 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Improving Explainability of Image Classification in Scenarios with Class Overlap: Application to COVID-19 and Pneumonia
Aug 06, 2020

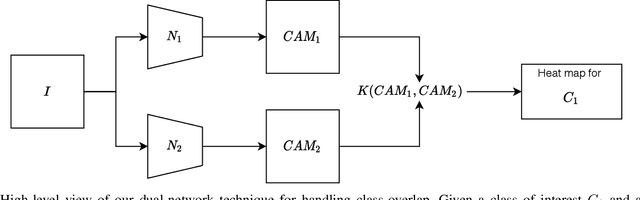
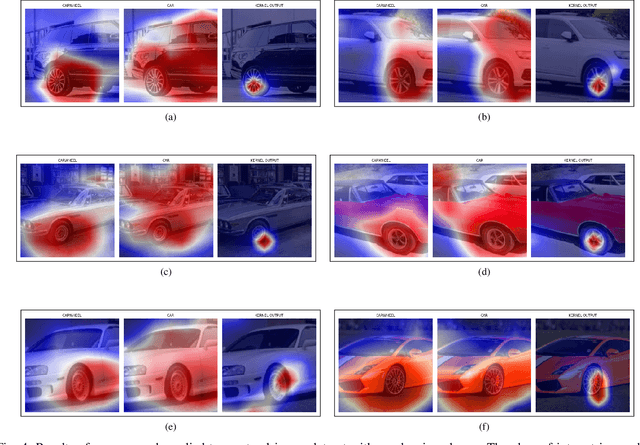
Trust in predictions made by machine learning models is increased if the model generalizes well on previously unseen samples and when inference is accompanied by cogent explanations of the reasoning behind predictions. In the image classification domain, generalization can also be assessed through accuracy, sensitivity, and specificity, and one measure to assess explainability is how well the model localizes the object of interest within an image. However, in multi-class settings, both generalization and explanation through localization are degraded when available training data contains features with significant overlap between classes. We propose a method to enhance explainability of image classification through better localization by mitigating the model uncertainty induced by class overlap. Our technique performs discriminative localization on images that contain features with significant class overlap, without explicitly training for localization. Our method is particularly promising in real-world class overlap scenarios, such as COVID19 vs pneumonia, where expertly labeled data for localization is not available. This can be useful for early, rapid, and trustworthy screening for COVID-19.
Visual Explanations for Convolutional Neural Networks via Latent Traversal of Generative Adversarial Networks
Nov 02, 2021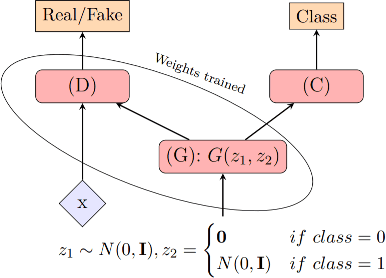
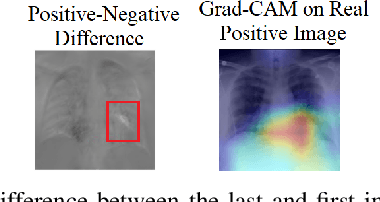
Lack of explainability in artificial intelligence, specifically deep neural networks, remains a bottleneck for implementing models in practice. Popular techniques such as Gradient-weighted Class Activation Mapping (Grad-CAM) provide a coarse map of salient features in an image, which rarely tells the whole story of what a convolutional neural network (CNN) learned. Using COVID-19 chest X-rays, we present a method for interpreting what a CNN has learned by utilizing Generative Adversarial Networks (GANs). Our GAN framework disentangles lung structure from COVID-19 features. Using this GAN, we can visualize the transition of a pair of COVID negative lungs in a chest radiograph to a COVID positive pair by interpolating in the latent space of the GAN, which provides fine-grained visualization of how the CNN responds to varying features within the lungs.
