 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Motion Blur Removal Using Noisy/Blurry Image Pairs
Nov 19, 2019

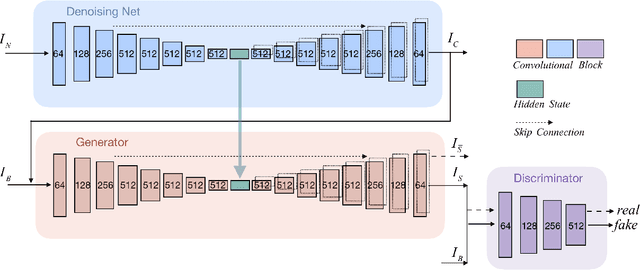
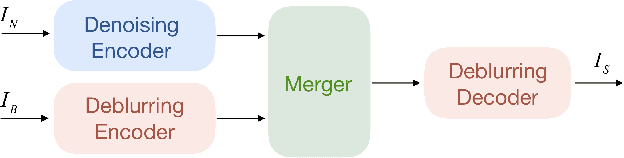

Removing spatially variant motion blur from a blurry image is a challenging problem as blur sources are complicated and difficult to model accurately. Recent progress in deep neural networks suggests that kernel free single image deblurring can be efficiently performed, but questions about deblurring performance persist. Thus, we propose to restore a sharp image by fusing a pair of noisy/blurry images captured in a burst. Two neural network structures, DeblurRNN and DeblurMerger, are presented to exploit the pair of images in a sequential manner or parallel manner. To boost the training, gradient loss, adversarial loss and spectral normalization are leveraged. The training dataset that consists of pairs of noisy/blurry images and the corresponding ground truth sharp image is synthesized based on the benchmark dataset GOPRO. We evaluated the trained networks on a variety of synthetic datasets and real image pairs. The results demonstrate that the proposed approach outperforms the state-of-the-art both qualitatively and quantitatively.
Comparing concepts of quantum and classical neural network models for image classification task
Aug 19, 2021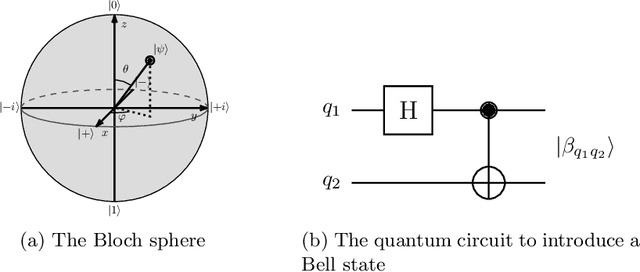

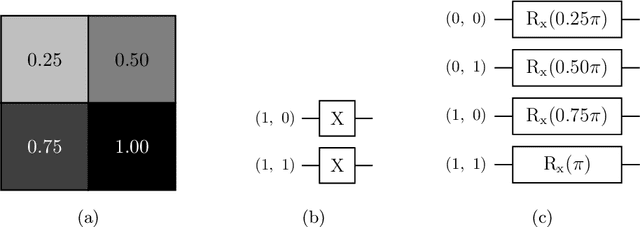
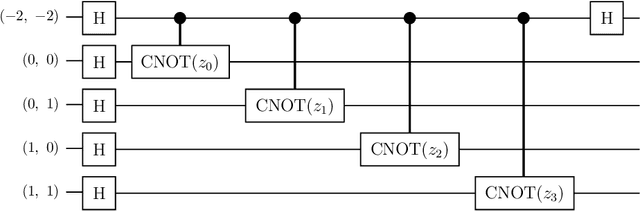
While quantum architectures are still under development, when available, they will only be able to process quantum data when machine learning algorithms can only process numerical data. Therefore, in the issues of classification or regression, it is necessary to simulate and study quantum systems that will transfer the numerical input data to a quantum form and enable quantum computers to use the available methods of machine learning. This material includes the results of experiments on training and performance of a hybrid quantum-classical neural network developed for the problem of classification of handwritten digits from the MNIST data set. The comparative results of two models: classical and quantum neural networks of a similar number of training parameters, indicate that the quantum network, although its simulation is time-consuming, overcomes the classical network (it has better convergence and achieves higher training and testing accuracy).
