 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Disentangled and Controllable Face Image Generation via 3D Imitative-Contrastive Learning
Apr 24, 2020
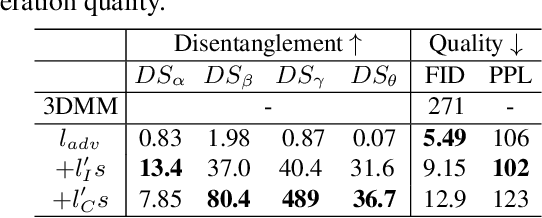
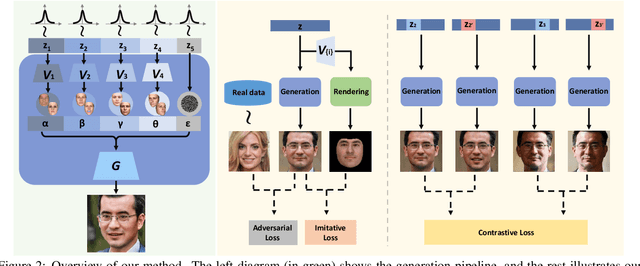
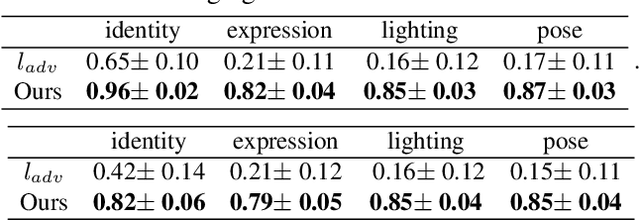
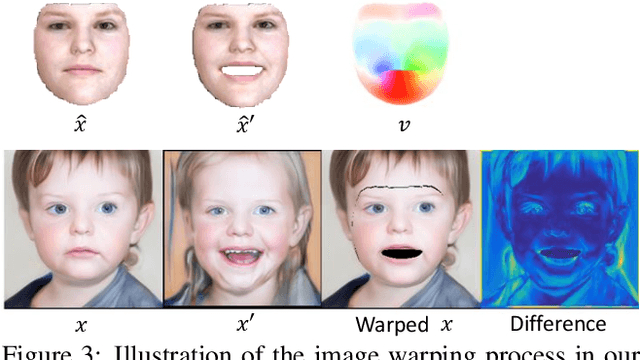
We propose an approach for face image generation of virtual people with disentangled, precisely-controllable latent representations for identity of non-existing people, expression, pose, and illumination. We embed 3D priors into adversarial learning and train the network to imitate the image formation of an analytic 3D face deformation and rendering process. To deal with the generation freedom induced by the domain gap between real and rendered faces, we further introduce contrastive learning to promote disentanglement by comparing pairs of generated images. Experiments show that through our imitative-contrastive learning, the factor variations are very well disentangled and the properties of a generated face can be precisely controlled. We also analyze the learned latent space and present several meaningful properties supporting factor disentanglement. Our method can also be used to embed real images into the disentangled latent space. We hope our method could provide new understandings of the relationship between physical properties and deep image synthesis.
