 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Donut: Document Understanding Transformer without OCR
Nov 30, 2021
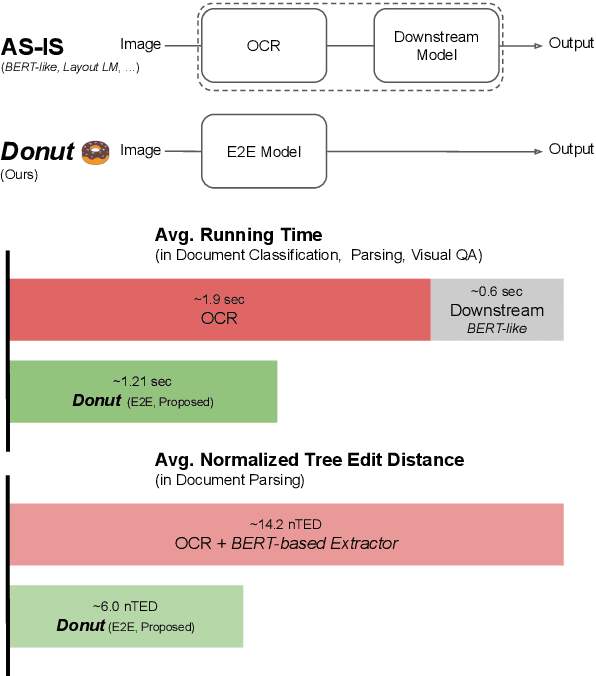
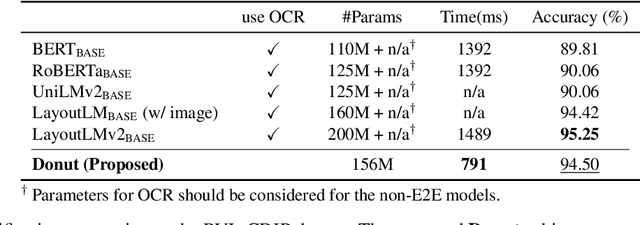
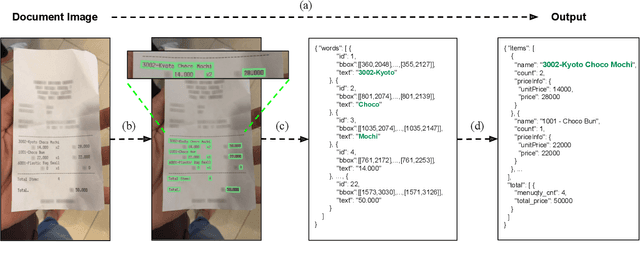

Understanding document images (e.g., invoices) has been an important research topic and has many applications in document processing automation. Through the latest advances in deep learning-based Optical Character Recognition (OCR), current Visual Document Understanding (VDU) systems have come to be designed based on OCR. Although such OCR-based approach promise reasonable performance, they suffer from critical problems induced by the OCR, e.g., (1) expensive computational costs and (2) performance degradation due to the OCR error propagation. In this paper, we propose a novel VDU model that is end-to-end trainable without underpinning OCR framework. To this end, we propose a new task and a synthetic document image generator to pre-train the model to mitigate the dependencies on large-scale real document images. Our approach achieves state-of-the-art performance on various document understanding tasks in public benchmark datasets and private industrial service datasets. Through extensive experiments and analysis, we demonstrate the effectiveness of the proposed model especially with consideration for a real-world application.
