 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Certified Patch Robustness via Smoothed Vision Transformers
Oct 11, 2021

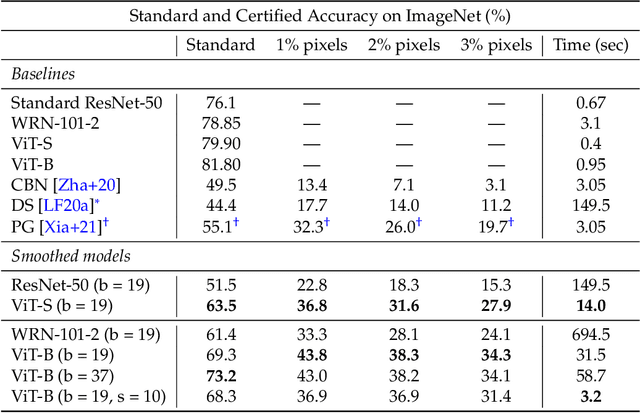
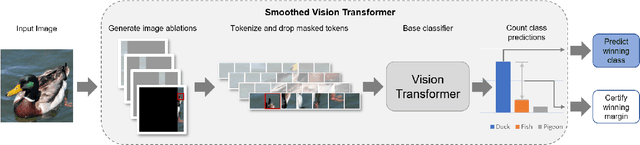
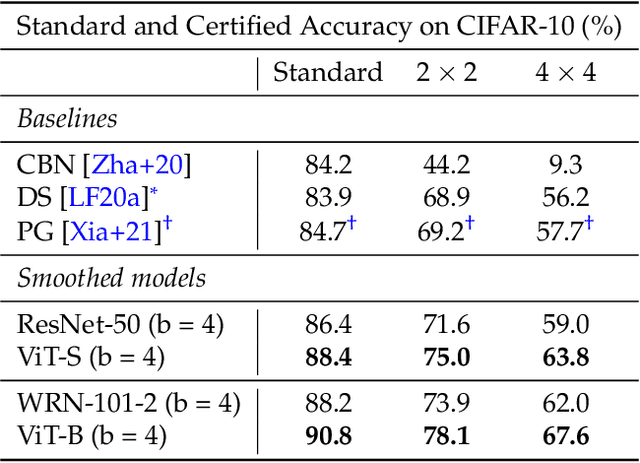
Certified patch defenses can guarantee robustness of an image classifier to arbitrary changes within a bounded contiguous region. But, currently, this robustness comes at a cost of degraded standard accuracies and slower inference times. We demonstrate how using vision transformers enables significantly better certified patch robustness that is also more computationally efficient and does not incur a substantial drop in standard accuracy. These improvements stem from the inherent ability of the vision transformer to gracefully handle largely masked images. Our code is available at https://github.com/MadryLab/smoothed-vit.
