 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Boundary Aware Networks for Medical Image Segmentation
Aug 21, 2019
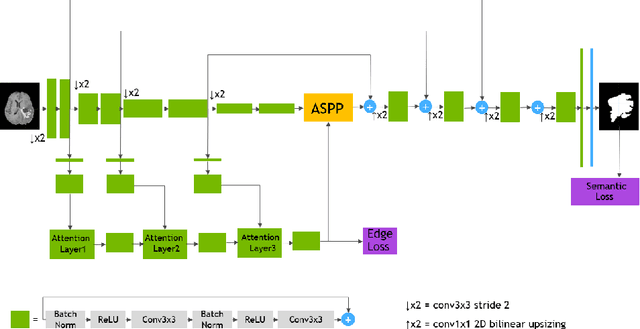
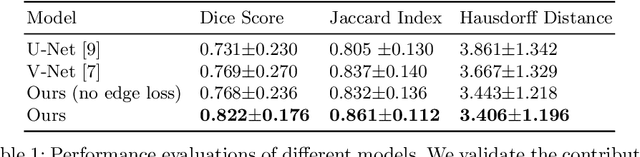
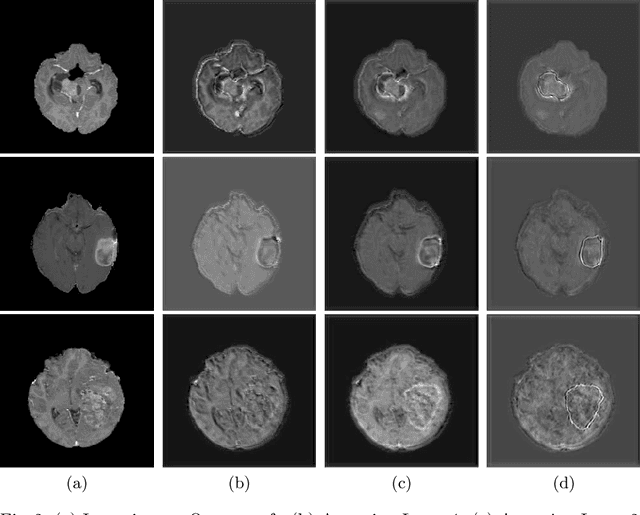
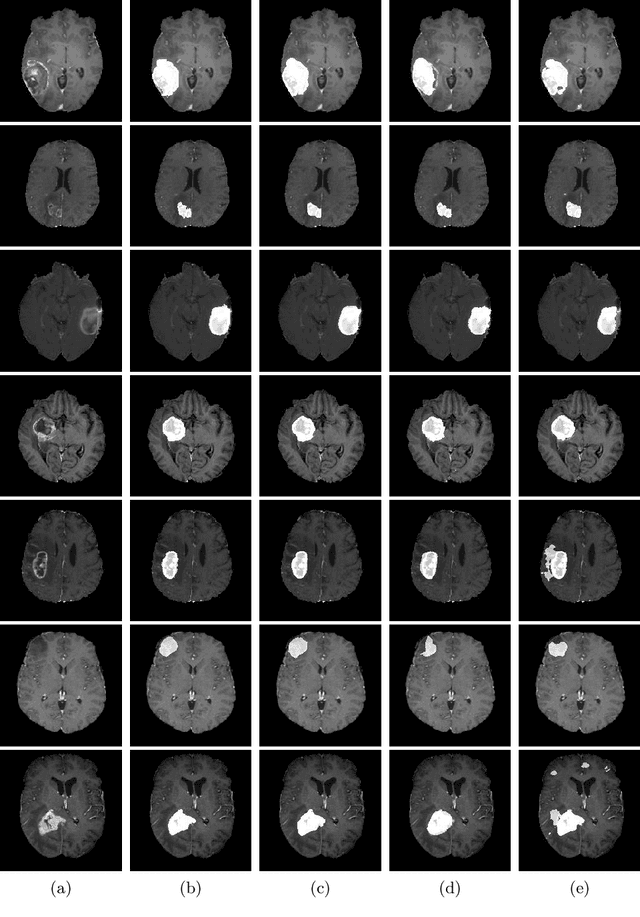
Fully convolutional neural networks (CNNs) have proven to be effective at representing and classifying textural information, thus transforming image intensity into output class masks that achieve semantic image segmentation. In medical image analysis, however, expert manual segmentation often relies on the boundaries of anatomical structures of interest. We propose boundary aware CNNs for medical image segmentation. Our networks are designed to account for organ boundary information, both by providing a special network edge branch and edge-aware loss terms, and they are trainable end-to-end. We validate their effectiveness on the task of brain tumor segmentation using the BraTS 2018 dataset. Our experiments reveal that our approach yields more accurate segmentation results, which makes it promising for more extensive application to medical image segmentation.