Single Image Optical Flow Estimation with an Event Camera
Apr 01, 2020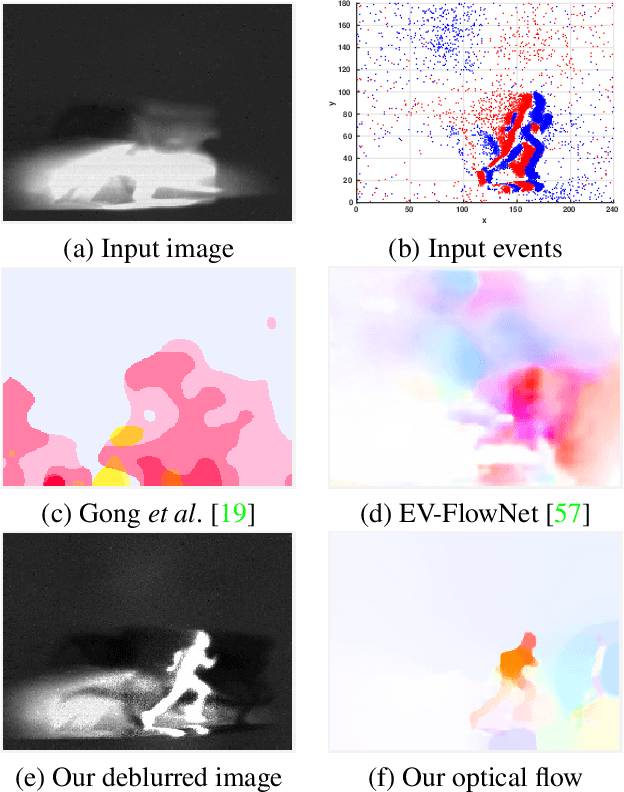

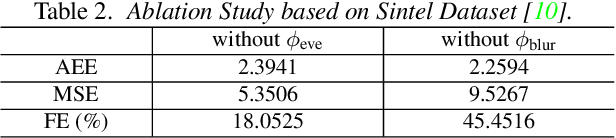
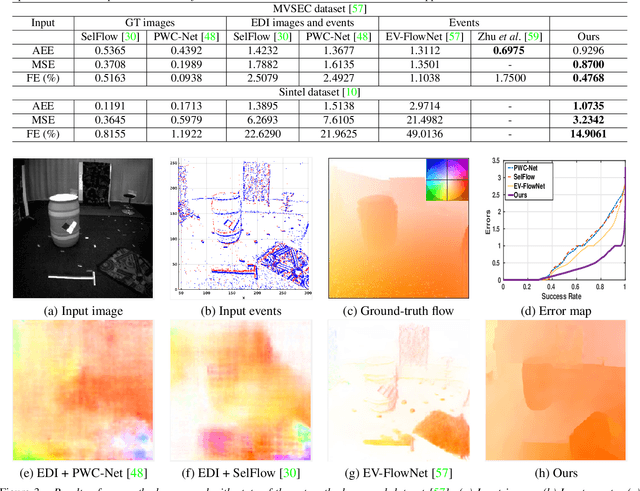
Event cameras are bio-inspired sensors that asynchronously report intensity changes in microsecond resolution. DAVIS can capture high dynamics of a scene and simultaneously output high temporal resolution events and low frame-rate intensity images. In this paper, we propose a single image (potentially blurred) and events based optical flow estimation approach. First, we demonstrate how events can be used to improve flow estimates. To this end, we encode the relation between flow and events effectively by presenting an event-based photometric consistency formulation. Then, we consider the special case of image blur caused by high dynamics in the visual environments and show that including the blur formation in our model further constrains flow estimation. This is in sharp contrast to existing works that ignore the blurred images while our formulation can naturally handle either blurred or sharp images to achieve accurate flow estimation. Finally, we reduce flow estimation, as well as image deblurring, to an alternative optimization problem of an objective function using the primal-dual algorithm. Experimental results on both synthetic and real data (with blurred and non-blurred images) show the superiority of our model in comparison to state-of-the-art approaches.
