 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Binarized P-Network: Deep Reinforcement Learning of Robot Control from Raw Images on FPGA
Sep 10, 2021
This paper explores a Deep Reinforcement Learning (DRL) approach for designing image-based control for edge robots to be implemented on Field Programmable Gate Arrays (FPGAs). Although FPGAs are more power-efficient than CPUs and GPUs, a typical (DRL) method cannot be applied since they are composed of many Logic Blocks (LBs) for high-speed logical operations but low-speed real-number operations. To cope with this problem, we propose a novel DRL algorithm called Binarized P-Network (BPN), which learns image-input control policies using Binarized Convolutional Neural Networks (BCNNs). To alleviate the instability of reinforcement learning caused by a BCNN with low function approximation accuracy, our BPN adopts a robust value update scheme called Conservative Value Iteration, which is tolerant of function approximation errors. We confirmed the BPN's effectiveness through applications to a visual tracking task in simulation and real-robot experiments with FPGA.
PIE: Portrait Image Embedding for Semantic Control
Sep 20, 2020

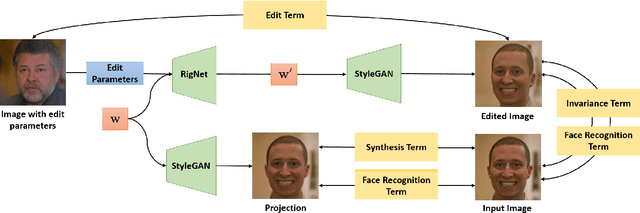

Editing of portrait images is a very popular and important research topic with a large variety of applications. For ease of use, control should be provided via a semantically meaningful parameterization that is akin to computer animation controls. The vast majority of existing techniques do not provide such intuitive and fine-grained control, or only enable coarse editing of a single isolated control parameter. Very recently, high-quality semantically controlled editing has been demonstrated, however only on synthetically created StyleGAN images. We present the first approach for embedding real portrait images in the latent space of StyleGAN, which allows for intuitive editing of the head pose, facial expression, and scene illumination in the image. Semantic editing in parameter space is achieved based on StyleRig, a pretrained neural network that maps the control space of a 3D morphable face model to the latent space of the GAN. We design a novel hierarchical non-linear optimization problem to obtain the embedding. An identity preservation energy term allows spatially coherent edits while maintaining facial integrity. Our approach runs at interactive frame rates and thus allows the user to explore the space of possible edits. We evaluate our approach on a wide set of portrait photos, compare it to the current state of the art, and validate the effectiveness of its components in an ablation study.