Boosting Few-Shot Classification with View-Learnable Contrastive Learning
Jul 30, 2021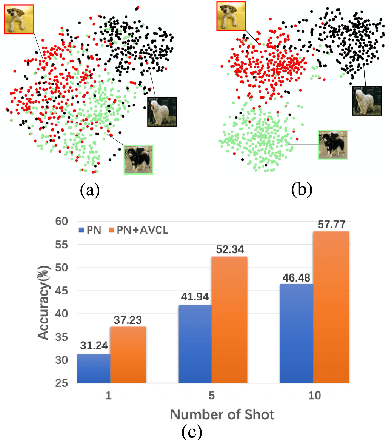
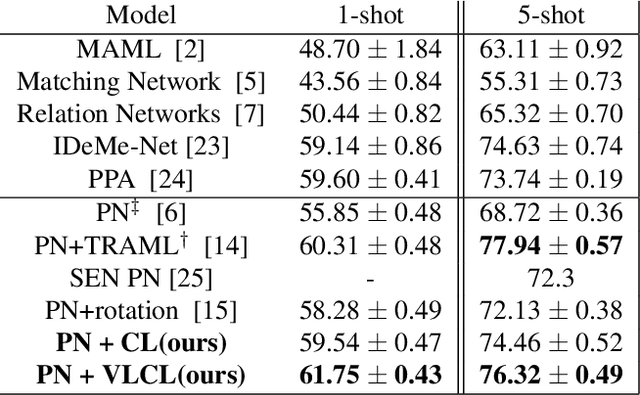
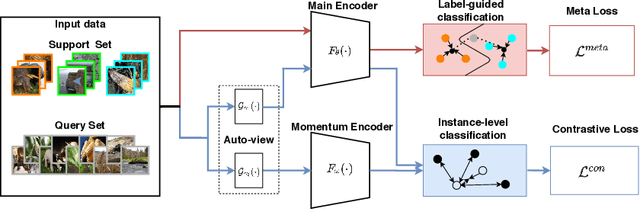
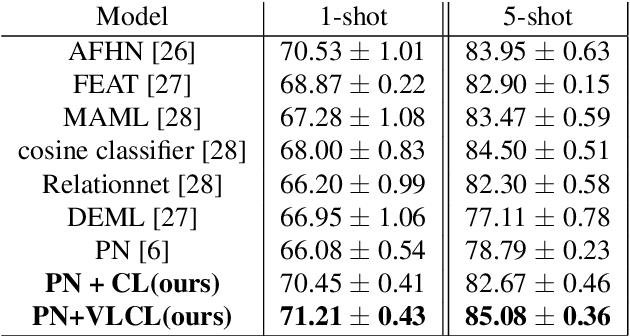
The goal of few-shot classification is to classify new categories with few labeled examples within each class. Nowadays, the excellent performance in handling few-shot classification problems is shown by metric-based meta-learning methods. However, it is very hard for previous methods to discriminate the fine-grained sub-categories in the embedding space without fine-grained labels. This may lead to unsatisfactory generalization to fine-grained subcategories, and thus affects model interpretation. To tackle this problem, we introduce the contrastive loss into few-shot classification for learning latent fine-grained structure in the embedding space. Furthermore, to overcome the drawbacks of random image transformation used in current contrastive learning in producing noisy and inaccurate image pairs (i.e., views), we develop a learning-to-learn algorithm to automatically generate different views of the same image. Extensive experiments on standard few-shot learning benchmarks demonstrate the superiority of our method.
Global and Local Texture Randomization for Synthetic-to-Real Semantic Segmentation
Aug 06, 2021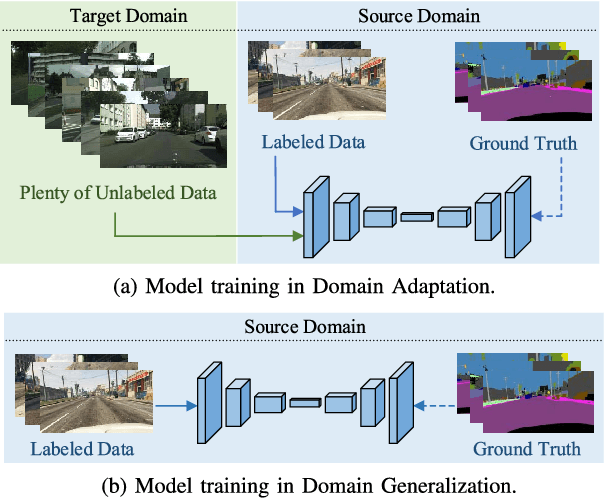
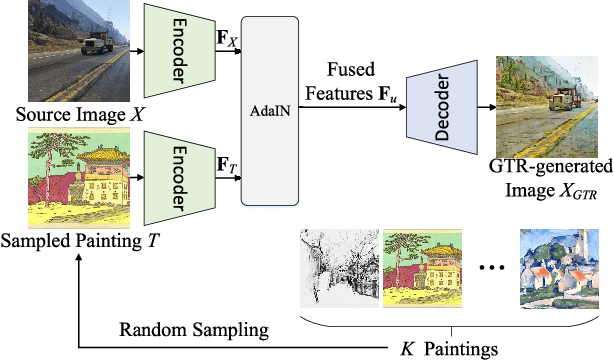
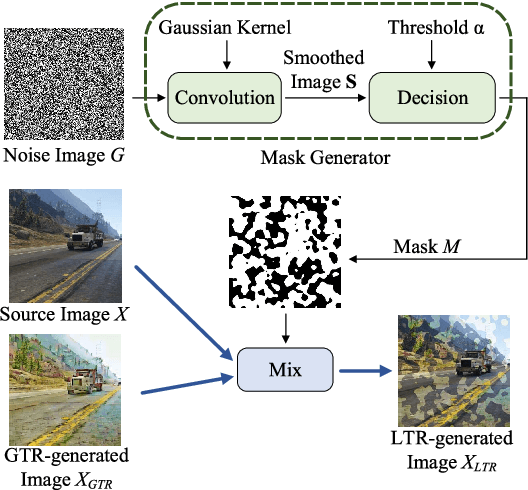
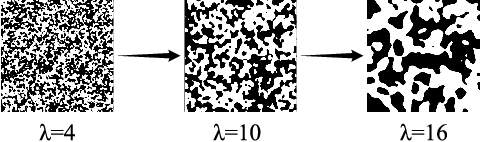
Semantic segmentation is a crucial image understanding task, where each pixel of image is categorized into a corresponding label. Since the pixel-wise labeling for ground-truth is tedious and labor intensive, in practical applications, many works exploit the synthetic images to train the model for real-word image semantic segmentation, i.e., Synthetic-to-Real Semantic Segmentation (SRSS). However, Deep Convolutional Neural Networks (CNNs) trained on the source synthetic data may not generalize well to the target real-world data. In this work, we propose two simple yet effective texture randomization mechanisms, Global Texture Randomization (GTR) and Local Texture