DeepFLASH: An Efficient Network for Learning-based Medical Image Registration
Apr 05, 2020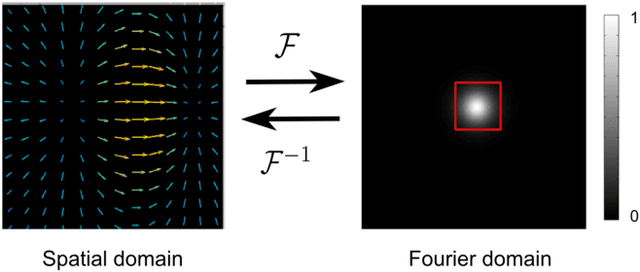
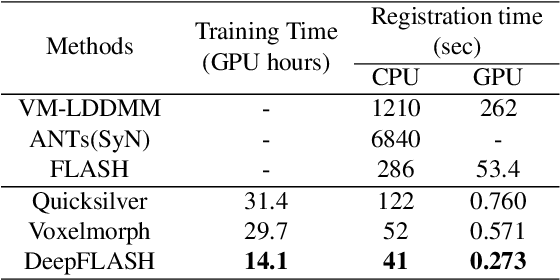
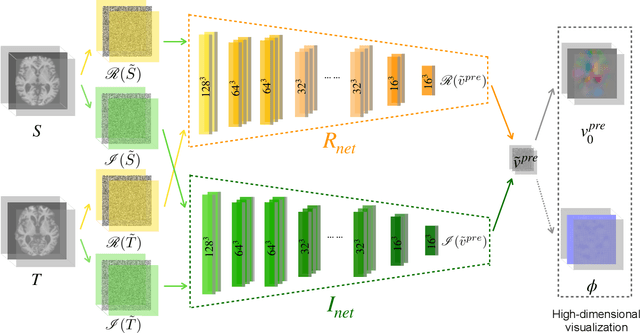

This paper presents DeepFLASH, a novel network with efficient training and inference for learning-based medical image registration. In contrast to existing approaches that learn spatial transformations from training data in the high dimensional imaging space, we develop a new registration network entirely in a low dimensional bandlimited space. This dramatically reduces the computational cost and memory footprint of an expensive training and inference. To achieve this goal, we first introduce complex-valued operations and representations of neural architectures that provide key components for learning-based registration models. We then construct an explicit loss function of transformation fields fully characterized in a bandlimited space with much fewer parameterizations. Experimental results show that our method is significantly faster than the state-of-the-art deep learning based image registration methods, while producing equally accurate alignment. We demonstrate our algorithm in two different applications of image registration: 2D synthetic data and 3D real brain magnetic resonance (MR) images. Our code is available at https://github.com/jw4hv/deepflash.
Rain Removal and Illumination Enhancement Done in One Go
Aug 09, 2021

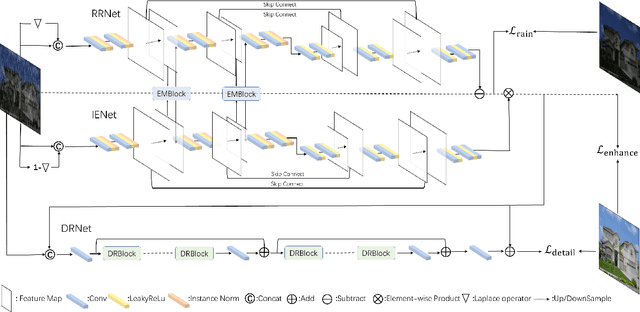
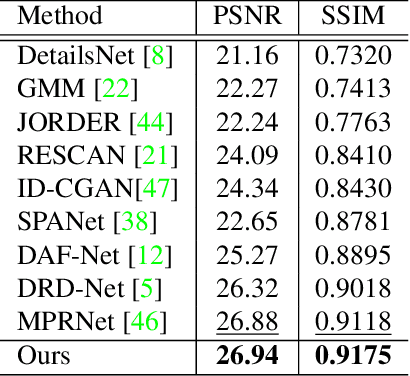
Rain removal plays an important role in the restoration of degraded images. Recently, data-driven methods have achieved remarkable success. However, these approaches neglect that the appearance of rain is often accompanied by low light conditions, which will further degrade the image quality. Therefore, it is very indispensable to jointly remove the rain and enhance the light for real-world rain image restoration. In this paper, we aim to address this problem from two aspects. First, we proposed a novel entangled network, namely EMNet, which can remove the rain and enhance illumination in one go. Specifically, two encoder-decoder networks interact complementary information through entanglement structure, and parallel rain removal and illumination enhancement. Considering that the encoder-decoder structure is unreliable in preserving spatial details, we employ a detail recovery network to restore the desired fine texture. Second, we present a new synthetic dataset, namely DarkRain, to boost the development of rain image restoration algorithms in practical scenarios. DarkRain not only contains different degrees of rain, but also considers different lighting conditions, and more realistically simulates the rainfall in the real world. EMNet is extensively evaluated on the proposed benchmark and achieves state-of-the-art results. In addition, after a simple transformation, our method outshines existing methods in both rain removal and low-light image enhancement. The source code and dataset will be made publicly available later.