How to Train Your Neural Network: A Comparative Evaluation
Nov 09, 2021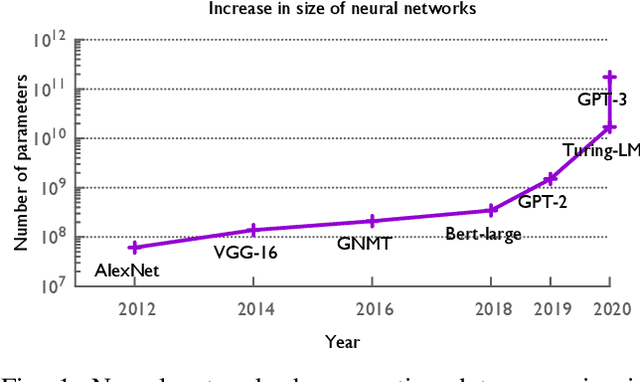
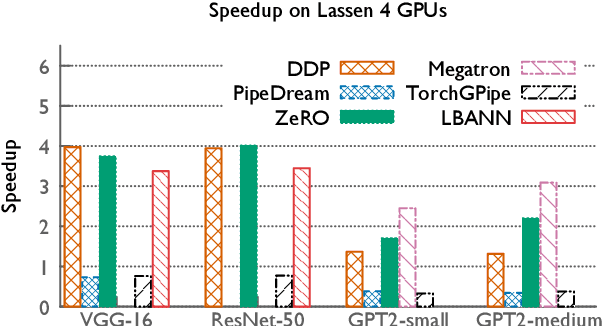
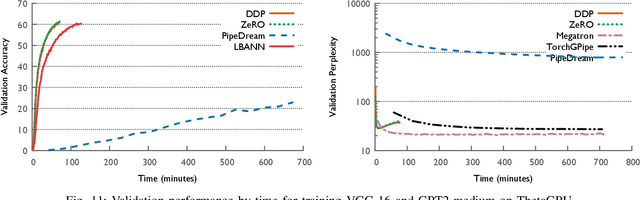
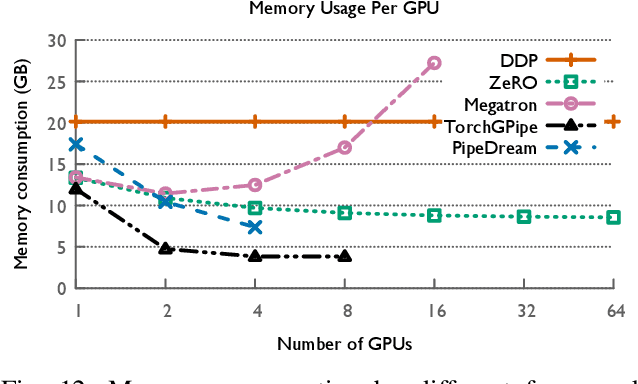
The field of deep learning has witnessed a remarkable shift towards extremely compute- and memory-intensive neural networks. These newer larger models have enabled researchers to advance state-of-the-art tools across a variety of fields. This phenomenon has spurred the development of algorithms for distributed training of neural networks over a larger number of hardware accelerators. In this paper, we discuss and compare current state-of-the-art frameworks for large scale distributed deep learning. First, we survey current practices in distributed learning and identify the different types of parallelism used. Then, we present empirical results comparing their performance on large image and language training tasks. Additionally, we address their statistical efficiency and memory consumption behavior. Based on our results, we discuss algorithmic and implementation portions of each framework which hinder performance.
Method Towards CVPR 2021 SimLocMatch Challenge
Aug 11, 2021
This report describes Megvii-3D team's approach towards SimLocMatch Challenge @ CVPR 2021 Image Matching Workshop.
DU-GAN: Generative Adversarial Networks with Dual-Domain U-Net Based Discriminators for Low-Dose CT Denoising
Aug 24, 2021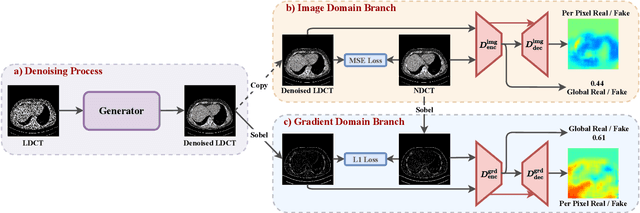
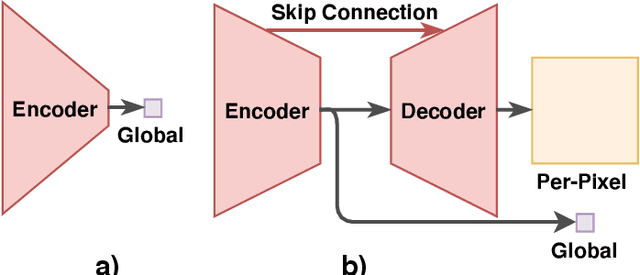
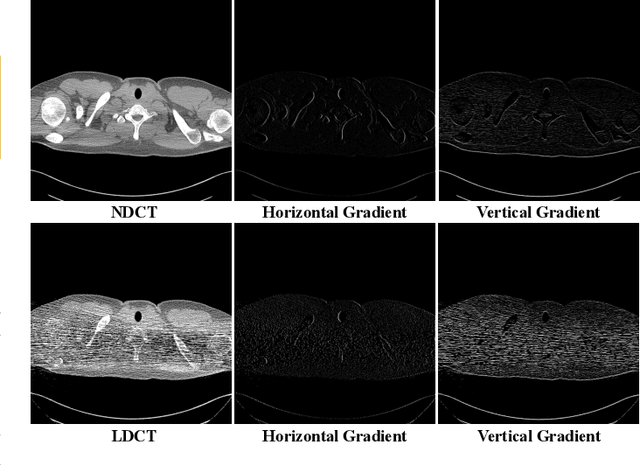
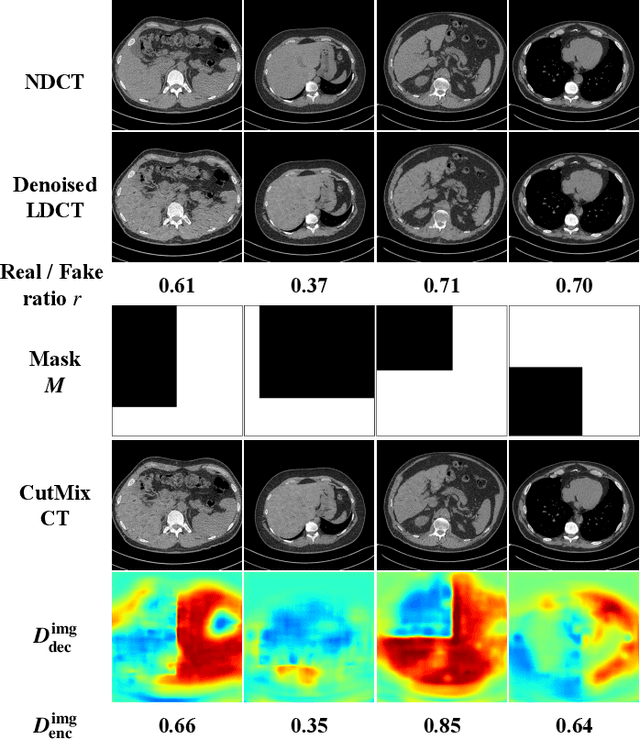
LDCT has drawn major attention in the medical imaging field due to the potential health risks of CT-associated X-ray radiation to patients. Reducing the radiation dose, however, decreases the quality of the reconstructed images, which consequently compromises the diagnostic performance. Various deep learning techniques have been introduced to improve the image quality of LDCT images through denoising. GANs-based denoising methods usually leverage an additional classification network, i.e. discriminator, to learn the most