 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Hole-robust Wireframe Detection
Nov 30, 2021
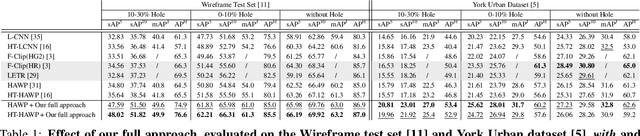
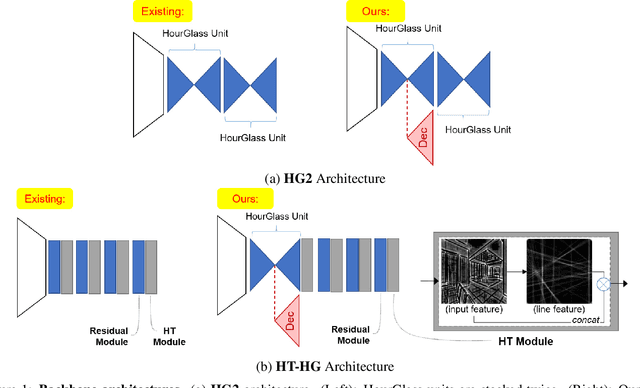
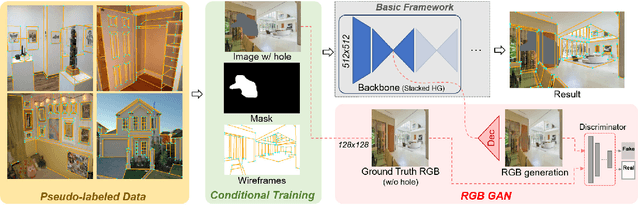
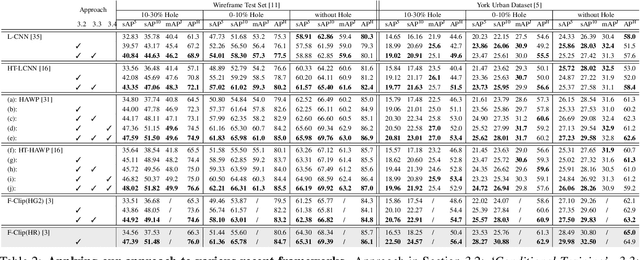
"Wireframe" is a line segment based representation designed to well capture large-scale visual properties of regular, structural shaped man-made scenes surrounding us. Unlike the wireframes, conventional edges or line segments focus on all visible edges and lines without particularly distinguishing which of them are more salient to man-made structural information. Existing wireframe detection models rely on supervising the annotated data but do not explicitly pay attention to understand how to compose the structural shapes of the scene. In addition, we often face that many foreground objects occluding the background scene interfere with proper inference of the full scene structure behind them. To resolve these problems, we first time in the field, propose new conditional data generation and training that help the model understand how to ignore occlusion indicated by holes, such as foreground object regions masked out on the image. In addition, we first time combine GAN in the model to let the model better predict underlying scene structure even beyond large holes. We also introduce pseudo labeling to further enlarge the model capacity to overcome small-scale labeled data. We show qualitatively and quantitatively that our approach significantly outperforms previous works unable to handle holes, as well as improves ordinary detection without holes given.