FOCUS: Familiar Objects in Common and Uncommon Settings
Oct 07, 2021
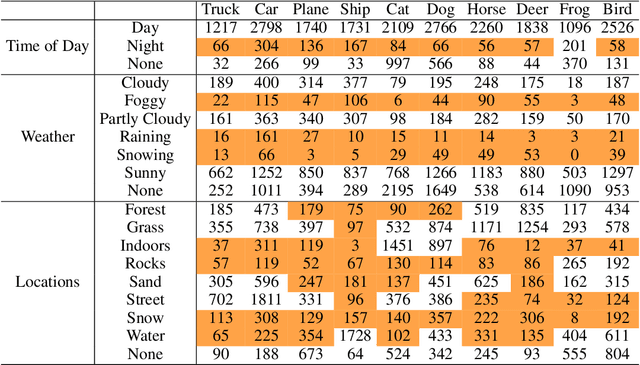

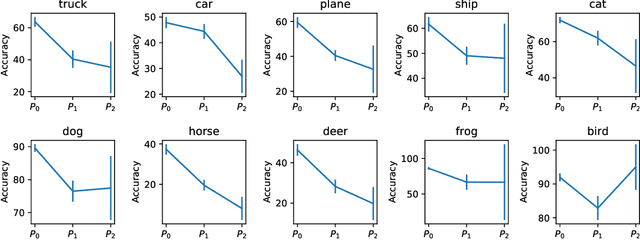
Standard training datasets for deep learning often contain objects in common settings (e.g., "a horse on grass" or "a ship in water") since they are usually collected by randomly scraping the web. Uncommon and rare settings (e.g., "a plane on water", "a car in snowy weather") are thus severely under-represented in the training data. This can lead to an undesirable bias in model predictions towards common settings and create a false sense of accuracy. In this paper, we introduce FOCUS (Familiar Objects in Common and Uncommon Settings), a dataset for stress-testing the generalization power of deep image classifiers. By leveraging the power of modern search engines, we deliberately gather data containing objects in common and uncommon settings in a wide range of locations, weather conditions, and time of day. We present a detailed analysis of the performance of various popular image classifiers on our dataset and demonstrate a clear drop in performance when classifying images in uncommon settings. By analyzing deep features of these models, we show that such errors can be due to the use of spurious features in model predictions. We believe that our dataset will aid researchers in understanding the inability of deep models to generalize well to uncommon settings and drive future work on improving their distributional robustness.
Aligning Visual Regions and Textual Concepts: Learning Fine-Grained Image Representations for Image Captioning
May 15, 2019
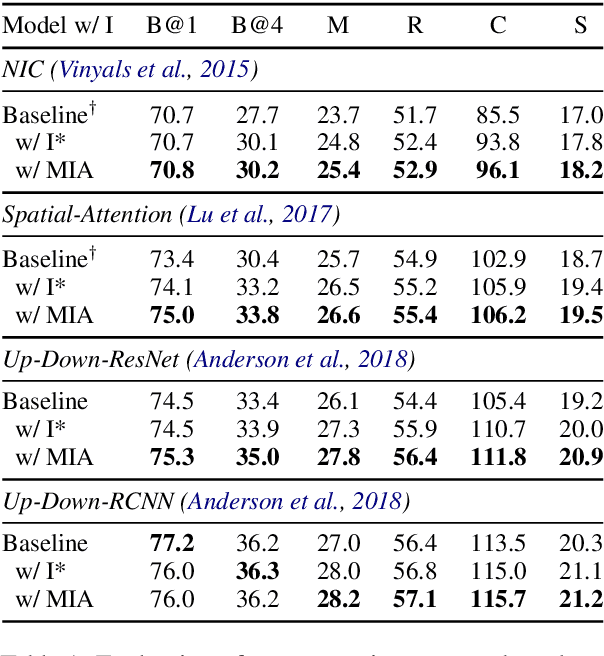
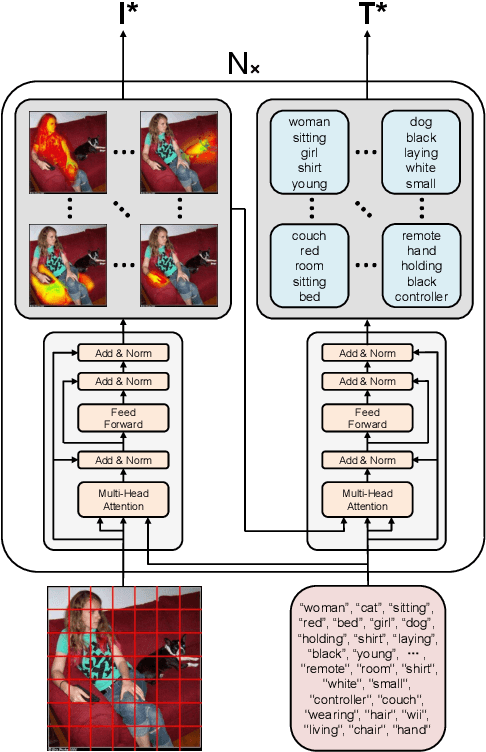
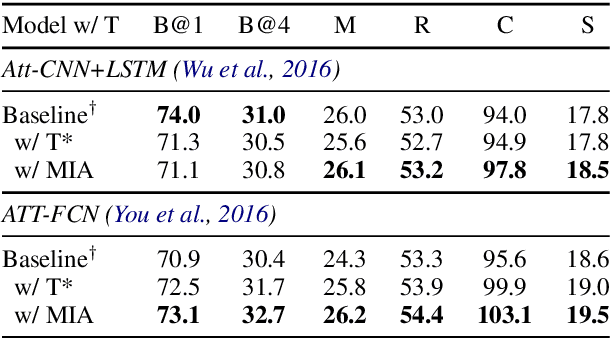
In image-grounded text generation, fine-grained representations of the image are considered to be of paramount importance. Most of the current systems incorporate visual features and textual concepts as a sketch of an image. However, plainly inferred representations are usually undesirable in that they are composed of separate components, the relations of which are elusive. In this work, we aim at representing an image with a set of integrated visual regions and corresponding textual concepts. To this end, we build the Mutual Iterative Attention (MIA) module, which integrates correlated