discriminate difference between the denoised and normal-dose images and, hence, regularize the denoising model accordingly; it often focuses either on the global structure or local details. To better regularize the LDCT denoising model, this paper proposes a novel method, termed DU-GAN, which leverages U-Net based discriminators in the GANs framework to learn both global and local difference between the denoised and normal-dose images in both image and gradient domains. The merit of such a U-Net based discriminator is that it can not only provide the per-pixel feedback to the denoising network through the outputs of the U-Net but also focus on the global structure in a semantic level through the middle layer of the U-Net. In addition to the adversarial training in the image domain, we also apply another U-Net based discriminator in the image gradient domain to alleviate the artifacts caused by photon starvation and enhance the edge of the denoised CT images. Furthermore, the CutMix technique enables the per-pixel outputs of the U-Net based discriminator to provide radiologists with a confidence map to visualize the uncertainty of the denoised results, facilitating the LDCT-based screening and diagnosis. Extensive experiments on the simulated and real-world datasets demonstrate superior performance over recently published methods both qualitatively and quantitatively.
Rethinking Image Mixture for Unsupervised Visual Representation Learning
Mar 11, 2020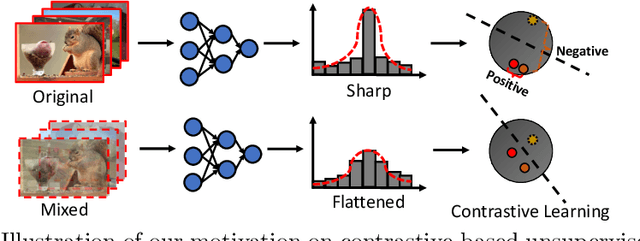


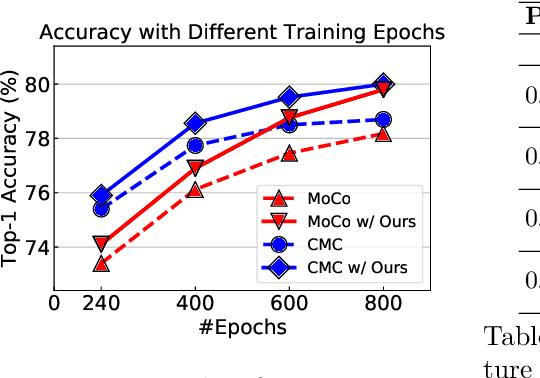
In supervised learning, smoothing label/prediction distribution in neural network training has been proven useful in preventing the model from being over-confident, and is crucial for learning more robust visual representations. This observation motivates us to explore the way to make predictions flattened in unsupervised learning. Considering that human annotated labels are not adopted in unsupervised learning, we introduce a straightforward approach to perturb input image space in order to soften the output prediction space indirectly. Despite its conceptual simplicity, we show empirically that with the simple solution -- image mixture, we can learn more robust visual representations from the transformed input, and the benefits of representations learned from this space can be inherited by the linear classification and downstream tasks.
