 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Estimating Barycenters of Distributions with Neural Optimal Transport
Feb 06, 2024
Given a collection of probability measures, a practitioner sometimes needs to find an "average" distribution which adequately aggregates reference distributions. A theoretically appealing notion of such an average is the Wasserstein barycenter, which is the primal focus of our work. By building upon the dual formulation of Optimal Transport (OT), we propose a new scalable approach for solving the Wasserstein barycenter problem. Our methodology is based on the recent Neural OT solver: it has bi-level adversarial learning objective and works for general cost functions. These are key advantages of our method, since the typical adversarial algorithms leveraging barycenter tasks utilize tri-level optimization and focus mostly on quadratic cost. We also establish theoretical error bounds for our proposed approach and showcase its applicability and effectiveness on illustrative scenarios and image data setups.
Weakly Supervised Learners for Correction of AI Errors with Provable Performance Guarantees
Feb 06, 2024We present a new methodology for handling AI errors by introducing weakly supervised AI error correctors with a priori performance guarantees. These AI correctors are auxiliary maps whose role is to moderate the decisions of some previously constructed underlying classifier by either approving or rejecting its decisions. The rejection of a decision can be used as a signal to suggest abstaining from making a decision. A key technical focus of the work is in providing performance guarantees for these new AI correctors through bounds on the probabilities of incorrect decisions. These bounds are distribution agnostic and do not rely on assumptions on the data dimension. Our empirical example illustrates how the framework can be applied to improve the performance of an image classifier in a challenging real-world task where training data are scarce.
A Review on Digital Pixel Sensors
Feb 07, 2024Digital pixel sensor (DPS) has evolved as a pivotal component in modern imaging systems and has the potential to revolutionize various fields such as medical imaging, astronomy, surveillance, IoT devices, etc. Compared to analog pixel sensors, the DPS offers high speed and good image quality. However, the introduced intrinsic complexity within each pixel, primarily attributed to the accommodation of the ADC circuit, engenders a substantial increase in the pixel pitch. Unfortunately, such a pronounced escalation in pixel pitch drastically undermines the feasibility of achieving high-density integration, which is an obstacle that significantly narrows down the field of potential applications. Nonetheless, designing compact conversion circuits along with strategic integration of 3D architectural paradigms can be a potential remedy to the prevailing situation. This review article presents a comprehensive overview of the vast area of DPS technology. The operating principles, advantages, and challenges of different types of DPS circuits have been analyzed. We categorize the schemes into several categories based on ADC operation. A comparative study based on different performance metrics has also been showcased for a well-rounded understanding.
LGM: Large Multi-View Gaussian Model for High-Resolution 3D Content Creation
Feb 07, 20243D content creation has achieved significant progress in terms of both quality and speed. Although current feed-forward models can produce 3D objects in seconds, their resolution is constrained by the intensive computation required during training. In this paper, we introduce Large Multi-View Gaussian Model (LGM), a novel framework designed to generate high-resolution 3D models from text prompts or single-view images. Our key insights are two-fold: 1) 3D Representation: We propose multi-view Gaussian features as an efficient yet powerful representation, which can then be fused together for differentiable rendering. 2) 3D Backbone: We present an asymmetric U-Net as a high-throughput backbone operating on multi-view images, which can be produced from text or single-view image input by leveraging multi-view diffusion models. Extensive experiments demonstrate the high fidelity and efficiency of our approach. Notably, we maintain the fast speed to generate 3D objects within 5 seconds while boosting the training resolution to 512, thereby achieving high-resolution 3D content generation.
FM-Fusion: Instance-aware Semantic Mapping Boosted by Vision-Language Foundation Models
Feb 07, 2024Semantic mapping based on the supervised object detectors is sensitive to image distribution. In real-world environments, the object detection and segmentation performance can lead to a major drop, preventing the use of semantic mapping in a wider domain. On the other hand, the development of vision-language foundation models demonstrates a strong zero-shot transferability across data distribution. It provides an opportunity to construct generalizable instance-aware semantic maps. Hence, this work explores how to boost instance-aware semantic mapping from object detection generated from foundation models. We propose a probabilistic label fusion method to predict close-set semantic classes from open-set label measurements. An instance refinement module merges the over-segmented instances caused by inconsistent segmentation. We integrate all the modules into a unified semantic mapping system. Reading a sequence of RGB-D input, our work incrementally reconstructs an instance-aware semantic map. We evaluate the zero-shot performance of our method in ScanNet and SceneNN datasets. Our method achieves 40.3 mean average precision (mAP) on the ScanNet semantic instance segmentation task. It outperforms the traditional semantic mapping method significantly.
