 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Fast and Real-time End to End Control in Autonomous Racing Cars Through Representation Learning
Nov 30, 2021
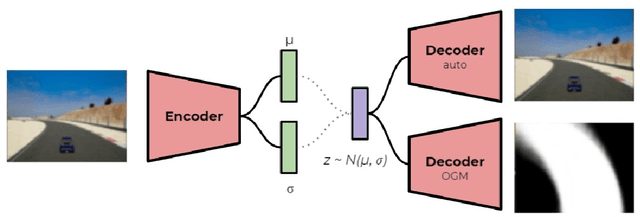

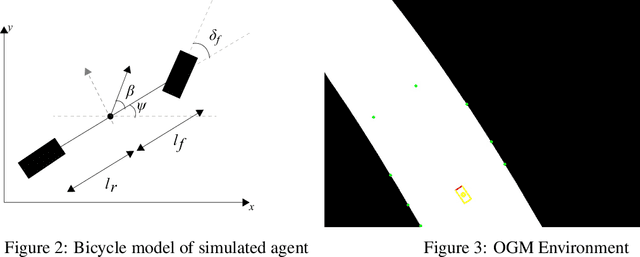
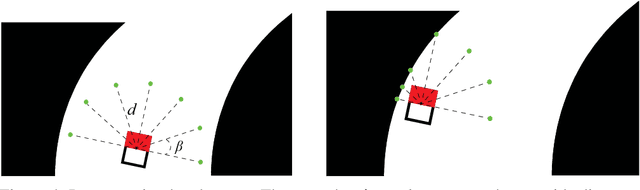
The challenges presented in an autonomous racing situation are distinct from those faced in regular autonomous driving and require faster end-to-end algorithms and consideration of a longer horizon in determining optimal current actions keeping in mind upcoming maneuvers and situations. In this paper, we propose an end-to-end method for autonomous racing that takes in as inputs video information from an onboard camera and determines final steering and throttle control actions. We use the following split to construct such a method (1) learning a low dimensional representation of the scene, (2) pre-generating the optimal trajectory for the given scene, and (3) tracking the predicted trajectory using a classical control method. In learning a low-dimensional representation of the scene, we use intermediate representations with a novel unsupervised trajectory planner to generate expert trajectories, and hence utilize them to directly predict race lines from a given front-facing input image. Thus, the proposed algorithm employs the best of two worlds - the robustness of learning-based approaches to perception and the accuracy of optimization-based approaches for trajectory generation in an end-to-end learning-based framework. We deploy and demonstrate our framework on CARLA, a photorealistic simulator for testing self-driving cars in realistic environments.
DeepEMD: Few-Shot Image Classification with Differentiable Earth Mover's Distance and Structured Classifiers
Mar 25, 2020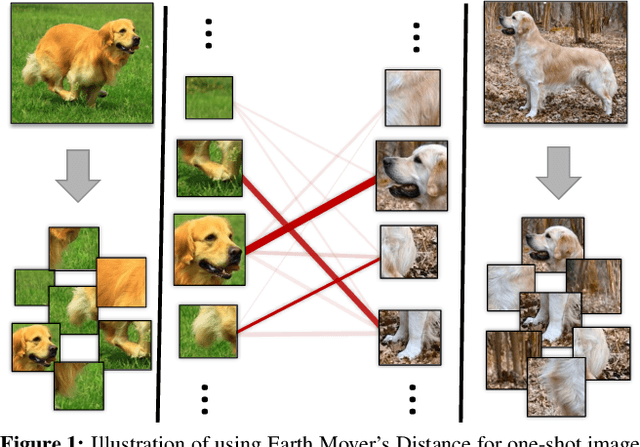
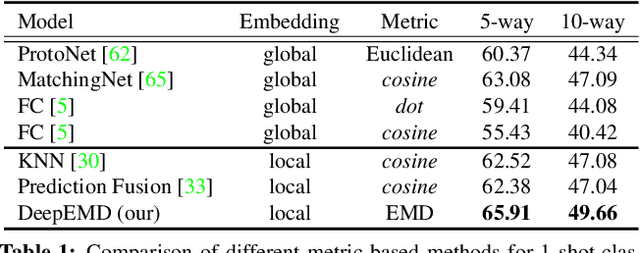
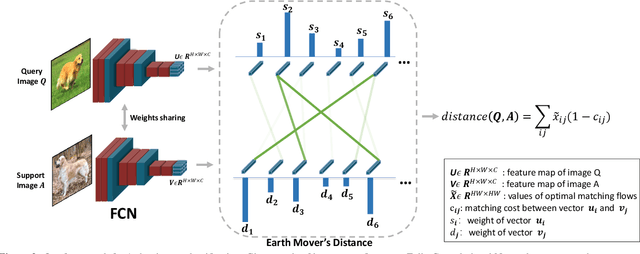