Exploring Pixel-level Self-supervision for Weakly Supervised Semantic Segmentation
Dec 10, 2021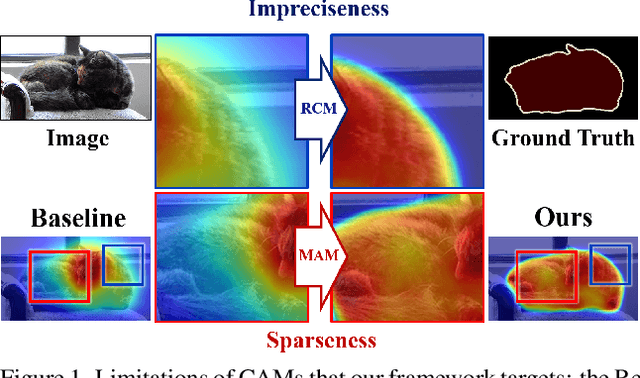
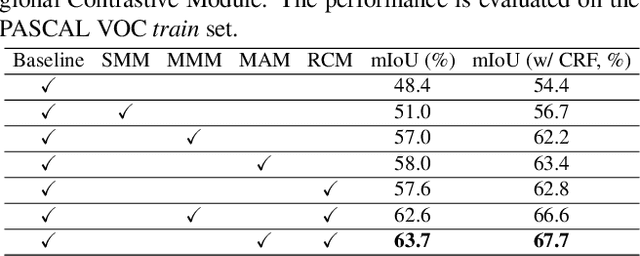
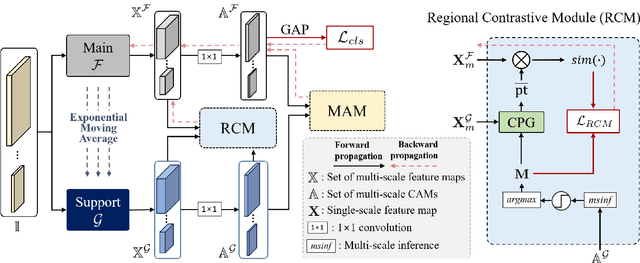
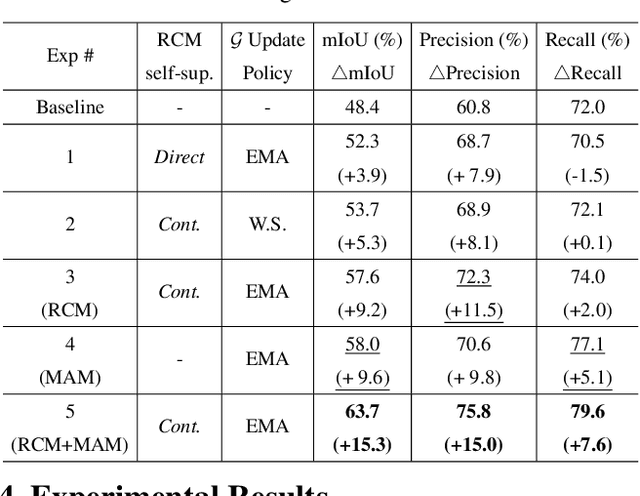
Existing studies in weakly supervised semantic segmentation (WSSS) have utilized class activation maps (CAMs) to localize the class objects. However, since a classification loss is insufficient for providing precise object regions, CAMs tend to be biased towards discriminative patterns (i.e., sparseness) and do not provide precise object boundary information (i.e., impreciseness). To resolve these limitations, we propose a novel framework (composed of MainNet and SupportNet.) that derives pixel-level self-supervision from given image-level supervision. In our framework, with the help of the proposed Regional Contrastive Module (RCM) and Multi-scale Attentive Module (MAM), MainNet is trained by self-supervision from the SupportNet. The RCM extracts two forms of self-supervision from SupportNet: (1) class region masks generated from the CAMs and (2) class-wise prototypes obtained from the features according to the class region masks. Then, every pixel-wise feature of the MainNet is trained by the prototype in a contrastive manner, sharpening the resulting CAMs. The MAM utilizes CAMs inferred at multiple scales from the SupportNet as self-supervision to guide the MainNet. Based on the dissimilarity between the multi-scale CAMs from MainNet and SupportNet, CAMs from the MainNet are trained to expand to the less-discriminative regions. The proposed method shows state-of-the-art WSSS performance both on the train and validation sets on the PASCAL VOC 2012 dataset. For reproducibility, code will be available publicly soon.