* 11 pages, 6 figures. The final publication is available via https://doi.org/10.1007/978-3-030-81523-3_6
LiteDenseNet: A Lightweight Network for Hyperspectral Image Classification
Apr 17, 2020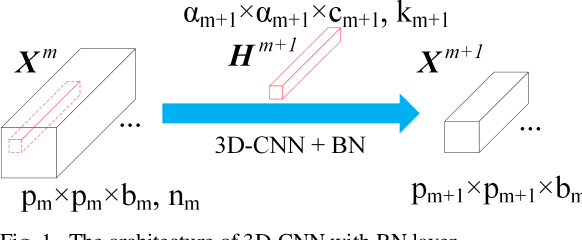
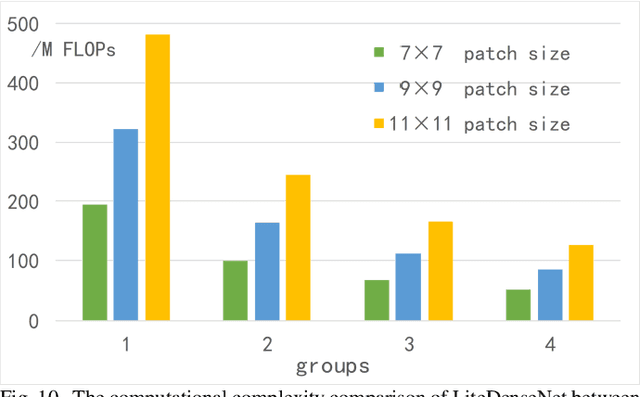
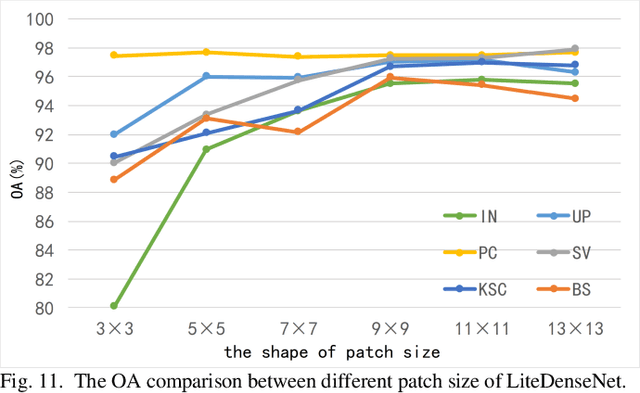
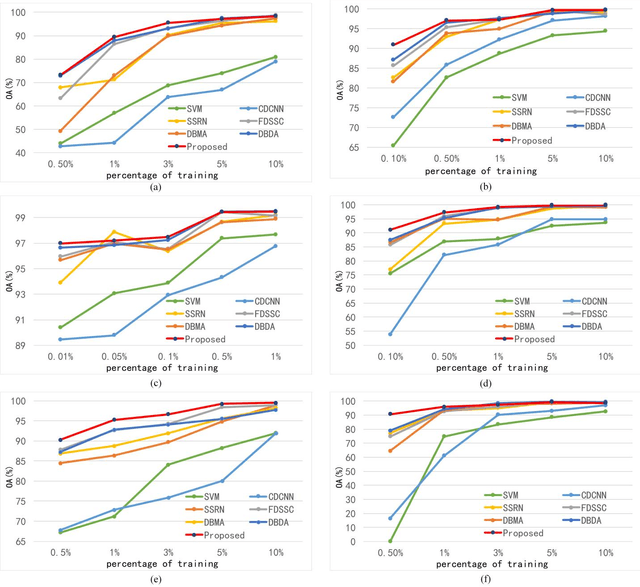
Hyperspectral Image (HSI) classification based on deep learning has been an attractive area in recent years. However, as a kind of data-driven algorithm, deep learning method usually requires numerous computational resources and high-quality labelled dataset, while the cost of high-performance computing and data annotation is expensive. In this paper, to reduce dependence on massive calculation and labelled samples, we propose a lightweight network architecture (LiteDenseNet) based on DenseNet for Hyperspectral Image Classification. Inspired by GoogLeNet and PeleeNet, we design a 3D two-way dense layer to capture the local and global features of the input. As convolution is a computationally intensive operation, we introduce group convolution to decrease calculation cost and parameter size further. Thus, the number of parameters and the consumptions of calculation are observably less than contrapositive deep learning methods, which means LiteDenseNet owns simpler architecture and higher efficiency. A series of quantitative experiences on 6 widely used hyperspectral datasets show that the proposed LiteDenseNet obtains the state-of-the-art performance, even though when the absence of labelled samples is severe.
