 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SynSin: End-to-end View Synthesis from a Single Image
Dec 18, 2019
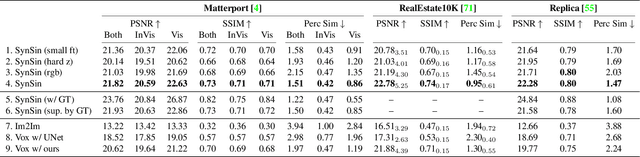

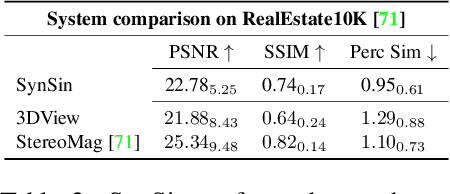

Single image view synthesis allows for the generation of new views of a scene given a single input image. This is challenging, as it requires comprehensively understanding the 3D scene from a single image. As a result, current methods typically use multiple images, train on ground-truth depth, or are limited to synthetic data. We propose a novel end-to-end model for this task; it is trained on real images without any ground-truth 3D information. To this end, we introduce a novel differentiable point cloud renderer that is used to transform a latent 3D point cloud of features into the target view. The projected features are decoded by our refinement network to inpaint missing regions and generate a realistic output image. The 3D component inside of our generative model allows for interpretable manipulation of the latent feature space at test time, e.g. we can animate trajectories from a single image. Unlike prior work, we can generate high resolution images and generalise to other input resolutions. We outperform baselines and prior work on the Matterport, Replica, and RealEstate10K datasets.
STAR: Noisy Semi-Supervised Transfer Learning for Visual Classification
Aug 18, 2021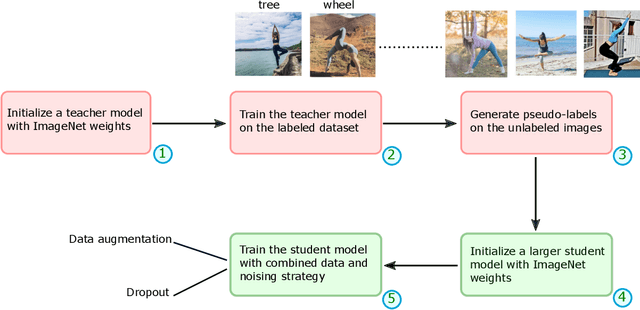
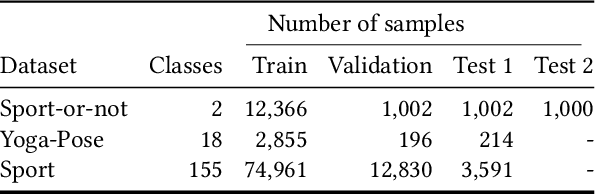

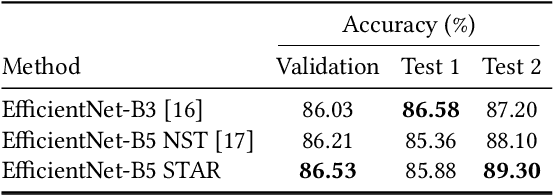
Semi-supervised learning (SSL) has proven to be effective at leveraging large-scale unlabeled data to mitigate the dependency on labeled data in order to learn better models for visual recognition and classification tasks. However, recent SSL methods rely on unlabeled image data at a scale of billions to work well. This becomes infeasible for tasks with relatively fewer unlabeled data in terms of runtime, memory and data acquisition. To address this issue, we propose noisy semi-supervised transfer learning, an efficient SSL approach that integrates transfer learning and self-training with noisy student into a single framework, which is tailored for tasks that can leverage unlabeled image data on a scale of thousands. We evaluate our method on both binary and multi-class classification tasks, where the objective is to identify whether an image displays people practicing sports or the type of sport, as well as to identify the pose from a pool of popular yoga poses. Extensive experiments and ablation studies demonstrate that by leveraging unlabeled data, our proposed framework significantly improves visual classification, especially in multi-class classification settings compared to state-of-the-art methods. Moreover, incorporating transfer learning not only improves classification performance, but also requires 6x less compute time and 5x less memory. We also show that our method boosts robustness of visual classification models, even without specifically optimizing for adversarial robustness.
