 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Multi-task manifold learning for small sample size datasets
Nov 24, 2021
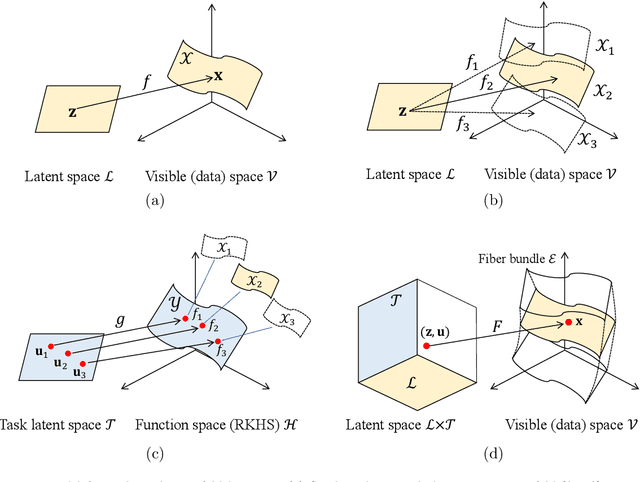
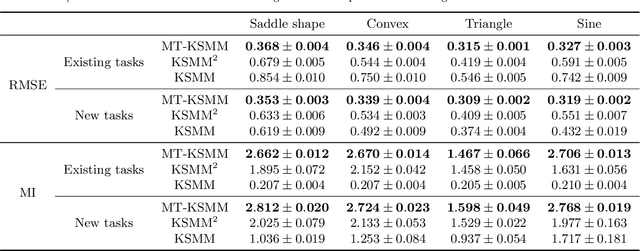
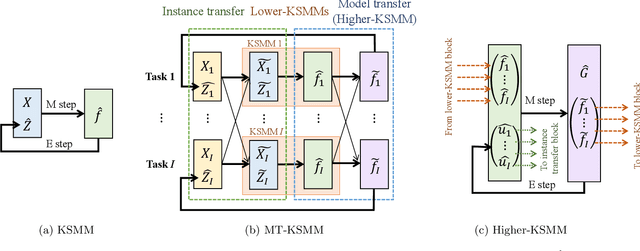

In this study, we develop a method for multi-task manifold learning. The method aims to improve the performance of manifold learning for multiple tasks, particularly when each task has a small number of samples. Furthermore, the method also aims to generate new samples for new tasks, in addition to new samples for existing tasks. In the proposed method, we use two different types of information transfer: instance transfer and model transfer. For instance transfer, datasets are merged among similar tasks, whereas for model transfer, the manifold models are averaged among similar tasks. For this purpose, the proposed method consists of a set of generative manifold models corresponding to the tasks, which are integrated into a general model of a fiber bundle. We applied the proposed method to artificial datasets and face image sets, and the results showed that the method was able to estimate the manifolds, even for a tiny number of samples.