Learning Diagnosis of COVID-19 from a Single Radiological Image
Jun 06, 2020
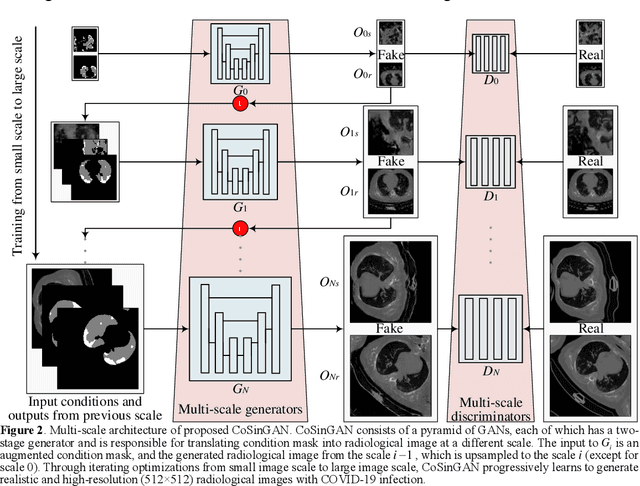
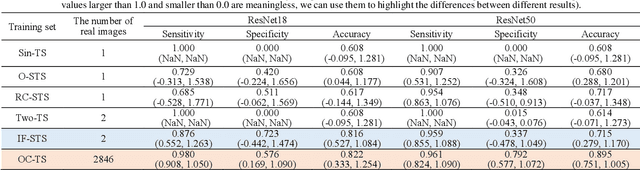
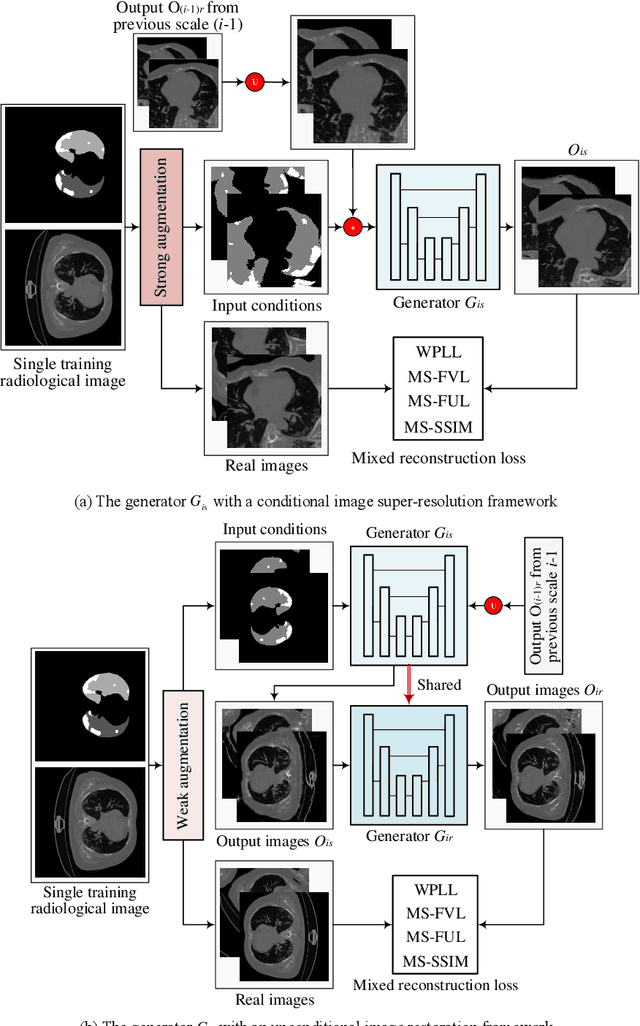
Radiological image is currently adopted as the visual evidence for COVID-19 diagnosis in clinical. Using deep models to realize automated infection measurement and COVID-19 diagnosis is important for faster examination based on radiological imaging. Unfortunately, collecting large training data systematically in the early stage is difficult. To address this problem, we explore the feasibility of learning deep models for COVID-19 diagnosis from a single radiological image by resorting to synthesizing diverse radiological images. Specifically, we propose a novel conditional generative model, called CoSinGAN, which can be learned from a single radiological image with a given condition, i.e., the annotations of the lung and COVID-19 infection. Our CoSinGAN is able to capture the conditional distribution of visual finds of COVID-19 infection, and further synthesize diverse and high-resolution radiological images that match the input conditions precisely. Both deep classification and segmentation networks trained on synthesized samples from CoSinGAN achieve notable detection accuracy of COVID-19 infection. Such results are significantly better than the counterparts trained on the same extremely small number of real samples (1 or 2 real samples) by using strong data augmentation, and approximate to the counterparts trained on large dataset (2846 real images). It confirms our method can significantly reduce the performance gap between deep models trained on extremely small dataset and on large dataset, and thus has the potential to realize learning COVID-19 diagnosis from few radiological images in the early stage of COVID-19 pandemic. Our codes are made publicly available at https://github.com/PengyiZhang/CoSinGAN.