DeeperLab: Single-Shot Image Parser
Mar 12, 2019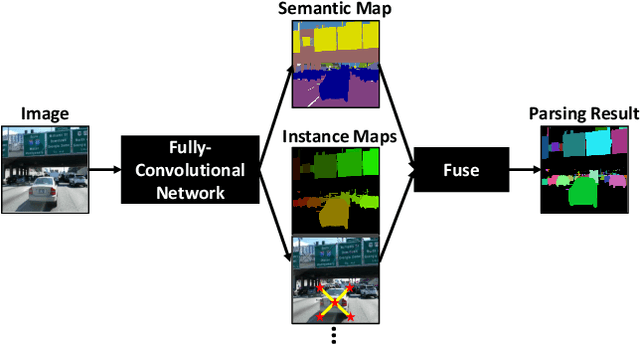
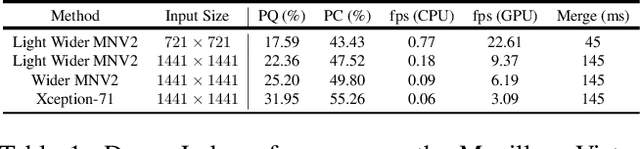


We present a single-shot, bottom-up approach for whole image parsing. Whole image parsing, also known as Panoptic Segmentation, generalizes the tasks of semantic segmentation for 'stuff' classes and instance segmentation for 'thing' classes, assigning both semantic and instance labels to every pixel in an image. Recent approaches to whole image parsing typically employ separate standalone modules for the constituent semantic and instance segmentation tasks and require multiple passes of inference. Instead, the proposed DeeperLab image parser performs whole image parsing with a significantly simpler, fully convolutional approach that jointly addresses the semantic and instance segmentation tasks in a single-shot manner, resulting in a streamlined system that better lends itself to fast processing. For quantitative evaluation, we use both the instance-based Panoptic Quality (PQ) metric and the proposed region-based Parsing Covering (PC) metric, which better captures the image parsing quality on 'stuff' classes and larger object instances. We report experimental results on the challenging Mapillary Vistas dataset, in which our single model achieves 31.95% (val) / 31.6% PQ (test) and 55.26% PC (val) with 3 frames per second (fps) on GPU or near real-time speed (22.6 fps on GPU) with reduced accuracy.
VirtualConductor: Music-driven Conducting Video Generation System
Jul 28, 2021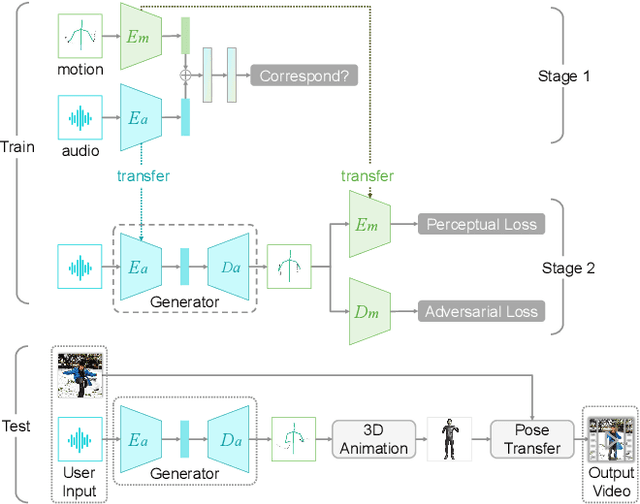
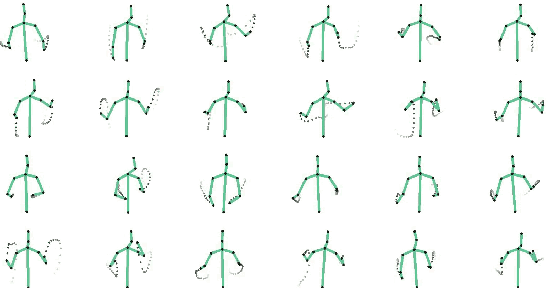


In this demo, we present VirtualConductor, a system that can generate conducting video from any given music and a single user's image. First, a large-scale conductor motion dataset is collected and constructed. Then, we propose Audio Motion Correspondence Network (AMCNet) and adversarial-perceptual learning to learn the cross-modal relationship and generate diverse, plausible, music-synchronized motion. Finally, we combine 3D animation rendering and a pose transfer model to synthesize conducting video from a single given user's image. Therefore, any user can become a virtual conductor through the system.