A Survey of Self-Supervised and Few-Shot Object Detection
Oct 27, 2021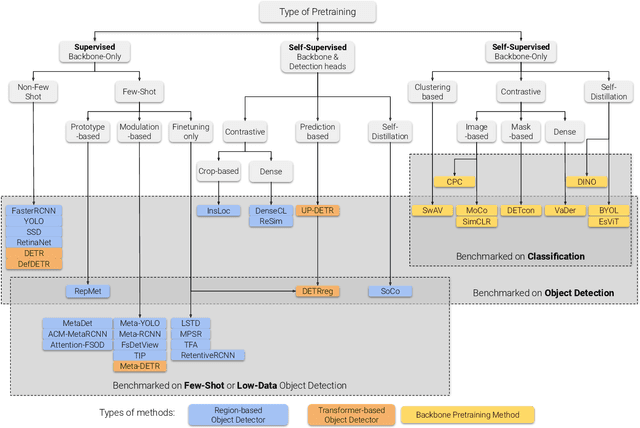

Labeling data is often expensive and time-consuming, especially for tasks such as object detection and instance segmentation, which require dense labeling of the image. While few-shot object detection is about training a model on novel (unseen) object classes with little data, it still requires prior training on many labeled examples of base (seen) classes. On the other hand, self-supervised methods aim at learning representations from unlabeled data which transfer well to downstream tasks such as object detection. Combining few-shot and self-supervised object detection is a promising research direction. In this survey, we review and characterize the most recent approaches on few-shot and self-supervised object detection. Then, we give our main takeaways and discuss future research directions.
Asking questions on handwritten document collections
Oct 02, 2021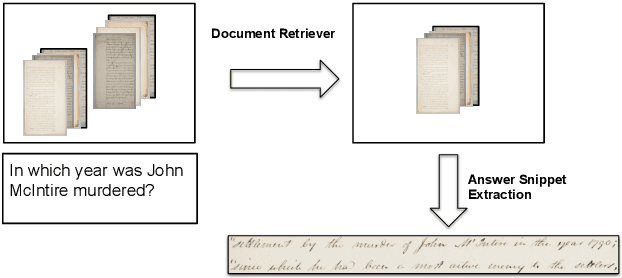

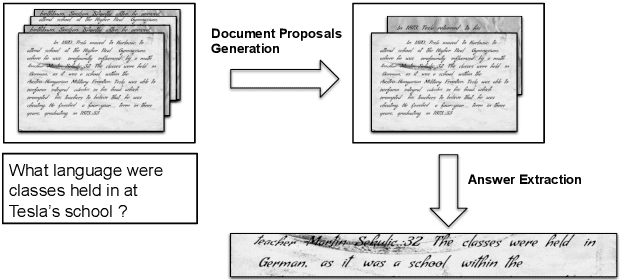

This work addresses the problem of Question Answering (QA) on handwritten document collections. Unlike typical QA and Visual Question Answering (VQA) formulations where the answer is a short text, we aim to locate a document snippet where the answer lies. The proposed approach works without recognizing the text in the documents. We argue that the recognition-free approach is suitable for handwritten documents and historical collections where robust text recognition is often difficult. At the same time, for human users, document image snippets containing answers act as a valid alternative to textual answers. The proposed approach uses an off-the-shelf deep embedding network which can project both textual words and word images into a common sub-space. This embedding bridges the textual and visual domains and helps us retrieve document