Randomization (LTR), for Domain Generalization based SRSS. GTR is proposed to randomize the texture of source images into diverse unreal texture styles. It aims to alleviate the reliance of the network on texture while promoting the learning of the domain-invariant cues. In addition, we find the texture difference is not always occurred in entire image and may only appear in some local areas. Therefore, we further propose a LTR mechanism to generate diverse local regions for partially stylizing the source images. Finally, we implement a regularization of Consistency between GTR and LTR (CGL) aiming to harmonize the two proposed mechanisms during training. Extensive experiments on five publicly available datasets (i.e., GTA5, SYNTHIA, Cityscapes, BDDS and Mapillary) with various SRSS settings (i.e., GTA5/SYNTHIA to Cityscapes/BDDS/Mapillary) demonstrate that the proposed method is superior to the state-of-the-art methods for domain generalization based SRSS.
Unknown Object Segmentation through Domain Adaptation
Aug 09, 2021


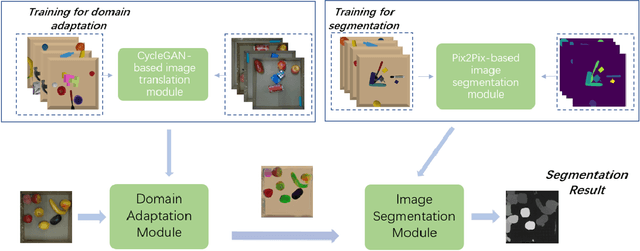
The ability to segment unknown objects in cluttered scenes has a profound impact on robot grasping. The rise of deep learning has greatly transformed the pipeline of robotic grasping from model-based approach to data-driven stream, which generally requires a large scale of grasping data either collected in simulation or from real-world examples. In this paper, we proposed a sim-to-real framework to transfer the object segmentation model learned in simulation to the real-world. First, data samples are collected in simulation, including RGB, 6D pose, and point cloud. Second, we also present a GAN-based unknown object segmentation method through domain adaptation, which consists of an image translation module and an image segmentation module. The image translation module is used to shorten the reality gap and the segmentation module is responsible for the segmentation mask generation. We used the above method to perform segmentation experiments on unknown objects in a bin-picking scenario. Finally, the experimental result shows that the segmentation model learned in simulation can be used for real-world data segmentation.