AssistSR: Affordance-centric Question-driven Video Segment Retrieval
Nov 30, 2021
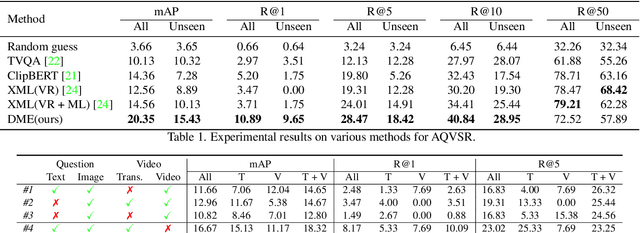
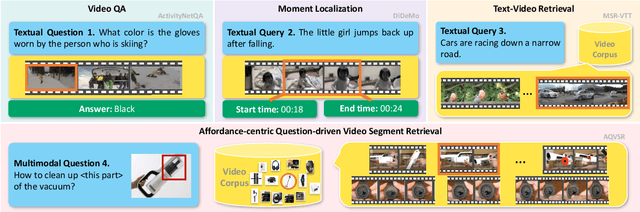
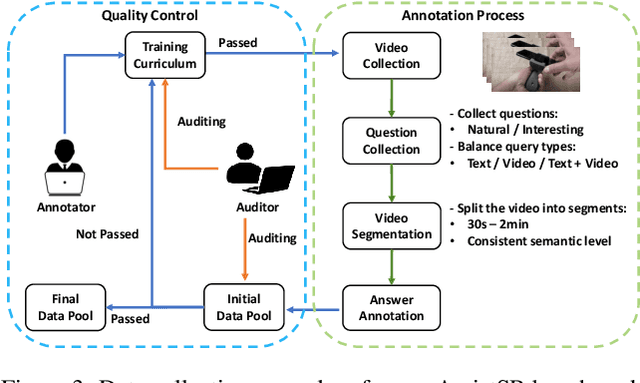
It is still a pipe dream that AI assistants on phone and AR glasses can assist our daily life in addressing our questions like "how to adjust the date for this watch?" and "how to set its heating duration? (while pointing at an oven)". The queries used in conventional tasks (i.e. Video Question Answering, Video Retrieval, Moment Localization) are often factoid and based on pure text. In contrast, we present a new task called Affordance-centric Question-driven Video Segment Retrieval (AQVSR). Each of our questions is an image-box-text query that focuses on affordance of items in our daily life and expects relevant answer segments to be retrieved from a corpus of instructional video-transcript segments. To support the study of this AQVSR task, we construct a new dataset called AssistSR. We design novel guidelines to create high-quality samples. This dataset contains 1.4k multimodal questions on 1k video segments from instructional videos on diverse daily-used items. To address AQVSR, we develop a straightforward yet effective model called Dual Multimodal Encoders (DME) that significantly outperforms several baseline methods while still having large room for improvement in the future. Moreover, we present detailed ablation analyses. Our codes and data are available at https://github.com/StanLei52/AQVSR.
MetaMedSeg: Volumetric Meta-learning for Few-Shot Organ Segmentation
Sep 18, 2021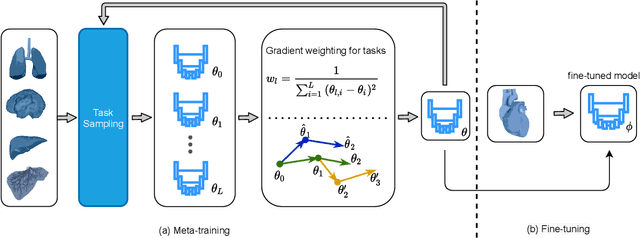
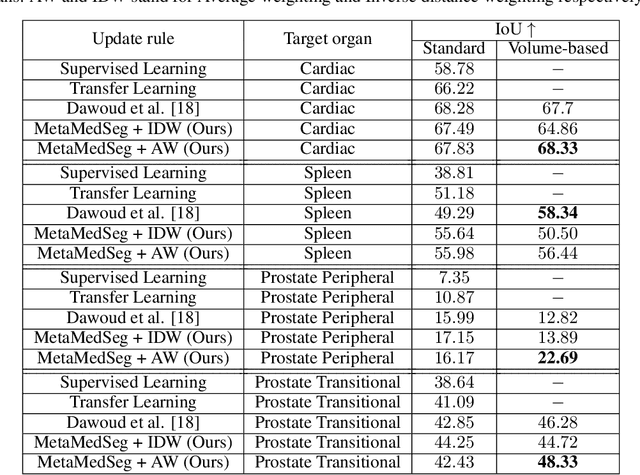
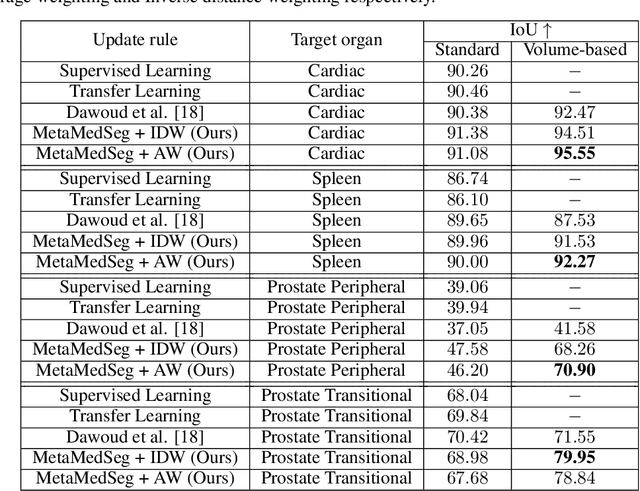
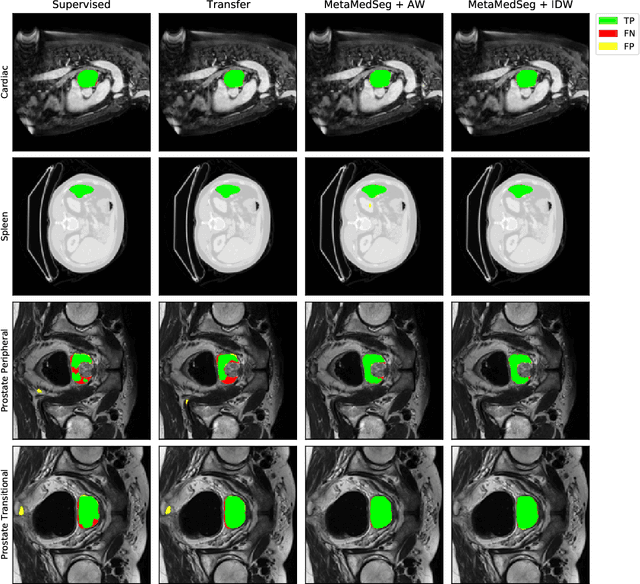
The lack of sufficient annotated image data is a common issue in medical image segmentation. For some organs and densities, the annotation may be scarce, leading to poor model training convergence, while other organs have plenty of annotated data. In this work, we present MetaMedSeg, a gradient-based meta-learning algorithm that redefines the meta-learning task for the volumetric medical data with the goal to capture the variety between the slices. We also explore different weighting schemes for gradients aggregation, arguing that different tasks might have different complexity, and hence, contribute differently