DeepRelativeFusion: Dense Monocular SLAM using Single-Image Relative Depth Prediction
Jun 07, 2020
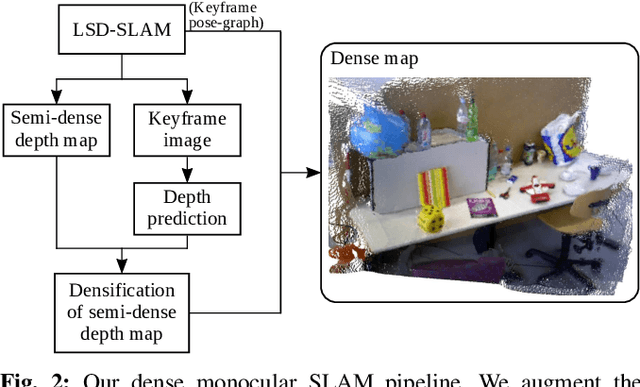
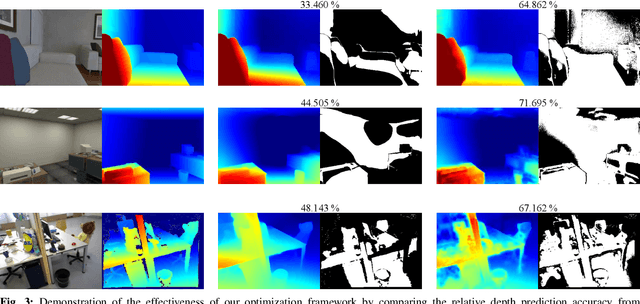
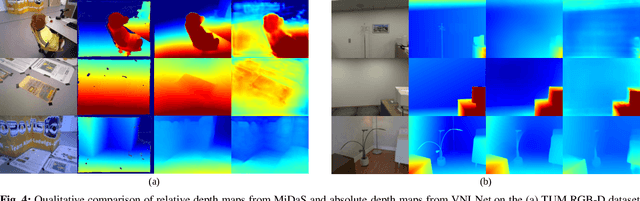
Traditional monocular visual simultaneous localization and mapping (SLAM) algorithms have been extensively studied and proven to reliably recover a sparse structure and camera motion. Nevertheless, the sparse structure is still insufficient for scene interaction, e.g., visual navigation and augmented reality applications. To densify the scene reconstruction, the use of single-image absolute depth prediction from convolutional neural networks (CNNs) for filling in the missing structure has been proposed. However, the prediction accuracy tends to not generalize well on scenes that are different from the training datasets. In this paper, we propose a dense monocular SLAM system, named DeepRelativeFusion, that is capable to recover a globally consistent 3D structure. To this end, we use a visual SLAM algorithm to reliably recover the camera poses and semi-dense depth maps of the keyframes, and then combine the keyframe pose-graph with the densified keyframe depth maps to reconstruct the scene. To perform the densification, we introduce two incremental improvements upon the energy minimization framework proposed by DeepFusion: (1) an additional image gradient term in the cost function, and (2) the use of single-image relative depth prediction. Despite the absence of absolute scale and depth range, the relative depth maps can be corrected using their respective semi-dense depth maps from the SLAM algorithm. We show that the corrected relative depth maps are sufficiently accurate to be used as priors for the densification. To demonstrate the generalizability of relative depth prediction, we illustrate qualitatively the dense reconstruction on two outdoor sequences. Our system also outperforms the state-of-the-art dense SLAM systems quantitatively in dense reconstruction accuracy by a large margin.
