 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Efficient Continuous Manifold Learning for Time Series Modeling
Dec 03, 2021
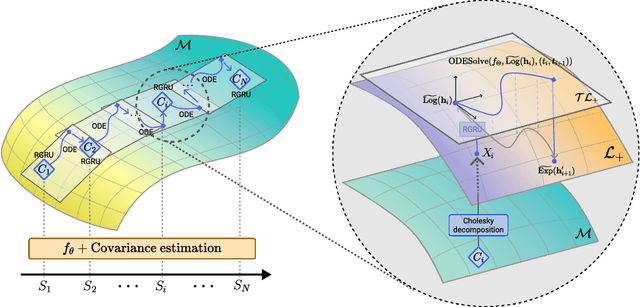
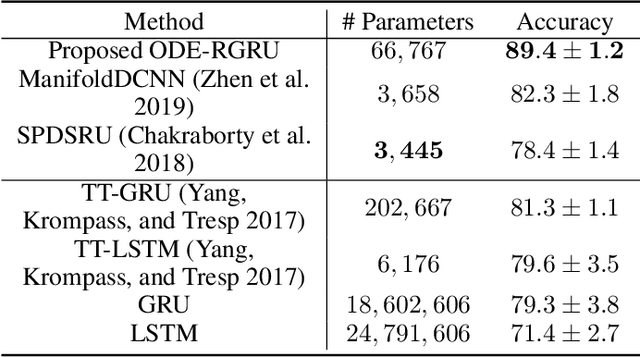
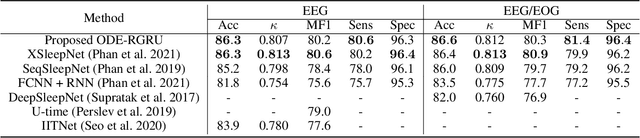
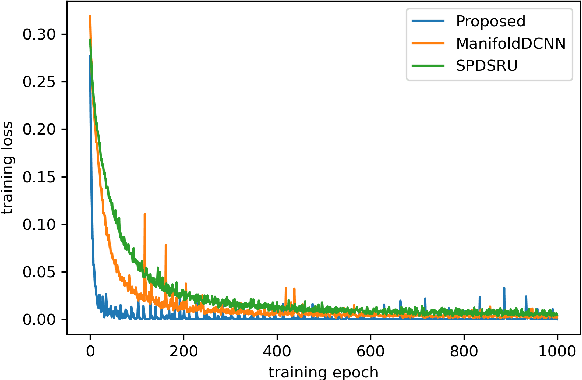
Modeling non-Euclidean data is drawing attention along with the unprecedented successes of deep neural networks in diverse fields. In particular, symmetric positive definite (SPD) matrix is being actively studied in computer vision, signal processing, and medical image analysis, thanks to its ability to learn appropriate statistical representations. However, due to its strong constraints, it remains challenging for optimization problems or inefficient computation costs, especially, within a deep learning framework. In this paper, we propose to exploit a diffeomorphism mapping between Riemannian manifolds and a Cholesky space, by which it becomes feasible not only to efficiently solve optimization problems but also to reduce computation costs greatly. Further, in order for dynamics modeling in time series data, we devise a continuous manifold learning method by integrating a manifold ordinary differential equation and a gated recurrent neural network in a systematic manner. It is noteworthy that because of the nice parameterization of matrices in a Cholesky space, it is straightforward to train our proposed network with Riemannian geometric metrics equipped. We demonstrate through experiments that the proposed model can be efficiently and reliably trained as well as outperform existing manifold methods and state-of-the-art methods in two classification tasks: action recognition and sleep staging classification.