to the initialization. We propose an importance-aware weighting scheme to train our model. In the experiments, we present an evaluation of the medical decathlon dataset by extracting 2D slices from CT and MRI volumes of different organs and performing semantic segmentation. The results show that our proposed volumetric task definition leads to up to 30% improvement in terms of IoU compared to related baselines. The proposed update rule is also shown to improve the performance for complex scenarios where the data distribution of the target organ is very different from the source organs.
Automated Side Channel Analysis of Media Software with Manifold Learning
Dec 10, 2021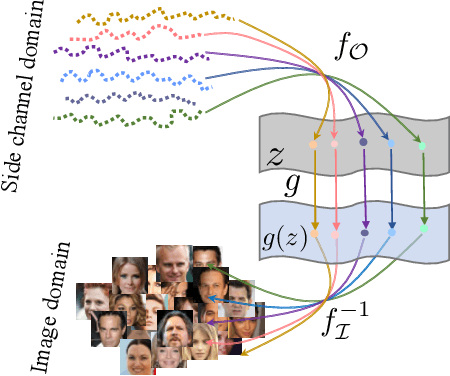

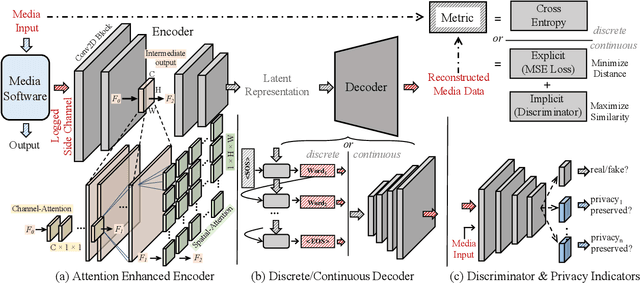

The prosperous development of cloud computing and machine learning as a service has led to the widespread use of media software to process confidential media data. This paper explores an adversary's ability to launch side channel analyses (SCA) against media software to reconstruct confidential media inputs. Recent advances in representation learning and perceptual learning inspired us to consider the reconstruction of media inputs from side channel traces as a cross-modality manifold learning task that can be addressed in a unified manner with an autoencoder framework trained to learn the mapping between media inputs and side channel observations. We further enhance the autoencoder with attention to localize the program points that make the primary contribution to SCA, thus automatically pinpointing information-leakage points in media software. We also propose a novel and highly effective defensive technique called perception blinding that can perturb media inputs with perception masks and mitigate manifold learning-based SCA. Our evaluation exploits three popular media software to reconstruct inputs in image, audio, and text formats. We analyze three common side channels - cache bank, cache line, and page tables - and userspace-only cache set accesses logged by standard Prime+Probe. Our framework successfully reconstructs high-quality confidential inputs from the assessed media software and automatically pinpoint their vulnerable program points, many of which are unknown to the public. We further show that perception blinding can mitigate manifold learning-based SCA with negligible extra cost.