snippets that potentially answer a question. We evaluate results of the proposed approach on two new datasets: (i) HW-SQuAD: a synthetic, handwritten document image counterpart of SQuAD1.0 dataset and (ii) BenthamQA: a smaller set of QA pairs defined on documents from the popular Bentham manuscripts collection. We also present a thorough analysis of the proposed recognition-free approach compared to a recognition-based approach which uses text recognized from the images using an OCR. Datasets presented in this work are available to download at docvqa.org
* pre-print version
Transform and Tell: Entity-Aware News Image Captioning
Apr 17, 2020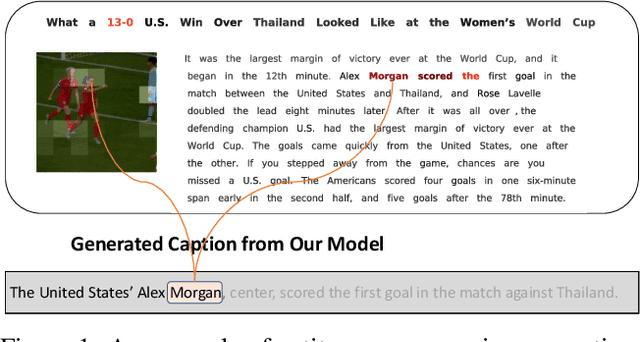
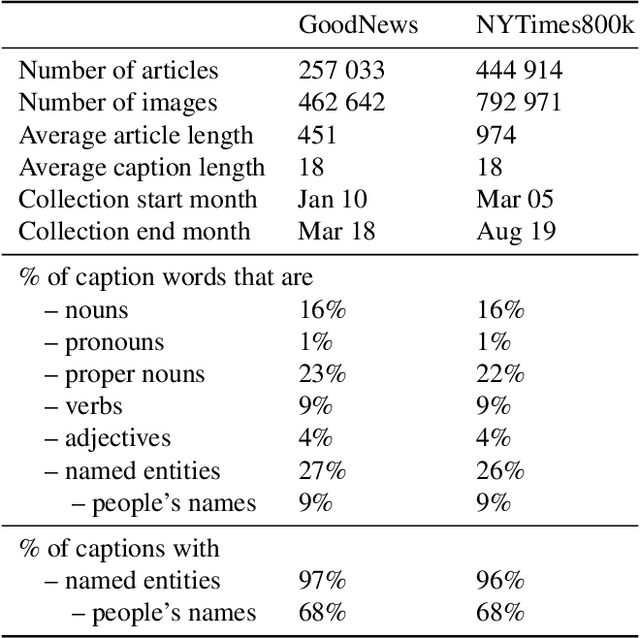
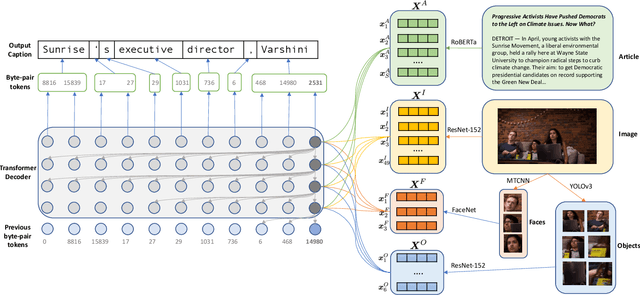
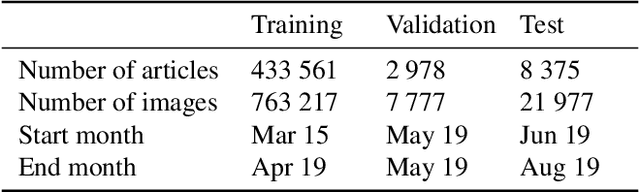
We propose an end-to-end model which generates captions for images embedded in news articles. News images present two key challenges: they rely on real-world knowledge, especially about named entities; and they typically have linguistically rich captions that include uncommon words. We address the first challenge by associating words in the caption with faces and objects in the image, via a multi-modal, multi-head attention mechanism. We tackle the second challenge with a state-of-the-art transformer language model that uses byte-pair-encoding to generate captions as a sequence of word parts. On the GoodNews dataset, our model outperforms the previous state of the art by a factor of four in CIDEr score (13 to 54). This performance gain comes from a unique combination of language models, word representation, image embeddings, face embeddings, object embeddings, and improvements in neural network design. We also introduce the NYTimes800k dataset which is 70% larger than GoodNews, has higher article quality, and includes the locations of images within articles as an additional contextual cue.