visual features and textual concepts, respectively, by aligning the two modalities. We evaluate the proposed approach on the COCO dataset for image captioning. Extensive experiments show that the refined image representations boost the baseline models by up to 12% in terms of CIDEr, demonstrating that our method is effective and generalizes well to a wide range of models.
Goal-driven text descriptions for images
Aug 28, 2021

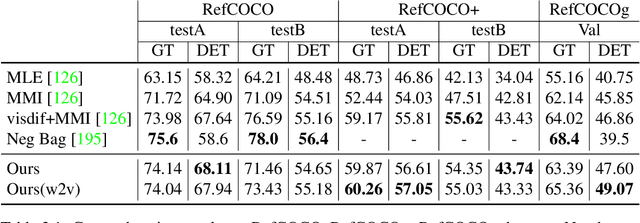
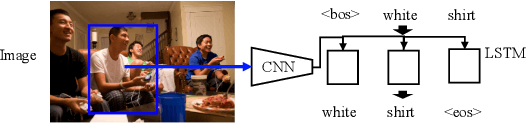
A big part of achieving Artificial General Intelligence(AGI) is to build a machine that can see and listen like humans. Much work has focused on designing models for image classification, video classification, object detection, pose estimation, speech recognition, etc., and has achieved significant progress in recent years thanks to deep learning. However, understanding the world is not enough. An AI agent also needs to know how to talk, especially how to communicate with a human. While perception (vision, for example) is more common across animal species, the use of complicated language is unique to humans and is one of the most important aspects of intelligence. In this thesis, we focus on generating textual output given visual input. In Chapter 3, we focus on generating the referring expression, a text description for an object in the image so that a receiver can infer which object is being described. We use a comprehension machine to directly guide the generated referring expressions to be more discriminative. In Chapter 4, we introduce a method that encourages discriminability in image caption generation. We show that more discriminative captioning models generate more descriptive captions. In Chapter 5, we study how training objectives and sampling methods affect the models' ability to generate diverse captions. We find that a popular captioning training strategy will be detrimental to the diversity of generated captions. In Chapter 6, we propose a model that can control the length of generated captions. By changing the desired length, one can influence the style and descriptiveness of the captions. Finally, in Chapter 7, we rank/generate informative image tags according to their information utility. The proposed method better matches what humans think are the most important tags for the images.
