 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Scale-Aware Dynamic Network for Continuous-Scale Super-Resolution
Oct 29, 2021
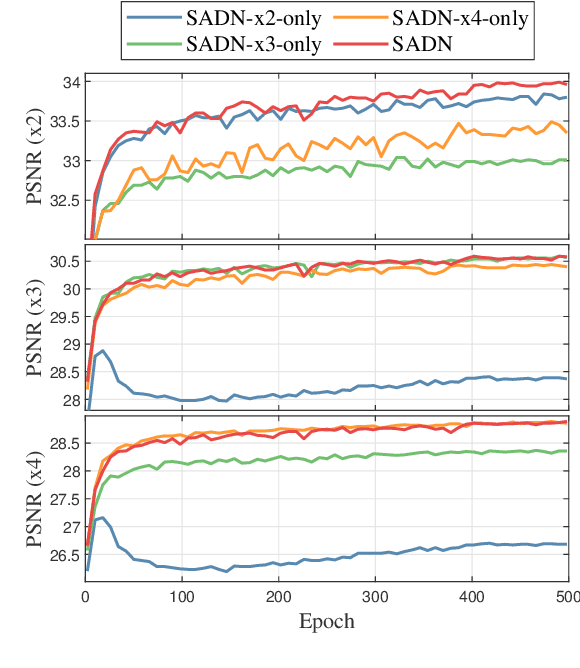

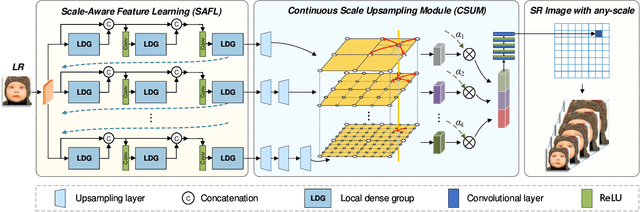
Single-image super-resolution (SR) with fixed and discrete scale factors has achieved great progress due to the development of deep learning technology. However, the continuous-scale SR, which aims to use a single model to process arbitrary (integer or non-integer) scale factors, is still a challenging task. The existing SR models generally adopt static convolution to extract features, and thus unable to effectively perceive the change of scale factor, resulting in limited generalization performance on multi-scale SR tasks. Moreover, the existing continuous-scale upsampling modules do not make full use of multi-scale features and face problems such as checkerboard artifacts in the SR results and high computational complexity. To address the above problems, we propose a scale-aware dynamic network (SADN) for continuous-scale SR. First, we propose a scale-aware dynamic convolutional (SAD-Conv) layer for the feature learning of multiple SR tasks with various scales. The SAD-Conv layer can adaptively adjust the attention weights of multiple convolution kernels based on the scale factor, which enhances the expressive power of the model with a negligible extra computational cost. Second, we devise a continuous-scale upsampling module (CSUM) with the multi-bilinear local implicit function (MBLIF) for any-scale upsampling. The CSUM constructs multiple feature spaces with gradually increasing scales to approximate the continuous feature representation of an image, and then the MBLIF makes full use of multi-scale features to map arbitrary coordinates to RGB values in high-resolution space. We evaluate our SADN using various benchmarks. The experimental results show that the CSUM can replace the previous fixed-scale upsampling layers and obtain a continuous-scale SR network while maintaining performance. Our SADN uses much fewer parameters and outperforms the state-of-the-art SR methods.