Understanding Square Loss in Training Overparametrized Neural Network Classifiers
Dec 07, 2021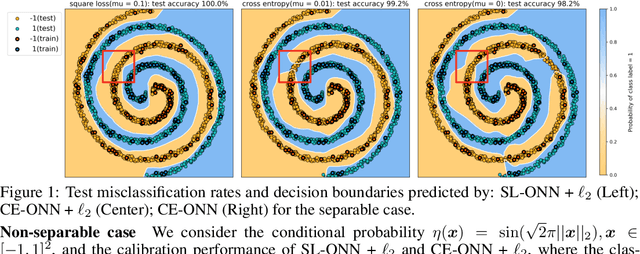
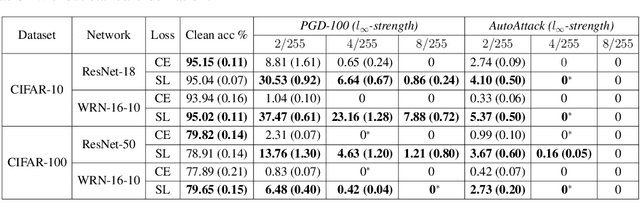
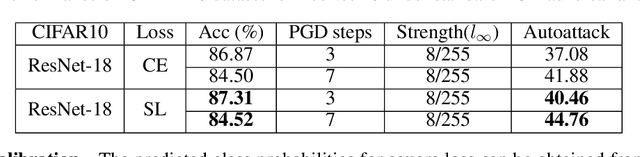
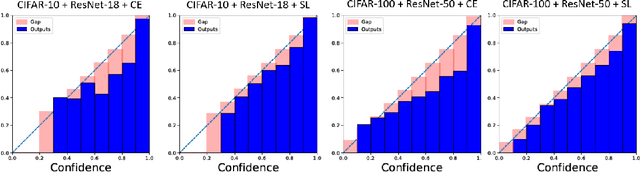
Deep learning has achieved many breakthroughs in modern classification tasks. Numerous architectures have been proposed for different data structures but when it comes to the loss function, the cross-entropy loss is the predominant choice. Recently, several alternative losses have seen revived interests for deep classifiers. In particular, empirical evidence seems to promote square loss but a theoretical justification is still lacking. In this work, we contribute to the theoretical understanding of square loss in classification by systematically investigating how it performs for overparametrized neural networks in the neural tangent kernel (NTK) regime. Interesting properties regarding the generalization error, robustness, and calibration error are revealed. We consider two cases, according to whether classes are separable or not. In the general non-separable case, fast convergence rate is established for both misclassification rate and calibration error. When classes are separable, the misclassification rate improves to be exponentially fast. Further, the resulting margin is proven to be lower bounded away from zero, providing theoretical guarantees for robustness. We expect our findings to hold beyond the NTK regime and translate to practical settings. To this end, we conduct extensive empirical studies on practical neural networks, demonstrating the effectiveness of square loss in both synthetic low-dimensional data and real image data. Comparing to cross-entropy, square loss has comparable generalization error but noticeable advantages in robustness and model calibration.