Multi-centred Strong Augmentation via Contrastive Learning for Unsupervised Lesion Detection and Segmentation
Sep 03, 2021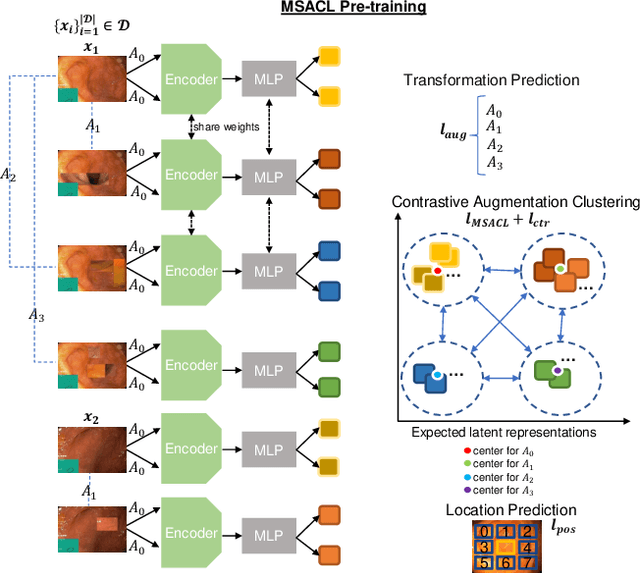
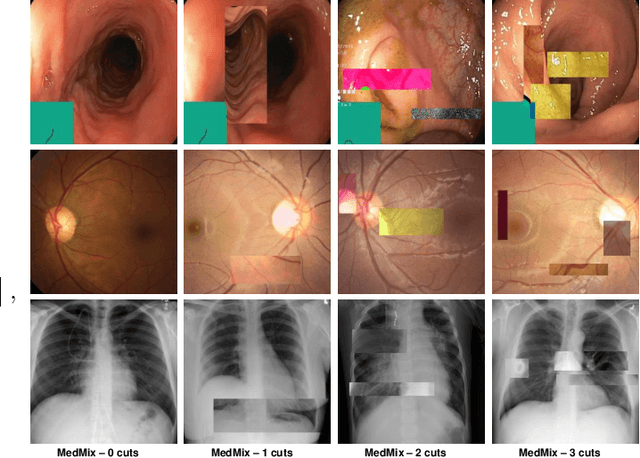
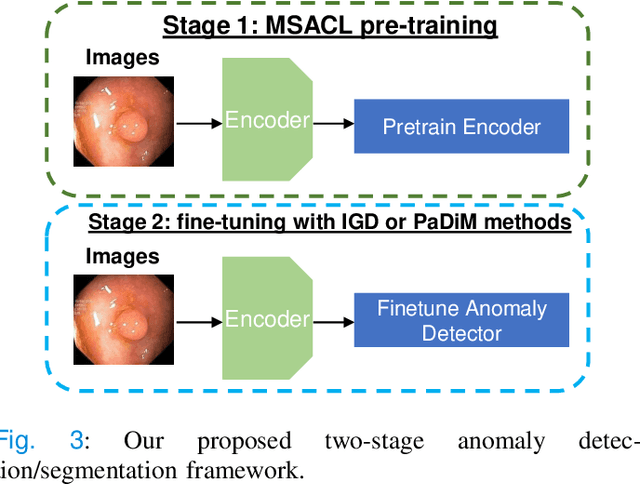
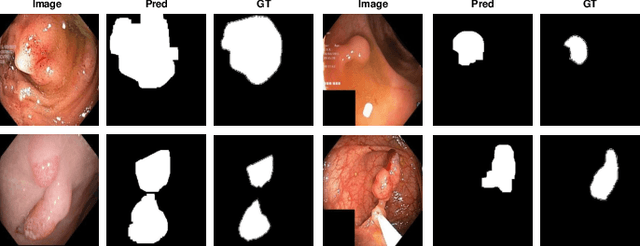
The scarcity of high quality medical image annotations hinders the implementation of accurate clinical applications for detecting and segmenting abnormal lesions. To mitigate this issue, the scientific community is working on the development of unsupervised anomaly detection (UAD) systems that learn from a training set containing only normal (i.e., healthy) images, where abnormal samples (i.e., unhealthy) are detected and segmented based on how much they deviate from the learned distribution of normal samples. One significant challenge faced by UAD methods is how to learn effective low-dimensional image representations that are sensitive enough to detect and segment abnormal lesions of varying size, appearance and shape. To address this challenge, we propose a novel self-supervised UAD pre-training algorithm, named Multi-centred Strong Augmentation via Contrastive Learning (MSACL). MSACL learns representations by separating several types of strong and weak augmentations of normal image samples, where the weak augmentations represent normal images and strong augmentations denote synthetic abnormal images. To produce such strong augmentations, we introduce MedMix, a novel data augmentation strategy that creates new training images with realistic looking lesions (i.e., anomalies) in normal images. The pre-trained representations from MSACL are generic and can be used to improve the efficacy of different types of off-the-shelf state-of-the-art (SOTA) UAD models. Comprehensive experimental results show that the use of MSACL largely improves these SOTA UAD models on four medical imaging datasets from diverse organs, namely colonoscopy, fundus screening and covid-19 chest-ray datasets.