A Volumetric Transformer for Accurate 3D Tumor Segmentation
Nov 26, 2021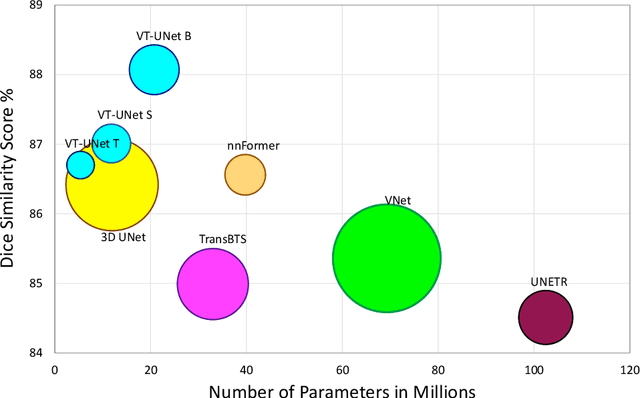
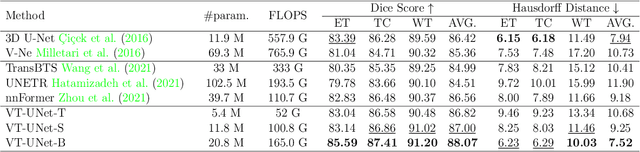
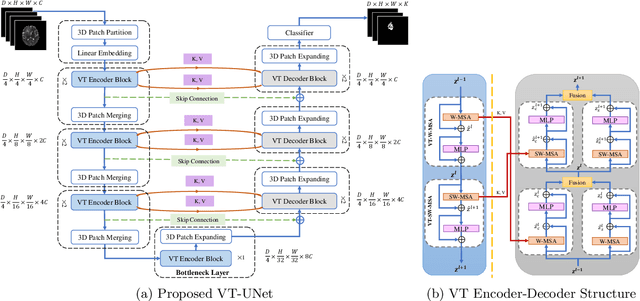
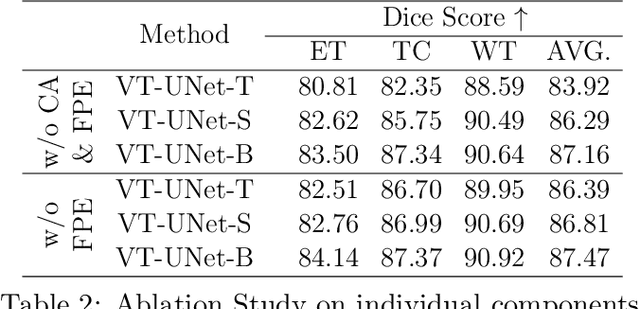
This paper presents a Transformer architecture for volumetric medical image segmentation. Designing a computationally efficient Transformer architecture for volumetric segmentation is a challenging task. It requires keeping a complex balance in encoding local and global spatial cues, and preserving information along all axes of the volumetric data. The proposed volumetric Transformer has a U-shaped encoder-decoder design that processes the input voxels in their entirety. Our encoder has two consecutive self-attention layers to simultaneously encode local and global cues, and our decoder has novel parallel shifted window based self and cross attention blocks to capture fine details for boundary refinement by subsuming Fourier position encoding. Our proposed design choices result in a computationally efficient architecture, which demonstrates promising results on Brain Tumor Segmentation (BraTS) 2021, and Medical Segmentation Decathlon (Pancreas and Liver) datasets for tumor segmentation. We further show that the representations learned by our model transfer better across-datasets and are robust against data corruptions. \href{https://github.com/himashi92/VT-UNet}{Our code implementation is publicly available}.