Cross-Modal Hierarchical Modelling for Fine-Grained Sketch Based Image Retrieval
Jul 29, 2020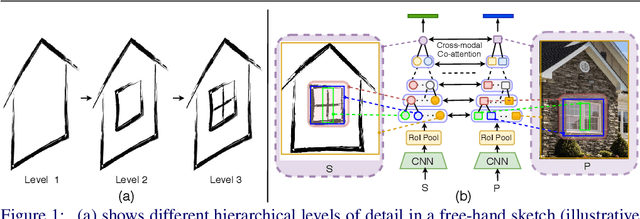
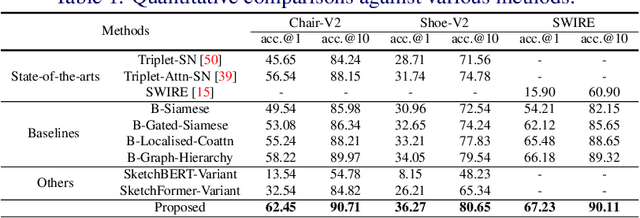
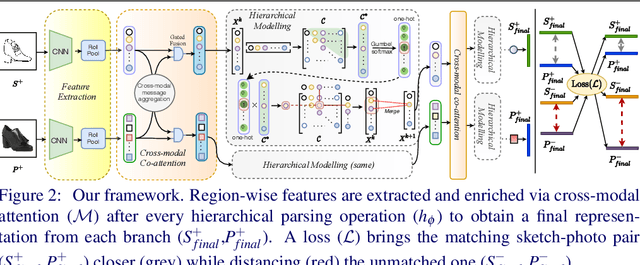
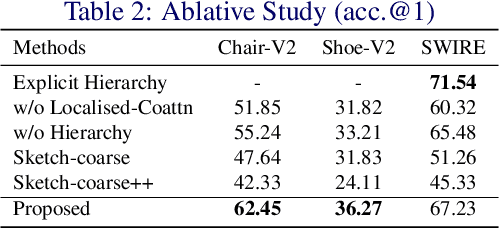
Sketch as an image search query is an ideal alternative to text in capturing the fine-grained visual details. Prior successes on fine-grained sketch-based image retrieval (FG-SBIR) have demonstrated the importance of tackling the unique traits of sketches as opposed to photos, e.g., temporal vs. static, strokes vs. pixels, and abstract vs. pixel-perfect. In this paper, we study a further trait of sketches that has been overlooked to date, that is, they are hierarchical in terms of the levels of detail -- a person typically sketches up to various extents of detail to depict an object. This hierarchical structure is often visually distinct. In this paper, we design a novel network that is capable of cultivating sketch-specific hierarchies and exploiting them to match sketch with photo at corresponding hierarchical levels. In particular, features from a sketch and a photo are enriched using cross-modal co-attention, coupled with hierarchical node fusion at every level to form a better embedding space to conduct retrieval. Experiments on common benchmarks show our method to outperform state-of-the-arts by a significant margin.