Towards Evaluating Gaussian Blurring in Perceptual Hashing as a Facial Image Filter
Feb 01, 2020
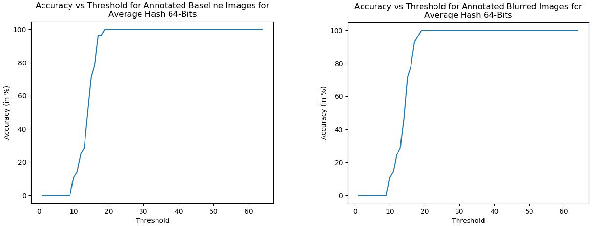
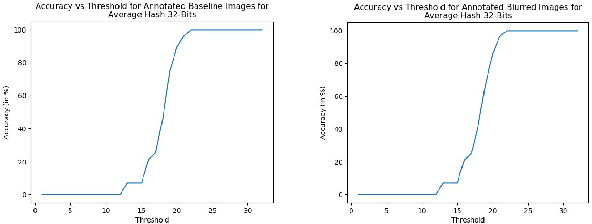
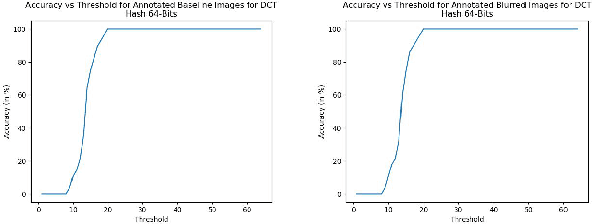
With the growth in social media, there is a huge amount of images of faces available on the internet. Often, people use other people's pictures on their own profile. Perceptual hashing is often used to detect whether two images are identical. Therefore, it can be used to detect whether people are misusing others' pictures. In perceptual hashing, a hash is calculated for a given image, and a new test image is mapped to one of the existing hashes if duplicate features are present. Therefore, it can be used as an image filter to flag banned image content or adversarial attacks --which are modifications that are made on purpose to deceive the filter-- even though the content might be changed to deceive the filters. For this reason, it is critical for perceptual hashing to be robust enough to take transformations such as resizing, cropping, and slight pixel modifications into account. In this paper, we would like to propose to experiment with effect of gaussian blurring in perceptual hashing for detecting misuse of personal images specifically for face images. We hypothesize that use of gaussian blurring on the image before calculating its hash will increase the accuracy of our filter that detects adversarial attacks which consist of image cropping, adding text annotation, and image rotation.
Continual Active Learning Using Pseudo-Domains for Limited Labelling Resources and Changing Acquisition Characteristics
Nov 25, 2021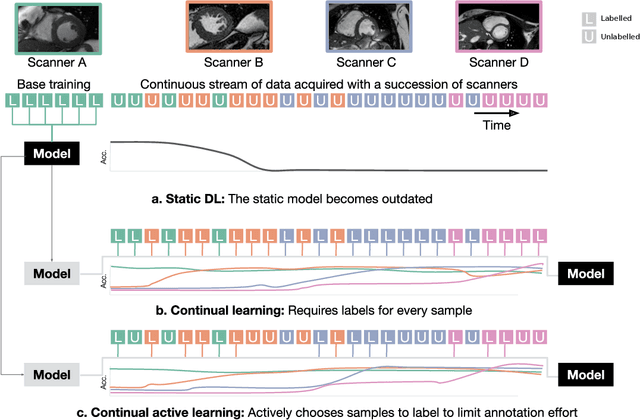
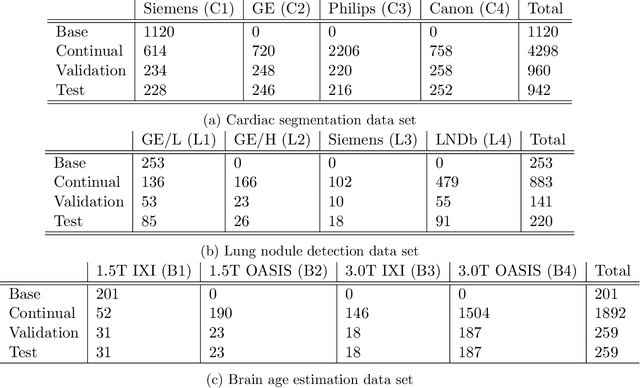
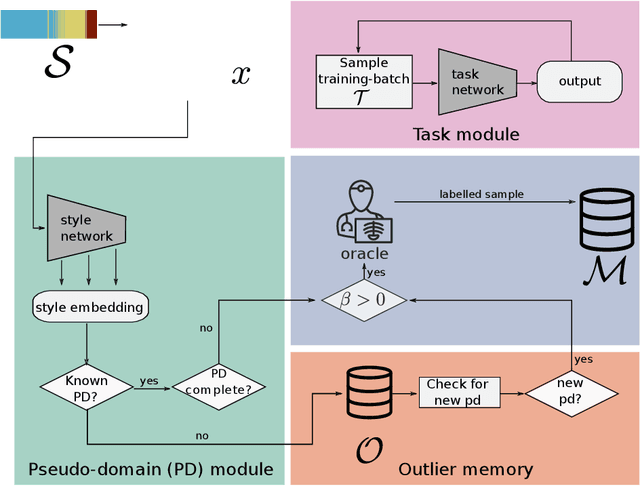
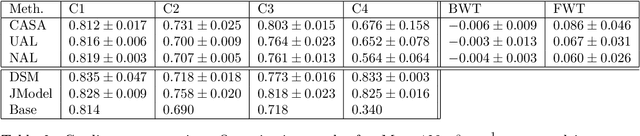