DMAT: A Dynamic Mask-Aware Transformer for Human De-occlusion
Feb 07, 2024Human de-occlusion, which aims to infer the appearance of invisible human parts from an occluded image, has great value in many human-related tasks, such as person re-id, and intention inference. To address this task, this paper proposes a dynamic mask-aware transformer (DMAT), which dynamically augments information from human regions and weakens that from occlusion. First, to enhance token representation, we design an expanded convolution head with enlarged kernels, which captures more local valid context and mitigates the influence of surrounding occlusion. To concentrate on the visible human parts, we propose a novel dynamic multi-head human-mask guided attention mechanism through integrating multiple masks, which can prevent the de-occluded regions from assimilating to the background. Besides, a region upsampling strategy is utilized to alleviate the impact of occlusion on interpolated images. During model learning, an amodal loss is developed to further emphasize the recovery effect of human regions, which also refines the model's convergence. Extensive experiments on the AHP dataset demonstrate its superior performance compared to recent state-of-the-art methods.
EvoSeed: Unveiling the Threat on Deep Neural Networks with Real-World Illusions
Feb 07, 2024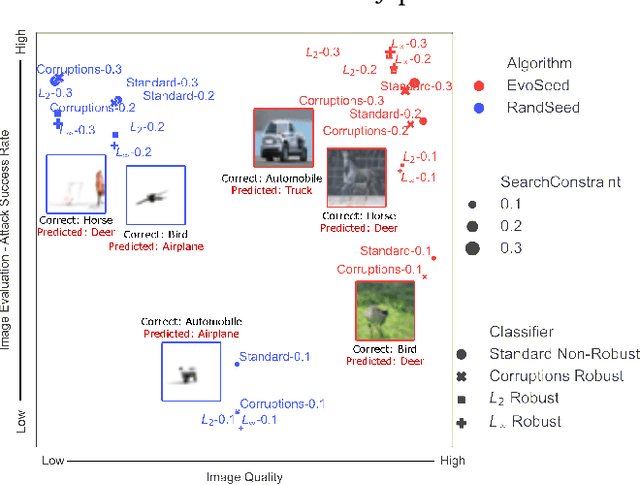
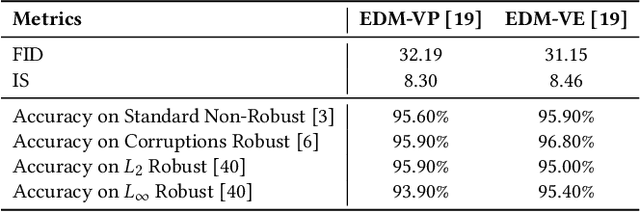
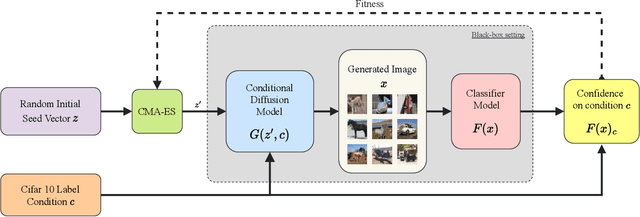
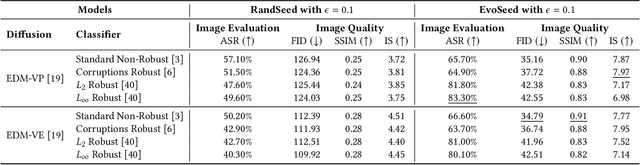
Deep neural networks are exploited using natural adversarial samples, which have no impact on human perception but are misclassified. Current approaches often rely on the white-box nature of deep neural networks to generate these adversarial samples or alter the distribution of adversarial samples compared to training distribution. To alleviate the limitations of current approaches, we propose EvoSeed, a novel evolutionary strategy-based search algorithmic framework to generate natural adversarial samples. Our EvoSeed framework uses auxiliary Diffusion and Classifier models to operate in a model-agnostic black-box setting. We employ CMA-ES to optimize the search for an adversarial seed vector, which, when processed by the Conditional Diffusion Model, results in an unrestricted natural adversarial sample misclassified by the Classifier Model. Experiments show that generated adversarial images are of high image quality and are transferable to different classifiers. Our approach demonstrates promise in enhancing the quality of adversarial samples using evolutionary algorithms. We hope our research opens new avenues to enhance the robustness of deep neural networks in real-world scenarios. Project Website can be accessed at \url{https://shashankkotyan.github.io/EvoSeed}.