HHF: Hashing-guided Hinge Function for Deep Hashing Retrieval
Dec 04, 2021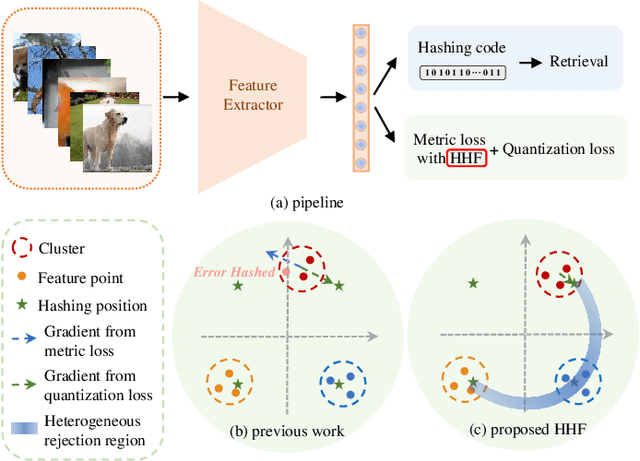

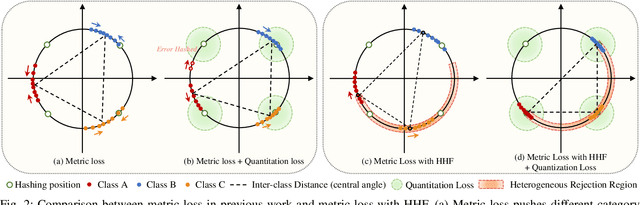
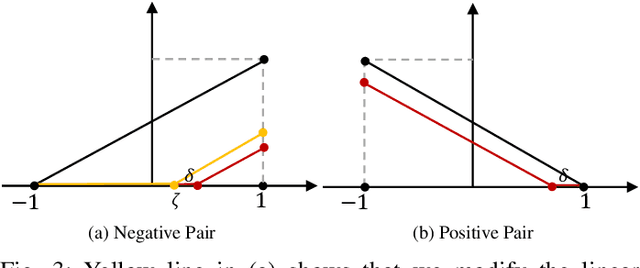
Deep hashing has shown promising performance in large-scale image retrieval. However, latent codes extracted by \textbf{D}eep \textbf{N}eural \textbf{N}etwork (DNN) will inevitably lose semantic information during the binarization process, which damages the retrieval efficiency and make it challenging. Although many existing approaches perform regularization to alleviate quantization errors, we figure out an incompatible conflict between the metric and quantization losses. The metric loss penalizes the inter-class distances to push different classes unconstrained far away. Worse still, it tends to map the latent code deviate from ideal binarization point and generate severe ambiguity in the binarization process. Based on the minimum distance of the binary linear code, \textbf{H}ashing-guided \textbf{H}inge \textbf{F}unction (HHF) is proposed to avoid such conflict. In detail, we carefully design a specific inflection point, which relies on the hash bit length and category numbers to balance metric learning and quantization learning. Such a modification prevents the network from falling into local metric optimal minima in deep hashing. Extensive experiments in CIFAR-10, CIFAR-100, ImageNet, and MS-COCO show that HHF consistently outperforms existing techniques, and is robust and flexible to transplant into other methods.