A Cross-Modal Image Fusion Theory Guided by Human Visual Characteristics
Dec 18, 2019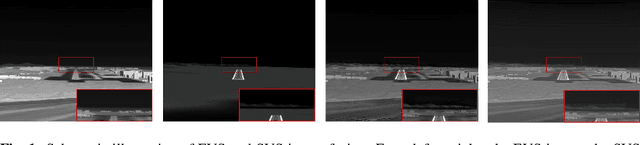
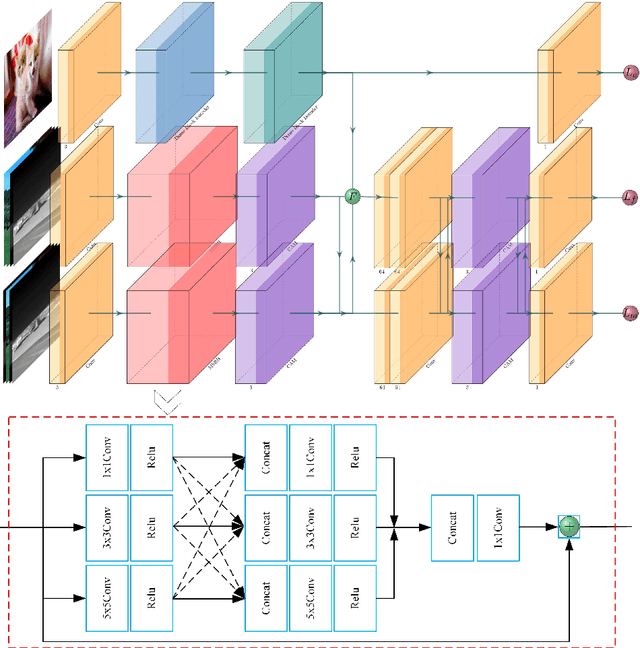

The characteristics of feature selection, nonlinear combination and multi-task auxiliary learning mechanism of human visual perception system play an important role in real-world scenarios, but the research of image fusion theory based on the characteristics of human visual perception is less. Inspired by the characteristics of human visual perception, we propose a robust multi-task auxiliary learning optimization image fusion theory. Firstly, we combine channel attention model with nonlinear convolutional neural network to select features and fuse nonlinear features. Then, we analyze the impact of the existing image fusion loss on the image fusion quality, and establish the multi-loss function model of unsupervised learning network. Secondly, aiming at the multi-task auxiliary learning mechanism of human visual perception system, we study the influence of multi-task auxiliary learning mechanism on image fusion task on the basis of single task multi-loss network model. By simulating the three characteristics of human visual perception system, the fused image is more consistent with the mechanism of human brain image fusion. Finally, in order to verify the superiority of our algorithm, we carried out experiments on the combined vision system image data set, and extended our algorithm to the infrared and visible image and the multi-focus image public data set for experimental verification. The experimental results demonstrate the superiority of our fusion theory over state-of-arts in generality and robustness.