Multi-Modal MRI Reconstruction with Spatial Alignment Network
Aug 12, 2021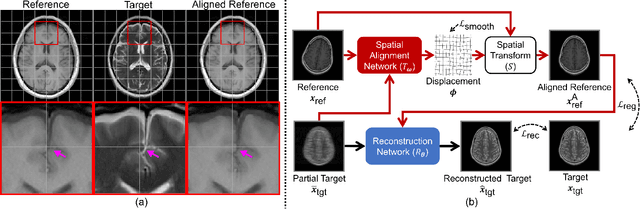
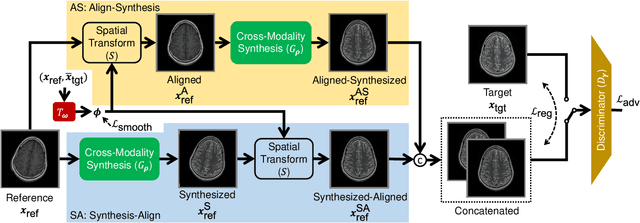

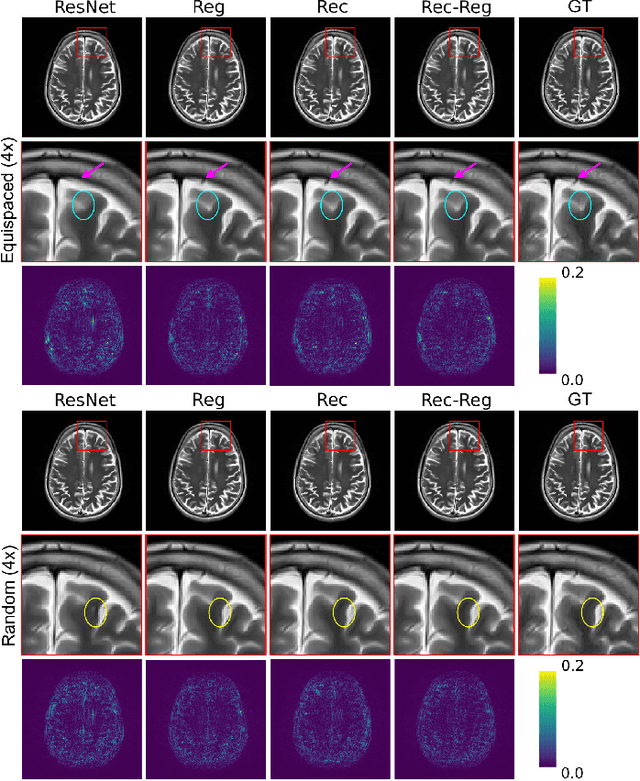
In clinical practice, magnetic resonance imaging (MRI) with multiple contrasts is usually acquired in a single study to assess different properties of the same region of interest in human body. The whole acquisition process can be accelerated by having one or more modalities under-sampled in the k-space. Recent researches demonstrate that, considering the redundancy between different contrasts or modalities, a target MRI modality under-sampled in the k-space can be better reconstructed with the helps from a fully-sampled sequence (i.e., the reference modality). It implies that, in the same study of the same subject, multiple sequences can be utilized together toward the purpose of highly efficient multi-modal reconstruction. However, we find that multi-modal reconstruction can be negatively affected by subtle spatial misalignment between different sequences, which is actually common in clinical practice. In this paper, we integrate the spatial alignment network with reconstruction, to improve the quality of the reconstructed target modality. Specifically, the spatial alignment network estimates the spatial misalignment between the fully-sampled reference and the under-sampled target images, and warps the reference image accordingly. Then, the aligned fully-sampled reference image joins the under-sampled target image in the reconstruction network, to produce the high-quality target image. Considering the contrast difference between the target and the reference, we particularly design the cross-modality-synthesis-based registration loss, in combination with the reconstruction loss, to jointly train the spatial alignment network and the reconstruction network. Our experiments on both clinical MRI and multi-coil k-space raw data demonstrate the superiority and robustness of our spatial alignment network. Code is publicly available at https://github.com/woxuankai/SpatialAlignmentNetwork.
