 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Distilling portable Generative Adversarial Networks for Image Translation
Mar 07, 2020
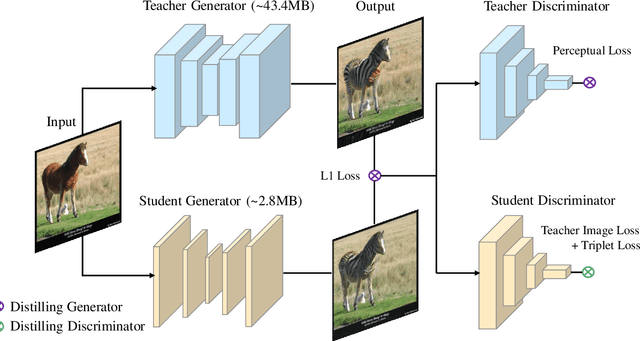
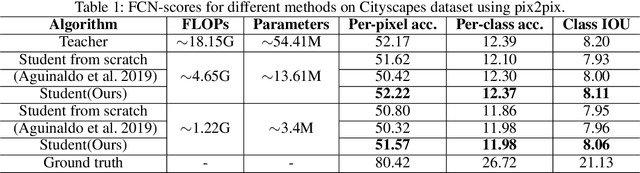

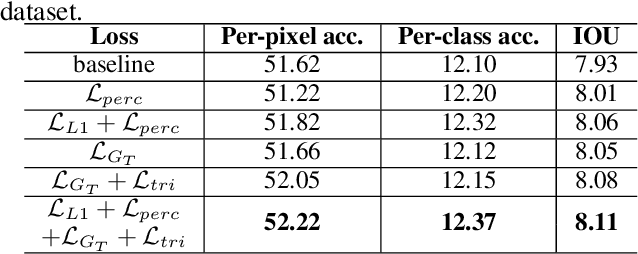
Despite Generative Adversarial Networks (GANs) have been widely used in various image-to-image translation tasks, they can be hardly applied on mobile devices due to their heavy computation and storage cost. Traditional network compression methods focus on visually recognition tasks, but never deal with generation tasks. Inspired by knowledge distillation, a student generator of fewer parameters is trained by inheriting the low-level and high-level information from the original heavy teacher generator. To promote the capability of student generator, we include a student discriminator to measure the distances between real images, and images generated by student and teacher generators. An adversarial learning process is therefore established to optimize student generator and student discriminator. Qualitative and quantitative analysis by conducting experiments on benchmark datasets demonstrate that the proposed method can learn portable generative models with strong performance.
Self-Supervised Monocular Scene Decomposition and Depth Estimation
Oct 21, 2021

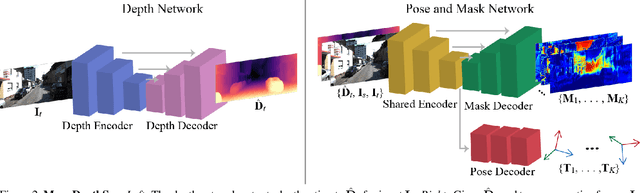

Self-supervised monocular depth estimation approaches either ignore independently moving objects in the scene or need a separate segmentation step to identify them. We propose MonoDepthSeg to jointly estimate depth and segment moving objects from monocular video without using any ground-truth labels. We decompose the scene into a fixed number of components where each component corresponds to a region on the image with its own transformation matrix representing its motion. We estimate both the mask and the motion of each component efficiently with a shared encoder. We evaluate our method on three driving datasets and show that our model clearly improves depth estimation while decomposing the scene into separately moving components.