KNAS: Green Neural Architecture Search
Nov 26, 2021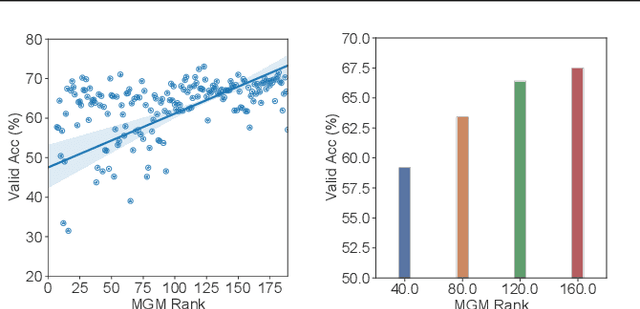
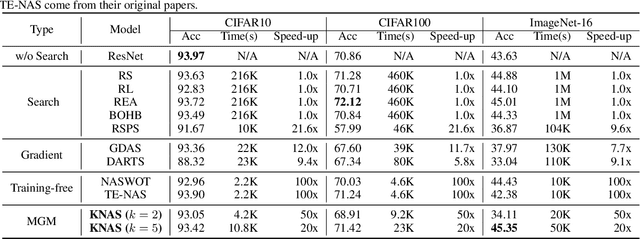

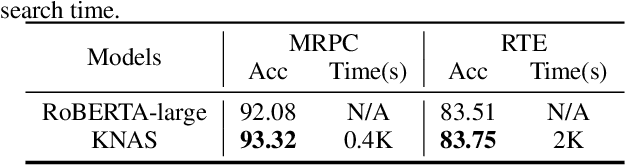
Many existing neural architecture search (NAS) solutions rely on downstream training for architecture evaluation, which takes enormous computations. Considering that these computations bring a large carbon footprint, this paper aims to explore a green (namely environmental-friendly) NAS solution that evaluates architectures without training. Intuitively, gradients, induced by the architecture itself, directly decide the convergence and generalization results. It motivates us to propose the gradient kernel hypothesis: Gradients can be used as a coarse-grained proxy of downstream training to evaluate random-initialized networks. To support the hypothesis, we conduct a theoretical analysis and find a practical gradient kernel that has good correlations with training loss and validation performance. According to this hypothesis, we propose a new kernel based architecture search approach KNAS. Experiments show that KNAS achieves competitive results with orders of magnitude faster than "train-then-test" paradigms on image classification tasks. Furthermore, the extremely low search cost enables its wide applications. The searched network also outperforms strong baseline RoBERTA-large on two text classification tasks. Codes are available at \url{https://github.com/Jingjing-NLP/KNAS} .
VLBInet: Radio Interferometry Data Classification for EHT with Neural Networks
Oct 14, 2021

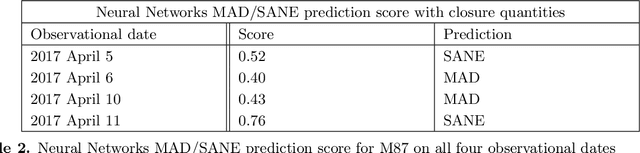
The Event Horizon Telescope (EHT) recently released the first horizon-scale images of the black hole in M87. Combined with other astronomical data, these images constrain the mass and spin of the hole as well as the accretion rate and magnetic flux trapped on the hole. An important question for the EHT is how well key parameters, such as trapped magnetic flux and the associated disk models, can be extracted from present and future EHT VLBI data products. The process of modeling visibilities and analyzing them is complicated by the fact that the data are sparsely sampled in the Fourier domain while most of the theory/simulation is constructed in the image domain. Here we propose a data-driven approach to analyze complex visibilities and closure quantities for radio interferometric data with neural networks. Using mock interferometric data, we show that our neural networks are able to infer the accretion state as either high magnetic flux (MAD) or low magnetic flux (SANE), suggesting that it is possible to perform parameter extraction directly in the visibility domain without image reconstruction. We have applied VLBInet to real M87 EHT data taken on four different days in 2017 (April 5, 6, 10, 11), and our neural networks give a score prediction 0.52, 0.4, 0.43, 0.76 for each day, with an average score 0.53, which shows no significant indication for the data to lean toward either the MAD or SANE state.
