 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Two-dimensional Deep Regression for Early Yield Prediction of Winter Wheat
Nov 15, 2021
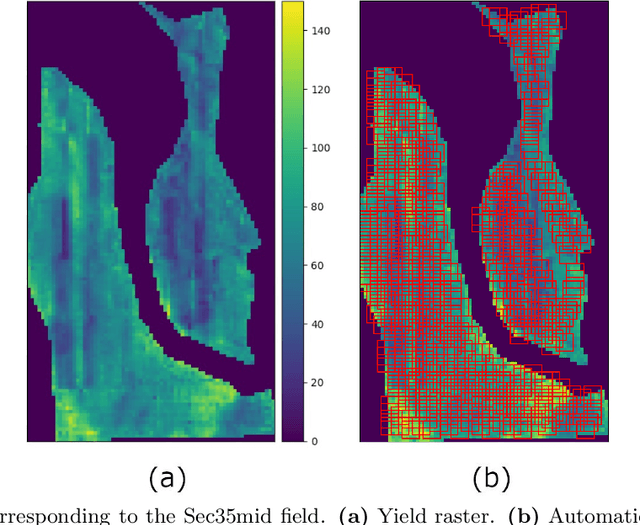
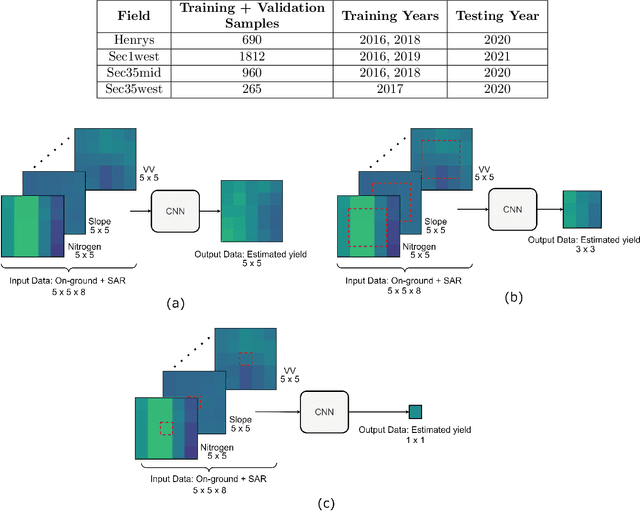
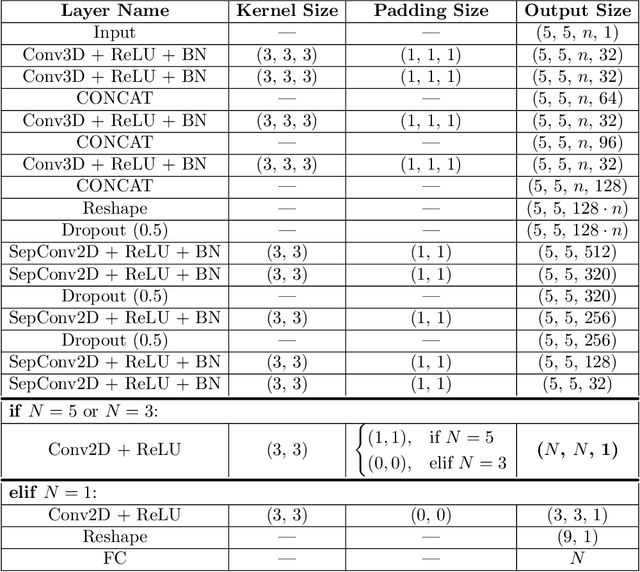
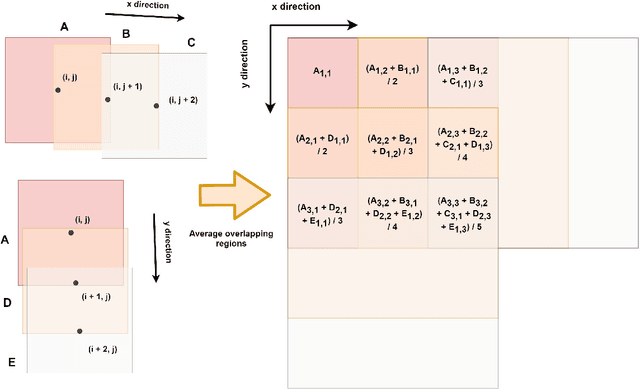
Crop yield prediction is one of the tasks of Precision Agriculture that can be automated based on multi-source periodic observations of the fields. We tackle the yield prediction problem using a Convolutional Neural Network (CNN) trained on data that combines radar satellite imagery and on-ground information. We present a CNN architecture called Hyper3DNetReg that takes in a multi-channel input image and outputs a two-dimensional raster, where each pixel represents the predicted yield value of the corresponding input pixel. We utilize radar data acquired from the Sentinel-1 satellites, while the on-ground data correspond to a set of six raster features: nitrogen rate applied, precipitation, slope, elevation, topographic position index (TPI), and aspect. We use data collected during the early stage of the winter wheat growing season (March) to predict yield values during the harvest season (August). We present experiments over four fields of winter wheat and show that our proposed methodology yields better results than five compared methods, including multiple linear regression, an ensemble of feedforward networks using AdaBoost, a stacked autoencoder, and two other CNN architectures.