Combining Geometric and Topological Information in Image Segmentation
Oct 10, 2019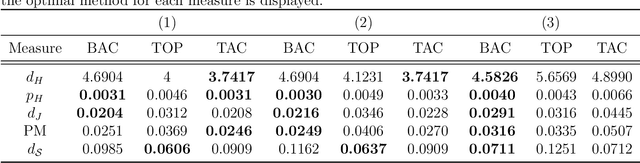
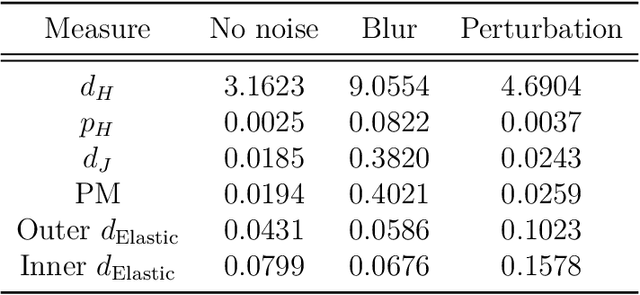
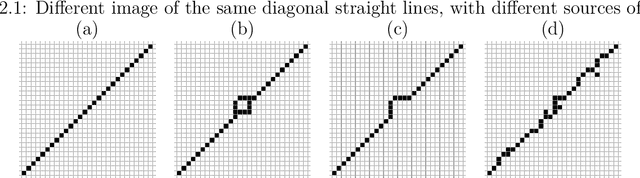

A fundamental problem in computer vision is image segmentation, where the goal is to delineate the boundary of the object in the image. The focus of this work is on the segmentation of grayscale images and its purpose is two-fold. First, we conduct an in-depth study comparing active contour and topologically-based methods, two popular approaches for boundary detection of 2-dimensional images. Certain properties of the image dataset may favor one method over the other, both from an interpretability perspective as well as through evaluation of performance measures. Second, we propose the use of topological knowledge to assist an active contour method, which can potentially incorporate prior shape information. The latter is known to be extremely sensitive to algorithm initialization, and thus, we use a topological model to provide an automatic initialization. In addition, our proposed model can handle objects in images with more complex topological structures. We demonstrate this on artificially-constructed image datasets from computer vision, as well as real medical image data.
Denoised Labels for Financial Time-Series Data via Self-Supervised Learning
Dec 19, 2021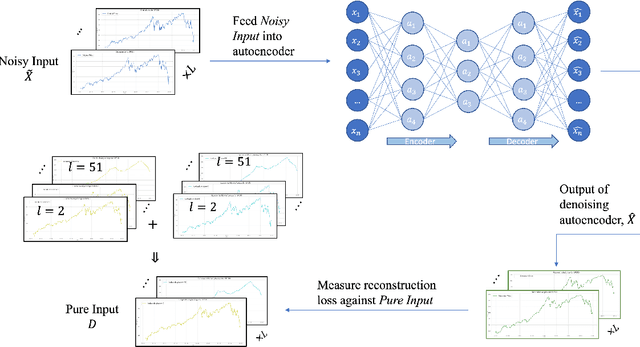
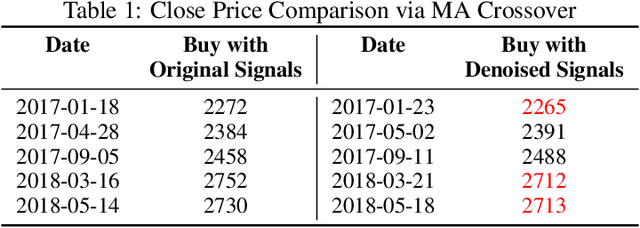
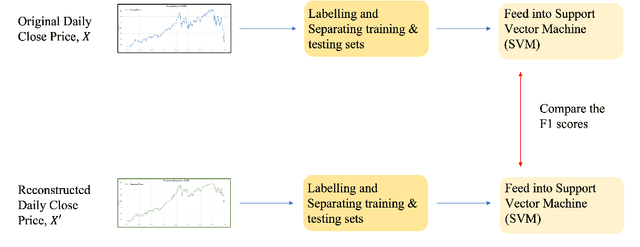
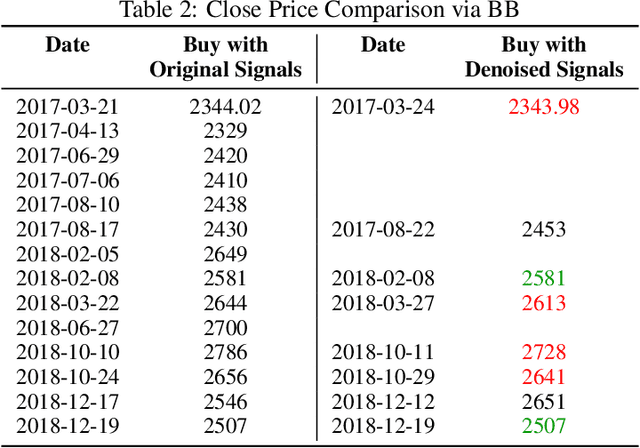
The introduction of electronic trading platforms effectively changed the organisation of traditional systemic trading from quote-driven markets into order-driven markets. Its convenience led to an exponentially increasing amount of financial data, which is however hard to use for the prediction of future prices, due to the low signal-to-noise ratio and the non-stationarity of financial time series. Simpler classification tasks -- where the goal is to predict the directions of future price movement -- via supervised learning algorithms, need sufficiently reliable labels to generalise well. Labelling financial data is however less well defined than other domains: did the price go up because of noise or because of signal? The existing labelling methods have limited countermeasures against noise and limited effects in improving learning algorithms. This work takes inspiration from image classification in trading and success in self-supervised learning. We investigate the idea of applying computer vision techniques to financial time-series to reduce the noise exposure and hence generate correct labels. We look at the label generation as the pretext task of a self-supervised learning approach and compare the naive (and noisy) labels, commonly used in the literature, with the labels generated by a denoising autoencoder for the same downstream classification task. Our results show that our denoised labels improve the performances of the downstream learning algorithm, for both small and large datasets. We further show that the signals we obtain can be used to effectively trade with binary strategies. We suggest that with proposed techniques, self-supervised learning constitutes a powerful framework for generating "better" financial labels that are useful for studying the underlying patterns of the market.
