 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
An Acceleration Method Based on Deep Learning and Multilinear Feature Space
Oct 16, 2021
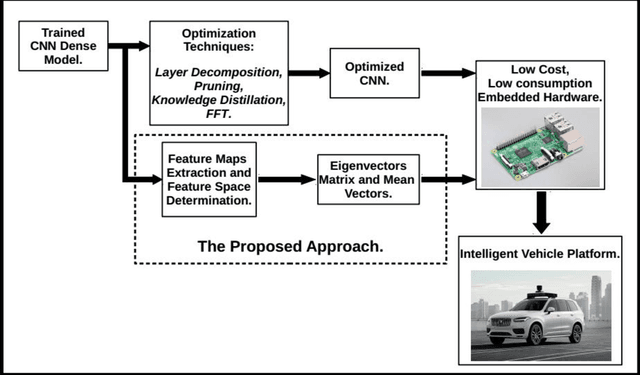
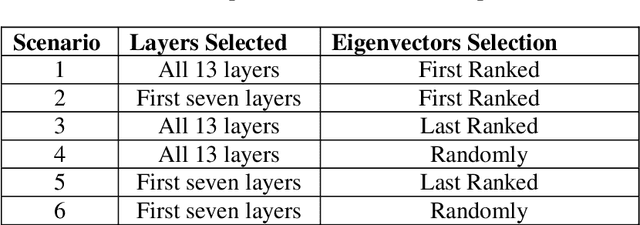
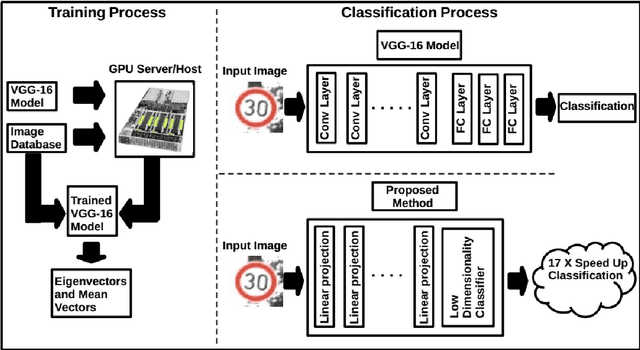
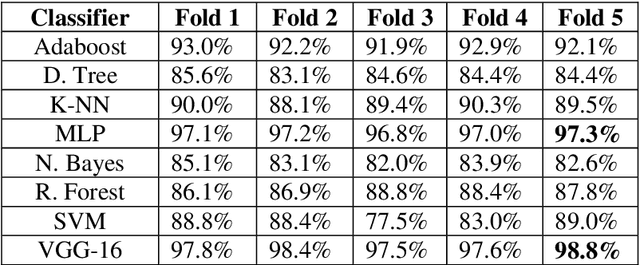
Computer vision plays a crucial role in Advanced Assistance Systems. Most computer vision systems are based on Deep Convolutional Neural Networks (deep CNN) architectures. However, the high computational resource to run a CNN algorithm is demanding. Therefore, the methods to speed up computation have become a relevant research issue. Even though several works on architecture reduction found in the literature have not yet been achieved satisfactory results for embedded real-time system applications. This paper presents an alternative approach based on the Multilinear Feature Space (MFS) method resorting to transfer learning from large CNN architectures. The proposed method uses CNNs to generate feature maps, although it does not work as complexity reduction approach. After the training process, the generated features maps are used to create vector feature space. We use this new vector space to make projections of any new sample to classify them. Our method, named AMFC, uses the transfer learning from pre-trained CNN to reduce the classification time of new sample image, with minimal accuracy loss. Our method uses the VGG-16 model as the base CNN architecture for experiments; however, the method works with any similar CNN model. Using the well-known Vehicle Image Database and the German Traffic Sign Recognition Benchmark, we compared the classification time of the original VGG-16 model with the AMFC method, and our method is, on average, 17 times faster. The fast classification time reduces the computational and memory demands in embedded applications requiring a large CNN architecture.