* Accepted to Machine Learning in Medical Imaging (MLMI 2019)
CC-Loss: Channel Correlation Loss For Image Classification
Oct 12, 2020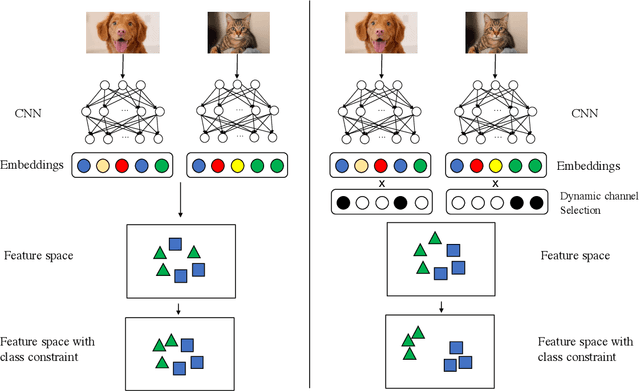

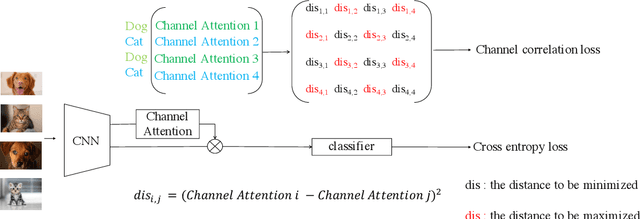
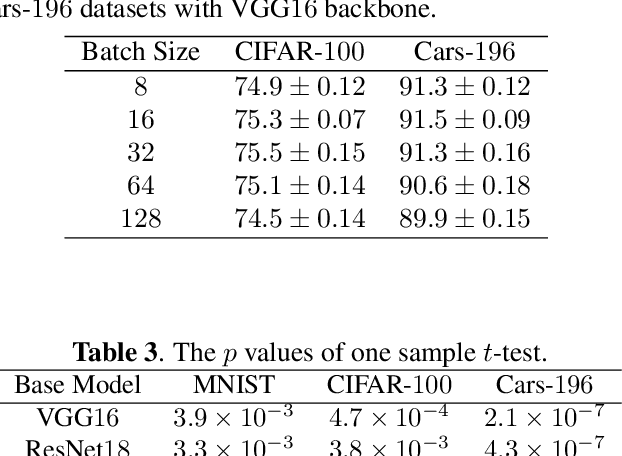
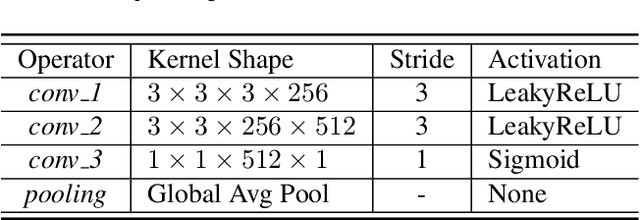
The loss function is a key component in deep learning models. A commonly used loss function for classification is the cross entropy loss, which is a simple yet effective application of information theory for classification problems. Based on this loss, many other loss functions have been proposed,~\emph{e.g.}, by adding intra-class and inter-class constraints to enhance the discriminative ability of the learned features. However, these loss functions fail to consider the connections between the feature distribution and the model structure. Aiming at addressing this problem, we propose a channel correlation loss (CC-Loss) that is able to constrain the specific relations between classes and channels as well as maintain the intra-class and the inter-class separability. CC-Loss uses a channel attention module to generate channel attention of features for each sample in the training stage. Next, an Euclidean distance matrix is calculated to make the channel attention vectors associated with the same class become identical and to increase the difference between different classes. Finally, we obtain a feature embedding with good intra-class compactness and inter-class separability.Experimental results show that two different backbone models trained with the proposed CC-Loss outperform the state-of-the-art loss functions on three image classification datasets.