CloudFindr: A Deep Learning Cloud Artifact Masker for Satellite DEM Data
Oct 26, 2021


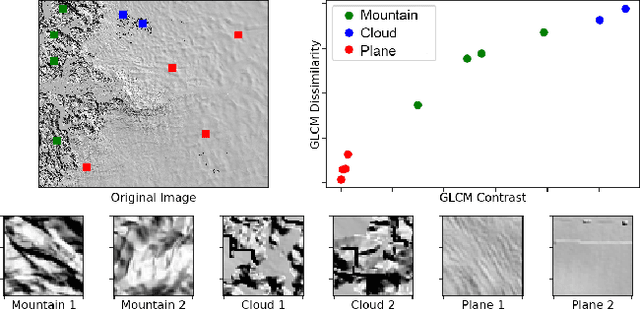
Artifact removal is an integral component of cinematic scientific visualization, and is especially challenging with big datasets in which artifacts are difficult to define. In this paper, we describe a method for creating cloud artifact masks which can be used to remove artifacts from satellite imagery using a combination of traditional image processing together with deep learning based on U-Net. Compared to previous methods, our approach does not require multi-channel spectral imagery but performs successfully on single-channel Digital Elevation Models (DEMs). DEMs are a representation of the topography of the Earth and have a variety applications including planetary science, geology, flood modeling, and city planning.
Learning Structural Representations for Recipe Generation and Food Retrieval
Oct 04, 2021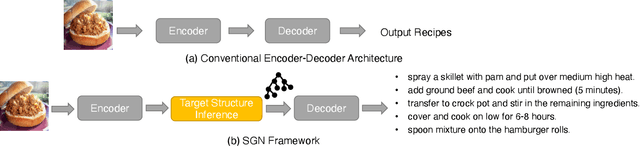
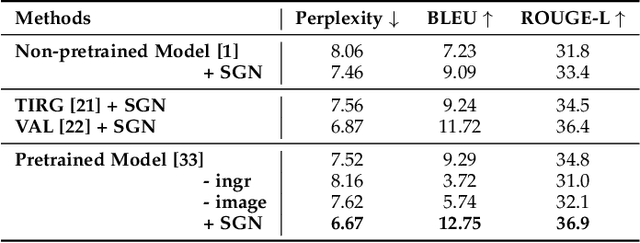
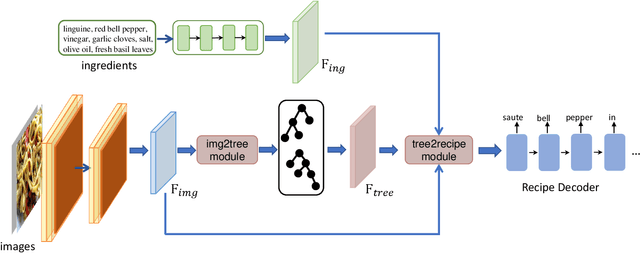
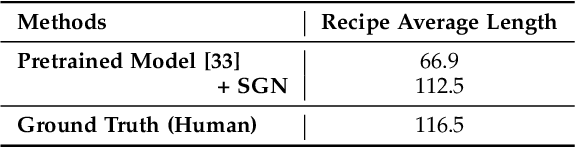
Food is significant to human daily life. In this paper, we are interested in learning structural representations for lengthy recipes, that can benefit the recipe generation and food retrieval tasks. We mainly investigate an open research task of generating cooking instructions based on food images and ingredients, which is similar to the image captioning task. However, compared with image captioning datasets, the target recipes are lengthy paragraphs and do not have annotations on structure information. To address the above limitations, we propose a novel framework of Structure-aware Generation Network (SGN) to tackle the food recipe generation task. Our approach brings together several novel ideas in a systematic framework: (1) exploiting an unsupervised learning approach to obtain the sentence-level tree structure labels before training; (2) generating trees of target recipes from images with the supervision of tree structure labels learned from (1); and (3) integrating the inferred tree structures into the recipe generation procedure. Our proposed model can produce high-quality and coherent recipes, and achieve the state-of-the-art performance on the benchmark Recipe1M dataset. We also validate the usefulness of our learned tree structures in the food cross-modal retrieval task, where the proposed model with tree representations can outperform state-of-the-art benchmark results.