Label Distribution Amendment with Emotional Semantic Correlations for Facial Expression Recognition
Jul 23, 2021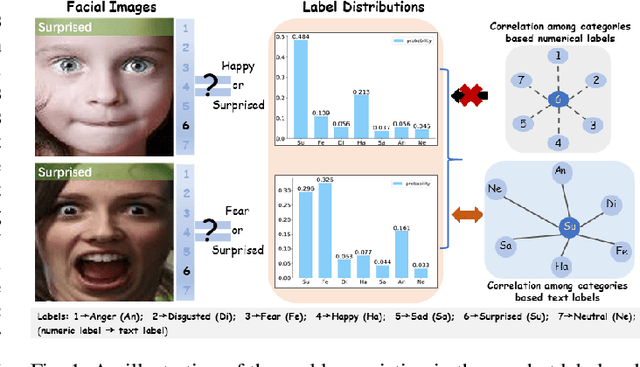
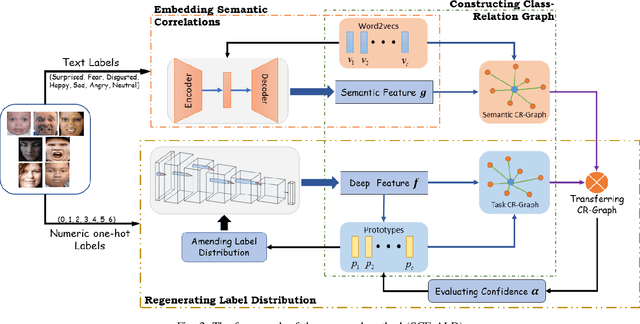
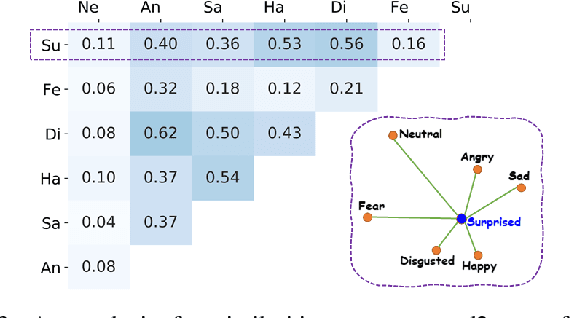
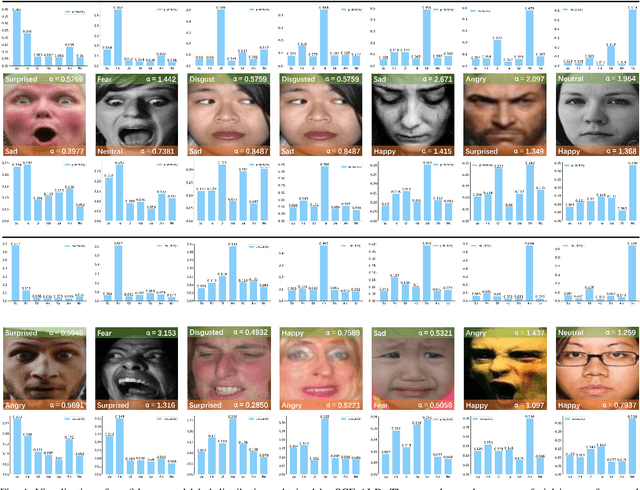
By utilizing label distribution learning, a probability distribution is assigned for a facial image to express a compound emotion, which effectively improves the problem of label uncertainties and noises occurred in one-hot labels. In practice, it is observed that correlations among emotions are inherently different, such as surprised and happy emotions are more possibly synchronized than surprised and neutral. It indicates the correlation may be crucial for obtaining a reliable label distribution. Based on this, we propose a new method that amends the label distribution of each facial image by leveraging correlations among expressions in the semantic space. Inspired by inherently diverse correlations among word2vecs, the topological information among facial expressions is firstly explored in the semantic space, and each image is embedded into the semantic space. Specially, a class-relation graph is constructed to transfer the semantic correlation among expressions into the task space. By comparing semantic and task class-relation graphs of each image, the confidence of its label distribution is evaluated. Based on the confidence, the label distribution is amended by enhancing samples with higher confidence and weakening samples with lower confidence. Experimental results demonstrate the proposed method is more effective than compared state-of-the-art methods.