P$^2$-GAN: Efficient Style Transfer Using Single Style Image
Jan 21, 2020
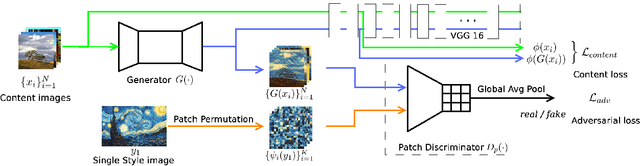
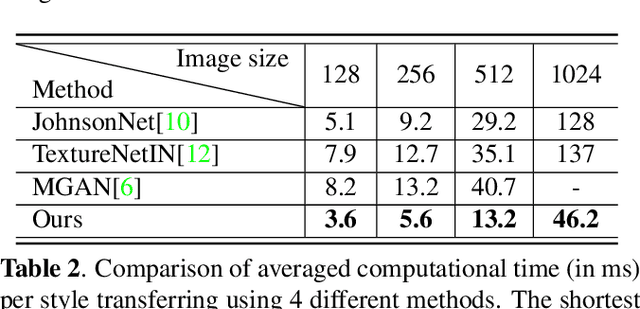
Style transfer is a useful image synthesis technique that can re-render given image into another artistic style while preserving its content information. Generative Adversarial Network (GAN) is a widely adopted framework toward this task for its better representation ability on local style patterns than the traditional Gram-matrix based methods. However, most previous methods rely on sufficient amount of pre-collected style images to train the model. In this paper, a novel Patch Permutation GAN (P$^2$-GAN) network that can efficiently learn the stroke style from a single style image is proposed. We use patch permutation to generate multiple training samples from the given style image. A patch discriminator that can simultaneously process patch-wise images and natural images seamlessly is designed. We also propose a local texture descriptor based criterion to quantitatively evaluate the style transfer quality. Experimental results showed that our method can produce finer quality re-renderings from single style image with improved computational efficiency compared with many state-of-the-arts methods.
Variational Osmosis for Non-linear Image Fusion
Oct 04, 2019



We propose a new variational model for nonlinear image fusion. Our approach incorporates the osmosis model proposed in Vogel et al. (2013) and Weickert et al. (2013) as an energy term in a variational model. The osmosis energy is known to realize visually plausible image data fusion. As a consequence, our method is invariant to multiplicative brightness changes. On the practical side, it requires minimal supervision and parameter tuning and can encode prior information on the structure of the images to be fused. We develop a primal-dual algorithm for solving this new image fusion model and we apply the resulting minimisation scheme to multi-modal image fusion for face fusion, colour transfer and some cultural heritage conservation challenges. Visual comparison to state-of-the-art proves the quality and flexibility of our method.