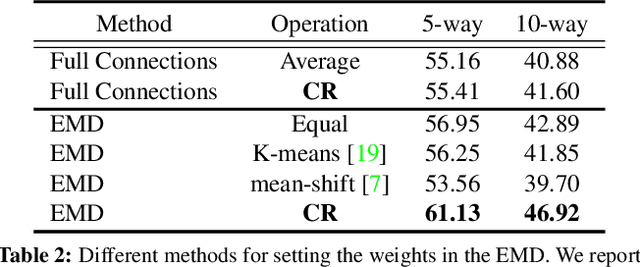
In this paper, we address the few-shot classification task from a new perspective of optimal matching between image regions. We adopt the Earth Mover's Distance (EMD) as a metric to compute a structural distance between dense image representations to determine image relevance. The EMD generates the optimal matching flows between structural elements that have the minimum matching cost, which is used to represent the image distance for classification. To generate the important weights of elements in the EMD formulation, we design a cross-reference mechanism, which can effectively minimize the impact caused by the cluttered background and large intra-class appearance variations. To handle k-shot classification, we propose to learn a structured fully connected layer that can directly classify dense image representations with the EMD. Based on the implicit function theorem, the EMD can be inserted as a layer into the network for end-to-end training. We conduct comprehensive experiments to validate our algorithm and we set new state-of-the-art performance on four popular few-shot classification benchmarks, namely miniImageNet, tieredImageNet, Fewshot-CIFAR100 (FC100) and Caltech-UCSD Birds-200-2011 (CUB).
CodeNeRF: Disentangled Neural Radiance Fields for Object Categories
Sep 03, 2021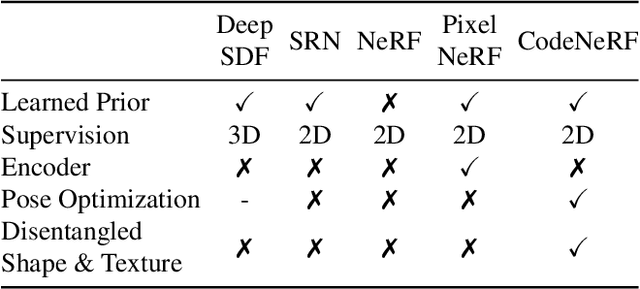
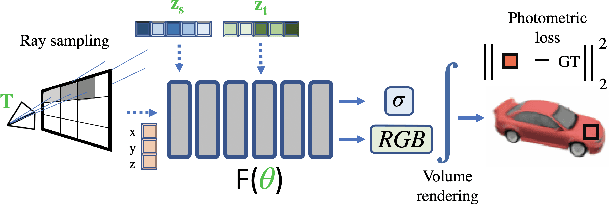
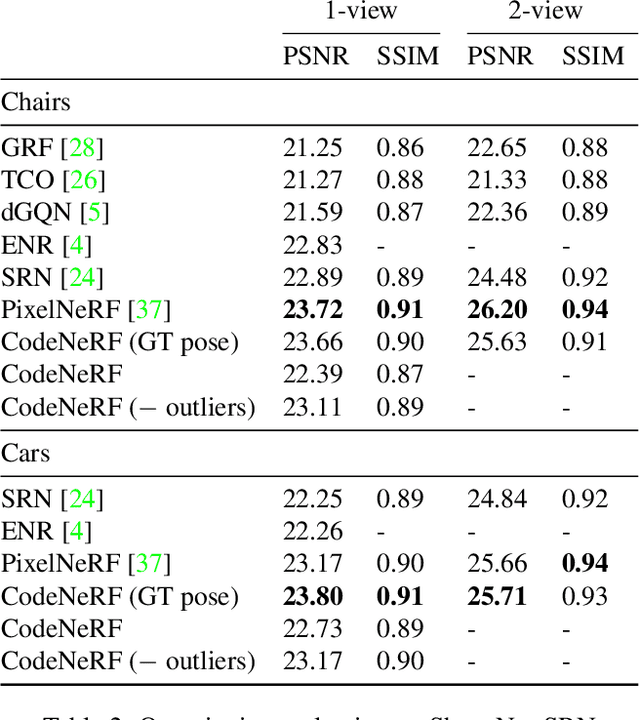
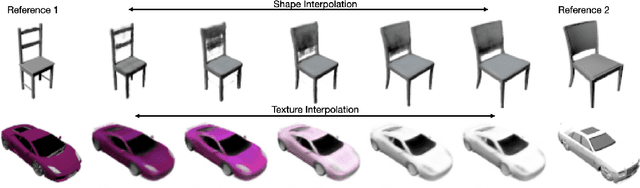
CodeNeRF is an implicit 3D neural representation that learns the variation of object shapes and textures across a category and can be trained, from a set of posed images, to synthesize novel views of unseen objects. Unlike the original NeRF, which is scene specific, CodeNeRF learns to disentangle shape and texture by learning separate embeddings. At test time, given a single unposed