Use of the Deep Learning Approach to Measure Alveolar Bone Level
Sep 24, 2021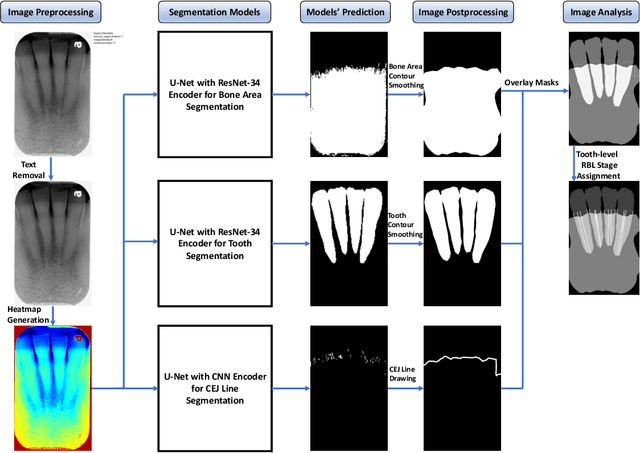
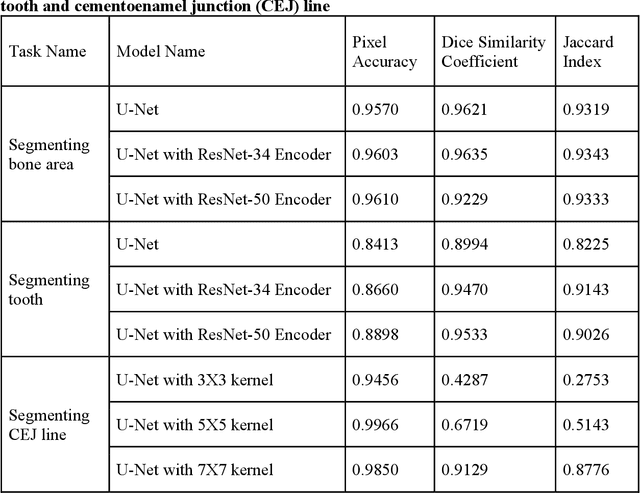
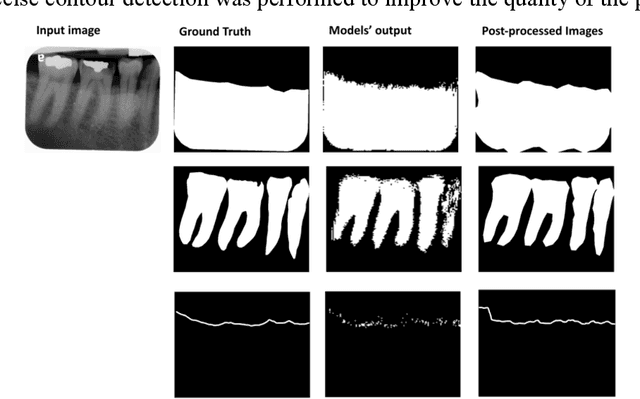
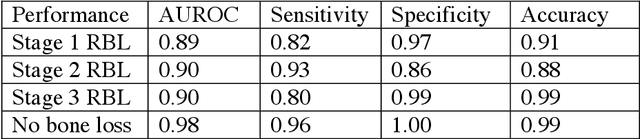
Abstract: Aim: The goal was to use a Deep Convolutional Neural Network to measure the radiographic alveolar bone level to aid periodontal diagnosis. Material and methods: A Deep Learning (DL) model was developed by integrating three segmentation networks (bone area, tooth, cementoenamel junction) and image analysis to measure the radiographic bone level and assign radiographic bone loss (RBL) stages. The percentage of RBL was calculated to determine the stage of RBL for each tooth. A provisional periodontal diagnosis was assigned using the 2018 periodontitis classification. RBL percentage, staging, and presumptive diagnosis were compared to the measurements and diagnoses made by the independent examiners. Results: The average Dice Similarity Coefficient (DSC) for segmentation was over 0.91. There was no significant difference in RBL percentage measurements determined by DL and examiners (p=0.65). The Area Under the Receiver Operating Characteristics Curve of RBL stage assignment for stage I, II and III was 0.89, 0.90 and 0.90, respectively. The accuracy of the case diagnosis was 0.85. Conclusion: The proposed DL model provides reliable RBL measurements and image-based periodontal diagnosis using periapical radiographic images. However, this model has to be further optimized and validated by a larger number of images to facilitate its application.