Cross-Modal Hierarchical Modelling for Fine-Grained Sketch Based Image Retrieval
Jul 29, 2020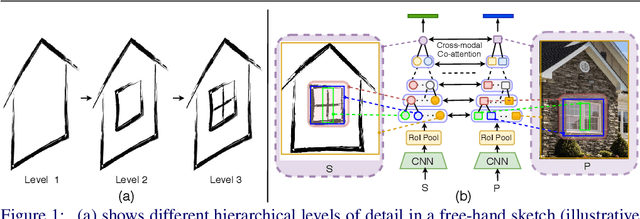
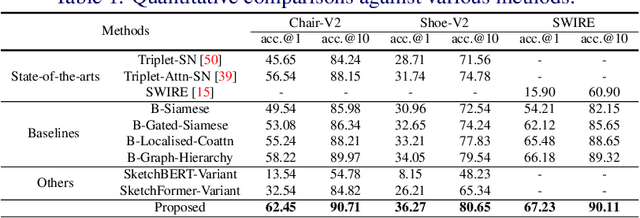
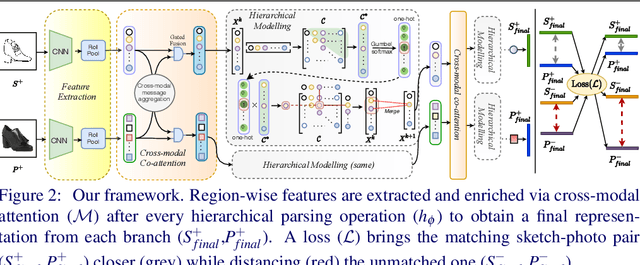
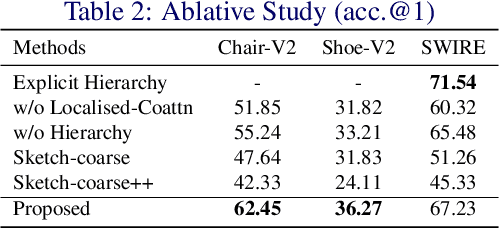
Sketch as an image search query is an ideal alternative to text in capturing the fine-grained visual details. Prior successes on fine-grained sketch-based image retrieval (FG-SBIR) have demonstrated the importance of tackling the unique traits of sketches as opposed to photos, e.g., temporal vs. static, strokes vs. pixels, and abstract vs. pixel-perfect. In this paper, we study a further trait of sketches that has been overlooked to date, that is, they are hierarchical in terms of the levels of detail -- a person typically sketches up to various extents of detail to depict an object. This hierarchical structure is often visually distinct. In this paper, we design a novel network that is capable of cultivating sketch-specific hierarchies and exploiting them to match sketch with photo at corresponding hierarchical levels. In particular, features from a sketch and a photo are enriched using cross-modal co-attention, coupled with hierarchical node fusion at every level to form a better embedding space to conduct retrieval. Experiments on common benchmarks show our method to outperform state-of-the-arts by a significant margin.
LegoDNN: Block-grained Scaling of Deep Neural Networks for Mobile Vision
Dec 18, 2021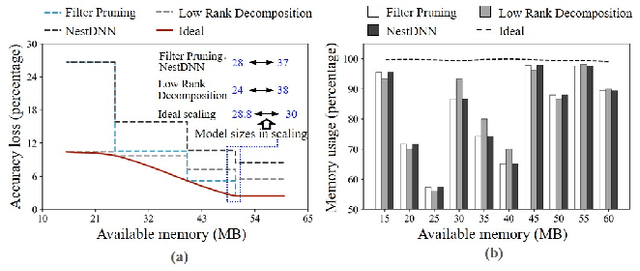
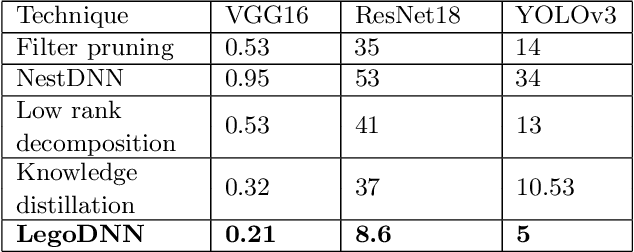
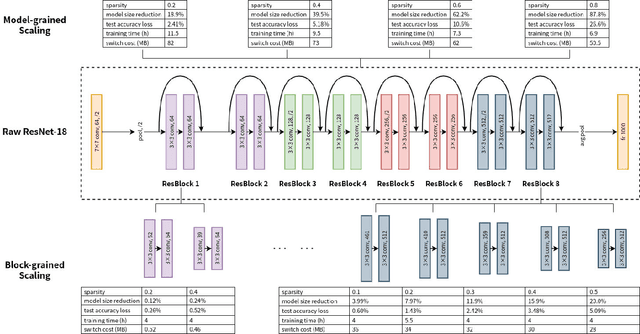
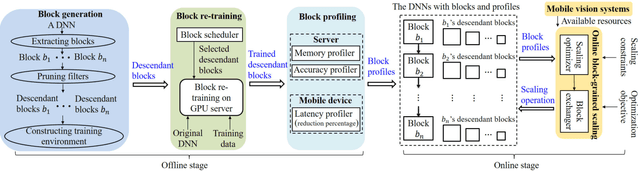
Deep neural networks (DNNs) have become ubiquitous techniques in mobile and embedded systems for applications such as image/object recognition and classification. The trend of executing multiple DNNs simultaneously exacerbate the existing limitations of meeting stringent latency/accuracy requirements on resource constrained mobile devices. The prior art sheds light on exploring the accuracy-resource tradeoff by scaling the model sizes in accordance to resource dynamics. However, such model scaling