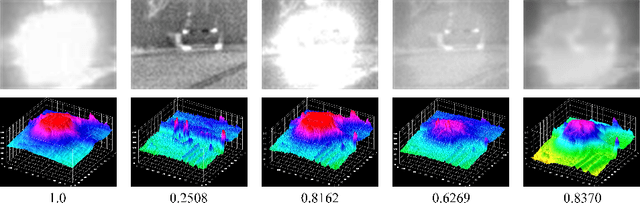
Audio Deepfake Perceptions in College Going Populations
Dec 06, 2021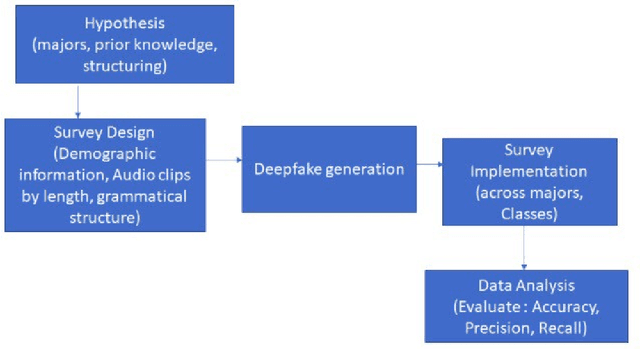
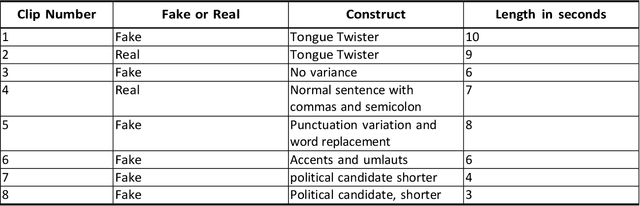

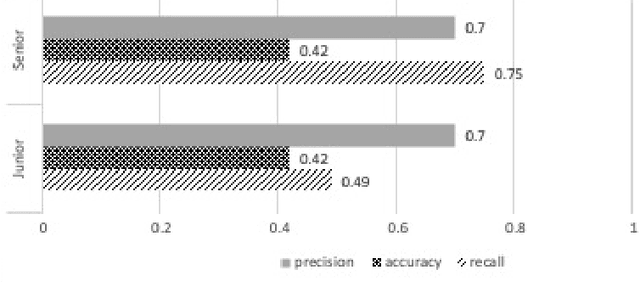
Deepfake is content or material that is generated or manipulated using AI methods, to pass off as real. There are four different deepfake types: audio, video, image and text. In this research we focus on audio deepfakes and how people perceive it. There are several audio deepfake generation frameworks, but we chose MelGAN which is a non-autoregressive and fast audio deepfake generating framework, requiring fewer parameters. This study tries to assess audio deepfake perceptions among college students from different majors. This study also answers the question of how their background and major can affect their perception towards AI generated deepfakes. We also analyzed the results based on different aspects of: grade level, complexity of the grammar used in the audio clips, length of the audio clips, those who knew the term deepfakes and those who did not, as well as the political angle. It is interesting that the results show when an audio clip has a political connotation, it can affect what people think about whether it is real or fake, even if the content is fairly similar. This study also explores the question of how background and major can affect perception towards deepfakes.
LiteDepthwiseNet: An Extreme Lightweight Network for Hyperspectral Image Classification