Boosting Few-Shot Classification with View-Learnable Contrastive Learning
Jul 30, 2021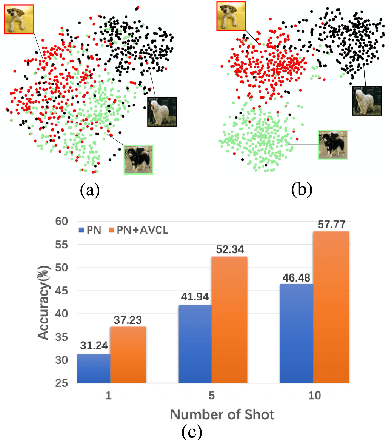
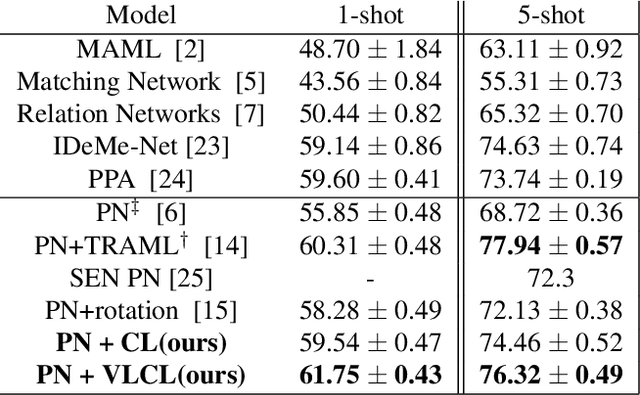
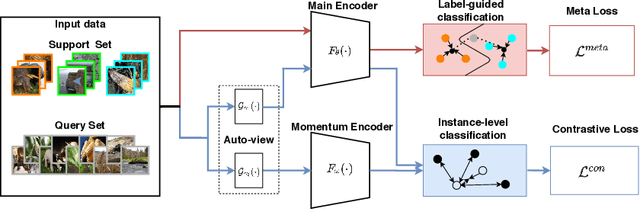
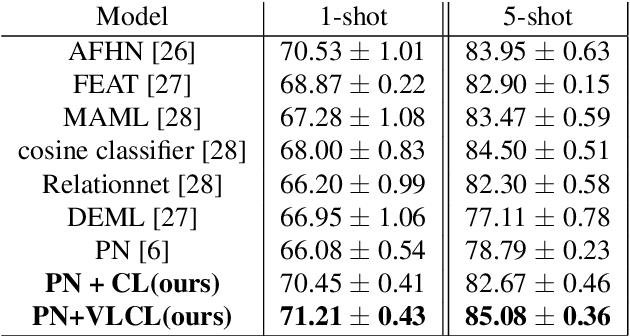
The goal of few-shot classification is to classify new categories with few labeled examples within each class. Nowadays, the excellent performance in handling few-shot classification problems is shown by metric-based meta-learning methods. However, it is very hard for previous methods to discriminate the fine-grained sub-categories in the embedding space without fine-grained labels. This may lead to unsatisfactory generalization to fine-grained subcategories, and thus affects model interpretation. To tackle this problem, we introduce the contrastive loss into few-shot classification for learning latent fine-grained structure in the embedding space. Furthermore, to overcome the drawbacks of random image transformation used in current contrastive learning in producing noisy and inaccurate image pairs (i.e., views), we develop a learning-to-learn algorithm to automatically generate different views of the same image. Extensive experiments on standard few-shot learning benchmarks demonstrate the superiority of our method.