image of an unseen object, CodeNeRF jointly estimates camera viewpoint, and shape and appearance codes via optimization. Unseen objects can be reconstructed from a single image, and then rendered from new viewpoints or their shape and texture edited by varying the latent codes. We conduct experiments on the SRN benchmark, which show that CodeNeRF generalises well to unseen objects and achieves on-par performance with methods that require known camera pose at test time. Our results on real-world images demonstrate that CodeNeRF can bridge the sim-to-real gap. Project page: \url{https://github.com/wayne1123/code-nerf}
Automatic ultrasound vessel segmentation with deep spatiotemporal context learning
Nov 03, 2021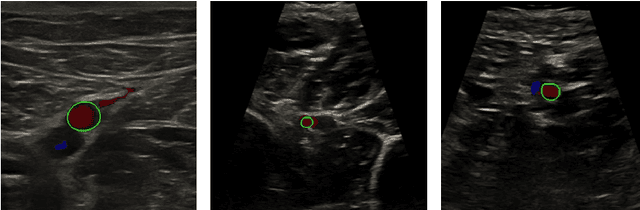
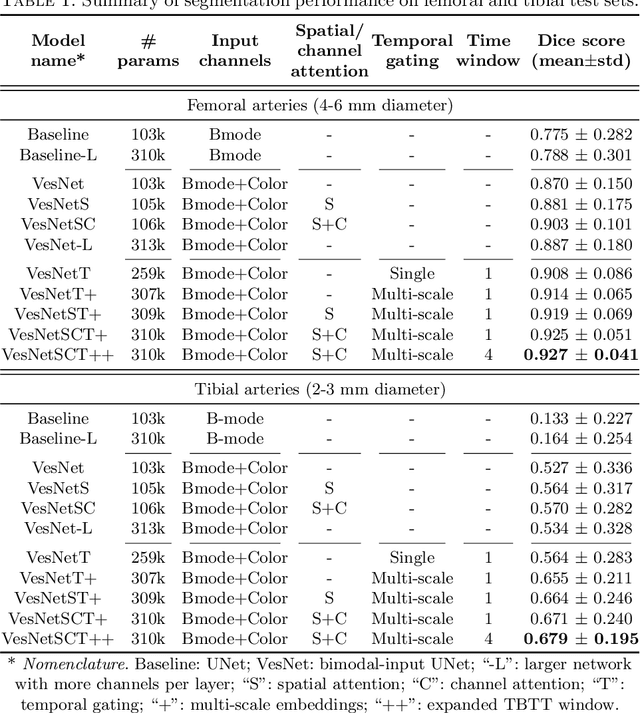
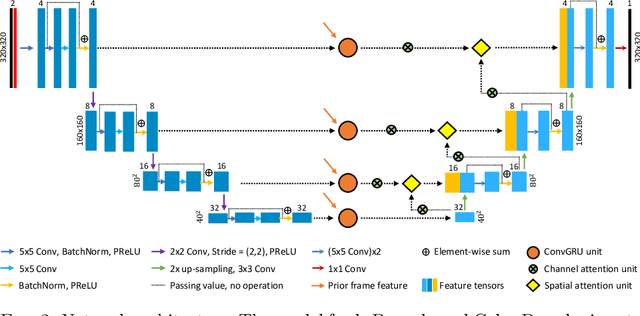
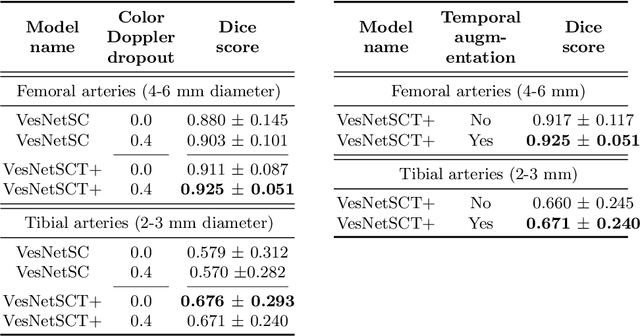
Accurate, real-time segmentation of vessel structures in ultrasound image sequences can aid in the measurement of lumen diameters and assessment of vascular diseases. This, however, remains a challenging task, particularly for extremely small vessels that are difficult to visualize. We propose to leverage the rich spatiotemporal context available in ultrasound to improve segmentation of small-scale lower-extremity arterial vasculature. We describe efficient deep learning methods that incorporate temporal, spatial, and feature-aware contextual embeddings at multiple resolution scales while jointly utilizing information from B-mode and Color Doppler signals. Evaluating on femoral and tibial artery scans performed on healthy subjects by an expert ultrasonographer, and comparing to consensus expert ground-truth annotations of inner lumen boundaries, we demonstrate real-time segmentation using the context-aware models and show that they significantly outperform comparable baseline approaches.