RGB-D Saliency Detection via Cascaded Mutual Information Minimization
Sep 15, 2021

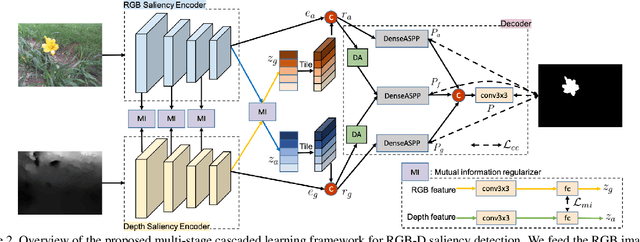
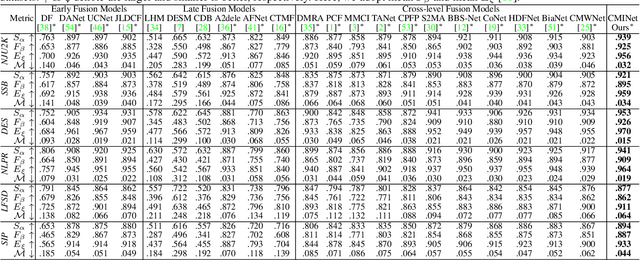
Existing RGB-D saliency detection models do not explicitly encourage RGB and depth to achieve effective multi-modal learning. In this paper, we introduce a novel multi-stage cascaded learning framework via mutual information minimization to "explicitly" model the multi-modal information between RGB image and depth data. Specifically, we first map the feature of each mode to a lower dimensional feature vector, and adopt mutual information minimization as a regularizer to reduce the redundancy between appearance features from RGB and geometric features from depth. We then perform multi-stage cascaded learning to impose the mutual information minimization constraint at every stage of the network. Extensive experiments on benchmark RGB-D saliency datasets illustrate the effectiveness of our framework. Further, to prosper the development of this field, we contribute the largest (7x larger than NJU2K) dataset, which contains 15,625 image pairs with high quality polygon-/scribble-/object-/instance-/rank-level annotations. Based on these rich labels, we additionally construct four new benchmarks with strong baselines and observe some interesting phenomena, which can motivate future model design. Source code and dataset are available at "https://github.com/JingZhang617/cascaded_rgbd_sod".