Comparing concepts of quantum and classical neural network models for image classification task
Aug 23, 2021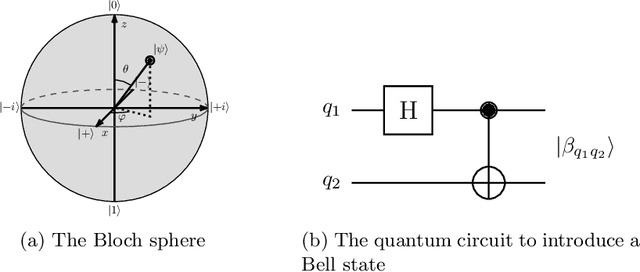

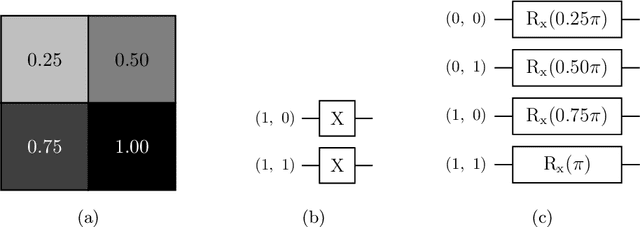
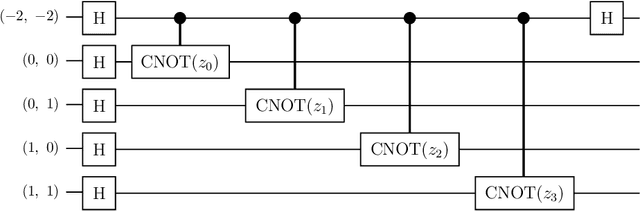
While quantum architectures are still under development, when available, they will only be able to process quantum data when machine learning algorithms can only process numerical data. Therefore, in the issues of classification or regression, it is necessary to simulate and study quantum systems that will transfer the numerical input data to a quantum form and enable quantum computers to use the available methods of machine learning. This material includes the results of experiments on training and performance of a hybrid quantum-classical neural network developed for the problem of classification of handwritten digits from the MNIST data set. The comparative results of two models: classical and quantum neural networks of a similar number of training parameters, indicate that the quantum network, although its simulation is time-consuming, overcomes the classical network (it has better convergence and achieves higher training and testing accuracy).
* 11 pages, 6 figures. The final publication is available via https://doi.org/10.1007/978-3-030-81523-3_6
Image super-resolution reconstruction based on attention mechanism and feature fusion
Apr 08, 2020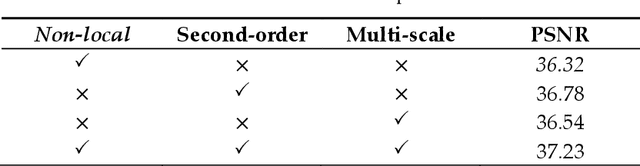
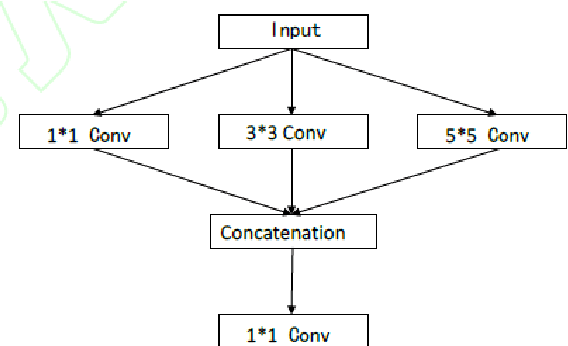
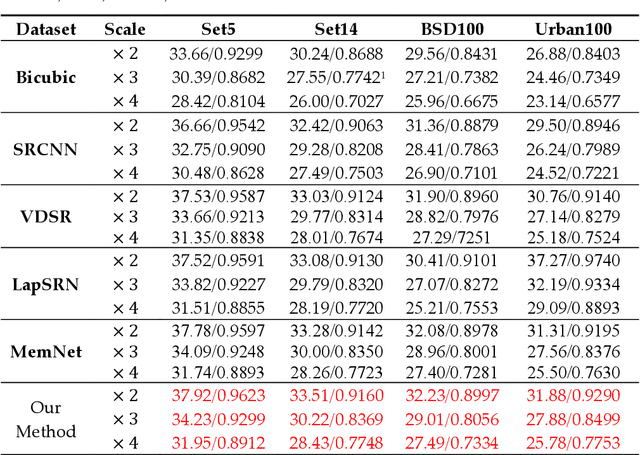
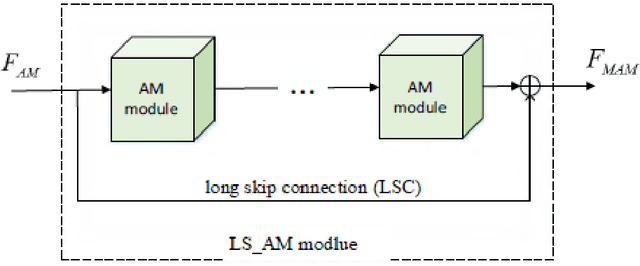
Aiming at the problems that the convolutional neural networks neglect to capture the inherent attributes of natural images and extract features only in a single scale in the field of image super-resolution reconstruction, a network structure based on attention mechanism and multi-scale feature fusion is proposed. By using the attention mechanism, the network can effectively integrate the non-local information and second-order features of the image, so as to improve the feature expression ability of the network. At the same time, the convolution kernel of different scales is used to extract the multi-scale information of the image, so as to preserve the complete information characteristics at different scales. Experimental results show that the proposed method can achieve better performance over other representative super-resolution reconstruction algorithms in objective quantitative metrics and visual quality.