Multi-Content Complementation Network for Salient Object Detection in Optical Remote Sensing Images
Dec 02, 2021
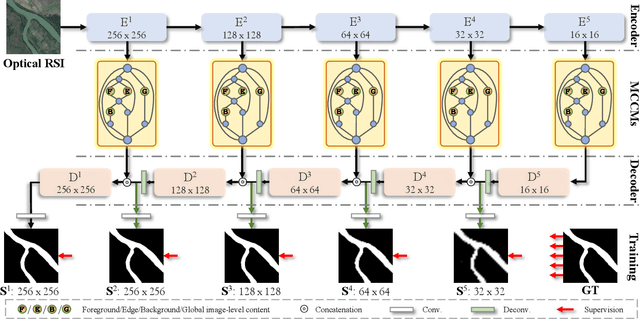
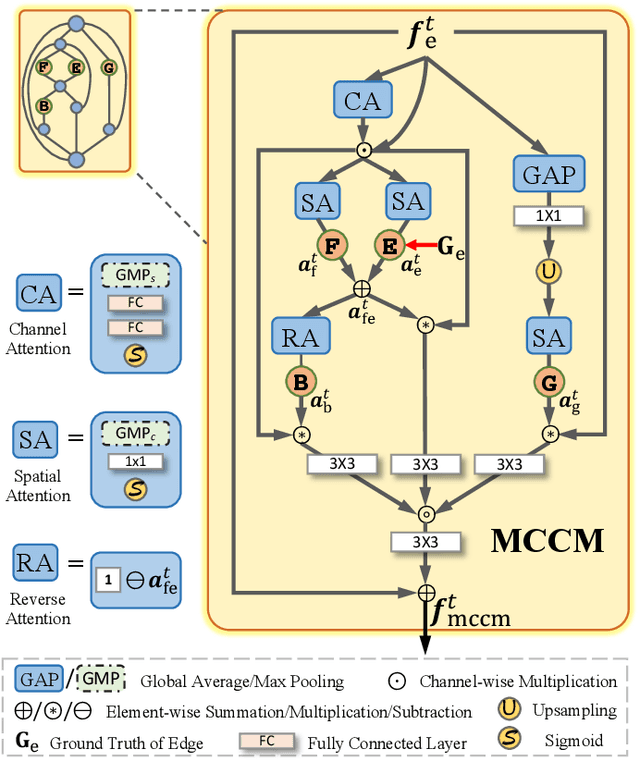
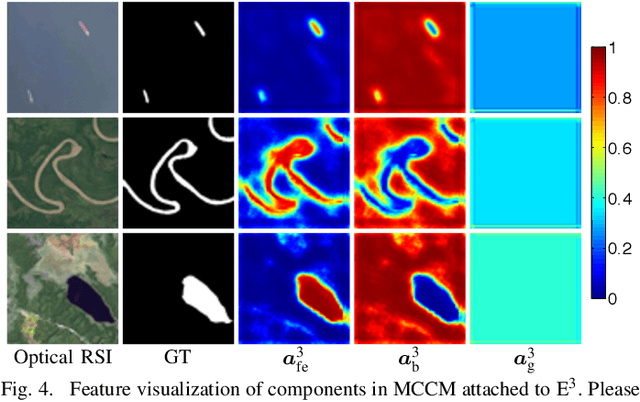
In the computer vision community, great progresses have been achieved in salient object detection from natural scene images (NSI-SOD); by contrast, salient object detection in optical remote sensing images (RSI-SOD) remains to be a challenging emerging topic. The unique characteristics of optical RSIs, such as scales, illuminations and imaging orientations, bring significant differences between NSI-SOD and RSI-SOD. In this paper, we propose a novel Multi-Content Complementation Network (MCCNet) to explore the complementarity of multiple content for RSI-SOD. Specifically, MCCNet is based on the general encoder-decoder architecture, and contains a novel key component named Multi-Content Complementation Module (MCCM), which bridges the encoder and the decoder. In MCCM, we consider multiple types of features that are critical to RSI-SOD, including foreground features, edge features, background features, and global image-level features, and exploit the content complementarity between them to highlight salient regions over various scales in RSI features through the attention mechanism. Besides, we comprehensively introduce pixel-level, map-level and metric-aware losses in the training phase. Extensive experiments on two popular datasets demonstrate that the proposed MCCNet outperforms 23 state-of-the-art methods, including both NSI-SOD and RSI-SOD methods. The code and results of our method are available at https://github.com/MathLee/MCCNet.