Learning Generalizable Vision-Tactile Robotic Grasping Strategy for Deformable Objects via Transformer
Dec 13, 2021

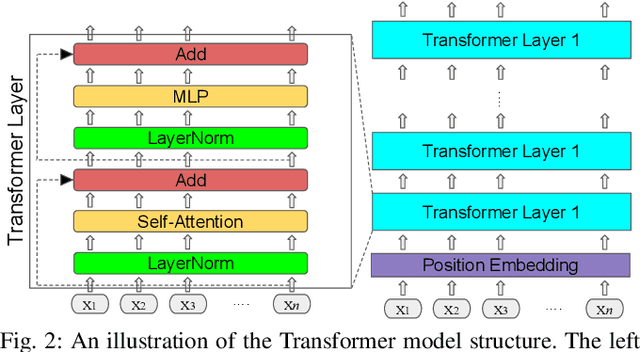
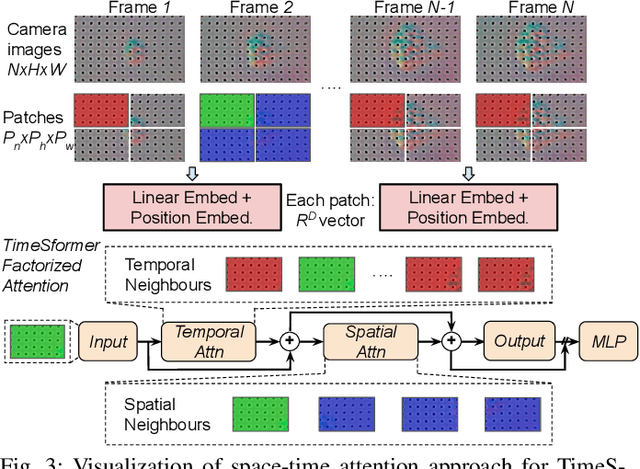
Reliable robotic grasping, especially with deformable objects, (e.g. fruit), remains a challenging task due to underactuated contact interactions with a gripper, unknown object dynamics, and variable object geometries. In this study, we propose a Transformer-based robotic grasping framework for rigid grippers that leverage tactile and visual information for safe object grasping. Specifically, the Transformer models learn physical feature embeddings with sensor feedback through performing two pre-defined explorative actions (pinching and sliding) and predict a final grasping outcome through a multilayer perceptron (MLP) with a given grasping strength. Using these predictions, the gripper is commanded with a safe grasping strength for the grasping tasks via inference. Compared with convolutional recurrent networks, the Transformer models can capture the long-term dependencies across the image sequences and process the spatial-temporal features simultaneously. We first benchmark the proposed Transformer models on a public dataset for slip detection. Following that, we show that the Transformer models outperform a CNN+LSTM model in terms of grasping accuracy and computational efficiency. We also collect our own fruit grasping dataset and conduct the online grasping experiments using the proposed framework for both seen and unseen fruits. Our codes and dataset are made public on GitHub.
Deep Saliency Prior for Reducing Visual Distraction
Sep 05, 2021
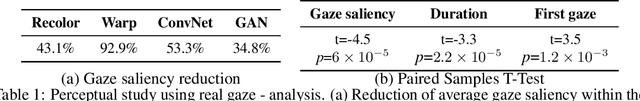


Using only a model that was trained to predict where people look at images, and no additional training data, we can produce a range of powerful editing effects for reducing distraction in images. Given an image and a mask specifying the region to edit, we backpropagate through a state-of-the-art saliency model to parameterize a differentiable editing operator, such that the saliency within the masked region is reduced. We demonstrate several operators, including: a recoloring operator, which learns to apply a color transform that camouflages and blends distractors into their surroundings; a warping operator, which warps less salient image regions to cover distractors, gradually collapsing objects into themselves and effectively removing them (an effect akin to inpainting); a GAN operator, which uses a semantic prior to fully replace image regions with plausible, less salient alternatives. The resulting effects are consistent with cognitive research on the human visual system (e.g., since color mismatch is salient, the recoloring operator learns to harmonize objects' colors with their surrounding to reduce their saliency), and, importantly, are all achieved solely through the guidance of the pretrained saliency model, with no additional supervision. We present results on a variety of natural images and conduct a perceptual study to evaluate and validate the changes in viewers' eye-gaze between the original images and our edited results.