Adapt Everywhere: Unsupervised Adaptation of Point-Clouds and Entropy Minimisation for Multi-modal Cardiac Image Segmentation
Mar 15, 2021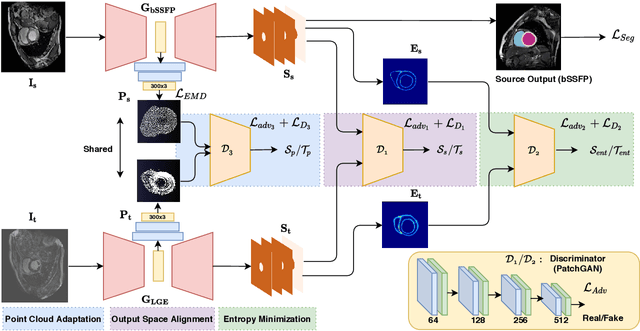
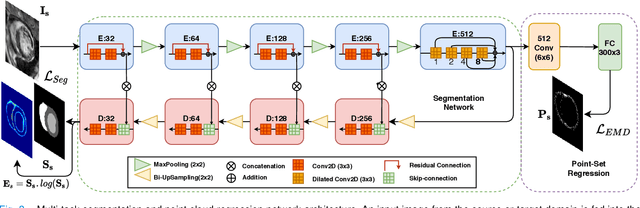
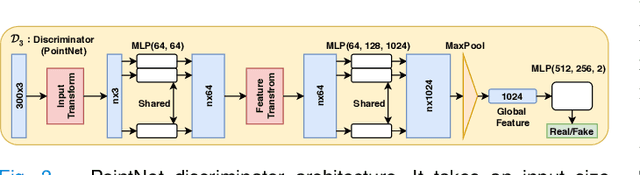
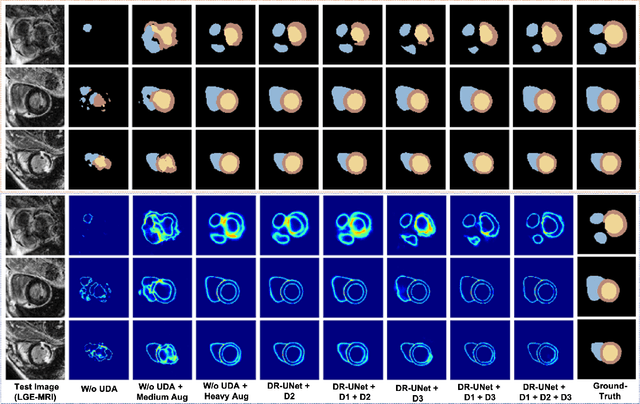
Deep learning models are sensitive to domain shift phenomena. A model trained on images from one domain cannot generalise well when tested on images from a different domain, despite capturing similar anatomical structures. It is mainly because the data distribution between the two domains is different. Moreover, creating annotation for every new modality is a tedious and time-consuming task, which also suffers from high inter- and intra- observer variability. Unsupervised domain adaptation (UDA) methods intend to reduce the gap between source and target domains by leveraging source domain labelled data to generate labels for the target domain. However, current state-of-the-art (SOTA) UDA methods demonstrate degraded performance when there is insufficient data in source and target domains. In this paper, we present a novel UDA method for multi-modal cardiac image segmentation. The proposed method is based on adversarial learning and adapts network features between source and target domain in different spaces. The paper introduces an end-to-end framework that integrates: a) entropy minimisation, b) output feature space alignment and c) a novel point-cloud shape adaptation based on the latent features learned by the segmentation model. We validated our method on two cardiac datasets by adapting from the annotated source domain, bSSFP-MRI (balanced Steady-State Free Procession-MRI), to the unannotated target domain, LGE-MRI (Late-gadolinium enhance-MRI), for the multi-sequence dataset; and from MRI (source) to CT (target) for the cross-modality dataset. The results highlighted that by enforcing adversarial learning in different parts of the network, the proposed method delivered promising performance, compared to other SOTA methods.