CloudFindr: A Deep Learning Cloud Artifact Masker for Satellite DEM Data
Oct 26, 2021


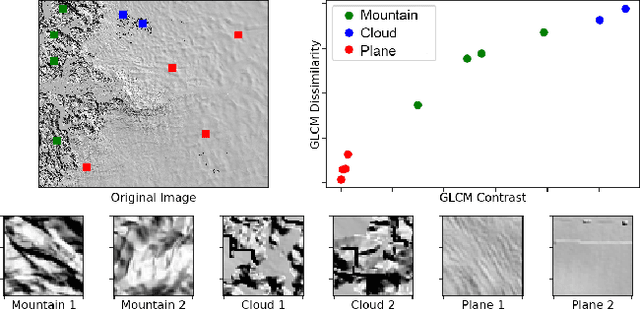
Artifact removal is an integral component of cinematic scientific visualization, and is especially challenging with big datasets in which artifacts are difficult to define. In this paper, we describe a method for creating cloud artifact masks which can be used to remove artifacts from satellite imagery using a combination of traditional image processing together with deep learning based on U-Net. Compared to previous methods, our approach does not require multi-channel spectral imagery but performs successfully on single-channel Digital Elevation Models (DEMs). DEMs are a representation of the topography of the Earth and have a variety applications including planetary science, geology, flood modeling, and city planning.
Secure Machine Learning in the Cloud Using One Way Scrambling by Deconvolution
Nov 04, 2021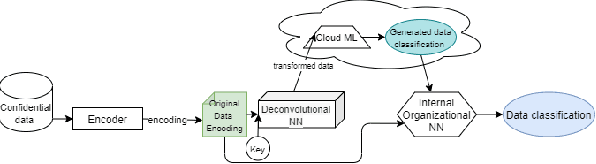
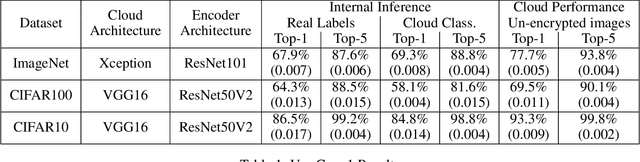
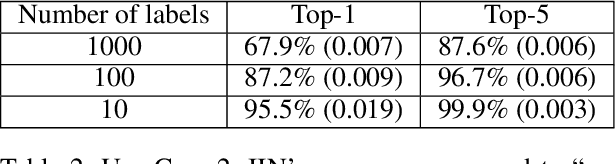
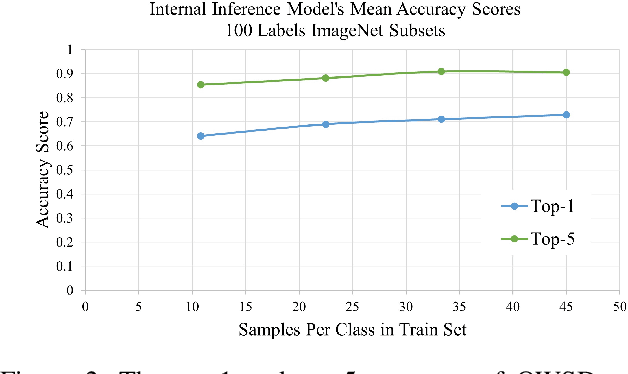
Cloud-based machine learning services (CMLS) enable organizations to take advantage of advanced models that are pre-trained on large quantities of data. The main shortcoming of using these services, however, is the difficulty of keeping the transmitted data private and secure. Asymmetric encryption requires the data to be decrypted in the cloud, while Homomorphic encryption is often too slow and difficult to implement. We propose One Way Scrambling by Deconvolution (OWSD), a deconvolution-based scrambling framework that offers the advantages of Homomorphic encryption at a fraction of the computational overhead. Extensive evaluation on multiple image datasets demonstrates OWSD's ability to achieve near-perfect classification performance when the output vector of the CMLS is sufficiently large. Additionally, we provide empirical analysis of the robustness of our approach.