Human-Vehicle Cooperative Visual Perception for Shared Autonomous Driving
Dec 17, 2021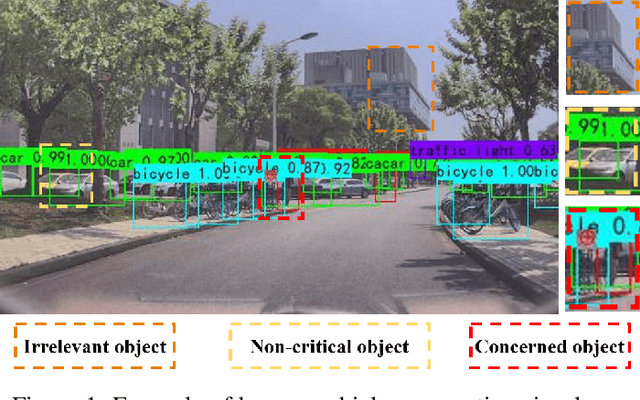
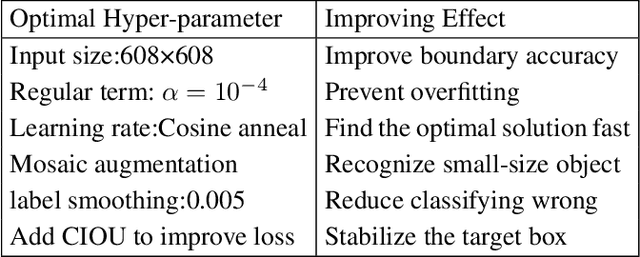
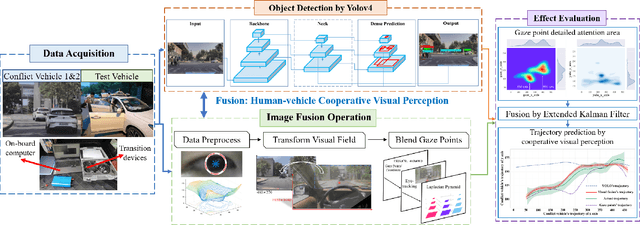

With the development of key technologies like environment perception, the automation level of autonomous vehicles has been increasing. However, before reaching highly autonomous driving, manual driving still needs to participate in the driving process to ensure the safety of human-vehicle shared driving. The existing human-vehicle cooperative driving focuses on auto engineering and drivers' behaviors, with few research studies in the field of visual perception. Due to the bad performance in the complex road traffic conflict scenarios, cooperative visual perception needs to be studied further. In addition, the autonomous driving perception system cannot correctly understand the characteristics of manual driving. Based on the background above, this paper directly proposes a human-vehicle cooperative visual perception method to enhance the visual perception ability of shared autonomous driving based on the transfer learning method and the image fusion algorithm for the complex road traffic scenarios. Based on transfer learning, the mAP of object detection reaches 75.52% and lays a solid foundation for visual fusion. And the fusion experiment further reveals that human-vehicle cooperative visual perception reflects the riskiest zone and predicts the conflict object's trajectory more precisely. This study pioneers a cooperative visual perception solution for shared autonomous driving and experiments in real-world complex traffic conflict scenarios, which can better support the following planning and controlling and improve the safety of autonomous vehicles.