Guided Generative Models using Weak Supervision for Detecting Object Spatial Arrangement in Overhead Images
Dec 10, 2021
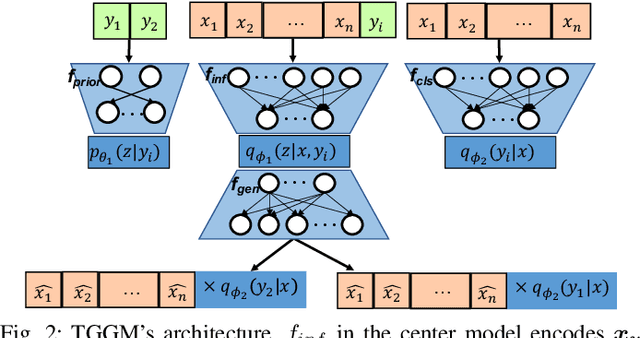
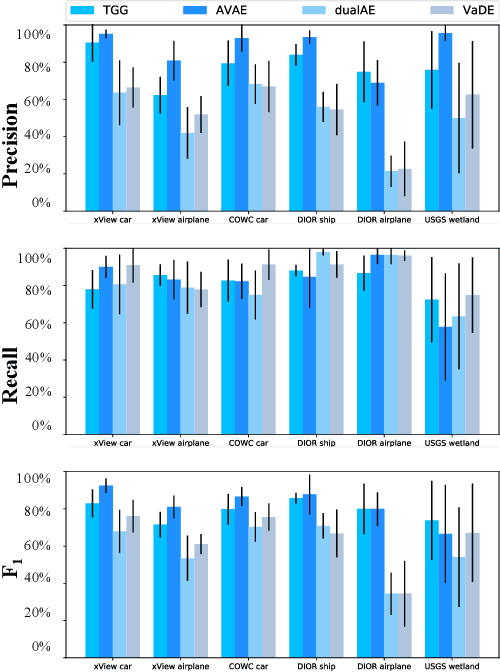

The increasing availability and accessibility of numerous overhead images allows us to estimate and assess the spatial arrangement of groups of geospatial target objects, which can benefit many applications, such as traffic monitoring and agricultural monitoring. Spatial arrangement estimation is the process of identifying the areas which contain the desired objects in overhead images. Traditional supervised object detection approaches can estimate accurate spatial arrangement but require large amounts of bounding box annotations. Recent semi-supervised clustering approaches can reduce manual labeling but still require annotations for all object categories in the image. This paper presents the target-guided generative model (TGGM), under the Variational Auto-encoder (VAE) framework, which uses Gaussian Mixture Models (GMM) to estimate the distributions of both hidden and decoder variables in VAE. Modeling both hidden and decoder variables by GMM reduces the required manual annotations significantly for spatial arrangement estimation. Unlike existing approaches that the training process can only update the GMM as a whole in the optimization iterations (e.g., a "minibatch"), TGGM allows the update of individual GMM components separately in the same optimization iteration. Optimizing GMM components separately allows TGGM to exploit the semantic relationships in spatial data and requires only a few labels to initiate and guide the generative process. Our experiments shows that TGGM achieves results comparable to the state-of-the-art semi-supervised methods and outperforms unsupervised methods by 10% based on the $F_{1}$ scores, while requiring significantly fewer labeled data.