Riemannian Preconditioned LoRA for Fine-Tuning Foundation Models
Feb 07, 2024In this work we study the enhancement of Low Rank Adaptation (LoRA) fine-tuning procedure by introducing a Riemannian preconditioner in its optimization step. Specifically, we introduce an $r\times r$ preconditioner in each gradient step where $r$ is the LoRA rank. This preconditioner requires a small change to existing optimizer code and creates virtually minuscule storage and runtime overhead. Our experimental results with both large language models and text-to-image diffusion models show that with our preconditioner, the convergence and reliability of SGD and AdamW can be significantly enhanced. Moreover, the training process becomes much more robust to hyperparameter choices such as learning rate. Theoretically, we show that fine-tuning a two-layer ReLU network in the convex paramaterization with our preconditioner has convergence rate independent of condition number of the data matrix. This new Riemannian preconditioner, previously explored in classic low-rank matrix recovery, is introduced to deep learning tasks for the first time in our work. We release our code at https://github.com/pilancilab/Riemannian_Preconditioned_LoRA.
Common Sense Reasoning for Deep Fake Detection
Jan 31, 2024State-of-the-art approaches rely on image-based features extracted via neural networks for the deepfake detection binary classification. While these approaches trained in the supervised sense extract likely fake features, they may fall short in representing unnatural `non-physical' semantic facial attributes -- blurry hairlines, double eyebrows, rigid eye pupils, or unnatural skin shading. However, such facial attributes are generally easily perceived by humans via common sense reasoning. Furthermore, image-based feature extraction methods that provide visual explanation via saliency maps can be hard to be interpreted by humans. To address these challenges, we propose the use of common sense reasoning to model deepfake detection, and extend it to the Deepfake Detection VQA (DD-VQA) task with the aim to model human intuition in explaining the reason behind labeling an image as either real or fake. To this end, we introduce a new dataset that provides answers to the questions related to the authenticity of an image, along with its corresponding explanations. We also propose a Vision and Language Transformer-based framework for the DD-VQA task, incorporating text and image aware feature alignment formulations. Finally, we evaluate our method on both the performance of deepfake detection and the quality of the generated explanations. We hope that this task inspires researchers to explore new avenues for enhancing language-based interpretability and cross-modality applications in the realm of deepfake detection.
Real-time Holistic Robot Pose Estimation with Unknown States
Feb 08, 2024Estimating robot pose from RGB images is a crucial problem in computer vision and robotics. While previous methods have achieved promising performance, most of them presume full knowledge of robot internal states, e.g. ground-truth robot joint angles, which are not always available in real-world scenarios. On the other hand, existing approaches that estimate robot pose without joint state priors suffer from heavy computation burdens and thus cannot support real-time applications. This work addresses the urgent need for efficient robot pose estimation with unknown states. We propose an end-to-end pipeline for real-time, holistic robot pose estimation from a single RGB image, even in the absence of known robot states. Our method decomposes the problem into estimating camera-to-robot rotation, robot state parameters, keypoint locations, and root depth. We further design a corresponding neural network module for each task. This approach allows for learning multi-facet representations and facilitates sim-to-real transfer through self-supervised learning. Notably, our method achieves inference with a single feedforward, eliminating the need for costly test-time iterative optimization. As a result, it delivers a 12-time speed boost with state-of-the-art accuracy, enabling real-time holistic robot pose estimation for the first time. Code is available at https://oliverbansk.github.io/Holistic-Robot-Pose/.