CF2-Net: Coarse-to-Fine Fusion Convolutional Network for Breast Ultrasound Image Segmentation
Mar 23, 2020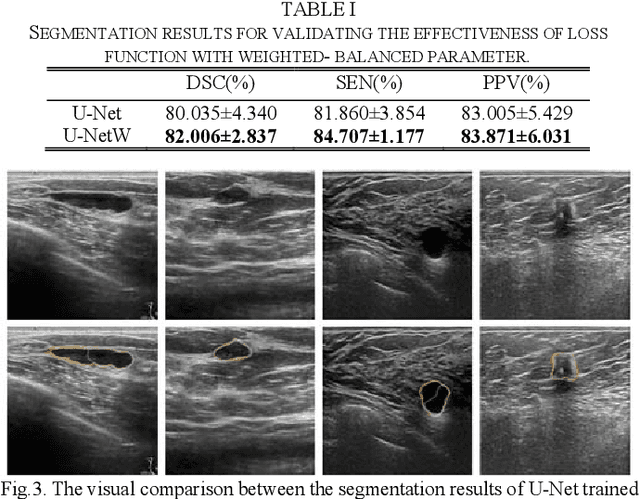

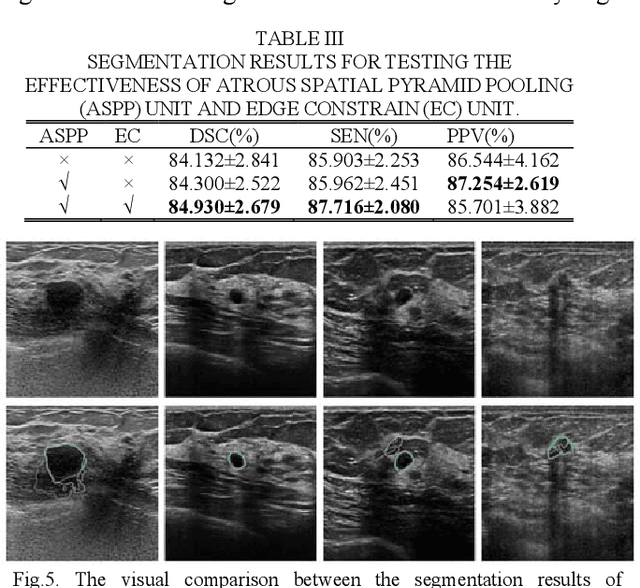
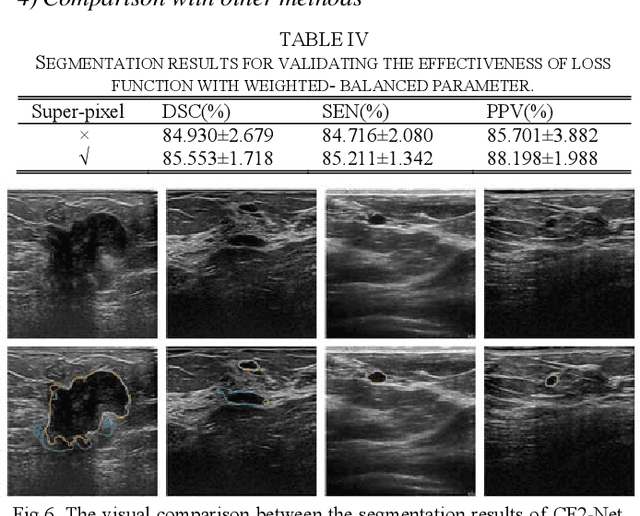
Breast ultrasound (BUS) image segmentation plays a crucial role in a computer-aided diagnosis system, which is regarded as a useful tool to help increase the accuracy of breast cancer diagnosis. Recently, many deep learning methods have been developed for segmentation of BUS image and show some advantages compared with conventional region-, model-, and traditional learning-based methods. However, previous deep learning methods typically use skip-connection to concatenate the encoder and decoder, which might not make full fusion of coarse-to-fine features from encoder and decoder. Since the structure and edge of lesion in BUS image are common blurred, these would make it difficult to learn the discriminant information of structure and edge, and reduce the performance. To this end, we propose and evaluate a coarse-to-fine fusion convolutional network (CF2-Net) based on a novel feature integration strategy (forming an 'E'-like type) for BUS image segmentation. To enhance contour and provide structural information, we concatenate a super-pixel image and the original image as the input of CF2-Net. Meanwhile, to highlight the differences in the lesion regions with variable sizes and relieve the imbalance issue, we further design a weighted-balanced loss function to train the CF2-Net effectively. The proposed CF2-Net was evaluated on an open dataset by using four-fold cross validation. The results of the experiment demonstrate that the CF2-Net obtains state-of-the-art performance when compared with other deep learning-based methods
Backdoor Attack through Frequency Domain
Nov 30, 2021


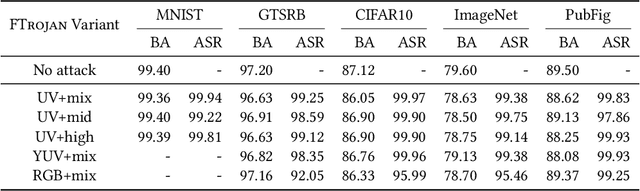
Backdoor attacks have been shown to be a serious threat against deep learning systems such as biometric authentication and autonomous driving. An effective backdoor attack could enforce the model misbehave under certain predefined conditions, i.e., triggers, but behave normally otherwise. However, the triggers of existing attacks are directly injected in the pixel space, which tend to be detectable by existing defenses and visually identifiable at both training and inference stages. In this paper, we propose a new backdoor attack FTROJAN through trojaning the frequency domain. The key intuition is that triggering perturbations in the frequency domain