Image compression optimized for 3D reconstruction by utilizing deep neural networks
Mar 27, 2020
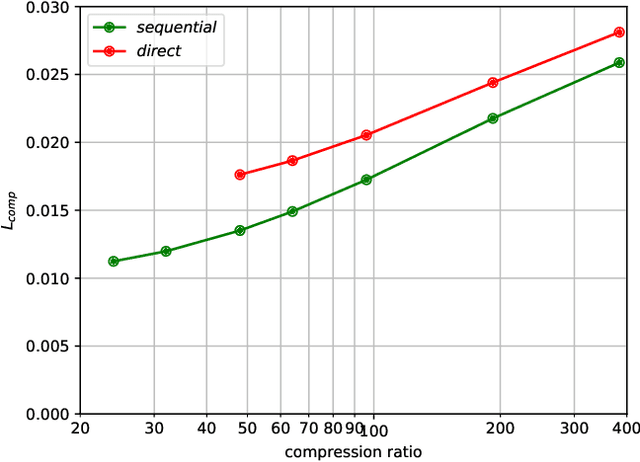
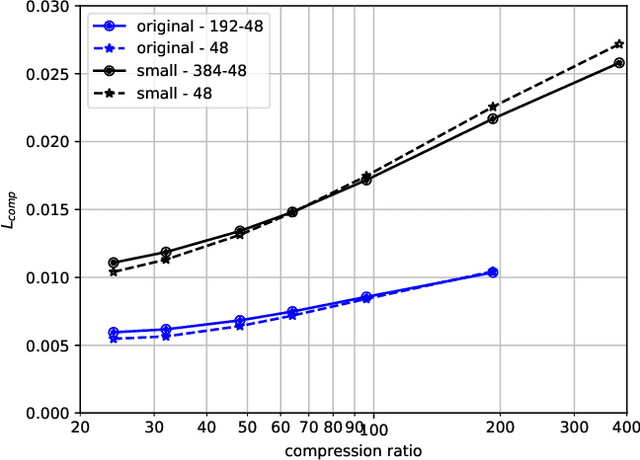
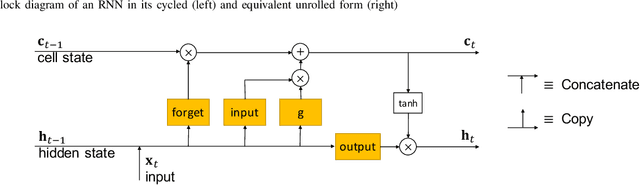
Computer vision tasks are often expected to be executed on compressed images. Classical image compression standards like JPEG 2000 are widely used. However, they do not account for the specific end-task at hand. Motivated by works on recurrent neural network (RNN)-based image compression and three-dimensional (3D) reconstruction, we propose unified network architectures to solve both tasks jointly. These joint models provide image compression tailored for the specific task of 3D reconstruction. Images compressed by our proposed models, yield 3D reconstruction performance superior as compared to using JPEG 2000 compression. Our models significantly extend the range of compression rates for which 3D reconstruction is possible. We also show that this can be done highly efficiently at almost no additional cost to obtain compression on top of the computation already required for performing the 3D reconstruction task.
Is RobustBench/AutoAttack a suitable Benchmark for Adversarial Robustness?
Dec 02, 2021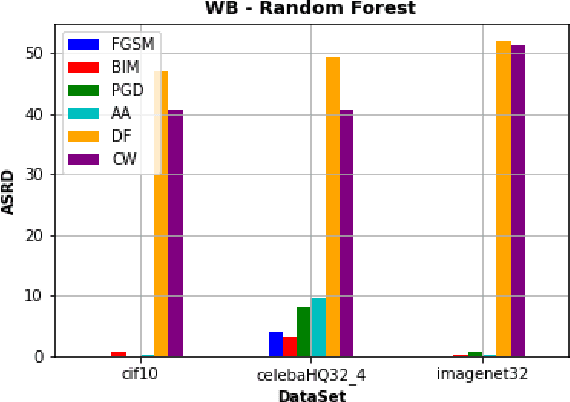
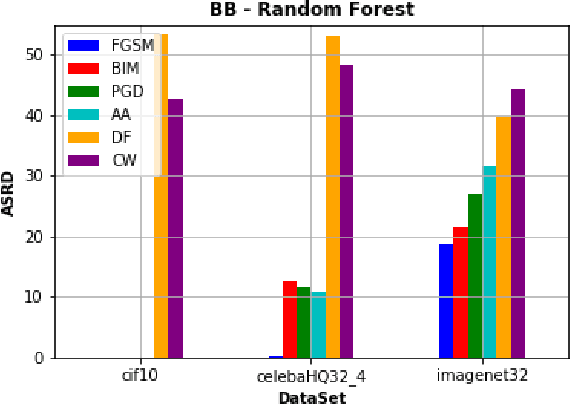
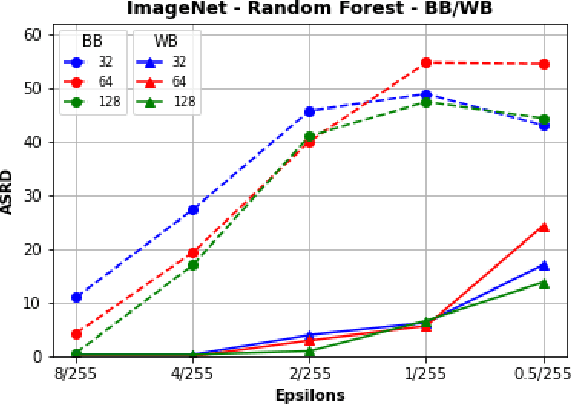
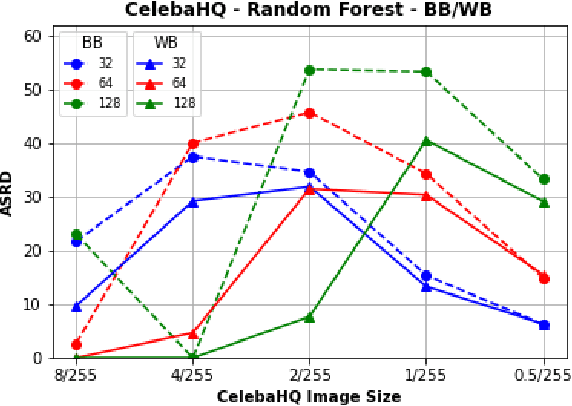
Recently, RobustBench (Croce et al. 2020) has become a widely recognized benchmark for the adversarial robustness of image classification networks. In its most commonly reported sub-task, RobustBench evaluates and ranks the adversarial robustness of trained neural networks on CIFAR10 under AutoAttack (Croce and Hein 2020b) with l-inf perturbations limited to eps = 8/255. With leading scores of the currently best performing models of around 60% of the baseline, it is fair to characterize this benchmark to be quite challenging. Despite its general acceptance in recent literature, we aim to foster