Deformable Kernel Networks for Joint Image Filtering
Oct 17, 2019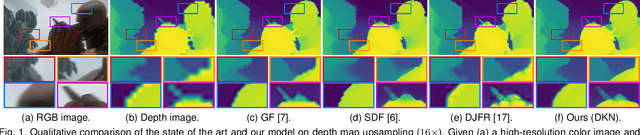
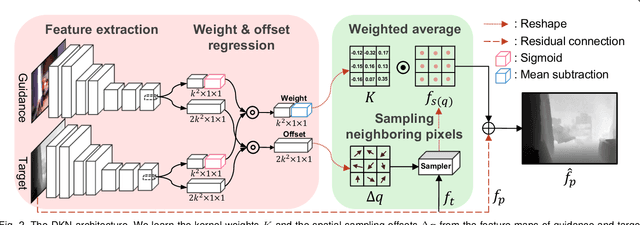

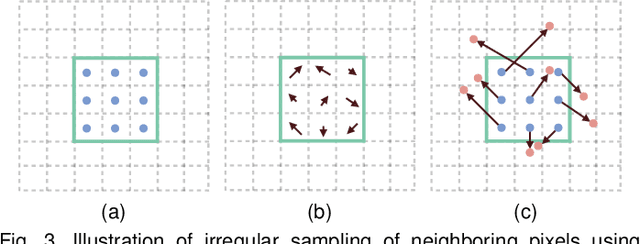
Joint image filters are used to transfer structural details from a guidance picture used as a prior to a target image, in tasks such as enhancing spatial resolution and suppressing noise. Previous methods based on convolutional neural networks (CNNs) combine nonlinear activations of spatially-invariant kernels to estimate structural details and regress the filtering result. In this paper, we instead learn explicitly sparse and spatially-variant kernels. We propose a CNN architecture and its efficient implementation, called the deformable kernel network (DKN), that outputs sets of neighbors and the corresponding weights adaptively for each pixel. The filtering result is then computed as a weighted average. We also propose a fast version of DKN that runs about seventeen times faster for an image of size 640 x 480. We demonstrate the effectiveness and flexibility of our models on the tasks of depth map upsampling, saliency map upsampling, cross-modality image restoration, texture removal, and semantic segmentation. In particular, we show that the weighted averaging process with sparsely sampled 3 x 3 kernels outperforms the state of the art by a significant margin in all cases.
Volumetric Attention for 3D Medical Image Segmentation and Detection
Apr 04, 2020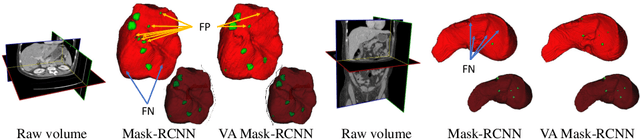
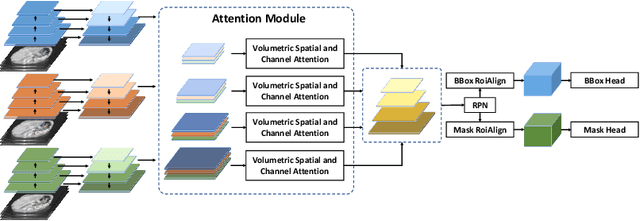
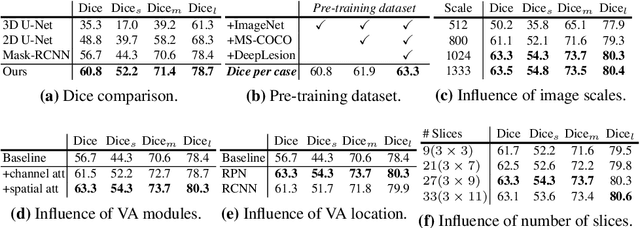
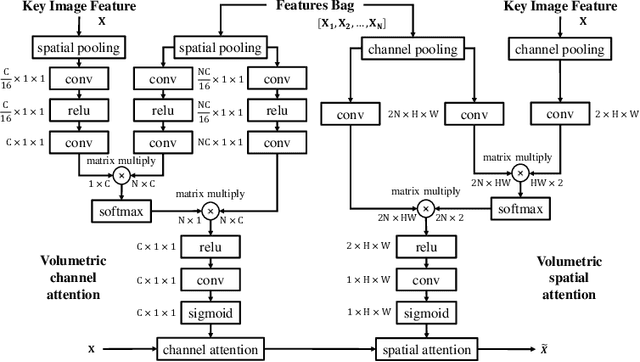
A volumetric attention(VA) module for 3D medical image segmentation and detection is proposed. VA attention is inspired by recent advances in video processing, enables 2.5D networks to leverage context information along the z direction, and allows the use of pretrained 2D detection models when training data is limited, as is often the case for medical applications. Its integration in the Mask R-CNN is shown to enable state-of-the-art performance on the Liver Tumor Segmentation (LiTS) Challenge, outperforming the previous challenge winner by 3.9 points and achieving top performance on the LiTS leader board at the time of paper submission. Detection experiments on the DeepLesion dataset also show that the addition of VA to existing object detectors enables a 69.1 sensitivity at 0.5 false positive per image, outperforming the best published results by 6.6 points.
