 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Multi-Scale High-Resolution Vision Transformer for Semantic Segmentation
Nov 23, 2021
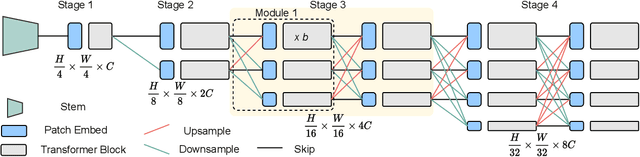

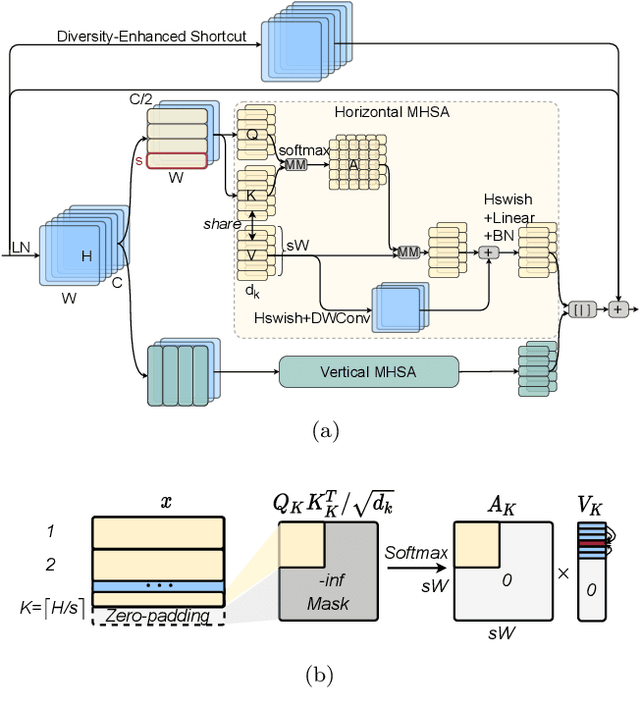
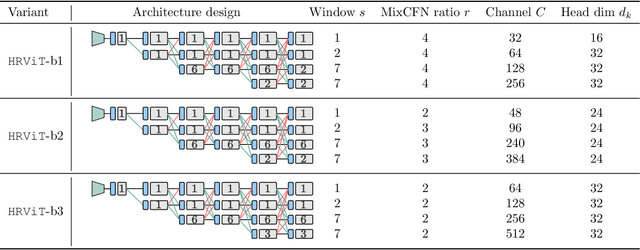
Vision Transformers (ViTs) have emerged with superior performance on computer vision tasks compared to convolutional neural network (CNN)-based models. However, ViTs are mainly designed for image classification that generate single-scale low-resolution representations, which makes dense prediction tasks such as semantic segmentation challenging for ViTs. Therefore, we propose HRViT, which enhances ViTs to learn semantically-rich and spatially-precise multi-scale representations by integrating high-resolution multi-branch architectures with ViTs. We balance the model performance and efficiency of HRViT by various branch-block co-optimization techniques. Specifically, we explore heterogeneous branch designs, reduce the redundancy in linear layers, and augment the attention block with enhanced expressiveness. Those approaches enabled HRViT to push the Pareto frontier of performance and efficiency on semantic segmentation to a new level, as our evaluation results on ADE20K and Cityscapes show. HRViT achieves 50.20% mIoU on ADE20K and 83.16% mIoU on Cityscapes, surpassing state-of-the-art MiT and CSWin backbones with an average of +1.78 mIoU improvement, 28% parameter saving, and 21% FLOPs reduction, demonstrating the potential of HRViT as a strong vision backbone for semantic segmentation.