discussion about the suitability of RobustBench as a key indicator for robustness which could be generalized to practical applications. Our line of argumentation against this is two-fold and supported by excessive experiments presented in this paper: We argue that I) the alternation of data by AutoAttack with l-inf, eps = 8/255 is unrealistically strong, resulting in close to perfect detection rates of adversarial samples even by simple detection algorithms and human observers. We also show that other attack methods are much harder to detect while achieving similar success rates. II) That results on low-resolution data sets like CIFAR10 do not generalize well to higher resolution images as gradient-based attacks appear to become even more detectable with increasing resolutions.
Improving accuracy and speeding up Document Image Classification through parallel systems
Jun 16, 2020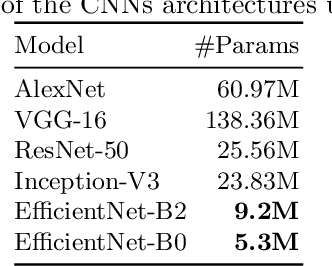
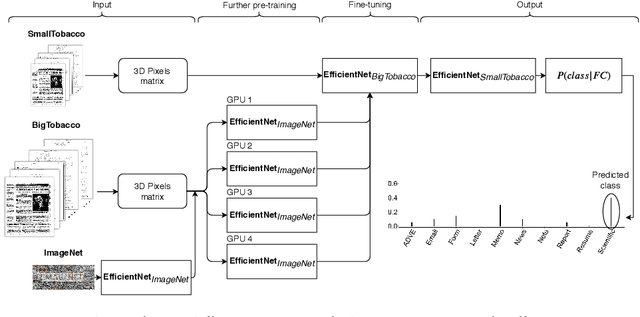
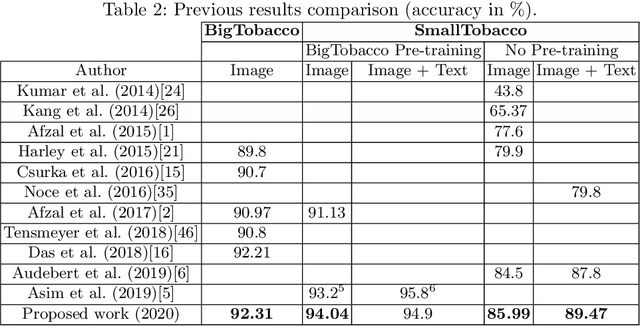
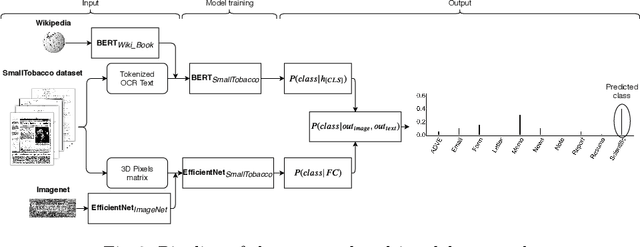
This paper presents a study showing the benefits of the EfficientNet models compared with heavier Convolutional Neural Networks (CNNs) in the Document Classification task, essential problem in the digitalization process of institutions. We show in the RVL-CDIP dataset that we can improve previous results with a much lighter model and present its transfer learning capabilities on a smaller in-domain dataset such as Tobacco3482. Moreover, we present an ensemble pipeline which is able to boost solely image input by combining image model predictions with the ones generated by BERT model on extracted text by OCR. We also show that the batch size can be effectively increased without hindering its accuracy so that the training process can be sped up by parallelizing throughout multiple GPUs, decreasing the computational time needed. Lastly, we expose the training performance differences between PyTorch and Tensorflow Deep Learning frameworks.