RadFusion: Benchmarking Performance and Fairness for Multimodal Pulmonary Embolism Detection from CT and EHR
Nov 23, 2021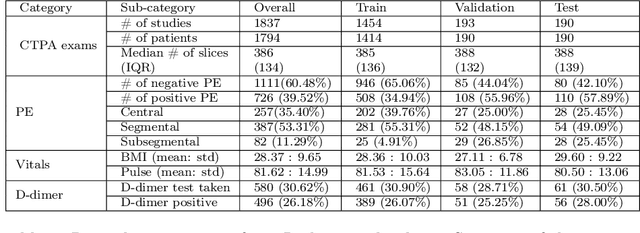
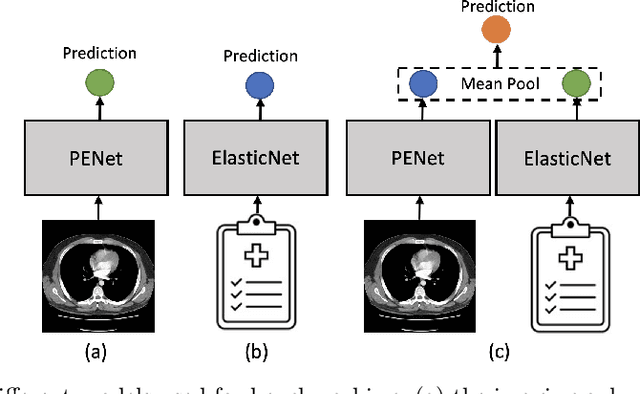
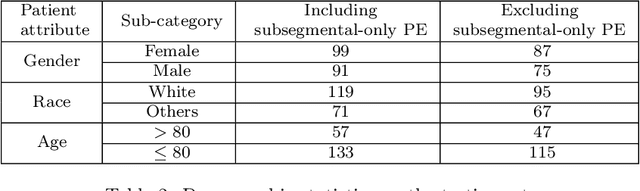
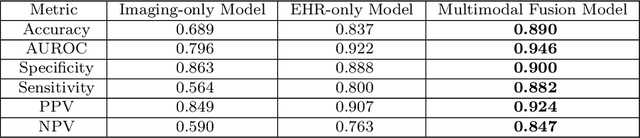
Despite the routine use of electronic health record (EHR) data by radiologists to contextualize clinical history and inform image interpretation, the majority of deep learning architectures for medical imaging are unimodal, i.e., they only learn features from pixel-level information. Recent research revealing how race can be recovered from pixel data alone highlights the potential for serious biases in models which fail to account for demographics and other key patient attributes. Yet the lack of imaging datasets which capture clinical context, inclusive of demographics and longitudinal medical history, has left multimodal medical imaging underexplored. To better assess these challenges, we present RadFusion, a multimodal, benchmark dataset of 1794 patients with corresponding EHR data and high-resolution computed tomography (CT) scans labeled for pulmonary embolism. We evaluate several representative multimodal fusion models and benchmark their fairness properties across protected subgroups, e.g., gender, race/ethnicity, age. Our results suggest that integrating imaging and EHR data can improve classification performance and robustness without introducing large disparities in the true positive rate between population groups.