Secure Machine Learning in the Cloud Using One Way Scrambling by Deconvolution
Nov 04, 2021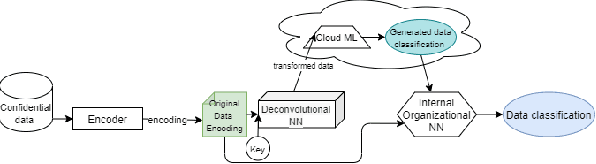
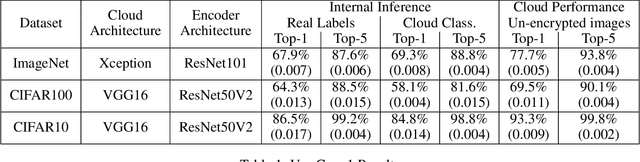
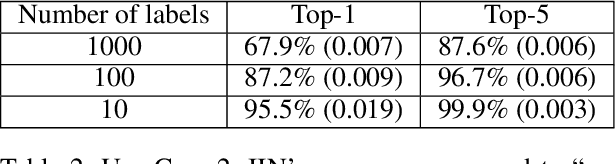
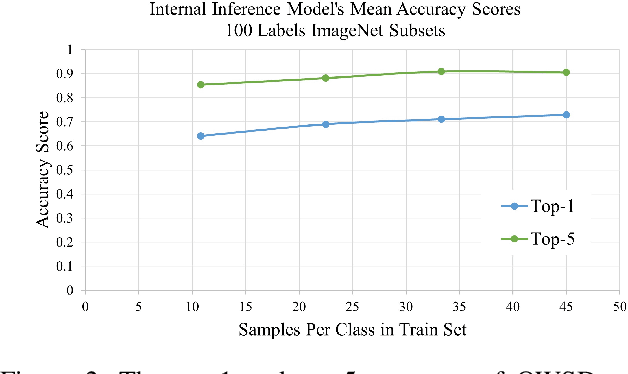
Cloud-based machine learning services (CMLS) enable organizations to take advantage of advanced models that are pre-trained on large quantities of data. The main shortcoming of using these services, however, is the difficulty of keeping the transmitted data private and secure. Asymmetric encryption requires the data to be decrypted in the cloud, while Homomorphic encryption is often too slow and difficult to implement. We propose One Way Scrambling by Deconvolution (OWSD), a deconvolution-based scrambling framework that offers the advantages of Homomorphic encryption at a fraction of the computational overhead. Extensive evaluation on multiple image datasets demonstrates OWSD's ability to achieve near-perfect classification performance when the output vector of the CMLS is sufficiently large. Additionally, we provide empirical analysis of the robustness of our approach.