Deep Adaptive Inference Networks for Single Image Super-Resolution
Apr 08, 2020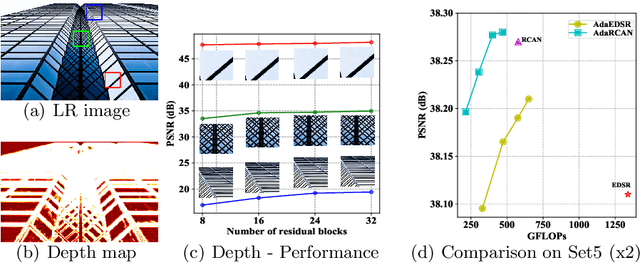
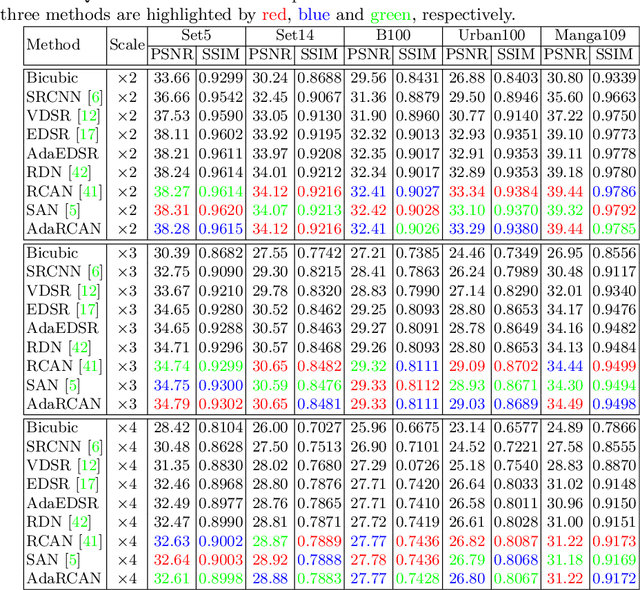
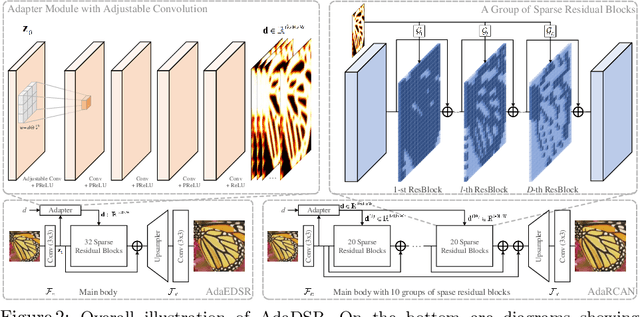
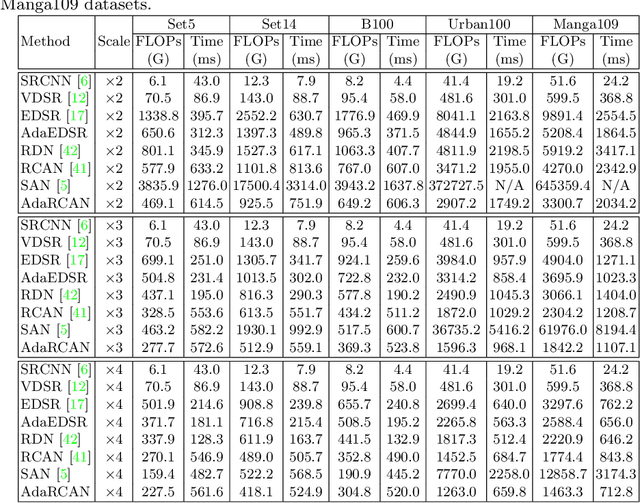
Recent years have witnessed tremendous progress in single image super-resolution (SISR) owing to the deployment of deep convolutional neural networks (CNNs). For most existing methods, the computational cost of each SISR model is irrelevant to local image content, hardware platform and application scenario. Nonetheless, content and resource adaptive model is more preferred, and it is encouraging to apply simpler and efficient networks to the easier regions with less details and the scenarios with restricted efficiency constraints. In this paper, we take a step forward to address this issue by leveraging the adaptive inference networks for deep SISR (AdaDSR). In particular, our AdaDSR involves an SISR model as backbone and a lightweight adapter module which takes image features and resource constraint as input and predicts a map of local network depth. Adaptive inference can then be performed with the support of efficient sparse convolution, where only a fraction of the layers in the backbone is performed at a given position according to its predicted depth. The network learning can be formulated as the joint optimization of reconstruction and network depth losses. In the inference stage, the average depth can be flexibly tuned to meet a range of efficiency constraints. Experiments demonstrate the effectiveness and adaptability of our AdaDSR in contrast to its counterparts (e.g., EDSR and RCAN).