Evaluation Metrics for Conditional Image Generation
Apr 26, 2020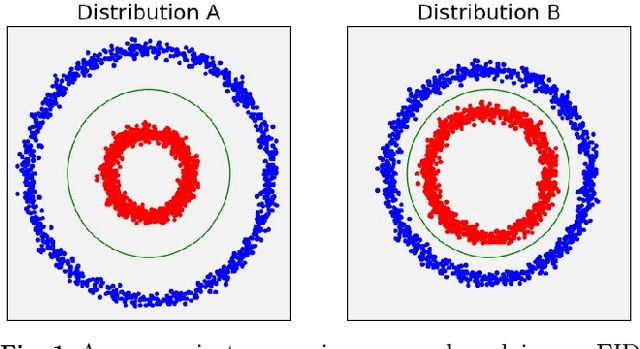
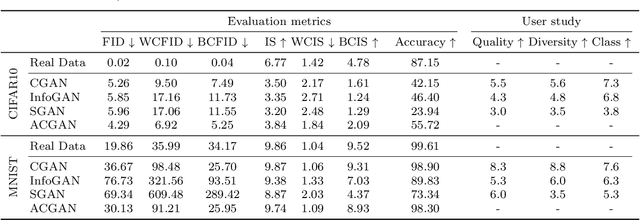
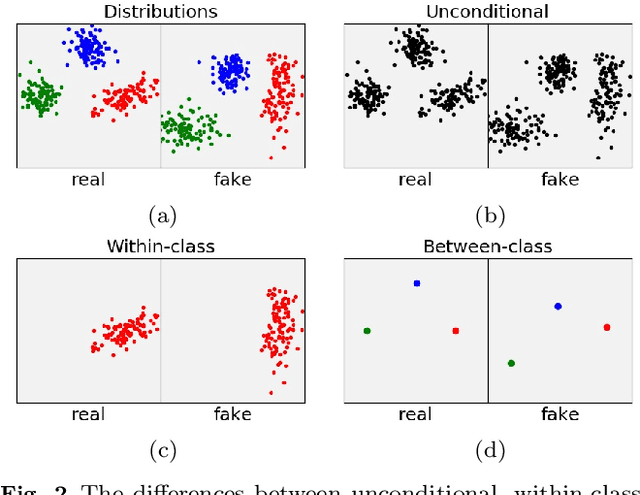
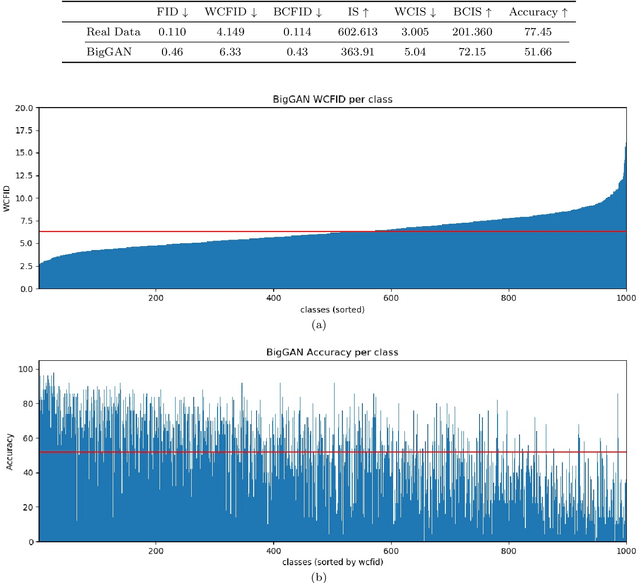
We present two new metrics for evaluating generative models in the class-conditional image generation setting. These metrics are obtained by generalizing the two most popular unconditional metrics: the Inception Score (IS) and the Fr\'{e}chet Inception Distance (FID). A theoretical analysis shows the motivation behind each proposed metric and links the novel metrics to their unconditional counterparts. The link takes the form of a product in the case of IS or an upper bound in the FID case. We provide an extensive empirical evaluation, comparing the metrics to their unconditional variants and to other metrics, and utilize them to analyze existing generative models, thus providing additional insights about their performance, from unlearned classes to mode collapse.