Multi-center, multi-vendor automated segmentation of left ventricular anatomy in contrast-enhanced MRI
Oct 28, 2021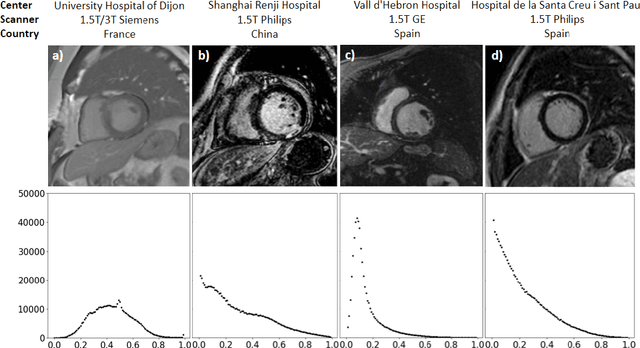
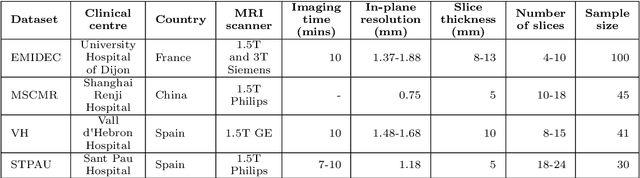
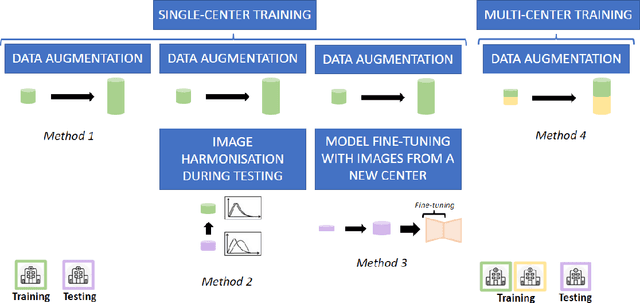
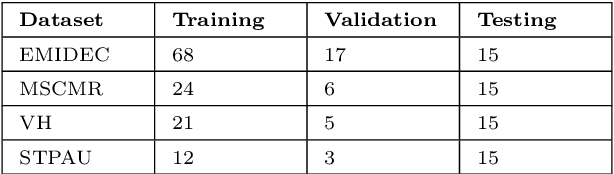
Accurate delineation of the left ventricular boundaries in late gadolinium-enhanced magnetic resonance imaging (LGE-MRI) is an essential step for scar tissue quantification and patient-specific assessment of myocardial infarction. Many deep-learning techniques have been proposed to perform automatic segmentations of the left ventricle (LV) in LGE-MRI showing segmentations as accurate as those obtained by expert cardiologists. Thus far, the existing models have been overwhelmingly developed and evaluated with LGE-MRI datasets from single clinical centers. However, in practice, LGE-MRI images vary significantly between clinical centers within and across countries, in particular due to differences in the MRI scanners, imaging conditions, contrast injection protocols and local clinical practise. This work investigates for the first time multi-center and multi-vendor LV segmentation in LGE-MRI, by proposing, implementing and evaluating in detail several strategies to enhance model generalizability across clinical cites. These include data augmentation to artificially augment the image variability in the training sample, image harmonization to align the distributions of LGE-MRI images across centers, and transfer learning to adjust existing single-center models to unseen images from new clinical sites. The results obtained based on a new multi-center LGE-MRI dataset acquired in four clinical centers in Spain, France and China, show that the combination of data