2nd Place Solution for SODA10M Challenge 2021 -- Continual Detection Track
Oct 25, 2021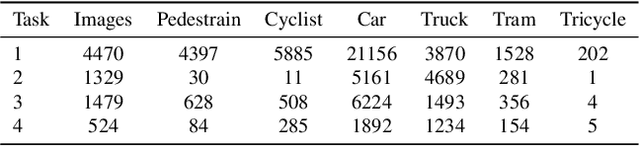
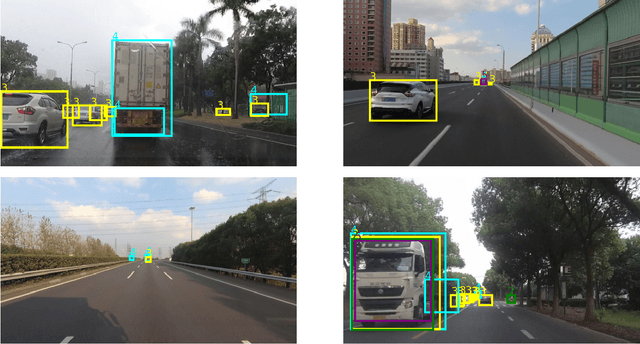
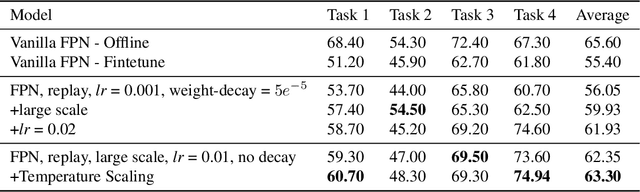

In this technical report, we present our approaches for the continual object detection track of the SODA10M challenge. We adapt ResNet50-FPN as the baseline and try several improvements for the final submission model. We find that task-specific replay scheme, learning rate scheduling, model calibration, and using original image scale helps to improve performance for both large and small objects in images. Our team `hypertune28' secured the second position among 52 participants in the challenge. This work will be presented at the ICCV 2021 Workshop on Self-supervised Learning for Next-Generation Industry-level Autonomous Driving (SSLAD).
Adversarial score matching and improved sampling for image generation
Sep 11, 2020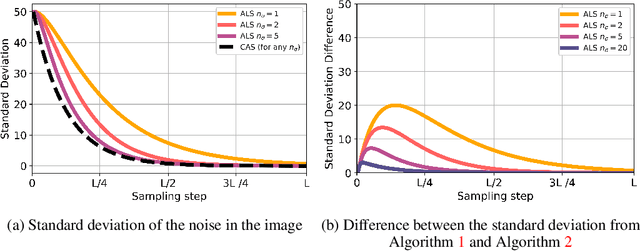

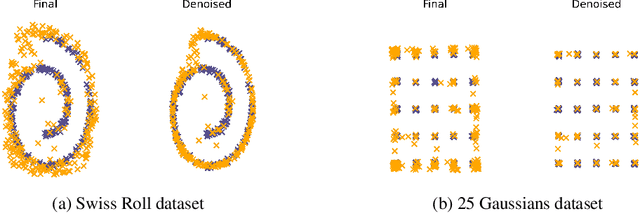
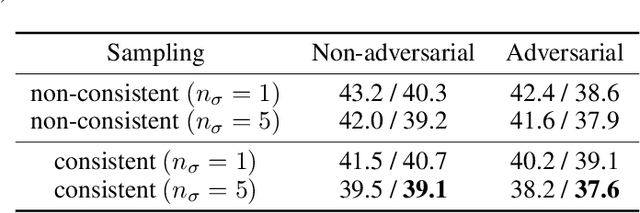
Denoising score matching with Annealed Langevin Sampling (DSM-ALS) is a recent approach to generative modeling. Despite the convincing visual quality of samples, this method appears to perform worse than Generative Adversarial Networks (GANs) under the Fr\'echet Inception Distance, a popular metric for generative models. We show that this apparent gap vanishes when denoising the final Langevin samples using the score network. In addition, we propose two improvements to DSM-ALS: 1) Consistent Annealed Sampling as a more stable alternative to Annealed Langevin Sampling, and 2) a hybrid training formulation,composed of both denoising score matching and adversarial objectives. By combining both of these techniques and exploring different network architectures, we elevate score matching methods and obtain results competitive with state-of-the-art image generation on CIFAR-10.