Cross-Modality Fusion Transformer for Multispectral Object Detection
Nov 11, 2021
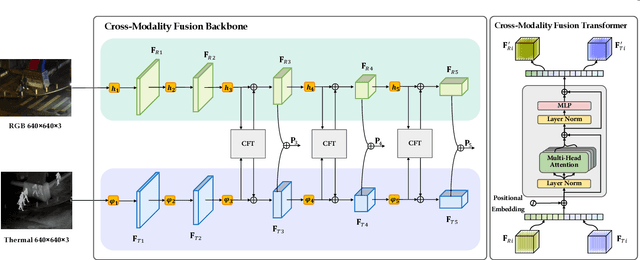
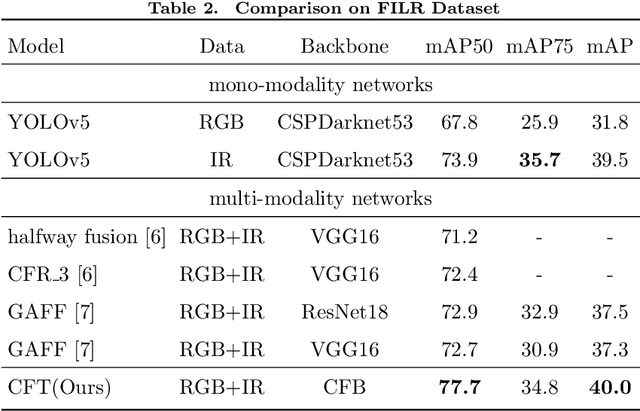
Multispectral image pairs can provide the combined information, making object detection applications more reliable and robust in the open world. To fully exploit the different modalities, we present a simple yet effective cross-modality feature fusion approach, named Cross-Modality Fusion Transformer (CFT) in this paper. Unlike prior CNNs-based works, guided by the transformer scheme, our network learns long-range dependencies and integrates global contextual information in the feature extraction stage. More importantly, by leveraging the self attention of the transformer, the network can naturally carry out simultaneous intra-modality and inter-modality fusion, and robustly capture the latent interactions between RGB and Thermal domains, thereby significantly improving the performance of multispectral object detection. Extensive experiments and ablation studies on multiple datasets demonstrate that our approach is effective and achieves state-of-the-art detection performance. Our code and models will be released soon at https://github.com/DocF/multispectral-object-detection.
Single-Modal Entropy based Active Learning for Visual Question Answering
Nov 18, 2021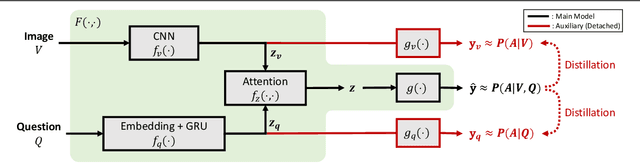
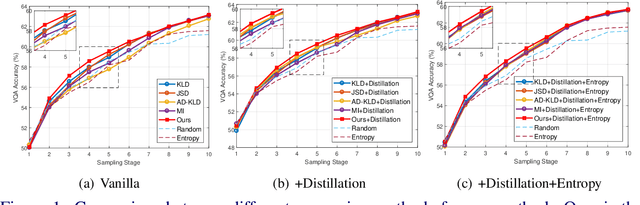
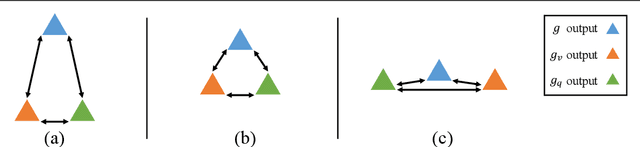
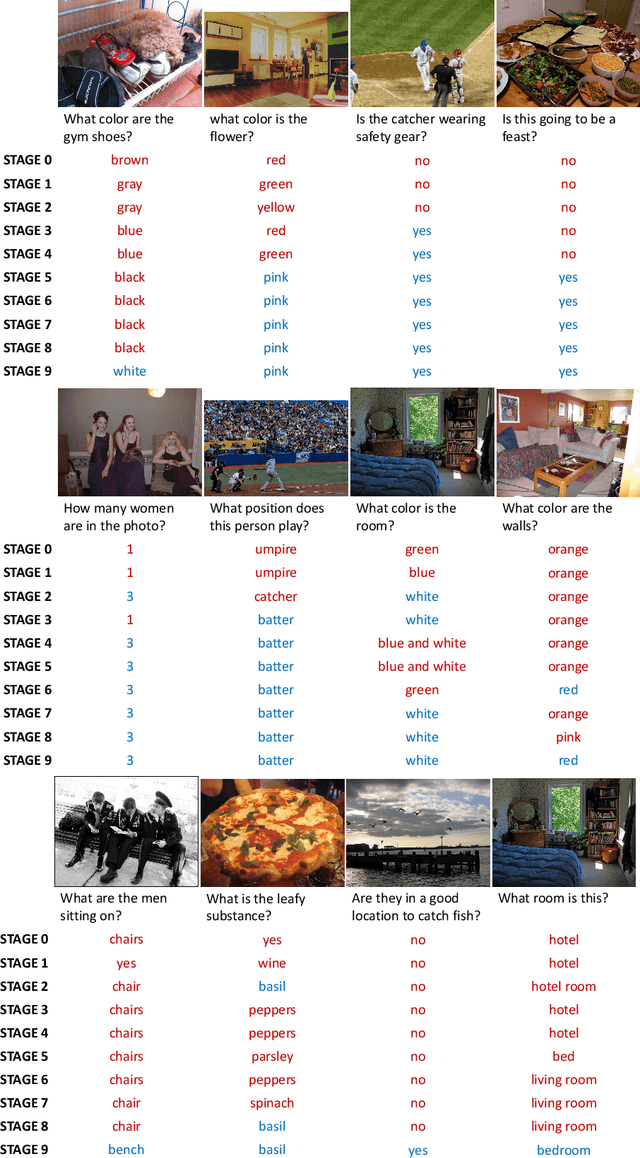
Constructing a large-scale labeled dataset in the real world, especially for high-level tasks (eg, Visual Question Answering), can be expensive and time-consuming. In addition, with the ever-growing amounts of data and architecture complexity, Active Learning has become an important aspect of computer