Learning Structural Representations for Recipe Generation and Food Retrieval
Oct 04, 2021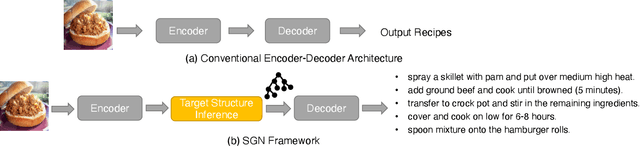
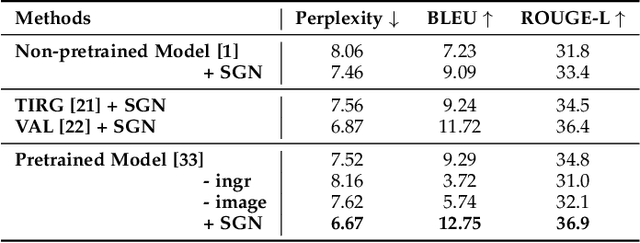
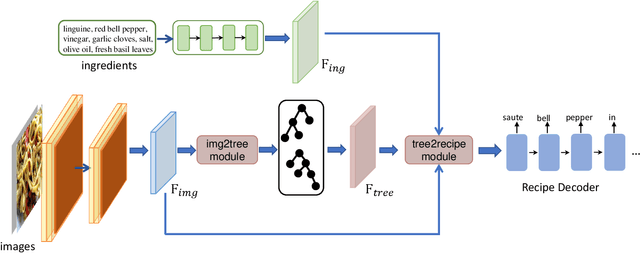
Food is significant to human daily life. In this paper, we are interested in learning structural representations for lengthy recipes, that can benefit the recipe generation and food retrieval tasks. We mainly investigate an open research task of generating cooking instructions based on food images and ingredients, which is similar to the image captioning task. However, compared with image captioning datasets, the target recipes are lengthy paragraphs and do not have annotations on structure information. To address the above limitations, we propose a novel framework of Structure-aware Generation Network (SGN) to tackle the food recipe generation task. Our approach brings together several novel ideas in a systematic framework: (1) exploiting an unsupervised learning approach to obtain the sentence-level tree structure labels before training; (2) generating trees of target recipes from images with the supervision of tree structure labels learned from (1); and (3) integrating the inferred tree structures into the recipe generation procedure. Our proposed model can produce high-quality and coherent recipes, and achieve the state-of-the-art performance on the benchmark Recipe1M dataset. We also validate the usefulness of our learned tree structures in the food cross-modal retrieval task, where the proposed model with tree representations can outperform state-of-the-art benchmark results.
Image Harmonization Datasets: HCOCO, HAdobe5k, HFlickr, and Hday2night
Aug 28, 2019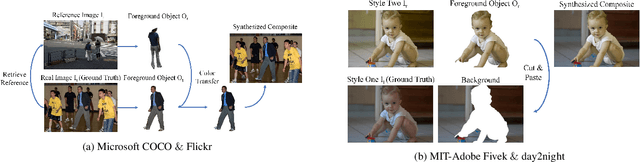
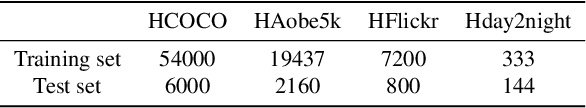
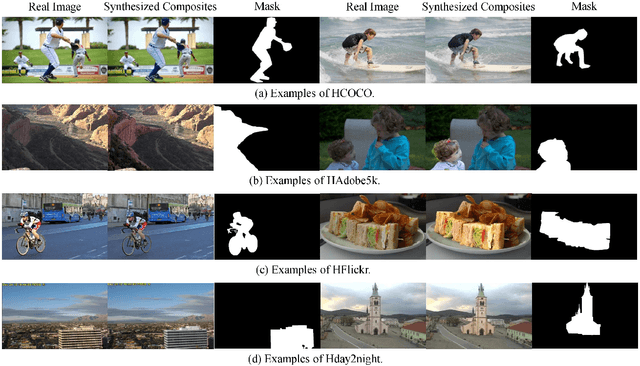
Image composition is an important operation in image processing, but the inconsistency between foreground and background significantly degrades the quality of composite image. Image harmonization, which aims to make the foreground compatible with the background, is a promising yet challenging task. However, the lack of high-quality public dataset for image harmonization, which significantly hinders the development of image harmonization techniques. Therefore, we create synthesized composite images based on existing COCO (resp., Adobe5k, day2night) dataset, leading to our HCOCO (resp., HAdobe5k, Hday2night) dataset. To enrich the diversity of our datasets, we also generate synthesized composite images based on our collected Flick images, leading to our HFlickr dataset. All four datasets are released in https://github.com/bcmi/Image_Harmonization_Datasets.