Achieving on-Mobile Real-Time Super-Resolution with Neural Architecture and Pruning Search
Aug 18, 2021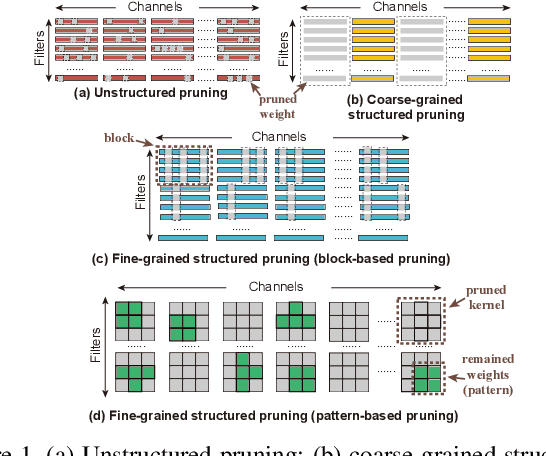
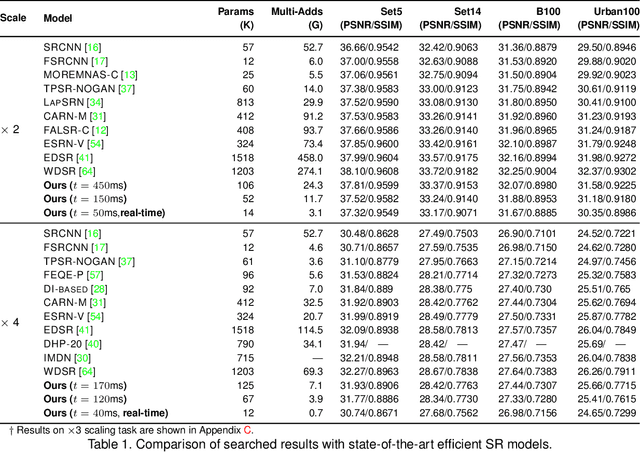
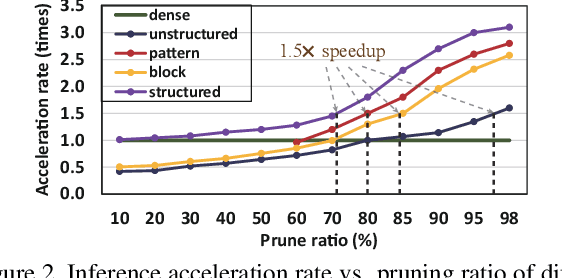
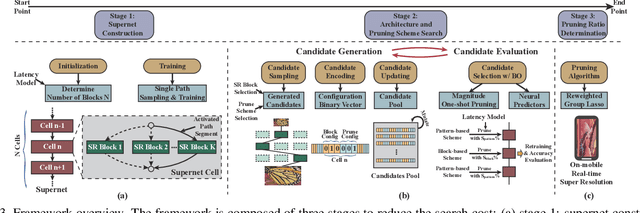
Though recent years have witnessed remarkable progress in single image super-resolution (SISR) tasks with the prosperous development of deep neural networks (DNNs), the deep learning methods are confronted with the computation and memory consumption issues in practice, especially for resource-limited platforms such as mobile devices. To overcome the challenge and facilitate the real-time deployment of SISR tasks on mobile, we combine neural architecture search with pruning search and propose an automatic search framework that derives sparse super-resolution (SR) models with high image quality while satisfying the real-time inference requirement. To decrease the search cost, we leverage the weight sharing strategy by introducing a supernet and decouple the search problem into three stages, including supernet construction, compiler-aware architecture and pruning search, and compiler-aware pruning ratio search. With the proposed framework, we are the first to achieve real-time SR inference (with only tens of milliseconds per frame) for implementing 720p resolution with competitive image quality (in terms of PSNR and SSIM) on mobile platforms (Samsung Galaxy S20).