Machine learning in medical imaging during clinical routine is impaired by changes in scanner protocols, hardware, or policies resulting in a heterogeneous set of acquisition settings. When training a deep learning model on an initial static training set, model performance and reliability suffer from changes of acquisition characteristics as data and targets may become inconsistent. Continual learning can help to adapt models to the changing environment by training on a continuous data stream. However, continual manual expert labelling of medical imaging requires substantial effort. Thus, ways to use labelling resources efficiently on a well chosen sub-set of new examples is necessary to render this strategy feasible. Here, we propose a method for continual active learning operating on a stream of medical images in a multi-scanner setting. The approach automatically recognizes shifts in image acquisition characteristics - new domains -, selects optimal examples for labelling and adapts training accordingly. Labelling is subject to a limited budget, resembling typical real world scenarios. To demonstrate generalizability, we evaluate the effectiveness of our method on three tasks: cardiac segmentation, lung nodule detection and brain age estimation. Results show that the proposed approach outperforms other active learning methods, while effectively counteracting catastrophic forgetting.
Learning Spatially Structured Image Transformations Using Planar Neural Networks
Dec 03, 2019

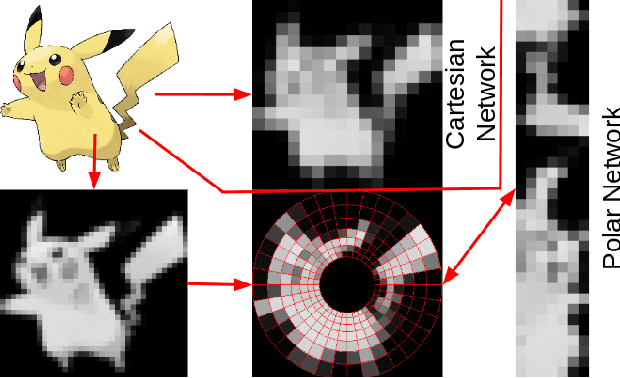
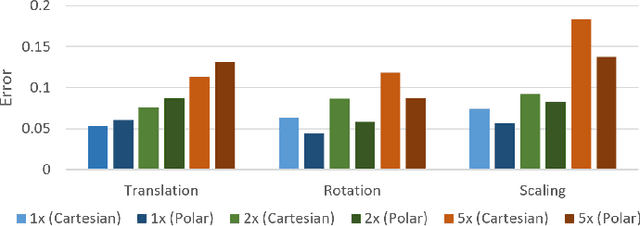
Learning image transformations is essential to the idea of mental simulation as a method of cognitive inference. We take a connectionist modeling approach, using planar neural networks to learn fundamental imagery transformations, like translation, rotation, and scaling, from perceptual experiences in the form of image sequences. We investigate how variations in network topology, training data, and image shape, among other factors, affect the efficiency and effectiveness of learning visual imagery transformations, including effectiveness of transfer to operating on new types of data.