* Accepted by MICCAI 2019
AutoLay: Benchmarking amodal layout estimation for autonomous driving
Aug 20, 2021


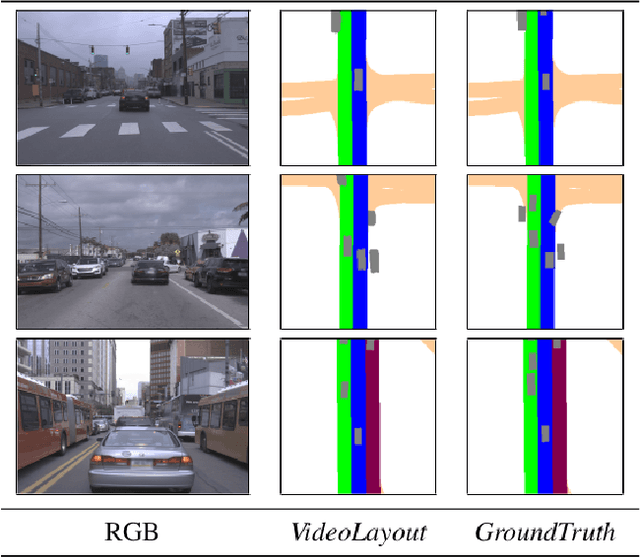
Given an image or a video captured from a monocular camera, amodal layout estimation is the task of predicting semantics and occupancy in bird's eye view. The term amodal implies we also reason about entities in the scene that are occluded or truncated in image space. While several recent efforts have tackled this problem, there is a lack of standardization in task specification, datasets, and evaluation protocols. We address these gaps with AutoLay, a dataset and benchmark for amodal layout estimation from monocular images. AutoLay encompasses driving imagery from two popular datasets: KITTI and Argoverse. In addition to fine-grained attributes such as lanes, sidewalks, and vehicles, we also provide semantically annotated 3D point clouds. We implement several baselines and bleeding edge approaches, and release our data and code.
Towards Super-Resolution CEST MRI for Visualization of Small Structures
Dec 03, 2021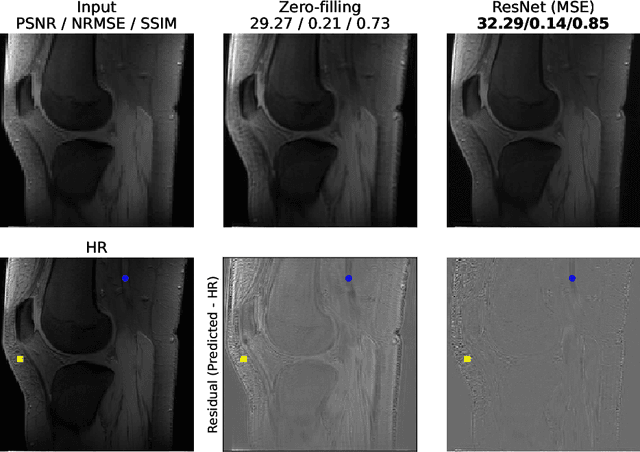
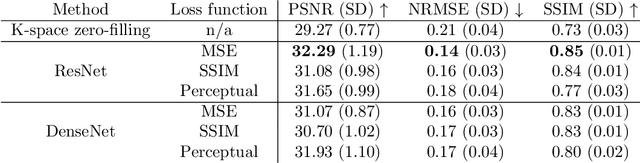
The onset of rheumatic diseases such as rheumatoid arthritis is typically subclinical, which results in challenging early detection of the disease. However, characteristic changes in the anatomy can be detected using imaging techniques such as MRI or CT. Modern imaging techniques such as chemical exchange saturation transfer (CEST) MRI drive the hope to improve early detection even further through the imaging of metabolites in the body. To image small structures in the joints of patients, typically one of the first regions where changes due to the disease occur, a high resolution for the CEST MR imaging is necessary. Currently, however, CEST MR suffers from an inherently low resolution due to the underlying physical constraints of the acquisition. In this work we compared established up-sampling techniques to neural network-based super-resolution approaches. We could show, that neural networks are able to learn the mapping from low-resolution to high-resolution unsaturated CEST images considerably better than present methods. On the test set a PSNR of 32.29dB (+10%), a NRMSE of 0.14 (+28%), and a SSIM of 0.85 (+15%) could be achieved using a ResNet neural network, improving the baseline considerably. This work paves the way for the prospective investigation of neural networks for super-resolution CEST MRI and, followingly, might lead to a earlier detection of the onset of rheumatic diseases.