correspond to small pixel-wise perturbations dispersed across the entire image, breaking the underlying assumptions of existing defenses and making the poisoning images visually indistinguishable from clean ones. We evaluate FTROJAN in several datasets and tasks showing that it achieves a high attack success rate without significantly degrading the prediction accuracy on benign inputs. Moreover, the poisoning images are nearly invisible and retain high perceptual quality. We also evaluate FTROJAN against state-of-the-art defenses as well as several adaptive defenses that are designed on the frequency domain. The results show that FTROJAN can robustly elude or significantly degenerate the performance of these defenses.
Camera Condition Monitoring and Readjustment by means of Noise and Blur
Dec 10, 2021

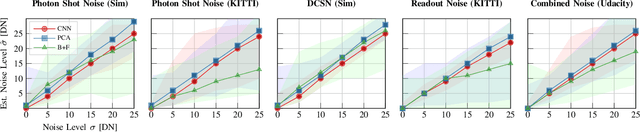
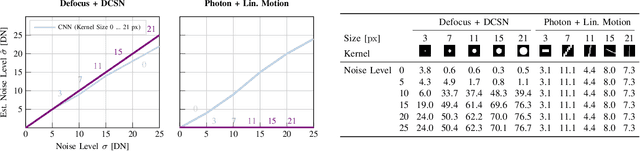
Autonomous vehicles and robots require increasingly more robustness and reliability to meet the demands of modern tasks. These requirements specially apply to cameras because they are the predominant sensors to acquire information about the environment and support actions. A camera must maintain proper functionality and take automatic countermeasures if necessary. However, there is little work that examines the practical use of a general condition monitoring approach for cameras and designs countermeasures in the context of an envisaged high-level application. We propose a generic and interpretable self-health-maintenance framework for cameras based on data- and physically-grounded models. To this end, we determine two reliable, real-time capable estimators for typical image effects of a camera in poor condition (defocus blur, motion blur, different noise phenomena and most common combinations) by comparing traditional and retrained machine learning-based approaches in extensive experiments. Furthermore, we demonstrate how one can adjust the camera parameters (e.g., exposure time and ISO gain) to achieve optimal whole-system capability based on experimental (non-linear and non-monotonic) input-output performance curves, using object detection, motion blur and sensor noise as examples. Our framework not only provides a practical ready-to-use solution to evaluate and maintain the health of cameras, but can also serve as a basis for extensions to tackle more sophisticated problems that combine additional data sources (e.g., sensor or environment parameters) empirically in order to attain fully reliable and robust machines.