Ensembling Low Precision Models for Binary Biomedical Image Segmentation
Oct 16, 2020
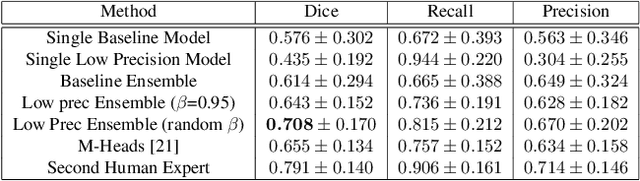
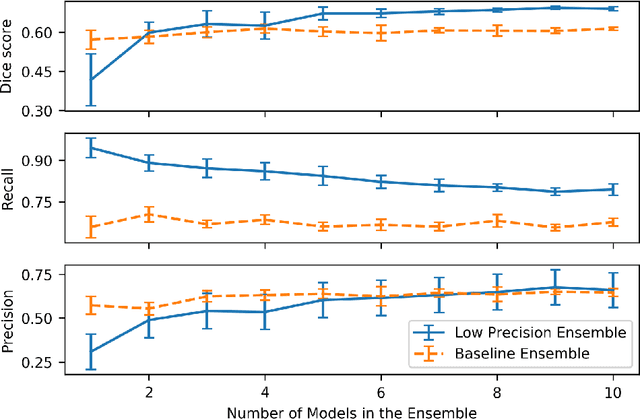

Segmentation of anatomical regions of interest such as vessels or small lesions in medical images is still a difficult problem that is often tackled with manual input by an expert. One of the major challenges for this task is that the appearance of foreground (positive) regions can be similar to background (negative) regions. As a result, many automatic segmentation algorithms tend to exhibit asymmetric errors, typically producing more false positives than false negatives. In this paper, we aim to leverage this asymmetry and train a diverse ensemble of models with very high recall, while sacrificing their precision. Our core idea is straightforward: A diverse ensemble of low precision and high recall models are likely to make different false positive errors (classifying background as foreground in different parts of the image), but the true positives will tend to be consistent. Thus, in aggregate the false positive errors will cancel out, yielding high performance for the ensemble. Our strategy is general and can be applied with any segmentation model. In three different applications (carotid artery segmentation in a neck CT angiography, myocardium segmentation in a cardiovascular MRI and multiple sclerosis lesion segmentation in a brain MRI), we show how the proposed approach can significantly boost the performance of a baseline segmentation method.