Semi-Supervised Learning with Taxonomic Labels
Nov 23, 2021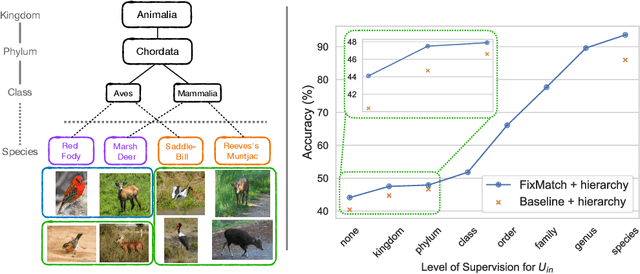
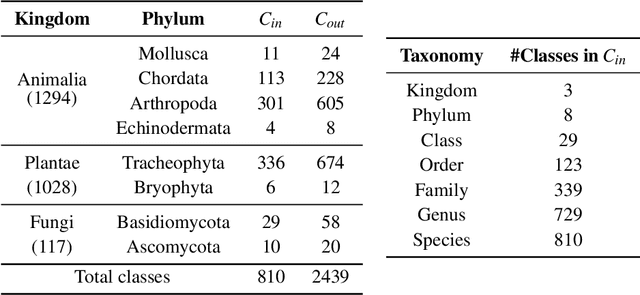
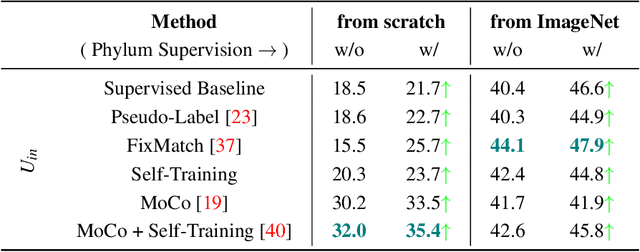
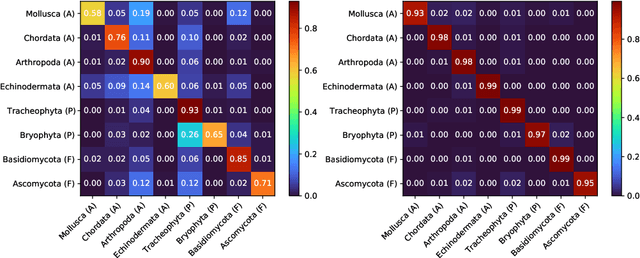
We propose techniques to incorporate coarse taxonomic labels to train image classifiers in fine-grained domains. Such labels can often be obtained with a smaller effort for fine-grained domains such as the natural world where categories are organized according to a biological taxonomy. On the Semi-iNat dataset consisting of 810 species across three Kingdoms, incorporating Phylum labels improves the Species level classification accuracy by 6% in a transfer learning setting using ImageNet pre-trained models. Incorporating the hierarchical label structure with a state-of-the-art semi-supervised learning algorithm called FixMatch improves the performance further by 1.3%. The relative gains are larger when detailed labels such as Class or Order are provided, or when models are trained from scratch. However, we find that most methods are not robust to the presence of out-of-domain data from novel classes. We propose a technique to select relevant data from a large collection of unlabeled images guided by the hierarchy which improves the robustness. Overall, our experiments show that semi-supervised learning with coarse taxonomic labels are practical for training classifiers in fine-grained domains.