NAS-Bench-360: Benchmarking Diverse Tasks for Neural Architecture Search
Oct 16, 2021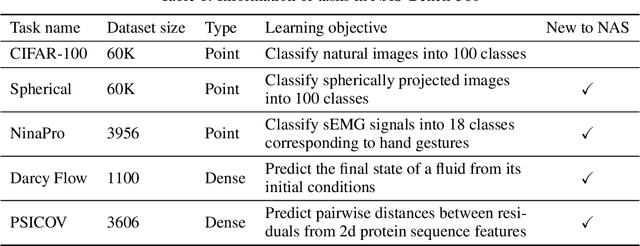
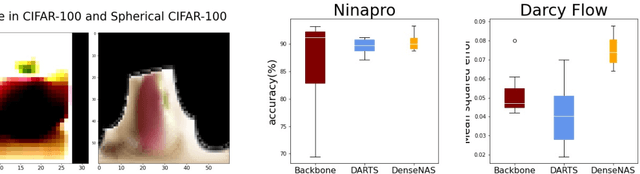
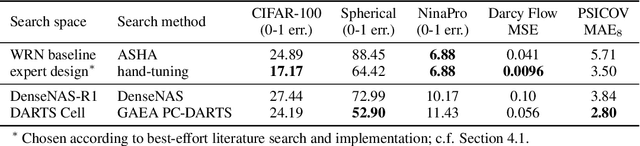
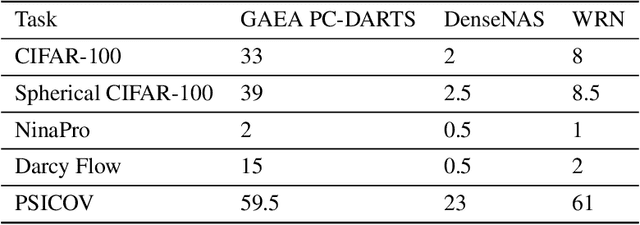
Most existing neural architecture search (NAS) benchmarks and algorithms prioritize performance on well-studied tasks, e.g., image classification on CIFAR and ImageNet. This makes the applicability of NAS approaches in more diverse areas inadequately understood. In this paper, we present NAS-Bench-360, a benchmark suite for evaluating state-of-the-art NAS methods for convolutional neural networks (CNNs). To construct it, we curate a collection of ten tasks spanning a diverse array of application domains, dataset sizes, problem dimensionalities, and learning objectives. By carefully selecting tasks that can both interoperate with modern CNN-based search methods but that are also far-afield from their original development domain, we can use NAS-Bench-360 to investigate the following central question: do existing state-of-the-art NAS methods perform well on diverse tasks? Our experiments show that a modern NAS procedure designed for image classification can indeed find good architectures for tasks with other dimensionalities and learning objectives; however, the same method struggles against more task-specific methods and performs catastrophically poorly on classification in non-vision domains. The case for NAS robustness becomes even more dire in a resource-constrained setting, where a recent NAS method provides little-to-no benefit over much simpler baselines. These results demonstrate the need for a benchmark such as NAS-Bench-360 to help develop NAS approaches that work well on a variety of tasks, a crucial component of a truly robust and automated pipeline. We conclude with a demonstration of the kind of future research our suite of tasks will enable. All data and code is made publicly available.