Common Language for Goal-Oriented Semantic Communications: A Curriculum Learning Framework
Nov 15, 2021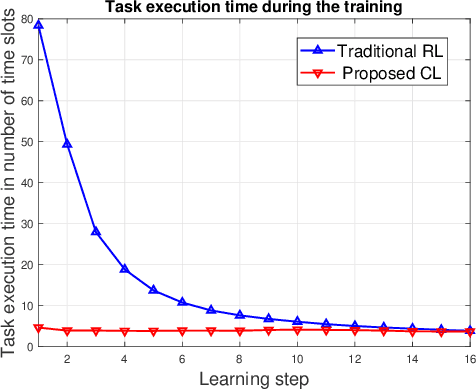
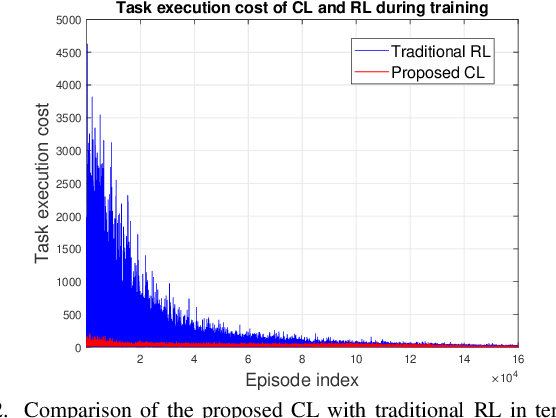
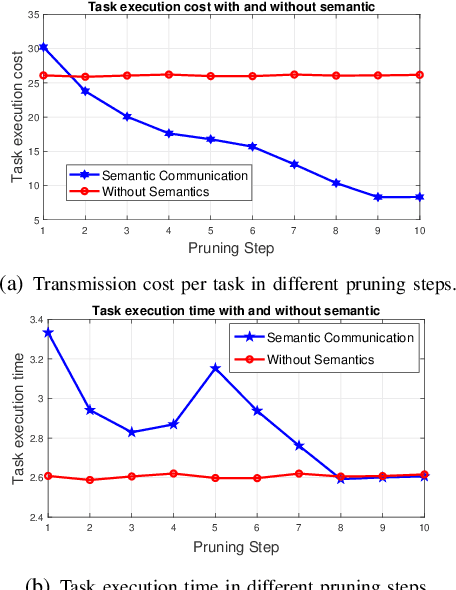
Semantic communications will play a critical role in enabling goal-oriented services over next-generation wireless systems. However, most prior art in this domain is restricted to specific applications (e.g., text or image), and it does not enable goal-oriented communications in which the effectiveness of the transmitted information must be considered along with the semantics so as to execute a certain task. In this paper, a comprehensive semantic communications framework is proposed for enabling goal-oriented task execution. To capture the semantics between a speaker and a listener, a common language is defined using the concept of beliefs to enable the speaker to describe the environment observations to the listener. Then, an optimization problem is posed to choose the minimum set of beliefs that perfectly describes the observation while minimizing the task execution time and transmission cost. A novel top-down framework that combines curriculum learning (CL) and reinforcement learning (RL) is proposed to solve this problem. Simulation results show that the proposed CL method outperforms traditional RL in terms of convergence time, task execution time, and transmission cost during training.
Monitoring crop phenology with street-level imagery using computer vision
Dec 16, 2021
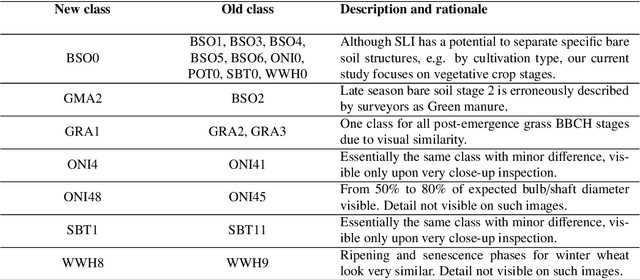


Street-level imagery holds a significant potential to scale-up in-situ data collection. This is enabled by combining the use of cheap high quality cameras with recent advances in deep learning compute solutions to derive relevant thematic information. We present a framework to collect and extract crop type and phenological information from street level imagery using computer vision. During the 2018 growing season, high definition pictures were captured with side-looking action cameras in the Flevoland province of the Netherlands. Each month from March to October, a fixed 200-km route was surveyed collecting one picture per second resulting in a total of 400,000 geo-tagged pictures. At 220 specific parcel locations detailed on the spot crop phenology observations were recorded for 17 crop types. Furthermore, the time span included specific pre-emergence parcel stages, such as differently cultivated bare soil for spring and summer crops as well as post-harvest cultivation practices, e.g. green manuring and catch crops. Classification was done using TensorFlow with a well-known image recognition model, based on transfer learning with convolutional neural networks (MobileNet). A hypertuning methodology was developed to obtain the best performing model among 160 models. This best model was applied on an independent inference set discriminating crop type with a Macro F1 score of 88.1% and main phenological stage at 86.9% at the parcel level. Potential and caveats of the approach along with practical considerations for implementation and improvement are discussed. The proposed framework speeds up high quality in-situ data collection and suggests avenues for massive data collection via automated classification using computer vision.