SMDS-Net: Model Guided Spectral-Spatial Network for Hyperspectral Image Denoising
Dec 03, 2020
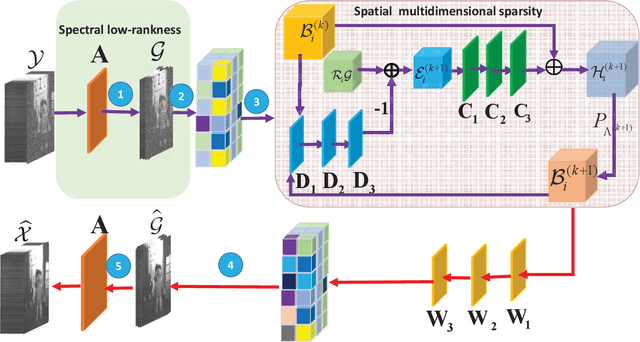


Deep learning (DL) based hyperspectral images (HSIs) denoising approaches directly learn the nonlinear mapping between observed noisy images and underlying clean images. They normally do not consider the physical characteristics of HSIs, therefore making them lack of interpretability that is key to understand their denoising mechanism.. In order to tackle this problem, we introduce a novel model guided interpretable network for HSI denoising. Specifically, fully considering the spatial redundancy, spectral low-rankness and spectral-spatial properties of HSIs, we first establish a subspace based multi-dimensional sparse model. This model first projects the observed HSIs into a low-dimensional orthogonal subspace, and then represents the projected image with a multidimensional dictionary. After that, the model is unfolded into an end-to-end network named SMDS-Net whose fundamental modules are seamlessly connected with the denoising procedure and optimization of the model. This makes SMDS-Net convey clear physical meanings, i.e., learning the low-rankness and sparsity of HSIs. Finally, all key variables including dictionaries and thresholding parameters are obtained by the end-to-end training. Extensive experiments and comprehensive analysis confirm the denoising ability and interpretability of our method against the state-of-the-art HSI denoising methods.
Quantification of groundnut leaf defects using image processing algorithms
Jun 11, 2020

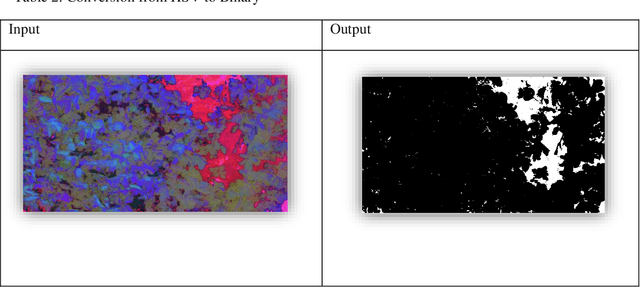
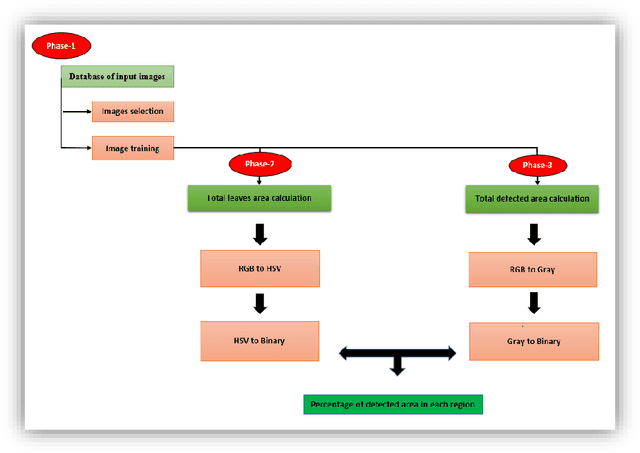
Identification, classification, and quantification of crop defects are of paramount of interest to the farmers for preventive measures and decrease the yield loss through necessary remedial actions. Due to the vast agricultural field, manual inspection of crops is tedious and time-consuming. UAV based data collection, observation, identification, and quantification of defected leaves area are considered to be an effective solution. The present work attempts to estimate the percentage of affected groundnut leaves area across four regions of Andharapradesh using image processing techniques. The proposed method involves colour space transformation combined with thresholding technique to perform the segmentation. The calibration measures are performed during acquisition with respect to UAV capturing distance, angle and other relevant camera parameters. Finally, our method can estimate the consolidated leaves and defected area. The image analysis results across these four regions reveal that around 14 - 28% of leaves area is affected across the groundnut field and thereby yield will be diminished correspondingly. Hence, it is recommended to spray the pesticides on the affected regions alone across the field to improve the plant growth and thereby yield will be increased.