360-DFPE: Leveraging Monocular 360-Layouts for Direct Floor Plan Estimation
Dec 12, 2021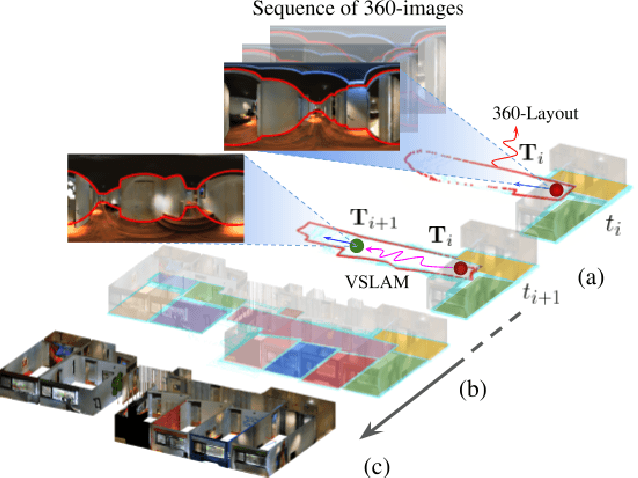
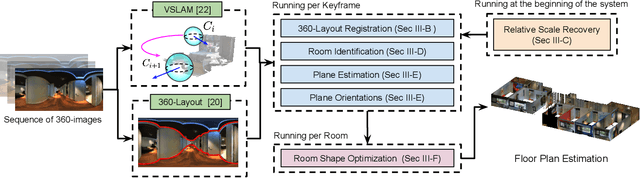
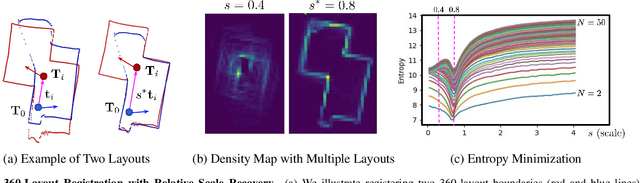
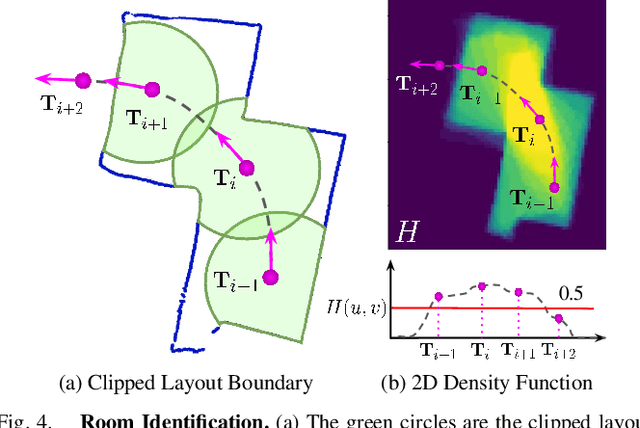
We present 360-DFPE, a sequential floor plan estimation method that directly takes 360-images as input without relying on active sensors or 3D information. Our approach leverages a loosely coupled integration between a monocular visual SLAM solution and a monocular 360-room layout approach, which estimate camera poses and layout geometries, respectively. Since our task is to sequentially capture the floor plan using monocular images, the entire scene structure, room instances, and room shapes are unknown. To tackle these challenges, we first handle the scale difference between visual odometry and layout geometry via formulating an entropy minimization process, which enables us to directly align 360-layouts without knowing the entire scene in advance. Second, to sequentially identify individual rooms, we propose a novel room identification algorithm that tracks every room along the camera exploration using geometry information. Lastly, to estimate the final shape of the room, we propose a shortest path algorithm with an iterative coarse-to-fine strategy, which improves prior formulations with higher accuracy and faster run-time. Moreover, we collect a new floor plan dataset with challenging large-scale scenes, providing both point clouds and sequential 360-image information. Experimental results show that our monocular solution achieves favorable performance against the current state-of-the-art algorithms that rely on active sensors and require the entire scene reconstruction data in advance. Our code and dataset will be released soon.
Reinforcement Explanation Learning
Nov 26, 2021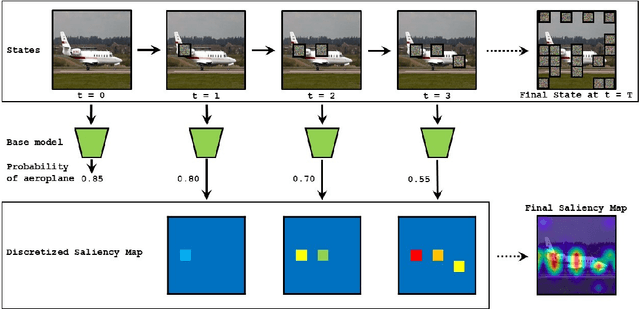
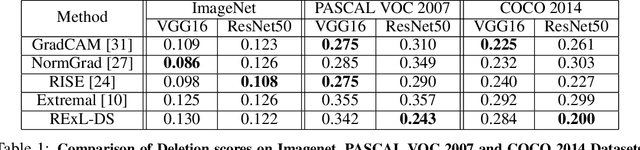
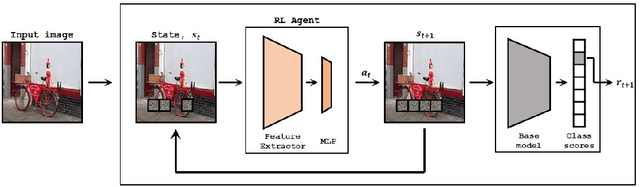
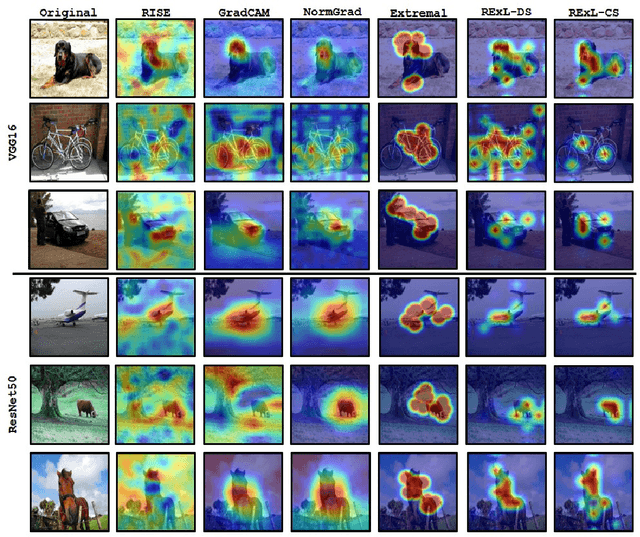