vision research. In this work, we address Active Learning in the multi-modal setting of Visual Question Answering (VQA). In light of the multi-modal inputs, image and question, we propose a novel method for effective sample acquisition through the use of ad hoc single-modal branches for each input to leverage its information. Our mutual information based sample acquisition strategy Single-Modal Entropic Measure (SMEM) in addition to our self-distillation technique enables the sample acquisitor to exploit all present modalities and find the most informative samples. Our novel idea is simple to implement, cost-efficient, and readily adaptable to other multi-modal tasks. We confirm our findings on various VQA datasets through state-of-the-art performance by comparing to existing Active Learning baselines.
Unaligned Image-to-Sequence Transformation with Loop Consistency
Oct 09, 2019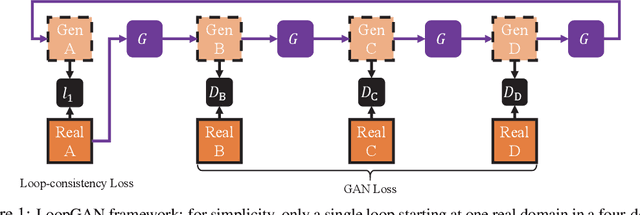
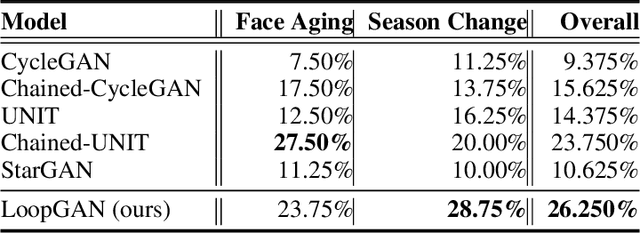
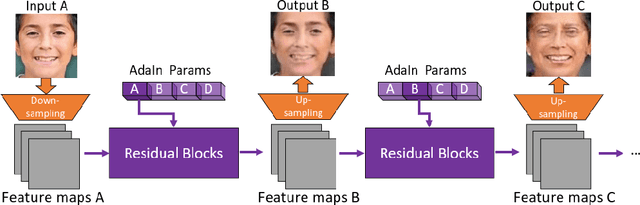

We tackle the problem of modeling sequential visual phenomena. Given examples of a phenomena that can be divided into discrete time steps, we aim to take an input from any such time and realize this input at all other time steps in the sequence. Furthermore, we aim to do this without ground-truth aligned sequences -- avoiding the difficulties needed for gathering aligned data. This generalizes the unpaired image-to-image problem from generating pairs to generating sequences. We extend cycle consistency to loop consistency and alleviate difficulties associated with learning in the resulting long chains of computation. We show competitive results compared to existing image-to-image techniques when modeling several different data sets including the Earth's seasons and aging of human faces.