approaches face to imminent challenges: (i) large space exploration of model sizes, and (ii) prohibitively long training time for different model combinations. In this paper, we present LegoDNN, a lightweight, block-grained scaling solution for running multi-DNN workloads in mobile vision systems. LegoDNN guarantees short model training times by only extracting and training a small number of common blocks (e.g. 5 in VGG and 8 in ResNet) in a DNN. At run-time, LegoDNN optimally combines the descendant models of these blocks to maximize accuracy under specific resources and latency constraints, while reducing switching overhead via smart block-level scaling of the DNN. We implement LegoDNN in TensorFlow Lite and extensively evaluate it against state-of-the-art techniques (FLOP scaling, knowledge distillation and model compression) using a set of 12 popular DNN models. Evaluation results show that LegoDNN provides 1,296x to 279,936x more options in model sizes without increasing training time, thus achieving as much as 31.74% improvement in inference accuracy and 71.07% reduction in scaling energy consumptions.
* 13 pages, 15 figures
Adversarial Attacks on Binary Image Recognition Systems
Oct 22, 2020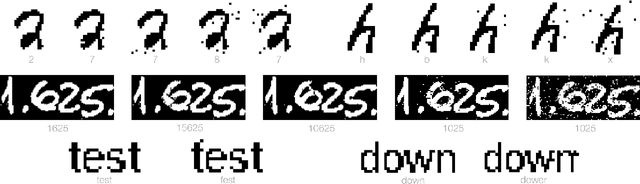
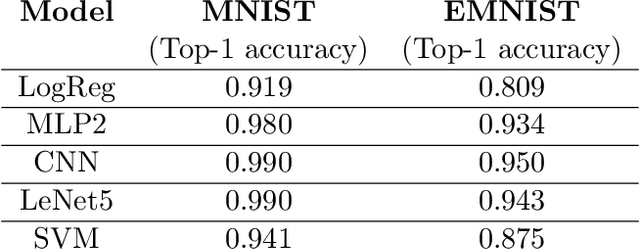
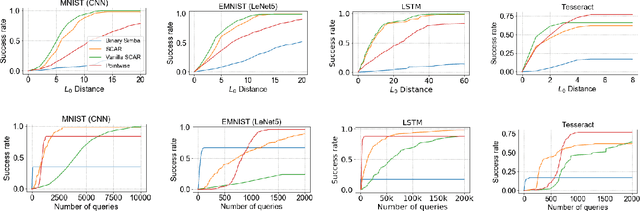

We initiate the study of adversarial attacks on models for binary (i.e. black and white) image classification. Although there has been a great deal of work on attacking models for colored and grayscale images, little is known about attacks on models for binary images. Models trained to classify binary images are used in text recognition applications such as check processing, license plate recognition, invoice processing, and many others. In contrast to colored and grayscale images, the search space of attacks on binary images is extremely restricted and noise cannot be hidden with minor perturbations in each pixel. Thus, the optimization landscape of attacks on binary images introduces new fundamental challenges. In this paper we introduce a new attack algorithm called SCAR, designed to fool classifiers