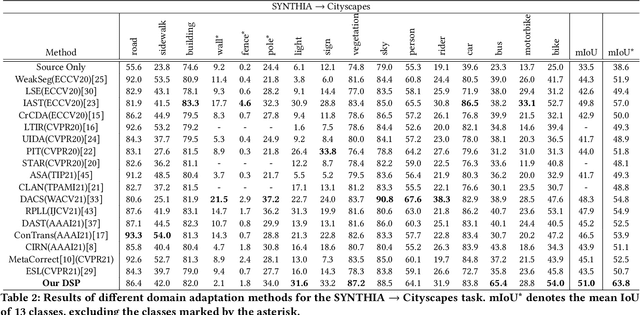
Unsupervised domain adaptation (UDA) for semantic segmentation aims to adapt a segmentation model trained on the labeled source domain to the unlabeled target domain. Existing methods try to learn domain invariant features while suffering from large domain gaps that make it difficult to correctly align discrepant features, especially in the initial training phase. To address this issue, we propose a novel Dual Soft-Paste (DSP) method in this paper. Specifically, DSP selects some classes from a source domain image using a long-tail class first sampling strategy and softly pastes the corresponding image patch on both the source and target training images with a fusion weight. Technically, we adopt the mean teacher framework for domain adaptation, where the pasted source and target images go through the student network while the original target image goes through the teacher network. Output-level alignment is carried out by aligning the probability maps of the target fused image from both networks using a weighted cross-entropy loss. In addition, feature-level alignment is carried out by aligning the feature maps of the source and target images from student network using a weighted maximum mean discrepancy loss. DSP facilitates the model learning domain-invariant features from the intermediate domains, leading to faster convergence and better performance. Experiments on two challenging benchmarks demonstrate the superiority of DSP over state-of-the-art methods. Code is available at \url{https://github.com/GaoLii/DSP}.
Learning ordered pooling weights in image classification
Jul 02, 2020