Attention Model Enhanced Network for Classification of Breast Cancer Image
Oct 07, 2020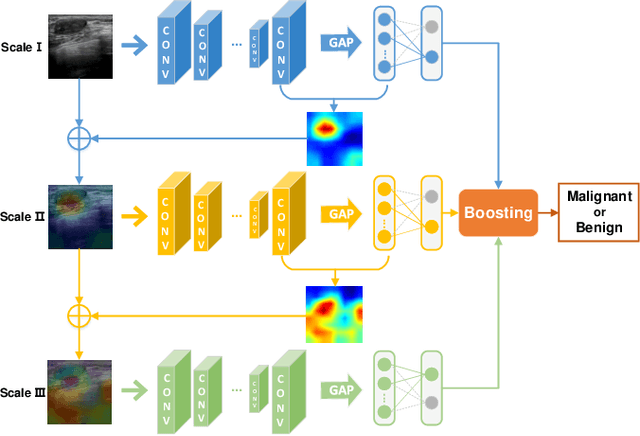
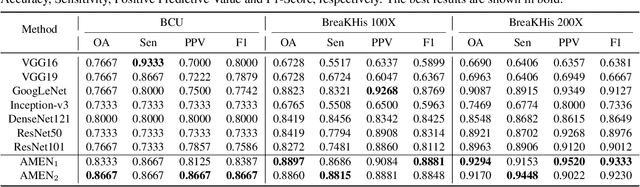
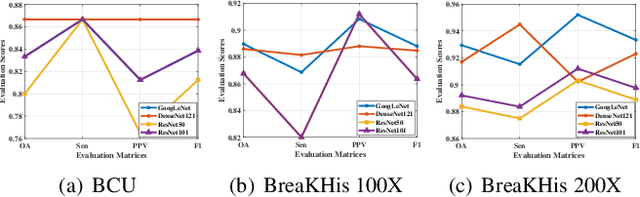
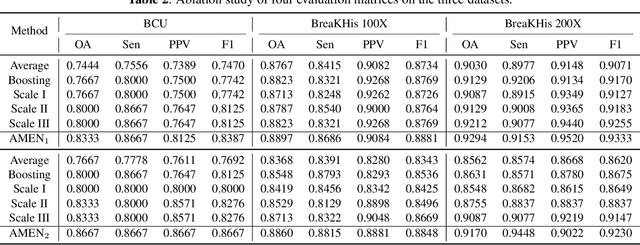
Breast cancer classification remains a challenging task due to inter-class ambiguity and intra-class variability. Existing deep learning-based methods try to confront this challenge by utilizing complex nonlinear projections. However, these methods typically extract global features from entire images, neglecting the fact that the subtle detail information can be crucial in extracting discriminative features. In this study, we propose a novel method named Attention Model Enhanced Network (AMEN), which is formulated in a multi-branch fashion with pixel-wised attention model and classification submodular. Specifically, the feature learning part in AMEN can generate pixel-wised attention map, while the classification submodular are utilized to classify the samples. To focus more on subtle detail information, the sample image is enhanced by the pixel-wised attention map generated from former branch. Furthermore, boosting strategy are adopted to fuse classification results from different branches for better performance. Experiments conducted on three benchmark datasets demonstrate the superiority of the proposed method under various scenarios.