Oct 15, 2020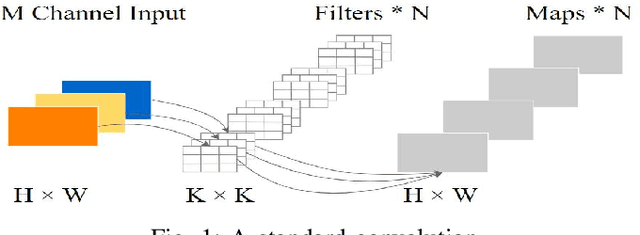
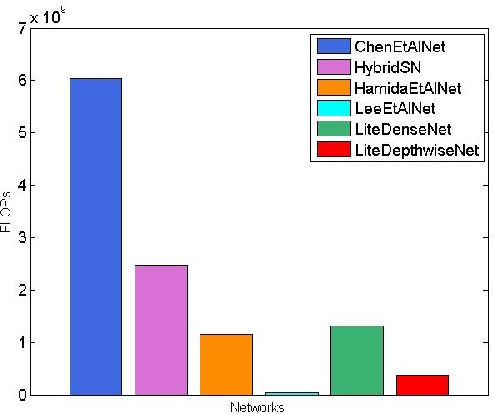
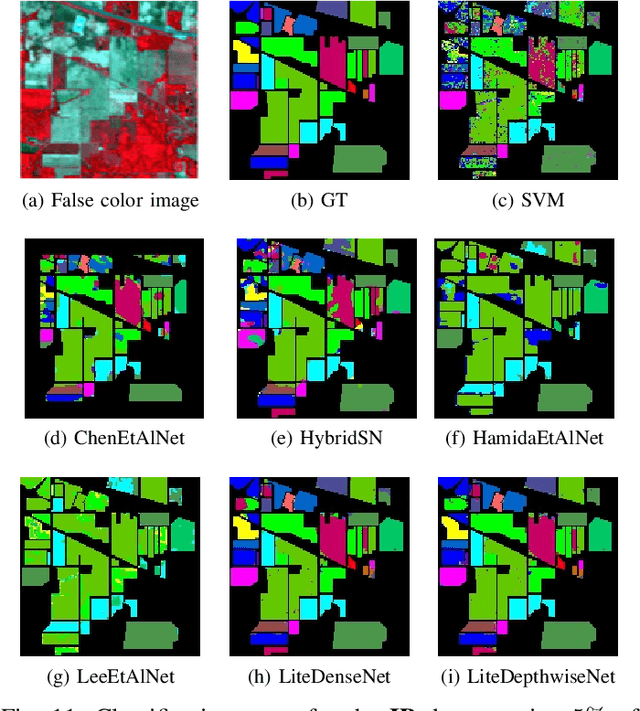
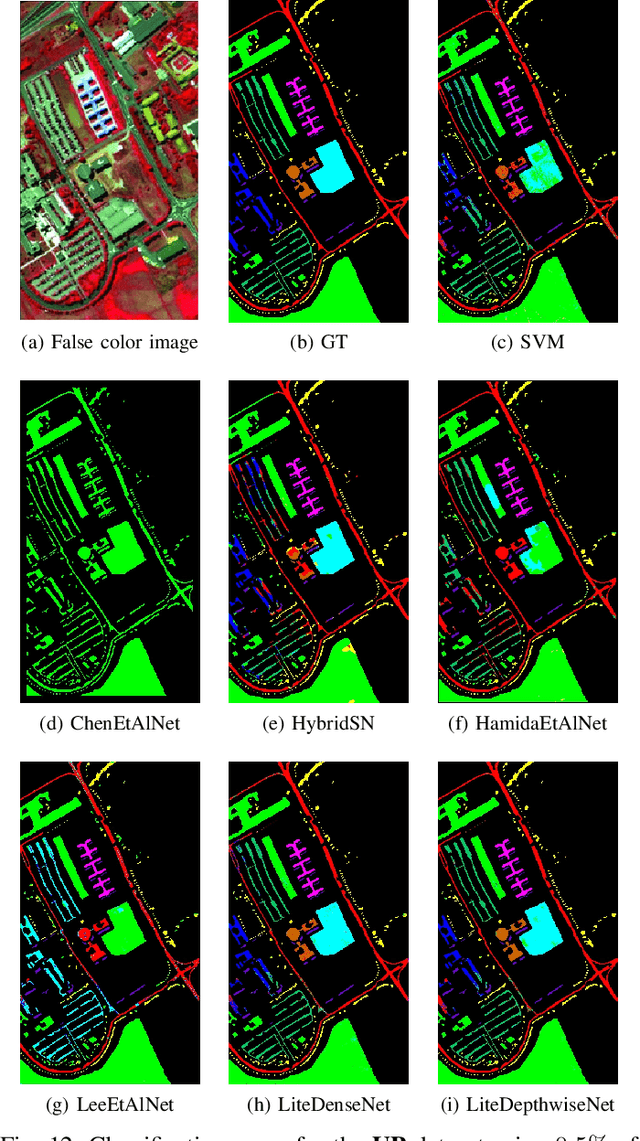
Deep learning methods have shown considerable potential for hyperspectral image (HSI) classification, which can achieve high accuracy compared with traditional methods. However, they often need a large number of training samples and have a lot of parameters and high computational overhead. To solve these problems, this paper proposes a new network architecture, LiteDepthwiseNet, for HSI classification. Based on 3D depthwise convolution, LiteDepthwiseNet can decompose standard convolution into depthwise convolution and pointwise convolution, which can achieve high classification performance with minimal parameters. Moreover, we remove the ReLU layer and Batch Normalization layer in the original 3D depthwise convolution, which significantly improves the overfitting phenomenon of the model on small sized datasets. In addition, focal loss is used as the loss function to improve the model's attention on difficult samples and unbalanced data, and its training performance is significantly better than that of cross-entropy loss or balanced cross-entropy loss. Experiment results on three benchmark hyperspectral datasets show that LiteDepthwiseNet achieves state-of-the-art performance with a very small number of parameters and low computational cost.