A Unified End-to-End Framework for Efficient Deep Image Compression
Feb 11, 2020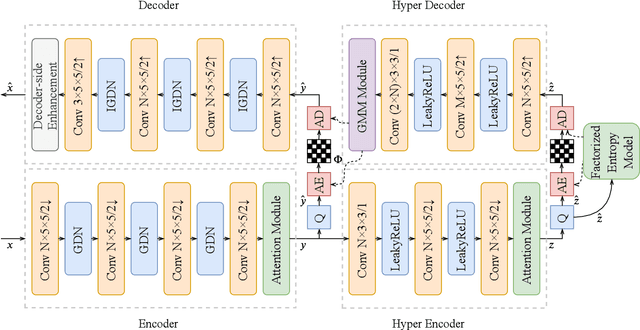
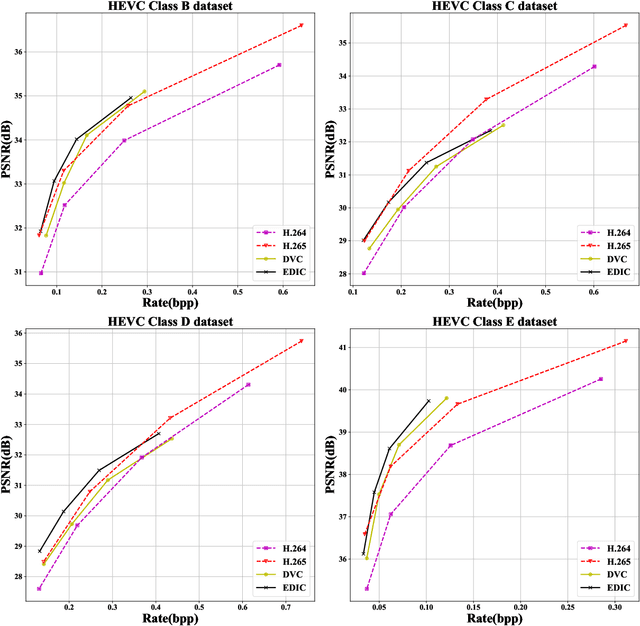
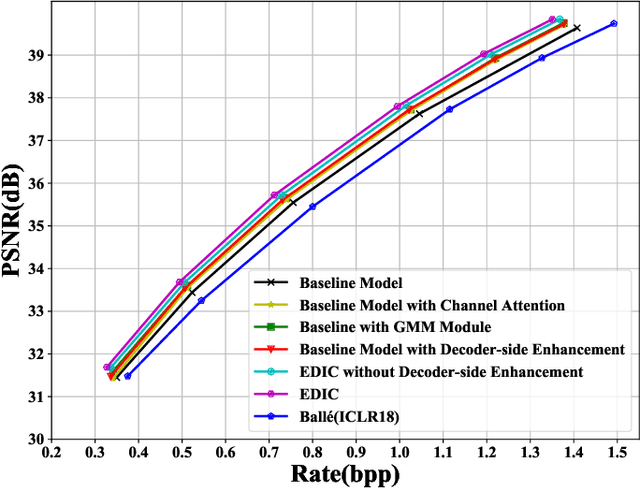
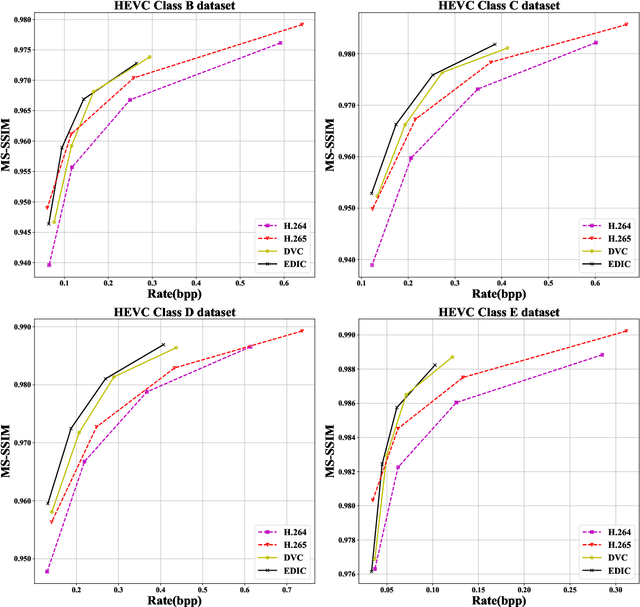
Image compression is a widely used technique to reduce the spatial redundancy in images. Recently, learning based image compression has achieved significant progress by using the powerful representation ability from neural networks. However, the current state-of-the-art learning based image compression methods suffer from the huge computational complexity, which limits their capacity for practical applications. In this paper, we propose a unified framework called Efficient Deep Image Compression (EDIC) based on three new technologies, including a channel attention module, a Gaussian mixture model and a decoder-side enhancement module. Specifically, we design an auto-encoder style network for learning based image compression. To improve the coding efficiency, we exploit the channel relationship between latent representations by using the channel attention module. Besides, the Gaussian mixture model is introduced for the entropy model and improves the accuracy for bitrate estimation. Furthermore, we introduce the decoder-side enhancement module to further improve image compression performance. Our EDIC method can also be readily incorporated with the Deep Video Compression (DVC) framework to further improve the video compression performance. Simultaneously, our EDIC method boosts the coding performance significantly while bringing slightly increased computational complexity. More importantly, experimental results demonstrate that the proposed approach outperforms the current state-of-the-art image compression methods and is up to more than 150 times faster in terms of decoding speed when compared with Minnen's method. The proposed framework also successfully improves the performance of the recent deep video compression system DVC.