Self-supervised Semi-supervised Learning for Data Labeling and Quality Evaluation
Nov 22, 2021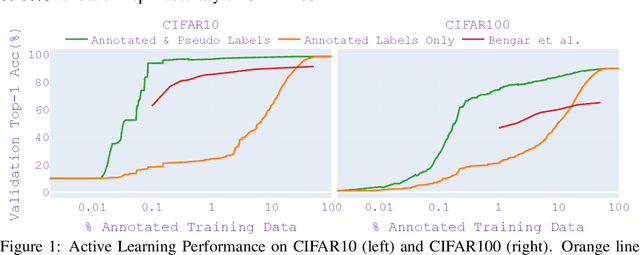
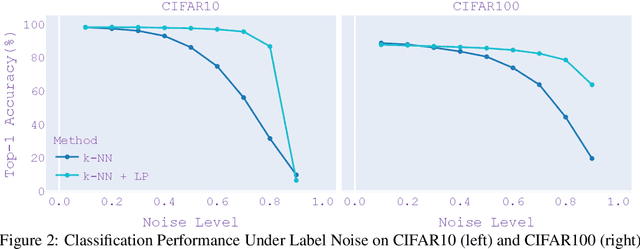
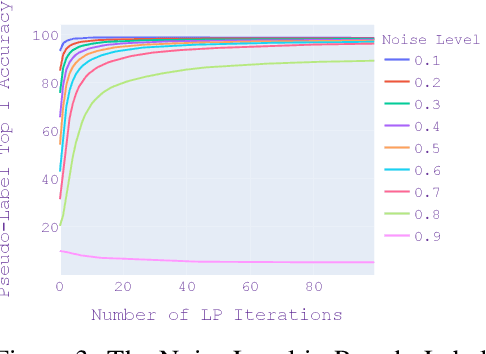
As the adoption of deep learning techniques in industrial applications grows with increasing speed and scale, successful deployment of deep learning models often hinges on the availability, volume, and quality of annotated data. In this paper, we tackle the problems of efficient data labeling and annotation verification under the human-in-the-loop setting. We showcase that the latest advancements in the field of self-supervised visual representation learning can lead to tools and methods that benefit the curation and engineering of natural image datasets, reducing annotation cost and increasing annotation quality. We propose a unifying framework by leveraging self-supervised semi-supervised learning and use it to construct workflows for data labeling and annotation verification tasks. We demonstrate the effectiveness of our workflows over existing methodologies. On active learning task, our method achieves 97.0% Top-1 Accuracy on CIFAR10 with 0.1% annotated data, and 83.9% Top-1 Accuracy on CIFAR100 with 10% annotated data. When learning with 50% of wrong labels, our method achieves 97.4% Top-1 Accuracy on CIFAR10 and 85.5% Top-1 Accuracy on CIFAR100.