Deep Learning for HDR Imaging: State-of-the-Art and Future Trends
Nov 02, 2021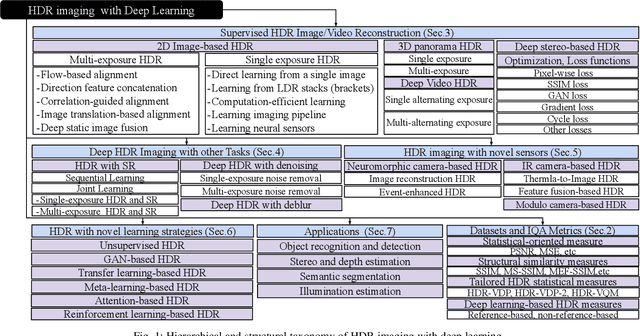
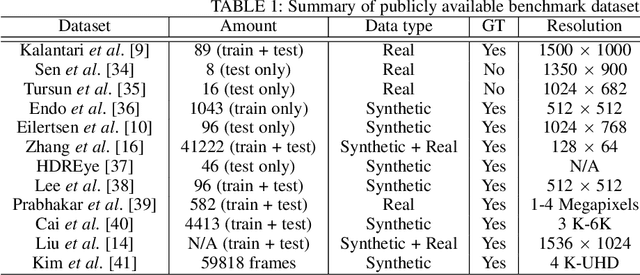
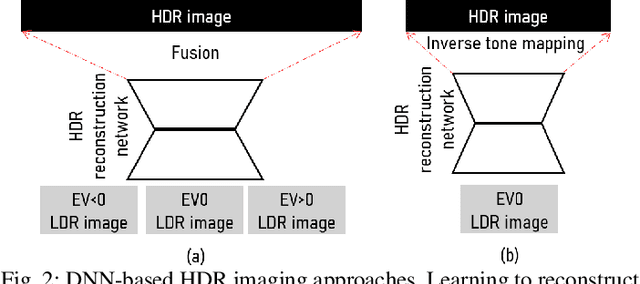
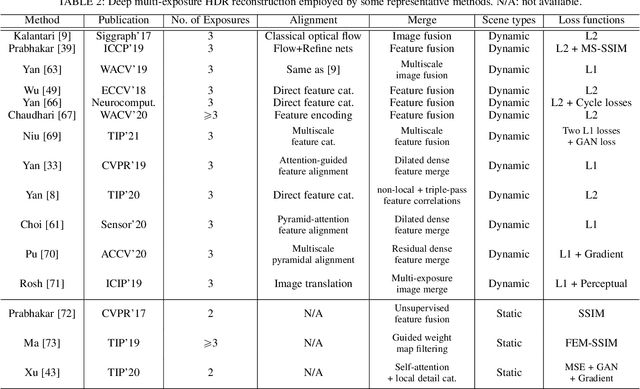
High dynamic range (HDR) imaging is a technique that allows an extensive dynamic range of exposures, which is important in image processing, computer graphics, and computer vision. In recent years, there has been a significant advancement in HDR imaging using deep learning (DL). This study conducts a comprehensive and insightful survey and analysis of recent developments in deep HDR imaging methodologies. We hierarchically and structurally group existing deep HDR imaging methods into five categories based on (1) number/domain of input exposures, (2) number of learning tasks, (3) novel sensor data, (4) novel learning strategies, and (5) applications. Importantly, we provide a constructive discussion on each category regarding its potential and challenges. Moreover, we review some crucial aspects of deep HDR imaging, such as datasets and evaluation metrics. Finally, we highlight some open problems and point out future research directions.
Poison Ink: Robust and Invisible Backdoor Attack
Aug 14, 2021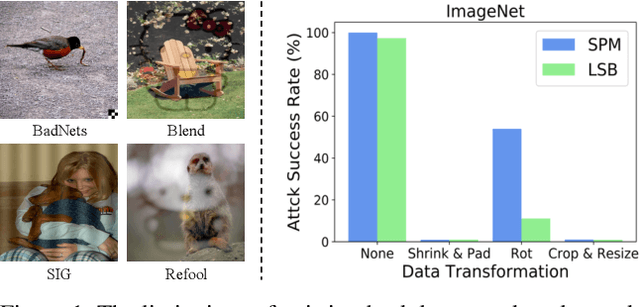
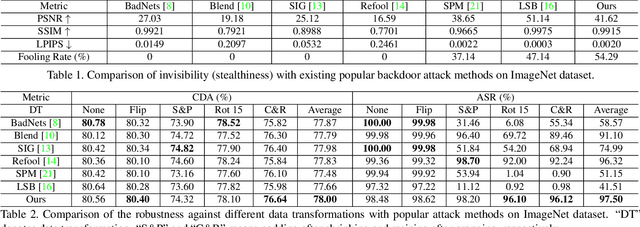
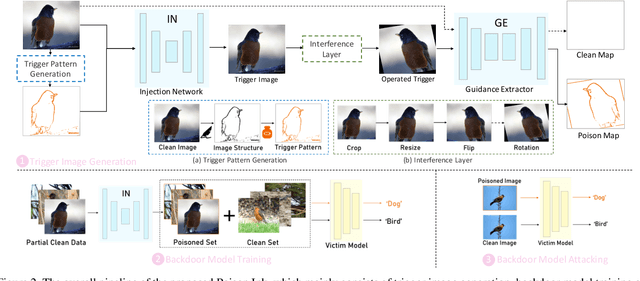

Recent research shows deep neural networks are vulnerable to different types of attacks, such as adversarial attack, data poisoning attack and backdoor attack. Among them, backdoor attack is the most cunning one and can occur in almost every stage of deep learning pipeline. Therefore, backdoor attack has attracted lots of interests from both academia and industry. However, most existing backdoor attack methods are either visible or fragile to some effortless pre-processing such as common data transformations. To address these limitations, we propose a robust and invisible backdoor attack called "Poison Ink". Concretely, we first leverage the image structures as target poisoning areas, and fill them with poison ink (information) to generate the trigger pattern. As the image structure can keep its semantic meaning during the data transformation, such trigger pattern is inherently robust to data transformations. Then we leverage a deep injection network to embed such trigger pattern into the cover image to achieve stealthiness. Compared to existing popular backdoor attack methods, Poison Ink outperforms both in stealthiness and robustness. Through extensive experiments, we demonstrate Poison Ink is not only general to different datasets and network architectures, but also flexible for different attack scenarios. Besides, it also has very strong resistance against many state-of-the-art defense techniques.