Evaluation Metrics for Conditional Image Generation
Apr 26, 2020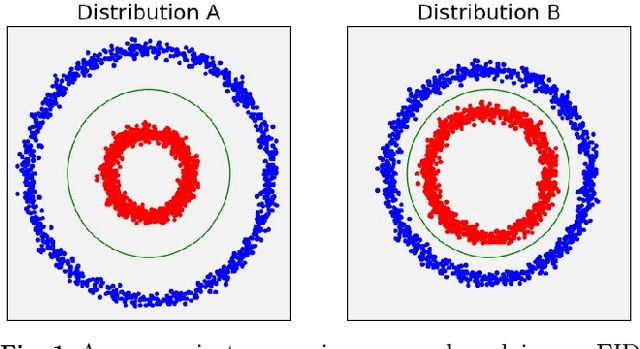
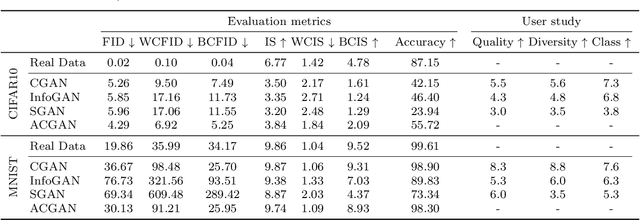
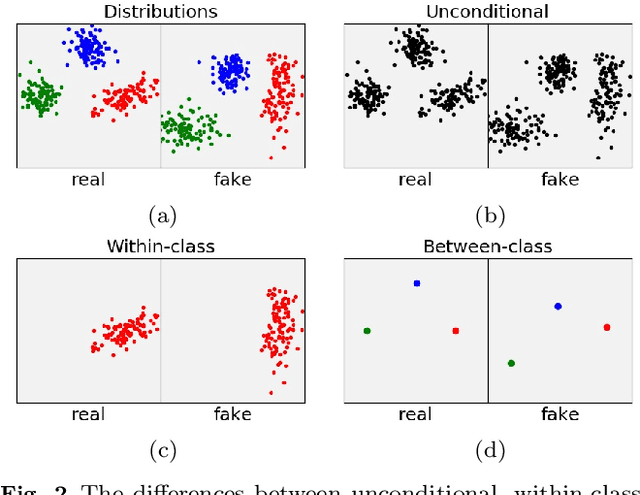
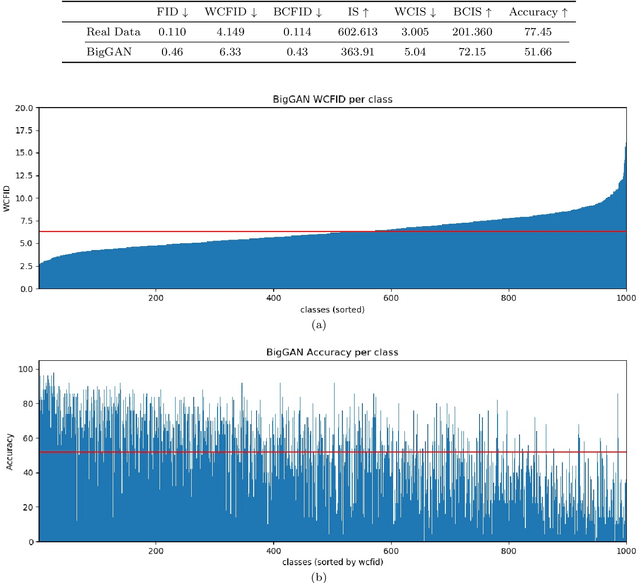
We present two new metrics for evaluating generative models in the class-conditional image generation setting. These metrics are obtained by generalizing the two most popular unconditional metrics: the Inception Score (IS) and the Fr\'{e}chet Inception Distance (FID). A theoretical analysis shows the motivation behind each proposed metric and links the novel metrics to their unconditional counterparts. The link takes the form of a product in the case of IS or an upper bound in the FID case. We provide an extensive empirical evaluation, comparing the metrics to their unconditional variants and to other metrics, and utilize them to analyze existing generative models, thus providing additional insights about their performance, from unlearned classes to mode collapse.