augmentation and transfer learning can lead to single-center models that generalize well to new clinical centers not included in the original training. The proposed framework shows the potential for developing clinical tools for automated LV segmentation in LGE-MRI that can be deployed in multiple clinical centers across distinct geographical locations.
Audio2Head: Audio-driven One-shot Talking-head Generation with Natural Head Motion
Jul 20, 2021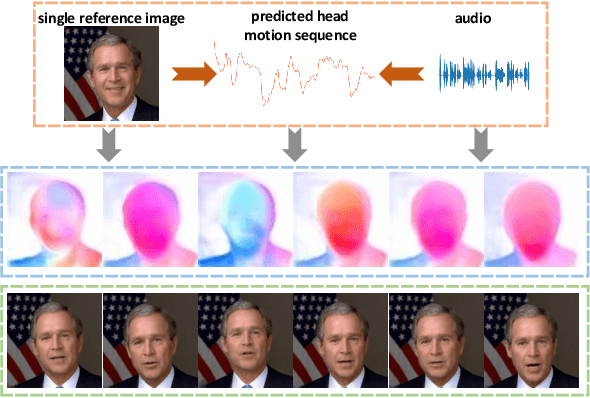
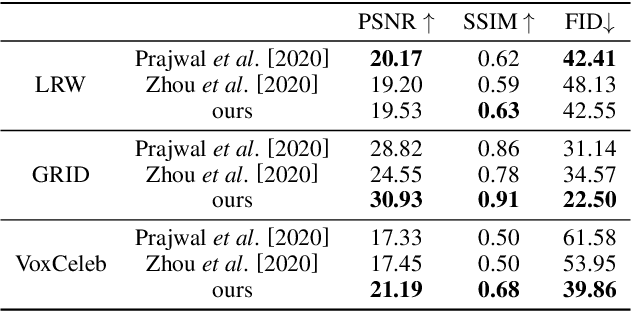
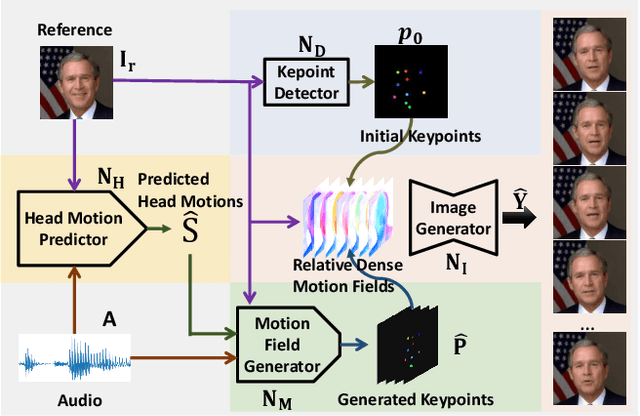

We propose an audio-driven talking-head method to generate photo-realistic talking-head videos from a single reference image. In this work, we tackle two key challenges: (i) producing natural head motions that match speech prosody, and (ii) maintaining the appearance of a speaker in a large head motion while stabilizing the non-face regions. We first design a head pose predictor by modeling rigid 6D head movements with a motion-aware recurrent neural network (RNN). In this way, the predicted head poses act as the low-frequency holistic movements of a talking head, thus allowing our latter network to focus on detailed facial movement generation. To depict the entire image motions arising from audio, we exploit a keypoint based dense motion field representation. Then, we develop a motion field generator to produce the dense motion fields from input audio, head poses, and a reference image. As this keypoint based representation models the motions of facial regions, head, and backgrounds integrally, our method can better constrain the spatial and temporal consistency of the generated videos. Finally, an image generation network is employed to render photo-realistic talking-head videos from the estimated keypoint based motion fields and the input reference image. Extensive experiments demonstrate that our method produces videos with plausible head motions, synchronized facial expressions, and stable backgrounds and outperforms the state-of-the-art.