Low-resource Learning with Knowledge Graphs: A Comprehensive Survey
Dec 22, 2021
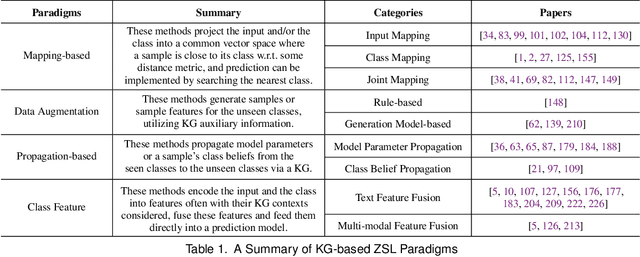
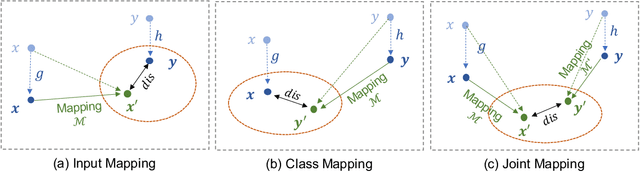
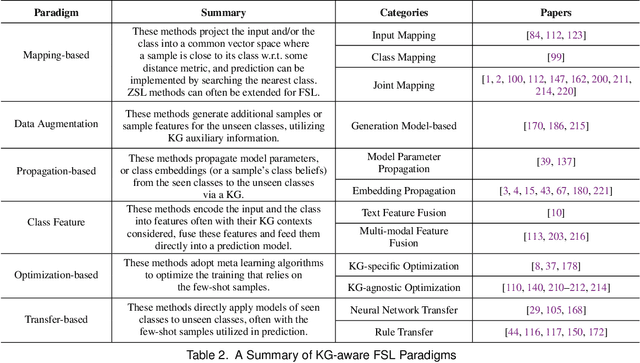
Machine learning methods especially deep neural networks have achieved great success but many of them often rely on a number of labeled samples for training. In real-world applications, we often need to address sample shortage due to e.g., dynamic contexts with emerging prediction targets and costly sample annotation. Therefore, low-resource learning, which aims to learn robust prediction models with no enough resources (especially training samples), is now being widely investigated. Among all the low-resource learning studies, many prefer to utilize some auxiliary information in the form of Knowledge Graph (KG), which is becoming more and more popular for knowledge representation, to reduce the reliance on labeled samples. In this survey, we very comprehensively reviewed over $90$ papers about KG-aware research for two major low-resource learning settings -- zero-shot learning (ZSL) where new classes for prediction have never appeared in training, and few-shot learning (FSL) where new classes for prediction have only a small number of labeled samples that are available. We first introduced the KGs used in ZSL and FSL studies as well as the existing and potential KG construction solutions, and then systematically categorized and summarized KG-aware ZSL and FSL methods, dividing them into different paradigms such as the mapping-based, the data augmentation, the propagation-based and the optimization-based. We next presented different applications, including not only KG augmented tasks in Computer Vision and Natural Language Processing (e.g., image classification, text classification and knowledge extraction), but also tasks for KG curation (e.g., inductive KG completion), and some typical evaluation resources for each task. We eventually discussed some challenges and future directions on aspects such as new learning and reasoning paradigms, and the construction of high quality KGs.