Homogeneous Learning: Self-Attention Decentralized Deep Learning
Oct 11, 2021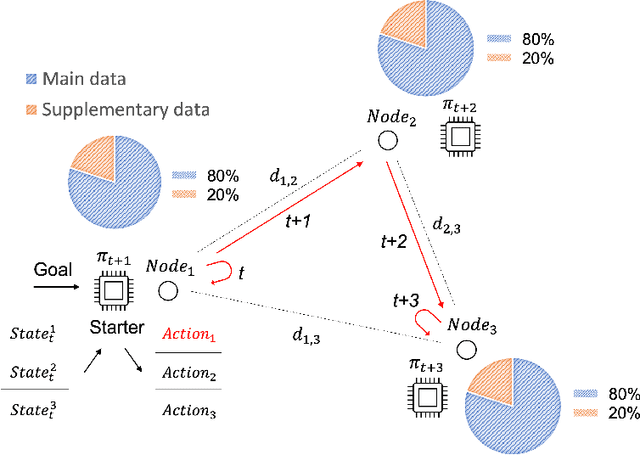
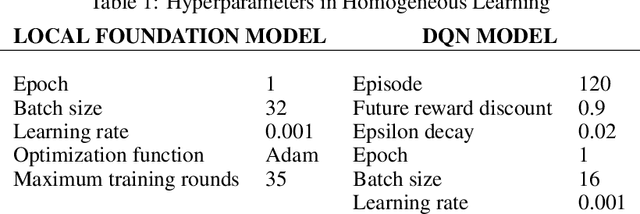
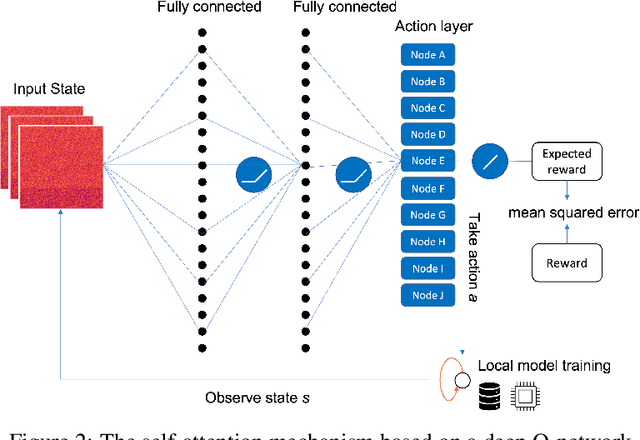
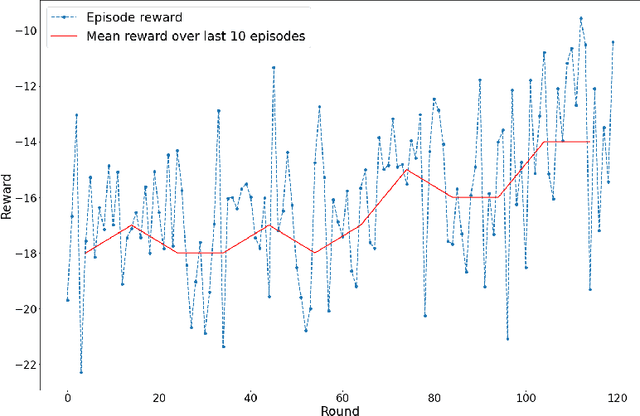
Federated learning (FL) has been facilitating privacy-preserving deep learning in many walks of life such as medical image classification, network intrusion detection, and so forth. Whereas it necessitates a central parameter server for model aggregation, which brings about delayed model communication and vulnerability to adversarial attacks. A fully decentralized architecture like Swarm Learning allows peer-to-peer communication among distributed nodes, without the central server. One of the most challenging issues in decentralized deep learning is that data owned by each node are usually non-independent and identically distributed (non-IID), causing time-consuming convergence of model training. To this end, we propose a decentralized learning model called Homogeneous Learning (HL) for tackling non-IID data with a self-attention mechanism. In HL, training performs on each round's selected node, and the trained model of a node is sent to the next selected node at the end of each round. Notably, for the selection, the self-attention mechanism leverages reinforcement learning to observe a node's inner state and its surrounding environment's state, and find out which node should be selected to optimize the training. We evaluate our method with various scenarios for an image classification task. The result suggests that HL can produce a better performance compared with standalone learning and greatly reduce both the total training rounds by 50.8% and the communication cost by 74.6% compared with random policy-based decentralized learning for training on non-IID data.