Deep Learning has become overly complicated and has enjoyed stellar success in solving several classical problems like image classification, object detection, etc. Several methods for explaining these decisions have been proposed. Black-box methods to generate saliency maps are particularly interesting due to the fact that they do not utilize the internals of the model to explain the decision. Most black-box methods perturb the input and observe the changes in the output. We formulate saliency map generation as a sequential search problem and leverage upon Reinforcement Learning (RL) to accumulate evidence from input images that most strongly support decisions made by a classifier. Such a strategy encourages to search intelligently for the perturbations that will lead to high-quality explanations. While successful black box explanation approaches need to rely on heavy computations and suffer from small sample approximation, the deterministic policy learned by our method makes it a lot more efficient during the inference. Experiments on three benchmark datasets demonstrate the superiority of the proposed approach in inference time over state-of-the-arts without hurting the performance. Project Page: https://cvir.github.io/projects/rexl.html
Self-Supervision with Superpixels: Training Few-shot Medical Image Segmentation without Annotation
Jul 20, 2020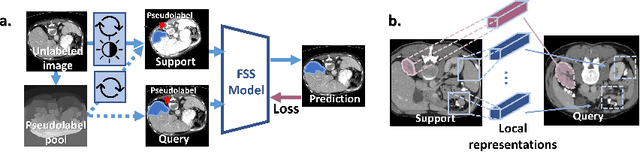
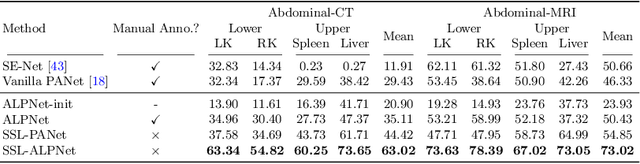
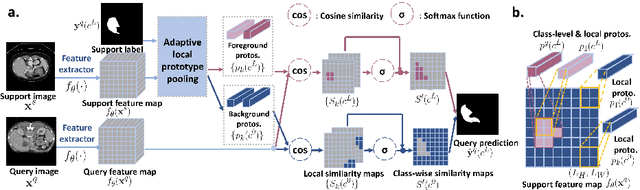
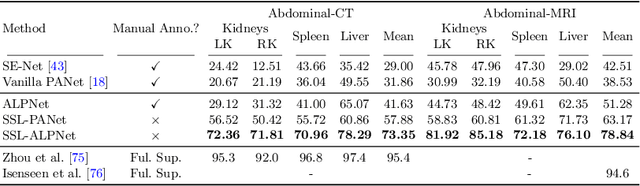
Few-shot semantic segmentation (FSS) has great potential for medical imaging applications. Most of the existing FSS techniques require abundant annotated semantic classes for training. However, these methods may not be applicable for medical images due to the lack of annotations. To address this problem we make several contributions: (1) A novel self-supervised FSS framework for medical images in order to eliminate the requirement for annotations during training. Additionally, superpixel-based pseudo-labels are generated to provide supervision; (2) An adaptive local prototype pooling module plugged into prototypical networks, to solve the common challenging foreground-background imbalance problem in medical image segmentation; (3) We demonstrate the general applicability of the proposed approach for medical images using three different tasks: abdominal organ segmentation for CT and MRI, as well as cardiac segmentation for MRI. Our results show that, for medical image segmentation, the proposed method outperforms conventional FSS methods which require manual annotations for training.