Weakly Supervised Semantic Segmentation by Pixel-to-Prototype Contrast
Oct 14, 2021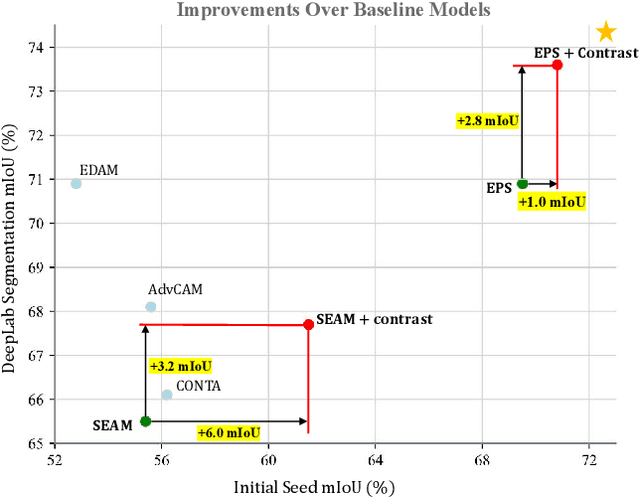
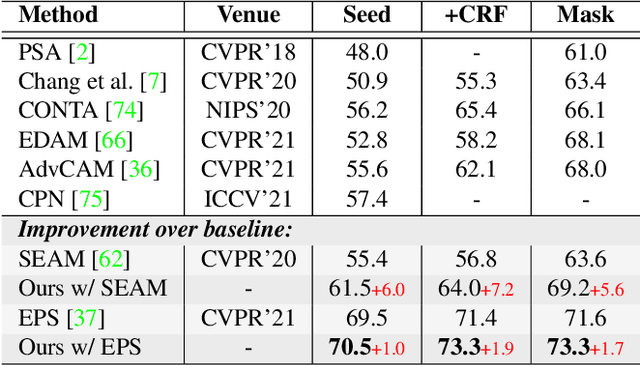
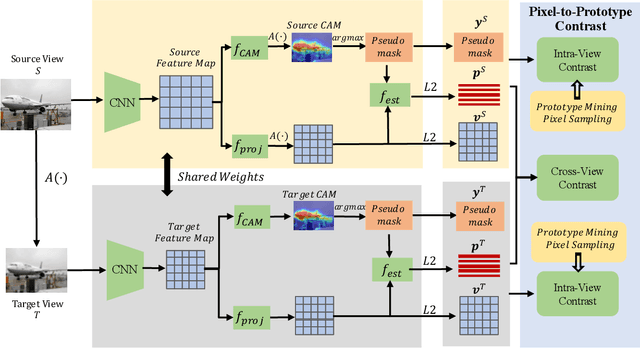
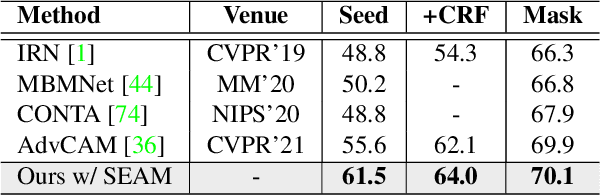
Though image-level weakly supervised semantic segmentation (WSSS) has achieved great progress with Class Activation Map (CAM) as the cornerstone, the large supervision gap between classification and segmentation still hampers the model to generate more complete and precise pseudo masks for segmentation. In this study, we explore two implicit but intuitive constraints, i.e., cross-view feature semantic consistency and intra(inter)-class compactness(dispersion), to narrow the supervision gap. To this end, we propose two novel pixel-to-prototype contrast regularization terms that are conducted cross different views and within per single view of an image, respectively. Besides, we adopt two sample mining strategies, named semi-hard prototype mining and hard pixel sampling, to better leverage hard examples while reducing incorrect contrasts caused due to the absence of precise pixel-wise labels. Our method can be seamlessly incorporated into existing WSSS models without any changes to the base network and does not incur any extra inference burden. Experiments on standard benchmark show that our method consistently improves two strong baselines by large margins, demonstrating the effectiveness of our method. Specifically, built on top of SEAM, we improve the initial seed mIoU on PASCAL VOC 2012 from 55.4% to 61.5%. Moreover, armed with our method, we increase the segmentation mIoU of EPS from 70.8% to 73.6%, achieving new state-of-the-art.