Self-Supervised Monocular Scene Decomposition and Depth Estimation
Oct 21, 2021

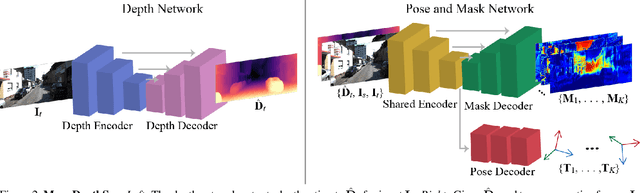

Self-supervised monocular depth estimation approaches either ignore independently moving objects in the scene or need a separate segmentation step to identify them. We propose MonoDepthSeg to jointly estimate depth and segment moving objects from monocular video without using any ground-truth labels. We decompose the scene into a fixed number of components where each component corresponds to a region on the image with its own transformation matrix representing its motion. We estimate both the mask and the motion of each component efficiently with a shared encoder. We evaluate our method on three driving datasets and show that our model clearly improves depth estimation while decomposing the scene into separately moving components.
Ensembling Low Precision Models for Binary Biomedical Image Segmentation
Oct 16, 2020
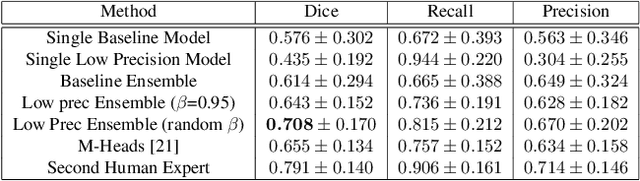
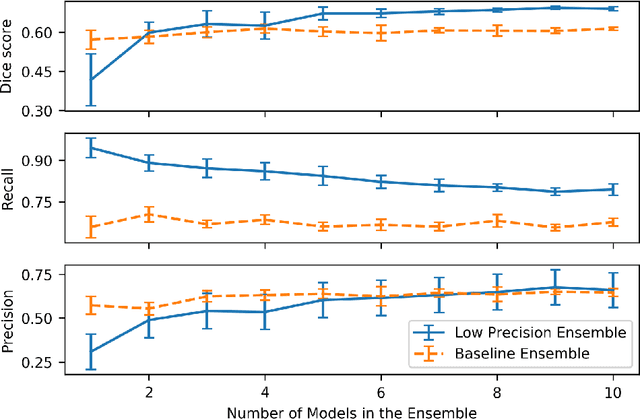

Segmentation of anatomical regions of interest such as vessels or small lesions in medical images is still a difficult problem that is often tackled with manual input by an expert. One of the major challenges for this task is that the appearance of foreground (positive) regions can be similar to background (negative) regions. As a result, many automatic segmentation algorithms tend to exhibit asymmetric errors, typically producing more false positives than false negatives. In this paper, we aim to leverage this asymmetry and train a diverse ensemble of models with very high recall, while sacrificing their precision. Our core idea is straightforward: A diverse ensemble of low precision and high recall models are likely to make different false positive errors (classifying background as foreground in different parts of the image), but the true positives will tend to be consistent. Thus, in aggregate the false positive errors will cancel out, yielding high performance for the ensemble. Our strategy is general and can be applied with any segmentation model. In three different applications (carotid artery segmentation in a neck CT angiography, myocardium segmentation in a cardiovascular MRI and multiple sclerosis lesion segmentation in a brain MRI), we show how the proposed approach can significantly boost the performance of a baseline segmentation method.