Can Vision Transformers Perform Convolution?
Nov 02, 2021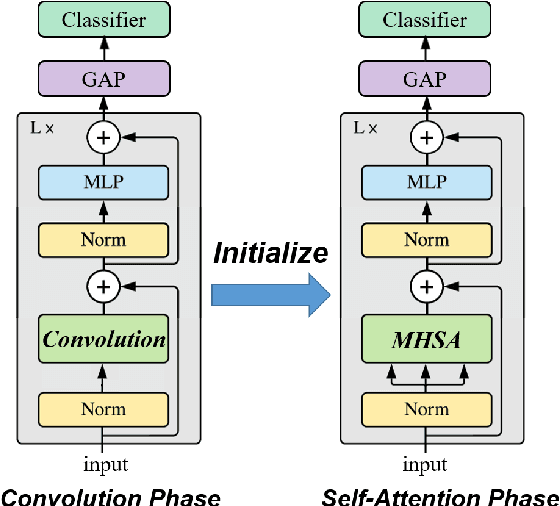
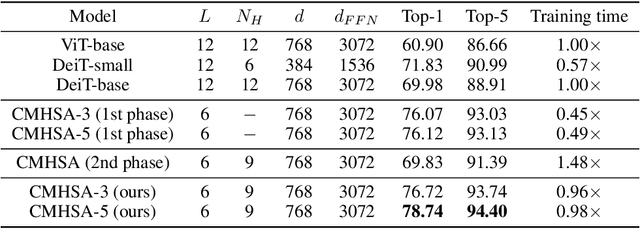
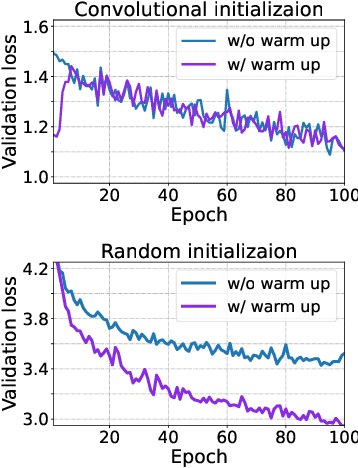
Several recent studies have demonstrated that attention-based networks, such as Vision Transformer (ViT), can outperform Convolutional Neural Networks (CNNs) on several computer vision tasks without using convolutional layers. This naturally leads to the following questions: Can a self-attention layer of ViT express any convolution operation? In this work, we prove that a single ViT layer with image patches as the input can perform any convolution operation constructively, where the multi-head attention mechanism and the relative positional encoding play essential roles. We further provide a lower bound on the number of heads for Vision Transformers to express CNNs. Corresponding with our analysis, experimental results show that the construction in our proof can help inject convolutional bias into Transformers and significantly improve the performance of ViT in low data regimes.