Graph Embedding via High Dimensional Model Representation for Hyperspectral Images
Nov 29, 2021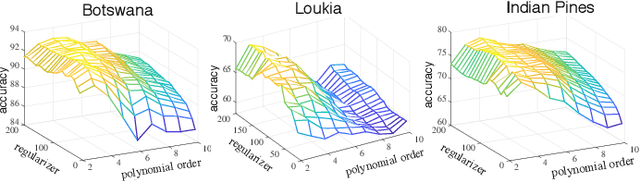
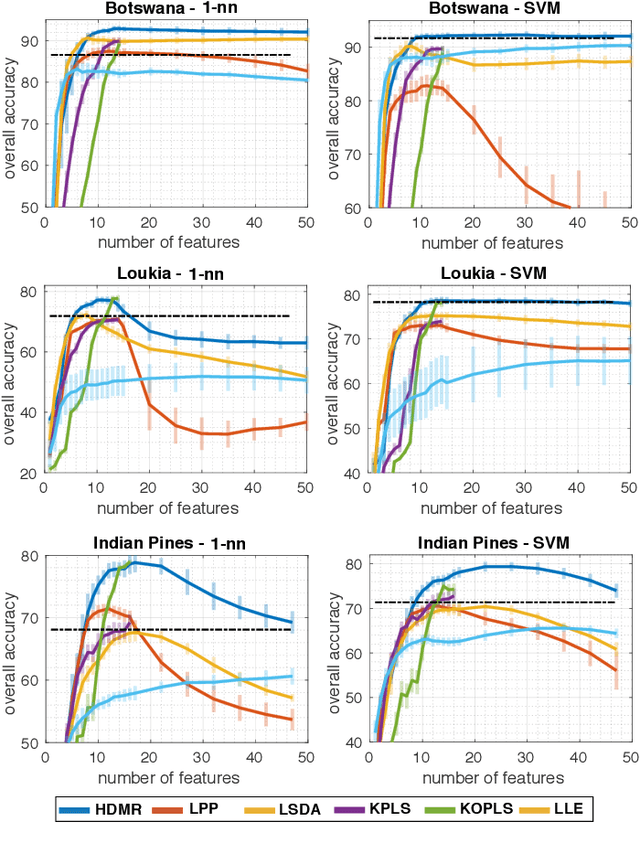
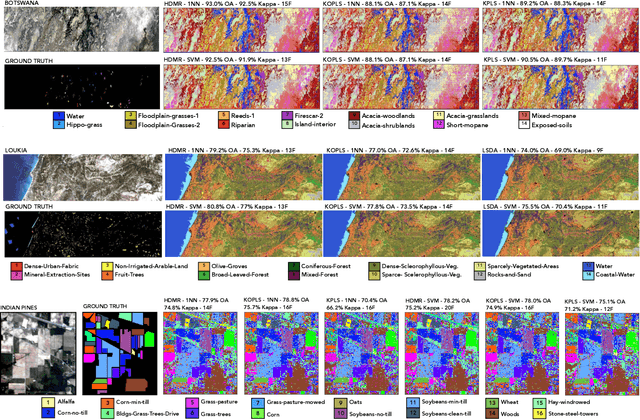
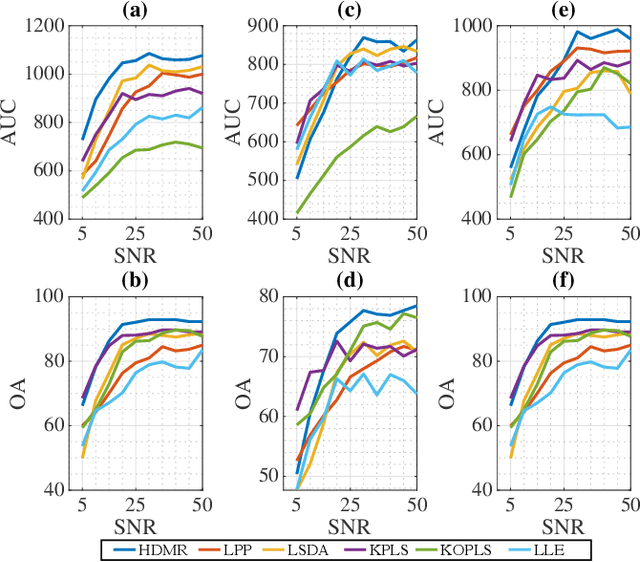
Learning the manifold structure of remote sensing images is of paramount relevance for modeling and understanding processes, as well as to encapsulate the high dimensionality in a reduced set of informative features for subsequent classification, regression, or unmixing. Manifold learning methods have shown excellent performance to deal with hyperspectral image (HSI) analysis but, unless specifically designed, they cannot provide an explicit embedding map readily applicable to out-of-sample data. A common assumption to deal with the problem is that the transformation between the high-dimensional input space and the (typically low) latent space is linear. This is a particularly strong assumption, especially when dealing with hyperspectral images due to the well-known nonlinear nature of the data. To address this problem, a manifold learning method based on High Dimensional Model Representation (HDMR) is proposed, which enables to present a nonlinear embedding function to project out-of-sample samples into the latent space. The proposed method is compared to manifold learning methods along with its linear counterparts and achieves promising performance in terms of classification accuracy of a representative set of hyperspectral images.