Learning to Downsample for Segmentation of Ultra-High Resolution Images
Sep 22, 2021
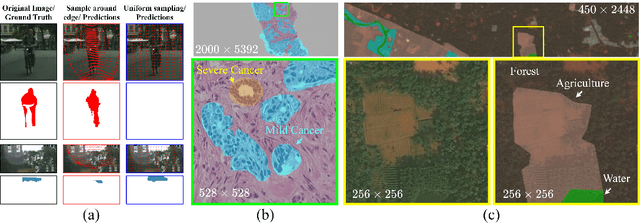
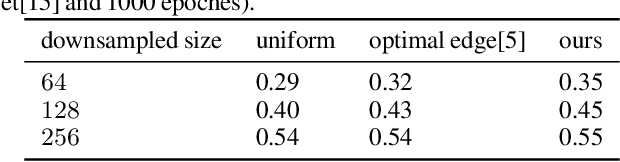

Segmentation of ultra-high resolution images with deep learning is challenging because of their enormous size, often millions or even billions of pixels. Typical solutions drastically downsample the image uniformly to meet memory constraints, implicitly assuming all pixels equally important by sampling at the same density at all spatial locations. However this assumption is not true and compromises the performance of deep learning techniques that have proved powerful on standard-sized images. For example with uniform downsampling, see green boxed region in Fig.1, the rider and bike do not have enough corresponding samples while the trees and buildings are oversampled, and lead to a negative effect on the segmentation prediction from the low-resolution downsampled image. In this work we show that learning the spatially varying downsampling strategy jointly with segmentation offers advantages in segmenting large images with limited computational budget. Fig.1 shows that our method adapts the sampling density over different locations so that more samples are collected from the small important regions and less from the others, which in turn leads to better segmentation accuracy. We show on two public and one local high-resolution datasets that our method consistently learns sampling locations preserving more information and boosting segmentation accuracy over baseline methods.