MARMOT: A Deep Learning Framework for Constructing Multimodal Representations for Vision-and-Language Tasks
Sep 23, 2021
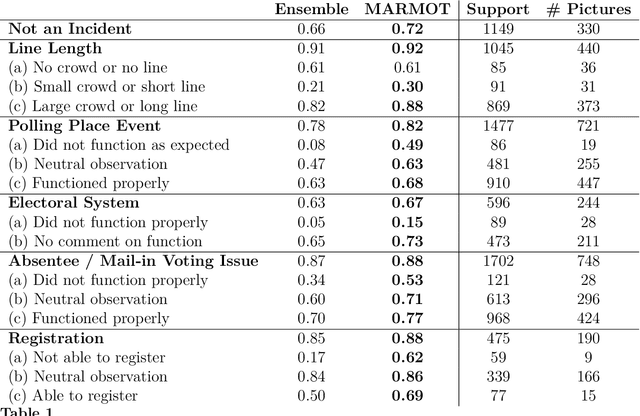
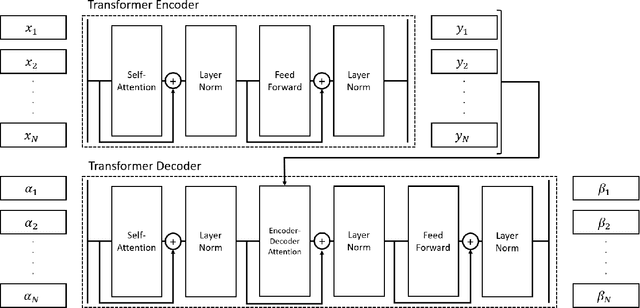
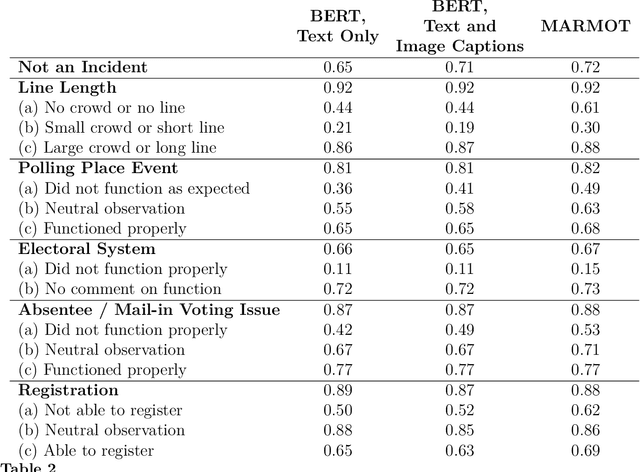
Political activity on social media presents a data-rich window into political behavior, but the vast amount of data means that almost all content analyses of social media require a data labeling step. However, most automated machine classification methods ignore the multimodality of posted content, focusing either on text or images. State-of-the-art vision-and-language models are unusable for most political science research: they require all observations to have both image and text and require computationally expensive pretraining. This paper proposes a novel vision-and-language framework called multimodal representations using modality translation (MARMOT). MARMOT presents two methodological contributions: it can construct representations for observations missing image or text, and it replaces the computationally expensive pretraining with modality translation. MARMOT outperforms an ensemble text-only classifier in 19 of 20 categories in multilabel classifications of tweets reporting election incidents during the 2016 U.S. general election. Moreover, MARMOT shows significant improvements over the results of benchmark multimodal models on the Hateful Memes dataset, improving the best result set by VisualBERT in terms of accuracy from 0.6473 to 0.6760 and area under the receiver operating characteristic curve (AUC) from 0.7141 to 0.7530.