EGFN: Efficient Geometry Feature Network for Fast Stereo 3D Object Detection
Nov 28, 2021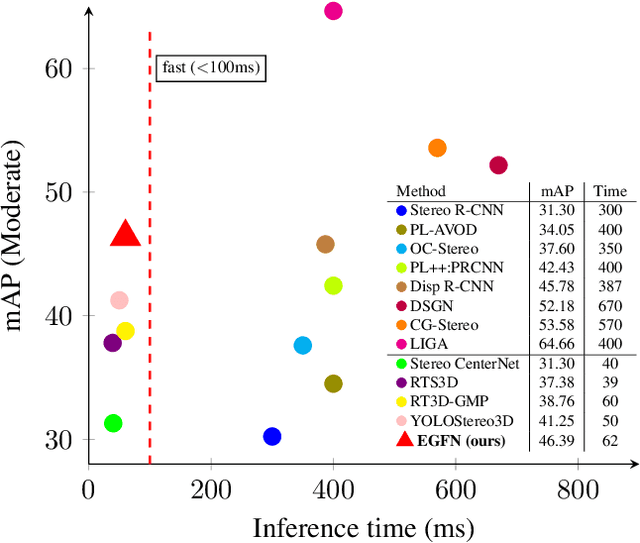
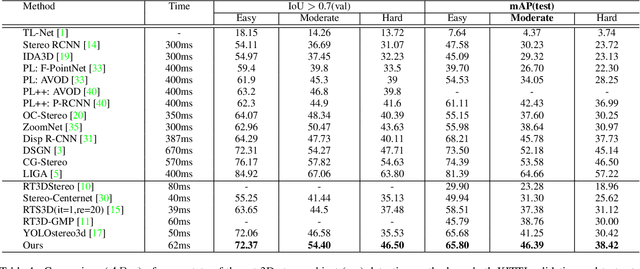
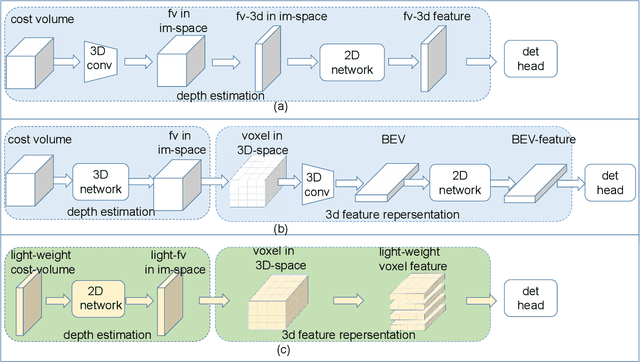
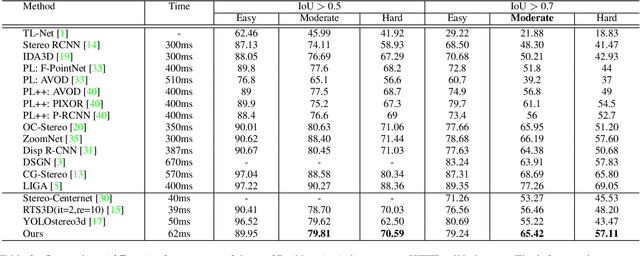
Fast stereo based 3D object detectors have made great progress in the sense of inference time recently. However, they lag far behind high-precision oriented methods in accuracy. We argue that the main reason is the missing or poor 3D geometry feature representation in fast stereo based methods. To solve this problem, we propose an efficient geometry feature generation network (EGFN). The key of our EGFN is an efficient and effective 3D geometry feature representation (EGFR) module. In the EGFR module, light-weight cost volume features are firstly generated, then are efficiently converted into 3D space, and finally multi-scale features enhancement in in both image and 3D spaces is conducted to obtain the 3D geometry features: enhanced light-weight voxel features. In addition, we introduce a novel multi-scale knowledge distillation strategy to guide multi-scale 3D geometry features learning. Experimental results on the public KITTI test set shows that the proposed EGFN outperforms YOLOStsereo3D, the advanced fast method, by 5.16\% on mAP$_{3d}$ at the cost of merely additional 12 ms and hence achieves a better trade-off between accuracy and efficiency for stereo 3D object detection. Our code will be publicly available.