Efficient Neural Radiance Fields with Learned Depth-Guided Sampling
Dec 02, 2021
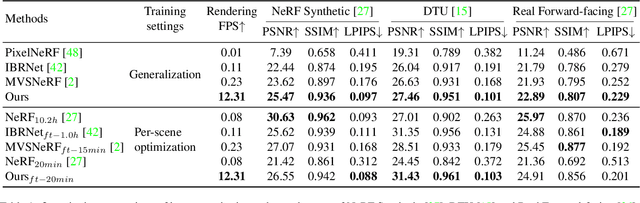
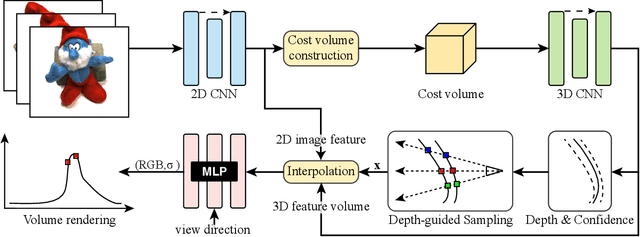
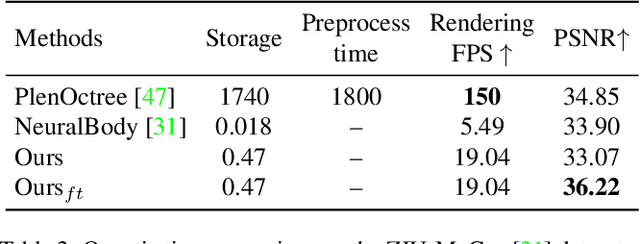
This paper aims to reduce the rendering time of generalizable radiance fields. Some recent works equip neural radiance fields with image encoders and are able to generalize across scenes, which avoids the per-scene optimization. However, their rendering process is generally very slow. A major factor is that they sample lots of points in empty space when inferring radiance fields. In this paper, we present a hybrid scene representation which combines the best of implicit radiance fields and explicit depth maps for efficient rendering. Specifically, we first build the cascade cost volume to efficiently predict the coarse geometry of the scene. The coarse geometry allows us to sample few points near the scene surface and significantly improves the rendering speed. This process is fully differentiable, enabling us to jointly learn the depth prediction and radiance field networks from only RGB images. Experiments show that the proposed approach exhibits state-of-the-art performance on the DTU, Real Forward-facing and NeRF Synthetic datasets, while being at least 50 times faster than previous generalizable radiance field methods. We also demonstrate the capability of our method to synthesize free-viewpoint videos of dynamic human performers in real-time. The code will be available at https://zju3dv.github.io/enerf/.
Constrained Deep One-Class Feature Learning For Classifying Imbalanced Medical Images
Nov 20, 2021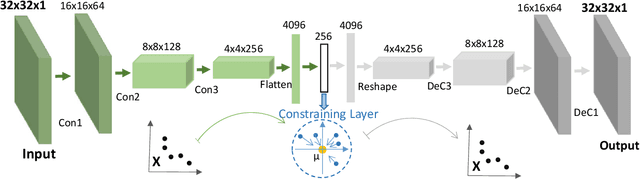

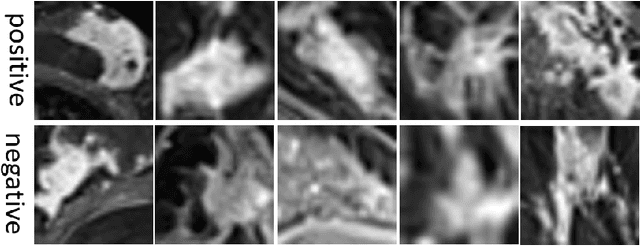
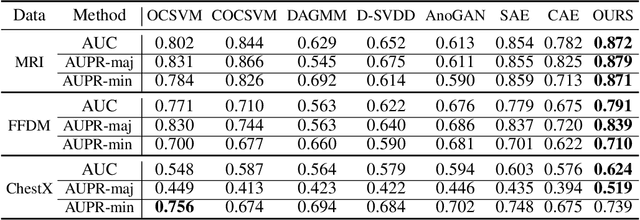
Medical image data are usually imbalanced across different classes. One-class classification has attracted increasing attention to address the data imbalance problem by distinguishing the samples of the minority class from the majority class. Previous methods generally aim to either learn a new feature space to map training samples together or to fit training samples by autoencoder-like models. These methods mainly focus on capturing either compact or descriptive features, where the information of the samples of a given one class is not sufficiently utilized. In this paper, we propose a novel deep learning-based method to learn compact features by adding constraints on the bottleneck features, and to preserve descriptive features by training an autoencoder at the same time. Through jointly optimizing the constraining loss and the autoencoder's reconstruction loss, our method can learn more relevant features associated with the given class, making the majority and minority samples more distinguishable. Experimental results on three clinical datasets (including the MRI breast images, FFDM breast images and chest X-ray images) obtains state-of-art performance compared to previous methods.