Global and Local Texture Randomization for Synthetic-to-Real Semantic Segmentation
Aug 06, 2021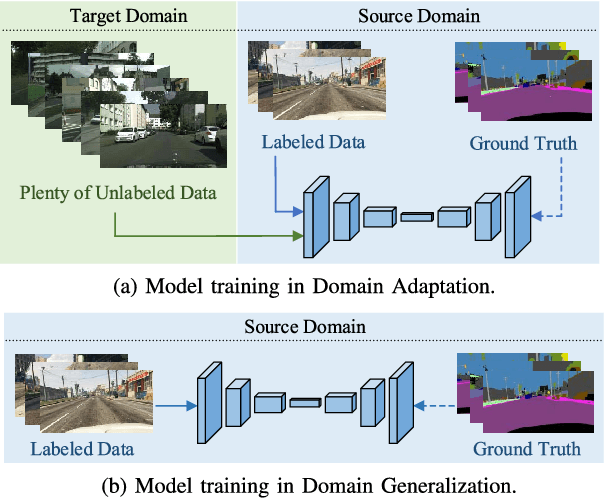
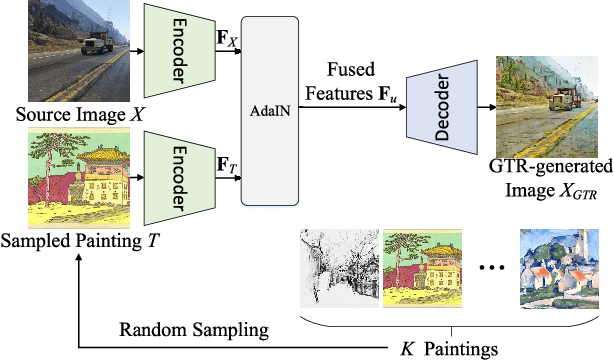
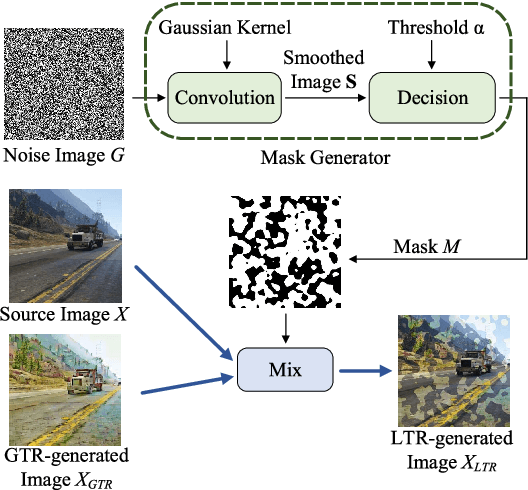
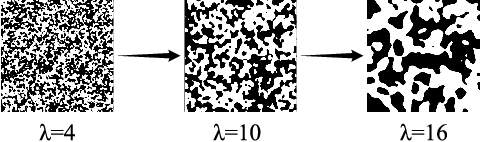
Semantic segmentation is a crucial image understanding task, where each pixel of image is categorized into a corresponding label. Since the pixel-wise labeling for ground-truth is tedious and labor intensive, in practical applications, many works exploit the synthetic images to train the model for real-word image semantic segmentation, i.e., Synthetic-to-Real Semantic Segmentation (SRSS). However, Deep Convolutional Neural Networks (CNNs) trained on the source synthetic data may not generalize well to the target real-world data. In this work, we propose two simple yet effective texture randomization mechanisms, Global Texture Randomization (GTR) and Local Texture Randomization (LTR), for Domain Generalization based SRSS. GTR is proposed to randomize the texture of source images into diverse unreal texture styles. It aims to alleviate the reliance of the network on texture while promoting the learning of the domain-invariant cues. In addition, we find the texture difference is not always occurred in entire image and may only appear in some local areas. Therefore, we further propose a LTR mechanism to generate diverse local regions for partially stylizing the source images. Finally, we implement a regularization of Consistency between GTR and LTR (CGL) aiming to harmonize the two proposed mechanisms during training. Extensive experiments on five publicly available datasets (i.e., GTA5, SYNTHIA, Cityscapes, BDDS and Mapillary) with various SRSS settings (i.e., GTA5/SYNTHIA to Cityscapes/BDDS/Mapillary) demonstrate that the proposed method is superior to the state-of-the-art methods for domain generalization based SRSS.