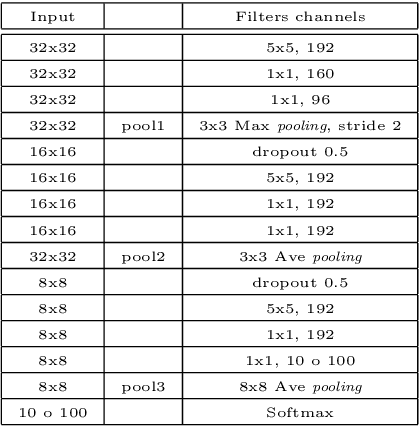
Spatial pooling is an important step in computer vision systems like Convolutional Neural Networks or the Bag-of-Words method. The spatial pooling purpose is to combine neighbouring descriptors to obtain a single descriptor for a given region (local or global). The resultant combined vector must be as discriminant as possible, in other words, must contain relevant information, while removing irrelevant and confusing details. Maximum and average are the most common aggregation functions used in the pooling step. To improve the aggregation of relevant information without degrading their discriminative power for image classification, we introduce a simple but effective scheme based on Ordered Weighted Average (OWA) aggregation operators. We present a method to learn the weights of the OWA aggregation operator in a Bag-of-Words framework and in Convolutional Neural Networks, and provide an extensive evaluation showing that OWA based pooling outperforms classical aggregation operators.
SIGN: Spatial-information Incorporated Generative Network for Generalized Zero-shot Semantic Segmentation
Aug 27, 2021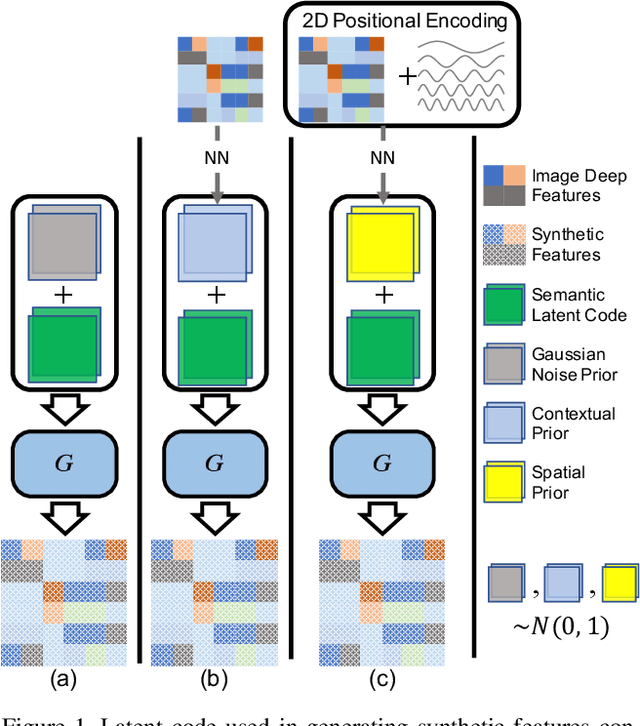
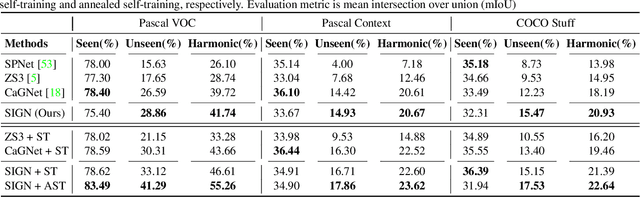
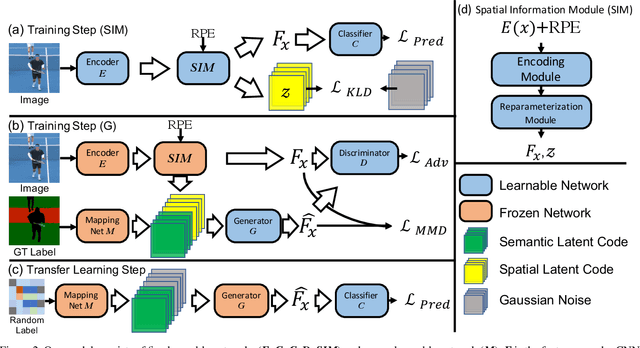
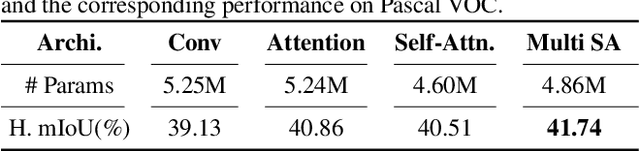
Unlike conventional zero-shot classification, zero-shot semantic segmentation predicts a class label at the pixel level instead of the image level. When solving zero-shot semantic segmentation problems, the need for pixel-level prediction with surrounding context motivates us to incorporate spatial information using positional encoding. We improve standard positional encoding by introducing the concept of Relative Positional Encoding, which integrates spatial information at the feature level and can handle arbitrary image sizes. Furthermore, while self-training is widely used in zero-shot semantic segmentation to generate pseudo-labels, we propose a new knowledge-distillation-inspired self-training strategy, namely Annealed Self-Training, which can automatically assign different importance to pseudo-labels to improve performance. We systematically study the proposed Relative Positional Encoding and Annealed Self-Training in a comprehensive experimental evaluation, and our empirical results confirm the effectiveness of our method on three benchmark datasets.
Location Leakage in Federated Signal Maps
Dec 07, 2021

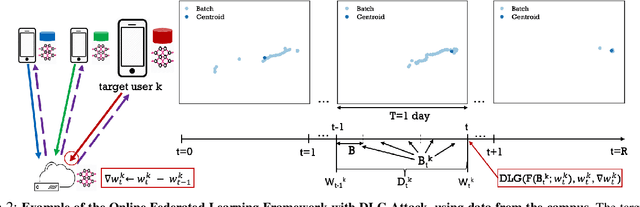

We consider the problem of predicting cellular network performance (signal maps) from measurements collected by several mobile devices. We formulate the problem within the online federated learning framework: (i) federated learning (FL) enables users to collaboratively train a model, while keeping their training data on their devices; (ii) measurements are collected as users move around over time and are used for local training in an online fashion. We consider an honest-but-curious server, who observes the updates from target users participating in FL and infers their location using a deep leakage from gradients (DLG) type of attack, originally developed to reconstruct training data of DNN image classifiers. We make the key observation that a DLG attack, applied to our setting, infers the average location of a batch of local data, and can thus be used to reconstruct the target users' trajectory at a coarse granularity. We show that a moderate level of privacy protection is already offered by the averaging of gradients, which is inherent to Federated Averaging. Furthermore, we propose an algorithm that devices can apply locally to curate the batches used for local updates, so as to effectively protect their location privacy without hurting utility. Finally, we show that the effect of multiple users participating in FL depends on the similarity of their trajectories. To the best of our knowledge, this is the first study of DLG attacks in the setting of FL from crowdsourced spatio-temporal data.
Real-MFF Dataset: A Large Realistic Multi-focus Image Dataset with Ground Truth
Mar 28, 2020