Lightweight Single-Image Super-Resolution Network with Attentive Auxiliary Feature Learning
Nov 13, 2020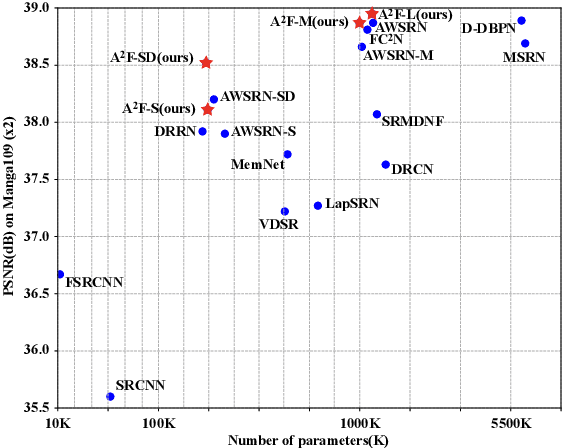
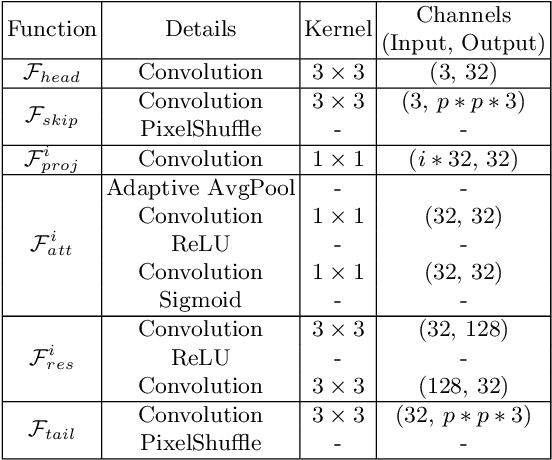
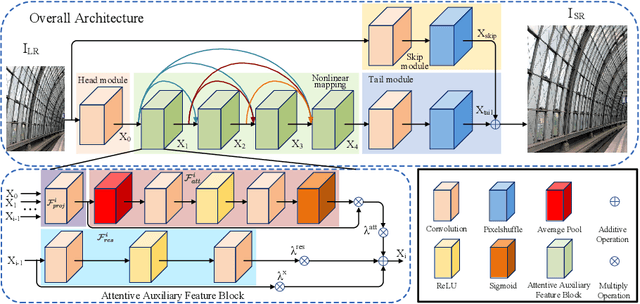
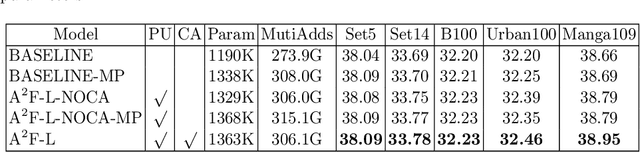
Despite convolutional network-based methods have boosted the performance of single image super-resolution (SISR), the huge computation costs restrict their practical applicability. In this paper, we develop a computation efficient yet accurate network based on the proposed attentive auxiliary features (A$^2$F) for SISR. Firstly, to explore the features from the bottom layers, the auxiliary feature from all the previous layers are projected into a common space. Then, to better utilize these projected auxiliary features and filter the redundant information, the channel attention is employed to select the most important common feature based on current layer feature. We incorporate these two modules into a block and implement it with a lightweight network. Experimental results on large-scale dataset demonstrate the effectiveness of the proposed model against the state-of-the-art (SOTA) SR methods. Notably, when parameters are less than 320k, A$^2$F outperforms SOTA methods for all scales, which proves its ability to better utilize the auxiliary features. Codes are available at https://github.com/wxxxxxxh/A2F-SR.