Monte Carlo dropout increases model repeatability
Nov 12, 2021
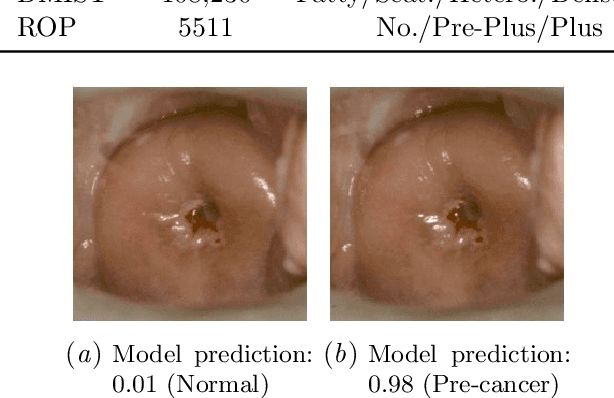
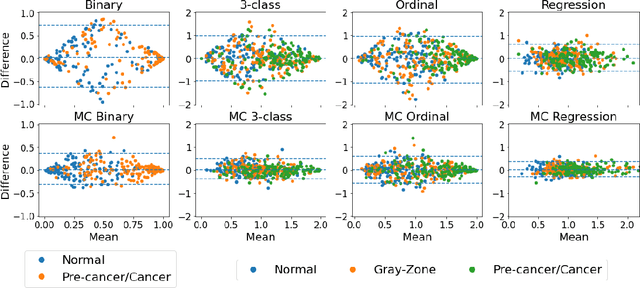
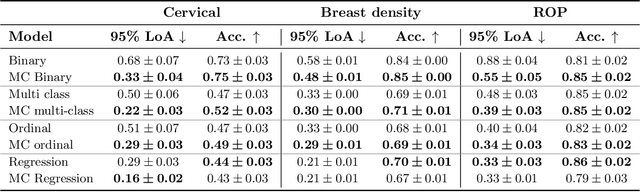
The integration of artificial intelligence into clinical workflows requires reliable and robust models. Among the main features of robustness is repeatability. Much attention is given to classification performance without assessing the model repeatability, leading to the development of models that turn out to be unusable in practice. In this work, we evaluate the repeatability of four model types on images from the same patient that were acquired during the same visit. We study the performance of binary, multi-class, ordinal, and regression models on three medical image analysis tasks: cervical cancer screening, breast density estimation, and retinopathy of prematurity classification. Moreover, we assess the impact of sampling Monte Carlo dropout predictions at test time on classification performance and repeatability. Leveraging Monte Carlo predictions significantly increased repeatability for all tasks on the binary, multi-class, and ordinal models leading to an average reduction of the 95% limits of agreement by 17% points.
Unknown Object Segmentation through Domain Adaptation
Aug 09, 2021


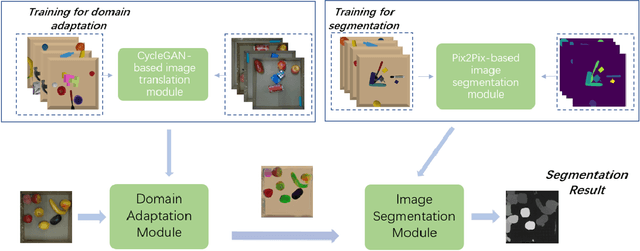
The ability to segment unknown objects in cluttered scenes has a profound impact on robot grasping. The rise of deep learning has greatly transformed the pipeline of robotic grasping from model-based approach to data-driven stream, which generally requires a large scale of grasping data either collected in simulation or from real-world examples. In this paper, we proposed a sim-to-real framework to transfer the object segmentation model learned in simulation to the real-world. First, data samples are collected in simulation, including RGB, 6D pose, and point cloud. Second, we also present a GAN-based unknown object segmentation method through domain adaptation, which consists of an image translation module and an image segmentation module. The image translation module is used to shorten the reality gap and the segmentation module is responsible for the segmentation mask generation. We used the above method to perform segmentation experiments on unknown objects in a bin-picking scenario. Finally, the experimental result shows that the segmentation model learned in simulation can be used for real-world data segmentation.