Adaptive Subsampling for ROI-based Visual Tracking: Algorithms and FPGA Implementation
Dec 17, 2021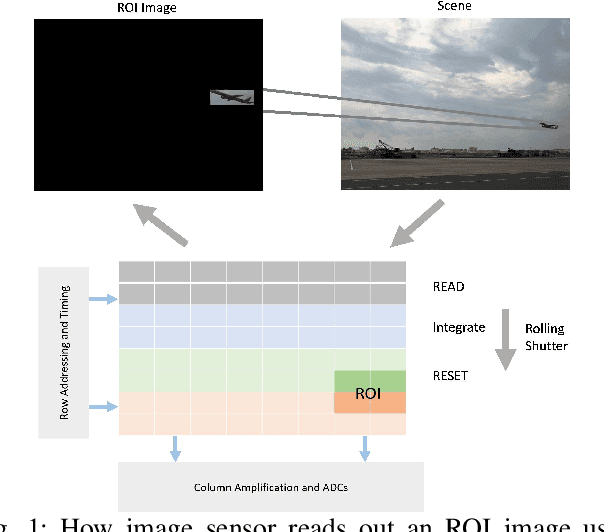

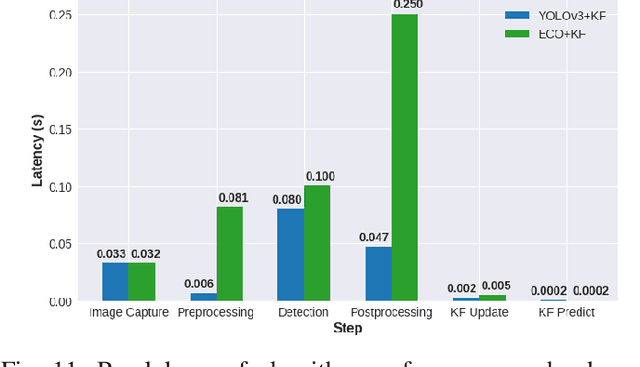

There is tremendous scope for improving the energy efficiency of embedded vision systems by incorporating programmable region-of-interest (ROI) readout in the image sensor design. In this work, we study how ROI programmability can be leveraged for tracking applications by anticipating where the ROI will be located in future frames and switching pixels off outside of this region. We refer to this process of ROI prediction and corresponding sensor configuration as adaptive subsampling. Our adaptive subsampling algorithms comprise an object detector and an ROI predictor (Kalman filter) which operate in conjunction to optimize the energy efficiency of the vision pipeline with the end task being object tracking. To further facilitate the implementation of our adaptive algorithms in real life, we select a candidate algorithm and map it onto an FPGA. Leveraging Xilinx Vitis AI tools, we designed and accelerated a YOLO object detector-based adaptive subsampling algorithm. In order to further improve the algorithm post-deployment, we evaluated several competing baselines on the OTB100 and LaSOT datasets. We found that coupling the ECO tracker with the Kalman filter has a competitive AUC score of 0.4568 and 0.3471 on the OTB100 and LaSOT datasets respectively. Further, the power efficiency of this algorithm is on par with, and in a couple of instances superior to, the other baselines. The ECO-based algorithm incurs a power consumption of approximately 4 W averaged across both datasets while the YOLO-based approach requires power consumption of approximately 6 W (as per our power consumption model). In terms of accuracy-latency tradeoff, the ECO-based algorithm provides near-real-time performance (19.23 FPS) while managing to attain competitive tracking precision.
VAE/WGAN-Based Image Representation Learning For Pose-Preserving Seamless Identity Replacement In Facial Images
Mar 02, 2020We present a novel variational generative adversarial network (VGAN) based on Wasserstein loss to learn a latent representation from a face image that is invariant to identity but preserves head-pose information. This facilitates synthesis of a realistic face image with the same head pose as a given input image, but with a different identity. One application of this network is in privacy-sensitive scenarios; after identity replacement in an image, utility, such as head pose, can still be recovered. Extensive experimental validation on synthetic and real human-face image datasets performed under 3 threat scenarios confirms the ability of the proposed network to preserve head pose of the input image, mask the input identity, and synthesize a good-quality realistic face image of a desired identity. We also show that our network can be used to perform pose-preserving identity morphing and identity-preserving pose morphing. The proposed method improves over a recent state-of-the-art method in terms of quantitative metrics as well as synthesized image quality.