Dynamic hardware system for cascade SVM classification of melanoma
Dec 10, 2021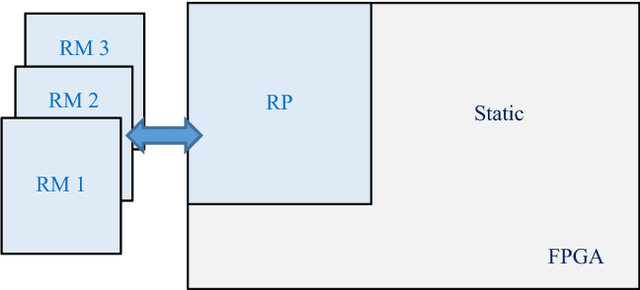


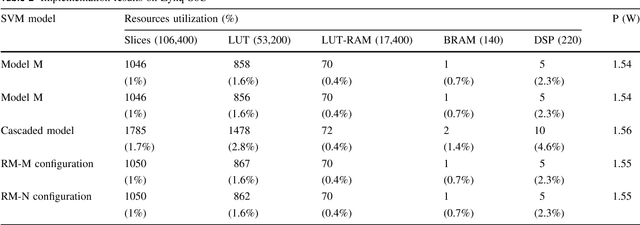
Melanoma is the most dangerous form of skin cancer, which is responsible for the majority of skin cancer-related deaths. Early diagnosis of melanoma can significantly reduce mortality rates and treatment costs. Therefore, skin cancer specialists are using image-based diagnostic tools for detecting melanoma earlier. We aim to develop a handheld device featured with low cost and high performance to enhance early detection of melanoma at the primary healthcare. But, developing this device is very challenging due to the complicated computations required by the embedded diagnosis system. Thus, we aim to exploit the recent hardware technology in reconfigurable computing to achieve a high-performance embedded system at low cost. Support vector machine (SVM) is a common classifier that shows high accuracy for classifying melanoma within the diagnosis system and is considered as the most compute-intensive task in the system. In this paper, we propose a dynamic hardware system for implementing a cascade SVM classifier on FPGA for early melanoma detection. A multi-core architecture is proposed to implement a two-stage cascade classifier using two classifiers with accuracies of 98% and 73%. The hardware implementation results were optimized by using the dynamic partial reconfiguration technology, where very low resource utilization of 1% slices and power consumption of 1.5 W were achieved. Consequently, the implemented dynamic hardware system meets vital embedded system constraints of high performance and low cost, resource utilization, and power consumption, while achieving efficient classification with high accuracy.
* Journal paper, 9 pages, 4 figures, 4 tables
Learning Canonical 3D Object Representation for Fine-Grained Recognition
Aug 10, 2021
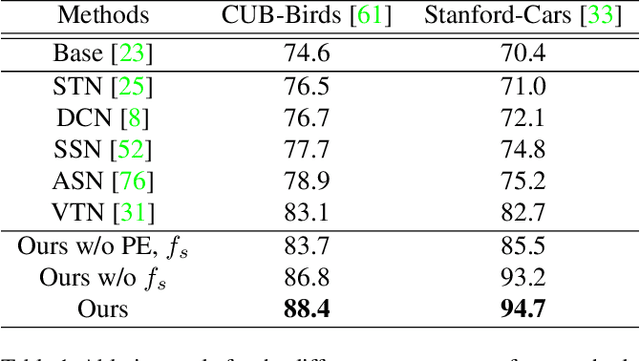
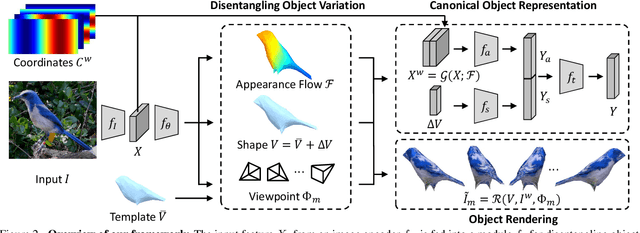

We propose a novel framework for fine-grained object recognition that learns to recover object variation in 3D space from a single image, trained on an image collection without using any ground-truth 3D annotation. We accomplish this by representing an object as a composition of 3D shape and its appearance, while eliminating the effect of camera viewpoint, in a canonical configuration. Unlike conventional methods modeling spatial variation in 2D images only, our method is capable of reconfiguring the appearance feature in a canonical 3D space, thus enabling the subsequent object classifier to be invariant under 3D geometric variation. Our representation also allows us to go beyond existing methods, by incorporating 3D shape variation as an additional cue for object recognition. To learn the model without ground-truth 3D annotation, we deploy a differentiable renderer in an analysis-by-synthesis framework. By incorporating 3D shape and appearance jointly in a deep representation, our method learns the discriminative representation of the object and achieves competitive performance on fine-grained image recognition and vehicle re-identification. We also demonstrate that the performance of 3D shape reconstruction is improved by learning fine-grained shape deformation in a boosting manner.