Block-wise Scrambled Image Recognition Using Adaptation Network
Jan 21, 2020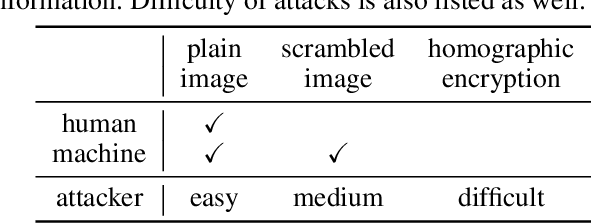
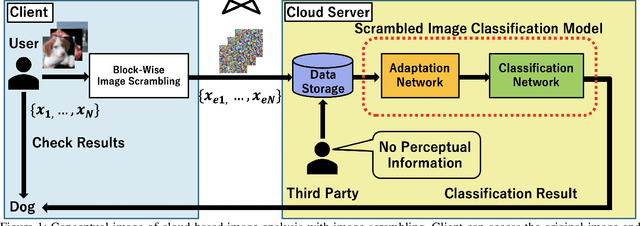


In this study, a perceptually hidden object-recognition method is investigated to generate secure images recognizable by humans but not machines. Hence, both the perceptual information hiding and the corresponding object recognition methods should be developed. Block-wise image scrambling is introduced to hide perceptual information from a third party. In addition, an adaptation network is proposed to recognize those scrambled images. Experimental comparisons conducted using CIFAR datasets demonstrated that the proposed adaptation network performed well in incorporating simple perceptual information hiding into DNN-based image classification.
WeakSTIL: Weak whole-slide image level stromal tumor infiltrating lymphocyte scores are all you need
Sep 13, 2021
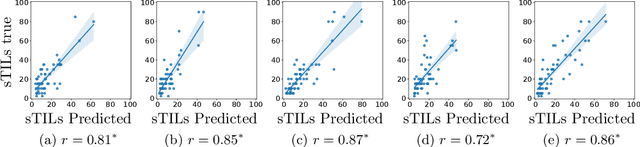
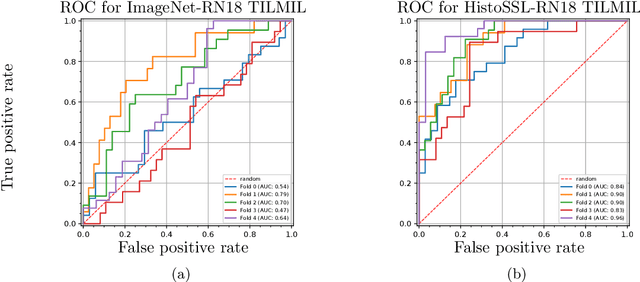
We present WeakSTIL, an interpretable two-stage weak label deep learning pipeline for scoring the percentage of stromal tumor infiltrating lymphocytes (sTIL%) in H&E-stained whole-slide images (WSIs) of breast cancer tissue. The sTIL% score is a prognostic and predictive biomarker for many solid tumor types. However, due to the high labeling efforts and high intra- and interobserver variability within and between expert annotators, this biomarker is currently not used in routine clinical decision making. WeakSTIL compresses tiles of a WSI using a feature extractor pre-trained with self-supervised learning on unlabeled histopathology data and learns to predict precise sTIL% scores for each tile in the tumor bed by using a multiple instance learning regressor that only requires a weak WSI-level label. By requiring only a weak label, we overcome the large annotation efforts required to train currently existing TIL detection methods. We show that WeakSTIL is at least as good as other TIL detection methods when predicting the WSI-level sTIL% score, reaching a coefficient of determination of $0.45\pm0.15$ when compared to scores generated by an expert pathologist, and an AUC of $0.89\pm0.05$ when treating it as the clinically interesting sTIL-high vs sTIL-low classification task. Additionally, we show that the intermediate tile-level predictions of WeakSTIL are highly interpretable, which suggests that WeakSTIL pays attention to latent features related to the number of TILs and the tissue type. In the future, WeakSTIL may be used to provide consistent and interpretable sTIL% predictions to stratify breast cancer patients into targeted therapy arms.