* 6 pages, 5 figures, 2019 IEEE 29th International Workshop on Machine Learning for Signal Processing (MLSP)
Introducing the structural bases of typicality effects in deep learning
Jul 07, 2021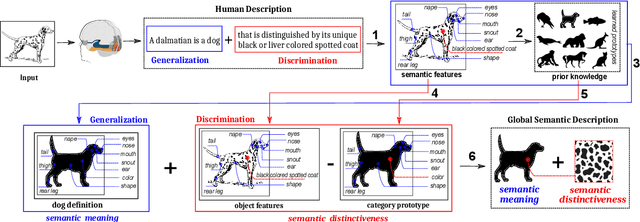
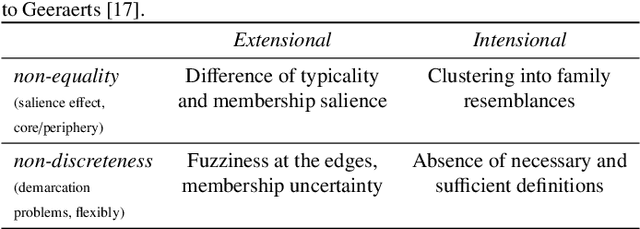
In this paper, we hypothesize that the effects of the degree of typicality in natural semantic categories can be generated based on the structure of artificial categories learned with deep learning models. Motivated by the human approach to representing natural semantic categories and based on the Prototype Theory foundations, we propose a novel Computational Prototype Model (CPM) to represent the internal structure of semantic categories. Unlike other prototype learning approaches, our mathematical framework proposes a first approach to provide deep neural networks with the ability to model abstract semantic concepts such as category central semantic meaning, typicality degree of an object's image, and family resemblance relationship. We proposed several methodologies based on the typicality's concept to evaluate our CPM-model in image semantic processing tasks such as image classification, a global semantic description, and transfer learning. Our experiments on different image datasets, such as ImageNet and Coco, showed that our approach might be an admissible proposition in the effort to endow machines with greater power of abstraction for the semantic representation of objects' categories.
Spatial-Angular Interaction for Light Field Image Super-Resolution
Dec 17, 2019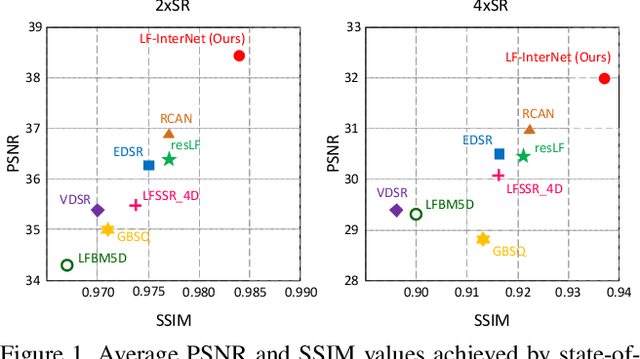
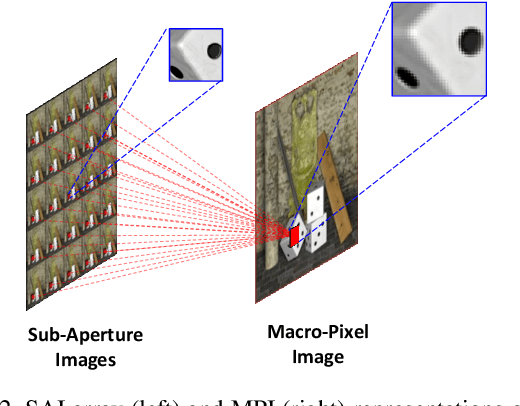
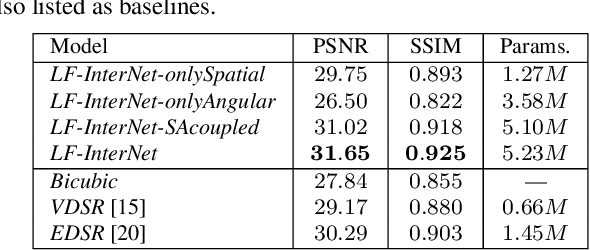
Light field (LF) cameras record both intensity and directions of light rays, and capture scenes from a number of viewpoints. Both information within each perspective (i.e., spatial information) and among different perspectives (i.e., angular information) is beneficial to image super-resolution (SR). In this paper, we propose a spatial-angular interactive network (namely, LF-InterNet) for LF image SR. In our method, spatial and angular features are separately extracted from the input LF using two specifically designed convolutions. These extracted features are then repetitively interacted to incorporate both spatial and angular information. Finally, the interacted spatial and angular features are fused to super-resolve each sub-aperture image. Experiments on 6 public LF datasets have demonstrated the superiority of our method. As compared to existing LF and single image SR methods, our method can recover much more details, and achieves significant improvements over the state-of-the-arts in terms of PSNR and SSIM.