Wavelet Integrated CNNs for Noise-Robust Image Classification
May 07, 2020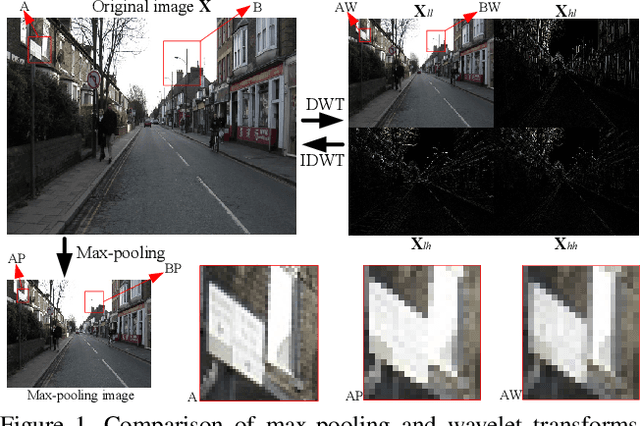
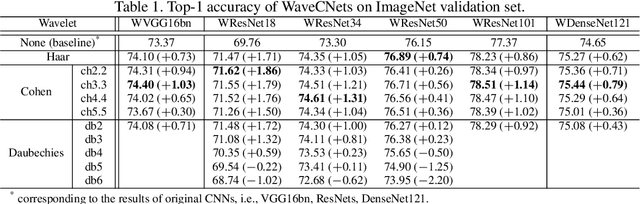
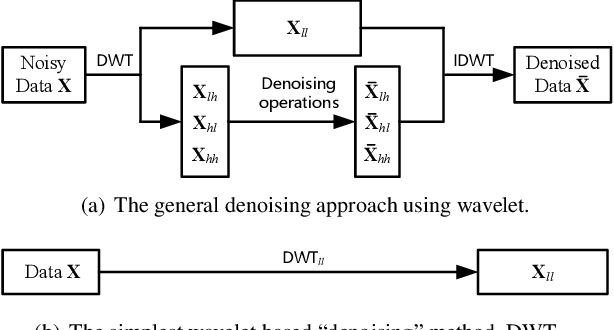
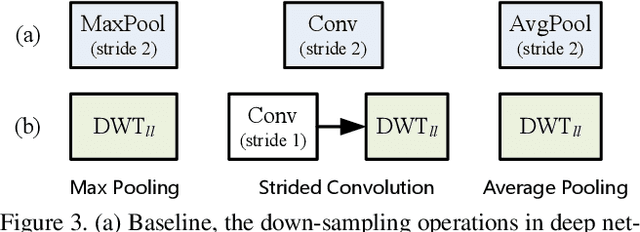
Convolutional Neural Networks (CNNs) are generally prone to noise interruptions, i.e., small image noise can cause drastic changes in the output. To suppress the noise effect to the final predication, we enhance CNNs by replacing max-pooling, strided-convolution, and average-pooling with Discrete Wavelet Transform (DWT). We present general DWT and Inverse DWT (IDWT) layers applicable to various wavelets like Haar, Daubechies, and Cohen, etc., and design wavelet integrated CNNs (WaveCNets) using these layers for image classification. In WaveCNets, feature maps are decomposed into the low-frequency and high-frequency components during the down-sampling. The low-frequency component stores main information including the basic object structures, which is transmitted into the subsequent layers to extract robust high-level features. The high-frequency components, containing most of the data noise, are dropped during inference to improve the noise-robustness of the WaveCNets. Our experimental results on ImageNet and ImageNet-C (the noisy version of ImageNet) show that WaveCNets, the wavelet integrated versions of VGG, ResNets, and DenseNet, achieve higher accuracy and better noise-robustness than their vanilla versions.