Urban Radiance Fields
Nov 29, 2021
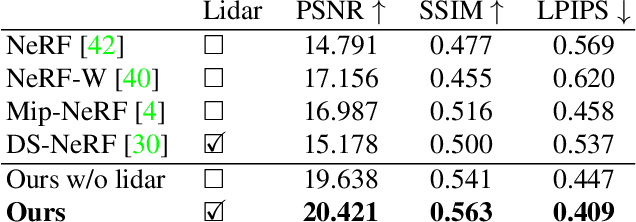


The goal of this work is to perform 3D reconstruction and novel view synthesis from data captured by scanning platforms commonly deployed for world mapping in urban outdoor environments (e.g., Street View). Given a sequence of posed RGB images and lidar sweeps acquired by cameras and scanners moving through an outdoor scene, we produce a model from which 3D surfaces can be extracted and novel RGB images can be synthesized. Our approach extends Neural Radiance Fields, which has been demonstrated to synthesize realistic novel images for small scenes in controlled settings, with new methods for leveraging asynchronously captured lidar data, for addressing exposure variation between captured images, and for leveraging predicted image segmentations to supervise densities on rays pointing at the sky. Each of these three extensions provides significant performance improvements in experiments on Street View data. Our system produces state-of-the-art 3D surface reconstructions and synthesizes higher quality novel views in comparison to both traditional methods (e.g.~COLMAP) and recent neural representations (e.g.~Mip-NeRF).
Curvature-guided dynamic scale networks for Multi-view Stereo
Dec 11, 2021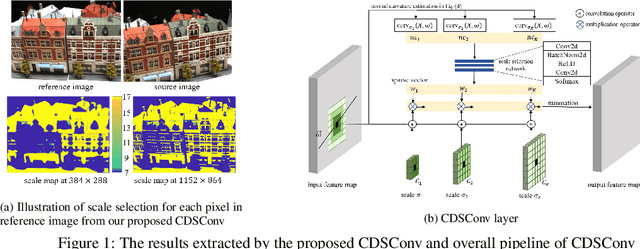
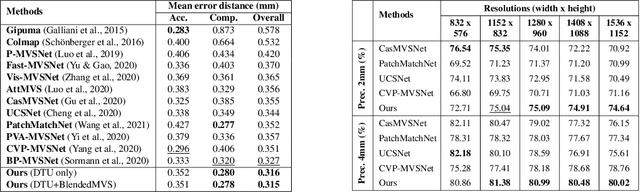
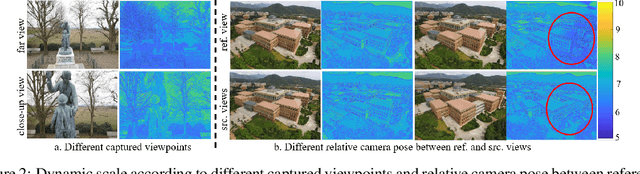
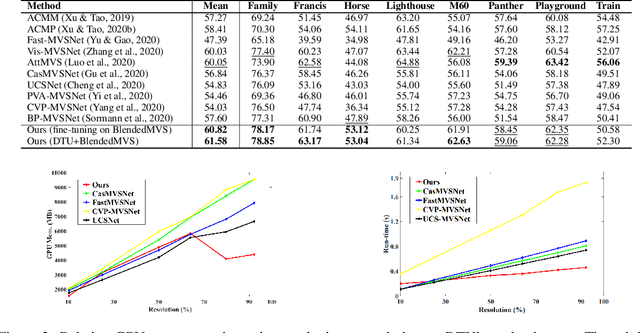
Multi-view stereo (MVS) is a crucial task for precise 3D reconstruction. Most recent studies tried to improve the performance of matching cost volume in MVS by designing aggregated 3D cost volumes and their regularization. This paper focuses on learning a robust feature extraction network to enhance the performance of matching costs without heavy computation in the other steps. In particular, we present a dynamic scale feature extraction network, namely, CDSFNet. It is composed of multiple novel convolution layers, each of which can select a proper patch scale for each pixel guided by the normal curvature of the image surface. As a result, CDFSNet can estimate the optimal patch scales to learn discriminative features for accurate matching computation between reference and source images. By combining the robust extracted features with an appropriate cost formulation strategy, our resulting MVS architecture can estimate depth maps more precisely. Extensive experiments showed that the proposed method outperforms other state-of-the-art methods on complex outdoor scenes. It significantly improves the completeness of reconstructed models. As a result, the method can process higher resolution inputs within faster run-time and lower memory than other MVS methods. Our source code is available at url{https://github.com/TruongKhang/cds-mvsnet}.