Learning of Frequency-Time Attention Mechanism for Automatic Modulation Recognition
Nov 05, 2021
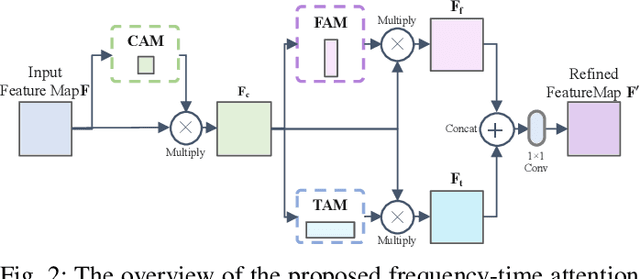
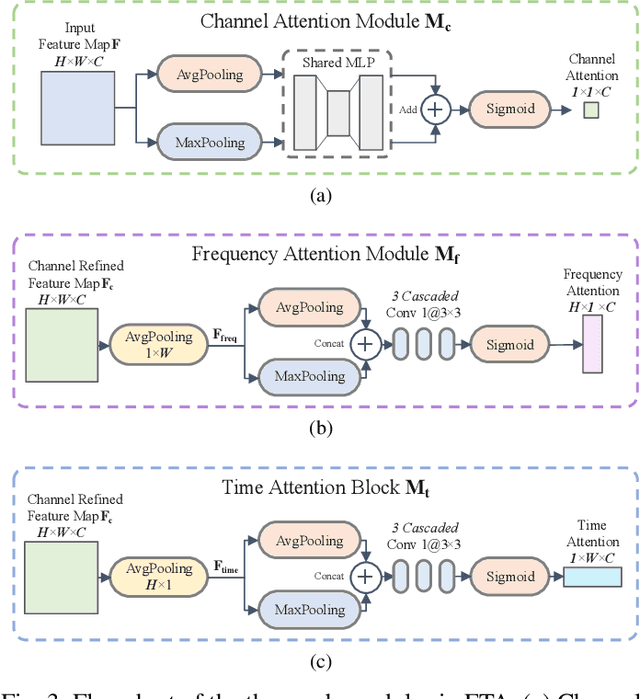
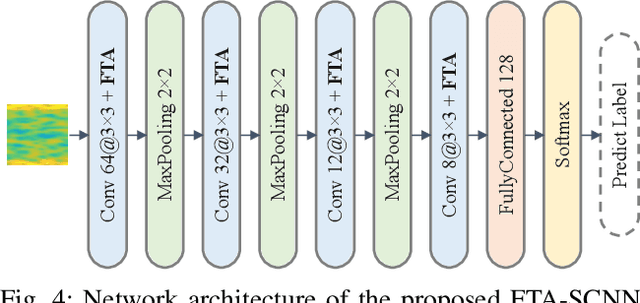
Recent learning-based image classification and speech recognition approaches make extensive use of attention mechanisms to achieve state-of-the-art recognition power, which demonstrates the effectiveness of attention mechanisms. Motivated by the fact that the frequency and time information of modulated radio signals are crucial for modulation mode recognition, this paper proposes a frequency-time attention mechanism for a convolutional neural network (CNN)-based modulation recognition framework. The proposed frequency-time attention module is designed to learn which channel, frequency and time information is more meaningful in CNN for modulation recognition. We analyze the effectiveness of the proposed frequency-time attention mechanism and compare the proposed method with two existing learning-based methods. Experiments on an open-source modulation recognition dataset show that the recognition performance of the proposed framework is better than those of the framework without frequency-time attention and existing learning-based methods.