OASIS: One-pass aligned Atlas Set for Image Segmentation
Dec 05, 2019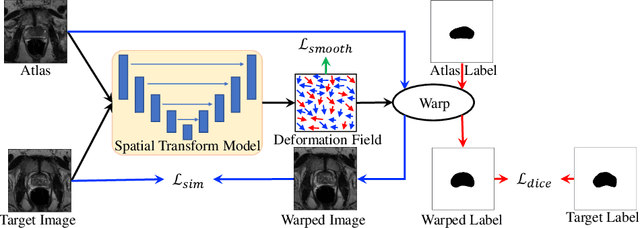
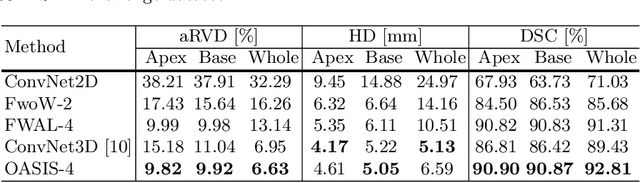
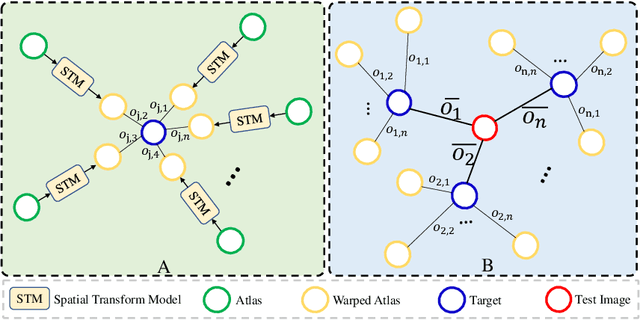
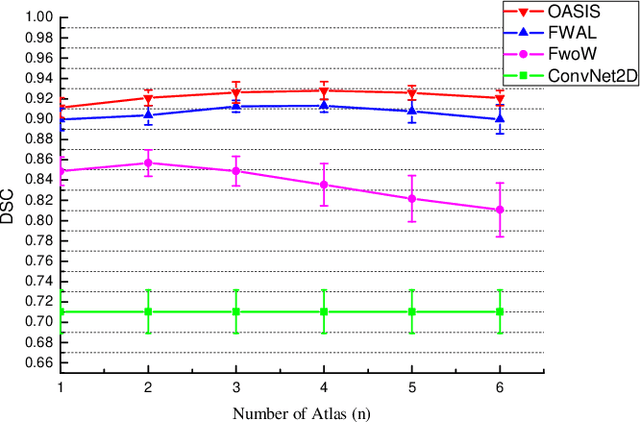
Medical image segmentation is a fundamental task in medical image analysis. Despite that deep convolutional neural networks have gained stellar performance in this challenging task, they typically rely on large labeled datasets, which have limited their extension to customized applications. By revisiting the superiority of atlas based segmentation methods, we present a new framework of One-pass aligned Atlas Set for Images Segmentation (OASIS). To address the problem of time-consuming iterative image registration used for atlas warping, the proposed method takes advantage of the power of deep learning to achieve one-pass image registration. In addition, by applying label constraint, OASIS also makes the registration process to be focused on the regions to be segmented for improving the performance of segmentation. Furthermore, instead of using image based similarity for label fusion, which can be distracted by the large background areas, we propose a novel strategy to compute the label similarity based weights for label fusion. Our experimental results on the challenging task of prostate MR image segmentation demonstrate that OASIS is able to significantly increase the segmentation performance compared to other state-of-the-art methods.