Automatic Foot Ulcer segmentation Using an Ensemble of Convolutional Neural Networks
Sep 03, 2021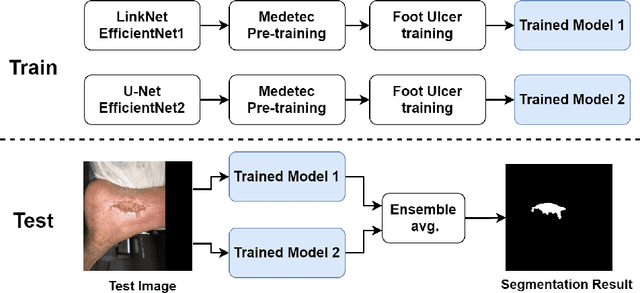
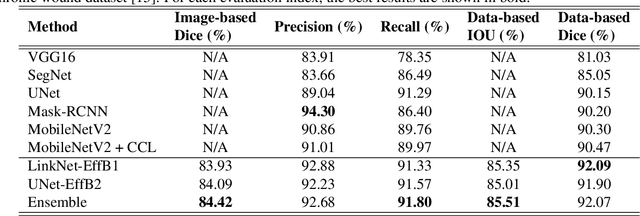

Foot ulcer is a common complication of diabetes mellitus; it is associated with substantial morbidity and mortality and remains a major risk factor for lower leg amputation. Extracting accurate morphological features from the foot wounds is crucial for proper treatment. Although visual and manual inspection by medical professionals is the common approach to extract the features, this method is subjective and error-prone. Computer-mediated approaches are the alternative solutions to segment the lesions and extract related morphological features. Among various proposed computer-based approaches for image segmentation, deep learning-based methods and more specifically convolutional neural networks (CNN) have shown excellent performances for various image segmentation tasks including medical image segmentation. In this work, we proposed an ensemble approach based on two encoder-decoder-based CNN models, namely LinkNet and UNet, to perform foot ulcer segmentation. To deal with limited training samples, we used pre-trained weights (EfficientNetB1 for the LinkNet model and EfficientNetB2 for the UNet model) and further pre-training by the Medetec dataset. We also applied a number of morphological-based and colour-based augmentation techniques to train the models. We integrated five-fold cross-validation, test time augmentation and result fusion in our proposed ensemble approach to boost the segmentation performance. Applied on a publicly available foot ulcer segmentation dataset and the MICCAI 2021 Foot Ulcer Segmentation (FUSeg) Challenge, our method achieved state-of-the-art data-based Dice scores of 92.07% and 88.80%, respectively. Our developed method achieved the first rank in the FUSeg challenge leaderboard. The Dockerised guideline, inference codes and saved trained models are publicly available in the published GitHub repository: https://github.com/masih4/Foot_Ulcer_Segmentation