Introducing the structural bases of typicality effects in deep learning
Jul 07, 2021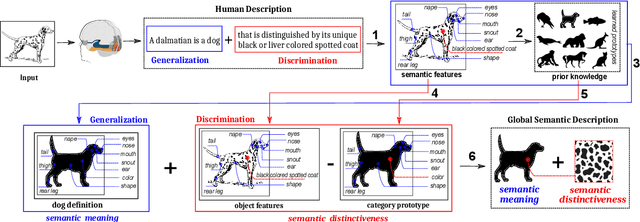
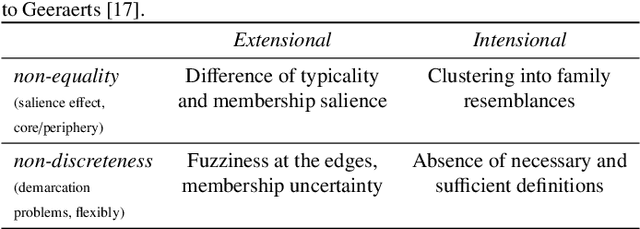
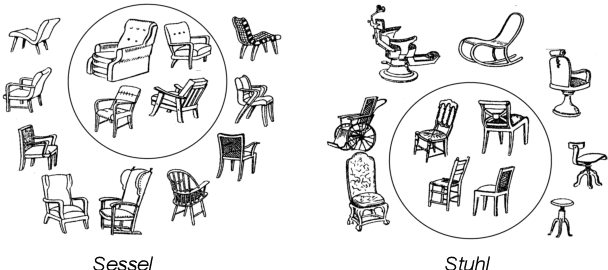
In this paper, we hypothesize that the effects of the degree of typicality in natural semantic categories can be generated based on the structure of artificial categories learned with deep learning models. Motivated by the human approach to representing natural semantic categories and based on the Prototype Theory foundations, we propose a novel Computational Prototype Model (CPM) to represent the internal structure of semantic categories. Unlike other prototype learning approaches, our mathematical framework proposes a first approach to provide deep neural networks with the ability to model abstract semantic concepts such as category central semantic meaning, typicality degree of an object's image, and family resemblance relationship. We proposed several methodologies based on the typicality's concept to evaluate our CPM-model in image semantic processing tasks such as image classification, a global semantic description, and transfer learning. Our experiments on different image datasets, such as ImageNet and Coco, showed that our approach might be an admissible proposition in the effort to endow machines with greater power of abstraction for the semantic representation of objects' categories.
Fast-Slow Transformer for Visually Grounding Speech
Oct 01, 2021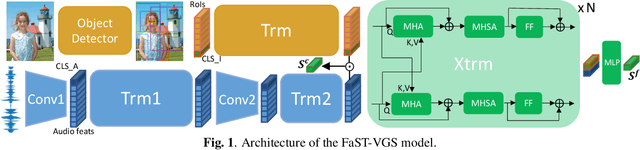
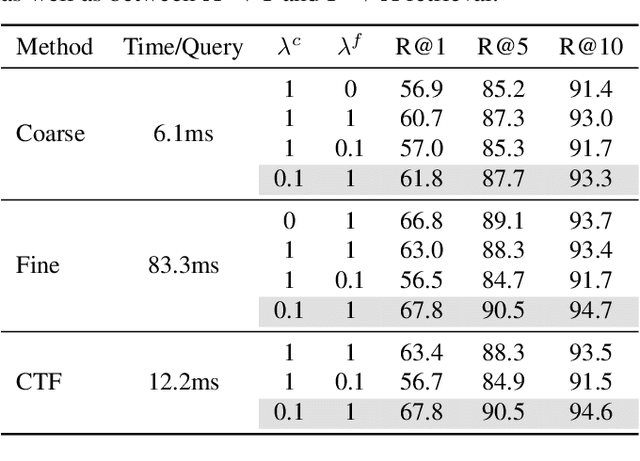
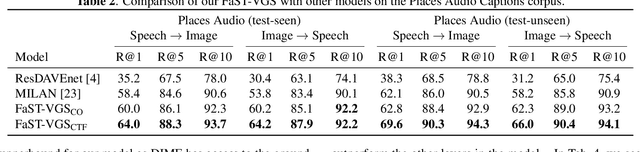
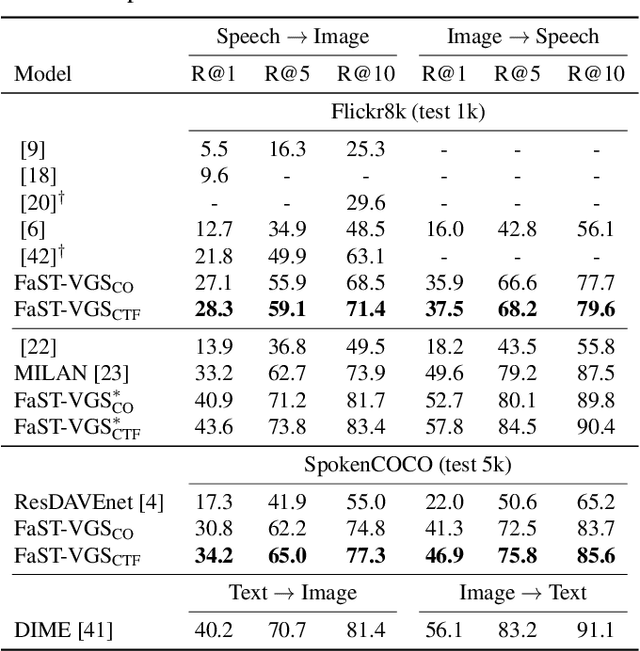
We present Fast-Slow Transformer for Visually Grounding Speech, or FaST-VGS. FaST-VGS is a Transformer-based model for learning the associations between raw speech waveforms and visual images. The model unifies dual-encoder and cross-attention architectures into a single model, reaping the superior retrieval speed of the former along with the accuracy of the latter. FaST-VGS achieves state-of-the-art speech-image retrieval accuracy on benchmark datasets, and its learned representations exhibit strong performance on the ZeroSpeech 2021 phonetic and semantic tasks.