Adversarial Test on Learnable Image Encryption
Jul 31, 2019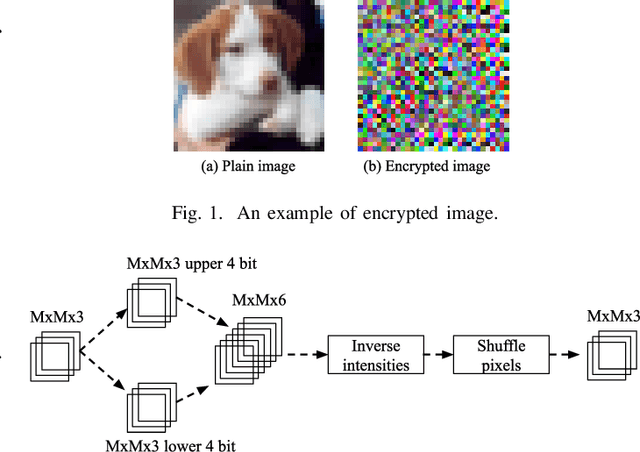
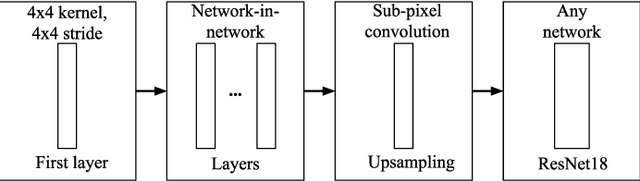
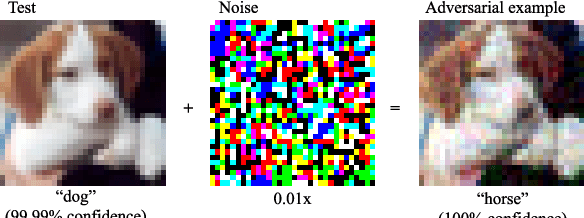
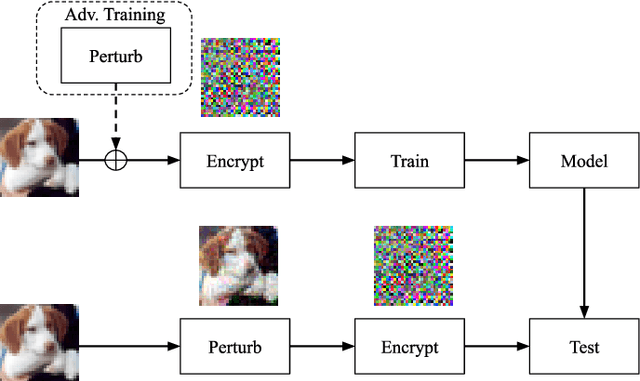
Data for deep learning should be protected for privacy preserving. Researchers have come up with the notion of learnable image encryption to satisfy the requirement. However, existing privacy preserving approaches have never considered the threat of adversarial attacks. In this paper, we ran an adversarial test on learnable image encryption in five different scenarios. The results show different behaviors of the network in the variable key scenarios and suggest learnable image encryption provides certain level of adversarial robustness.