Deep Learning for Fitness
Sep 03, 2021
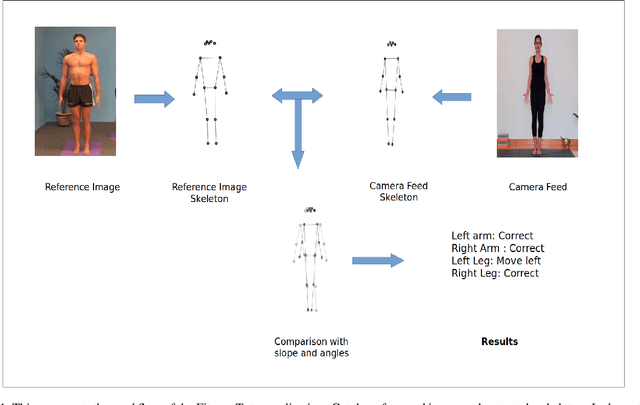
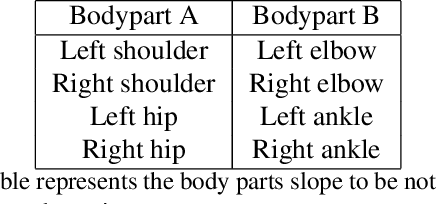

We present Fitness tutor, an application for maintaining correct posture during workout exercises or doing yoga. Current work on fitness focuses on suggesting food supplements, accessing workouts, workout wearables does a great job in improving the fitness. Meanwhile, the current situation is making difficult to monitor workouts by trainee. Inspired by healthcare innovations like robotic surgery, we design a novel application Fitness tutor which can guide the workouts using pose estimation. Pose estimation can be deployed on the reference image for gathering data and guide the user with the data. This allow Fitness tutor to guide the workouts (both exercise and yoga) in remote conditions with a single reference posture as image. We use posenet model in tensorflow with p5js for developing skeleton. Fitness tutor is an application of pose estimation model in bringing a realtime teaching experience in fitness. Our experiments shows that it can leverage potential of pose estimation models by providing guidance in realtime.
Hole-robust Wireframe Detection
Nov 30, 2021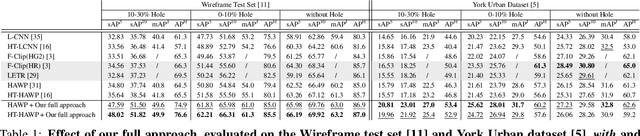
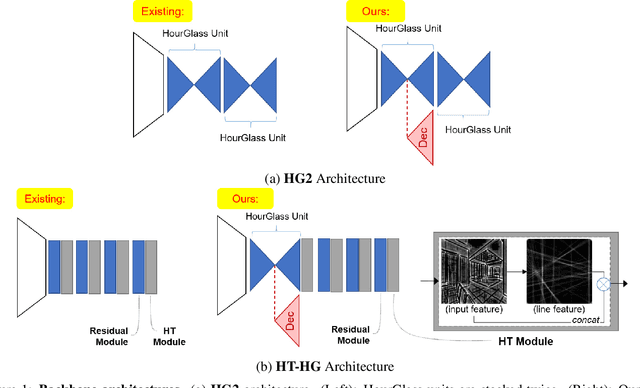
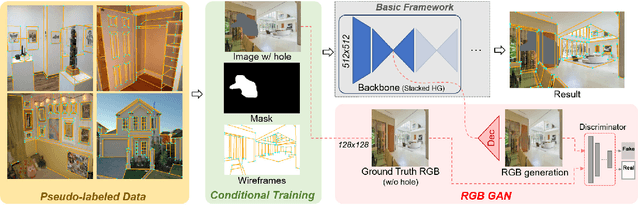
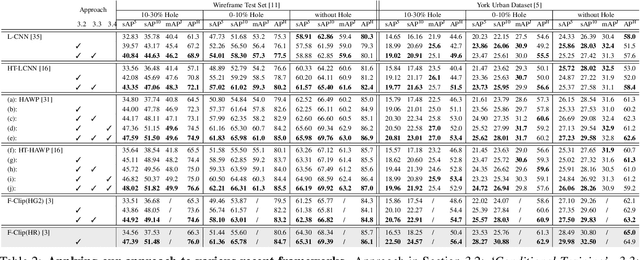
"Wireframe" is a line segment based representation designed to well capture large-scale visual properties of regular, structural shaped man-made scenes surrounding us. Unlike the wireframes, conventional edges or line segments focus on all visible edges and lines without particularly distinguishing which of them are more salient to man-made structural information. Existing wireframe detection models rely on supervising the annotated data but do not explicitly pay attention to understand how to compose the structural shapes of the scene. In addition, we often face that many foreground objects occluding the background scene interfere with proper inference of the full scene structure behind them. To resolve these problems, we first time in the field, propose new conditional data generation and training that help the model understand how to ignore occlusion indicated by holes, such as foreground object regions masked out on the image. In addition, we first time combine GAN in the model to let the model better predict underlying scene structure even beyond large holes. We also introduce pseudo labeling to further enlarge the model capacity to overcome small-scale labeled data. We show qualitatively and quantitatively that our approach significantly outperforms previous works unable to handle holes, as well as improves ordinary detection without holes given.