Multi-focus image fusion, a technique to generate an all-in-focus image from two or more source images, can benefit many computer vision tasks. However, currently there is no large and realistic dataset to perform convincing evaluation and comparison for exiting multi-focus image fusion. For deep learning methods, it is difficult to train a network without a suitable dataset. In this paper, we introduce a large and realistic multi-focus dataset containing 800 pairs of source images with the corresponding ground truth images. The dataset is generated using a light field camera, consequently, the source images as well as the ground truth images are realistic. Moreover, the dataset contains a variety of scenes, including buildings, plants, humans, shopping malls, squares and so on, to serve as a well-founded benchmark for multi-focus image fusion tasks. For illustration, we evaluate 10 typical multi-focus algorithms on this dataset.
PACE: Posthoc Architecture-Agnostic Concept Extractor for Explaining CNNs
Aug 31, 2021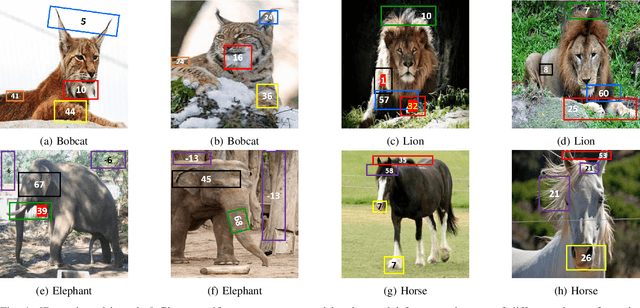
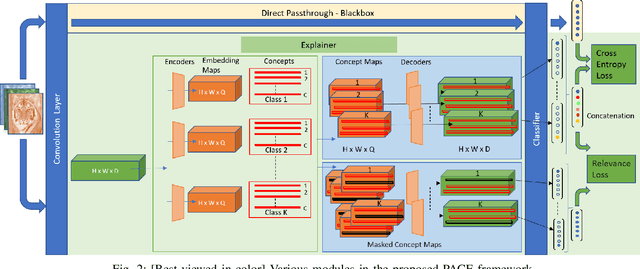
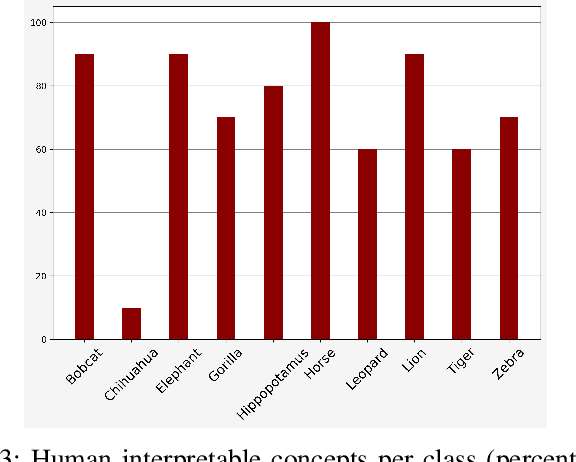

Deep CNNs, though have achieved the state of the art performance in image classification tasks, remain a black-box to a human using them. There is a growing interest in explaining the working of these deep models to improve their trustworthiness. In this paper, we introduce a Posthoc Architecture-agnostic Concept Extractor (PACE) that automatically extracts smaller sub-regions of the image called concepts relevant to the black-box prediction. PACE tightly integrates the faithfulness of the explanatory framework to the black-box model. To the best of our knowledge, this is the first work that extracts class-specific discriminative concepts in a posthoc manner automatically. The PACE framework is used to generate explanations for two different CNN architectures trained for classifying the AWA2 and Imagenet-Birds datasets. Extensive human subject experiments are conducted to validate the human interpretability and consistency of the explanations extracted by PACE. The results from these experiments suggest that over 72% of the concepts extracted by PACE are human interpretable.
DynaDog+T: A Parametric Animal Model for Synthetic Canine Image Generation
Jul 20, 2021
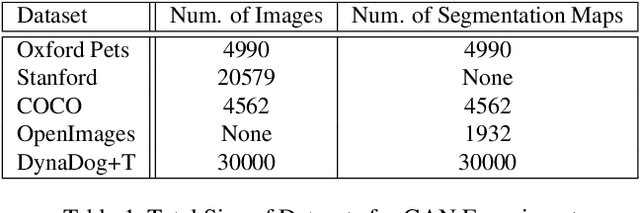


Synthetic data is becoming increasingly common for training computer vision models for a variety of tasks. Notably, such data has been applied in tasks related to humans such as 3D pose estimation where data is either difficult to create or obtain in realistic settings. Comparatively, there has been less work into synthetic animal data and it's uses for training models. Consequently, we introduce a parametric canine model, DynaDog+T, for generating synthetic canine images and data which we use for a common computer vision task, binary segmentation, which would otherwise be difficult due to the lack of available data.