ST-MAML: A Stochastic-Task based Method for Task-Heterogeneous Meta-Learning
Sep 27, 2021
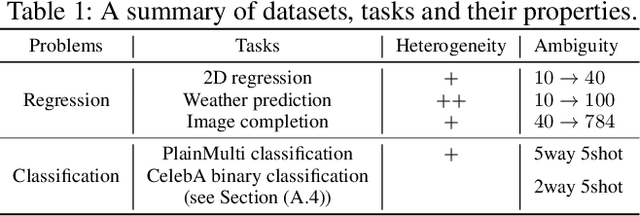
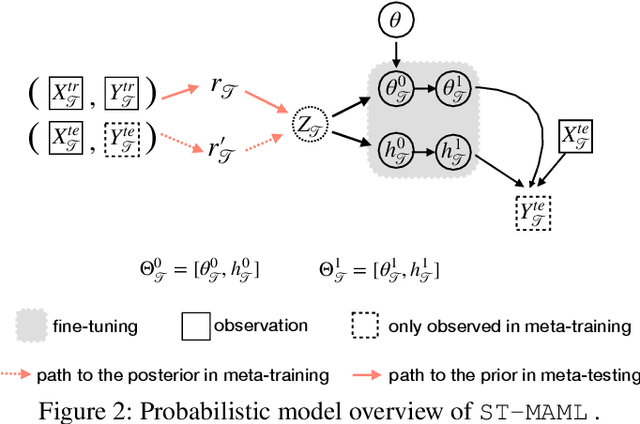

Optimization-based meta-learning typically assumes tasks are sampled from a single distribution - an assumption oversimplifies and limits the diversity of tasks that meta-learning can model. Handling tasks from multiple different distributions is challenging for meta-learning due to a so-called task ambiguity issue. This paper proposes a novel method, ST-MAML, that empowers model-agnostic meta-learning (MAML) to learn from multiple task distributions. ST-MAML encodes tasks using a stochastic neural network module, that summarizes every task with a stochastic representation. The proposed Stochastic Task (ST) strategy allows a meta-model to get tailored for the current task and enables us to learn a distribution of solutions for an ambiguous task. ST-MAML also propagates the task representation to revise the encoding of input variables. Empirically, we demonstrate that ST-MAML matches or outperforms the state-of-the-art on two few-shot image classification tasks, one curve regression benchmark, one image completion problem, and a real-world temperature prediction application. To the best of authors' knowledge, this is the first time optimization-based meta-learning method being applied on a large-scale real-world task.
A Survey of Self-Supervised and Few-Shot Object Detection
Nov 08, 2021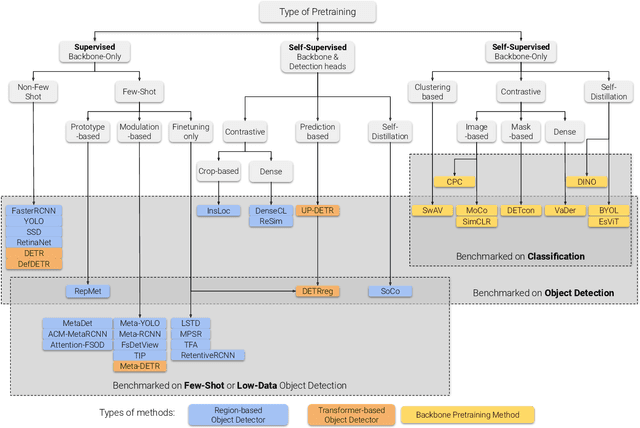

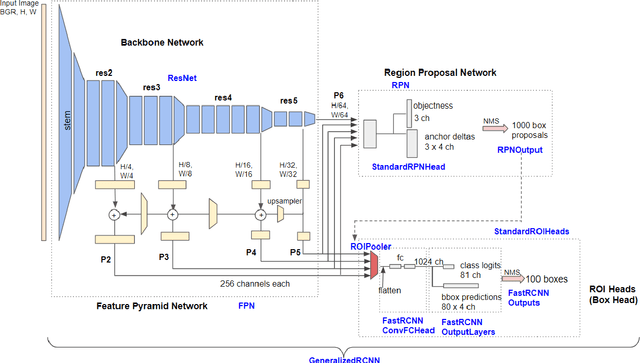
Labeling data is often expensive and time-consuming, especially for tasks such as object detection and instance segmentation, which require dense labeling of the image. While few-shot object detection is about training a model on novel (unseen) object classes with little data, it still requires prior training on many labeled examples of base (seen) classes. On the other hand, self-supervised methods aim at learning representations from unlabeled data which transfer well to downstream tasks such as object detection. Combining few-shot and self-supervised object detection is a promising research direction. In this survey, we review and characterize the most recent approaches on few-shot and self-supervised object detection. Then, we give our main takeaways and discuss future research directions. Project page at https://gabrielhuang.github.io/fsod-survey/