3D Human Shape Style Transfer
Sep 03, 2021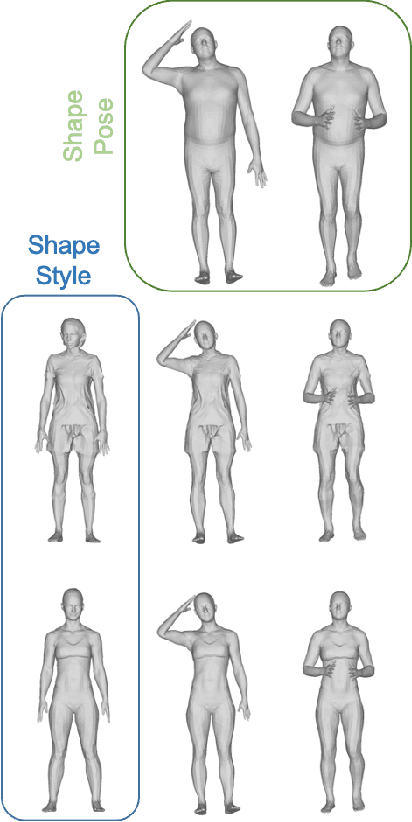
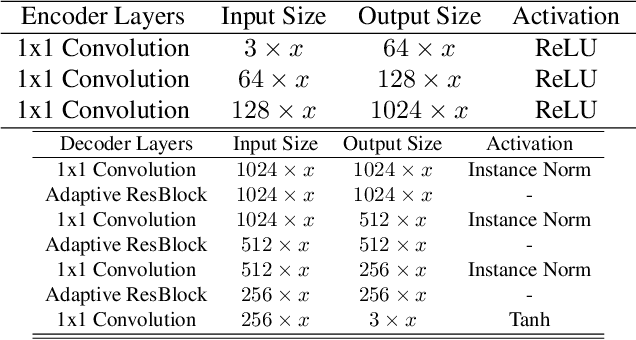
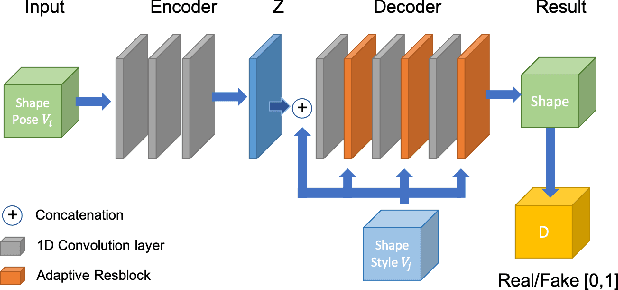

We consider the problem of modifying/replacing the shape style of a real moving character with those of an arbitrary static real source character. Traditional solutions follow a pose transfer strategy, from the moving character to the source character shape, that relies on skeletal pose parametrization. In this paper, we explore an alternative approach that transfers the source shape style onto the moving character. The expected benefit is to avoid the inherently difficult pose to shape conversion required with skeletal parametrization applied on real characters. To this purpose, we consider image style transfer techniques and investigate how to adapt them to 3D human shapes. Adaptive Instance Normalisation (AdaIN) and SPADE architectures have been demonstrated to efficiently and accurately transfer the style of an image onto another while preserving the original image structure. Where AdaIN contributes with a module to perform style transfer through the statistics of the subjects and SPADE contribute with a residual block architecture to refine the quality of the style transfer. We demonstrate that these approaches are extendable to the 3D shape domain by proposing a convolutional neural network that applies the same principle of preserving the shape structure (shape pose) while transferring the style of a new subject shape. The generated results are supervised through a discriminator module to evaluate the realism of the shape, whilst enforcing the decoder to synthesise plausible shapes and improve the style transfer for unseen subjects. Our experiments demonstrate an average of $\approx 56\%$ qualitative and quantitative improvements over the baseline in shape transfer through optimization-based and learning-based methods.