of binary images. We show that SCAR significantly outperforms existing $L_0$ attacks applied to the binary setting and use it to demonstrate the vulnerability of real-world text recognition systems. SCAR's strong performance in practice contrasts with the existence of classifiers that are provably robust to large perturbations. In many cases, altering a single pixel is sufficient to trick Tesseract, a popular open-source text recognition system, to misclassify a word as a different word in the English dictionary. We also license software from providers of check processing systems to most of the major US banks and demonstrate the vulnerability of check recognitions for mobile deposits. These systems are substantially harder to fool since they classify both the handwritten amounts in digits and letters, independently. Nevertheless, we generalize SCAR to design attacks that fool state-of-the-art check processing systems using unnoticeable perturbations that lead to misclassification of deposit amounts. Consequently, this is a powerful method to perform financial fraud.
Self-supervised Image Enhancement Network: Training with Low Light Images Only
Feb 26, 2020
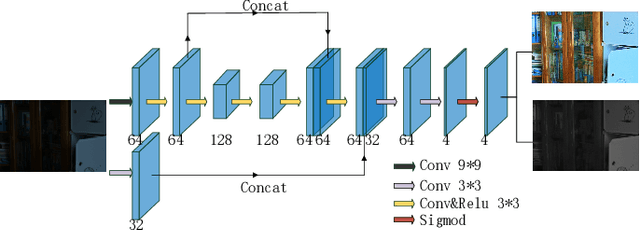
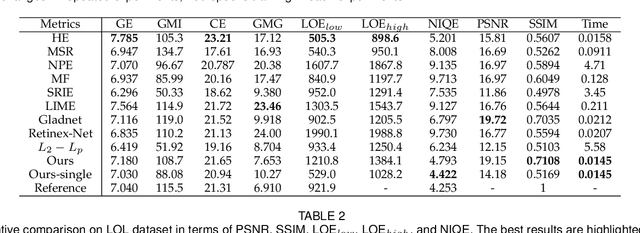
This paper proposes a self-supervised low light image enhancement method based on deep learning. Inspired by information entropy theory and Retinex model, we proposed a maximum entropy based Retinex model. With this model, a very simple network can separate the illumination and reflectance, and the network can be trained with low light images only. We introduce a constraint that the maximum channel of the reflectance conforms to the maximum channel of the low light image and its entropy should be largest in our model to achieve self-supervised learning. Our model is very simple and does not rely on any well-designed data set (even one low light image can complete the training). The network only needs minute-level training to achieve image enhancement. It can be proved through experiments that the proposed method has reached the state-of-the-art in terms of processing speed and effect.