Towards Photo-Realistic Virtual Try-On by Adaptively Generating$\leftrightarrow$Preserving Image Content
Mar 12, 2020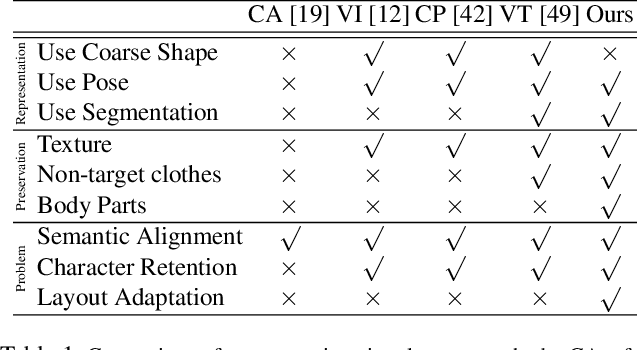
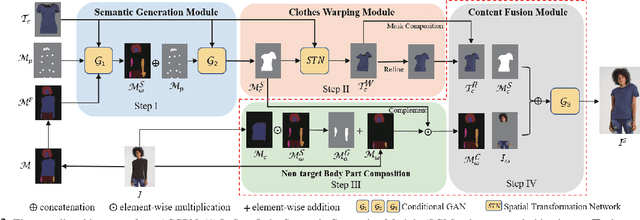
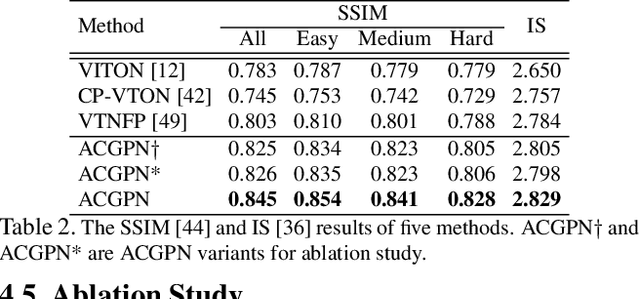

Image visual try-on aims at transferring a target clothing image onto a reference person, and has become a hot topic in recent years. Prior arts usually focus on preserving the character of a clothing image (e.g. texture, logo, embroidery) when warping it to arbitrary human pose. However, it remains a big challenge to generate photo-realistic try-on images when large occlusions and human poses are presented in the reference person. To address this issue, we propose a novel visual try-on network, namely Adaptive Content Generating and Preserving Network (ACGPN). In particular, ACGPN first predicts semantic layout of the reference image that will be changed after try-on (e.g. long sleeve shirt$\rightarrow$arm, arm$\rightarrow$jacket), and then determines whether its image content needs to be generated or preserved according to the predicted semantic layout, leading to photo-realistic try-on and rich clothing details. ACGPN generally involves three major modules. First, a semantic layout generation module utilizes semantic segmentation of the reference image to progressively predict the desired semantic layout after try-on. Second, a clothes warping module warps clothing images according to the generated semantic layout, where a second-order difference constraint is introduced to stabilize the warping process during training. Third, an inpainting module for content fusion integrates all information (e.g. reference image, semantic layout, warped clothes) to adaptively produce each semantic part of human body. In comparison to the state-of-the-art methods, ACGPN can generate photo-realistic images with much better perceptual quality and richer fine-details.