Understanding the Impact of UGC Specificities on Translation Quality
Oct 24, 2021
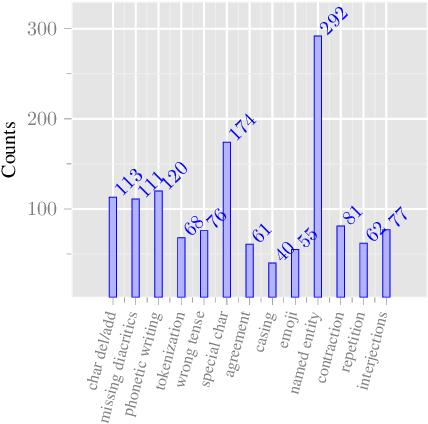
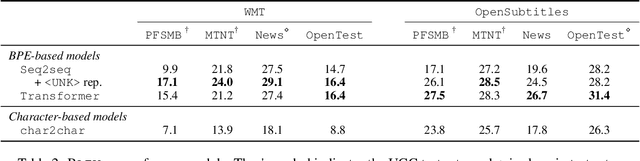
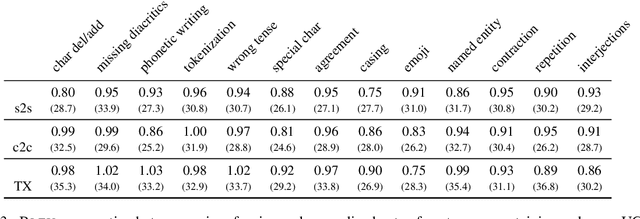
This work takes a critical look at the evaluation of user-generated content automatic translation, the well-known specificities of which raise many challenges for MT. Our analyses show that measuring the average-case performance using a standard metric on a UGC test set falls far short of giving a reliable image of the UGC translation quality. That is why we introduce a new data set for the evaluation of UGC translation in which UGC specificities have been manually annotated using a fine-grained typology. Using this data set, we conduct several experiments to measure the impact of different kinds of UGC specificities on translation quality, more precisely than previously possible.
Unsupervised Deformable Medical Image Registration via Pyramidal Residual Deformation Fields Estimation
Apr 16, 2020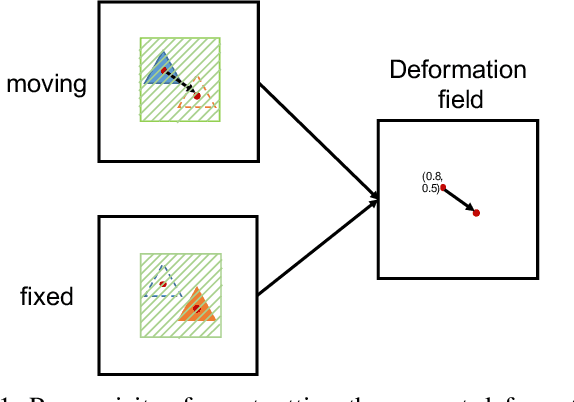
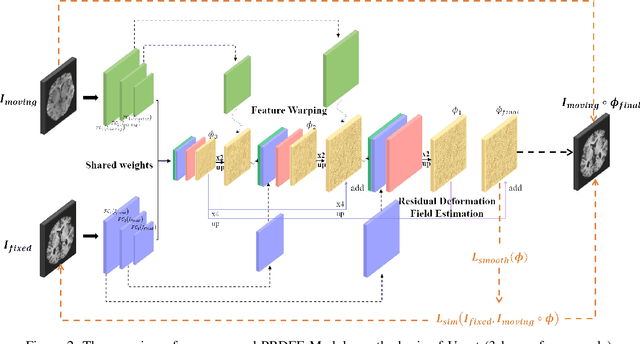


Deformation field estimation is an important and challenging issue in many medical image registration applications. In recent years, deep learning technique has become a promising approach for simplifying registration problems, and has been gradually applied to medical image registration. However, most existing deep learning registrations do not consider the problem that when the receptive field cannot cover the corresponding features in the moving image and the fixed image, it cannot output accurate displacement values. In fact, due to the limitation of the receptive field, the 3 x 3 kernel has difficulty in covering the corresponding features at high/original resolution. Multi-resolution and multi-convolution techniques can improve but fail to avoid this problem. In this study, we constructed pyramidal feature sets on moving and fixed images and used the warped moving and fixed features to estimate their "residual" deformation field at each scale, called the Pyramidal Residual Deformation Field Estimation module (PRDFE-Module). The "total" deformation field at each scale was computed by upsampling and weighted summing all the "residual" deformation fields at all its previous scales, which can effectively and accurately transfer the deformation fields from low resolution to high resolution and is used for warping the moving features at each scale. Simulation and real brain data results show that our method improves the accuracy of the registration and the rationality of the deformation field.